- 浏览: 535710 次
-

文章分类
最新评论
linux 高端内存页框管理:永久内核映射、临时内核映射以及非连续内存分配
摘要:高端内存页框的内核映射分为三种情况:永久内核映射、临时内核映射和非连续内存映射。那么这三者有什么区别和联系呢?临时内核映射如何保证不会被阻塞呢?本文主要为你解答这些疑问,并详细探讨高端内存映射的前两种方式。
本文来源:linux 高端内存页框管理:永久内核映射、临时内核映射以及非连续内存分配http://blog.csdn.net/trochiluses/article/details/13016023
1.高端内存的区域划分
内核将高端内存划分为3部分:VMALLOC_START~VMALLOC_END、KMAP_BASE~FIXADDR_START和FIXADDR_START~4G。
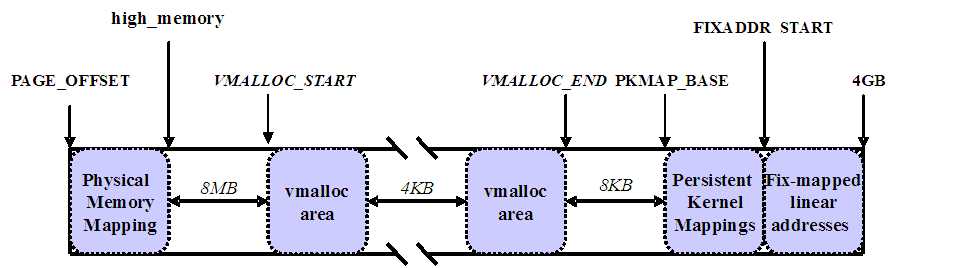
对 于高端内存,可以通过 alloc_page() 或者其它函数获得对应的 page,但是要想访问实际物理内存,还得把 page 转为线性地址才行(为什么?想想 MMU 是如何访问物理内存的),也就是说,我们需要为高端内存对应的 page 找一个线性空间,这个过程称为高端内存映射。
对应高端内存的3部分,高端内存映射有三种方式:
映射到”内核动态映射空间”(noncontiguous memory allocation)
这种方式很简单,因为通过 vmalloc() ,在”内核动态映射空间”申请内存的时候,就可能从高端内存获得页面(参看 vmalloc 的实现),因此说高端内存有可能映射到”内核动态映射空间”中。
持久内核映射(permanent kernel mapping)
如果是通过 alloc_page() 获得了高端内存对应的 page,如何给它找个线性空间?
内核专门为此留出一块线性空间,从 PKMAP_BASE 到 FIXADDR_START ,用于映射高端内存。在 2.6内核上,这个地址范围是 4G-8M 到 4G-4M 之间。这个空间起叫”内核永久映射空间”或者”永久内核映射空间”。这个空间和其它空间使用同样的页目录表,对于内核来说,就是 swapper_pg_dir,对普通进程来说,通过 CR3 寄存器指向。通常情况下,这个空间是
4M 大小,因此仅仅需要一个页表即可(注意理解这句话:一个页表(不是页表项),大小为4K,可以映射4M的空间),内核通过来 pkmap_page_table 寻找这个页表。通过 kmap(),可以把一个 page 映射到这个空间来。由于这个空间是 4M 大小,最多能同时映射 1024 个 page。因此,对于不使用的的 page,及应该时从这个空间释放掉(也就是解除映射关系),通过 kunmap() ,可以把一个 page 对应的线性地址从这个空间释放出来。
临时映射(temporary kernel mapping)
内核在 FIXADDR_START 到 FIXADDR_TOP 之间保留了一些线性空间用于特殊需求。这个空间称为”固定映射空间”在这个空间中,有一部分用于高端内存的临时映射。
这块空间具有如下特点:
(1)每个 CPU 占用一块空间
(2)在每个 CPU 占用的那块空间中,又分为多个小空间,每个小空间大小是 1 个 page,每个小空间用于一个目的,这些目的定义在 kmap_types.h 中的 km_type 中。
当要进行一次临时映射的时候,需要指定映射的目的,根据映射目的,可以找到对应的小空间,然后把这个空间的地址作为映射地址。这意味着一次临时映射会导致以前的映射被覆盖。通过 kmap_atomic() 可实现临时映射。
896M边界以上的页框并不映射在内核线性地址空间的第4个GB,因此内核不能直接访问它们。所以,返回所分配页框线性地址的页分配器函数并不对高端内存可用。
在64位平台上不存在这个问题,因为可以使用的线性地址空间大于能安装的RAM,也就是说这些体系结构的ZONE_HIGHMEM是空的。linux使用如下方法来使用高端内存:
1)高端内存页框的分配只能通过alloc_pages( )函数和它的快捷函数alloc_page( )。这些函数不返回线性地址,而是返回第一分配页框的页描述符的线性地址。
2)没有线性地址的高端内存中的页框不能被内核访问。
内核采用三种不同的机制将页框映射到高端内存:永久内核映射、临时内核映射、非连续内存分配。本节讨论前两种。
建立永久内核映射可能阻塞当前进程;也就是高端内存上没有页表项可以用作页框的窗口的时候。因此,这种方法不能用在中断处理函数和可延迟函数。临时内核映射不会阻塞当前进程,但是只有很少的临时内核映射可以建立起来。
需要注意的是,无论哪种方法,128M的线性地址用于高端内存映射,无法保证寻址范围同时到达的物理内存。
2.永久内核映射:注意,下列多有函数应用的范围是内核空间
宏定义与关键变量定义:
pkmap_page_table:高端内存主内核页表中,一个用于永久内核映射的专用页表锁在的地址
LAST_PKMAP: 上述页表所含有的表项(512或者1024)
PKMAP_BASE:该页表所映射线性地址的start地址
pkmap_count:对页表项提供计数器的数组
page_address_htable:散列表,用于记录高端页框与永久内核映射的线性地址之间的关系
page_address_map:一个数据结构,包含指向页描述符的指针和分配给页框的线性地址;用于为高端内存的每个页框提供当前映射,它被包含在page_address_htable这个hansh表中
关键函数:
page_address( page):返回页框对应的线性地址
Void * kmap(struct page * page):返回对应page的线性地址
Void * kmap_high(struct page * page): 同上,不过接受的参数是高端内存的页框描述符
map_new_virtual( ):插入页框的物理地址到pkmap_page_table,在page_address_htable散列表中加入一个元素
它是高端页框到内核地址空间的长期映射。使用主内核页表中的一个专门页表,地址存放在pkmap_page_table变量中。页表中的表项数由LAST_PKMAP宏产生。页表照样包含512或者1024项,这取决于PAE是否激活,因此,内核一次访问最多2M或者4M的高端内存。
该页表映射的线性地址从PKMAP_BASE开始,pkmap_count数组包涵LAST_PKMAP个计数器,pkmap_page_table页表中的每一个项都有一个。我们区分下列三种情况
计数器为0:对应页表项没有映射任何的高端内存页框,并且是可用的。
计数器为1:对应的页表项没有映射任何内存页框,但是它不可用,因为从它最后一次使用以来,对应的TLB表项还未被刷新。
计数器为n:相应的页表项映射一个高端内存页框,这意味着正好有n-1个内核成分在使用这个页框。
当分配项的值等于0时为自由项,等于1时为缓冲项,大于1时为映射项。映射页面的分配基于分配表的扫描,当所有的自由项都用完时,系统将清除所有的缓冲项,如果连缓冲项都用完时,系统将进入等待状态。
为了记录高端内存页框与永久内核映射的线性地址之间的联系,内核使用了page_address_htable散列表。该表包含一个page_address_map数据结构,用于为高端内存的每个页框进行当前映射。而该数据结构还包涵一个指向页描述符号的指针和分配给该页框的线性地址。
对应数据结构关系图如下:

page_address()函数返回页框对应的线性地址,如果页框在高端内存中并没有被映射,则返回NULL。这个函数接受一个页描述符指针page作为参数,并区分以下两种情况:
1)页框不在高端内存中:
__va( ( unsigned long) (page - meme_map) << 12)
2) 页框在高端内存中,该函数就得到page_address_htable中寻找。如果在散列表中找到页框,page_address()就返回它的线性地址,否则就返回NULL。
代码实现如下:
void *kmap(struct page *page)
{
might_sleep();
if (!PageHighMem(page))
return page_address(page);
return kmap_high(page);
}
如果页框确实属于高端内存,那么调用kmap_high()函数如下:
/* We cannot call this from interrupts, as it may block.
*/
void *kmap_high(struct page *page)
{
unsigned long vaddr;
/*
* For highmem pages, we can't trust "virtual" until
* after we have the lock.
*/
lock_kmap();
vaddr = (unsigned long)page_address(page);//检查页框是否已经被映射
if (!vaddr)//没有被映射
vaddr = map_new_virtual(page);//将页框的物理地址插入到pkmap_page_table并在pkmapa_address_table散列表中加入一个元素
pkmap_count[PKMAP_NR(vaddr)]++;//页框的线性地址对应的计数器+1
BUG_ON(pkmap_count[PKMAP_NR(vaddr)] < 2);
unlock_kmap();
return (void*) vaddr;
}
其中的一些宏定义内容如下:
#define PKMAP_BASE (PAGE_OFFSET - PMD_SIZE)
#define LAST_PKMAP PTRS_PER_PTE
#define LAST_PKMAP_MASK (LAST_PKMAP - 1)
#define PKMAP_NR(virt) (((virt) - PKMAP_BASE) >> PAGE_SHIFT)
#define PKMAP_ADDR(nr) (PKMAP_BASE + ((nr) << PAGE_SHIFT))
map_new_virtual( )函数本质上是两个嵌套循环,完成的工作是:插入物理地址到hashtable和在对应hashtable中增加一个元素,代码如下:
static inline unsigned long map_new_virtual(struct page *page)
{
unsigned long vaddr;
int count;
start:
count = LAST_PKMAP;//固定映射的页表项个数
/* Find an empty entry */
for (;;) {
last_pkmap_nr = (last_pkmap_nr + 1) & LAST_PKMAP_MASK;//与掩码进行按位与运算,避免数据过长造成的溢出
if (!last_pkmap_nr) {//last_pkmap_nr==0,说明它原来已经到达最大值(注意与运算)
flush_all_zero_pkmaps();
count = LAST_PKMAP;
}
if (!pkmap_count[last_pkmap_nr])
break; /* Found a usable entry */
if (--count)
continue;
/*
* Sleep for somebody else to unmap their entries
*/
{
DECLARE_WAITQUEUE(wait, current);
__set_current_state(TASK_UNINTERRUPTIBLE);
add_wait_queue(&pkmap_map_wait, &wait);
unlock_kmap();
schedule();
remove_wait_queue(&pkmap_map_wait, &wait);
lock_kmap();
/* Somebody else might have mapped it while we slept */
if (page_address(page))
return (unsigned long)page_address(page);
/* Re-start */
goto start;
}
}
vaddr = PKMAP_ADDR(last_pkmap_nr);
set_pte_at(&init_mm, vaddr,
&(pkmap_page_table[last_pkmap_nr]), mk_pte(page, kmap_prot));
pkmap_count[last_pkmap_nr] = 1;
set_page_address(page, (void *)vaddr);
return vaddr;
}
然后,kunmap()函数撤销原来有kmap()建立的永久内核映射。如果页处在高端内存,调用kunmap_high()函数。代码如下:
250 void kunmap_high(struct page *page)
251 {
252 unsigned long vaddr;
253 unsigned long nr;
254 unsigned long flags;
255 int need_wakeup;
256
257 lock_kmap_any(flags);
258 vaddr = (unsigned long)page_address(page);
259 BUG_ON(!vaddr);//嵌入式汇编有关的bug处理
260 nr = PKMAP_NR(vaddr);//(((virt) - PKMAP_BASE) >> PAGE_SHIFT)页号
261
262 /*
263 * A count must never go down to zero
264 * without a TLB flush!
265 */
266 need_wakeup = 0;
267 switch (--pkmap_count[nr]) {
268 case 0:
269 BUG();
270 case 1://没有进程在使用页
271 /*
272 * Avoid an unnecessary wake_up() function call.
273 * The common case is pkmap_count[] == 1, but
274 * no waiters.
275 * The tasks queued in the wait-queue are guarded
276 * by both the lock in the wait-queue-head and by
277 * the kmap_lock. As the kmap_lock is held here,
278 * no need for the wait-queue-head's lock. Simply
279 * test if the queue is empty.
280 */
281 need_wakeup = waitqueue_active(&pkmap_map_wait);//唤醒
282 }
283 unlock_kmap_any(flags);
284
285 /* do wake-up, if needed, race-free outside of the spin lock */
286 if (need_wakeup)
287 wake_up(&pkmap_map_wait);//唤醒由map_new_virtual()添加在等待队列中的进程
288 }
289
3.临时内核映射:和进程控制有关
临时内核映射实现简单,可以用在中断处理程序和可延迟函数的内部(这些函数不能被阻塞),因为临时内核映射从来不阻塞当前进程,因为它被设计成是原子的。对比永久内核映射,发现如果页框暂时没有空闲的虚拟地址可以映射,那么永久内核映射将要被阻塞。
建立临时内核映射禁用内核抢占,这是必须的,因为映射对于每个处理器都是独特的,如果没有禁用抢占,那么哪个任务在哪个CPU上运行是不确定的。(这一段需要结合进程管理加以理解)
撤销临时内核映射的函数实际上可以不进行任何实质性的操作,它仅仅允许内核抢占即可(这样新的进程被调度,可以直接使用临时内核映射区域,覆盖原来的映射关系)。
每个CPU都有它自己的包含13个窗口的集合,它们用enum km_type数据结构表示。该数据结构定义的每个符号,标识了一个窗口的线性地址。
7 enum km_type {
8 KM_BOUNCE_READ,
9 KM_SKB_SUNRPC_DATA,
10 KM_SKB_DATA_SOFTIRQ,
11 KM_USER0,
12 KM_USER1,
13 KM_BIO_SRC_IRQ,
14 KM_BIO_DST_IRQ,
15 KM_PTE0,
16 KM_PTE1,
17 KM_IRQ0,
18 KM_IRQ1,
19 KM_SOFTIRQ0,
20 KM_SOFTIRQ1,
21 KM_L1_CACHE,
22 KM_L2_CACHE,
23 KM_TYPE_NR
24 };
其中,内核要确保同一个窗口永远不会被两个不同的控制路径同时使用。最后一个符号非线性地址,但由每个CPU用来产生不同的可用窗口数。
km_type的每一个符号都是固定映射的线性地址的一个下标。enum fixed_addresses数据结构包含符号FIX——KMAP——BEGIN和FIX_KMP_END;把后者的值赋成下标FIX_KMAP_BEGIN+(KM_TYPE_NR*NR_CPUS)-1。在这种方式下,系统中的每个CPU有KM-TYPE-NR个固定映射的线性地址。此外,内核用fix_to
_virt(FIX_KMAP_BEGIN )线性地址对应的页表项的地址初始化kmap_pte变量。
39 void *kmap_atomic(struct page *page, enum km_type type)
40 {
41 unsigned int idx;
42 unsigned long vaddr;
43 void *kmap;
44
45 pagefault_disable();//有关锁和内核抢占机制
46 if (!PageHighMem(page))
47 return page_address(page);
48
49 debug_kmap_atomic(type);//debug点
50
51 kmap = kmap_high_get(page);//类似kmap_high的功能,只有这个函数返回非空指针,才可以调用kmap_high()
52 if (kmap)
53 return kmap;
54
55 idx = type + KM_TYPE_NR * smp_processor_id();//指明需要使用的线性地址
56 vaddr = __fix_to_virt(FIX_KMAP_BEGIN + idx);//固定映射的线性地址转化成虚拟地址
57 #ifdef CONFIG_DEBUG_HIGHMEM
58 /*
59 * With debugging enabled, kunmap_atomic forces that entry to 0.
60 * Make sure it was indeed properly unmapped.
61 */
62 BUG_ON(!pte_none(*(TOP_PTE(vaddr))));
63 #endif
64 set_pte_ext(TOP_PTE(vaddr), mk_pte(page, kmap_prot), 0);//设置页表项:线性地址,page 页框信息
65 /*
66 * When debugging is off, kunmap_atomic leaves the previous mapping
67 * in place, so this TLB flush ensures the TLB is updated with the
68 * new mapping.
69 */
70 local_flush_tlb_kernel_page(vaddr);//刷新TLB无效
71
72 return (void *)vaddr;
73 }
#define set_pte_ext(ptep,pte,ext) cpu_set_pte_ext(ptep,pte,ext)
68 #define cpu_set_pte_ext(ptep,pte,ext) processor.set_pte_ext(ptep,pte,ext)
6 #define TOP_PTE(x) pte_offset_kernel(top_pmd, x)
311 /* Find an entry in the third-level page table.. */
312 extern inline pte_t * pte_offset_kernel(pmd_t * dir, unsigned long address)
313 {
314 pte_t *ret = (pte_t *) pmd_page_vaddr(*dir)
315 + ((address >> PAGE_SHIFT) & (PTRS_PER_PAGE - 1));
316 smp_read_barrier_depends(); /* see above */
317 return ret;
318 }
371 #define mk_pte(page, pgprot) pfn_pte(page_to_pfn(page), (pgprot))


发表评论

相关推荐
高端内存映射的三种机制分别是永久映射、临时映射和非连续内存分配映射(vmalloc)。 1. **非连续内存分配(vmalloc)**:vmalloc是一种用于分配大块但不连续物理内存的机制,特别是在物理内存碎片化严重时。vmalloc...
在 Linux 内核中,大内存分配的实现主要通过 alloc_page() 和 alloc_pages() 函数来实现,它们都是通过伙伴系统算法来分配内存的。free_page() 和 free_pages() 函数则用于释放已经分配的内存。 在 Linux 中,每一...
Linux内核内存管理是操作系统中极为重要的一个部分,它涉及到操作系统如何高效、合理地使用物理内存资源以及虚拟内存资源。Linux内核内存管理机制包括页面类型与组织、页面回收逻辑、内存区域划分、页面分配策略、...
- **临时内核映射**:仅在特定时间段内有效的内存映射。 #### 第二章:内核级内存管理系统 ##### 2.1 Linux页面管理 Linux内核使用页面作为基本的内存分配单元。页面管理涉及到页面的分配、回收等操作。 - **...
1. **页(Page)和页框(Page Frame)**:Linux内核以页为单位管理内存,页是内存分配的基本单位,通常为4KB。页框则是物理内存中实际的硬件内存块。 2. **页表(Page Table)**:每个进程都有自己的页表,用于映射...
3. 内存管理:了解Linux如何分配和回收内存,包括物理内存的组织、虚拟内存的映射、页面缓存等机制。这些知识对于优化程序性能和避免内存泄漏至关重要。 4. 文件系统:Linux内核支持多种文件系统,如EXT2、EXT3、...
对于高端内存页,则在“内核永久映射空间”中创建映射。kmap()返回的地址应当在使用完毕后通过kunmap()释放,以避免过多的映射压垮系统。 总结来说,kmalloc() 和 kfree() 通常用于分配小块内存,适用于内核频繁...
内容概要:本文探讨了 Linux 内核引入大型 Folios(大页)来管理匿名内存的技术进展。Folios 具备动态调整页面大小的能力,从而减少页面错误次数和提升内存访问效率。文中介绍了一项改进内存映射机制的工作,在处理...
这种机制允许内核利用有限的虚拟地址空间访问所有的物理内存,而无需为每个物理内存分配固定的虚拟地址。 Linux内核通过页表(Page Table)来实现这种映射。在32位系统中,使用PTE(Page Table Entry)来描述物理页...
Linux操作系统采用了现代计算机体系结构中的内存分页管理机制,这一机制的核心在于将物理内存分割成固定大小的页面(通常为4KB),并将虚拟地址空间同样划分为相同大小的页框。这种分页机制允许操作系统将一个进程的...
Linux 2.6内核的技术进步,如反向映射、更大的内存页、页表条目的高端内存存储和更为稳定的内存管理器等,都极大地提高了Linux作为企业级操作系统的适用性。 X86架构上的硬件寻址方法涉及到Intel x86手册中的具体...
- Linux0.11内核采用伙伴系统(Buddy System)来管理物理内存,这是一种高效的小块内存分配策略。 - 伙伴系统将内存划分为不同大小的块,每个块的大小是2的幂次方,这样分配和回收时可以快速找到相邻的伙伴。 5. ...
除了这些基本的内存分配方式,Linux还提供了其他高级内存管理机制,如slab缓存,用于高效管理内核对象的内存分配,以及伙伴系统,用于物理页的分配和回收。设备驱动程序常常利用内存映射技术来直接访问硬件寄存器或...
本文将深入探讨Linux在X86平台上如何实现虚拟内存管理,包括虚拟地址空间的划分、页表机制、内存分配与回收、交换机制以及缓存管理。 1. 虚拟地址空间: 在X86架构下,Linux为每个进程分配了一个独立的4GB虚拟地址...
- **功能描述**:非连续内存分配机制允许内核为设备驱动程序分配非连续的物理内存页,这对于某些硬件设备来说是非常必要的。 - **函数调用关系图**:展示了非连续内存分配过程中各个函数之间的调用关系。 - **主要...
Linux内核内存管理是操作系统设计的关键部分,它负责有效地分配、使用和回收系统中的物理内存。在Linux系统中,内存管理机制确保了高效且可靠的内存使用,为各个进程提供了一个一致且安全的运行环境。本资料主要探讨...
与直接映射的物理内存末端、高端内存的始端所对应...分别叫做内核映射、临时内核映射以及非连续内存分配。在这里,只总结前两种技术,第三种技术将在后面总结。 建立内核映射可能阻塞当前进程;这发生在空闲页表项不
4. **vmalloc机制**:允许非连续物理页框通过连续的虚拟地址访问,有效利用高端内存。 slab分配器是解决物理内存内部碎片的关键,它为不同类型的内核对象建立高速缓存,每个对象高速缓存由多个slab组成,slab又由页...
在 Linux 内核启动时,需要初始化内存管理系统,包括建立内存管理数据结构、 initializes 页框分配器、设置内存保护机制等。在这个过程中,Linux 内核会根据 Bootloader 传递的参数建立 meminfo 结构体,用于描述...
Linux 内核的内存管理探秘之四 虚拟内存的管理 Linux 操作系统中,内存管理是非常重要的一部分。虚拟内存技术是现代操作系统中的一个关键技术,它克服了旧有的内存管理的限制,允许系统运行比物理内存大的应用程序...