
jstorm消息处理的容错语意
分布式流式计算的容错问题
分布式计算不仅带来了系统的横向扩展能力,同时也带来了网络通信的复杂性和更大的故障概率等问题。因此,分布式计算平台、系统首要解决的问题就是容错,在出现网络不畅、机器宕机、进程失效等问题时,能够及时发现故障,采取处理措施,保证计算的正确性。
相比批处理,分布式流式计算面临的容错考验会更大,因为流式计算一般调度处理的数据单元粒度更细,受故障影响的数据更难追踪;往往会实时对外部状态进行更新;同时,在一般的实时计算应用场景下,在线数据的正常处理不希望因为小规模故障而出现中断。因此,在处理故障时,怎么判断数据是否已经处理过、更新过外部状态,对受故障影响的数据加以恢复更加困难,也往往意味着对正常处理流程会带来一定的开销。
在继续之前,首先介绍一下流式计算平台的计算模型。流式计算的计算模型类似于大型工厂里的流水线,根据工种的不同和对应的处理顺序,将整个数据处理过程安排成一个有向无环图(DAG)的拓扑结构,在storm和jstorm中,这种有向无环图就称呼为拓扑(topology),具有数据源头节点spout,和执行不同处理工作的处理节点bolt
为了方便后续理解,给出本文中几个特定名词的含义:
源头节点:图中的水龙头,代表拓扑中产生原始数据的节点,只有输出流,一般负责从如消息队列等上游数据源拉取数据发送到自己的输出流,供后续处理节点计算处理。
处理节点:图中的水滴闪电,代表真正执行计算子任务的节点,在拓扑结构中根据需要并联、串联,从上游流中获取数据,如果有后续处理,通过后续流发送到后续处理节点。
流:一对上下游节点间数据单元流向的逻辑概念,图中每一个蓝箭头代表一个流。
消息和元组(tuple):消息在本文中特指源头节点从外部接收数据的最小单元,在源头节点这条消息变成一条或若干条后续数据单元,在拓扑中继续传播,在jstorm中这个数据单元被称为元组(tuple)。处理节点接收到上游元组又会根据需要向下游流中发送一条或若干条下游元组。
分布式流式计算的容错语意
典型场景下流式计算平台的消息是一条条待分析处理的日志,在容错的场景下,对于一条消息的处理,提供了以下三种类型的处理语意:
at most once
一条消息经过系统,由这条消息产生的后续元组在各个处理节点最多会被处理一次,含义就是,出现故障时,不保证这条消息原本应该涉及的所有处理节点计算都顺利完成。
at least once
一条消息经过系统,由这条消息产生的后续元组在各个处理节点至少会被处理一次,含义就是,出现故障时,系统能够识别并进行元组重发,但是没办法判断是否之前该元组被成功处理完成了,因此可能会有重复处理的情况,对于某些改变外部状态的场景,会造成脏数据。
exactly once
一条消息经过系统,不管是否发生故障,由其产生的后续元组,在所有处理节点上有且仅会被处理一次,这是最理想的情况,即使出现故障,也能符合正确的业务预期,但一般会带来比较大的性能开销。
需要注意的是:
第2和3点由于涉及到数据的重发,而且一般的流式计算平台不会同时持久化当前正在消费的原始消息,因此需要上游数据源提供一定的数据追溯能力,如kafka、metaQ。
在很多场景下,业务代码通过实现元组的幂等处理可以选择第2点的方式,避免带来太多额外的性能开销,且达到exactly once一样的处理结果。
Storm at least once语意和实现原理
Storm原本实现了at most once和at least once语意,在Jstorm中,这一机制也得以保留。
At most once很好理解,就是故障时只重启相关进程,恢复处理链路,不对处理中的数据做额外的判断和重发,可能带来数据丢失。
At least once需要跟踪故障发生时,可能影响到的元组,并且对这些元组进行重发。
那么storm是如何跟踪这些元组的处理是否受故障影响的呢?
首先第一个问题,怎样算收到故障影响。
为此storm定义了一个概念:完全处理。
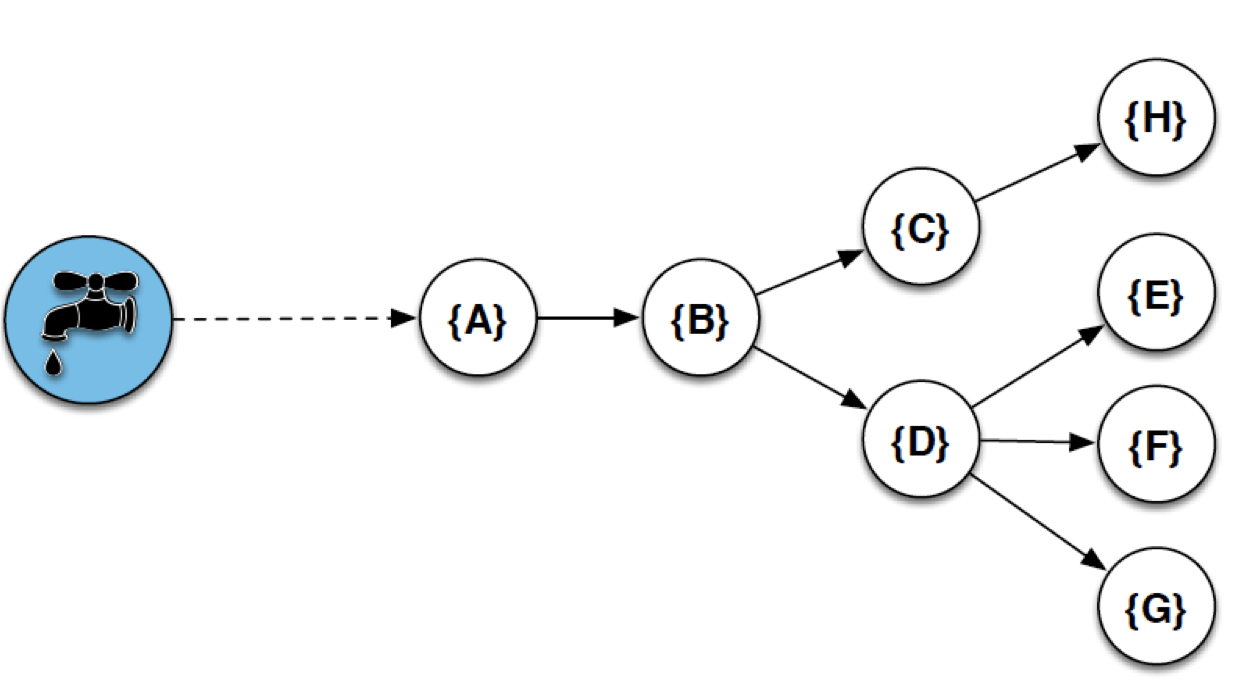
按照上图想象一下,每条消息到达源头节点并向拓扑中传播元组,会按照拓扑的形状产生一条元组树(tuple tree),不同的处理节点处理着不同的由这个原始消息产生的后续元组,当所有的后续元组在所有处理节点完成正常处理流程,则称为这条原始消息被完全处理。如果中间某一个后续元组在处理节点上处理失败,或者干脆某个处理节点在某段时间因为故障丢失,都不算消息被完全处理。(实际上,完全处理定义的最小主体是由源头节点发出的元组,但一般情况下,这个元组是和原始消息对应的)
在处理吞吐量较大、拓扑较复杂的情况下,同时正在在拓扑中处理的元组数量庞大,storm是如何跟踪每条元组是否被完全处理?
-
首先,storm通过异或计算来保存元组树的处理状态,大大降低了跟踪每条消息的空间开销和计算复杂度。
2.然后,storm除了根据用户定义的拓扑启动节点进程外,还会额外的启动一些系统节点进程,包括一个叫acker的系统节点,每个源头节点、处理节点同时也会有一个隐含的输出流通向acker节点,在发送后续元组以及确认输入元组的处理情况时向acker节点发送相关数据。
JStorm Acker详解
acker概述
JStorm的acker机制,能够保证消息至少被处理一次(at least once)。也就是说,能够保证不丢消息。这里就详细解析一下acker的实现原理。
消息流
假设我们有一个简单的topology,结构为spout -> bolt。 spout emit了一条消息,发送至bolt。bolt作为最后一个处理者,没有再向下游emit消息。
在JStorm中,acker是一种bolt,因此它的处理、消息发送跟正常的bolt是一样的。只不过,acker是JStorm框架创建的bolt,用户不能自行创建。如果用户在代码中使用
Config.setNumAckers(conf, 1);就会自动创建并行度为1的acker bolt;如果为0,则就没有acker bolt了。
如何判断消息是否被成功处理?
acker的算法非常巧妙,它利用了数学上的异或操作来实现对整个tuple tree的判断。在一个topology中的一条消息形成的tuple tree中,所有的消息,都会有一个MessageId,它内部其实就是一个map:
Map<Long, Long> _anchorsToIds;存储的是anchor和anchor value。而anchor其实就是root_id,它在spout中生成,并且一路透传到所有的bolt中,属于同一个tuple tree中的消息都会有相同的root_id,它可以唯一标识spout发出来的这条消息(以及从下游bolt根据这个tuple衍生发出的消息)。
下面是一个tuple的ack流程:
- spout发送消息时,先生成root_id。
- 对每一个目标bolt task,生成
<root_id, random()>,即为这个root_id对应一个随机数值,然后随着消息本身发送到下游bolt中。假设有2个bolt,生成的随机数对分别为:<root_id, r1>,<root_id, r2>。 - spout向acker发送ack_init消息,它的MessageId =
<root_id, r1 ^ r2>(即所有task产生的随机数列表的异或值)。 - bolt收到spout或上游bolt发送过来的tuple之后,首先它会向acker发送ack消息,MessageId即为收到的值。同时,如果bolt下游还有bolt,则跟步骤2类似,会对每一个bolt,生成随机数对,root_id相同,但是值变为
当前值 ^ 新生成的随机数。以此类推。 - acker收到消息后,会对root_id下所有的值做异或操作,如果算出来的值为0,表示整个tuple tree被成功处理;否则就会一直等待,直到超时,则tuple tree处理失败。
- acker通知spout消息处理成功或失败。
我们以一个稍微复杂一点的topology为例,描述一下它的整个过程。 假设我们的topology结构为: spout -> bolt1/bolt2 -> bolt3 即spout同时向bolt1和bolt2发送消息,它们处理完后,都向bolt3发送消息。bolt3没有后续处理节点。

1). spout发射一条消息,生成root_id,由于这个值不变,我们就用root_id来标识。 spout -> bolt1的MessageId = <root_id, 1> spout -> bolt2的MessageId = <root_id, 2> spout -> acker的MessageId = <root_id, 1^2>
2). bolt1收到消息后,生成如下消息: bolt1 -> bolt3的MessageId = <root_id, 3> bolt1 -> acker的MessageId = <root_id, 1^3>
3). 同样,bolt2收到消息后,生成如下消息: bolt2 -> bolt3的MessageId = <root_id, 4> bolt2 -> acker的MessageId = <root_id, 2^4>
4). bolt3收到消息后,生成如下消息: bolt3 -> acker的MessageId = <root_id, 3> bolt3 -> acker的MessageId = <root_id, 4>
5). acker中总共收到以下消息: <root_id, 1^2> <root_id, 1^3> <root_id, 2^4> <root_id, 3> <root_id, 4> 所有的值进行异或之后,即为1^2^1^3^2^4^3^4 = 0。
如何使用acker
- 设置acker的并发度要>0;
- spout发送消息时,使用的接口List emit(List tuple, Object messageId);其中messageId由用户指定生成,用户消息处理成功或者失败后,用于对public void ack(Object messageId) 和public void fail(Object messageId) 接口的回调;
- 如果spout同时从IAckValueSpout和IFailValueSpout派生,那么要求实现void fail(Object messageId, List values)和void ack(Object messageId, List values);这两接口除了会返回messageId,还会返回每一条消息;
- bolt一般从如果从IRichBolt派生,发送消息到下游时要注意以下两种不同类型的接口:
public List<Integer> emit(Tuple anchor, List<Object> tuple); //anchor 代表当前bolt接收到的消息, tuple代表发送到下游的消息
public List<Integer> emit(List<Object> tuple);
//如果对即将发送的消息不打算acker的话,可以直接用第二种接口;如果需要对即将发送的下游的消息要进行acker的话,emit的时候需要携带anchor5.如果bolt接收到的消息是需要被acker的话,记得在execute里头别忘了执行_collector.ack(tuple)操作;例子如下
@Override
public void execute(Tuple tuple) {
_collector.emit(tuple, new Values(tuple.getString(0)));
_collector.ack(tuple);
}- 对于从IRichBolt派生的的bolt来说是不是很麻烦,即要求采样合适的emit接口,还要求主动执行acker操作,那么好消息来了如果当前bolt是从IBasicBolt派生的话,内部都会帮你执行这些操作,你只管调用emit(List tuple)发送消息即可;
- 例子如下
public class PairCount implements IBasicBolt {
private static final long serialVersionUID = 7346295981904929419L;
public static final Logger LOG = LoggerFactory.getLogger(PairCount.class);
private AtomicLong sum = new AtomicLong(0);
private TpsCounter tpsCounter;
public void prepare(Map conf, TopologyContext context) {
tpsCounter = new TpsCounter(context.getThisComponentId() +
":" + context.getThisTaskId());
LOG.info("Successfully do parepare " + context.getThisComponentId());
}
public void execute(Tuple tuple, BasicOutputCollector collector) {
tpsCounter.count();
Long tupleId = tuple.getLong(0);
Pair pair = (Pair)tuple.getValue(1);
sum.addAndGet(pair.getValue());
// 如果需要ack,只需要这么做:
collector.emit(new Values(tupleId, pair));
}
public void cleanup() {
tpsCounter.cleanup();
LOG.info("Total receive value :" + sum);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("ID", "PAIR"));
}
public Map<String, Object> getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
}
}ack存在的问题
这种实现方式有一个问题,按照上面的完全处理原则,元组树中的某一个节点处理失败都会导致整个元组树的重发,因此有很多元组会被重复处理,因此叫做at least once。
还有一个严重问题就是,对拓扑中产生的每个元组,都会发送一个ack消息,在大吞吐量、拓扑复杂的情况下会造成相当可观的网络IO开销。
参考:http://jstorm.io/ProgrammingGuide_cn/AdvancedUsage/Theory/Acker.html



相关推荐
JStorm流处理框架.pptx
它作为消息中间件,提供了高吞吐量的消息生产和消费能力,同时支持数据持久化,使得消息能够被多次消费,非常适合大数据实时处理和日志收集。 集成JStorm与Kafka的目的是利用Kafka作为数据源,通过JStorm进行实时...
在JStorm 2.1.1中,`ISpout`接口定义了Spout的基本行为,包括`nextTuple`(发布新数据)、`ack`(确认消息已被处理)和`fail`(处理失败的消息)。开发者可以自定义实现`ISpout`,创建满足特定数据源需求的Spout。 ...
JStorm是一款分布式实时计算系统,它允许用户处理数据流,而Kafka则是一个高吞吐量的分布式消息系统,用于实时数据传递。接下来,我们将深入讲解这两个组件的集成过程,以及如何通过Java编写可运行的代码实例。 ...
7. **实时流处理原理**:简述实时计算的基本原理,如数据窗口、状态管理和容错机制。 8. **最佳实践**:分享一些使用JStorm时的注意事项和最佳实践,如资源管理、性能调优等。 通过这个入门示例,学习者将能够对...
JStorm适用于无状态计算任务,如日志分析、管道系统、消息转换器和统计分析器等,这些任务的数据处理不依赖额外的存储状态。 **总结** JStorm作为一款分布式实时计算引擎,因其高度的定制化、优秀的稳定性和扩展性...
JStorm是一个分布式实时计算系统,类似于Apache Storm,它允许开发者构建容错、低延迟的实时数据处理应用。在JStorm中,Bolt是处理数据的核心组件,它们负责对Tuples(数据单元)进行各种操作,如计算、过滤、聚合等...
- JStorm的容错机制,如acker机制,保证数据至少被处理一次。 - JStorm的动态调整功能,允许在运行时增加或减少Topology的worker和task数量。 - JStorm与其他大数据组件(如Hadoop、HBase)的集成,实现更复杂的数据...
JStorm的核心设计理念是简单、高效和稳定,能够处理大规模的数据流处理任务,广泛应用于广告推荐、日志分析、用户行为分析等领域。 **JStorm与Apache Storm的区别** 虽然JStorm是基于Apache Storm的,但两者之间...
在JStorm 2.2.1中,对性能进行了优化,包括减少网络传输的开销、提升调度效率以及增强容错能力。此外,它还提供了一套完整的监控和告警机制,便于运维人员实时了解系统状态和问题定位。 开发JStorm应用时,开发者...
还有,JStorm的容错设计,如Failed Task自动重试、检查点机制,确保系统的高可用性。 在《JStorm阿里巴巴官方文档》中,你还会看到许多示例代码,比如压缩包内的"storm-book-examples-ch02-getting_started-8e42636...
标题"jstorm课程"指的是关于JStorm的教育课程,JStorm是阿里巴巴开源的一个分布式实时计算框架,它是Apache Storm的Java版本,主要用于处理大规模数据流的实时计算。 描述中提到的"全套storm资料初学者必备 比较...
随着大数据技术的不断发展,JStorm也在持续进化,如优化内存管理和资源调度,增强容错机制,以及引入新的编程模型等,以应对更复杂、更大规模的实时计算挑战。 总结,阿里巴巴JStorm作为一款强大的分布式实时计算...
Jstorm组合消息队列中间件开发Demo
【JStorm到Apache Flink...总的来说,字节跳动从JStorm迁移到Apache Flink的实践展示了实时数仓系统演进的一个典型案例,揭示了在应对大规模实时数据处理时,如何选择合适的工具以应对性能、资源管理和运维效率等挑战。
jstorm框架介绍,包含架构图、jstorm安装部署以及配置、如何在jstorm框架里写业务代码。
Apache Storm和jstorm都广泛应用于大数据实时处理领域,提供高容错能力的实时计算解决方案。 从文档中可以提取出以下关键知识点: 1. jstorm的版本演进:文档提到了多个jstorm版本,例如0.7.1、0.9.x系列以及更高...
1. **TLog**:Transaction Log,是JStorm实现容错性和高可用性的基础,确保数据的一致性。 2. **Kepler**:调度器,负责任务分配和资源管理,保证系统的高效运行。 3. **NUT**和**ARM**:NUT是网络传输层,负责数据...
标题《JStorm生态》和描述《阿里jstorm生态,JStorm基础入门,讲解详细,阐述清晰,适合新手看》表明,本文主要围绕阿里巴巴开源的大规模实时数据处理系统JStorm进行讲解。JStorm是基于Apache Storm的一个分支,主要...
jstorm框架default.yaml参数配置项列表详解