
Overview
Apache Tez models data processing as a dataflow graph, with the vertices in the graph representing processing of data and edges representing movement of data between the processing. Thus user logic, that analyses and modifies the data, sits in the vertices. Edges determine the consumer of the data, how the data is transferred and the dependency between the producer and consumer vertices. This model concisely captures the logical definition of the computation. When the Tez job executes on the cluster, it expands this logical graph into a physical graph by adding parallelism at the vertices to scale to the data size being processed. Multiple tasks are created per logical vertex to perform the computation in parallel.
DAG Definition API
More technically, the data processing is expressed in the form of a directed acyclic graph (DAG). The processing starts at the root vertices of the DAG and continues down the directed edges till it reaches the leaf vertices. When all the vertices in the DAG have completed then the data processing job is done. The graph does not have cycles because the fault tolerance mechanism used by Tez is re-execution of failed tasks. When the input to a task is lost then the producer task of the input is re-executed and so Tez needs to be able to walk up the graph edges to locate a non-failed task from which to re-start the computation. Cycles in the graph can make this walk difficult to perform. In some cases, cycles may be handled by unrolling them to create a DAG.
Tez defines a simple Java API to express a DAG of data processing. The API has three components
- DAG. this defines the overall job. The user creates a DAG object for each data processing job.
- Vertex. this defines the user logic and the resources & environment needed to execute the user logic. The user creates a Vertex object for each step in the job and adds it to the DAG.
- Edge. this defines the connection between producer and consumer vertices. The user creates an Edge object and connects the producer and consumer vertices using it.

The diagram shows a dataflow graph and its definition using the DAG API (simplified). The job consists of 2 vertices performing a “Map” operation on 2 datasets. Their output is consumed by 2 vertices that do a “Reduce” operation. Their output is brought together in the last vertex that does a “Join” operation.
Tez handles expanding this logical graph at runtime to perform the operations in parallel using multiple tasks. The diagram shows a runtime expansion in which the first M-R pair has a parallelism of 2 while the second has a parallelism of 3. Both branches of computation merge in the Join operation that has a parallelism of 2. Edge properties are at the heart of this runtime activity.

Edge Properties
The following edge properties enable Tez to instantiate the tasks, configure their inputs and outputs, schedule them appropriately and help route the data between the tasks. The parallelism for each vertex is determined based on user guidance, data size and resources.
-
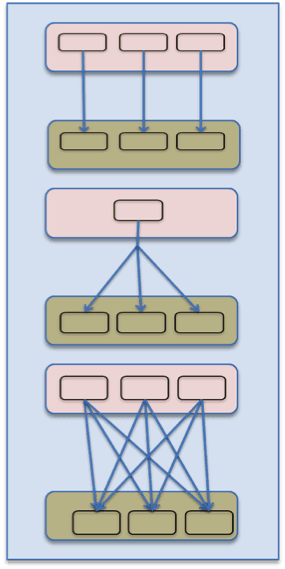 Data movement. Defines routing of data between tasks
Data movement. Defines routing of data between tasks
- One-To-One: Data from the ith producer task routes to the ith consumer task.
- Broadcast: Data from a producer task routes to all consumer tasks.
- Scatter-Gather: Producer tasks scatter data into shards and consumer tasks gather the shards. The ith shard from all producer tasks routes to the ithconsumer task.
-
Scheduling. Defines when a consumer task is scheduled
- Sequential: Consumer task may be scheduled after a producer task completes.
- Concurrent: Consumer task must be co-scheduled with a producer task.
- Data source. Defines the lifetime/reliability of a task output
- Persisted: Output will be available after the task exits. Output may be lost later on.
- Persisted-Reliable: Output is reliably stored and will always be available
- Ephemeral: Output is available only while the producer task is running
Some real life use cases will help in clarifying the edge properties. Mapreduce would be expressed with the scatter-gather, sequential and persisted edge properties. Map tasks scatter partitions and reduce tasks gather them. Reduce tasks are scheduled after the map tasks complete and the map task outputs are written to local disk and hence available after the map tasks have completed. When a vertex checkpoints its output into HDFS then its output edge has a persisted-reliable property. If a producer vertex is streaming data directly to a consumer vertex then the edge between them has ephemeral and concurrent properties. A broadcast property is used on a sampler vertex that produces a global histogram of data ranges for range partitioning.
We hope that the Tez dataflow definition API will be able to express a broad spectrum of data processing topologies and enable higher level languages to elegantly transform their queries into Tez jobs.
orginal doc : http://hortonworks.com/blog/expressing-data-processing-in-apache-tez/



相关推荐
该文档来自于Apache Hadoop和Tez项目PMC成员Bikas Saha,在2014中国大数据技术大会大数据技术分论坛的演讲“Apache Tez-A Framework to Model and Build Hadoop Data Processing Applications”。
Use Pig with Apache Tez to build high-performance batch and interactive data processing applications Create your own load and store functions to handle data formats and storage mechanisms
Programming with Apache Hive, Apache Tez in HDInsight, and Apache HCatalog Hour 14. Consuming HDInsight Data from Microsoft BI Tools over Hive ODBC Driver: Part 1 Hour 15. Consuming HDInsight Data ...
Apache Hadoop YARN是Hadoop 2.0核心组件之一,它代表了Hadoop技术的重大进步,超越了原有的MapReduce和批处理的局限性。Hadoop YARN权威指南是一本专门介绍YARN架构及其功能的书籍。首先,我们需要了解Hadoop YARN...
- 内存调优:调整Hive的内存参数,如mapreduce.map.memory.mb、hive.server2.tez.sessions.per.default.pool等。 7. **安全性**: - Hive支持Hadoop的Sentry、Kerberos等安全机制,实现权限管理和身份验证。 ...
TPCDS(Transaction Processing Performance Council Data Warehouse Benchmark)是大数据领域常用的一种数据仓库基准测试套件,主要用于衡量数据仓库系统的性能。Hive作为Apache Hadoop生态系统中的一个数据仓库...