接上一篇文章:
Hadoop学习全程记录——hadoop 入门
这是Hadoop学习全程记录第2篇,在这篇里我将介绍一下如何在Eclipse下写第一个MapReduce程序。
新说明一下我的开发环境:
操作系统:在windows下使用wubi安装了ubuntu 10.10
hadoop版本:hadoop-0.20.2.tar.gz
Eclipse版本:eclipse-jee-helios-SR1-linux-gtk.tar.gz
为了学习方便这个例子在“伪分布式模式”Hadoop安装方式下开发。
第一步,我们先启动Hadoop守护进程。
如果你读过我第1篇文章
Hadoop学习全程记录——hadoop 入门应该比较清楚在“伪分布式模式”下启动Hadoop守护进程的方法,在这里就不多说了。
第二步,在Eclipse下安装hadoop-plugin。
1.复制 hadoop安装目录/contrib/eclipse-plugin/hadoop-0.20.2-eclipse-plugin.jar 到 eclipse安装目录/plugins/ 下。
2.重启eclipse,配置hadoop installation directory。
如果安装插件成功,打开Window-->Preferens,你会发现Hadoop Map/Reduce选项,在这个选项里你需要配置Hadoop installation directory。配置完成后退出。

3.配置Map/Reduce Locations。
在Window-->Show View中打开Map/Reduce Locations。
在Map/Reduce Locations中新建一个Hadoop Location。在这个View中,右键-->New Hadoop Location。在弹出的对话框中你需要配置Location name,如myubuntu,还有Map/Reduce Master和DFS Master。这里面的Host、Port分别为你在mapred-site.xml、core-site.xml中配置的地址及端口。如:
Map/Reduce Master
localhost
9001
DFS Master
localhost
9000

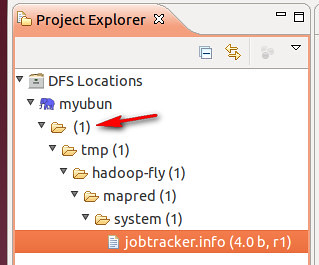
配置完后退出。点击DFS Locations-->myubuntu如果能显示文件夹(2)说明配置正确,如果显示"拒绝连接",请检查你的配置。

第三步,新建项目。
File-->New-->Other-->Map/Reduce Project
项目名可以随便取,如hadoop-test。
复制 hadoop安装目录/src/example/org/apache/hadoop/example/WordCount.java到刚才新建的项目下面。
第四步,上传模拟数据文件夹。
为了运行程序,我们需要一个输入的文件夹,和输出的文件夹。输出文件夹,在程序运行完成后会自动生成。我们需要给程序一个输入文件夹。
1.在当前目录(如hadoop安装目录)下新建文件夹input,并在文件夹下新建两个文件file01、file02,这两个文件内容分别如下:
file01
Hello World Bye World
file02
Hello Hadoop Goodbye Hadoop
2.将文件夹input上传到分布式文件系统中。
在已经启动Hadoop守护进程终端中cd 到hadoop安装目录,运行下面命令:
bin/hadoop fs -put input input01
这个命令将input文件夹上传到了hadoop文件系统了,在该系统下就多了一个input01文件夹,你可以使用下面命令查看:
bin/hadoop fs -ls
第五步,运行项目。
1.在新建的项目hadoop-test,点击WordCount.java,右键-->Run As-->Run Configurations
2.在弹出的Run Configurations对话框中,点Java Application,右键-->New,这时会新建一个application名为WordCount
3.配置运行参数,点Arguments,在Program arguments中输入“你要传给程序的输入文件夹和你要求程序将计算结果保存的文件夹”,如:
hdfs://localhost:9000/user/panhuizhi/input01 hdfs://localhost:9000/user/panhuizhi/output01
这里面的input01就是你刚传上去文件夹。文件夹地址你可以根据自己具体情况填写。

4.点击Run,运行程序。
点击Run,运行程序,过段时间将运行完成,等运行结束后,可以在终端中用命令:
bin/hadoop fs -ls
查看是否生成文件夹output01。
用下面命令查看生成的文件内容:
bin/hadoop fs -cat output01/*
如果显示如下,恭喜你一切顺利,你已经成功在eclipse下运行第一个MapReduce程序了。
Bye 1
Goodbye 1
Hadoop 2
Hello 2
World 2

- 大小: 29.2 KB

- 大小: 44.8 KB

- 大小: 96.4 KB

- 大小: 7.2 KB
分享到:









相关推荐
在本文中,我们将深入探讨如何在Eclipse环境中编写并运行你的第一个MapReduce程序,这是一个针对Hadoop初学者的教程。Hadoop是一个开源框架,用于处理和存储大量数据,而MapReduce是Hadoop的核心计算模型,它将...
总之,要在Windows下的Eclipse环境中成功运行MapReduce程序,关键在于正确配置Hadoop环境,导入所有必要的jar包,并理解如何设置和提交MapReduce作业。这个过程可能需要一些时间和实践,但一旦配置完成,将为高效...
Eclipse作为流行的Java集成开发环境,配合Hadoop-Eclipse Plugin,使得在Eclipse中编写、调试和运行MapReduce程序变得非常方便。 ### 实验目的 1. 学习如何在Ubuntu/CentOS系统上使用Eclipse开发MapReduce程序。 2....
在Hadoop 2.6.0中,运行一个简单的MapReduce示例——WordCount,至少需要以下三个JAR文件: - `$HADOOP_HOME/share/hadoop/common/hadoop-common-2.6.0.jar` - `$HADOOP_HOME/share/hadoop/mapreduce/hadoop-...
在Eclipse中运行MapReduce程序,特别是针对Hadoop的Word Count示例,是学习和开发分布式计算的关键步骤。本文将详细介绍如何在Eclipse环境中配置和运行一个简单的MapReduce项目,以便于理解Hadoop的工作原理。 首先...
接着,安装Hadoop-Eclipse-Plugin插件,该插件允许开发者在Eclipse中直接编写、调试和运行MapReduce程序。配置插件时,要确保指向正确的Hadoop安装路径,以便Eclipse能识别Hadoop环境。通过Eclipse操作HDFS文件,...
选择 WordCount 程序,在 Arguments 中配置运行参数:/mapreduce/wordcount/input /mapreduce/wordcount/output/1 分别表示 HDFS 下的输入目录和输出目录,其中输入目录中有几个文本文件,输出目录必须不存在。...
Eclipse Hadoop2 插件是为开发人员提供的一种强大工具,它允许用户在Eclipse集成开发环境中(IDE)直接编写、调试和管理Hadoop项目。这个插件针对Hadoop 2.x版本进行了优化,提供了丰富的功能来简化Hadoop应用程序的...
在这个"可运行的Hadoop1 MapReduce Eclipse项目"中,开发者编写了MapReduce程序来计算电影的平均评分、总评分人数以及去重后的评分人数。这通常涉及到从大规模的用户评价数据中提取信息,通过Map阶段对每条评价进行...
本文主要介绍了如何使用Java编写MapReduce程序,并运行第一个MapReduce作业,包括遇到的问题和解决方案。 首先,环境搭建是使用Hadoop MapReduce的重要步骤。本文的环境基于CDH5(Cloudera's Distribution ...
在进行Hadoop MapReduce的学习和开发时,尤其是在Windows环境下,我们通常需要搭建一个模拟的分布式环境来进行测试。...在学习过程中,记得结合文档资料,实践操作,不断调试和优化,才能更好地掌握这一技术。
标题中的“eclipse运行MapReduce架包”指的是使用Eclipse集成开发环境来运行Apache Hadoop的MapReduce程序。Hadoop是大数据处理领域的基石,而MapReduce是它的一部分,用于处理和存储海量数据。Eclipse插件`hadoop-...
通过学习和运行这些案例,开发者可以快速掌握Hadoop MapReduce编程模型,以及在Eclipse中部署和调试作业的方法。 总的来说,要使Eclipse连接并运行Hadoop项目,我们需要安装Hadoop Eclipse Plugin,并理解`hadoop....
最近学习hadoop,发现Hadoop不提供编译后的hadoop-eclipse插件,于是就自己动手编译了hadoop-eclipse-plugin-1.1.0.rar插件 Hadoop1.1.0是beta版本,有兴趣的朋友可以下载装装,感受下MapReduce编程框架
这个插件允许开发者直接在IDE中对Hadoop集群进行操作,如创建、编辑和运行MapReduce任务,极大地提升了开发效率。本文将详细介绍这两个版本的Hadoop Eclipse Plugin——1.2.1和2.8.0。 首先,Hadoop-Eclipse-Plugin...
Eclipse是流行的Java集成开发环境(IDE),而Hadoop-Eclipse插件是将Hadoop与Eclipse结合的工具,允许开发者在Eclipse中直接创建、运行和调试Hadoop MapReduce程序。这些文件"hadop-eclipse-plugin-2.5.2.jar"、...
在这个案例中,我们将深入探讨如何在 Hadoop 环境中使用 MapReduce 实现 WordCount。 【描述】在 Hadoop 环境中,WordCount 的实现主要涉及两个关键阶段:Map 阶段和 Reduce 阶段。Map 阶段将原始输入数据(通常是...
这个插件提供了在Eclipse中直接创建、编辑和运行Hadoop MapReduce程序的功能。通过这个插件,开发者可以将Hadoop集群视图集成到Eclipse的工作空间中,使得集群管理和任务调度变得更加直观和便捷。 以下是使用Hadoop...
在Windows环境下,使用Eclipse进行远程开发MapReduce程序是一个复杂的过程,涉及到多个步骤,包括环境配置、插件安装以及依赖管理。以下是对整个过程的详细解释: 首先,我们需要准备必要的工具和库。`hadoop-...