
I construct three internal tables with different table types:
The complete test source code could be found in the end part of the blog.
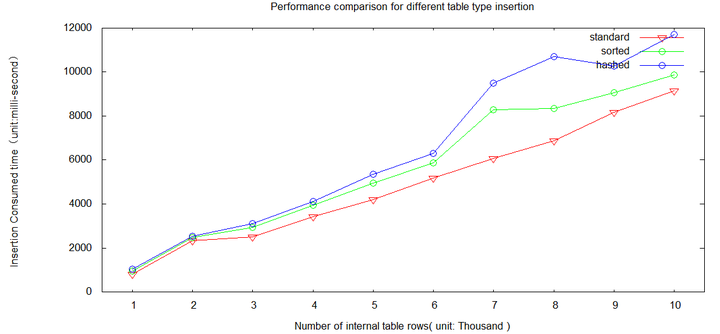
insert operation comparison
The hashed table is least efficient since additional overhead is paid to maintain the internal administrative information for hash logic. The standard table is fastest due to the fact that there is no overhead.
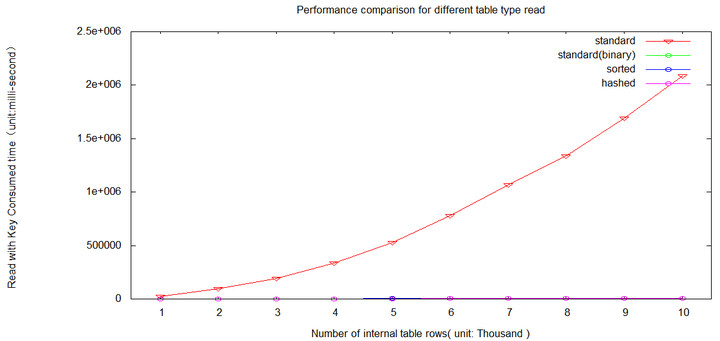
read operation comparison
The standard table read is slowest due to o(n) complexity.
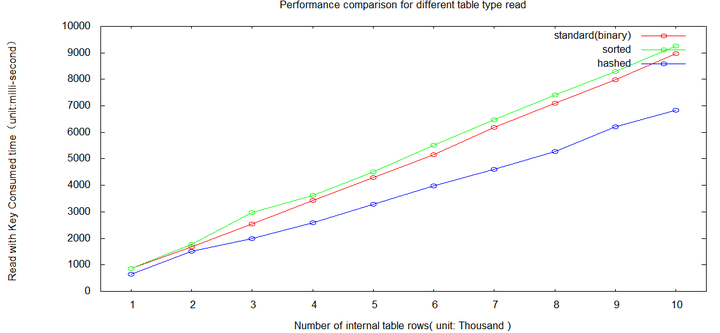
If we exclude the standard table read and compare the left three, it is clear the hashed table read is most efficient.
The complete test source code:
REPORT z.
PARAMETERS: count TYPE i OBLIGATORY DEFAULT 1000.
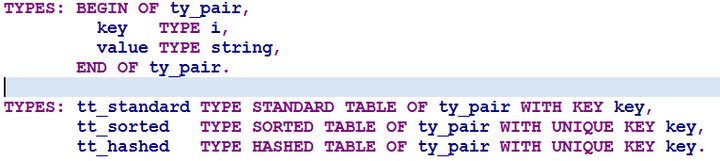
TYPES: BEGIN OF ty_pair,
key TYPE i,
value TYPE string,
END OF ty_pair.
TYPES: tt_standard TYPE STANDARD TABLE OF ty_pair WITH KEY key,
tt_sorted TYPE SORTED TABLE OF ty_pair WITH UNIQUE KEY key,
tt_hashed TYPE HASHED TABLE OF ty_pair WITH UNIQUE KEY key.
DATA: lv_start TYPE i,
lv_end TYPE i,
lt_standard TYPE tt_standard,
lt_sorted TYPE tt_sorted,
lt_hashed TYPE tt_hashed,
lv_size TYPE i.
START-OF-SELECTION.
lv_size = count.
PERFORM insert_standard.
PERFORM insert_sorted.
PERFORM insert_hashed.
PERFORM read_standard.
PERFORM read_standard_binary.
PERFORM read_sorted.
PERFORM read_hashed.
FORM insert_standard.
PERFORM start_timer.
DO lv_size TIMES.
DATA(line) = VALUE ty_pair( key = sy-index value = sy-index ).
APPEND line TO lt_standard.
ENDDO.
PERFORM stop_timer.
" WRITE: / 'standard table insertion: ' , lv_end.
ENDFORM.
FORM insert_sorted.
PERFORM start_timer.
DO lv_size TIMES.
DATA(line) = VALUE ty_pair( key = sy-index value = sy-index ).
INSERT line INTO TABLE lt_sorted.
ENDDO.
PERFORM stop_timer.
" WRITE: / 'sorted table insertion: ' , lv_end.
ENDFORM.
FORM insert_hashed.
PERFORM start_timer.
DO lv_size TIMES.
DATA(line) = VALUE ty_pair( key = sy-index value = sy-index ).
INSERT line INTO TABLE lt_hashed.
ENDDO.
PERFORM stop_timer.
" WRITE: / 'hashed table insertion: ' , lv_end.
ENDFORM.
FORM read_standard.
PERFORM start_timer.
DO lv_size TIMES.
READ TABLE lt_standard ASSIGNING FIELD-SYMBOL(<standard>) WITH KEY key = sy-index.
ASSERT sy-subrc = 0.
ENDDO.
PERFORM stop_timer.
WRITE:/ 'standard table read: ', lv_end.
ENDFORM.
FORM read_standard_binary.
SORT lt_standard BY key.
PERFORM start_timer.
DO lv_size TIMES.
READ TABLE lt_standard ASSIGNING FIELD-SYMBOL(<standard>) WITH KEY key = sy-index BINARY SEARCH.
ASSERT sy-subrc = 0.
ENDDO.
PERFORM stop_timer.
WRITE:/ 'standard table binary read: ', lv_end.
ENDFORM.
FORM read_sorted.
PERFORM start_timer.
DO lv_size TIMES.
READ TABLE lt_sorted ASSIGNING FIELD-SYMBOL(<sorted>) WITH KEY key = sy-index.
ASSERT sy-subrc = 0.
ENDDO.
PERFORM stop_timer.
WRITE:/ 'sorted table read: ', lv_end.
ENDFORM.
FORM read_hashed.
PERFORM start_timer.
DO lv_size TIMES.
READ TABLE lt_hashed ASSIGNING FIELD-SYMBOL(<sorted>) WITH TABLE KEY key = sy-index.
ASSERT sy-subrc = 0.
ENDDO.
PERFORM stop_timer.
WRITE:/ 'hashed table read: ', lv_end.
ENDFORM.
FORM start_timer.
CLEAR: lv_start, lv_end.
GET RUN TIME FIELD lv_start.
ENDFORM.
FORM stop_timer.
GET RUN TIME FIELD lv_end.
lv_end = lv_end - lv_start.
ENDFORM.要获取更多Jerry的原创文章,请关注公众号"汪子熙":




相关推荐
2. 数据类型:ABAP支持多种数据类型,如字符(CHAR)、数值(INT)、浮点数(FLOAT)等,还有更复杂的结构类型如表(TABLES)和结构(STRUCTURE)。 二、ABAP语句和控制结构 1. SELECT语句:用于从数据库中检索数据...
内表是ABAP中用于存储数据的一种结构化方式,新版ABAP对内表进行了改进,主要体现在以下几个方面: - **增强的数据处理能力**:通过内表可以更方便地进行数据排序、筛选等操作。 - **更灵活的索引机制**:提供了更...
ABAP支持INNER JOIN、LEFT JOIN、RIGHT JOIN等多种类型,用于合并不同表格中的数据。 3. **OPEN DATASET和CLOSE DATASET**:这是处理内部表和物理表之间交互的常用命令,用于打开和关闭数据集,进行读写操作。 4. ...
- ABAP内表的处理也得到了增强,可能包括更快的访问速度、更方便的遍历和更高效的内存管理,但具体细节未在提供的内容中详细说明。 3. **基于类的异常处理** - 异常处理从传统的结构化方式转向了面向对象的异常...
1. **数据声明与类型**:ABAP提供了多种数据类型,如CHAR、NUMC、INT、DEC、STRING等,以及结构化类型如TABLES和REF TO。数据声明通常包括变量、常量、内部表的定义,它们是程序处理数据的基本元素。 2. **控制结构...
- 内表是ABAP中一种重要的数据结构,用于存储一系列相似的数据项。工作区则是内表的一个临时副本,用于数据处理前的准备和预览。 7. **模块化程序** - 模块化编程是ABAP中的一个关键概念,它鼓励将大型程序分解为...
- **数据库访问**: 内置OpenSQL子集,实现跨数据库系统的表数据读写。 - **内部表管理**: 允许定义仅存在于程序运行周期内的表结构,简化复杂数据结构处理。 - **子程序定义与调用**: 支持自定义子程序及函数模块的...
- 表达式与运算符:ABAP支持算术、比较和逻辑运算符,用于进行计算和条件判断。 - 语句结构:包括IF...ENDIF、CASE...ENDCASE等控制流程语句,以及LOOP...ENDLOOP循环结构。 2. **数据类型** - ABAP提供了多种...
- **字段符号**: 字段符号是 ABAP 中的一种特殊类型,用于引用数据表中的字段。通过字段符号可以实现对内表中特定字段的操作,提高程序的灵活性。 **4. 模块化程序** - **模块**: ABAP 支持模块化编程,通过将...
通过`CL_ABAP_STRUCTDESCR`和`CL_ABAP_TABLEDESCR`类可以创建动态内表。 2. **内表操作** - 获取内表的行指针后,你可以通过字段符号访问特定字段并读写其值。例如,使用`read table`语句读取指定索引的行,并通过...
- **锁类型:** 介绍了不同类型锁(如共享锁、排他锁)的特点和应用场景。 - **死锁预防:** 讨论了如何预防和解决死锁问题,以确保事务处理的顺利进行。 #### 十一、SQL语句优化 第十一章聚焦于SQL语句的优化,这...
智能数据集成利用虚拟化技术,提高了读写ABAP系统的能力,动态分层则允许企业管理和存储超大规模的数据,确保系统的稳定性和性能。 系统双活是下一代数据仓库的另一个重要特性,它可以实现主备系统的实时同步,备机...
除了基本的读写操作,SAP Connector还支持事务处理、错误处理、性能优化等功能。例如,通过`NTransaction`类可以进行多步骤操作的事务管理,确保数据的一致性。同时,可以通过调整连接池大小和超时设置来优化性能。 ...