
What is Apache Tez?
Apache Tez generalizes the MapReduce paradigm to execute a complex DAG (directed acyclic graph) of tasks. It also represents the next logical next step for Hadoop 2 and the introduction of with YARN and its more general-purpose resource management framework.
While MapReduce has served masterfully as the data processing backbone for Hadoop, its batch-oriented nature makes it unsuited for certain workloads like interactive query. Tez represents an alternate to the traditional MapReduce that allows for jobs to meet demands for fast response times and extreme throughput at petabyte scale. A great example of a benefactor of this new approach is Apache Hive and the work being done in theStinger Initiative
Motivation
Distributed data processing is the core application that Apache Hadoop is built around. Storing and analyzing large volumes and variety of data efficiently has been the cornerstone use case that has driven large scale adoption of Hadoop, and has resulted in creating enormous value for the Hadoop adopters. Over the years, while building and running data processing applications based on MapReduce, we have understood a lot about the strengths and weaknesses of this framework and how we would like to evolve the Hadoop data processing framework to meet the evolving needs of Hadoop users. As the Hadoop compute platform moves into its next phase with YARN, it has decoupled itself from MapReduce being the only application, and opened the opportunity to create a new data processing framework to meet the new challenges. Apache Tez aspires to live up to these lofty goals.
Key Design Themes
Higher-level data processing applications like Hive and Pig need an execution framework that can express their complex query logic in an efficient manner and then execute it with high performance. Apache Tez has been built around the following main design themes that solve these key challenges in the Hadoop data processing domain.
Ability to express, model and execute data processing logic
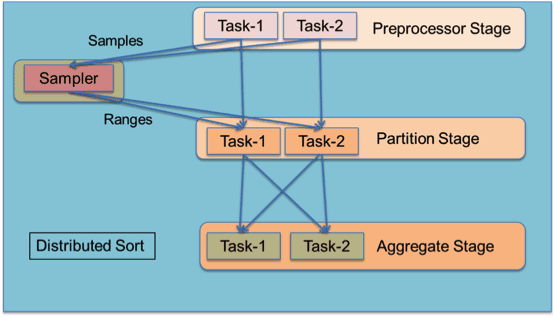 Tez models data processing as a dataflow graph with vertices in the graph representing application logic and edges representing movement of data. A rich dataflow definition API allows users to express complex query logic in an intuitive manner and it is a natural fit for query plans produced by higher-level declarative applications like Hive and Pig. As an example, the diagram shows how to model an ordered distributed sort using range partitioning. The Preprocessor stage sends samples to a Sampler that calculates sorted data ranges for each data partition such that the work is uniformly distributed. The ranges are sent to Partition and Aggregate stages that read their assigned ranges and perform the data scatter-gather. This dataflow pipeline can be expressed as a single Tez job that will run the entire computation. Expanding this logical graph into a physical graph of tasks and executing it is taken care of by Tez.
Tez models data processing as a dataflow graph with vertices in the graph representing application logic and edges representing movement of data. A rich dataflow definition API allows users to express complex query logic in an intuitive manner and it is a natural fit for query plans produced by higher-level declarative applications like Hive and Pig. As an example, the diagram shows how to model an ordered distributed sort using range partitioning. The Preprocessor stage sends samples to a Sampler that calculates sorted data ranges for each data partition such that the work is uniformly distributed. The ranges are sent to Partition and Aggregate stages that read their assigned ranges and perform the data scatter-gather. This dataflow pipeline can be expressed as a single Tez job that will run the entire computation. Expanding this logical graph into a physical graph of tasks and executing it is taken care of by Tez.
Flexible Input-Processor-Output task model
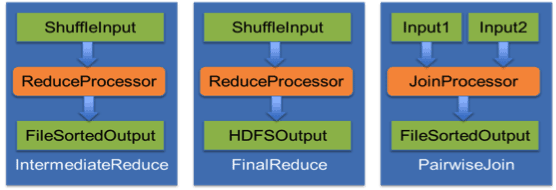 Tez models the user logic running in each vertex of the dataflow graph as a composition of Input, Processor and Output modules. Input & Output determine the data format and how and where it is read/written. Processor holds the data transformation logic. Tez does not impose any data format and only requires that a combination of Input, Processor and Output must be compatible with each other with respect to their formats when they are composed to instantiate a vertex task. Similarly, an Input and Output pair connecting two tasks should be compatible with each other. In the diagram, we can see how composing different Inputs, Outputs and Processors can produce different tasks.
Tez models the user logic running in each vertex of the dataflow graph as a composition of Input, Processor and Output modules. Input & Output determine the data format and how and where it is read/written. Processor holds the data transformation logic. Tez does not impose any data format and only requires that a combination of Input, Processor and Output must be compatible with each other with respect to their formats when they are composed to instantiate a vertex task. Similarly, an Input and Output pair connecting two tasks should be compatible with each other. In the diagram, we can see how composing different Inputs, Outputs and Processors can produce different tasks.
Performance via Dynamic Graph Reconfiguration
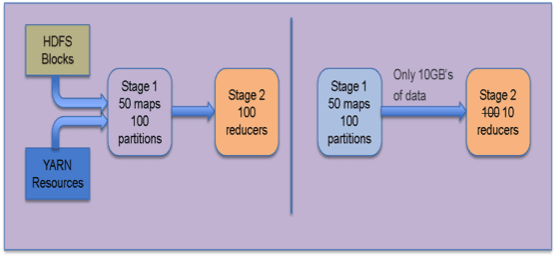 Distributed data processing is dynamic by nature and it is extremely difficult to statically determine optimal concurrency and data movement methods a priori. More information is available during runtime, like data samples and sizes, which may help optimize the execution plan further. We also recognize that Tez by itself cannot always have the smarts to perform these dynamic optimizations. The design of Tez includes support for pluggable vertex management modules to collect relevant information from tasks and change the dataflow graph at runtime to optimize for performance and resource usage. The diagram shows how Tez can determine an appropriate number of reducers in a MapReduce like job by observing the actual data output produced and the desired load per reduce task.
Distributed data processing is dynamic by nature and it is extremely difficult to statically determine optimal concurrency and data movement methods a priori. More information is available during runtime, like data samples and sizes, which may help optimize the execution plan further. We also recognize that Tez by itself cannot always have the smarts to perform these dynamic optimizations. The design of Tez includes support for pluggable vertex management modules to collect relevant information from tasks and change the dataflow graph at runtime to optimize for performance and resource usage. The diagram shows how Tez can determine an appropriate number of reducers in a MapReduce like job by observing the actual data output produced and the desired load per reduce task.
Performance via Optimal Resource Management
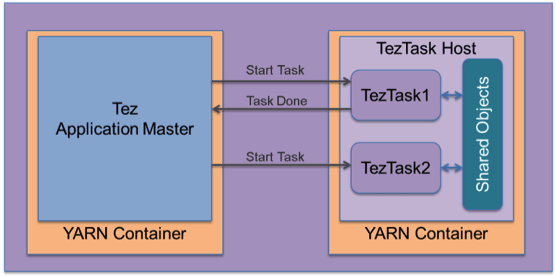 Resources acquisition in a distributed multi-tenant environment is based on cluster capacity, load and other quotas enforced by the resource management framework like YARN. Thus resource available to the user may vary over time and over different executions of the job. It becomes paramount to be able to efficiently use all available resources to run a job as fast as possible during one instance of execution and predictably over different instances of execution. The Tez execution engine framework allows for efficient acquisition of resources from YARN along with extensive reuse of every component in the pipeline such that no operation is duplicated unnecessarily. These efficiencies are exposed to user logic, where possible, such that users may also leverage this for efficient caching and avoid work duplication. The diagram shows how Tez runs multiple containers within the same YARN container host and how users can leverage that to store their own objects that may be shared across tasks.
Resources acquisition in a distributed multi-tenant environment is based on cluster capacity, load and other quotas enforced by the resource management framework like YARN. Thus resource available to the user may vary over time and over different executions of the job. It becomes paramount to be able to efficiently use all available resources to run a job as fast as possible during one instance of execution and predictably over different instances of execution. The Tez execution engine framework allows for efficient acquisition of resources from YARN along with extensive reuse of every component in the pipeline such that no operation is duplicated unnecessarily. These efficiencies are exposed to user logic, where possible, such that users may also leverage this for efficient caching and avoid work duplication. The diagram shows how Tez runs multiple containers within the same YARN container host and how users can leverage that to store their own objects that may be shared across tasks.
We hope this brief overview about the philosophy and design of Apache Tez will throw some light on the aspirations of the project and how we hope to work with the Apache Hadoop community to bring them to life. Apache Hive and Apache Pig projects have already show deep interest in integrating with Tez.
http://hortonworks.com/blog/apache-tez-a-new-chapter-in-hadoop-data-processing/



相关推荐
Apache Tez是一个通用的数据处理管道引擎,被设想为用于更高抽象的低级引擎,例如Apache Hadoop Map-Reduce,Apache Pig,Apache Hive等。 从本质上讲,tez非常简单,只有两个组成部分: 数据处理流水线引擎可以...
Apache TEZ 是一个基于 Hadoop 的数据处理引擎,它提供了高性能、可扩展的数据处理能力。Apache TEZ 部署手册是一份详细的指导手册,涵盖了 Apache TEZ 的部署、配置和使用。 一、准备 在部署 Apache TEZ 之前,...
该文档来自于Apache Hadoop和Tez项目PMC成员Bikas Saha,在2014中国大数据技术大会大数据技术分论坛的演讲“Apache Tez-A Framework to Model and Build Hadoop Data Processing Applications”。
Apache Tez 是一个高度可扩展和灵活的数据处理框架,它为Apache Hadoop生态系统提供了一个高效、低延迟的处理引擎。Tez 建立在Hadoop MapReduce之上,旨在优化大规模数据处理作业的性能,特别是在复杂的计算任务和...
当前版本Apache Hive(主干版) Apache Tez 0.5.2 Apache Hadoop 2.5.2 PostgreSQL 9.3(Hive 元存储后端)在 Mac OS X 上运行此步骤仅适用于 Mac OS X,因为 Mac OS X 本身不支持 docker。要在 Mac OS X 上运行 ...
源码使用的是apache-tez-0.8.3,对应的hadoop版本2.8.3,源码包中的nodejs的版本是v0.12.3,很难编译通过,最后把nodejs改成了v4.0.0才编译通过tez-ui2模块。
1. **安装与配置**:首先需要解压"apache-tez-0.8.5-bin",并将Tez的库文件添加到Hadoop的类路径中。还需要在Hadoop的配置文件中启用Tez,并设置相关参数。 2. **DAG设计**:理解DAG的概念至关重要,因为它是Tez...
源码使用的是apache-tez-0.8.3,对应的hadoop版本2.7.3,源码包中的nodejs的版本是v0.12.3,很难编译通过,最后把nodejs改成了v4.0.0才编译通过tez-ui2模块。
Tez是Apache Hadoop生态系统中的一个关键组件,它是一个可扩展的、高性能的数据处理框架,用于构建复杂的数据处理作业。在Hadoop-2.7.1这个版本中,Tez发挥了重要作用,优化了MapReduce的性能,并提供了更灵活的作业...
Chapter 1: Setting the Stage for Hive: Hadoop Chapter 2: Introducing Hive Chapter 3: Hive Architecture Chapter 4: Hive Tables DDL Chapter 5: Data Manipulation Language (DML) Chapter 6: Loading Data ...
Tez是Apache Hadoop生态系统中的一个关键组件,它是一个数据处理框架,旨在提供比MapReduce更高效、更灵活的数据处理能力。Tez 0.8.5是该框架的一个特定版本,与Hadoop 2.6.5兼容,这意味着它是为在Hadoop 2.x环境下...
Use Pig with Apache Tez to build high-performance batch and interactive data processing applications Create your own load and store functions to handle data formats and storage mechanisms
Apache Tez是一个高性能、灵活的数据处理框架,它被广泛应用于Hadoop生态系统,特别是在大数据分析任务中,如Apache Hive的查询优化。该WAR文件是Tez UI的最新0.10.1版本,设计用于解决在编译或部署过程中遇到的问题...
Hadoop3+Hive3+Tez编译安装;适用视频:https://www.bilibili.com/video/BV1L54
Apache Tez 是一个高度可扩展和灵活的数据处理框架,它构建在 Apache Hadoop 上,用于执行复杂的、有向无环图(DAG)任务。这个框架优化了 MapReduce 模型,提供了更高效的并行计算能力,适用于大规模数据处理工作。...
Cloudera Distribution Including Apache Hadoop (CDH) 是一款由 Cloudera 公司提供的企业级大数据平台,它包含了 Hadoop 生态系统中的核心组件和服务。Tez 是一个支持复杂数据处理任务的框架,能够提高 MapReduce ...
1. **Hadoop版本匹配**: CDH版本需要与Tez版本相匹配。在这个例子中,CDH版本是6.2.0,而Tez版本是0.9.1。确保使用兼容的Hadoop版本进行编译,例如 `<hadoop.version>3.0.0-cdh6.2.0</hadoop.version>`。 2. **...
tez:训练pytorch模型fastrrrr ....... tez:训练pytorch模型fastrrrr .......注意:当前,我们不接受任何拉取请求! 所有公共关系将被关闭。 如果您需要某个功能或某些功能不起作用,请创建一个问题。 意思是“锐利...
在大数据处理领域,Hive作为一个基于Hadoop的数据仓库工具,被广泛用于结构化数据的查询、分析和管理。然而,在实际操作中,我们经常会遇到一些常见的错误,特别是当Hive运行在Tez引擎上时。这里我们将深入探讨五个...
藏经阁-Apache Hadoop 3.0_ What’s new in YARN & MapReduce.pdf Apache Hadoop 3.0 版本中,YARN(Yet Another Resource Negotiator)和 MapReduce 组件发生了许多变化。本文将对这些变化进行详细的介绍和分析。 ...