了解HashMap原理对于日后的缓存机制多少有些认识。在网络中也有很多方面的帖子,但是很多都是轻描淡写,很少有把握的比较准确的信息,在这里试着不妨说解一二。
对于HashMap主要以键值(key-value)的方式来体现,笼统的说就是采用key值的哈希算法来,外加取余最终获取索引,而这个索引可以认定是一种地址,既而把相应的value存储在地址指向内容中。这样说或许比较概念化,也可能复述不够清楚,来看列式更加清晰:
int hash=key.hashCode();//------------------------1
int index=hash%table.lenth;//table表示当前对象的长度-----------------------2
其实最终就是这两个式子决定了值得存储位置。但是以上两个表达式还有欠缺。为什么这么说?例如在key.hashCode()后可能存在是一个负整数,你会问:是啊,那这个时候怎么办呢?所以在这里就需要进一步加强改造式子2了,修改后的:
int index=(hash&Ox7FFFFFFF)%table.lenth;
到这里又迷惑了,为什么上面是这样的呢?对于先前我们谈到在hash有可能产生负数的情况,这里我们使用当前的hash做一个“与”操作,在这里需要和int最大的值相“与”。这样的话就可以保证数据的统一性,把有符号的数值给“与”掉。而一般这里我们把二进制的数值转换成16进制的就变成了:Ox7FFFFFFF。(注:与操作的方式为,不同为0,相同为1)。而对于hashCode()的方法一般有:
public int hashCode(){
int hash=0,offset,len=count;
char[] var=value;
for(int i=0;i<len;i++){
h=31*hash+var[offset++];
}
return hash;
}
说道这里大家可能会说,到这里算完事了吧。但是你可曾想到如果数据都采用上面的方式,最终得到的可能index会相同怎么办呢?如果你想到的话,那恭喜你!又增进一步了,这里就是要说到一个名词:冲突率。是的就是前面说道的一旦index有相同怎么办?数据又该如何存放呢,而且这个在数据量非常庞大的时候这个基率更大。这里按照算法需要明确的一点:每个键(key)被散列分布到任何一个数组索引的可能性相同,而且不取决于其它键分布的位置。这句话怎么理解呢?从概率论的角度,也就是说如果key的个数达到一个极限,每个key分布的机率都是均等的。更进一步就是:即便key1不等于key2也还是可能key1.hashCode()=key2.hashCode()。
对于早期的解决冲突的方法有折叠法(folding),例如我们在做系统的时候有时候会采用部门编号附加到某个单据标号后,这里比如产生一个9~11位的编码。通过对半折叠做。
现在的策略有:
1. 键式散列
2. 开放地址法
在了解这两个策略前,我们先定义清楚几个名词解释:
threshold[阀值],对象大小的边界值;
loadFactor[加载因子]=n/m ;其中n代表对象元素个数,m表示当前表的容积最大值
threshold=(int)table.length*loadFactor
清晰了这几个定义,我们再来看具体的解决方式
键式散列:
我们直接看一个实例,这样就更加清晰它的工作方式,从而避免文字定义。我们这里还是来举一个图书编号的例子,下面比如有这样一些编号:
78938-0000
45678-0001
72678-0002
24678-0001
16678-0001
98678-0003
85678-0002
45232-0004
步骤:
1. 把编号作为key,即:int hash=key.hashCode();
2. int index=hash%表大小;
3. 逐步按顺序插入对象中
现在问题出现了:对于编号通过散列算法后很可能产生相同的索引值,意味着存在冲突。

解释上面的操作:如果对于key.hashCode()产生了冲突(比如途中对于插入24678-0001对于通过哈希算法后可能产生的index或许也是501),既而把相应的前驱有相同的index的对象指向当前引用。这也就是大家认定的单链表方式。以此类推…
而这里存在冲突对象的元素放在Entry对象中,Entry具有以下一些属性:
int hash;
Object key;
Entry next;
对于Entry对象就可以直接追溯到链表数据结构体中查阅。
开放地址法:
1. 线性地址探测法:
如何理解这个概念呢,一句话:就是通过算法规则在对象地址N+1中查阅找到为NULL的索引内容。
处理方式:如果index索引与当前的index有冲突,即把当前的索引index+1。如果在index+1已经存在占位现象(index+1的内容不为NULL)试图接着index+2执行。。。直到找到索引为内容为NULL的为止。这种处理方式也叫:线性地址探测法(offset-of-1)
如果采用线性地址探测法会带来一个效率的不良影响。现在我们来分析这种方式会带来哪些不良因素。大家试想下如果一个非常庞大的数据存储在Map中,假如在某些记录集中有一些数据非常相似(他们产生的索引在内存的某个块中非常的密集),也就是说他们产生的索引地址是一个连续数值,而造成数据成块现象。另一个致命的问题就是在数据删除后,如果再次查询可能无法定到下一个连续数字,这个又是一个什么概念呢?例如以下图片就很好的说明开发地址散列如何把数据按照算法插入到对象中:
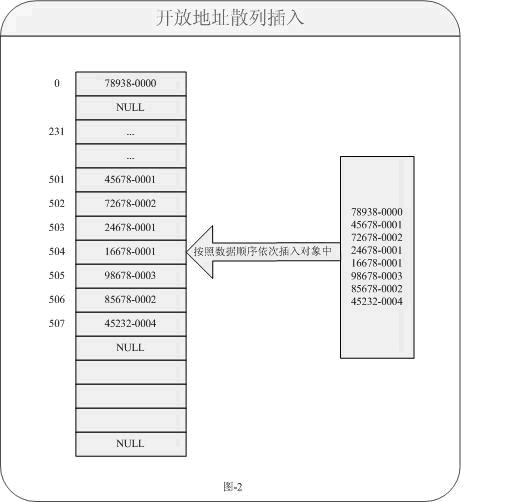
对于上图的注释步骤说明:
从数据“78938-0000”开始通过哈希算法按顺序依次插入到对象中,例如78938-0000通过换
算得到索引为0,当前所指内容为NULL所以直接插入;45678-0001同样通过换算得到索引为地址501所指内容,当前内容为NULL所以也可以插入;72678-0002得到索引502所指内容,当前内容为NULL也可以插入;请注意当24678-0001得到索引也为501,当前地址所指内容为45678-0001。即表示当前数据存在冲突,则直接对地址501+1=502所指向内容为72678-0002不为NULL也不允许插入,再次对索引502+1=503所指内容为NULL允许插入。。。依次类推只要对于索引存在冲突现象,则逐次下移位知道索引地址所指为NULL;如果索引不冲突则还是按照算法放入内容。对于这样的对象是一种插入方式,接下来就是我们的删除(remove)方法了。按照常理对于删除,方式基本区别不大。但是现在问题又出现了,如果删除的某个数据是一个存在冲突索引的内容,带来后续的问题又会接踵而来。那是什么问题呢?我们还是同样来看看图示的描述,对于图-2中如果删除(remove)数据24678-0001的方法如下图所示:
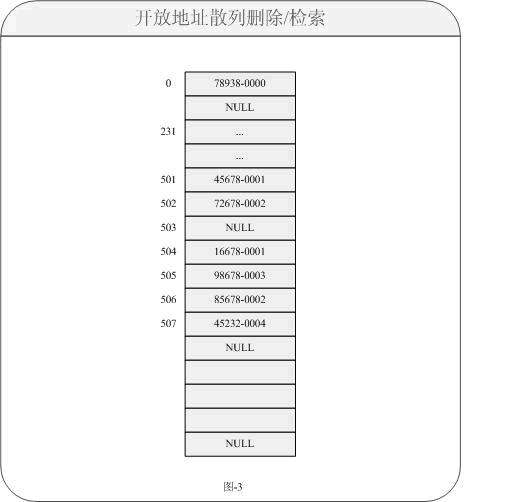
对于我们会想当然的觉得只要把指向数据置为NULL就可以,这样的做法对于删除来说当然是没有问题的。如果再次定位检索数据16678-0001不会成功,因为这个时候以前的链路已经堵上了,但是需要检索的数据事实上又存在。那我们如何来解决这个问题呢?对于JDK中的Entry类中的方法存在一个:boolean markedForRemoval;它就是一个典型的删除标志位,对于对象中如果需要删除时,我们只是对于它做一个“软删除”即置一个标志位为true就可以。而插入时,默认状态为false就可以。这样的话就变成以下图所示:
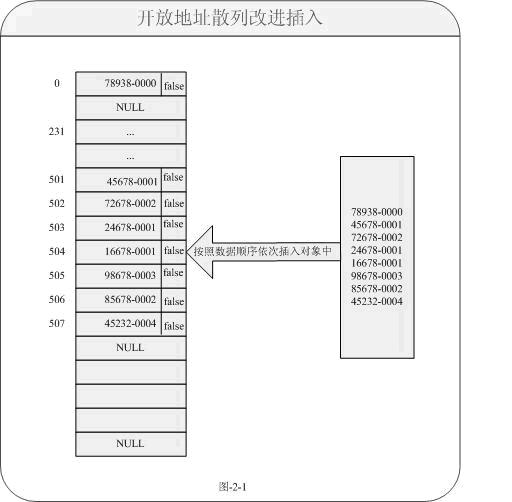
通过以上方式更好的解决冲突地址删除数据无法检索其他链路数据问题了。
2. 双散列(余商法)
在了解开放地址散列的时候我们一直在说解决方法,但是大家都知道一个数据结构的完善更多的是需要高效的算法。这当中我们却没有涉及到。接下来我们就来看看在开放地址散列中它存在的一些不足以及如何改善这样的方法,既而达到无论是在方法的解决上还是在算法的复杂度上更加达到高效的方案。
在图2-1中类似这样一些数据插入进对象,存在冲突采用不断移位加一的方式,直到找到不为NULL内容的索引地址。也正是由于这样一种可能加大了时间上的变慢。大家是否注意到像图这样一些数据目前呈现出一种连续索引的插入,而且是一种成块是的数据。如果数据量非常的庞大,或许这种可能性更大。尽管它解决了冲突,但是对于数据检索的时间度来说,我们是不敢想象的。所有分布到同一个索引index上的key保持相同的路径:index,index+1,index+2…依此类推。更加糟糕的是索引键值的检索需要从索引开始查找。正是这样的原因,对于线性探索法我们需要更进一步的改进。而刚才所描述这种成块出现的数据也就定义成:簇。而这样一种现象称之为:主簇现象。
(主簇:就是冲突处理允许簇加速增长时出现的现象)而开放式地址冲突也是允许主簇现象产生的。那我们如何来避免这种主簇现象呢?这个方式就是我们要来说明的:双散列解决冲突法了。主要的方式为:
u int hash=key.hasCode();
u int index=(hash&Ox7FFFFFFF)%table.length;
u 按照以上方式得到索引存在冲突,则开始对当前索引移位,而移位方式为:
offset=(hash&Ox7FFFFFFF)/table.length;
u 如果第一次移位还存在同样的冲突,则继续:当前冲突索引位置(索引号+余数)%表.length
u 如果存在的余数恰好是表的倍数,则作偏移位置为一下移,依此类推
这样双散列冲突处理就避免了主簇现象。至于HashSet的原理基本和它是一致的,这里不再复述。在这里其实还是主要说了一些简单的解决方式,而且都是在一些具体参数满足条件下的说明,像一旦数据超过初始值该需要rehash,加载因子一旦大于1.0是何种情况等等。还有很多问题都可以值得我们更加进一步讨论的,比如:在java.util.HashMap中的加载因子为什么会是0.75,而它默认的初始大小为什么又是16等等这些问题都还值得说明。要说明这些问题可能又需要更加详尽的说明清楚。
分享到:





相关推荐
哈希映射(HashMap)是Java编程语言中广泛使用的数据结构之一,主要提供键值对的存储和查找功能。HashMap的实现基于哈希表的概念,它通过计算对象的哈希码来快速定位数据,从而实现了O(1)的平均时间复杂度。在深入...
Java HashMap原理分析 Java HashMap是一种基于哈希表的数据结构,它的存储原理是通过将Key-Value对存储在一个数组中,每个数组元素是一个链表,链表中的每个元素是一个Entry对象,Entry对象包含了Key、Value和指向...
### HashMap原理详解 #### 一、HashMap简介与应用场景 HashMap是Java集合框架中一个非常重要的组成部分,它提供了基于键值对(key-value)映射的高效数据存储方式。由于其内部采用了数组加链表(以及红黑树优化)的...
HashMap是Java编程语言中最常用的集合类之一,它属于`java.util`包,提供了一种以键值对形式存储数据的数据结构。HashMap的核心在于其高效的数据查找、插入和删除操作,这些都得益于哈希表(Hash Table)的实现方式...
HashMap的扩容通常发生在以下情况之一: - 当调用`put(K, V)`方法时,如果当前HashMap的大小(即键值对的数量)达到了预定的阈值(threshold),并且对应的桶(bucket)不是空桶时,将触发扩容操作。 - 阈值是由...
HashMap底层原理.md
HashMap是Java编程语言中最常用的集合类之一,它提供了一种基于键值对(key-value pair)的数据存储方式,允许我们快速查找、插入和删除元素。HashMap的底层原理主要依赖于哈希表,这是一种数据结构,它通过计算键的...
详细介绍了hashMap原理,值得一看,对于面试者有很大帮助
一线大厂BATJ面试题讲解-hashmap原理实现
总之,HashMap之所以成为Java中最常用的集合类框架之一,是因为其在性能和灵活性上的出色表现,它通过哈希表、链表和红黑树的结合,实现了快速的查找、插入和删除操作,同时提供了良好的空间利用率。对于Java初学者...
hashMap基本工作原理,图解分析,基础Map集合
在JDK 1.8之前,HashMap仅使用数组和链表结构,但在JDK 1.8及之后的版本中,当链表长度超过阈值时,链表会转换成红黑树结构,以减少查找时间复杂度。这一改变主要针对大量哈希冲突时的性能优化。 以下是HashMap中几...
HashMap和HashTable底层原理以及常见面试题 HashMap和HashTable是Java中两个常用的数据结构,都是基于哈希表实现的,但它们之间存在着一些关键的区别。本文将深入探讨HashMap和HashTable的底层原理,并总结常见的...
本文将深入探讨HashMap的内部机制,包括其构造、工作原理、哈希函数、冲突解决策略以及扩容机制。 首先,HashMap的基本结构是由数组(Entry[] table)和链表组成的。每个元素是一个内部类Entry,它包含了键值对...
hashMap基本工作原理,图解分析,基础Map集合
HashMap的重要特点是使用散列法来解决冲突问题,使用链表和数组结合的数据结构来实现快速的插入和删除操作。HashMap的应用非常广泛,例如在数据库中建立索引,并进行搜索,同时还用在各种解密算法中。
二、HashMap底层原理 HashMap的内部实现基于数组+链表/红黑树的结构。数组中的每个元素都是一个Entry对象,每个Entry包含键值对和指向下一个Entry的引用。当冲突较多导致链表过长时,会自动转换为红黑树,以保证查找...
HashMap是Java中广泛使用的数据结构之一,它在处理大量数据时能提供高效的操作性能。在Java 1.8中,HashMap的实现采用了数组+链表+红黑树的混合结构,以解决哈希冲突并优化查询效率。本文将深入解析HashMap的put方法...
hashmap实现原理.pdf
### HashMap的实现原理 #### 1. HashMap概述 HashMap 是 Java 集合框架中一个非常重要的类,它实现了 Map 接口,并提供了基于哈希表的存储方式。与其它 Map 实现不同的是,HashMap 允许使用 `null` 键和 `null` 值...