gaozzsoft
- ТхЈУДѕ: 427237 ТгА
- ТђДтѕФ:

- ТЮЦУЄф: тїЌС║г
-

ТќЄуФатѕєу▒╗
- тЁежЃетЇџт«б (184)
- IDE (4)
- dotCMS (3)
- Liferay Portal (1)
- J2EE (7)
- My SQL (16)
- IBM DB2 (3)
- Oracle (2)
- JDBC (4)
- Hibernate (3)
- JSP (0)
- Framework (4)
- Javaу╝ќуеІ (30)
- C++у╝ќуеІ (0)
- Struts 1.X (2)
- Struts 2.X (6)
- Linux (11)
- Spring (7)
- JavaScript (6)
- Ajax (2)
- XML (3)
- IBM Websphere Portal (1)
- IBM Lotus Quickr (1)
- CMS (2)
- ERP (0)
- CRM (0)
- тцДтъІуйЉуФЎТъХТъёт╝ђтЈЉ (1)
- жЮбУ»ЋТГдтЎе (2)
- HTML 5 (2)
- dTree && webFxloadTree (2)
- JVM (7)
- SQL Server (3)
- Tomcat && Apache && Jboss && Weblogic-СИГжЌ┤С╗Х (4)
- FreeMarker (2)
- MongoDB (7)
- OpenSourceт╝ђТ║љ (24)
- Cloud (0)
- FFmpeg (3)
- Thrift (1)
- SpringSide (1)
- Design Pattern (1)
- solr&&ES (2)
- git&svn (1)
- тцДТЋ░ТЇ« (8)
- С║║тиЦТЎ║УЃй (0)
- Hadoop (3)
- Spark (0)
- Sqoop (1)
- Flume (1)
- Hive (3)
- HDFS (4)
- ES (0)
- Redis (1)
- Kafka (3)
- MR (0)
- Тю║тЎетГдС╣а (0)
- Ти▒т║дтГдС╣а (0)
- Impala (2)
- HBase (2)
- Spring Boot (1)
- Spring Cloud (0)
- тцДТЋ░ТЇ«ТъХТъё (6)
- ТъХТъёТђЮТЃ│уљєУ«║ (6)
- ТіђТю»у«Ауљє (4)
- ТЋ░ТЇ«у╗ЊТъёСИју«ЌТ│Ћ (4)
уцЙтї║уЅѕтЮЌ
- ТѕЉуџёУхёУ«» ( 0)
- ТѕЉуџёУ«║тЮЏ ( 0)
- ТѕЉуџёжЌ«уГћ ( 0)
тГўТАБтѕєу▒╗
- 2023-09 ( 2)
- 2023-06 ( 4)
- 2022-04 ( 4)
- ТЏ┤тцџтГўТАБ...
ТюђТќ░У»ёУ«║
-
huijz№╝џ
...
Spring Data JPAуаћуЕХ-Сй┐ућеSpring Data JPA у«ђтїќJPA т╝ђтЈЉ(ZZ) -
ућеТѕитљЇСИЇтГўтюе№╝џ
[img][/img][*]т╝Ћуће[u][/u][i][/i][ ...
MongoDB ТеАу│іТЪЦУ»буџёСИЅуДЇт«ъуј░Тќ╣т╝Ј-morphiaт«ъуј░ -
junsheng100№╝џ
У»иу╗ЎСИфт«їТЋ┤уџёСЙІтГљтљД№╝ЂтїЁТІгjarТќЄС╗ХуГЅ
javaУ░ЃућеffmpegУјитЈќУДєжбЉТќЄС╗ХС┐АТЂ»тЈѓТЋ░С╗БуаЂ -
mj№╝џ
У░бУ░б№╝Ђ№╝Ђ
SQL ServerжЄїжЮбтдѓСйЋт»╝тЄ║тїЁтљФ(insert into)ТЋ░ТЇ«уџёSQLУёџТюг (УйгУййZZ)
СИђсђЂуЏИтЁ│Тдѓт┐х
тЪ║ТюгтЏъТћХу«ЌТ│Ћ
-
т╝ЋућеУ«АТЋ░№╝ѕReference Counting№╝Ѕ
Т»ћУЙЃтЈцУђЂуџётЏъТћХу«ЌТ│ЋсђѓтјЪуљєТў»ТГцт»╣У▒АТюЅСИђСИфт╝Ћуће№╝їтЇ│тбътіаСИђСИфУ«АТЋ░№╝їтѕажЎцСИђСИфт╝ЋућетѕЎтЄЈт░ЉСИђСИфУ«АТЋ░сђѓтъЃтюЙтЏъТћХТЌХ№╝їтЈфућеТћХжЏєУ«АТЋ░СИ║0уџёт»╣У▒АсђѓТГцу«ЌТ│ЋТюђУЄ┤тЉйуџёТў»ТЌаТ│ЋтцёуљєтЙфуј»т╝ЋућеуџёжЌ«жбўсђѓ -
ТаЄУ«░-ТИЁжЎц№╝ѕMark-Sweep№╝Ѕ
ТГцу«ЌТ│ЋТЅДУАїтѕєСИцжўХТ«хсђѓуггСИђжўХТ«хС╗јт╝ЋућеТа╣Уіѓуѓ╣т╝ђтДІТаЄУ«░ТЅђТюЅУбФт╝Ћућеуџёт»╣У▒А№╝їуггС║їжўХТ«хжЂЇтјєТЋ┤СИфтає№╝їТііТюфТаЄУ«░уџёт»╣У▒АТИЁжЎцсђѓТГцу«ЌТ│ЋжюђУдЂТџѓтЂюТЋ┤СИфт║ћуће№╝їтљїТЌХ№╝їС╝џС║ДућЪтєЁтГўубјуЅЄсђѓ -
тцЇтѕХ№╝ѕCopying№╝Ѕ
ТГцу«ЌТ│ЋТіітєЁтГўуЕ║жЌ┤тѕњСИ║СИцСИфуЏИуГЅуџётї║тЪЪ№╝їТ»ЈТгАтЈфСй┐ућетЁХСИГСИђСИфтї║тЪЪсђѓтъЃтюЙтЏъТћХТЌХ№╝їжЂЇтјєтйЊтЅЇСй┐ућетї║тЪЪ№╝їТііТГБтюеСй┐ућеСИГуџёт»╣У▒АтцЇтѕХтѕ░тЈдтцќСИђСИфтї║тЪЪСИГсђѓТгАу«ЌТ│ЋТ»ЈТгАтЈфтцёуљєТГБтюеСй┐ућеСИГуџёт»╣У▒А№╝їтЏаТГцтцЇтѕХТѕљТюгТ»ћУЙЃт░Ј№╝їтљїТЌХтцЇтѕХУ┐Єтј╗С╗ЦтљјУ┐ўУЃйУ┐ЏУАїуЏИт║ћуџётєЁтГўТЋ┤уљє№╝їСИЇУ┐ЄтЄ║уј░РђюубјуЅЄРђЮжЌ«жбўсђѓтйЊуёХ№╝їТГцу«ЌТ│Ћуџёу╝║уѓ╣С╣ЪТў»тЙѕТўјТўЙуџё№╝їт░▒Тў»жюђУдЂСИцтђЇтєЁтГўуЕ║жЌ┤сђѓ -
ТаЄУ«░-ТЋ┤уљє№╝ѕMark-Compact№╝Ѕ
ТГцу«ЌТ│Ћу╗ЊтљѕС║єРђюТаЄУ«░-ТИЁжЎцРђЮтњїРђютцЇтѕХРђЮСИцСИфу«ЌТ│ЋуџёС╝ўуѓ╣сђѓС╣ЪТў»тѕєСИцжўХТ«х№╝їуггСИђжўХТ«хС╗јТа╣Уіѓуѓ╣т╝ђтДІТаЄУ«░ТЅђТюЅУбФт╝Ћућет»╣У▒А№╝їуггС║їжўХТ«хжЂЇтјєТЋ┤СИфтає№╝їТііТИЁжЎцТюфТаЄУ«░т»╣У▒Ат╣ХСИћТіітГўТ┤╗т»╣У▒АРђютјІу╝ЕРђЮтѕ░таєуџётЁХСИГСИђтЮЌ№╝їТїЅжА║т║ЈТјњТћЙсђѓТГцу«ЌТ│ЋжЂ┐тЁЇС║єРђюТаЄУ«░-ТИЁжЎцРђЮуџёубјуЅЄжЌ«жбў№╝їтљїТЌХС╣ЪжЂ┐тЁЇС║єРђютцЇтѕХРђЮу«ЌТ│ЋуџёуЕ║жЌ┤жЌ«жбўсђѓ -
тбъжЄЈТћХжЏє№╝ѕIncremental Collecting№╝Ѕ
т«ъТќйтъЃтюЙтЏъТћХу«ЌТ│Ћ№╝їтЇ│№╝џтюет║ћућеУ┐ЏУАїуџётљїТЌХУ┐ЏУАїтъЃтюЙтЏъТћХсђѓСИЇуЪЦжЂЊС╗ђС╣ѕтјЪтЏаJDK5.0СИГуџёТћХжЏєтЎеТ▓АТюЅСй┐ућеУ┐ЎуДЇу«ЌТ│Ћуџёсђѓ -
тѕєС╗Б№╝ѕGenerational Collecting№╝Ѕ
тЪ║С║јт»╣т»╣У▒АућЪтЉйтЉеТюЪтѕєТъљтљјтЙЌтЄ║уџётъЃтюЙтЏъТћХу«ЌТ│ЋсђѓТііт»╣У▒АтѕєСИ║т╣┤жЮњС╗БсђЂт╣┤УђЂС╗БсђЂТїЂС╣ЁС╗Б№╝їт»╣СИЇтљїућЪтЉйтЉеТюЪуџёт»╣У▒АСй┐ућеСИЇтљїуџёу«ЌТ│Ћ№╝ѕСИіУ┐░Тќ╣т╝ЈСИГуџёСИђСИф№╝ЅУ┐ЏУАїтЏъТћХсђѓуј░тюеуџётъЃтюЙтЏъТћХтЎе№╝ѕС╗јJ2SE1.2т╝ђтДІ№╝ЅжЃйТў»Сй┐ућеТГцу«ЌТ│Ћуџёсђѓ
тѕєС╗БтъЃтюЙтЏъТћХУ»дУ┐░
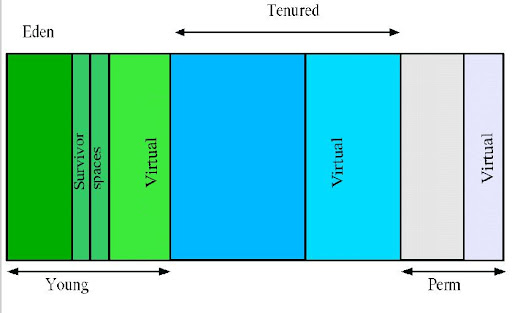
тдѓСИітЏЙТЅђуц║№╝їСИ║JavaтаєСИГуџётљёС╗БтѕєтИЃсђѓ
-
Young№╝ѕт╣┤Уй╗С╗Б№╝Ѕ
т╣┤Уй╗С╗БтѕєСИЅСИфтї║сђѓСИђСИфEdenтї║№╝їСИцСИфSurvivorтї║сђѓтцДжЃетѕєт»╣У▒АтюеEdenтї║СИГућЪТѕљсђѓтйЊEdenтї║Т╗АТЌХ№╝їУ┐ўтГўТ┤╗уџёт»╣У▒Ат░єУбФтцЇтѕХтѕ░Survivorтї║№╝ѕСИцСИфСИГуџёСИђСИф№╝Ѕ№╝їтйЊУ┐ЎСИфSurvivorтї║Т╗АТЌХ№╝їТГцтї║уџётГўТ┤╗т»╣У▒Ат░єУбФтцЇтѕХтѕ░тЈдтцќСИђСИфSurvivorтї║№╝їтйЊУ┐ЎСИфSurvivorтј╗С╣ЪТ╗АС║єуџёТЌХтђЎ№╝їС╗југгСИђСИфSurvivorтї║тцЇтѕХУ┐ЄТЮЦуџёт╣ХСИћТГцТЌХУ┐ўтГўТ┤╗уџёт»╣У▒А№╝їт░єУбФтцЇтѕХРђют╣┤УђЂтї║(Tenured)РђЮсђѓжюђУдЂТ│еТёЈ№╝їSurvivorуџёСИцСИфтї║Тў»т»╣уД░уџё№╝їТ▓АтЁѕтљјтЁ│у│╗№╝їТЅђС╗ЦтљїСИђСИфтї║СИГтЈ»УЃйтљїТЌХтГўтюеС╗јEdenтцЇтѕХУ┐ЄТЮЦ т»╣У▒А№╝їтњїС╗јтЅЇСИђСИфSurvivorтцЇтѕХУ┐ЄТЮЦуџёт»╣У▒А№╝їУђїтцЇтѕХтѕ░т╣┤УђЂтї║уџётЈфТюЅС╗југгСИђСИфSurvivorтј╗У┐ЄТЮЦуџёт»╣У▒АсђѓУђїСИћ№╝їSurvivorтї║Тђ╗ТюЅСИђСИфТў»уЕ║уџёсђѓ -
Tenured№╝ѕт╣┤УђЂС╗Б№╝Ѕ
т╣┤УђЂС╗БтГўТћЙС╗јт╣┤Уй╗С╗БтГўТ┤╗уџёт»╣У▒АсђѓСИђУѕгТЮЦУ»┤т╣┤УђЂС╗БтГўТћЙуџёжЃйТў»ућЪтЉйТюЪУЙЃжЋ┐уџёт»╣У▒Асђѓ -
Perm№╝ѕТїЂС╣ЁС╗Б№╝Ѕ
ућеС║јтГўТћЙжЮЎТђЂТќЄС╗Х№╝їтдѓС╗іJavaу▒╗сђЂТќ╣Т│ЋуГЅсђѓТїЂС╣ЁС╗Бт»╣тъЃтюЙтЏъТћХТ▓АТюЅТўЙУЉЌтй▒тЊЇ№╝їСйєТў»ТюЅС║Џт║ћућетЈ»УЃйтіеТђЂућЪТѕљТѕќУђЁУ░ЃућеСИђС║Џclass№╝їСЙІтдѓHibernateуГЅ№╝їтюеУ┐ЎуДЇТЌХтђЎжюђУдЂУ«Йуй«СИђСИфТ»ћУЙЃтцДуџёТїЂС╣ЁС╗БуЕ║жЌ┤ТЮЦтГўТћЙУ┐ЎС║ЏУ┐љУАїУ┐ЄуеІСИГТќ░тбъуџёу▒╗сђѓТїЂС╣ЁС╗БтцДт░ЈжђџУ┐Є-XX:MaxPermSize=<N>У┐ЏУАїУ«Йуй«сђѓ
GCу▒╗тъІ
GCТюЅСИцуДЇу▒╗тъІ№╝џScavenge GCтњїFull GCсђѓ
- Scavenge GC
СИђУѕгТЃЁтєхСИІ№╝їтйЊТќ░т»╣У▒АућЪТѕљ№╝їт╣ХСИћтюеEdenућ│У»иуЕ║жЌ┤тц▒У┤ЦТЌХ№╝їт░▒тЦйУДдтЈЉScavenge GC№╝їтаєEdenтї║тЪЪУ┐ЏУАїGC№╝їТИЁжЎцжЮътГўТ┤╗т»╣У▒А№╝їт╣ХСИћТііт░џСИћтГўТ┤╗уџёт»╣У▒АуД╗тіетѕ░Survivorтї║сђѓуёХтљјТЋ┤уљєSurvivorуџёСИцСИфтї║сђѓ - Full GC
т»╣ТЋ┤СИфтаєУ┐ЏУАїТЋ┤уљє№╝їтїЁТІгYoungсђЂTenuredтњїPermсђѓFull GCТ»ћScavenge GCУдЂТЁб№╝їтЏаТГцт║ћУ»Цт░йтЈ»УЃйтЄЈт░ЉFull GCсђѓТюЅтдѓСИІтјЪтЏатЈ»УЃйт»╝УЄ┤Full GC№╝џ- TenuredУбФтєЎТ╗А
- PermтЪЪУбФтєЎТ╗А
- System.gc()УбФТўЙуц║У░Ѓуће
- СИіСИђТгАGCС╣ІтљјHeapуџётљётЪЪтѕєжЁЇуГќуЋЦтіеТђЂтЈўтїќ
тѕєС╗БтъЃтюЙтЏъТћХУ┐ЄуеІТ╝ћуц║



С║їсђЂтъЃтюЙтЏъТћХтЎе
уЏ«тЅЇуџёТћХжЏєтЎеСИ╗УдЂТюЅСИЅуДЇ№╝џСИ▓УАїТћХжЏєтЎесђЂт╣ХУАїТћХжЏєтЎесђЂт╣ХтЈЉТћХжЏєтЎесђѓ
-
СИ▓УАїТћХжЏєтЎе

Сй┐ућетЇЋу║┐уеІтцёуљєТЅђТюЅтъЃтюЙтЏъТћХтиЦСйю№╝їтЏаСИ║ТЌажюђтцџу║┐уеІС║цС║њ№╝їТЅђС╗ЦТЋѕујЄТ»ћУЙЃжФўсђѓСйєТў»№╝їС╣ЪТЌаТ│ЋСй┐ућетцџтцёуљєтЎеуџёС╝ўті┐№╝їТЅђС╗ЦТГцТћХжЏєтЎежђѓтљѕтЇЋтцёуљєтЎеТю║тЎесђѓтйЊуёХ№╝їТГцТћХжЏєтЎеС╣ЪтЈ»С╗Цућетюет░ЈТЋ░ТЇ«жЄЈ№╝ѕ100MтидтЈ│№╝ЅТЃЁтєхСИІуџётцџтцёуљєтЎеТю║тЎеСИісђѓтЈ»С╗ЦСй┐уће-XX:+UseSerialGCТЅЊт╝ђсђѓ
-
т╣ХУАїТћХжЏєтЎе

- т»╣т╣┤Уй╗С╗БУ┐ЏУАїт╣ХУАїтъЃтюЙтЏъТћХ№╝їтЏаТГцтЈ»С╗ЦтЄЈт░ЉтъЃтюЙтЏъТћХТЌХжЌ┤сђѓСИђУѕгтюетцџу║┐уеІтцџтцёуљєтЎеТю║тЎеСИіСй┐ућесђѓСй┐уће-XX:+UseParallelGC.ТЅЊт╝ђсђѓт╣ХУАїТћХжЏєтЎетюеJ2SE5.0уггтЁГ6ТЏ┤Тќ░СИіт╝ЋтЁЦ№╝їтюеJava SE6.0СИГУ┐ЏУАїС║єтбът╝║--тЈ»С╗Цтаєт╣┤УђЂС╗БУ┐ЏУАїт╣ХУАїТћХжЏєсђѓтдѓТъют╣┤УђЂС╗БСИЇСй┐ућет╣ХтЈЉТћХжЏєуџёУ»Ю№╝їТў»Сй┐ућетЇЋу║┐уеІУ┐ЏУАїтъЃтюЙтЏъТћХ№╝їтЏаТГцС╝џтѕХу║дТЅЕт▒ЋУЃйтіЏсђѓСй┐уће-XX:+UseParallelOldGCТЅЊт╝ђсђѓ
- Сй┐уће-XX:ParallelGCThreads=<N>У«Йуй«т╣ХУАїтъЃтюЙтЏъТћХуџёу║┐уеІТЋ░сђѓТГцтђ╝тЈ»С╗ЦУ«Йуй«СИјТю║тЎетцёуљєтЎеТЋ░жЄЈуЏИуГЅсђѓ
- ТГцТћХжЏєтЎетЈ»С╗ЦУ┐ЏУАїтдѓСИІжЁЇуй«№╝џ
- ТюђтцДтъЃтюЙтЏъТћХТџѓтЂю:ТїЄт«џтъЃтюЙтЏъТћХТЌХуџёТюђжЋ┐ТџѓтЂюТЌХжЌ┤№╝їжђџУ┐Є-XX:MaxGCPauseMillis=<N>ТїЄт«џсђѓ<N>СИ║Т»ФуДњ.тдѓТъюТїЄт«џС║єТГцтђ╝уџёУ»Ю№╝їтаєтцДт░ЈтњїтъЃтюЙтЏъТћХуЏИтЁ│тЈѓТЋ░С╝џУ┐ЏУАїУ░ЃТЋ┤С╗ЦУЙЙтѕ░ТїЄт«џтђ╝сђѓУ«Йт«џТГцтђ╝тЈ»УЃйС╝џтЄЈт░Љт║ћућеуџётљътљљжЄЈсђѓ
- тљътљљжЄЈ:тљътљљжЄЈСИ║тъЃтюЙтЏъТћХТЌХжЌ┤СИјжЮътъЃтюЙтЏъТћХТЌХжЌ┤уџёТ»ћтђ╝№╝їжђџУ┐Є-XX:GCTimeRatio=<N>ТЮЦУ«Йт«џ№╝їтЁгт╝ЈСИ║1/№╝ѕ1+N№╝ЅсђѓСЙІтдѓ№╝ї-XX:GCTimeRatio=19ТЌХ№╝їУАеуц║5%уџёТЌХжЌ┤ућеС║јтъЃтюЙтЏъТћХсђѓж╗ўУ«цТЃЁтєхСИ║99№╝їтЇ│1%уџёТЌХжЌ┤ућеС║јтъЃтюЙтЏъТћХсђѓ
-
т╣ХтЈЉТћХжЏєтЎе
тЈ»С╗ЦС┐ЮУ»ЂтцДжЃетѕєтиЦСйюжЃйт╣ХтЈЉУ┐ЏУАї№╝ѕт║ћућеСИЇтЂюТГб№╝Ѕ№╝їтъЃтюЙтЏъТћХтЈфТџѓтЂютЙѕт░ЉуџёТЌХжЌ┤№╝їТГцТћХжЏєтЎежђѓтљѕт»╣тЊЇт║ћТЌХжЌ┤УдЂТ▒ѓТ»ћУЙЃжФўуџёСИГсђЂтцДУДёТеАт║ћућесђѓСй┐уће-XX:+UseConcMarkSweepGCТЅЊт╝ђсђѓ
- т╣ХтЈЉТћХжЏєтЎеСИ╗УдЂтЄЈт░Љт╣┤УђЂС╗БуџёТџѓтЂюТЌХжЌ┤№╝їС╗ќтюет║ћућеСИЇтЂюТГбуџёТЃЁтєхСИІСй┐ућеуІгуФІуџётъЃтюЙтЏъТћХу║┐уеІ№╝їУиЪУИфтЈ»УЙЙт»╣У▒АсђѓтюеТ»ЈСИфт╣┤УђЂС╗БтъЃтюЙтЏъТћХтЉеТюЪСИГ№╝їтюеТћХжЏєтѕЮТюЪт╣ХтЈЉТћХжЏєтЎеС╝џт»╣ТЋ┤СИфт║ћућеУ┐ЏУАїу«ђуЪГуџёТџѓтЂю№╝їтюеТћХжЏєСИГУ┐ўС╝џтєЇТџѓтЂюСИђТгАсђѓуггС║їТгАТџѓтЂюС╝џТ»ћуггСИђТгАуеЇжЋ┐№╝їтюеТГцУ┐ЄуеІСИГтцџСИфу║┐уеІтљїТЌХУ┐ЏУАїтъЃтюЙтЏъТћХтиЦСйюсђѓ
- т╣ХтЈЉТћХжЏєтЎеСй┐ућетцёуљєтЎеТЇбТЮЦуЪГТџѓуџётЂюжА┐ТЌХжЌ┤сђѓтюеСИђСИфNСИфтцёуљєтЎеуџёу│╗у╗ЪСИі№╝їт╣ХтЈЉТћХжЏєжЃетѕєСй┐ућеK/NСИфтЈ»ућетцёуљєтЎеУ┐ЏУАїтЏъТћХ№╝їСИђУѕгТЃЁтєхСИІ1<=K<=N/4сђѓ
- тюетЈфТюЅСИђСИфтцёуљєтЎеуџёСИ╗Тю║СИіСй┐ућет╣ХтЈЉТћХжЏєтЎе№╝їУ«Йуй«СИ║incremental modeТеАт╝ЈС╣ЪтЈ»УјитЙЌУЙЃуЪГуџётЂюжА┐ТЌХжЌ┤сђѓ
- Тх«тіетъЃтюЙ№╝џућ▒С║јтюет║ћућеУ┐љУАїуџётљїТЌХУ┐ЏУАїтъЃтюЙтЏъТћХ№╝їТЅђС╗ЦТюЅС║ЏтъЃтюЙтЈ»УЃйтюетъЃтюЙтЏъТћХУ┐ЏУАїт«їТѕљТЌХС║ДућЪ№╝їУ┐ЎТаит░▒жђаТѕљС║єРђюFloating GarbageРђЮ№╝їУ┐ЎС║ЏтъЃтюЙжюђУдЂтюеСИІТгАтъЃтюЙтЏъТћХтЉеТюЪТЌХТЅЇУЃйтЏъТћХТјЅсђѓТЅђС╗Ц№╝їт╣ХтЈЉТћХжЏєтЎеСИђУѕгжюђУдЂ20%уџёжбёуЋЎуЕ║жЌ┤ућеС║јУ┐ЎС║ЏТх«тіетъЃтюЙсђѓ
- Concurrent Mode Failure№╝џт╣ХтЈЉТћХжЏєтЎетюет║ћућеУ┐љУАїТЌХУ┐ЏУАїТћХжЏє№╝їТЅђС╗ЦжюђУдЂС┐ЮУ»ЂтаєтюетъЃтюЙтЏъТћХуџёУ┐ЎТ«хТЌХжЌ┤ТюЅУХ│тцЪуџёуЕ║жЌ┤СЙЏуеІт║ЈСй┐уће№╝їтљдтѕЎ№╝їтъЃтюЙтЏъТћХУ┐ўТюфт«їТѕљ№╝їтаєуЕ║жЌ┤тЁѕТ╗АС║єсђѓУ┐ЎуДЇТЃЁтєхСИІт░єС╝џтЈЉућЪРђют╣ХтЈЉТеАт╝Јтц▒У┤ЦРђЮ№╝їТГцТЌХТЋ┤СИфт║ћућет░єС╝џТџѓтЂю№╝їУ┐ЏУАїтъЃтюЙтЏъТћХсђѓ
- тљ»тіет╣ХтЈЉТћХжЏєтЎе№╝џтЏаСИ║т╣ХтЈЉТћХжЏєтюет║ћућеУ┐љУАїТЌХУ┐ЏУАїТћХжЏє№╝їТЅђС╗Цт┐ЁжА╗С┐ЮУ»ЂТћХжЏєт«їТѕљС╣ІтЅЇТюЅУХ│тцЪуџётєЁтГўуЕ║жЌ┤СЙЏуеІт║ЈСй┐уће№╝їтљдтѕЎС╝џтЄ║уј░РђюConcurrent Mode FailureРђЮсђѓжђџУ┐ЄУ«Йуй«-XX:CMSInitiatingOccupancyFraction=<N>ТїЄт«џУ┐ўТюЅтцџт░ЉтЅЕСйЎтаєТЌХт╝ђтДІТЅДУАїт╣ХтЈЉТћХжЏє
-
т░Ју╗Њ
-
СИ▓УАїтцёуљєтЎе№╝џ
┬а--жђѓућеТЃЁтєх№╝џТЋ░ТЇ«жЄЈТ»ћУЙЃт░Ј№╝ѕ100MтидтЈ│№╝Ѕ№╝ЏтЇЋтцёуљєтЎеСИІт╣ХСИћт»╣тЊЇт║ћТЌХжЌ┤ТЌаУдЂТ▒ѓуџёт║ћућесђѓ
┬а--у╝║уѓ╣№╝џтЈфУЃйућеС║јт░ЈтъІт║ћуће -
т╣ХУАїтцёуљєтЎе№╝џ
┬а--жђѓућеТЃЁтєх№╝џРђют»╣тљътљљжЄЈТюЅжФўУдЂТ▒ѓРђЮ№╝їтцџCPUсђЂт»╣т║ћућетЊЇт║ћТЌХжЌ┤ТЌаУдЂТ▒ѓуџёСИГсђЂтцДтъІт║ћућесђѓСИЙСЙІ№╝џтљјтЈ░тцёуљєсђЂуДЉтГдУ«Ау«Ќсђѓ
┬а--у╝║уѓ╣№╝џт║ћућетЊЇт║ћТЌХжЌ┤тЈ»УЃйУЙЃжЋ┐ -
т╣ХтЈЉтцёуљєтЎе№╝џ
┬а--жђѓућеТЃЁтєх№╝џРђют»╣тЊЇт║ћТЌХжЌ┤ТюЅжФўУдЂТ▒ѓРђЮ№╝їтцџCPUсђЂт»╣т║ћућетЊЇт║ћТЌХжЌ┤ТюЅУЙЃжФўУдЂТ▒ѓуџёСИГсђЂтцДтъІт║ћућесђѓСИЙСЙІ№╝џWebТюЇтіАтЎе/т║ћућеТюЇтіАтЎесђЂућхС┐АС║цТЇбсђЂжЏєТѕљт╝ђтЈЉуј»тбЃсђѓ
-
СИ▓УАїтцёуљєтЎе№╝џ
СИЅсђЂтИИУДЂжЁЇуй«СИЙСЙІ
-
таєтцДт░ЈУ«Йуй«
JVM СИГТюђтцДтаєтцДт░ЈТюЅСИЅТќ╣жЮбжЎљтѕХ№╝џуЏИтЁ│ТЊЇСйюу│╗у╗ЪуџёТЋ░ТЇ«ТеАтъІ№╝ѕ32-btУ┐ўТў»64-bit№╝ЅжЎљтѕХ№╝Џу│╗у╗ЪуџётЈ»ућеУЎџТІЪтєЁтГўжЎљтѕХ№╝Џу│╗у╗ЪуџётЈ»ућеуЅЕуљєтєЁтГўжЎљтѕХсђѓ32СйЇу│╗у╗ЪСИІ№╝їСИђУѕгжЎљтѕХтюе1.5G~2G№╝Џ64СИ║ТЊЇСйюу│╗у╗Ът»╣тєЁтГўТЌажЎљтѕХсђѓТѕЉтюеWindows Server 2003 у│╗у╗Ъ№╝ї3.5GуЅЕуљєтєЁтГў№╝їJDK5.0СИІТхІУ»Ћ№╝їТюђтцДтЈ»У«Йуй«СИ║1478mсђѓтЁИтъІУ«Йуй«№╝џ-
java -Xmx3550m -Xms3550m -Xmn2g-Xss128k-Xmx3550m№╝џУ«Йуй«JVMТюђтцДтЈ»ућетєЁтГўСИ║3550Mсђѓ-Xms3550m№╝џУ«Йуй«JVMС┐ЃСй┐тєЁтГўСИ║3550mсђѓТГцтђ╝тЈ»С╗ЦУ«Йуй«СИј-XmxуЏИтљї№╝їС╗ЦжЂ┐тЁЇТ»ЈТгАтъЃтюЙтЏъТћХт«їТѕљтљјJVMжЄЇТќ░тѕєжЁЇтєЁтГўсђѓ-Xmn2g№╝џУ«Йуй«т╣┤Уй╗С╗БтцДт░ЈСИ║2GсђѓТЋ┤СИфтаєтцДт░Ј=т╣┤Уй╗С╗БтцДт░Ј + т╣┤УђЂС╗БтцДт░Ј + ТїЂС╣ЁС╗БтцДт░ЈсђѓТїЂС╣ЁС╗БСИђУѕгтЏ║т«џтцДт░ЈСИ║64m№╝їТЅђС╗ЦтбътцДт╣┤Уй╗С╗Бтљј№╝їт░єС╝џтЄЈт░Јт╣┤УђЂС╗БтцДт░ЈсђѓТГцтђ╝т»╣у│╗у╗ЪТђДУЃйтй▒тЊЇУЙЃтцД№╝їSunт«ўТќ╣ТјеУЇљжЁЇуй«СИ║ТЋ┤СИфтаєуџё3/8сђѓ-Xss128k№╝џУ«Йуй«Т»ЈСИфу║┐уеІуџётаєТаѕтцДт░ЈсђѓJDK5.0С╗ЦтљјТ»ЈСИфу║┐уеІтаєТаѕтцДт░ЈСИ║1M№╝їС╗ЦтЅЇТ»ЈСИфу║┐уеІтаєТаѕтцДт░ЈСИ║256KсђѓТЏ┤тЁит║ћућеуџёу║┐уеІТЅђжюђтєЁтГўтцДт░ЈУ┐ЏУАїУ░ЃТЋ┤сђѓтюеуЏИтљїуЅЕуљєтєЁтГўСИІ№╝їтЄЈт░ЈУ┐ЎСИфтђ╝УЃйућЪТѕљТЏ┤тцџуџёу║┐уеІсђѓСйєТў»ТЊЇСйюу│╗у╗Ът»╣СИђСИфУ┐ЏуеІтєЁуџёу║┐уеІТЋ░У┐ўТў»ТюЅжЎљтѕХуџё№╝їСИЇУЃйТЌажЎљућЪТѕљ№╝їу╗Јжфїтђ╝тюе3000~5000тидтЈ│сђѓ -
java -Xmx3550m -Xms3550m-Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxPermSize=16m -XX:MaxTenuringThreshold=0-XX:NewRatio=4:У«Йуй«т╣┤Уй╗С╗Б№╝ѕтїЁТІгEdenтњїСИцСИфSurvivorтї║№╝ЅСИјт╣┤УђЂС╗БуџёТ»ћтђ╝№╝ѕжЎцтј╗ТїЂС╣ЁС╗Б№╝ЅсђѓУ«Йуй«СИ║4№╝їтѕЎт╣┤Уй╗С╗БСИјт╣┤УђЂС╗БТЅђтЇаТ»ћтђ╝СИ║1№╝џ4№╝їт╣┤Уй╗С╗БтЇаТЋ┤СИфтаєТаѕуџё1/5-XX:SurvivorRatio=4№╝џУ«Йуй«т╣┤Уй╗С╗БСИГEdenтї║СИјSurvivorтї║уџётцДт░ЈТ»ћтђ╝сђѓУ«Йуй«СИ║4№╝їтѕЎСИцСИфSurvivorтї║СИјСИђСИфEdenтї║уџёТ»ћтђ╝СИ║2:4№╝їСИђСИфSurvivorтї║тЇаТЋ┤СИфт╣┤Уй╗С╗Буџё1/6-XX:MaxPermSize=16m:У«Йуй«ТїЂС╣ЁС╗БтцДт░ЈСИ║16mсђѓ-XX:MaxTenuringThreshold=0№╝џУ«Йуй«тъЃтюЙТюђтцДт╣┤жЙёсђѓтдѓТъюУ«Йуй«СИ║0уџёУ»Ю№╝їтѕЎт╣┤Уй╗С╗Бт»╣У▒АСИЇу╗ЈУ┐ЄSurvivorтї║№╝їуЏ┤ТјЦУ┐ЏтЁЦт╣┤УђЂС╗Бсђѓт»╣С║јт╣┤УђЂС╗БТ»ћУЙЃтцџуџёт║ћуће№╝їтЈ»С╗ЦТЈљжФўТЋѕујЄсђѓтдѓТъют░єТГцтђ╝У«Йуй«СИ║СИђСИфУЙЃтцДтђ╝№╝їтѕЎт╣┤Уй╗С╗Бт»╣У▒АС╝џтюеSurvivorтї║У┐ЏУАїтцџТгАтцЇтѕХ№╝їУ┐ЎТаитЈ»С╗Цтбътіат»╣У▒АтєЇт╣┤Уй╗С╗БуџётГўТ┤╗ТЌХжЌ┤№╝їтбътіатюет╣┤Уй╗С╗БтЇ│УбФтЏъТћХуџёТдѓУ«║сђѓ
-
-
тЏъТћХтЎежђЅТІЕ
JVMу╗ЎС║єСИЅуДЇжђЅТІЕ№╝џСИ▓УАїТћХжЏєтЎесђЂт╣ХУАїТћХжЏєтЎесђЂт╣ХтЈЉТћХжЏєтЎе№╝їСйєТў»СИ▓УАїТћХжЏєтЎетЈфжђѓућеС║јт░ЈТЋ░ТЇ«жЄЈуџёТЃЁтєх№╝їТЅђС╗ЦУ┐ЎжЄїуџёжђЅТІЕСИ╗УдЂжњѕт»╣т╣ХУАїТћХжЏєтЎетњїт╣ХтЈЉТћХжЏєтЎесђѓж╗ўУ«цТЃЁтєхСИІ№╝їJDK5.0С╗ЦтЅЇжЃйТў»Сй┐ућеСИ▓УАїТћХжЏєтЎе№╝їтдѓТъюТЃ│Сй┐ућетЁХС╗ќТћХжЏєтЎежюђУдЂтюетљ»тіеТЌХтіатЁЦуЏИт║ћтЈѓТЋ░сђѓJDK5.0С╗Цтљј№╝їJVMС╝џТа╣ТЇ«тйЊтЅЇу│╗у╗ЪжЁЇуй«У┐ЏУАїтѕцТќГсђѓ-
тљътљљжЄЈС╝ўтЁѕуџёт╣ХУАїТћХжЏєтЎе
тдѓСИіТќЄТЅђУ┐░№╝їт╣ХУАїТћХжЏєтЎеСИ╗УдЂС╗Цтѕ░УЙЙСИђт«џуџётљътљљжЄЈСИ║уЏ«ТаЄ№╝їжђѓућеС║јуДЉтГдТіђТю»тњїтљјтЈ░тцёуљєуГЅсђѓ
тЁИтъІжЁЇуй«№╝џ-
java -Xmx3800m -Xms3800m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads=20-XX:+UseParallelGC№╝џжђЅТІЕтъЃтюЙТћХжЏєтЎеСИ║т╣ХУАїТћХжЏєтЎесђѓТГцжЁЇуй«С╗Ёт»╣т╣┤Уй╗С╗БТюЅТЋѕсђѓтЇ│СИіУ┐░жЁЇуй«СИІ№╝їт╣┤Уй╗С╗БСй┐ућет╣ХтЈЉТћХжЏє№╝їУђїт╣┤УђЂС╗БС╗ЇТЌДСй┐ућеСИ▓УАїТћХжЏєсђѓ-XX:ParallelGCThreads=20№╝џжЁЇуй«т╣ХУАїТћХжЏєтЎеуџёу║┐уеІТЋ░№╝їтЇ│№╝џтљїТЌХтцџт░ЉСИфу║┐уеІСИђУхиУ┐ЏУАїтъЃтюЙтЏъТћХсђѓТГцтђ╝ТюђтЦйжЁЇуй«СИјтцёуљєтЎеТЋ░уЏ«уЏИуГЅсђѓ -
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads=20 -XX:+UseParallelOldGC-XX:+UseParallelOldGC№╝џжЁЇуй«т╣┤УђЂС╗БтъЃтюЙТћХжЏєТќ╣т╝ЈСИ║т╣ХУАїТћХжЏєсђѓJDK6.0Тћ»ТїЂт»╣т╣┤УђЂС╗Бт╣ХУАїТћХжЏєсђѓ -
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC┬а -XX:MaxGCPauseMillis=100-XX:MaxGCPauseMillis=100:У«Йуй«Т»ЈТгАт╣┤Уй╗С╗БтъЃтюЙтЏъТћХуџёТюђжЋ┐ТЌХжЌ┤№╝їтдѓТъюТЌаТ│ЋТ╗АУХ│ТГцТЌХжЌ┤№╝їJVMС╝џУЄфтіеУ░ЃТЋ┤т╣┤Уй╗С╗БтцДт░Ј№╝їС╗ЦТ╗АУХ│ТГцтђ╝сђѓ -
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC┬а -XX:MaxGCPauseMillis=100-XX:+UseAdaptiveSizePolicy
-XX:+UseAdaptiveSizePolicy№╝џУ«Йуй«ТГцжђЅжА╣тљј№╝їт╣ХУАїТћХжЏєтЎеС╝џУЄфтіежђЅТІЕт╣┤Уй╗С╗Бтї║тцДт░ЈтњїуЏИт║ћуџёSurvivorтї║Т»ћСЙІ№╝їС╗ЦУЙЙтѕ░уЏ«ТаЄу│╗у╗ЪУДёт«џуџёТюђСйјуЏИт║ћТЌХжЌ┤ТѕќУђЁТћХжЏєжбЉујЄуГЅ№╝їТГцтђ╝т╗║У««Сй┐ућет╣ХУАїТћХжЏєтЎеТЌХ№╝їСИђуЏ┤ТЅЊт╝ђсђѓ
-
-
тЊЇт║ћТЌХжЌ┤С╝ўтЁѕуџёт╣ХтЈЉТћХжЏєтЎе
тдѓСИіТќЄТЅђУ┐░№╝їт╣ХтЈЉТћХжЏєтЎеСИ╗УдЂТў»С┐ЮУ»Ђу│╗у╗ЪуџётЊЇт║ћТЌХжЌ┤№╝їтЄЈт░ЉтъЃтюЙТћХжЏєТЌХуџётЂюжА┐ТЌХжЌ┤сђѓжђѓућеС║јт║ћућеТюЇтіАтЎесђЂућхС┐АжбєтЪЪуГЅсђѓ
тЁИтъІжЁЇуй«№╝џ-
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:ParallelGCThreads=20 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC-XX:+UseConcMarkSweepGC№╝џУ«Йуй«т╣┤УђЂС╗БСИ║т╣ХтЈЉТћХжЏєсђѓТхІУ»ЋСИГжЁЇуй«У┐ЎСИфС╗Цтљј№╝ї-XX:NewRatio=4уџёжЁЇуй«тц▒ТЋѕС║є№╝їтјЪтЏаСИЇТўјсђѓТЅђС╗Ц№╝їТГцТЌХт╣┤Уй╗С╗БтцДт░ЈТюђтЦйуће-XmnУ«Йуй«сђѓ-XX:+UseParNewGC:У«Йуй«т╣┤Уй╗С╗БСИ║т╣ХУАїТћХжЏєсђѓтЈ»СИјCMSТћХжЏєтљїТЌХСй┐ућесђѓJDK5.0С╗ЦСИі№╝їJVMС╝џТа╣ТЇ«у│╗у╗ЪжЁЇуй«УЄфУАїУ«Йуй«№╝їТЅђС╗ЦТЌажюђтєЇУ«Йуй«ТГцтђ╝сђѓ -
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseConcMarkSweepGC-XX:CMSFullGCsBeforeCompaction=5-XX:+UseCMSCompactAtFullCollection-XX:CMSFullGCsBeforeCompaction№╝џућ▒С║јт╣ХтЈЉТћХжЏєтЎеСИЇт»╣тєЁтГўуЕ║жЌ┤У┐ЏУАїтјІу╝ЕсђЂТЋ┤уљє№╝їТЅђС╗ЦУ┐љУАїСИђТ«хТЌХжЌ┤С╗ЦтљјС╝џС║ДућЪРђюубјуЅЄРђЮ№╝їСй┐тЙЌУ┐љУАїТЋѕујЄжЎЇСйјсђѓТГцтђ╝У«Йуй«У┐љУАїтцџт░ЉТгАGCС╗Цтљјт»╣тєЁтГўуЕ║жЌ┤У┐ЏУАїтјІу╝ЕсђЂТЋ┤уљєсђѓ-XX:+UseCMSCompactAtFullCollection№╝џТЅЊт╝ђт»╣т╣┤УђЂС╗БуџётјІу╝ЕсђѓтЈ»УЃйС╝џтй▒тЊЇТђДУЃй№╝їСйєТў»тЈ»С╗ЦТХѕжЎцубјуЅЄ
-
-
тљътљљжЄЈС╝ўтЁѕуџёт╣ХУАїТћХжЏєтЎе
-
УЙЁтіЕС┐АТЂ»
JVMТЈљСЙЏС║єтцДжЄЈтЉйС╗цУАїтЈѓТЋ░№╝їТЅЊтЇ░С┐АТЂ»№╝їСЙЏУ░ЃУ»ЋСй┐ућесђѓСИ╗УдЂТюЅС╗ЦСИІСИђС║Џ№╝џ-
-XX:+PrintGC
УЙЊтЄ║тйбт╝Ј№╝џ[GC 118250K->113543K(130112K), 0.0094143 secs]┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а [Full GC 121376K->10414K(130112K), 0.0650971 secs]
-
-XX:+PrintGCDetails
УЙЊтЄ║тйбт╝Ј№╝џ[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs]┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а [GC [DefNew: 8614K->8614K(9088K), 0.0000665 secs][Tenured: 112761K->10414K(121024K), 0.0433488 secs] 121376K->10414K(130112K), 0.0436268 secs]
-
-XX:+PrintGCTimeStamps -XX:+PrintGC№╝џPrintGCTimeStampsтЈ»СИјСИіжЮбСИцСИфТиитљѕСй┐уће
УЙЊтЄ║тйбт╝Ј№╝џ11.851: [GC 98328K->93620K(130112K), 0.0082960 secs]
-
-XX:+PrintGCApplicationConcurrentTime:ТЅЊтЇ░Т»ЈТгАтъЃтюЙтЏъТћХтЅЇ№╝їуеІт║ЈТюфСИГТќГуџёТЅДУАїТЌХжЌ┤сђѓтЈ»СИјСИіжЮбТиитљѕСй┐уће
УЙЊтЄ║тйбт╝Ј№╝џApplication time: 0.5291524 seconds
-
-XX:+PrintGCApplicationStoppedTime№╝џТЅЊтЇ░тъЃтюЙтЏъТћХТюЪжЌ┤уеІт║ЈТџѓтЂюуџёТЌХжЌ┤сђѓтЈ»СИјСИіжЮбТиитљѕСй┐уће
УЙЊтЄ║тйбт╝Ј№╝џTotal time for which application threads were stopped: 0.0468229 seconds
-
-XX:PrintHeapAtGC:ТЅЊтЇ░GCтЅЇтљјуџёУ»ду╗єтаєТаѕС┐АТЂ»
УЙЊтЄ║тйбт╝Ј№╝џ
34.702: [GC {Heap before gc invocations=7:
┬аdef new generation┬а┬а total 55296K, used 52568K [0x1ebd0000, 0x227d0000, 0x227d0000)
eden space 49152K,┬а 99% used [0x1ebd0000, 0x21bce430, 0x21bd0000)
from space 6144K,┬а 55% used [0x221d0000, 0x22527e10, 0x227d0000)
┬а to┬а┬а space 6144K,┬а┬а 0% used [0x21bd0000, 0x21bd0000, 0x221d0000)
┬аtenured generation┬а┬а total 69632K, used 2696K [0x227d0000, 0x26bd0000, 0x26bd0000)
the space 69632K,┬а┬а 3% used [0x227d0000, 0x22a720f8, 0x22a72200, 0x26bd0000)
┬аcompacting perm gen┬а total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000)
┬а┬а the space 8192K,┬а 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000)
┬а┬а┬а ro space 8192K,┬а 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000)
┬а┬а┬а rw space 12288K,┬а 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000)
34.735: [DefNew: 52568K->3433K(55296K), 0.0072126 secs] 55264K->6615K(124928K)Heap after gc invocations=8:
┬аdef new generation┬а┬а total 55296K, used 3433K [0x1ebd0000, 0x227d0000, 0x227d0000)
eden space 49152K,┬а┬а 0% used [0x1ebd0000, 0x1ebd0000, 0x21bd0000)
┬а from space 6144K,┬а 55% used [0x21bd0000, 0x21f2a5e8, 0x221d0000)
┬а to┬а┬а space 6144K,┬а┬а 0% used [0x221d0000, 0x221d0000, 0x227d0000)
┬аtenured generation┬а┬а total 69632K, used 3182K [0x227d0000, 0x26bd0000, 0x26bd0000)
the space 69632K,┬а┬а 4% used [0x227d0000, 0x22aeb958, 0x22aeba00, 0x26bd0000)
┬аcompacting perm gen┬а total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000)
┬а┬а the space 8192K,┬а 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000)
┬а┬а┬а ro space 8192K,┬а 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000)
┬а┬а┬а rw space 12288K,┬а 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000)
}
, 0.0757599 secs]
- -Xloggc:filename:СИјСИіжЮбтЄаСИфжЁЇтљѕСй┐уће№╝їТііуЏИтЁ│ТЌЦт┐ЌС┐АТЂ»У«░тйЋтѕ░ТќЄС╗ХС╗ЦСЙ┐тѕєТъљсђѓ
-
-XX:+PrintGC
-
тИИУДЂжЁЇуй«Т▒ЄТђ╗
- таєУ«Йуй«
- -Xms:тѕЮтДІтаєтцДт░Ј
- -Xmx:ТюђтцДтаєтцДт░Ј
- -XX:NewSize=n:У«Йуй«т╣┤Уй╗С╗БтцДт░Ј
- -XX:NewRatio=n:У«Йуй«т╣┤Уй╗С╗Бтњїт╣┤УђЂС╗БуџёТ»ћтђ╝сђѓтдѓ:СИ║3№╝їУАеуц║т╣┤Уй╗С╗БСИјт╣┤УђЂС╗БТ»ћтђ╝СИ║1№╝џ3№╝їт╣┤Уй╗С╗БтЇаТЋ┤СИфт╣┤Уй╗С╗Бт╣┤УђЂС╗Бтњїуџё1/4
- -XX:SurvivorRatio=n:т╣┤Уй╗С╗БСИГEdenтї║СИјСИцСИфSurvivorтї║уџёТ»ћтђ╝сђѓТ│еТёЈSurvivorтї║ТюЅСИцСИфсђѓтдѓ№╝џ3№╝їУАеуц║Eden№╝џSurvivor=3№╝џ2№╝їСИђСИфSurvivorтї║тЇаТЋ┤СИфт╣┤Уй╗С╗Буџё1/5
- -XX:MaxPermSize=n:У«Йуй«ТїЂС╣ЁС╗БтцДт░Ј
- ТћХжЏєтЎеУ«Йуй«
- -XX:+UseSerialGC:У«Йуй«СИ▓УАїТћХжЏєтЎе
- -XX:+UseParallelGC:У«Йуй«т╣ХУАїТћХжЏєтЎе
- -XX:+UseParalledlOldGC:У«Йуй«т╣ХУАїт╣┤УђЂС╗БТћХжЏєтЎе
- -XX:+UseConcMarkSweepGC:У«Йуй«т╣ХтЈЉТћХжЏєтЎе
- тъЃтюЙтЏъТћХу╗ЪУ«АС┐АТЂ»
- -XX:+PrintGC
- -XX:+PrintGCDetails
- -XX:+PrintGCTimeStamps
- -Xloggc:filename
- т╣ХУАїТћХжЏєтЎеУ«Йуй«
- -XX:ParallelGCThreads=n:У«Йуй«т╣ХУАїТћХжЏєтЎеТћХжЏєТЌХСй┐ућеуџёCPUТЋ░сђѓт╣ХУАїТћХжЏєу║┐уеІТЋ░сђѓ
- -XX:MaxGCPauseMillis=n:У«Йуй«т╣ХУАїТћХжЏєТюђтцДТџѓтЂюТЌХжЌ┤
- -XX:GCTimeRatio=n:У«Йуй«тъЃтюЙтЏъТћХТЌХжЌ┤тЇауеІт║ЈУ┐љУАїТЌХжЌ┤уџёуЎЙтѕєТ»ћсђѓтЁгт╝ЈСИ║1/(1+n)
- т╣ХтЈЉТћХжЏєтЎеУ«Йуй«
- -XX:+CMSIncrementalMode:У«Йуй«СИ║тбъжЄЈТеАт╝ЈсђѓжђѓућеС║јтЇЋCPUТЃЁтєхсђѓ
- -XX:ParallelGCThreads=n:У«Йуй«т╣ХтЈЉТћХжЏєтЎет╣┤Уй╗С╗БТћХжЏєТќ╣т╝ЈСИ║т╣ХУАїТћХжЏєТЌХ№╝їСй┐ућеуџёCPUТЋ░сђѓт╣ХУАїТћХжЏєу║┐уеІТЋ░сђѓ
- таєУ«Йуй«
тЏЏсђЂУ░ЃС╝ўТђ╗у╗Њ
-
т╣┤Уй╗С╗БтцДт░ЈжђЅТІЕ
- тЊЇт║ћТЌХжЌ┤С╝ўтЁѕуџёт║ћуће№╝џт░йтЈ»УЃйУ«ЙтцД№╝їуЏ┤тѕ░ТјЦУ┐Љу│╗у╗ЪуџёТюђСйјтЊЇт║ћТЌХжЌ┤жЎљтѕХ№╝ѕТа╣ТЇ«т«ъжЎЁТЃЁтєхжђЅТІЕ№╝ЅсђѓтюеТГцуДЇТЃЁтєхСИІ№╝їт╣┤Уй╗С╗БТћХжЏєтЈЉућЪуџёжбЉујЄС╣ЪТў»Тюђт░ЈуџёсђѓтљїТЌХ№╝їтЄЈт░Љтѕ░УЙЙт╣┤УђЂС╗Буџёт»╣У▒Асђѓ
- тљътљљжЄЈС╝ўтЁѕуџёт║ћуће№╝џт░йтЈ»УЃйуџёУ«Йуй«тцД№╝їтЈ»УЃйтѕ░УЙЙGbitуџёуеІт║дсђѓтЏаСИ║т»╣тЊЇт║ћТЌХжЌ┤Т▓АТюЅУдЂТ▒ѓ№╝їтъЃтюЙТћХжЏєтЈ»С╗Цт╣ХУАїУ┐ЏУАї№╝їСИђУѕгжђѓтљѕ8CPUС╗ЦСИіуџёт║ћућесђѓ
-
т╣┤УђЂС╗БтцДт░ЈжђЅТІЕ
-
тЊЇт║ћТЌХжЌ┤С╝ўтЁѕуџёт║ћуће№╝џт╣┤УђЂС╗БСй┐ућет╣ХтЈЉТћХжЏєтЎе№╝їТЅђС╗ЦтЁХтцДт░ЈжюђУдЂт░Јт┐ЃУ«Йуй«№╝їСИђУѕгУдЂУђЃУЎЉт╣ХтЈЉС╝џУ»ЮујЄтњїС╝џУ»ЮТїЂу╗ГТЌХжЌ┤уГЅСИђС║ЏтЈѓТЋ░сђѓтдѓТъютаєУ«Йуй«т░ЈС║є№╝їтЈ»С╗ЦС╝џжђаТѕљтєЁтГўубјуЅЄсђЂжФўтЏъТћХжбЉујЄС╗ЦтЈіт║ћућеТџѓтЂюУђїСй┐ућеС╝ау╗ЪуџёТаЄУ«░ТИЁжЎцТќ╣т╝Ј№╝ЏтдѓТъютаєтцДС║є№╝їтѕЎжюђУдЂУЙЃжЋ┐уџёТћХжЏєТЌХжЌ┤сђѓТюђС╝ўтїќуџёТќ╣ТАѕ№╝їСИђУѕгжюђУдЂтЈѓУђЃС╗ЦСИІТЋ░ТЇ«УјитЙЌ№╝џ
- т╣ХтЈЉтъЃтюЙТћХжЏєС┐АТЂ»
- ТїЂС╣ЁС╗Бт╣ХтЈЉТћХжЏєТгАТЋ░
- С╝ау╗ЪGCС┐АТЂ»
- Уі▒тюет╣┤Уй╗С╗Бтњїт╣┤УђЂС╗БтЏъТћХСИіуџёТЌХжЌ┤Т»ћСЙІ
- тљътљљжЄЈС╝ўтЁѕуџёт║ћуће№╝џСИђУѕгтљътљљжЄЈС╝ўтЁѕуџёт║ћућежЃйТюЅСИђСИфтЙѕтцДуџёт╣┤Уй╗С╗БтњїСИђСИфУЙЃт░Јуџёт╣┤УђЂС╗БсђѓтјЪтЏаТў»№╝їУ┐ЎТаитЈ»С╗Цт░йтЈ»УЃйтЏъТћХТјЅтцДжЃетѕєуЪГТюЪт»╣У▒А№╝їтЄЈт░ЉСИГТюЪуџёт»╣У▒А№╝їУђїт╣┤УђЂС╗Бт░йтГўТћЙжЋ┐ТюЪтГўТ┤╗т»╣У▒Асђѓ
-
тЊЇт║ћТЌХжЌ┤С╝ўтЁѕуџёт║ћуће№╝џт╣┤УђЂС╗БСй┐ућет╣ХтЈЉТћХжЏєтЎе№╝їТЅђС╗ЦтЁХтцДт░ЈжюђУдЂт░Јт┐ЃУ«Йуй«№╝їСИђУѕгУдЂУђЃУЎЉт╣ХтЈЉС╝џУ»ЮујЄтњїС╝џУ»ЮТїЂу╗ГТЌХжЌ┤уГЅСИђС║ЏтЈѓТЋ░сђѓтдѓТъютаєУ«Йуй«т░ЈС║є№╝їтЈ»С╗ЦС╝џжђаТѕљтєЁтГўубјуЅЄсђЂжФўтЏъТћХжбЉујЄС╗ЦтЈіт║ћућеТџѓтЂюУђїСй┐ућеС╝ау╗ЪуџёТаЄУ«░ТИЁжЎцТќ╣т╝Ј№╝ЏтдѓТъютаєтцДС║є№╝їтѕЎжюђУдЂУЙЃжЋ┐уџёТћХжЏєТЌХжЌ┤сђѓТюђС╝ўтїќуџёТќ╣ТАѕ№╝їСИђУѕгжюђУдЂтЈѓУђЃС╗ЦСИІТЋ░ТЇ«УјитЙЌ№╝џ
-
УЙЃт░Јтаєт╝ЋУхиуџёубјуЅЄжЌ«жбў
тЏаСИ║т╣┤УђЂС╗Буџёт╣ХтЈЉТћХжЏєтЎеСй┐ућеТаЄУ«░сђЂТИЁжЎцу«ЌТ│Ћ№╝їТЅђС╗ЦСИЇС╝џт»╣таєУ┐ЏУАїтјІу╝ЕсђѓтйЊТћХжЏєтЎетЏъТћХТЌХ№╝їС╗ќС╝џТііуЏИжѓ╗уџёуЕ║жЌ┤У┐ЏУАїтљѕт╣Х№╝їУ┐ЎТаитЈ»С╗ЦтѕєжЁЇу╗ЎУЙЃтцДуџёт»╣У▒АсђѓСйєТў»№╝їтйЊтаєуЕ║жЌ┤УЙЃт░ЈТЌХ№╝їУ┐љУАїСИђТ«хТЌХжЌ┤С╗Цтљј№╝їт░▒С╝џтЄ║уј░РђюубјуЅЄРђЮ№╝їтдѓТъют╣ХтЈЉТћХжЏєтЎеТЅЙСИЇтѕ░УХ│тцЪуџёуЕ║жЌ┤№╝їжѓБС╣ѕт╣ХтЈЉТћХжЏєтЎет░єС╝џтЂюТГб№╝їуёХтљјСй┐ућеС╝ау╗ЪуџёТаЄУ«░сђЂТИЁжЎцТќ╣т╝ЈУ┐ЏУАїтЏъТћХсђѓтдѓТъютЄ║уј░РђюубјуЅЄРђЮ№╝їтЈ»УЃйжюђУдЂУ┐ЏУАїтдѓСИІжЁЇуй«№╝џ- -XX:+UseCMSCompactAtFullCollection№╝џСй┐ућет╣ХтЈЉТћХжЏєтЎеТЌХ№╝їт╝ђтљ»т»╣т╣┤УђЂС╗БуџётјІу╝Есђѓ
- -XX:CMSFullGCsBeforeCompaction=0№╝џСИіжЮбжЁЇуй«т╝ђтљ»уџёТЃЁтєхСИІ№╝їУ┐ЎжЄїУ«Йуй«тцџт░ЉТгАFull GCтљј№╝їт»╣т╣┤УђЂС╗БУ┐ЏУАїтјІу╝Е
С║ћсђЂтЈѓУђЃТќЄуї«
- Java уљєУ«║СИјт«ъУих: тъЃтюЙТћХжЏєу«ђтЈ▓
- Java SE 6 HotSpot[tm] Virtual Machine Garbage Collection Tuning
- Improving Java Application Performance and Scalability by Reducing Garbage Collection Times and Sizing Memory Using JDK 1.4.1
- Hotspot memory management whitepaper
- Java Tuning White Paper
- Diagnosing a Garbage Collection problem
- Java HotSpot VM Options
- A Collection of JVM Options
- Frequently Asked Questions about Garbage Collection in the HotspotTM JavaTM Virtual Machine
тјЪТќЄтю░тЮђ№╝џhttp://pengjiaheng.spaces.live.com/blog/cns!2DAA368B386E6AEA!770.entry
тѕєС║Фтѕ░№╝џ


- 2011-01-22 21:11
- ТхЈУДѕ 801
- У»ёУ«║(0)
- тѕєу▒╗:у╝ќуеІУ»ГУеђ
- ТЪЦуюІТЏ┤тцџ
тЈЉУАеУ»ёУ«║

-
СИђТгАJavaтъЃтюЙТћХжЏєУ░ЃС╝ўт«ъТѕў
2011-01-22 21:38 27651.┬аУхёТќЎ JDK5.0тъЃтюЙТћХжЏєС╝ўтїќС╣І--Don't ... -
JavaТђДУЃйС╝ўтїќуџёуГќуЋЦтњїтИИУДЂТќ╣Т│Ћ№╝ѕС║ї№╝Ѕ
2011-01-22 21:33 12471№╝ЅJVMт»╣таєуЕ║жЌ┤уџёу«Ауљє ... -
JavaТђДУЃйС╝ўтїќуџёуГќуЋЦтњїтИИУДЂТќ╣Т│Ћ(СИђ)
2011-01-22 21:31 1131ТдѓУ┐░жџЈуЮђJavaуџёт╣┐Т│Џт║ћуће№╝їУХіТЮЦУХітцџуџётЁ│жћ«С╝ЂСИџу│╗у╗ЪС╣ЪСй┐ућеJ ... -
jvmТђДУЃйС╝ўтїќтЪ╣У«Гућеуџёppt
2011-01-22 21:27 1340jvmТђДУЃйС╝ўтїќ: ┬а┬а┬а таєТаѕТеАтъІ ┬а┬а┬а таєТаѕућЪтЉйтЉеТюЪ ┬а┬а ... -
JVM&&жА╣уЏ«ТђДУЃйУ░ЃС╝ў
2011-01-22 21:14 1072┬а┬а┬аТхІУ»ЋТхІуџёУ┐ЎС╣ѕуЃѓ№╝їУ ... -
С╗Іу╗Їт╣ХУ░ЃС╝ўJVM GC(Garbage Collection)
2011-01-22 21:01 1152У░ЃТЋ┤JVM GC(Garbage Collection)№╝їтЈ»С╗Ц ...
уЏИтЁ│ТјеУЇљ
1.1 JVMУ░ЃС╝ўТђ╗у╗Њ-т║Ј3 1.2 JVMУ░ЃС╝ўТђ╗у╗Њ№╝ѕСИђ№╝Ѕ-- СИђС║ЏТдѓт┐х 4 1.3 JVMУ░ЃС╝ўТђ╗у╗Њ№╝ѕС║ї№╝Ѕ-СИђС║ЏТдѓт┐х 7 1.4 JVMУ░ЃС╝ўТђ╗у╗Њ№╝ѕСИЅ№╝Ѕ-тЪ║ТюгтъЃтюЙтЏъТћХу«ЌТ│Ћ 9 1.5 JVMУ░ЃС╝ўТђ╗у╗Њ№╝ѕтЏЏ№╝Ѕ-тъЃтюЙтЏъТћХжЮбСИ┤уџёжЌ«жбў 12 1.6 JVMУ░ЃС╝ўТђ╗у╗Њ№╝ѕС║ћ№╝Ѕ-тѕєС╗Б...
### JVMУ░ЃС╝ўТђ╗у╗Њ #### СИђсђЂТдѓУ┐░ JavaУЎџТІЪТю║(JVM)Тў»JavaуеІт║ЈуџёТаИт┐ЃУ┐љУАїуј»тбЃ№╝їт»╣С║јТЈљжФўJavaт║ћућеуеІт║ЈТђДУЃйУЄ│тЁ│жЄЇУдЂсђѓJVMУ░ЃС╝ўТў»ТїЄжђџУ┐ЄУ░ЃТЋ┤JVMуџёжЁЇуй«тЈѓТЋ░ТЮЦС╝ўтїќуеІт║ЈТђДУЃйуџёУ┐ЄуеІсђѓТюгТќЄт░єтЏ┤у╗ЋJVMУ░ЃС╝ўт▒Ћт╝ђУ«еУ«║№╝їжЄЇуѓ╣тѕєТъљТЋ░ТЇ«...
JVMУ░ЃС╝ўТђ╗у╗Њ -Xms -Xmx -Xmn -Xss JVM У░ЃС╝ўТў» Java virtual machine уџёТђДУЃйС╝ўтїќ№╝їжђџУ┐ЄУ░ЃТЋ┤ JVM уџётЈѓТЋ░ТЮЦТЈљжФў Java т║ћућеуеІт║ЈуџёТђДУЃйсђѓтЁХСИГ№╝ї-XmsсђЂ-XmxсђЂ-XmnсђЂ-Xss Тў»тЏЏСИфжЄЇУдЂуџётЈѓТЋ░№╝їтѕєтѕФТјДтѕХ JVM уџётѕЮтДІтаєтцДт░ЈсђЂ...
### JVMУ░ЃС╝ўСИјтъЃтюЙтЏъТћХТю║тѕХУ»дУДБ #### СИђсђЂт╝ЋУеђ жџЈуЮђУй»С╗Ху│╗у╗ЪуџётцЇТЮѓт║дСИЇТќГТЈљжФў№╝їТђДУЃйС╝ўтїќТѕљСИ║С║єУй»С╗Хт╝ђтЈЉСИГуџёСИђСИфжЄЇУдЂуј»Уіѓсђѓт»╣С║јJavaт║ћућеуеІт║ЈТЮЦУ»┤№╝їJavaУЎџТІЪТю║(JVM)уџёТђДУЃйуЏ┤ТјЦтй▒тЊЇуЮђт║ћућеуџёТЋ┤СйЊУАеуј░сђѓтъЃтюЙтЏъТћХ(GC)...
ТюгТќЄТАБТђ╗у╗ЊС║єJVMУ░ЃС╝ўуџётЪ║уАђуЪЦУ»єтњїСИђС║ЏТаИт┐ЃТдѓт┐х№╝їТЌетюетИ«тіЕт╝ђтЈЉУђЁТЏ┤тЦйтю░ТјїТЈАJavaуеІт║ЈуџёТђДУЃйС╝ўтїќсђѓ ждќтЁѕ№╝їТќЄТАБТЈљтѕ░С║єJavaСИГуџёТЋ░ТЇ«у▒╗тъІтѕєСИ║тЪ║Тюгу▒╗тъІтњїт╝Ћућеу▒╗тъІсђѓтЪ║Тюгу▒╗тъІуџётЈўжЄЈтГўтѓеуџёТў»тјЪтДІТЋ░ТЇ«тђ╝№╝їУђїт╝Ћућеу▒╗тъІуџётЈўжЄЈ...
JVMУ░ЃС╝ўТђ╗у╗Њ JVM№╝ѕJava Virtual Machine№╝ЅТў» Java У»ГУеђуџёУ┐љУАїуј»тбЃ№╝їУ┤ЪУ┤Бт░є Java тГЌУіѓуаЂУйгТЇбСИ║Тю║тЎеуаЂт╣ХТЅДУАїсђѓуёХУђї№╝їжџЈуЮђ Java т║ћућеуеІт║ЈуџётцЇТЮѓт║дтњїУДёТеАуџётбътіа№╝їJVM уџёТђДУЃйтЈўтЙЌУХіТЮЦУХіжЄЇУдЂсђѓтЏаТГц№╝їJVM У░ЃС╝ўТў»жЮътИИт┐ЁУдЂуџё...
тюеТи▒тЁЦУ«еУ«║JVM№╝ѕJavaУЎџТІЪТю║№╝ЅУ░ЃС╝ўС╣ІтЅЇ№╝їТѕЉС╗гТюЅт┐ЁУдЂтЁѕС║єУДБСИђСИІУЎџТІЪТю║уџётЪ║ТюгТдѓт┐хтњїтаєТаѕ...жђџУ┐ЄСИіУ┐░уџётѕєТъљтњїТђ╗у╗Њ№╝їТѕЉС╗гтЈ»С╗ЦтЙЌтЄ║№╝їJVMУ░ЃС╝ўТў»СИђСИфТХЅтЈітцџТќ╣жЮбуЪЦУ»єуџётцЇТЮѓУ┐ЄуеІ№╝їжюђУдЂт╝ђтЈЉУђЁтЁитцЄТЅјт«ъуџёуљєУ«║тЪ║уАђтњїСИ░т»їуџёт«ъУиху╗Јжфїсђѓ
### JVMУ░ЃС╝ўТђ╗у╗Њ№╝џXmsсђЂXmxсђЂXmnсђЂXss тюеJavaУЎџТІЪТю║№╝ѕJVM№╝ЅуџёУ┐љУАїУ┐ЄуеІСИГ№╝їтљѕуљєуџётЈѓТЋ░жЁЇуй«т»╣С║јТЈљжФўуеІт║ЈТђДУЃйУЄ│тЁ│жЄЇУдЂсђѓТюгТќЄт░єт»╣JVMУ░ЃС╝ўСИГуџётЄаСИфтЁ│жћ«тЈѓТЋ░У┐ЏУАїТи▒тЁЦУДБТъљ№╝їтїЁТІг-XmsсђЂ-XmxсђЂ-Xmnтњї-XssуГЅ№╝їтИ«тіЕт╝ђтЈЉУђЁТЏ┤тЦй...
"JVMУ░ЃС╝ўТђ╗у╗Њ" JVMУ░ЃС╝ўТў»СИђуДЇжЮътИИжЄЇУдЂуџёТіђТю»№╝їУЃйтцЪтИ«тіЕТѕЉС╗гТЈљжФўJavaт║ћућеуеІт║ЈуџёТђДУЃйтњїуе│т«џТђДсђѓтюеУ┐Ўу»ЄТќЄуФаСИГ№╝їТѕЉС╗гт░єТђ╗у╗ЊJVMУ░ЃС╝ўуџёСИђС║ЏтЪ║ТюгТдѓт┐хтњїу«ЌТ│Ћсђѓ СИђсђЂуЏИтЁ│Тдѓт┐х JVMУ░ЃС╝ўуџётЪ║ТюгТдѓт┐хтїЁТІгт╝ЋућеУ«АТЋ░сђЂТаЄУ«░-ТИЁжЎцсђЂ...
### JVMУ░ЃС╝ўУ»дУДБ #### СИђсђЂJVMУ░ЃС╝ўТдѓУ┐░ тюеуј░С╗БУй»С╗Хт╝ђтЈЉСИГ№╝їJavaУЎџТІЪТю║№╝ѕJVM№╝ЅСйюСИ║Javaт║ћућеуеІт║ЈуџёУ┐љУАїуј»тбЃ№╝їт»╣С║јТЈљжФўт║ћућеуеІт║ЈуџёТђДУЃйУЄ│тЁ│жЄЇУдЂсђѓJVMУ░ЃС╝ўТў»ТїЄжђџУ┐ЄУ░ЃТЋ┤JVMуџётљёуДЇтЈѓТЋ░ТЮЦС╝ўтїќJavaт║ћућеуеІт║ЈуџёУ┐љУАїТЋѕујЄ№╝їтЄЈт░Љ...
JVMУ░ЃС╝ўТђ╗у╗Њ --ТћХжЏєТЪљСйЇжФўС║║уџётЇџт«б.
### жЕгтБФтЁхJVMУ░ЃС╝ўугћУ«░уЪЦУ»єуѓ╣Тб│уљє ...С╗ЦСИіТў»тЪ║С║јсђіжЕгтБФтЁхJVMУ░ЃС╝ўугћУ«░сђІТќЄТАБтєЁт«╣ТЋ┤уљєуџётЁ│жћ«уЪЦУ»єуѓ╣Тђ╗у╗ЊсђѓжђџУ┐ЄуљєУДБтњїТјїТЈАУ┐ЎС║ЏТдѓт┐хСИјТіђтиД№╝їтЈ»С╗ЦтИ«тіЕт╝ђтЈЉУђЁТЏ┤жФўТЋѕтю░у«АуљєтњїС╝ўтїќJavaт║ћућеуеІт║ЈуџётєЁтГўСй┐ућеТЃЁтєхсђѓ
сђљJVMУ░ЃС╝ўТђ╗у╗ЊсђЉ JavaУЎџТІЪТю║№╝ѕJVM№╝ЅТў»JavaуеІт║ЈУ┐љУАїуџётЪ║уАђ№╝їт«ЃУ┤ЪУ┤БУДБТъљтГЌУіѓуаЂт╣Хт░єтЁХУйгТЇбСИ║Тю║тЎетЈ»ТЅДУАїуџёТїЄС╗цсђѓJVMУ░ЃС╝ўТў»С╝ўтїќJavaт║ћућеуеІт║ЈТђДУЃйуџётЁ│жћ«ТГЦжфц№╝їт░цтЁХт»╣С║јтцДтъІтѕєтИЃт╝Ју│╗у╗ЪУђїУеђ№╝їУЅ»тЦйуџёJVMжЁЇуй«тЈ»С╗ЦТўЙУЉЌТЈљжФўу│╗у╗Ъ...
JVMТђДУЃйУ░ЃС╝ўТђ╗у╗Њ JVMТђДУЃйУ░ЃС╝ўТў»Javaт╝ђтЈЉСИГжЮътИИжЄЇУдЂуџёСИђТќ╣жЮб№╝їуЏ┤ТјЦтй▒тЊЇтѕ░у│╗у╗ЪуџёТђДУЃйтњїуе│т«џТђДсђѓТюгТќЄт░єТђ╗у╗ЊJVMТђДУЃйУ░ЃС╝ўуџёу╗ЈжфїтњїТіђтиД№╝їт╣ХТЈљСЙЏСИђС║Џт«ъућеуџёжЁЇуй«тЈѓТЋ░тњїт╗║У««сђѓ СИђсђЂтаєтцДт░ЈУ«Йуй« таєтцДт░ЈТў»JVMТђДУЃйУ░ЃС╝ўСИГуџёСИђСИф...
### Java-JVMУ░ЃС╝ўТђ╗у╗Њ #### СИђсђЂт╝ЋУеђ тюеуј░С╗БУй»С╗Хт╝ђтЈЉСИГ№╝їJava СйюСИ║СИђуДЇт╣┐Т│ЏСй┐ућеуџёу╝ќуеІУ»ГУеђ№╝їтЁХт║ћућеуеІт║ЈуџёТђДУЃйС╝ўтїќУЄ│тЁ│жЄЇУдЂсђѓУђї JVM№╝ѕJava Virtual Machine№╝ЅСйюСИ║ Java уеІт║ЈУ┐љУАїуџётЪ║уАђуј»тбЃ№╝їт»╣тЁХУ┐ЏУАїтљѕуљєуџёУ░ЃС╝ўтЈ»С╗Ц...
JVM У░ЃС╝ўТђ╗у╗Њ JVM У░ЃС╝ўТў»СИђСИфтцЇТЮѓуџёУ┐ЄуеІ№╝їжюђУдЂС╗јтцџСИфУДњт║дУ┐ЏУАїУђЃУЎЉсђѓСИІжЮбТў»т»╣ JVM У░ЃС╝ўуџёСИђС║ЏТђ╗у╗Њу╗Јжфїсђѓ JVM У░ЃС╝ўтЅЇуџётЄєтцЄ тюеУ┐ЏУАї JVM У░ЃС╝ўС╣ІтЅЇ№╝їжюђУдЂС║єУДБ JVM уџётЪ║ТюгТдѓт┐хтњїтјЪуљє№╝їтїЁТІг JVM уџёТъХТъёсђЂтъЃтюЙтЏъТћХТю║тѕХсђЂ...
сђљJVMУ░ЃС╝ўТђ╗у╗Њ№╝џУ░ЃС╝ўТќ╣Т│ЋсђЉ JavaУЎџТІЪТю║№╝ѕJVM№╝ЅУ░ЃС╝ўТў»СИђжА╣тЁ│жћ«уџёС╗╗тіА№╝їТЌетюеС╝ўтїќт║ћућеуеІт║ЈуџёТђДУЃй№╝їтЄЈт░ЉтєЁтГўТ│ёТ╝Ј№╝їт╣ХуА«С┐Юу│╗у╗Ъуе│т«џУ┐љУАїсђѓС╗ЦСИІТў»т»╣JVMУ░ЃС╝ўуџёСИђС║ЏТаИт┐ЃТќ╣Т│ЋтњїтиЦтЁиуџёУ»ду╗єУ»┤Тўјсђѓ ### JVMУ░ЃС╝ўтиЦтЁи #### 1. ...
JVMТђДУЃйУ░ЃС╝ўтЁиТюЅт║ћућеуІгуЅ╣ТђД№╝ѕapplication specific№╝Ѕ№╝їт░▒Тў»У»┤№╝їСИЇтљїуџёт║ћућеТЃЁтйбт║ћУ»ЦТюЅСИЇтљїуџёУ░ЃТЋ┤Тќ╣ТАѕ№╝їУ┐Ўт░▒УдЂТ▒ѓСйаждќтЁѕУдЂУДѓт»ЪJVMуџёУ┐љУАїуіХТђЂ№╝їуёХтљјТа╣ТЇ«УДѓт»Ъу╗ЊТъюУ░ЃТЋ┤тЈѓТЋ░сђѓТ▓АТюЅСИђСИфжђџућеуџёУ░ЃС╝ўТќ╣ТАѕтЈ»С╗ЦжђѓућеС║јТЅђТюЅуџё...