
Lucene жәҗз Ғеү–жһҗ
4.3В В В В В В В зҙўеј•еҲӣе»әиҝҮзЁӢ
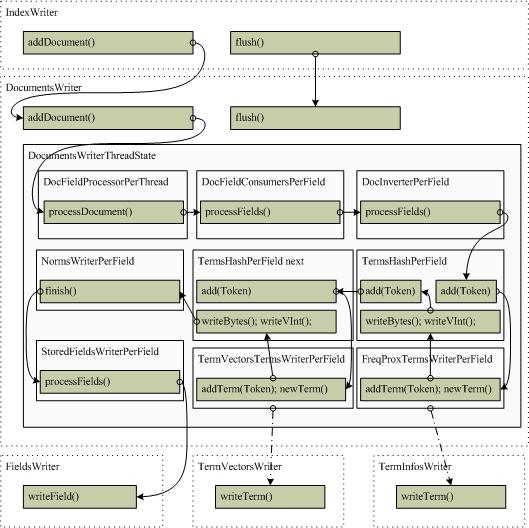
В В В В ж–ҮжЎЈзҡ„зҙўеј•иҝҮзЁӢжҳҜйҖҡиҝҮDocumentsWriterзҡ„еҶ…йғЁж•°жҚ®еӨ„зҗҶй“ҫе®ҢжҲҗзҡ„пјҢDocumentsWriterеҸҜд»Ҙе®һзҺ°еҗҢж—¶ж·»еҠ еӨҡдёӘж–Ү档并е°Ҷе®ғ们еҶҷе…ҘдёҖдёӘдёҙж—¶зҡ„segmentдёӯпјҢе®ҢжҲҗеҗҺеҶҚз”ұIndexWriterе’ҢSegmentMergerеҗҲ并еҲ°з»ҹдёҖзҡ„segmentдёӯеҺ»гҖӮDocumentsWriterж”ҜжҢҒеӨҡзәҝзЁӢеӨ„зҗҶпјҢеҚіеӨҡдёӘзәҝзЁӢеҗҢж—¶ж·»еҠ ж–ҮжЎЈпјҢе®ғдјҡдёәжҜҸдёӘиҜ·жұӮеҲҶй…ҚдёҖдёӘDocumentsWriterThreadStateеҜ№иұЎжқҘзӣ‘жҺ§жӯӨеӨ„зҗҶиҝҮзЁӢгҖӮеӨ„зҗҶж—¶йҖҡиҝҮDocumentsWriterеҲқе§ӢеҢ–ж—¶е»әз«Ӣзҡ„DocFieldProcessorз®ЎзҗҶзҡ„зҙўеј•еӨ„зҗҶй“ҫжқҘе®ҢжҲҗзҡ„пјҢдҫқж¬ЎеӨ„зҗҶдёәDocFieldConsumersгҖҒDocInverterгҖҒTermsHashгҖҒFreqProxTermsWriterгҖҒTermVectorsTermsWriterгҖҒNormsWriterд»ҘеҸҠStoredFieldsWriterзӯүгҖӮВ В В В В
В В
зҙўеј•еҲӣе»әеӨ„зҗҶиҝҮзЁӢеҸҠзұ»зҡ„дё»зәҝиҜ·жұӮй“ҫиЎЁеҰӮдёӢеӣҫжүҖзӨәпјҡ
В
В
 В
В
В В В дёӢйқўд»Ӣз»Қдё»иҰҒжӯҘйӘӨзҡ„еӨ„зҗҶиҝҮзЁӢВ
В
4.3.1В DocFieldProcessorPerThread.processDocument()
В
В В В В иҜҘж–№жі•жҳҜеӨ„зҗҶдёҖдёӘж–ҮжЎЈзҡ„и°ғеәҰеҮҪж•°пјҢиҙҹиҙЈж•ҙзҗҶж–ҮжЎЈзҡ„еҗ„дёӘfieldsж•°жҚ®пјҢ并еҲӣе»әзӣёеә”зҡ„DocFieldProcessorPerFieldеҜ№иұЎжқҘдҫқж¬ЎеӨ„зҗҶжҜҸдёҖдёӘfieldгҖӮиҜҘж–№жі•йҰ–е…Ҳи°ғз”Ёзҙўеј•й“ҫиЎЁзҡ„startDocument()жқҘеҲқе§ӢеҢ–еҗ„йЎ№ж•°жҚ®пјҢ然еҗҺдҫқж¬ЎйҒҚеҺҶжҜҸдёҖдёӘfieldsпјҢе°Ҷе®ғ们е»әз«ӢдёҖдёӘд»ҘfieldеҗҚеӯ—и®Ўз®—зҡ„hashеҖјдёәkeyзҡ„hashиЎЁпјҢеҖјдёәDocFieldProcessorPerFieldзұ»еһӢгҖӮеҰӮжһңhashиЎЁдёӯе·ІеӯҳеңЁиҜҘfieldпјҢеҲҷжӣҙж–°иҜҘFieldInfoпјҲи°ғз”ЁFieldInfo.update()ж–№жі•пјүпјҢеҰӮжһңдёҚеӯҳеңЁеҲҷеҲӣе»әдёҖдёӘж–°зҡ„DocFieldProcessorPerFieldжқҘеҠ е…ҘhashиЎЁдёӯгҖӮжіЁж„ҸпјҢиҜҘhashиЎЁдјҡеӯҳеӮЁеҢ…жӢ¬еҪ“еүҚж·»еҠ ж–ҮжЎЈзҡ„жүҖжңүж–ҮжЎЈзҡ„fieldsдҝЎжҒҜпјҢе№¶ж №жҚ®FieldInfo.update()жқҘеҗҲ并зӣёеҗҢfieldеҗҚеӯ—зҡ„еҹҹи®ҫзҪ®дҝЎжҒҜгҖӮВ
В
В В В В е»әз«ӢhashиЎЁзҡ„еҗҢж—¶пјҢз”ҹжҲҗй’ҲеҜ№иҜҘж–ҮжЎЈзҡ„fields[]ж•°з»„пјҲеҸӘеҢ…еҗ«иҜҘж–ҮжЎЈзҡ„fieldsпјҢдҪҶдјҡе…ұз”ЁзӣёеҗҢзҡ„fieldsж•°з»„пјҢйҖҡиҝҮlastGenжқҘжҺ§еҲ¶еҪ“еүҚж–ҮжЎЈпјүпјҢеҰӮжһңfieldеҗҚеӯ—зӣёеҗҢпјҢеҲҷе°ҶFieldж·»еҠ еҲ°DocFieldProcessorPerFieldдёӯзҡ„fieldsж•°з»„дёӯгҖӮе»әз«Ӣе®ҢfieldsеҗҺеҶҚе°ҶжӯӨfieldsж•°з»„жҢүfieldеҗҚеӯ—жҺ’еәҸпјҢдҪҝеҫ—еҶҷе…Ҙзҡ„vectorsзӯүж•°жҚ®д№ҹжҢүжӯӨйЎәеәҸжҺ’еәҸгҖӮд№ӢеҗҺејҖе§ӢжӯЈејҸзҡ„ж–ҮжЎЈеӨ„зҗҶпјҢйҖҡиҝҮйҒҚеҺҶfieldsж•°з»„дҫқж¬Ўи°ғз”ЁDocFieldProcessorPerFieldзҡ„processFields()ж–№жі•иҝӣиЎҢпјҲдёӢе°ҸиҠӮ继з»ӯи®Іи§ЈпјүпјҢе®ҢжҲҗеҗҺи°ғз”ЁfinishDocument()е®ҢжҲҗеҗҺеәҸе·ҘдҪңпјҢеҰӮеҶҷе…ҘFieldInfosзӯүгҖӮВ
В
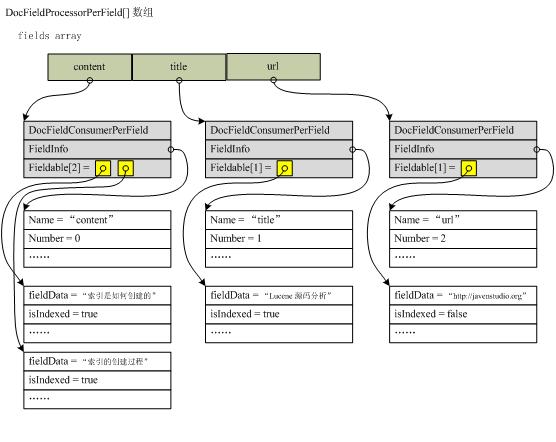
В В В В дёӢйқўдёҫдҫӢиҜҙжҳҺжӯӨиҝҮзЁӢпјҢеҒҮи®ҫиҰҒж·»еҠ еҰӮдёӢдёҖдёӘж–ҮжЎЈпјҡВ
В
В
|
ж–ҮжЎЈеҹҹ |
еҶ…е®№ |
жҳҜеҗҰзҙўеј• |
|
title |
LuceneВ жәҗз ҒеҲҶжһҗ |
true |
|
url |
http://javenstudio.org |
false |
|
content |
зҙўеј•жҳҜеҰӮдҪ•еҲӣе»әзҡ„ |
true |
|
content |
зҙўеј•зҡ„еҲӣе»әиҝҮзЁӢ |
true |
В
В
В В В В дёӢеӣҫжҸҸиҝ°еӨ„зҗҶеҗҺfieldsж•°з»„зҡ„ж•°жҚ®з»“жһ„
В В В В
В
В
 В
В
В
В http://www.cnblogs.com/eaglet/archive/2009/02/16/1391506.html
В



зӣёе…іжҺЁиҚҗ
ж Үйўҳдёӯзҡ„".NET Lucene жәҗд»Јз Ғ"иЎЁжҳҺжҲ‘们е°ҶжҺўи®Ёзҡ„жҳҜеҰӮдҪ•еңЁ.NETзҺҜеўғдёӢеҲ©з”ЁLuceneиҝӣиЎҢжҗңзҙўеј•ж“Һзҡ„ејҖеҸ‘пјҢ并且дјҡж¶үеҸҠеҲ°жәҗд»Јз ҒеұӮйқўзҡ„и§ЈжһҗгҖӮжҸҸиҝ°дёӯжҸҗеҲ°зҡ„вҖңз®ҖеҚ•жҳ“з”ЁвҖқпјҢжҸӯзӨәдәҶLuceneзҡ„ж ёеҝғзү№жҖ§д№ӢдёҖпјҢеҚіе®ғеҜ№ејҖеҸ‘иҖ…еҸӢеҘҪпјҢжҳ“дәҺ...
гҖҠLuceneжәҗд»Јз Ғеү–жһҗгҖӢжҳҜдёҖжң¬ж·ұеәҰжҺўи®ЁJavaзүҲжң¬Luceneжҗңзҙўеј•ж“Һеә“зҡ„дё“дёҡд№ҰзұҚгҖӮLuceneжҳҜApacheиҪҜ件еҹәйҮ‘дјҡзҡ„дёҖдёӘејҖжәҗйЎ№зӣ®пјҢе№ҝжіӣеә”з”ЁдәҺе…Ёж–ҮжЈҖзҙўе’ҢдҝЎжҒҜжЈҖзҙўйўҶеҹҹгҖӮжң¬д№Ұж—ЁеңЁйҖҡиҝҮж·ұе…Ҙи§Јжһҗе…¶жәҗд»Јз ҒпјҢеё®еҠ©ејҖеҸ‘иҖ…зҗҶи§ЈLuceneзҡ„е·ҘдҪң...
йҰ–е…ҲпјҢи®©жҲ‘们дәҶи§ЈдёҖдёӢLuceneзҡ„зҙўеј•еҲӣе»әиҝҮзЁӢгҖӮеңЁLuceneдёӯпјҢж•°жҚ®иў«иҪ¬еҢ–дёәдёҖз§ҚдҫҝдәҺжҗңзҙўзҡ„з»“жһ„вҖ”вҖ”еҖ’жҺ’зҙўеј•гҖӮиҝҷдёӘиҝҮзЁӢеҢ…жӢ¬д»ҘдёӢеҮ дёӘжӯҘйӘӨпјҡ 1. **еҲҶжһҗпјҲAnalyzerпјү**пјҡиҝҷжҳҜйў„еӨ„зҗҶйҳ¶ж®өпјҢз”ЁдәҺе°Ҷиҫ“е…Ҙзҡ„ж–Үжң¬еҲҶи§ЈжҲҗиҜҚе…ғ...
гҖҠLucene-2.3.1 жәҗд»Јз Ғйҳ…иҜ»еӯҰд№ гҖӢ LuceneжҳҜApacheиҪҜ件еҹәйҮ‘дјҡзҡ„дёҖдёӘејҖж”ҫжәҗз ҒйЎ№зӣ®пјҢе®ғжҳҜдёҖдёӘй«ҳжҖ§иғҪгҖҒе…Ёж–Үжң¬жҗңзҙўеә“пјҢдёәејҖеҸ‘иҖ…жҸҗдҫӣдәҶеңЁJavaеә”з”ЁзЁӢеәҸдёӯе®һзҺ°е…Ёж–ҮжЈҖзҙўеҠҹиғҪзҡ„еҹәзЎҖжһ¶жһ„гҖӮжң¬зҜҮж–Үз« е°Ҷж·ұе…ҘжҺўи®ЁLucene 2.3.1зүҲжң¬...
- йҖҡиҝҮйҳ…иҜ»жәҗд»Јз ҒпјҢеҸҜд»ҘзҗҶи§ЈLuceneзҡ„еҶ…йғЁе·ҘдҪңеҺҹзҗҶпјҢеҰӮеҰӮдҪ•жһ„е»әзҙўеј•гҖҒжү§иЎҢжҹҘиҜўзӯүгҖӮ - еҲҶжһҗеҷЁйғЁеҲҶзҡ„жәҗз ҒжңүеҠ©дәҺдәҶи§Јж–Үжң¬йў„еӨ„зҗҶиҝҮзЁӢпјҢеҢ…жӢ¬еҲҶиҜҚгҖҒеҺ»йҷӨеҒңз”ЁиҜҚзӯүгҖӮ - жҺўз©¶жҹҘиҜўи§ЈжһҗеҷЁзҡ„е®һзҺ°пјҢжҺҢжҸЎеҰӮдҪ•е°ҶиҮӘ然иҜӯиЁҖиҪ¬еҢ–дёә...
гҖҠж·ұе…Ҙеү–жһҗLucene.NETпјҡеҹәдәҺжәҗд»Јз Ғзҡ„е®һдҫӢи§ЈжһҗгҖӢ Lucene.NETпјҢдҪңдёәApache Luceneзҡ„.NETзүҲжң¬пјҢжҳҜдёҖдёӘй«ҳжҖ§иғҪгҖҒе…Ёж–ҮжЈҖзҙўеә“пјҢдёә.NETејҖеҸ‘иҖ…жҸҗдҫӣдәҶејәеӨ§зҡ„ж–Үжң¬жҗңзҙўеҠҹиғҪгҖӮжң¬е®һдҫӢе°ҶеёҰжӮЁж·ұе…ҘзҗҶи§ЈLucene.NETзҡ„еҶ…йғЁжңәеҲ¶пјҢйҖҡиҝҮжәҗ...
- зҙўеј•еҲӣе»әиҝҮзЁӢдёӯеҸҜиғҪдјҡйҒҮеҲ°еҗ„з§ҚејӮеёёпјҢеә”ж·»еҠ йҖӮеҪ“зҡ„й”ҷиҜҜеӨ„зҗҶжңәеҲ¶гҖӮ - еҜ№дәҺеӨ§йҮҸж–ҮжЎЈпјҢеҸҜиғҪйңҖиҰҒиҖғиҷ‘еҲҶжү№еӨ„зҗҶд»ҘйҒҝе…ҚеҶ…еӯҳжәўеҮәзӯүй—®йўҳгҖӮ йҖҡиҝҮд»ҘдёҠжӯҘйӘӨпјҢжҲ‘们еҸҜд»Ҙжңүж•Ҳең°дҪҝз”ЁLucene3.0жқҘеҲӣе»әзҙўеј•пјҢд»ҺиҖҢжҸҗй«ҳж–Үжң¬ж•°жҚ®зҡ„жЈҖзҙў...
2. зҙўеј•иҝҮзЁӢпјҡLuceneзҡ„зҙўеј•иҝҮзЁӢеҢ…жӢ¬еҲҶжһҗпјҲAnalyzerпјүгҖҒжңҜиҜӯж–ҮжЎЈиЎЁпјҲTerm Document Matrixпјүз”ҹжҲҗе’ҢеҖ’жҺ’зҙўеј•пјҲInverted Indexпјүзҡ„жһ„е»әгҖӮеҲҶжһҗйҳ¶ж®өе°Ҷиҫ“е…Ҙж–Үжң¬жӢҶеҲҶжҲҗжңүж„Ҹд№үзҡ„еҚ•е…ғвҖ”вҖ”жңҜиҜӯпјҢ然еҗҺеҲӣе»әжңҜиҜӯж–ҮжЎЈиЎЁпјҢжңҖеҗҺжһ„е»ә...
ејҖеҸ‘иҖ…еҸҜд»ҘжҹҘзңӢе’Ңдҝ®ж”№жәҗд»Јз ҒпјҢдәҶи§Јзҙўеј•жһ„е»әгҖҒжҹҘиҜўи§ЈжһҗгҖҒжҗңзҙўжү§иЎҢзӯүж ёеҝғжөҒзЁӢпјҢиҝҷеҜ№дәҺејҖеҸ‘иҮӘе®ҡд№үзҡ„жҗңзҙўеј•ж“ҺжҲ–жү©еұ•зҺ°жңүеҠҹиғҪйқһеёёжңүз”ЁгҖӮйҖҡиҝҮеӯҰд№ CLuceneпјҢдҪ еҸҜд»ҘжҺҢжҸЎеҰӮдҪ•еңЁC++дёӯе®һзҺ°й«ҳж•Ҳзҡ„ж–Үжң¬еҲҶжһҗгҖҒзҙўеј•жһ„е»әе’Ңжҗңзҙўзӯ–з•ҘгҖӮ...
гҖҠж·ұе…ҘзҗҶи§ЈLukeпјҡLuceneзҙўеј•жҹҘзңӢе·Ҙе…·зҡ„жәҗд»Јз Ғи§ЈжһҗгҖӢ LukeпјҢдҪңдёәдёҖдёӘејҖжәҗзҡ„Luceneзҙўеј•жөҸи§ҲеҷЁпјҢдёәејҖеҸ‘иҖ…жҸҗдҫӣдәҶзӣҙжҺҘжҹҘзңӢе’ҢеҲҶжһҗLuceneзҙўеј•зҡ„иғҪеҠӣгҖӮе®ғдёҚд»…жҳҜдёҖдёӘејәеӨ§зҡ„е·Ҙе…·пјҢд№ҹжҳҜеӯҰд№ Luceneзҙўеј•жңәеҲ¶зҡ„йҮҚиҰҒйҖ”еҫ„гҖӮйҖҡиҝҮйҳ…иҜ»...
иҝҷдёӘжәҗд»Јз ҒзүҲжң¬д»ЈиЎЁдәҶLucene 3.xзі»еҲ—зҡ„жңҖеҗҺдёҖдёӘзЁіе®ҡзүҲжң¬пјҢдёәејҖеҸ‘иҖ…жҸҗдҫӣдәҶж·ұе…ҘзҗҶи§ЈLuceneеҶ…йғЁжңәеҲ¶зҡ„е®қиҙөиө„жәҗгҖӮдёӢйқўе°ҶиҜҰз»ҶжҺўи®ЁLucene 3.6.2дёӯзҡ„е…ій”®зҹҘиҜҶзӮ№гҖӮ 1. **еҲҶиҜҚеҷЁпјҲTokenizersпјү**: Luceneзҡ„ж ёеҝғеҠҹиғҪд№ӢдёҖжҳҜ...
гҖҠж·ұе…ҘзҗҶи§ЈLucene 3.0.1пјҡеә“дёҺжәҗд»Јз Ғи§ЈжһҗгҖӢ LuceneжҳҜдёҖдёӘејҖжәҗе…Ёж–Үжҗңзҙўеј•ж“Һеә“пјҢз”ұApacheиҪҜ件еҹәйҮ‘дјҡејҖеҸ‘并з»ҙжҠӨгҖӮиҝҷдёӘвҖңlucene-3.0.1вҖқзүҲжң¬д»ЈиЎЁдәҶLuceneеңЁ2009е№ҙзҡ„дёҖдёӘйҮҚиҰҒйҮҢзЁӢзў‘пјҢе®ғжҸҗдҫӣдәҶејәеӨ§зҡ„ж–Үжң¬жЈҖзҙўеҠҹиғҪпјҢиў«е№ҝжіӣ...
з”ұдәҺжҸҸиҝ°дёӯжҸҗеҲ°вҖңе·Ізј–иҜ‘пјҢдёҚеҗ«жәҗд»Јз ҒвҖқпјҢиҝҷж„Ҹе‘ізқҖжҸҗдҫӣзҡ„ж–Ү件жҳҜзј–иҜ‘еҗҺзҡ„дәҢиҝӣеҲ¶зүҲжң¬пјҢз”ЁжҲ·еҸҜд»ҘзӣҙжҺҘеңЁ.NETзҺҜеўғдёӯдҪҝз”ЁпјҢиҖҢж— йңҖиҮӘиЎҢзј–иҜ‘жәҗд»Јз ҒгҖӮ Lucene.Netзҡ„ж ёеҝғеҠҹиғҪеҢ…жӢ¬пјҡ 1. **е…Ёж–ҮжЈҖзҙў**пјҡLucene.Netж”ҜжҢҒеҜ№ж–Үжң¬...
1. **LuceneжҰӮиҝ°**: LuceneжҳҜApacheиҪҜ件еҹәйҮ‘дјҡзҡ„дёҖдёӘејҖж”ҫжәҗд»Јз ҒйЎ№зӣ®пјҢе®ғжҳҜJavaиҜӯиЁҖзј–еҶҷзҡ„дҝЎжҒҜжЈҖзҙўеә“гҖӮе®ғжҸҗдҫӣдәҶй«ҳзә§зҡ„зҙўеј•е’ҢжҗңзҙўеҠҹиғҪпјҢж”ҜжҢҒеҲҶиҜҚгҖҒеёғе°”иҝҗз®—гҖҒзҹӯиҜӯжҗңзҙўгҖҒиҝ‘дјјжҗңзҙўзӯүеӨҡз§ҚжҗңзҙўжЁЎејҸгҖӮ 2. **Luceneж ёеҝғ组件...
LuceneжҳҜApacheиҪҜ件еҹәйҮ‘дјҡзҡ„дёҖдёӘејҖж”ҫжәҗд»Јз ҒйЎ№зӣ®пјҢе®ғжҳҜдёҖдёӘе…Ёж–Үжҗңзҙўеј•ж“Һеә“пјҢжҸҗдҫӣдәҶж–Үжң¬еҲҶжһҗгҖҒзҙўеј•е’Ңжҗңзҙўзҡ„еҹәжң¬еҠҹиғҪгҖӮ 1. **Luceneз®Җд»Ӣ** LuceneжҳҜдёҖдёӘй«ҳжҖ§иғҪгҖҒе…Ёж–Үжң¬жЈҖзҙўеә“пјҢеҸҜйӣҶжҲҗеҲ°еҗ„з§Қзі»з»ҹдёӯпјҢз”ЁдәҺжһ„е»әејәеӨ§зҡ„...
Lucene.NetжҸҗдҫӣдәҶеӨҡз§ҚеҶ…зҪ®еҲҶжһҗеҷЁпјҢеҰӮж ҮеҮҶеҲҶжһҗеҷЁпјҲStandardAnalyzerпјүгҖҒзӣҳеҸӨеҲҶжһҗеҷЁпјҲPanguAnalyzerпјүпјҢд№ҹеҸҜиҮӘе®ҡд№үеҲҶжһҗеҷЁд»Ҙж»Ўи¶ізү№е®ҡзҡ„иҜӯиЁҖжҲ–дёҡеҠЎйңҖжұӮгҖӮ 3. **ж–ҮжЎЈпјҲDocumentпјү**пјҡж–ҮжЎЈжҳҜдҝЎжҒҜзҡ„еҹәжң¬еҚ•дҪҚпјҢеҸҜд»ҘеҢ…еҗ«еӨҡдёӘ...
йҖҡиҝҮйҳ…иҜ»е’ҢеҲҶжһҗжәҗд»Јз ҒпјҢжҲ‘们еҸҜд»ҘеӯҰд№ еҲ°еҰӮдҪ•ж“ҚдҪңLuceneзҙўеј•пјҢд»ҘеҸҠеҰӮдҪ•жһ„е»әзұ»дјјзҡ„е·Ҙе…·гҖӮ жҖ»з»“иҖҢиЁҖпјҢlukeдҪңдёәLuceneзҙўеј•зҡ„еҸҜи§ҶеҢ–е·Ҙе…·пјҢжһҒеӨ§ең°дҫҝеҲ©дәҶејҖеҸ‘иҖ…еҜ№зҙўеј•зҡ„зҗҶи§Је’Ңи°ғиҜ•гҖӮж— и®әжҳҜеҲқеӯҰиҖ…иҝҳжҳҜз»ҸйӘҢдё°еҜҢзҡ„ејҖеҸ‘дәәе‘ҳпјҢйғҪ...
Luceneзҡ„ж ёеҝғеҠҹиғҪеҢ…жӢ¬ж–Үжң¬еҲҶжһҗгҖҒзҙўеј•еҲӣе»әгҖҒжҹҘиҜўи§Јжһҗе’Ңз»“жһңжҺ’еәҸгҖӮз”ұдәҺе…¶ејҖж”ҫжәҗд»Јз Ғзҡ„зү№жҖ§пјҢејҖеҸ‘иҖ…еҸҜд»Ҙж №жҚ®иҮӘе·ұзҡ„йңҖжұӮиҝӣиЎҢе®ҡеҲ¶е’Ңжү©еұ•гҖӮ дёүгҖҒLuceneзҡ„еә”з”ЁгҖҒзү№зӮ№еҸҠдјҳеҠҝ Luceneиў«е№ҝжіӣеә”з”ЁдәҺеҗ„з§ҚеңәжҷҜпјҢеҰӮзҪ‘з«ҷжҗңзҙўеј•ж“ҺгҖҒ...
Lucene 4.2.1жҳҜиҝҷдёӘеә“зҡ„дёҖдёӘзүҲжң¬пјҢе®ғеҢ…еҗ«дәҶжәҗд»Јз ҒпјҢе…Ғи®ёејҖеҸ‘иҖ…ж·ұе…ҘзҗҶи§Је…¶е·ҘдҪңеҺҹзҗҶпјҢе№¶ж №жҚ®йңҖиҰҒиҝӣиЎҢе®ҡеҲ¶е’Ңжү©еұ•гҖӮ еңЁLucene 4.2.1дёӯпјҢдҪ еҸҜд»ҘжүҫеҲ°д»ҘдёӢе…ій”®зҹҘиҜҶзӮ№пјҡ 1. **зҙўеј•жһ„е»ә**пјҡLuceneзҡ„ж ёеҝғеҠҹиғҪд№ӢдёҖжҳҜиғҪеӨҹй«ҳж•Ҳ...