

简单说就是可以给ES集群中的节点分配不同角色,每种角色干的活都不一样。
Master
主要负责集群中索引的创建、删除以及数据的Rebalance等操作。Master不负责数据的索引和检索,所以负载较轻。当Master节点失联或者挂掉的时候,ES集群会自动从其他Master节点选举出一个Leader。为了防止脑裂,常常设置参数为discovery.zen.minimum_master_nodes=N/2+1,其中N为集群中Master节点的个数。建议集群中Master节点的个数为奇数个,如3个或者5个。
设置一个几点为Master节点的方式如下:
node.master: true
node.data: false
node.ingest: false
search.remote.connect: false
Data Node
主要负责集群中数据的索引和检索,一般压力比较大。建议和Master节点分开,避免因为Data Node节点出问题影响到Master节点。
设置一个几点为Data Node节点的方式如下:
node.master: false
node.data: true
node.ingest: false
search.remote.connect: false
Coordinating Node
对于协调节点,个人觉得官网说的很清楚,很简练。


Ingest Node
Ingest node专门对索引的文档做预处理,实际中不常用,除非文档在索引之前有大量的预处理工作需要做。Ingest node设置如下:
node.master: false node.master: false node.master: false
node.data: false
node.ingest: true
search.remote.connect: false
Tribe Node
Tribe Node主要用于跨级群透明访问。但是官方已经不建议使用了,在5.4.0版本以后已经废弃掉了,在7.0的版本中将移除该功能。在5.5版本以后建议使用Cross-cluster search替代Tribe Node。
总结:
小集群可以不考虑结群节点的角色划分,大规模ES集群建议将Master Node、Data Node和Coordinating Node独立出来,每个节点各司其职。
在生产环境下,如果不修改elasticsearch节点的角色信息,在高数据量,高并发的场景下集群容易出现脑裂等问题。
默认情况下,elasticsearch集群中每个节点都有成为主节点的资格,也都存储数据,即双重角色。
由两个属性控制:node.master和node.data,默认情况下这两个属性的值都是true:
* node.master:表示节点是否具有成为主节点的资格,值为true并不意味着这个节点就是主节点,真正的主节点是由多个具有主节点资格的节点进行选举产生的。
* node.data:表示节点是否存储数据。
这两个属性可以有四种组合:
* 第一种,这种组合表示这个节点即有成为主节点的资格,又存储数据,
这个时候如果某个节点被选举成为了真正的主节点,那么他还要存储数据,这样对于这个节点的压力就比较大了。elasticsearch默认每个节点都是这样的配置,在测试环境下这样做没问题。实际工作中建议不要这样设置,这样相当于主节点和数据节点的角色混合到一块了。
node.master: true
node.data: true
* 第二种:这种组合表示这个节点没有成为主节点的资格,也就不参与选举,只会存储数据。这个节点我们称为data(数据)节点。在集群中需要单独设置几个这样的节点负责存储数据。后期提供存储和查询服务。
node.master: false
node.data: true
第三种:这种组合表示这个节点不会存储数据,有成为主节点的资格,可以参与选举,有可能成为真正的主节点。这个节点我们称为master节点
node.master: true
node.data: false
第四种:这种组合表示这个节点即不会成为主节点,也不会存储数据,
这个节点的意义是作为一个client(客户端)节点,主要是针对海量请求的时候可以进行负载均衡。
node.master: false
node.data: false
默认情况下,每个节点都有成为主节点的资格,也会存储数据,还会处理客户端的请求。
在一个生产集群中我们可以对这些节点的职责进行划分。
建议集群中设置3台以上的节点作为master节点,这些节点只负责成为主节点,维护整个集群的状态。
再根据数据量设置一批data节点,这些节点只负责存储数据,后期提供建立索引和查询索引的服务,这样的话如果用户请求比较频繁,这些节点的压力也会比较大。
所以在集群中建议再设置一批client节点
这些节点只负责处理用户请求,实现请求转发,负载均衡等功能。
master节点:普通服务器即可(CPU 内存 消耗一般)
data节点:主要消耗磁盘,内存
client节点:普通服务器即可(如果要进行分组聚合操作的话,建议这个节点内存也分配多一点)
原文链接:https://blog.csdn.net/psc0606/article/details/80247662
1、问题引出
ES5.X节点类型多了ingest节点类型。
针对3个节点、5个节点或更多节点的集群,如何配置节点角色才能使得系统性能最优呢?
2、ES2.X及之前版本节点角色概述

3、ES5.X节点角色清单

由于其他几种类型节点和用途都很好理解,无非主节点、数据节点、路由节点。
Ingest的用途:
1)Ingest节点和集群中的其他节点一样,但是它能够创建多个处理器管道,用以修改传入文档。类似 最常用的Logstash过滤器已被实现为处理器。
2)Ingest节点 可用于执行常见的数据转换和丰富。 处理器配置为形成管道。 在写入时,Ingest Node有20个内置处理器,例如grok,date,gsub,小写/大写,删除和重命名。
3)在批量请求或索引操作之前,Ingest节点拦截请求,并对文档进行处理。
这样的处理器的一个例子可以是日期处理器,其用于解析字段中的日期。
另一个例子是转换处理器,它将字段值转换为目标类型,例如将字符串转换为整数。
4、ES5.X节点组合类型有多种类型,如何抉择?
Elasticsearch的员工 Christian_Dahlqvist解读如下:
一个节点的缺省配置是:主节点+数据节点两属性为一身。对于3-5个节点的小集群来讲,通常让所有节点存储数据和具有获得主节点的资格。你可以将任何请求发送给任何节点,并且由于所有节点都具有集群状态的副本,它们知道如何路由请求。
通常只有较大的集群才能开始分离专用主节点、数据节点。 对于许多用户场景,路由节点根本不一定是必需的。
专用协调节点(也称为client节点或路由节点)从数据节点中消除了聚合/查询的请求解析和最终阶段,并允许他们专注于处理数据。
在多大程度上这对集群有好处将因情况而异。 通常我会说,在查询大量使用情况下路由节点更常见。
5、ES5.X集群中如何设置节点角色
对于3个节点、5个节点甚至更多节点角色的配置,Elasticsearch官网、国内外论坛、博客都没有明确的定义。
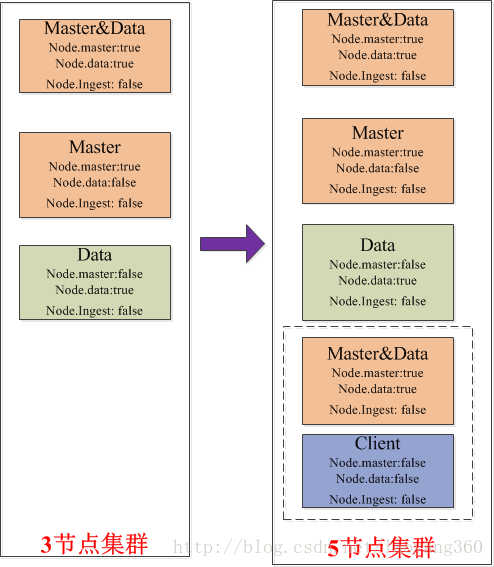
我的思考如下:
1)对于Ingest节点,如果我们没有格式转换、类型转换等需求,直接设置为false。
2)3-5个节点属于轻量级集群,要保证主节点个数满足((节点数/2)+1)。
3)轻量级集群,节点的多重属性如:Master&Data设置为同一个节点可以理解的。
4)如果进一步优化,5节点可以将Master和Data再分离。
6、小结
1)Elasticsearch博大精深,尤其新的5.X特性比较多,需要进一步深入研究;
2)集群的配置还有赖于进一步事件总结,再好的理论部署实践都是“花瓶”;
3)貌似图示划分了这么细、写了那么多,以官网为基准,也顺带调研了N多文档,但对Ingest节点的作用依然理解的不够深。希望大家评论探讨下。
原文链接:https://blog.csdn.net/laoyang360/article/details/78290484



相关推荐
白色大气风格的旅游酒店企业网站模板.zip
python实现用户注册
Matlab领域上传的视频均有对应的完整代码,皆可运行,亲测可用,适合小白; 1、代码压缩包内容 主函数:main.m; 调用函数:其他m文件;无需运行 运行结果效果图; 2、代码运行版本 Matlab 2019b;若运行有误,根据提示修改;若不会,私信博主; 3、运行操作步骤 步骤一:将所有文件放到Matlab的当前文件夹中; 步骤二:双击打开main.m文件; 步骤三:点击运行,等程序运行完得到结果; 4、仿真咨询 如需其他服务,可私信博主; 4.1 博客或资源的完整代码提供 4.2 期刊或参考文献复现 4.3 Matlab程序定制 4.4 科研合作
内容来源于网络分享,如有侵权请联系我删除。另外如果没有积分的同学需要下载,请私信我。
1、资源项目源码均已通过严格测试验证,保证能够正常运行; 2、项目问题、技术讨论,可以给博主私信或留言,博主看到后会第一时间与您进行沟通; 3、本项目比较适合计算机领域相关的毕业设计课题、课程作业等使用,尤其对于计算机科学与技术等相关专业,更为适合;
内容概要:文档名为《平方表,派表集合.docx》,主要内容是1至1000的平方值以及1至1000与π的乘积结果。每个数字从1开始,逐步增加至1000,对应地计算了平方值和乘以π后的值。所有计算均通过Python脚本完成,并在文档中列出了详细的计算结果。 适合人群:需要进行数学计算或程序验证的学生、教师和研究人员。 使用场景及目标:用于快速查找特定数字的平方值或其与π的乘积,适用于教学、科研及程序测试等场景。 阅读建议:可以直接查阅所需的具体数值,无需从头到尾逐行阅读。建议在使用时配合相应的计算工具,以验证和拓展数据的应用范围。
1、资源项目源码均已通过严格测试验证,保证能够正常运行; 2、项目问题、技术讨论,可以给博主私信或留言,博主看到后会第一时间与您进行沟通; 3、本项目比较适合计算机领域相关的毕业设计课题、课程作业等使用,尤其对于计算机科学与技术等相关专业,更为适合;
白色大气风格的健身私人教练模板下载.zip
白色简洁风的商务网站模板下载.zip
白色大气风格的前端设计案例展示模板.zip
内容概要:本文介绍了两个有趣的圣诞树项目方向:一是使用Arduino或Raspberry Pi开发可编程的圣诞树灯光控制系统;二是基于MATLAB开发一个圣诞树模拟器。前者通过硬件连接、编写Arduino/Raspberry Pi程序、MATLAB控制程序来实现LED灯带的闪烁;后者则通过创建圣诞树图形、添加动画效果、用户交互功能来实现虚拟的圣诞树效果。 适合人群:具备基本电子工程和编程基础的爱好者和学生。 使用场景及目标:①通过硬件和MATLAB的结合,实现实际的圣诞树灯光控制系统;②通过MATLAB模拟器,实现一个有趣的圣诞树动画展示。 阅读建议:读者可以根据自己的兴趣选择合适的项目方向,并按照步骤进行动手实践,加深对硬件编程和MATLAB编程的理解。
白色扁平风格的温室大棚公司企业网站源码下载.zip
Navicat.zip
内容概要:本文详细介绍了主成分分析(PCA)技术的原理及其在Scikit-learn库中的Python实现。首先讲解了PCA的基本概念和作用,接着通过具体示例展示了如何使用Scikit-learn进行PCA降维。内容涵盖了数据准备、模型训练、数据降维、逆转换数据等步骤,并通过可视化和实际应用案例展示了PCA的效果。最后讨论了PCA的局限性和参数调整方法。 适合人群:数据科学家、机器学习工程师、数据分析从业者及科研人员。 使用场景及目标:适用于高维数据处理,特别是在需要降维以简化数据结构、提高模型性能的场景中。具体目标包括减少计算复杂度、提高数据可视化效果和改进模型训练速度。 其他说明:本文不仅提供了详细的代码示例,还讨论了PCA在手写数字识别和机器学习模型中的应用。通过比较原始数据和降维后数据的模型性能,读者可以更好地理解PCA的影响。
VOC格式的数据集转COCO格式数据集 VOC格式的数据集转YOLO格式数据集。内容来源于网络分享,如有侵权请联系我删除。另外如果没有积分的同学需要下载,请私信我。
数字信号处理课程设计.doc
白色扁平化风格的灯饰灯具销售企业网站模板.zip
华豫佰佳组合促销视图.sql
白色大气风格的商务团队公司模板下载.zip
白色大气风格的VPS销售网站模板.zip