ж‘ҳиҮӘпјҡ
http://www.blogjava.net/zhenandaci/archive/2009/03/01/257237.html
и®©жҲ‘еҶҚдёҖж¬ЎжҜ”иҫғе®Ңж•ҙзҡ„йҮҚеӨҚдёҖдёӢжҲ‘们иҰҒи§ЈеҶізҡ„й—®йўҳпјҡжҲ‘们жңүеұһдәҺдёӨдёӘзұ»еҲ«зҡ„ж ·жң¬зӮ№пјҲ并дёҚйҷҗе®ҡиҝҷдәӣзӮ№еңЁдәҢз»ҙз©әй—ҙдёӯпјүиӢҘе№ІпјҢеҰӮеӣҫпјҢ
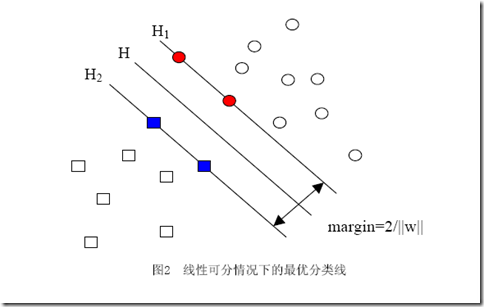
еңҶеҪўзҡ„ж ·жң¬зӮ№е®ҡдёәжӯЈж ·жң¬пјҲиҝһеёҰзқҖпјҢжҲ‘们еҸҜд»ҘжҠҠжӯЈж ·жң¬жүҖеұһзҡ„зұ»еҸ«еҒҡжӯЈзұ»пјүпјҢж–№еҪўзҡ„зӮ№е®ҡдёәиҙҹдҫӢгҖӮжҲ‘们жғіжұӮеҫ—иҝҷж ·дёҖдёӘзәҝжҖ§еҮҪж•°пјҲеңЁnз»ҙз©әй—ҙдёӯзҡ„зәҝжҖ§еҮҪж•°пјүпјҡ
g(x)=wx+b
дҪҝеҫ—жүҖжңүеұһдәҺжӯЈзұ»зҡ„зӮ№x+д»Је…Ҙд»ҘеҗҺжңүg(x+)вүҘ1пјҢиҖҢжүҖжңүеұһдәҺиҙҹзұ»зҡ„зӮ№x-д»Је…ҘеҗҺжңүg(x-)вүӨ-1пјҲд№ӢжүҖд»ҘжҖ»и·ҹ1жҜ”иҫғпјҢж— и®әжӯЈдёҖиҝҳжҳҜиҙҹдёҖпјҢйғҪжҳҜеӣ дёәжҲ‘们еӣәе®ҡдәҶй—ҙйҡ”дёә1пјҢжіЁж„Ҹй—ҙйҡ”е’ҢеҮ дҪ•й—ҙйҡ”зҡ„еҢәеҲ«пјүгҖӮд»Је…Ҙg(x)еҗҺзҡ„еҖјеҰӮжһңеңЁ1е’Ң-1д№Ӣй—ҙпјҢжҲ‘们е°ұжӢ’з»қеҲӨж–ӯгҖӮ
жұӮиҝҷж ·зҡ„g(x)зҡ„иҝҮзЁӢе°ұжҳҜжұӮwпјҲдёҖдёӘnз»ҙеҗ‘йҮҸпјүе’ҢbпјҲдёҖдёӘе®һж•°пјүдёӨдёӘеҸӮж•°зҡ„иҝҮзЁӢпјҲдҪҶе®һйҷ…дёҠеҸӘйңҖиҰҒжұӮwпјҢжұӮеҫ—д»ҘеҗҺжүҫжҹҗдәӣж ·жң¬зӮ№д»Је…Ҙе°ұеҸҜд»ҘжұӮеҫ—bпјүгҖӮеӣ жӯӨеңЁжұӮg(x)зҡ„ж—¶еҖҷпјҢwжүҚжҳҜеҸҳйҮҸгҖӮ
дҪ иӮҜе®ҡиғҪзңӢеҮәжқҘпјҢдёҖж—ҰжұӮеҮәдәҶwпјҲд№ҹе°ұжұӮеҮәдәҶbпјүпјҢйӮЈд№Ҳдёӯй—ҙзҡ„зӣҙзәҝHе°ұзҹҘйҒ“дәҶпјҲеӣ дёәе®ғе°ұжҳҜwx+b=0еҳӣпјҢе“Ҳе“ҲпјүпјҢйӮЈд№ҲH1е’ҢH2д№ҹе°ұзҹҘйҒ“дәҶпјҲеӣ дёәдёүиҖ…жҳҜе№іиЎҢзҡ„пјҢиҖҢдё”зӣёйҡ”зҡ„и·қзҰ»иҝҳжҳҜ||w||еҶіе®ҡзҡ„пјүгҖӮйӮЈд№ҲwжҳҜи°ҒеҶіе®ҡзҡ„пјҹжҳҫ然жҳҜдҪ з»ҷзҡ„ж ·жң¬еҶіе®ҡзҡ„пјҢдёҖж—ҰдҪ еңЁз©әй—ҙдёӯз»ҷеҮәдәҶйӮЈдәӣдёӘж ·жң¬зӮ№пјҢдёүжқЎзӣҙзәҝзҡ„дҪҚзҪ®е®һйҷ…дёҠе°ұе”ҜдёҖзЎ®е®ҡдәҶпјҲеӣ дёәжҲ‘们жұӮзҡ„жҳҜжңҖдјҳзҡ„йӮЈдёүжқЎпјҢеҪ“然жҳҜе”ҜдёҖзҡ„пјүпјҢжҲ‘们解дјҳеҢ–й—®йўҳзҡ„иҝҮзЁӢд№ҹеҸӘдёҚиҝҮжҳҜжҠҠиҝҷдёӘзЎ®е®ҡдәҶзҡ„дёңиҘҝз®—еҮәжқҘиҖҢе·ІгҖӮ
ж ·жң¬зЎ®е®ҡдәҶwпјҢз”Ёж•°еӯҰзҡ„иҜӯиЁҖжҸҸиҝ°пјҢе°ұжҳҜwеҸҜд»ҘиЎЁзӨәдёәж ·жң¬зҡ„жҹҗз§Қз»„еҗҲпјҡ
w=Оұ1x1+Оұ2x2+вҖҰ+Оұnxn
ејҸеӯҗдёӯзҡ„ОұiжҳҜдёҖдёӘдёҖдёӘзҡ„ж•°пјҲеңЁдёҘж јзҡ„иҜҒжҳҺиҝҮзЁӢдёӯпјҢиҝҷдәӣОұиў«з§°дёәжӢүж јжң—ж—Ҙд№ҳеӯҗпјүпјҢиҖҢxiжҳҜж ·жң¬зӮ№пјҢеӣ иҖҢжҳҜеҗ‘йҮҸпјҢnе°ұжҳҜжҖ»ж ·жң¬зӮ№зҡ„дёӘж•°гҖӮдёәдәҶж–№дҫҝжҸҸиҝ°пјҢд»ҘдёӢејҖе§ӢдёҘж јеҢәеҲ«ж•°еӯ—дёҺеҗ‘йҮҸзҡ„д№ҳз§Ҝе’Ңеҗ‘йҮҸй—ҙзҡ„д№ҳз§ҜпјҢжҲ‘дјҡз”ЁОұ1x1иЎЁзӨәж•°еӯ—е’Ңеҗ‘йҮҸзҡ„д№ҳз§ҜпјҢиҖҢз”Ё<x1,x2>иЎЁзӨәеҗ‘йҮҸx1,x2зҡ„еҶ…з§ҜпјҲд№ҹеҸ«зӮ№з§ҜпјҢжіЁж„ҸдёҺеҗ‘йҮҸеҸүз§Ҝзҡ„еҢәеҲ«пјүгҖӮеӣ жӯӨg(x)зҡ„иЎЁиҫҫејҸдёҘж јзҡ„еҪўејҸеә”иҜҘжҳҜпјҡ
g(x)=<w,x>+b
дҪҶжҳҜдёҠйқўзҡ„ејҸеӯҗиҝҳдёҚеӨҹеҘҪпјҢдҪ еӣһеӨҙзңӢзңӢеӣҫдёӯжӯЈж ·жң¬е’Ңиҙҹж ·жң¬зҡ„дҪҚзҪ®пјҢжғіеғҸдёҖдёӢпјҢжҲ‘дёҚеҠЁжүҖжңүзӮ№зҡ„дҪҚзҪ®пјҢиҖҢеҸӘжҳҜжҠҠе…¶дёӯдёҖдёӘжӯЈж ·жң¬зӮ№е®ҡдёәиҙҹж ·жң¬зӮ№пјҲд№ҹе°ұжҳҜжҠҠдёҖдёӘзӮ№зҡ„еҪўзҠ¶д»ҺеңҶеҪўеҸҳдёәж–№еҪўпјүпјҢз»“жһңжҖҺд№Ҳж ·пјҹдёүжқЎзӣҙзәҝйғҪеҝ…须移еҠЁпјҲеӣ дёәеҜ№иҝҷдёүжқЎзӣҙзәҝзҡ„иҰҒжұӮжҳҜеҝ…йЎ»жҠҠж–№еҪўе’ҢеңҶеҪўзҡ„зӮ№жӯЈзЎ®еҲҶејҖпјүпјҒиҝҷиҜҙжҳҺwдёҚд»…и·ҹж ·жң¬зӮ№зҡ„дҪҚзҪ®жңүе…іпјҢиҝҳи·ҹж ·жң¬зҡ„зұ»еҲ«жңүе…іпјҲд№ҹе°ұжҳҜе’Ңж ·жң¬зҡ„вҖңж ҮзӯҫвҖқжңүе…іпјүгҖӮеӣ жӯӨз”ЁдёӢйқўиҝҷдёӘејҸеӯҗиЎЁзӨәжүҚз®—е®Ңж•ҙпјҡ
w=Оұ1y1x1+Оұ2y2x2+вҖҰ+Оұnynxn пјҲејҸ1пјү
е…¶дёӯзҡ„yiе°ұжҳҜ第iдёӘж ·жң¬зҡ„ж ҮзӯҫпјҢе®ғзӯүдәҺ1жҲ–иҖ…-1гҖӮе…¶е®һд»ҘдёҠејҸеӯҗзҡ„йӮЈдёҖе ҶжӢүж јжң—ж—Ҙд№ҳеӯҗдёӯпјҢеҸӘжңүеҫҲе°‘зҡ„дёҖйғЁеҲҶдёҚзӯүдәҺ0пјҲдёҚзӯүдәҺ0жүҚеҜ№wиө·еҶіе®ҡдҪңз”ЁпјүпјҢиҝҷйғЁеҲҶдёҚзӯүдәҺ0зҡ„жӢүж јжң—ж—Ҙд№ҳеӯҗеҗҺйқўжүҖд№ҳзҡ„ж ·жң¬зӮ№пјҢе…¶е®һйғҪиҗҪеңЁH1е’ҢH2дёҠпјҢд№ҹжӯЈжҳҜиҝҷйғЁеҲҶж ·жң¬пјҲиҖҢдёҚйңҖиҰҒе…ЁйғЁж ·жң¬пјүе”ҜдёҖзҡ„зЎ®е®ҡдәҶеҲҶзұ»еҮҪж•°пјҢеҪ“然пјҢжӣҙдёҘж јзҡ„иҜҙпјҢиҝҷдәӣж ·жң¬зҡ„дёҖйғЁеҲҶе°ұеҸҜд»ҘзЎ®е®ҡпјҢеӣ дёәдҫӢеҰӮзЎ®е®ҡдёҖжқЎзӣҙзәҝпјҢеҸӘйңҖиҰҒдёӨдёӘзӮ№е°ұеҸҜд»ҘпјҢеҚідҫҝжңүдёүдә”дёӘйғҪиҗҪеңЁдёҠйқўпјҢжҲ‘们д№ҹдёҚжҳҜе…ЁйғҪйңҖиҰҒгҖӮиҝҷйғЁеҲҶжҲ‘们зңҹжӯЈйңҖиҰҒзҡ„ж ·жң¬зӮ№пјҢе°ұеҸ«еҒҡж”ҜжҢҒпјҲж’‘пјүеҗ‘йҮҸпјҒпјҲеҗҚеӯ—иҝҳжҢәеҪўиұЎеҗ§пјҢ他们вҖңж’‘вҖқиө·дәҶеҲҶз•Ңзәҝпјү
ејҸеӯҗд№ҹеҸҜд»Ҙз”ЁжұӮе’Ңз¬ҰеҸ·з®ҖеҶҷдёҖдёӢпјҡ
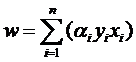
еӣ жӯӨеҺҹжқҘзҡ„g(x)иЎЁиҫҫејҸеҸҜд»ҘеҶҷдёәпјҡ
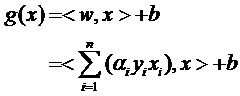
жіЁж„ҸејҸеӯҗдёӯxжүҚжҳҜеҸҳйҮҸпјҢд№ҹе°ұжҳҜдҪ иҰҒеҲҶзұ»е“ӘзҜҮж–ҮжЎЈпјҢе°ұжҠҠиҜҘж–ҮжЎЈзҡ„еҗ‘йҮҸиЎЁзӨәд»Је…ҘеҲ° xзҡ„дҪҚзҪ®пјҢиҖҢжүҖжңүзҡ„xiз»ҹз»ҹйғҪжҳҜе·ІзҹҘзҡ„ж ·жң¬гҖӮиҝҳжіЁж„ҸеҲ°ејҸеӯҗдёӯеҸӘжңүxiе’ҢxжҳҜеҗ‘йҮҸпјҢеӣ жӯӨдёҖйғЁеҲҶеҸҜд»Ҙд»ҺеҶ…з§Ҝз¬ҰеҸ·дёӯжӢҝеҮәжқҘпјҢеҫ—еҲ°g(x)зҡ„ејҸеӯҗдёәпјҡ

еҸ‘зҺ°дәҶд»Җд№ҲпјҹwдёҚи§Ғе•ҰпјҒд»ҺжұӮwеҸҳжҲҗдәҶжұӮОұгҖӮ
дҪҶиӮҜе®ҡжңүдәәдјҡиҜҙпјҢиҝҷ并没жңүжҠҠеҺҹй—®йўҳз®ҖеҢ–е‘ҖгҖӮеҳҝеҳҝпјҢе…¶е®һз®ҖеҢ–дәҶпјҢеҸӘдёҚиҝҮеңЁдҪ зңӢдёҚи§Ғзҡ„ең°ж–№пјҢд»Ҙиҝҷж ·зҡ„еҪўејҸжҸҸиҝ°й—®йўҳд»ҘеҗҺпјҢжҲ‘们зҡ„дјҳеҢ–й—®йўҳе°‘дәҶеҫҲеӨ§дёҖйғЁеҲҶдёҚзӯүејҸзәҰжқҹпјҲи®°еҫ—иҝҷжҳҜжҲ‘们解дёҚдәҶжһҒеҖјй—®йўҳзҡ„дёҮжҒ¶д№ӢжәҗпјүгҖӮдҪҶжҳҜжҺҘдёӢжқҘе…Ҳи·іиҝҮзәҝжҖ§еҲҶзұ»еҷЁжұӮи§Јзҡ„йғЁеҲҶпјҢжқҘзңӢзңӢ SVMеңЁзәҝжҖ§еҲҶзұ»еҷЁдёҠжүҖеҒҡзҡ„йҮҚеӨ§ж”№иҝӣвҖ”вҖ”ж ёеҮҪж•°гҖӮ
еҲҶдә«еҲ°пјҡ





зӣёе…іжҺЁиҚҗ
жӯӨеӨ–пјҢиҝҳеҸҜд»ҘжҺўи®ЁеңЁдёҚеҗҢзү№еҫҒз»ҙеәҰгҖҒж•°жҚ®еҲҶеёғзӯүжғ…еҶөдёӢпјҢFisherеҮҶеҲҷзәҝжҖ§еҲҶзұ»еҷЁзҡ„жҖ§иғҪеҸҳеҢ–пјҢд»ҘеҸҠдёҺе…¶д»–еҲҶзұ»з®—жі•пјҲеҰӮSVMгҖҒKNNзӯүпјүзҡ„еҜ№жҜ”пјҢиҝӣдёҖжӯҘзҗҶи§ЈFisherеҮҶеҲҷзҡ„йҖӮз”ЁжҖ§е’ҢеұҖйҷҗжҖ§гҖӮ жҖ»д№ӢпјҢеҹәдәҺFisherеҮҶеҲҷзҡ„зәҝжҖ§еҲҶзұ»еҷЁи®ҫи®Ў...
зәҝжҖ§еҲҶзұ»еҷЁдёҺзәҝжҖ§ж”ҜжҢҒеҗ‘йҮҸжңәпјҲSVMпјүжҳҜжңәеҷЁеӯҰд№ йўҶеҹҹдёӯдёӨз§ҚйҮҚиҰҒзҡ„з®—жі•пјҢдё»иҰҒз”ЁдәҺи§ЈеҶідәҢеҲҶзұ»й—®йўҳгҖӮжң¬ж–Үе°Ҷж·ұе…ҘжҺўи®ЁиҝҷдёӨз§Қж–№жі•пјҢ并йҖҡиҝҮMatlabд»Јз ҒиҝӣиЎҢжј”зӨәгҖӮ зәҝжҖ§еҲҶзұ»еҷЁжҳҜдёҖз§ҚеҹәдәҺзү№еҫҒзҡ„з®ҖеҚ•еҲҶзұ»жЁЎеһӢпјҢе®ғйҖҡиҝҮжһ„е»әдёҖдёӘ...
еҸҰдёҖз§Қеёёи§Ғзҡ„зәҝжҖ§еҲҶзұ»еҷЁжҳҜйҖ»иҫ‘еӣһеҪ’пјҢе®ғйҖҡиҝҮзәҝжҖ§еҮҪж•°жҳ е°„еҲ°жҰӮзҺҮз©әй—ҙпјҢ并дҪҝз”ЁsigmoidеҮҪж•°иҝӣиЎҢйқһзәҝжҖ§еҸҳжҚўпјҢе®һзҺ°жҰӮзҺҮйў„жөӢгҖӮеңЁMATLABдёӯпјҢеҸҜд»ҘдҪҝз”Ё`fisherdiscrim`еҮҪж•°е®һзҺ°LDAпјҢжҲ–иҖ…`fitclinear`еҮҪж•°иҝӣиЎҢйҖ»иҫ‘еӣһеҪ’и®ӯз»ғгҖӮ ...
еңЁиҝҷдёӘвҖңзәҝжҖ§еҲҶзұ»еҷЁд»Јз ҒвҖқеҺӢзј©еҢ…дёӯпјҢжҲ‘们еҫҲеҸҜиғҪдјҡжүҫеҲ°дҪҝз”ЁPythonе®һзҺ°зҡ„зәҝжҖ§еҲҶзұ»еҷЁзӨәдҫӢпјҢдҫӢеҰӮйҖ»иҫ‘еӣһеҪ’гҖҒж”ҜжҢҒеҗ‘йҮҸжңәпјҲSVMпјүжҲ–иҖ…зәҝжҖ§еҲӨеҲ«еҲҶжһҗпјҲLDAпјүгҖӮиҝҷдәӣжЁЎеһӢйғҪеҹәдәҺж•°жҚ®зҡ„зәҝжҖ§зү№жҖ§иҝӣиЎҢйў„жөӢпјҢ并且еңЁиҜёеҰӮдәҢеҲҶзұ»жҲ–еӨҡе…ғ...
еҜ№дәҺзәҝжҖ§еҲҶзұ»еҷЁпјҢжҲ‘们йҖҡеёёдҪҝз”ЁжўҜеәҰдёӢйҷҚжі•жҲ–жӯЈи§„ж–№зЁӢжқҘжұӮи§ЈжЁЎеһӢеҸӮж•°гҖӮжўҜеәҰдёӢйҷҚжҳҜиҝӯд»Јж–№жі•пјҢйҖҡиҝҮдёҚж–ӯи°ғж•ҙжқғйҮҚд»ҘжңҖе°ҸеҢ–жҚҹеӨұеҮҪж•°пјӣжӯЈи§„ж–№зЁӢеҲҷзӣҙжҺҘи®Ўз®—жңҖдјҳи§ЈпјҢйҖӮеҗҲе°Ҹ规模数жҚ®йӣҶгҖӮ еңЁnumpyдёӯпјҢжҲ‘们еҸҜд»ҘеҲ©з”Ёзҹ©йҳөд№ҳжі•пјҲ`@`...
йҖҡиҝҮи§ЈеҶідјҳеҢ–й—®йўҳпјҢSVMеҸҜд»ҘеӨ„зҗҶзәҝжҖ§е’ҢйқһзәҝжҖ§еҲҶзұ»д»»еҠЎпјҢ并且з”ұдәҺе…¶дјҳз§Җзҡ„жіӣеҢ–иғҪеҠӣпјҢжҲҗдёәжңәеҷЁеӯҰд№ дёӯдёҚеҸҜжҲ–зјәзҡ„е·Ҙе…·д№ӢдёҖгҖӮеңЁе®һйҷ…еә”з”ЁдёӯпјҢйҖүжӢ©еҗҲйҖӮзҡ„ж ёеҮҪж•°гҖҒи°ғж•ҙжӯЈеҲҷеҢ–еҸӮж•°Cд»ҘеҸҠеӨ„зҗҶеӨ§и§„жЁЎж•°жҚ®йӣҶжҳҜдјҳеҢ–SVMжЁЎеһӢжҖ§иғҪзҡ„...
SVMзҡ„еҹәжң¬жЁЎеһӢжҳҜе®ҡд№үеңЁзү№еҫҒз©әй—ҙдёҠзҡ„й—ҙйҡ”жңҖеӨ§зҡ„зәҝжҖ§еҲҶзұ»еҷЁпјҢй—ҙйҡ”жңҖеӨ§дҪҝе®ғжңүеҲ«дәҺж„ҹзҹҘжңәпјӣSVMиҝҳеҢ…жӢ¬дәҶж ёжҠҖе·§пјҢиҝҷдҪҝеҫ—е®ғжҲҗдёәе®һиҙЁдёҠзҡ„йқһзәҝжҖ§еҲҶзұ»еҷЁгҖӮж ёжҠҖе·§йҖҡиҝҮе°ҶеҺҹе§Ӣж•°жҚ®жҳ е°„еҲ°й«ҳз»ҙз©әй—ҙпјҢдҪҝеҫ—еңЁеҺҹз©әй—ҙдёӯйҡҫд»ҘеҲҶзҰ»зҡ„ж•°жҚ®еңЁ...
йқһзәҝжҖ§SVMеҲҶзұ»еҷЁи®ҫи®ЎжҳҜж”ҜжҢҒеҗ‘йҮҸжңәпјҲSVMпјүдёӯзҡ„дёҖдёӘйҮҚиҰҒз ”з©¶йўҶеҹҹгҖӮSVMжҳҜдёҖз§Қе№ҝжіӣеә”з”ЁдәҺеҲҶзұ»й—®йўҳзҡ„зӣ‘зқЈеӯҰд№ ж–№жі•гҖӮе®ғеңЁеӨ„зҗҶй«ҳз»ҙж•°жҚ®ж—¶е…·жңүиүҜеҘҪзҡ„жҖ§иғҪпјҢ并且еҜ№дәҺйқһзәҝжҖ§й—®йўҳе…·жңүиҫғеҘҪзҡ„еӨ„зҗҶиғҪеҠӣгҖӮ йҰ–е…ҲпјҢдәҶи§ЈSVMеҲҶзұ»еҷЁзҡ„...
6. **ж ёеҮҪж•°**пјҡиҷҪ然зәҝжҖ§SVMдё»иҰҒеӨ„зҗҶзәҝжҖ§й—®йўҳпјҢдҪҶйҖҡиҝҮеј•е…Ҙж ёеҮҪж•°пјҢеҰӮй«ҳж–Ҝж ёпјҲRBFпјүгҖҒеӨҡйЎ№ејҸж ёгҖҒsigmoidж ёзӯүпјҢеҸҜд»Ҙе°Ҷж•°жҚ®жҳ е°„еҲ°й«ҳз»ҙз©әй—ҙпјҢеңЁж–°зҡ„з©әй—ҙдёӯе®һзҺ°йқһзәҝжҖ§еҲҶзұ»гҖӮ 7. **жӯЈеҲҷеҢ–**пјҡеңЁзәҝжҖ§SVMзҡ„дјҳеҢ–зӣ®ж ҮдёӯпјҢжңүдёҖ...
гҖҠжЁЎејҸиҜҶеҲ«пјҡжЁЎеһӢйҖүжӢ©гҖҒSVMдёҺеҲҶзұ»еҷЁйӣҶжҲҗиҜҰи§ЈгҖӢ жЁЎејҸиҜҶеҲ«жҳҜжңәеҷЁеӯҰд№ зҡ„ж ёеҝғйўҶеҹҹпјҢж¶үеҸҠжЁЎеһӢйҖүжӢ©гҖҒеҲҶзұ»еҷЁжһ„е»әд»ҘеҸҠйӣҶжҲҗзӯ–з•ҘзӯүеӨҡдёӘе…ій”®жҰӮеҝөгҖӮжң¬ж–Үе°Ҷж·ұе…ҘжҺўи®ЁAdaboostз®—жі•зҡ„и®ҫи®ЎжҖқжғіпјҢжЁЎеһӢйҖүжӢ©зҡ„еҹәжң¬еҺҹеҲҷпјҢд»ҘеҸҠSVMзҡ„зҗҶи®ә...
2. SVMзҡ„ж ёеҮҪж•°пјҡи®Іи§ЈSVMеҰӮдҪ•еӨ„зҗҶйқһзәҝжҖ§еҸҜеҲҶй—®йўҳпјҢйҖҡиҝҮеј•е…Ҙж ёеҮҪж•°еҰӮзәҝжҖ§ж ёгҖҒеӨҡйЎ№ејҸж ёгҖҒй«ҳж–Ҝж ёпјҲRBFпјүзӯүпјҢе°Ҷж•°жҚ®жҳ е°„еҲ°й«ҳз»ҙз©әй—ҙпјҢе®һзҺ°йқһзәҝжҖ§еҲҶзұ»гҖӮ 3. жңҖеӨ§иҫ№з•ҢдёҺж”ҜжҢҒеҗ‘йҮҸпјҡи§ЈйҮҠж”ҜжҢҒеҗ‘йҮҸжҳҜеҰӮдҪ•е®ҡд№үзҡ„пјҢе®ғ们жҳҜзҰ»еҶізӯ–...
### SVMе…Ҙй—ЁпјҲе…ӯпјүзәҝжҖ§еҲҶзұ»еҷЁзҡ„жұӮи§ЈвҖ”вҖ”й—®йўҳзҡ„иҪ¬еҢ–пјҢзӣҙи§Ӯи§’еәҰ #### 1. й—®йўҳиғҢжҷҜдёҺзӣ®ж Ү ж”ҜжҢҒеҗ‘йҮҸжңә(Support Vector Machine, SVM)жҳҜдёҖз§Қе№ҝжіӣеә”з”ЁдәҺжңәеҷЁеӯҰд№ йўҶеҹҹзҡ„еҲҶзұ»дёҺеӣһеҪ’еҲҶжһҗз®—жі•гҖӮжң¬ж–ҮжЎЈж—ЁеңЁйҖҡиҝҮдёҖзі»еҲ—ж•ҷзЁӢеё®еҠ©...
еңЁе®һйҷ…еә”з”ЁдёӯпјҢз ”з©¶дәәе‘ҳеҸҜд»ҘеҲ©з”ЁиҝҷдәӣдјҳеҢ–зҡ„SVMеҲҶзұ»еҷЁжқҘи§ЈеҶіеҗ„з§ҚдҝЎеҸ·еҲҶзұ»й—®йўҳпјҢдҫӢеҰӮеЈ°йҹіиҜҶеҲ«гҖҒеӣҫеғҸеҲҶзұ»гҖҒз”ҹзү©еҢ»еӯҰдҝЎеҸ·еҲҶжһҗзӯүгҖӮйҖҡиҝҮи°ғж•ҙеҸӮж•°гҖҒйҖүжӢ©йҖӮеҪ“зҡ„ж ёеҮҪж•°е’ҢдјҳеҢ–з®—жі•пјҢеҸҜд»Ҙжңүж•Ҳең°жҸҗй«ҳжЁЎеһӢеңЁзү№е®ҡд»»еҠЎдёҠзҡ„жҖ§иғҪгҖӮ
еңЁж ҮйўҳвҖңSVM.rar_gmm svm д»Јз Ғ_svm cд»Јз Ғ_svmеҲҶзұ»еҷЁ_svmеҲҶзұ»еҷЁз”Ёжі•вҖқдёӯпјҢжҲ‘们еҸҜд»ҘзңӢеҲ°SVMдёҺGMMпјҲй«ҳж–Ҝж··еҗҲжЁЎеһӢпјүзҡ„з»“еҗҲпјҢд»ҘеҸҠSVMзҡ„CиҜӯиЁҖе®һзҺ°е’ҢдҪҝз”Ёж–№жі•гҖӮиҝҷдёӘеҺӢзј©еҢ…ж–Ү件еҫҲеҸҜиғҪжҳҜеҢ…еҗ«дәҶдёҖдёӘе®һзҺ°иҝҷдәӣеҠҹиғҪзҡ„жәҗд»Јз Ғеә“гҖӮ ...
жң¬ж–ҮжЎЈж—ЁеңЁеё®еҠ©иҜ»иҖ…зҗҶи§Јж”ҜжҢҒеҗ‘йҮҸжңә(SVM)дёӯзҡ„зәҝжҖ§еҲҶзұ»еҷЁжұӮи§ЈиҝҮзЁӢеҸҠе…¶ж•°еӯҰиЎЁиҝ°пјҢзү№еҲ«е…іжіЁдәҺеҰӮдҪ•е°ҶзәҝжҖ§еҲҶзұ»еҷЁй—®йўҳиҪ¬еҢ–дёәдјҳеҢ–й—®йўҳпјҢ并讨и®әе…¶и§ЈеҶіж–№жЎҲгҖӮ #### дјҳеҢ–й—®йўҳжҰӮиҝ° еңЁж•°еӯҰдјҳеҢ–йўҶеҹҹпјҢдёҖдёӘж ҮеҮҶзҡ„дјҳеҢ–й—®йўҳеҸҜд»Ҙиў«...
SVMеҲҶзұ»еҷЁдёӯзҡ„жңҖдјҳеҢ–й—®йўҳжҳҜжҢҮеҰӮдҪ•йҖҡиҝҮжұӮи§ЈжңҖдјҳеҢ–й—®йўҳжқҘеҫ—еҲ°SVMеҲҶзұ»еҷЁзҡ„жңҖжӯЈзЎ®еҸӮж•°пјҢдҪҝеҫ—SVMеҲҶзұ»еҷЁзҡ„жҖ§иғҪжңҖеҘҪгҖӮ дёҖгҖҒзәҝжҖ§еҲҶзұ» еңЁSVMеҲҶзұ»еҷЁдёӯпјҢзәҝжҖ§еҲҶзұ»жҳҜжҢҮж•°жҚ®зӮ№еңЁй«ҳз»ҙз©әй—ҙдёӯзҡ„еҲҶзұ»гҖӮеҒҮи®ҫжҲ‘们жңүдёҖдёӘж•°жҚ®зӮ№ixпјҢixжҳҜ...
йқһзәҝжҖ§еҲҶзұ»еҷЁзҡ„дё»иҰҒд»ЈиЎЁвҖ”вҖ”зҘһз»ҸзҪ‘з»ңе’ҢSVMпјҢйғҪиғҪеӨҹйҖҡиҝҮдёҚеҗҢзҡ„ж•°еӯҰе·Ҙе…·е’ҢдјҳеҢ–зӯ–з•ҘпјҢиҫҫеҲ°е°ҶеӨҚжқӮж•°жҚ®еҲҶзұ»зҡ„зӣ®зҡ„гҖӮиҝҷдәӣж–№жі•еңЁеӣҫеғҸиҜҶеҲ«гҖҒиҜӯйҹіиҜҶеҲ«гҖҒиҮӘ然иҜӯиЁҖеӨ„зҗҶзӯүдј—еӨҡйўҶеҹҹйғҪжңүеҮәиүІзҡ„иЎЁзҺ°пјҢжһҒеӨ§ең°жҺЁеҠЁдәҶдәәе·ҘжҷәиғҪжҠҖжңҜзҡ„...
зәҝжҖ§еҲҶзұ»еҷЁ - **жңҖеӨ§й—ҙйҡ”**пјҡSVMиҜ•еӣҫжүҫеҲ°дёҖдёӘи¶…е№ійқўпјҢдҪҝеҫ—жӯЈиҙҹж ·жң¬и·қзҰ»иҜҘи¶…е№ійқўзҡ„е№іеқҮи·қзҰ»жңҖеӨ§еҢ–гҖӮиҝҷз§ҚжңҖеӨ§еҢ–й—ҙйҡ”зҡ„ж–№жі•жңүеҠ©дәҺжҸҗй«ҳжЁЎеһӢзҡ„жіӣеҢ–иғҪеҠӣгҖӮ - **ж”ҜжҢҒеҗ‘йҮҸ**пјҡзҰ»и¶…е№ійқўжңҖиҝ‘зҡ„ж ·жң¬зӮ№з§°дёәж”ҜжҢҒеҗ‘йҮҸгҖӮиҝҷдәӣзӮ№еҶіе®ҡ...
жҖ»зҡ„жқҘиҜҙпјҢC++е®һзҺ°зҡ„ж”ҜжҢҒеҗ‘йҮҸжңәSVMеҲҶзұ»еҷЁжҳҜжңәеҷЁеӯҰд№ дёӯзҡ„дёҖдёӘйҮҚиҰҒе·Ҙе…·пјҢз»“еҗҲ`svm_light`еә“пјҢжҲ‘们еҸҜд»Ҙеҝ«йҖҹжһ„е»әе’Ңеә”з”ЁSVMжЁЎеһӢпјҢи§ЈеҶіе®һйҷ…зҡ„еҲҶзұ»й—®йўҳгҖӮеңЁе®һйҷ…йЎ№зӣ®дёӯпјҢејҖеҸ‘иҖ…йңҖиҰҒж №жҚ®е…·дҪ“й—®йўҳйҖүжӢ©еҗҲйҖӮзҡ„еҸӮж•°пјҢдёҚж–ӯи°ғдјҳпјҢд»Ҙ...
ж”ҜжҢҒеҗ‘йҮҸжңәпјҲsupport vector machines, SVMпјүжҳҜдёҖз§ҚдәҢеҲҶзұ»жЁЎеһӢпјҢе®ғзҡ„еҹәжң¬жЁЎеһӢжҳҜе®ҡд№үеңЁзү№еҫҒз©әй—ҙдёҠзҡ„й—ҙйҡ”жңҖеӨ§зҡ„зәҝжҖ§еҲҶзұ»еҷЁпјҢй—ҙйҡ”жңҖеӨ§дҪҝе®ғжңүеҲ«дәҺж„ҹзҹҘжңәпјӣSVMиҝҳеҢ…жӢ¬ж ёжҠҖе·§пјҢиҝҷдҪҝе®ғжҲҗдёәе®һиҙЁдёҠзҡ„йқһзәҝжҖ§еҲҶзұ»еҷЁгҖӮSVMзҡ„зҡ„еӯҰд№ ...