
HBase上Regionserver的内存分为两个部分,一部分作为Memstore,主要用来写;另外一部分作为BlockCache,主要用于读数据;上面一篇文章已经介绍过Memstore,这里主要介绍读取数据的部分,即BlockCache。
BlockCache主要提供给读使用。读请求先到memstore中查数据,查不到就到blockcache中查,再查不到就会到磁盘上读,并把读的结果放入blockcache。由于blockcache是一个LRU,因此blockcache达到上限(heapsize * hfile.block.cache.size)后,会启动淘汰机制,淘汰掉最老的一批数据。
1.服务器端配置
一个regionserver上有一个blockcache和N个memstore,它们的大小之和必须小于heapsize* 0.8,否则hbase不能启动,因为仍然要留有一些内存保证其它任务的执行。即为
(1)hbase.regionserver.global.memstore.upperLimit默认值:0.4
(2)hfile.block.cache.size 默认值0.2
这两个值默认和为RegionServer的堆内存的60%,上面值在hbase-memstore刷写已经介绍过。一般情况下可具体看读写情况,对于注重读响应时间的系统,应该将blockcache设大些,比如设置blockcache=0.4,memstore=0.39,这会加大缓存命中率。
2.客户端读取数据配置
(1)hbase.client.scanner.caching 默认值:1
hbase.client.scanner.caching配置项可以设置HBase scanner一次从服务端抓取的数据条数,默认情况下一次一条。通过将其设置成一个合理的值,可以减少scan过程中next()的时间开销,代价是 scanner需要通过客户端的内存来维持这些被cache的行记录。
有三个地方可以进行配置:1)在HBase的conf配置文件中进行配置;2)通过调用HTable.setScannerCaching(intscannerCaching)进行配置;3)通过调用Scan.setCaching(intcaching)进行配置。三者的优先级越来越高。
少的RPC是提高hbase执行效率的一种方法,理论上一次性获取越多数据就会越少的RPC,也就越高效。但是内存是最大的障碍。设置这个值的时候要选择合适的大小,一面一次性获取过多数据占用过多内存,造成其他程序使用内存过少。或者造成程序超时等错误(这个超时与hbase.regionserver.lease.period相关)。
(2)hbase.regionserver.lease.period默认值:60000
说明:客户端租用HRegion server 期限,即超时阀值。
调优:这个配合hbase.client.scanner.caching使用,如果内存够大,但是取出较多数据后计算过程较长,可能超过这个阈值,适当可设置较长的响应时间以防被认为宕机。
本文参考(http://blog.csdn.net/huoyunshen88/article/details/9169077 https://blog.csdn.net/u014297175/article/details/47976909)
--------------------------------------------------------------------------------------------------------------
HBase上RegionServer的cache主要分为两个部分,分别是memstore&blockcache,其中memstore主要用于写缓存,而blockcache用于读缓存。
当数据写入hbase时,会先写入memstore,RegionServer会给每个region提供一个memstore,memstore中的数据达到系统设置的水位值后,会触发flush将memstore中的数据刷写到磁盘。
客户的读请求会先到memstore中查数据,若查不到就到blockcache中查,再查不到就会从磁盘上读,并把读入的数据同时放入blockcahce。我们知道缓存有三种不同的更新策略,分别是先入先出(FIFO)、LRU(最近最少使用)和LFU(最近最不常使用),hbase的block使用的是LRU策略,当BlockCache的大小达到上限后,会触发缓存淘汰机制,将最老的一批数据淘汰掉。
一个RegionServer上有一个BlockCache和N个Memstore。下面我们从hbase的源码中展开阐述Blockcache的具体实现,并在讲解实现的中间补充阐述关于缓存的相关机制介绍。
BlockCache在HBase中所处的位置如下图中所示:
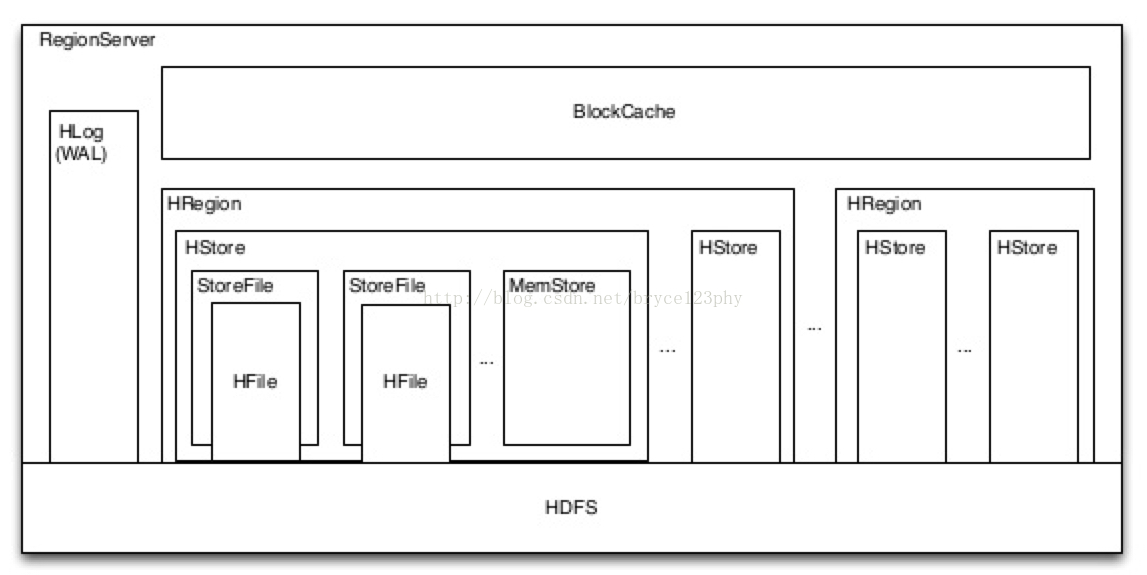
BlockCache的实现是基于On-heap ConcurrentHashMap。map的key是BlockCacheKey类型的对象,包括了offset、hfileName等成员变量,map的value是LruCachedBlock类型的对象,表示缓存的实体,该对象中定义了成员变量accesstime,用于LRU淘汰时的比较依据。BlockCache的大小是固定的,由参数hfile.block.cache.size决定,默认是RegionServer的堆内存的40%。
BlockCache的初始化在HRegionServer的handleReportForDutyResponse里完成,HRegionServer有一个HeapMemoryManager类型的成员变量,用于管理RegionServer进程的堆内存,HeapMemoryManager中的blockCache就是RegionServer中的读缓存,它的初始化在CacheConfig的instantiateBlockCache方法中完成,剪掉一些判断BlockCache是否禁用的代码,我们列出其中的主要逻辑如下:
public static synchronized BlockCache instantiateBlockCache(Configuration conf) {
MemoryUsage mu = ManagementFactory.getMemoryMXBean().getHeapMemoryUsage();
LruBlockCache l1 = getL1(conf, mu);
BlockCache l2 = getL2(conf, mu);
if (l2 == null) {
GLOBAL_BLOCK_CACHE_INSTANCE = l1;
} else {
boolean useExternal = conf.getBoolean(EXTERNAL_BLOCKCACHE_KEY, EXTERNAL_BLOCKCACHE_DEFAULT);
boolean combinedWithLru = conf.getBoolean(BUCKET_CACHE_COMBINED_KEY,
DEFAULT_BUCKET_CACHE_COMBINED);
if (useExternal) {
GLOBAL_BLOCK_CACHE_INSTANCE = new InclusiveCombinedBlockCache(l1, l2);
} else {
if (combinedWithLru) {
GLOBAL_BLOCK_CACHE_INSTANCE = new CombinedBlockCache(l1, l2);
} else {
GLOBAL_BLOCK_CACHE_INSTANCE = l1;
}
}
l1.setVictimCache(l2);
}
return GLOBAL_BLOCK_CACHE_INSTANCE;
}
其中的GLOBAL_BLOCK_CACHE_INSTANCE是CacheConfig中维护的静态BlockCache实例,也就是我们要返回给RegionServer的读缓存。注意代码中对useExternal和combinedWithLru的判断,如果指定了useExternal为true,则结合memcached等外部缓存与BlockCache一起使用。如果指定了combinedWithLru,则结合bucketCache,也就是堆外内存与BlockCache一起使用。在上述两种情况下,BlockCache用于存放索引等元数据,真实的数据文件则缓存在memcached或bucketCache中。
如果想使用上述两种特性,可以分别将"hbase.block.use.external"或"hbase.bucketcache.combinedcache.enabled"设置为true。其中,外部缓存对象经hbase.blockcache.external.class由反射方法注入,关于hbase中外部缓存的使用可以参看HBase的issue13170,里面有详细的介绍。
BlockCache基于客户端对数据的访问频率,定义了三个不同的优先级,如下所示:
SINGLE:如果一个Block被第一次访问,则该Block被放在这一优先级队列中;
MULTI:如果一个Block被多次访问,则从single移到Multi中;
MEMORY:memory优先级由用户指定,一般不推荐,只用系统表才使用memory优先级;
以上将cache分级的好处在于:
首先,通过Memory类型的cache,可以将重要的数据放到RegionServer内存中常驻,例如Meta或者namespace的元数据信息;
其次,通过区分single和multi类型cache,可以防止由于scan操作带来的cache频繁颠簸,将最少使用的block加入到淘汰算法中;
默认配置下,对于整个blockcache的内存,按照以下百分比分配给single、multi和inMemory使用:0.25、0.5和0.25;
下面我们分析将Block块加入缓存的实现,主要代码如下所示:
public void cacheBlock(BlockCacheKey cacheKey, Cacheable buf, boolean inMemory,
final boolean cacheDataInL1) {
//首先判断cacheKey是否已被缓存,省略
LruCachedBlock cb = new LruCachedBlock(cacheKey, buf, count.incrementAndGet(), inMemory); //创建BlockCache中的实体
long newSize = updateSizeMetrics(cb, false); //更新metrics
map.put(cacheKey, cb);
if (newSize > acceptableSize() && !evictionInProgress) { //如果cache达到大小限制,执行evict逻辑
runEviction();
}
}
1、首先假设不会对同一个已经被缓存的BlockCacheKey重复放入cache操作;
2、根据是否inmemory创建不同类别的CachedBlock对象:若inMemory为true则创建BlockPriority.MEMORY类型,否则创建BlockPriority.SINGLE类型;
3、将BlockCacheKey和创建的CachedBlock对象加入到前文说过的ConcurrentHashMap中,同时更新log&metrics上的计数;
4、最后判断如果加入新block后cache size大于设定的临界值且当前没有淘汰线程运行,则调用runEviction()方法启动LRU淘汰线程,runEviciton方法如下:
private void runEviction() {
if (evictionThread == null) {
evict();
} else {
evictionThread.evict();
}
}
其中淘汰线程evictionThread在LruBlockCache初始化的同时创建,并且指定为守护daemon线程;
evictionThread用于与主线程同步完成block cache的淘汰过程,该过程的主要逻辑在run方法中:
public void run() {
enteringRun = true;
while (this.go) {
synchronized(this) {
try {
this.wait(1000 * 10/*Don't wait for ever*/);
} catch(InterruptedException e) {
LOG.warn("Interrupted eviction thread ", e);
Thread.currentThread().interrupt();
}
}
LruBlockCache cache = this.cache.get();
if (cache == null) break;
cache.evict();
}
}
evictionThread线程启动后,调用wait被阻塞住,直到EvictionThread线程的evict方法被runEviction调用后,evict中执行notifyAll唤醒被阻塞住的evictionThread主线程,主线程继续执行LruBlockCache的evict方法进行真正的淘汰过程。evict方法的主流程如下所示:
void evict() {
if(!evictionLock.tryLock()) return;
try {
evictionInProgress = true;
long currentSize = this.size.get();
long bytesToFree = currentSize - minSize();
if(bytesToFree <= 0) return;
BlockBucket bucketSingle = new BlockBucket("single", bytesToFree, blockSize, singleSize());
BlockBucket bucketMulti = new BlockBucket("multi", bytesToFree, blockSize, multiSize());
BlockBucket bucketMemory = new BlockBucket("memory", bytesToFree, blockSize, memorySize());
for(LruCachedBlock cachedBlock : map.values()) {
switch(cachedBlock.getPriority()) {
case SINGLE: {
bucketSingle.add(cachedBlock);
break;
}
case MULTI: {
bucketMulti.add(cachedBlock);
break;
}
case MEMORY: {
bucketMemory.add(cachedBlock);
break;
}
}
}
long bytesFreed = 0;
if (forceInMemory || memoryFactor > 0.999f) {
long s = bucketSingle.totalSize();
long m = bucketMulti.totalSize();
if (bytesToFree > (s + m)) {
bytesFreed = bucketSingle.free(s);
bytesFreed += bucketMulti.free(m);
bytesFreed += bucketMemory.free(bytesToFree - bytesFreed);
} else {
long bytesRemain = s + m - bytesToFree;
if (3 * s <= bytesRemain) {
bytesFreed = bucketMulti.free(bytesToFree);
} else if (3 * m <= 2 * bytesRemain) {
bytesFreed = bucketSingle.free(bytesToFree);
} else {
bytesFreed = bucketSingle.free(s - bytesRemain / 3);
if (bytesFreed < bytesToFree) {
bytesFreed += bucketMulti.free(bytesToFree - bytesFreed);
}
}
}
} else {
PriorityQueue<BlockBucket> bucketQueue =
new PriorityQueue<BlockBucket>(3);
bucketQueue.add(bucketSingle);
bucketQueue.add(bucketMulti);
bucketQueue.add(bucketMemory);
int remainingBuckets = 3;
BlockBucket bucket;
while((bucket = bucketQueue.poll()) != null) {
long overflow = bucket.overflow();
if(overflow > 0) {
long bucketBytesToFree = Math.min(overflow,
(bytesToFree - bytesFreed) / remainingBuckets);
bytesFreed += bucket.free(bucketBytesToFree);
}
remainingBuckets--;
}
}
} finally {
stats.evict();
evictionInProgress = false;
evictionLock.unlock();
}
}
下面我们跟着代码详解evict中每一步的实现及含义:
1、首先获取锁,保证同一时刻只有一个淘汰线程正在运行;
2、计算得到当前block cache总大小currentSize以及需要被淘汰释放掉的大小bytesToFree,如果bytesToFree小于等于0则不进行后续操作;
3、初始化创建三个BlockBucket对象,对象中包含了一个元素为LruCachedBlock的MinMaxPriorityQueue队列,分别用于三种优先级的cahceBlock对象,队列按LRU(最近最少使用)的原则维护BlockBucket中缓存住的所有对象;
4、遍历全局ConcurrentHashMap中的所有BlockCache,依类型加入到相应的BlockBucket队列中;
5、如果指定了放入最高优先级memory,则根据single、multi和bytesFreed三者之间的关系计算在各个队列中需要释放的空间,此种情况不推荐,因此不再细述;
6、将以上三个BlockBucket队列加入到一个优先级队列bucketQueue中,队列按照各个BlockBucket超出指定bucketSize的大小(overflow)顺序排序;
7、遍历优先级队列,对于每个BlockBucket,通过Math.min(overflow,(bytesToFree - bytesFreed)/remainingBuckets)计算出需要释放的空间大小,这样做可以保证尽可能平均地从三个BlockBucket释放LruCachedBlock。释放过程在BlockBucket的free方法;
8、具体到free方法,它每次从BlockBucket维护的队尾取出一个LruCachedBlock对象并调用evictBlock方法,evictBlock将LruCachedBlock从全局的concurrentHashMap中移除,同时更新相关计数;
9、如果有bucketCache或者memcached等其它辅助缓存,第八步总淘汰掉的CacheBlock会进入辅助缓存;
前面讲过一个LruCachedBlock如果被多次连续访问,那么它会从SINGLE优先级升级到MULTI优先级,这部分逻辑在getBlock中实现,getBlock接收用户传入的BlockCacheKey,并返回该Key制定的LruCachedBlock,如果目标LruCachedBlock在全局map中存在,那么会触发LruCachedBlock的access执行,将目标LruCachedBlock从SINGLE优先级调整为MULTI。
public void access(long accessTime) {
this.accessTime = accessTime;
if(this.priority == BlockPriority.SINGLE) {
this.priority = BlockPriority.MULTI;
}
}
参数accessTime指定了调用access的次数,每调用access一次,accessTime就自增1,这是由于LruCachedBlock在BlockBucket中是按照升序排列的。accessTime越大,则LruCachedBlock在队列中的位置越靠后,执行淘汰时,就越晚被淘汰。
需要注意的是在BlockCache中的数据是经过decompressed(解压缩)的,用户可将如下配置修改为true,当其为true时读入blockcache中的数据不会经过解压缩,如此可以增大单位blockcache中可缓存的数据条数,但是用户读取数据数据需要解压缩。
hbase.block.data.cachecompressed
上述配置的默认值是false。
from原文:https://blog.csdn.net/bryce123phy/article/details/62051927



相关推荐
HBase的Block Cache是 RegionServer 中的一块缓存区域,用于存储频繁访问的数据块。增大Block Cache的大小可以提高读取性能。默认情况下,HBase的Block Cache大小为0.0,可以根据实际情况调整这个值。例如,将Block ...
### HBase Bucket Cache:一种高效的缓存管理方案 #### 概述 HBase Bucket Cache 是一个针对 HBase 的块缓存实现,旨在解决 CMS(Concurrent Mark Sweep)垃圾收集器和堆内存碎片带来的性能问题,并提供更大的缓存...
HBase的BlockCache是一种用于提高读取性能的重要机制,它主要用于缓存HFile的Block数据,以减少磁盘I/O操作,从而加快读取速度。BlockCache分为两种类型:LruCache和BucketCache。 - **LruCache**:基于最近最少...
一个 RegionServer 上有一个 BlockCache 和 N 个 Memstore,它们的大小之和不能大于等于 heapsize * 0.8,否则 HBase 不能正常启动。 HBase RegionServer 中的 Block 优先级队列 HBase RegionServer 中有三个级别...
例如,`org.apache.hadoop.hbase.regionserver.HStore`类实现了MemStore和BlockCache,它们分别缓存内存中的新写入数据和硬盘上的热数据,提高读写效率。同时,HBase还支持Compaction操作,通过`org.apache.hadoop....
5. **BlockCache**:配置BlockCache大小,缓存最近访问的数据,提高读取速度。 ### 总结 HBase是大数据处理领域的重要工具,尤其适合实时查询和大规模数据存储。理解并掌握HBase的核心概念、安装配置、数据模型...
`hbase.blockcache.size`配置全局BlockCache的大小,它用于缓存数据块以提高读取性能。`hbase.hregion.memstore.block.multiplier`控制内存中memstore的大小,防止过多数据堆积导致RegionServer崩溃。 10. **性能...
11. **优化策略**:包括合理设置Region大小、预分区表、选择合适的Column Family、启用BlockCache等,以提升HBase的性能。 12. **安全配置**:在生产环境中,可能需要配置HBase与Kerberos进行集成,以实现身份验证...
create 'ImagesTable', 'Images', {NAME => 'ImageData', VERSIONS => 1, BLOCKCACHE => true, COMPRESSION => 'NONE', MOB_ENABLED => true, MOB_THRESHOLD => 1048576} ``` 3. 上传文件:使用HBase的Java API...
5. **文件系统和缓存设置**:`fs.defaultFS`设定默认的HDFS文件系统,`hbase.hregion.blockmultiplier`控制BlockCache的大小,`hbase.hregion.memstore.block.multiplier`则用于控制MemStore的大小。 6. **客户端...
- **BlockCache**和**MemStore**:缓存机制用于提高读写性能。 8. **扩展性**: HBase支持水平扩展,可以通过增加RegionServer来处理更多数据。 9. **监控与运维**: HBase提供丰富的监控指标,如JMX、Web UI等...
其次,Block Cache作为HBase中一个重要的性能优化工具,它类似于操作系统的页面缓存,能够对热点数据进行缓存,加速数据的读取速度。此外,合理的Row Key设计也十分关键,良好的Row Key设计可以减少查询的I/O操作,...
5. **性能优化**:分享在项目实践中遇到的问题及解决方案,如Region大小调整、Compaction策略、BlockCache的使用等,以提高Hbase的读写性能。 6. **案例分析**:通过实际项目案例,展示Hbase在互联网、物联网、日志...
- **缓存机制**:HBase利用内存缓存来加速读取操作,包括MemStore(内存中存储未刷新到磁盘的数据)和BlockCache(缓存经常访问的数据块)。 #### 四、HBase的应用场景 - **实时数据分析**:由于HBase提供了低延迟...
例如,它改进了BlockCache的管理,提高了缓存效率;增强了MemStore的压缩算法,降低了存储成本;同时,还优化了Region分裂过程,减少了对系统的影响。 2. **多版本支持**:HBase允许用户保留多个版本的数据,便于...
可以通过调整表分区策略、预分割表、使用合适的MemStore大小、开启BlockCache等手段提升性能。同时,了解HBase的Region Server、Zookeeper的角色和工作原理也对理解和优化HBase至关重要。 总的来说,理解并熟练运用...
- 可通过调整配置参数优化性能,如Region大小、BlockCache设置等。 在解压“hbase-1.3.1-bin.zip”后,你可以找到启动和配置HBase所需的所有文件,包括bin目录下的可执行脚本、conf目录中的配置文件、lib目录中的...
3. **实时查询**:HBase支持实时读写操作,通过内存缓存和BlockCache机制,提供了亚秒级的查询响应速度。 4. **稀疏性**:HBase可以存储大量的稀疏数据,即许多行或列可能存在大量缺失值,只存储有实际数据的位置,...
在HBase中,MemStore和BlockCache是两个关键的缓存机制。MemStore用于列族/Store级别的写入缓存,而BlockCache则服务于RegionServer级别的读取缓存。Rowkey长度的控制尤为重要,过长的Rowkey会导致缓存中数据密度...
10. **性能优化**:根据查询和操作的性能反馈,指导用户调整Hbase的配置参数,如Memstore大小、BlockCache设置等。 "**hbase-data-browser-v4.0-RC**"这个文件名可能是该管理器的一个特定版本,4.0代表主版本号,RC...