
摘要: 昨天,DataWorks推出了PYODPS任务类型,集成了Maxcompute的Python SDK,可在DataWorks的PYODPS节点上直接编辑Python代码操作Maxcompute,也可以设置调度任务来处理数据,提高数据开发效率。
昨天,DataWorks推出了PYODPS任务类型,集成了Maxcompute的Python SDK,可在DataWorks的PYODPS节点上直接编辑Python代码操作Maxcompute,也可以设置调度任务来处理数据,提高数据开发效率。
效果如下图
适用region
只有华东2(上海)region 支持了 PYODPS 节点。
注:底层的 Python 版本为 2.7 。
新建 PYODPS 节点
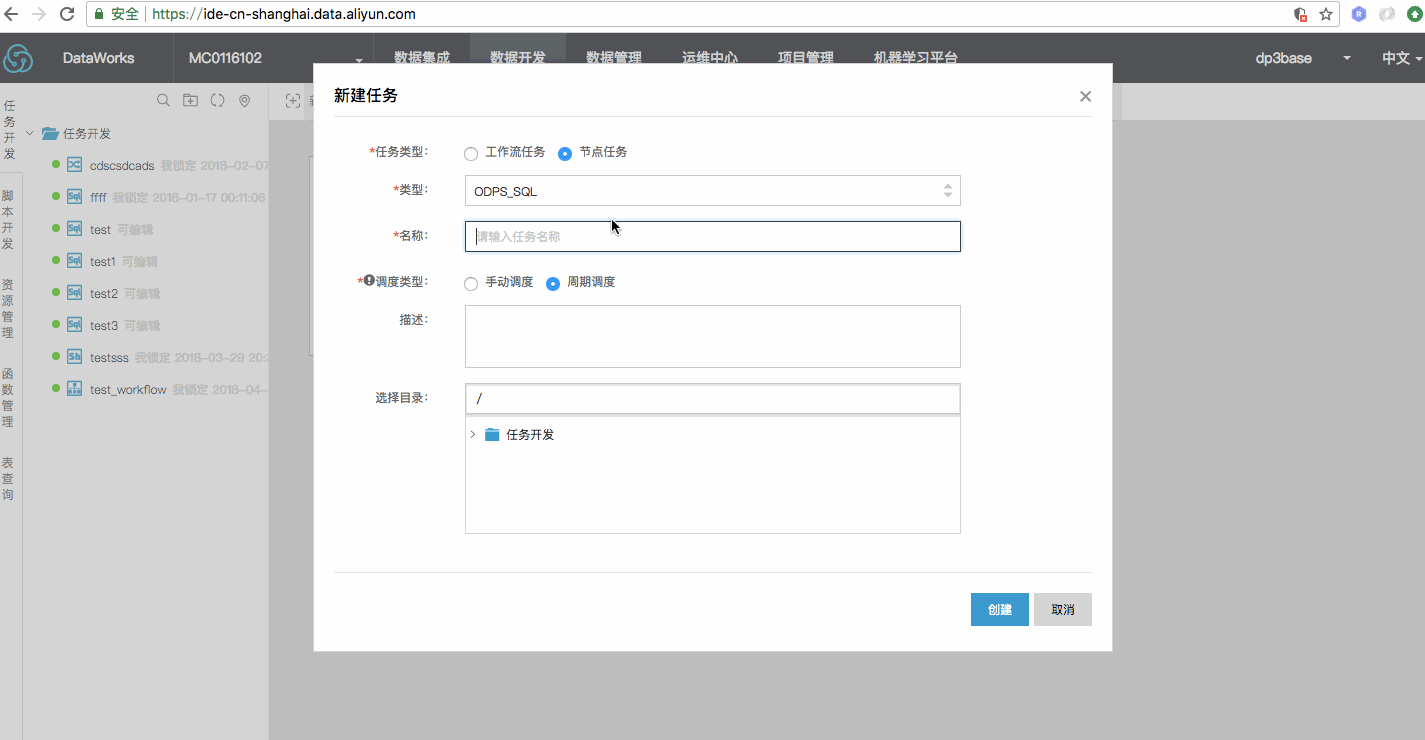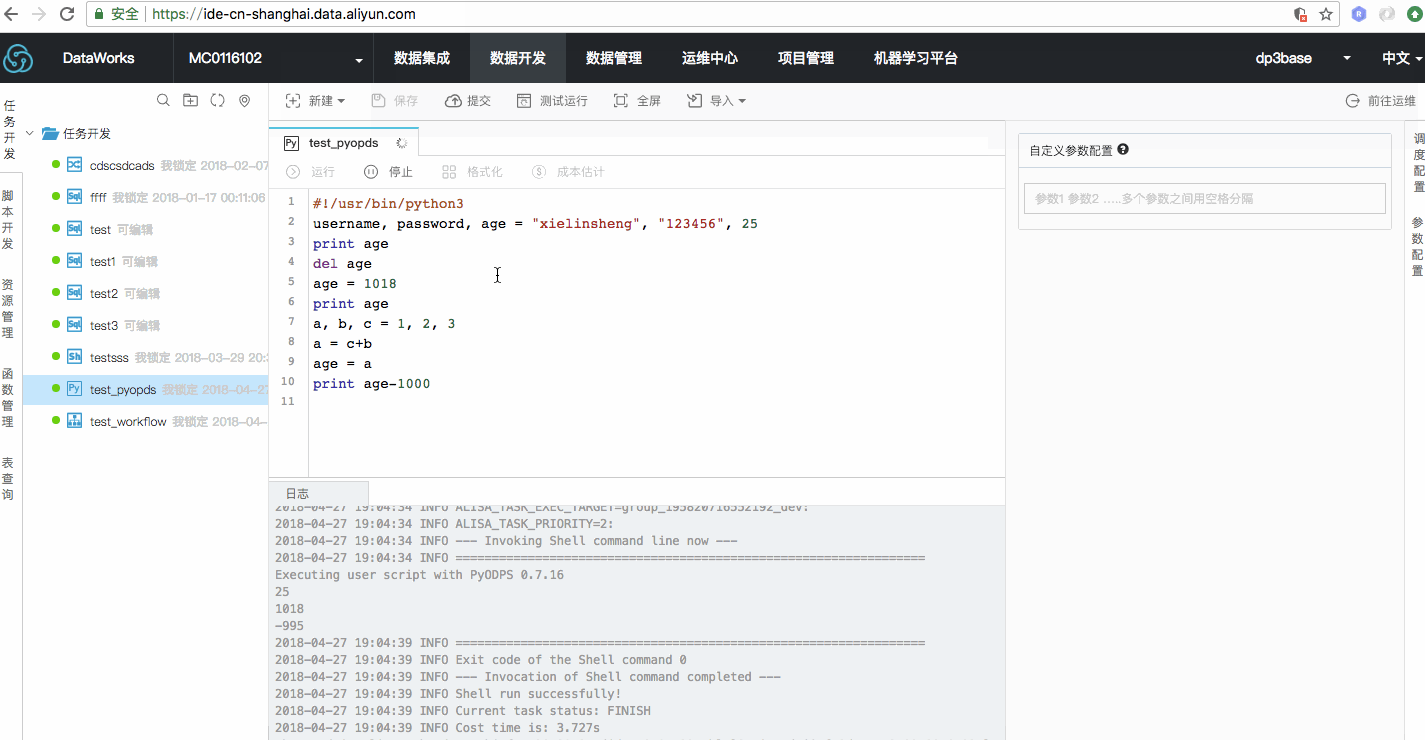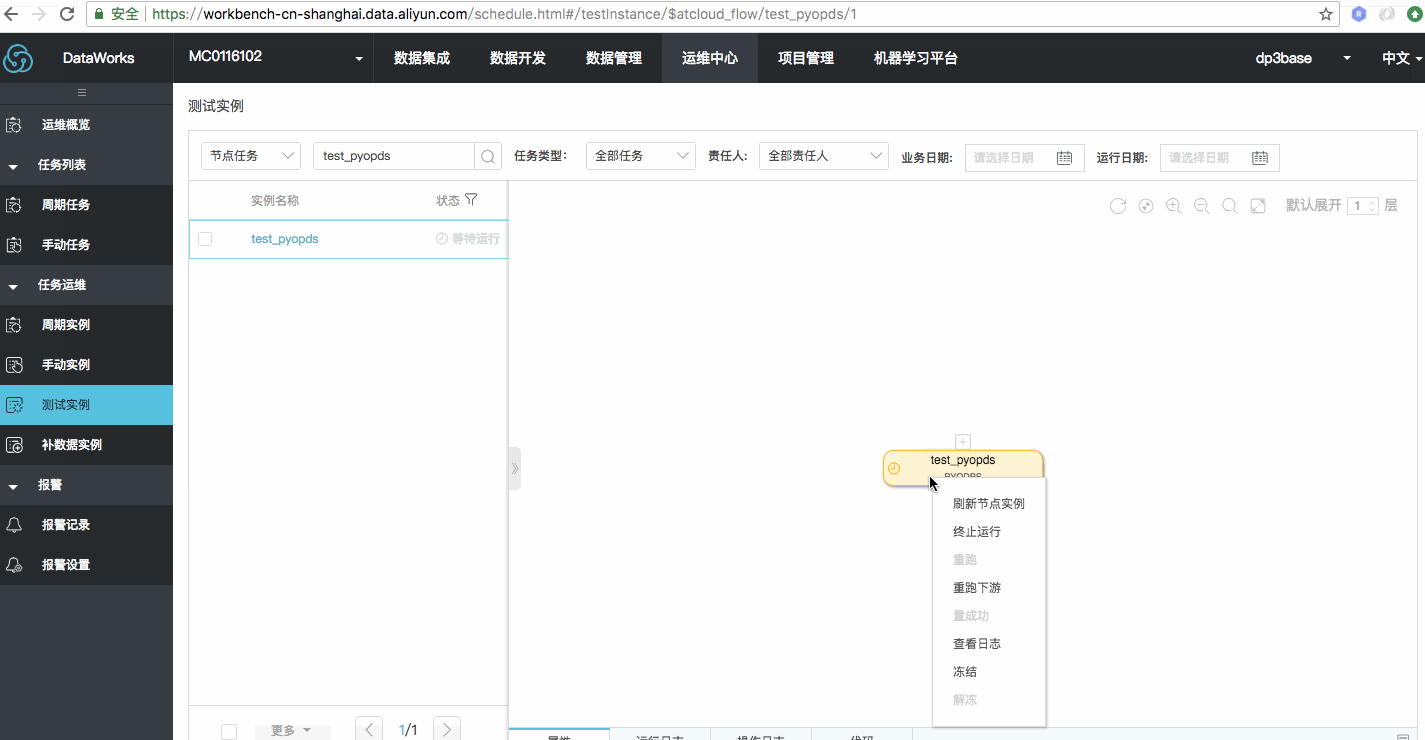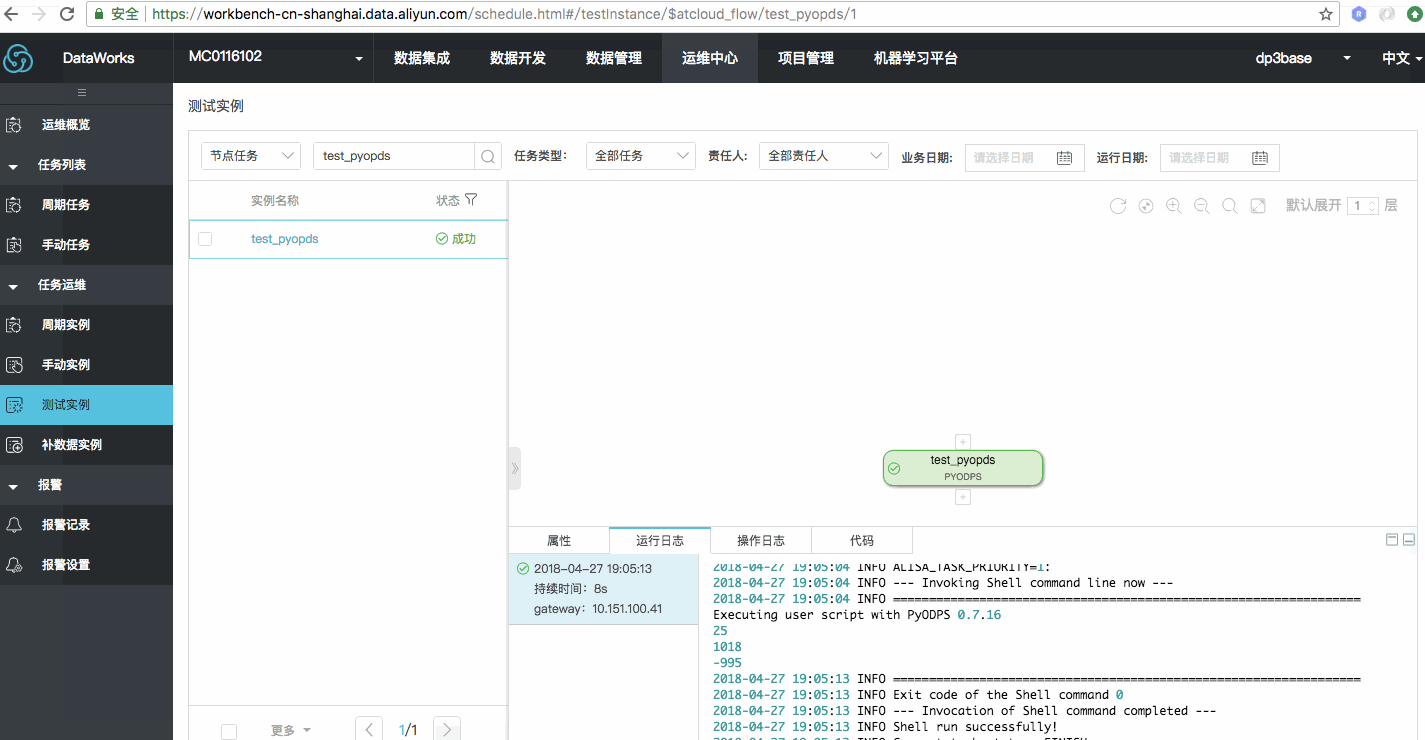
新建 PYODPS 节点具体操作如下:
1) 单击数据开发页面工具栏中的 新建 > 新建任务。2) 填写新建任务弹出框中的各配置项。
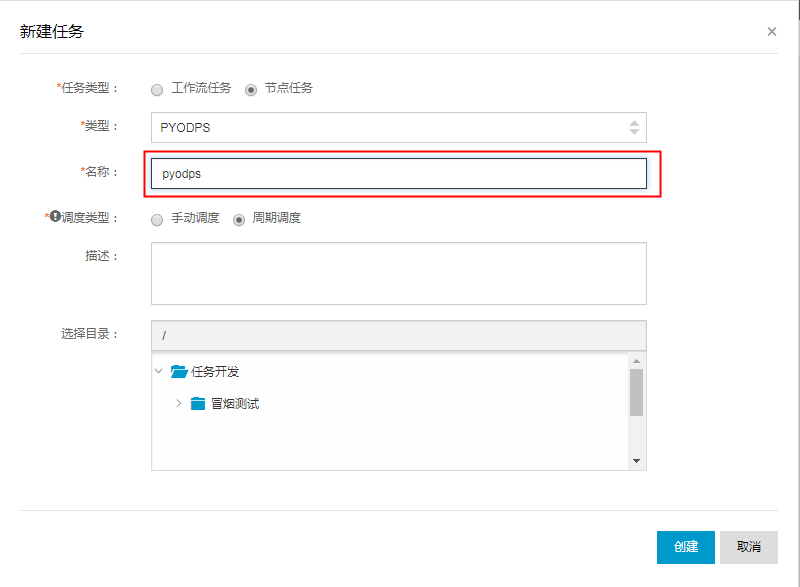
3) 单击创建
编辑 PYODPS 节点
ODPS入口
DataWorks 的 PyODPS 节点中,将会包含一个全局的变量 odps 或者 o ,即 ODPS 入口。用户不需要手动定义 ODPS 入口。
print(odps.exist_table('pyodps_iris'))
执行SQL
PyODPS支持ODPS SQL的查询,并可以读取执行的结果。 execute_sql 或者 run_sql 方法的返回值是 运行实例 。
注解:并非所有在 ODPS Console 中可以执行的命令都是 ODPS 可以接受的 SQL 语句。 在调用非 DDL / DML 语句时,请使用其他方法,例如 GRANT / REVOKE 等语句请使用 run_security_query 方法,PAI 命令请使用 run_xflow 或 execute_xflow 方法。
>>> o.execute_sql('select * from dual') # 同步的方式执行,会阻塞直到SQL执行完成 >>> >>> instance = o.run_sql('select * from dual') # 异步的方式执行 >>> print(instance.get_logview_address()) # 获取logview地址 >>> instance.wait_for_success() # 阻塞直到完成
设置运行参数
有时,我们在运行时,需要设置运行时参数,我们可以通过设置 hints 参数,参数类型是dict。
>>> o.execute_sql('select * from pyodps_iris', hints={'odps.sql.mapper.split.size': 16})
我们可以对于全局配置设置sql.settings后,每次运行时则都会添加相关的运行时参数。
>>> from odps import options
>>> options.sql.settings = {'odps.sql.mapper.split.size': 16}
>>> o.execute_sql('select * from pyodps_iris') # 会根据全局配置添加hints
读取SQL执行结果
运行 SQL 的 instance 能够直接执行 open_reader 的操作,一种情况是SQL返回了结构化的数据。
>>> with o.execute_sql('select * from dual').open_reader() as reader:
>>> for record in reader:
>>> # 处理每一个record
另一种情况是 SQL 可能执行的比如 desc,这时通过 reader.raw 属性取到原始的SQL执行结果。
>>> with o.execute_sql('desc dual').open_reader() as reader:
>>> print(reader.raw)
使用调度参数
PYODPS节点使用调度参数需要注意一下,系统定义的调度参数,可以直接通过此方法获取。
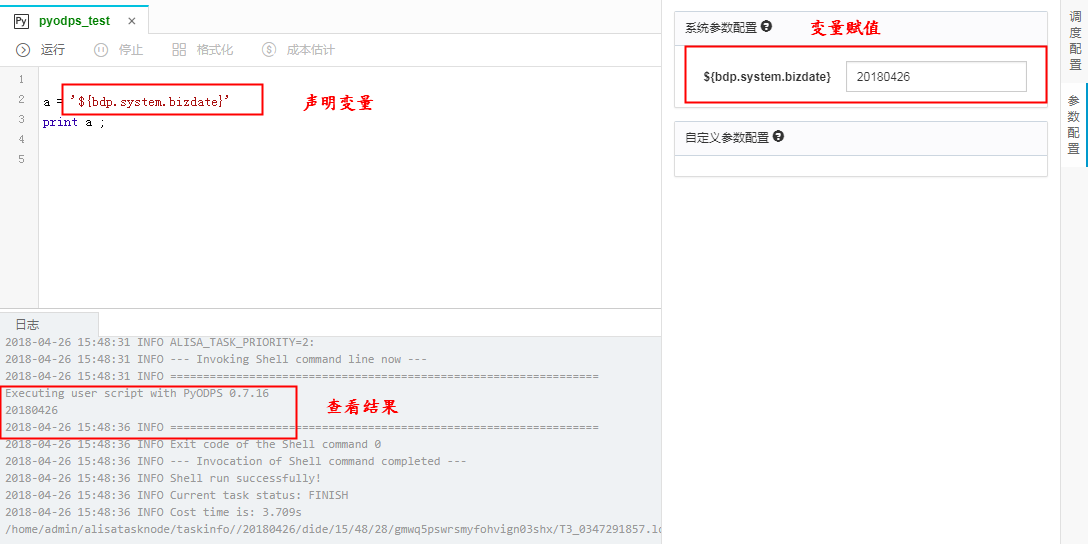
自定义参数的使用,需要使用单独的方法获取。
在全局包括一个 args 对象,可以在这个中获取,它是一个dict类型。
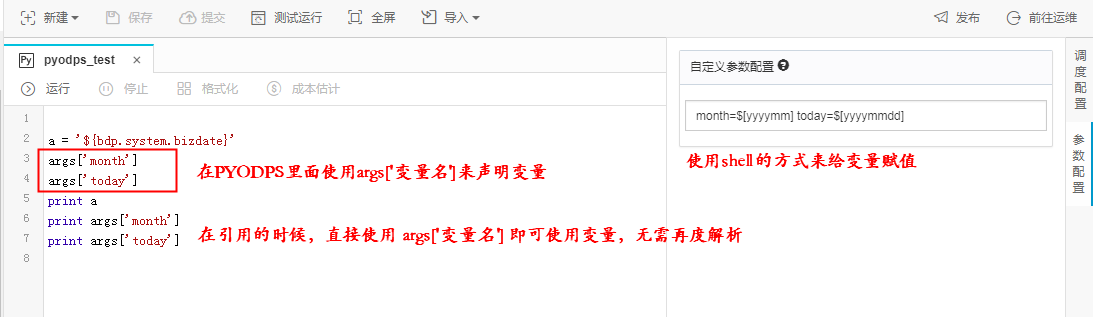
测试运行结果如下:
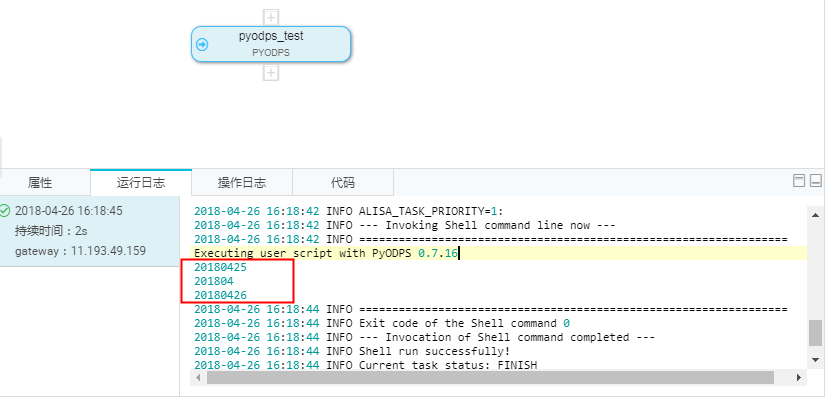
请注意:在数据开发下,使用了自定义调度参数,页面上直接触发运行PYODPS节点时,需要写死时间,PYODPS节点无法像SQL一样直接替换。
调度请参考:https://help.aliyun.com/document_detail/30298.html



相关推荐
"DataWorks调度任务迁移概述" DataWorks调度任务迁移是指将DataWorks工作空间中的调度任务迁移到新的环境中,以便更好地管理和维护这些任务。该技术创新为DataWorks工作空间迁移提供了强大的解决方案。 数据备份是...
4. 任务实例:涉及如何在PyODPS中操作任务实例,包括任务实例状态的查看、子任务操作等。 5. 资源和函数:资源可能指的是文件资源和表资源。函数部分会介绍如何创建、删除和更新用户自定义函数。 6. XFlow和模型:...
DataWorks支持多种数据源的接入,包括RDS、MaxCompute、OSS等,通过数据开发面板,用户可以创建数据同步任务,实现数据的实时或批量迁移。同时,DataWorks提供了ETL(提取、转换、加载)工具,用于清洗、转换和整合...
DataWorks V2.0的发布标志着其形成了一站式的解决方案,涵盖数据集成、数据开发、数据服务以及应用开发等多个环节,支持Hadoop、Flink、PAI等多样化的存储计算引擎,提供统一的任务调度、元数据中心、权限管理和智能...
DataWorks支持关系型数据库、MPP数据库、大数据存储、非结构化存储以及NoSql存储之间的数据同步。数据集成可以实现在不同数据源之间的数据同步,实现数据的一致性和统一性。 调度系统 DataWorks的调度系统负责调度...
在使用DataWorks进行数据同步任务时,可能会遇到各种错误,尤其是在从MaxCompute向其他数据源如RDS或HybridDB迁移数据的过程中。下面我们将详细探讨这些常见错误及其解决策略。 1. **数据回滚**: 当数据批量写入...
阿里云 DataWorks 支持多种数据类型,包括整型、浮点型、字符串型、日期时间型、布尔型等。每种数据类型都有其特点和取值范围,例如 BIGINT 类型的取值范围为 -2^63+1~2^63-1,DOUBLE 类型的取值范围为 10 进制精确...
- **数据开发**:支持SQL、Python、Spark等多种计算引擎的任务编写,同时具备任务调度能力,可实现定时任务和依赖任务的自动化运行。 - **数据治理**:DataWorks强调数据质量管理,包括数据血缘分析、数据质量检测...
dataworks使用分享,注意事项
1. 数据仓库概念和应用场景:数据仓库是企业的“大脑”,区别于OLTP业务数据库,支持OLAP在线分析,通过海量、全面、实时的分析为机构和企业各个角色的决策制定过程,提供所有类型数据支持的集合。 2. AnalyticDB+...
DataWorks提供了一个统一的数据处理平台,支持各种类型的数据 Sources,包括关系型数据库、NoSQL数据库、文件系统和消息队列等。 2. 数据Sources管理 DataWorks支持多种类型的数据 Sources,包括关系型数据库、...
6. **版本管理**:DataWorks支持任务版本管理,可以回溯和对比不同版本的任务,便于维护和修复问题,以及跟踪代码变更历史。 在使用DataWorks时,用户需要注意法律声明中的条款,包括但不限于仅能通过官方渠道获取...
在阿里云DataWorks中,数据集成服务(Data Integration)支持多种数据源,如RDS、MaxCompute、OSS、ADS等,并提供ETL(提取、转换、加载)功能。 2. **DataX介绍**:DataX是阿里云DataWorks中的开源数据同步工具,...
DataWorks支持多种数据源类型,包括关系数据库、Nosql数据库、云存储、消息队列等,提供了灵活的数据集成和数据处理能力。 二、产品特性和核心优点 DataWorks具有以下特性和优点: * 高性能和可扩展性:DataWorks...
1. **源代码**:通常包括Python模块和脚本,它们实现了与阿里云DataWorks服务的交互逻辑,如API调用、数据传输、任务管理等。 2. **文档**:可能包含README文件,提供了库的快速入门指南、安装步骤、使用示例等信息...
DataWorks 数据分析技术介绍 DataWorks 作为一款数据分析技术,旨在提供高效、智能、可视化的数据分析解决方案。下面将详细介绍 DataWorks 的技术创新、特点、产品功能模块和数据分析应用场景。 技术创新: ...