
LuceneВ жәҗз Ғеү–жһҗ
4В В В В В В В В В В В зҙўеј•жҳҜеҰӮдҪ•еҲӣе»әзҡ„
дёәдәҶдҪҝз”ЁLuceneжқҘзҙўеј•ж•°жҚ®пјҢйҰ–е…ҲдҪ жҜ”жҠҠе®ғиҪ¬жҚўжҲҗдёҖдёӘзәҜж–Үжң¬пјҲplain-textпјүtokensзҡ„ж•°жҚ®жөҒпјҲstreamпјүпјҢ并йҖҡиҝҮе®ғеҲӣе»әеҮәDocumentеҜ№иұЎпјҢе…¶еҢ…еҗ«зҡ„FieldsжҲҗе‘ҳе®№зәіиҝҷдәӣж–Үжң¬ж•°жҚ®гҖӮдёҖж—ҰдҪ еҮҶеӨҮеҘҪдәӣDocumentеҜ№иұЎпјҢдҪ е°ұеҸҜд»Ҙи°ғз”ЁIndexWriterзұ»зҡ„addDocument(Document)ж–№жі•жқҘдј йҖ’иҝҷдәӣеҜ№иұЎеҲ°Lucene并еҶҷе…Ҙзҙўеј•дёӯгҖӮеҪ“дҪ еҒҡиҝҷдәӣзҡ„ж—¶еҖҷпјҢLuceneйҰ–е…ҲеҲҶжһҗпјҲanalyzerпјүиҝҷдәӣж•°жҚ®жқҘдҪҝеҫ—е®ғ们жӣҙйҖӮеҗҲзҙўеј•гҖӮиҜҰи§ҒгҖҠLucene In ActionгҖӢ
В В
В В В
4.1В В В зҙўеј•еҲӣе»әзӨәдҫӢ
В В В дёӢйқўзҡ„д»Јз ҒзӨәдҫӢеҰӮдҪ•з»ҷдёҖдёӘж–Ү件е»әз«Ӣзҙўеј•гҖӮВ
В В В В
В В В В //В StoreВ theВ indexВ onВ disk
В В В В DirectoryВ directoryВ =В FSDirectory.getDirectory(вҖң/tmp/testindexвҖң);
В В В В //В UseВ standardВ analyzer
В В В В AnalyzerВ analyzerВ =В newВ StandardAnalyzer();В
В В В В //В CreateВ IndexWriterВ object
В В В В IndexWriterВ iwriterВ =В newВ IndexWriter(directory,В analyzer,В true);
В В В В iwriter.setMaxFieldLength(25000);
В В В В //В makeВ aВ new,В emptyВ document
В В В В DocumentВ docВ =В newВ Document();
В В В В FileВ fВ =В newВ File(вҖң/tmp/test.txtвҖң);
В В В В //В AddВ theВ pathВ ofВ theВ fileВ asВ aВ fieldВ namedВ вҖқpathвҖқ.В В UseВ aВ fieldВ thatВ isВ
В В В В //В indexedВ (i.e.В searchable),В butВ donвҖҷtВ tokenizeВ theВ fieldВ intoВ words.
В В В В doc.add(newВ Field(вҖңpathвҖң,В f.getPath(),В Field.Store.YES,В Field.Index.UN_TOKENIZED));
В В В В StringВ textВ =В вҖңThisВ isВ theВ textВ toВ beВ indexed.вҖң;
В В В В doc.add(newВ Field(вҖңfieldnameвҖң,В text,В Field.Store.YES,В В В В В В Field.Index.TOKENIZED));
В В В В //В AddВ theВ lastВ modifiedВ dateВ ofВ theВ fileВ aВ fieldВ namedВ вҖқmodifiedвҖқ.В В UseВ
В В В В //В aВ fieldВ thatВ isВ indexedВ (i.e.В searchable),В butВ donвҖҷtВ tokenizeВ theВ field
В В В В //В intoВ words.
В В В В doc.add(newВ Field(вҖңmodifiedвҖң,
В В В В В В В В DateTools.timeToString(f.lastModified(),В DateTools.Resolution.MINUTE),
В В В В В В В В Field.Store.YES,В Field.Index.UN_TOKENIZED));
В В В В //В AddВ theВ contentsВ ofВ theВ fileВ toВ aВ fieldВ namedВ вҖқcontentsвҖқ.В В SpecifyВ aВ Reader,
В В В В //В soВ thatВ theВ textВ ofВ theВ fileВ isВ tokenizedВ andВ indexed,В butВ notВ stored.
В В В В //В NoteВ thatВ FileReaderВ expectsВ theВ fileВ toВ beВ inВ theВ systemвҖҷsВ defaultВ encoding.
В В В В //В IfВ thatвҖҷsВ notВ theВ caseВ searchingВ forВ specialВ charactersВ willВ fail.
В В В В doc.add(newВ Field(вҖңcontentsвҖң,В newВ FileReader(f)));
В В В В iwriter.addDocument(doc);
В В В В iwriter.optimize();
В В В В iwriter.close();
В В В
дёӢйқўиҜҰз»Ҷд»Ӣз»ҚжҜҸдёҖдёӘзұ»зҡ„еӨ„зҗҶжңәеҲ¶гҖӮ
4.2В В В В В В В зҙўеј•еҲӣе»әзұ»IndexWriter
дёҖдёӘIndexWriterеҜ№иұЎеҲӣе»ә并且з»ҙжҠӨ(maintains)В дёҖжқЎзҙўеј•е№¶з”ҹжҲҗsegmentпјҢдҪҝз”ЁDocumentsWriterзұ»жқҘе»әз«ӢеӨҡдёӘж–ҮжЎЈзҡ„зҙўеј•ж•°жҚ®пјҢSegmentMergerзұ»иҙҹиҙЈеҗҲ并еӨҡдёӘsegmentгҖӮ
В В
4.2.1В В В В В В org.apache.lucene.store.IndexWriter
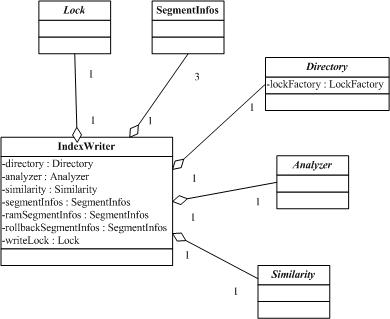
дёҖдёӘIndexWriterеҜ№иұЎеҸӘеҲӣе»ә并з»ҙжҠӨдёҖдёӘзҙўеј•гҖӮIndexWriterйҖҡиҝҮжҢҮе®ҡеӯҳж”ҫзҡ„зӣ®еҪ•пјҲDirectoryпјүд»ҘеҸҠж–ҮжЎЈеҲҶжһҗеҷЁпјҲAnalyzerпјүжқҘжһ„е»әпјҢdirecotryд»ЈиЎЁзҙўеј•еӯҳеӮЁпјҲresidesпјүеңЁе“ӘйҮҢпјӣanalyzerиЎЁзӨәеҰӮдҪ•жқҘеҲҶжһҗж–ҮжЎЈзҡ„еҶ…е®№пјӣsimilarityз”ЁжқҘи§„ж јеҢ–пјҲnormalizeпјүж–ҮжЎЈпјҢз»ҷж–ҮжЎЈз®—еҲҶпјҲscoringпјүпјӣIndexWriterзұ»йҮҢиҝҳжңүдёҖдәӣSegmentInfosеҜ№иұЎз”ЁдәҺеӯҳеӮЁзҙўеј•зүҮж®өдҝЎжҒҜпјҢд»ҘеҸҠеҸ‘з”ҹж•…йҡңеӣһж»ҡзӯүгҖӮд»ҘдёӢжҳҜе®ғ们зҡ„зұ»еӣҫпјҡ
В В
В
 В В
В В
В В
е®ғзҡ„жһ„йҖ еҮҪж•°(constructor)зҡ„createеҸӮж•°(argument)зЎ®е®ҡ(determines)жҳҜеҗҰдёҖжқЎж–°зҡ„зҙўеј•е°Ҷиў«еҲӣе»әпјҢжҲ–иҖ…жҳҜеҗҰдёҖжқЎе·Із»ҸеӯҳеңЁзҡ„зҙўеј•е°Ҷиў«жү“ејҖгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜдҪ еҸҜд»ҘдҪҝз”Ёcreate=trueеҸӮж•°жү“ејҖдёҖжқЎзҙўеј•пјҢеҚідҪҝжңүе…¶д»–readersд№ҹеңЁеңЁдҪҝз”ЁиҝҷжқЎзҙўеј•гҖӮж—§зҡ„readersе°Ҷ继з»ӯжЈҖзҙўе®ғ们已з»Ҹжү“ејҖзҡ„вҖқpoint in timeвҖқеҝ«з…§пјҲsnapshotпјүпјҢ并дёҚиғҪзңӢи§ҒйӮЈдәӣж–°е·ІеҲӣе»әзҡ„зҙўеј•пјҢзӣҙеҲ°е®ғ们еҶҚж¬Ўжү“ејҖпјҲre-openпјүгҖӮеҸҰеӨ–иҝҳжңүдёҖдёӘжІЎжңүcreateеҸӮж•°зҡ„жһ„йҖ еҮҪж•°пјҢеҰӮжһңжҸҗдҫӣзҡ„зӣ®еҪ•пјҲprovided pathпјүдёӯжІЎжңүе·Із»ҸеӯҳеңЁзҡ„зҙўеј•пјҢе®ғе°ҶеҲӣе»әе®ғпјҢеҗҰеҲҷе°Ҷжү“ејҖжӯӨеӯҳеңЁзҡ„зҙўеј•гҖӮ
В В
еҸҰдёҖж–№йқўпјҲin either caseпјүпјҢж·»еҠ ж–ҮжЎЈдҪҝз”ЁaddDocument()ж–№жі•пјҢеҲ йҷӨж–ҮжЎЈдҪҝз”ЁremoveDocument()ж–№жі•пјҢиҖҢдё”дёҖзҜҮж–ҮжЎЈеҸҜд»ҘдҪҝз”ЁupdateDocument()ж–№жі•жқҘжӣҙж–°пјҲд»…д»…жҳҜе…Ҳжү§иЎҢdeleteеңЁжү§иЎҢaddж“ҚдҪңиҖҢе·ІпјүгҖӮеҪ“е®ҢжҲҗдәҶж·»еҠ гҖҒеҲ йҷӨгҖҒжӣҙж–°ж–ҮжЎЈпјҢеә”иҜҘйңҖиҰҒи°ғз”Ёcloseж–№жі•гҖӮ
В В
иҝҷдәӣдҝ®ж”№дјҡзј“еӯҳеңЁеҶ…еӯҳдёӯпјҲbuffered in memoryпјүпјҢ并且е®ҡжңҹең°пјҲperiodicallyпјүеҲ·ж–°еҲ°пјҲflushпјүDirectoryдёӯпјҲеңЁдёҠиҝ°ж–№жі•зҡ„и°ғз”Ёжңҹй—ҙпјүгҖӮдёҖж¬Ўflushж“ҚдҪңдјҡеңЁеҰӮдёӢж—¶еҖҷи§ҰеҸ‘пјҲtriggeredпјүпјҡеҪ“д»ҺдёҠдёҖж¬Ўflushж“ҚдҪңеҗҺжңүи¶іеӨҹеӨҡзј“еӯҳзҡ„deleteж“ҚдҪңпјҲеҸӮи§ҒsetMaxBufferedDeleteTerms(int)пјүпјҢжҲ–иҖ…и¶іеӨҹеӨҡе·Іж·»еҠ зҡ„ж–ҮжЎЈпјҲеҸӮи§ҒsetMaxBufferedDocs(int)пјүпјҢж— и®әе“ӘдёӘжӣҙеҝ«дәӣпјҲwhichever is soonerпјүгҖӮеҜ№иў«ж·»еҠ зҡ„ж–ҮжЎЈжқҘиҜҙпјҢдёҖж¬ЎflushдјҡеңЁеҰӮдёӢд»»дҪ•дёҖз§Қжғ…еҶөдёӢи§ҰеҸ‘пјҢж–ҮжЎЈзҡ„RAMзј“еӯҳдҪҝз”ЁзҺҮпјҲsetRAMBufferSizeMBпјүжҲ–иҖ…е·Іж·»еҠ зҡ„ж–ҮжЎЈж•°зӣ®пјҢзјәзңҒзҡ„RAMжңҖй«ҳдҪҝз”ЁзҺҮжҳҜ16MпјҢдёәеҫ—еҲ°зҙўеј•зҡ„жңҖй«ҳж•ҲзҺҮпјҢдҪ йңҖиҰҒдҪҝз”ЁжӣҙеӨ§зҡ„RAMзј“еӯҳеӨ§е°ҸгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢflushеӨ„зҗҶд»…д»…жҳҜе°ҶIndexWriterдёӯеҶ…йғЁзј“еӯҳзҡ„зҠ¶жҖҒпјҲinternal buffered stateпјү移еҠЁиҝӣзҙўеј•йҮҢеҺ»пјҢдҪҶжҳҜиҝҷдәӣж”№еҸҳдёҚдјҡи®©IndexReaderи§ҒеҲ°пјҢзӣҙеҲ°commit()е’Ңclose()дёӯзҡ„д»»дҪ•дёҖдёӘж–№жі•иў«и°ғз”Ёж—¶гҖӮдёҖж¬ЎflushеҸҜиғҪи§ҰеҸ‘дёҖдёӘжҲ–жӣҙеӨҡзҡ„зүҮж–ӯеҗҲ并пјҲsegment mergesпјүпјҢиҝҷж—¶дјҡеҗҜеҠЁдёҖдёӘеҗҺеҸ°зҡ„зәҝзЁӢжқҘеӨ„зҗҶпјҢжүҖд»ҘдёҚдјҡдёӯж–ӯaddDocumentзҡ„и°ғз”ЁпјҢиҜ·еҸӮиҖғMergeSchedulerгҖӮ
В В
жһ„йҖ еҮҪж•°дёӯзҡ„еҸҜйҖүеҸӮж•°пјҲoptional argumentпјүautoCommitжҺ§еҲ¶пјҲcontrolsпјүдҝ®ж”№еҜ№IndexReaderе®һдҪ“пјҲinstanceпјүиҜ»еҸ–зӣёеҗҢзҙўеј•зҡ„иғҪи§ҒеәҰпјҲvisibilityпјүгҖӮеҪ“и®ҫзҪ®дёәfalseж—¶пјҢдҝ®ж”№ж“ҚдҪңе°ҶдёҚеҸҜи§ҒпјҲvisibleпјүзӣҙеҲ°close()ж–№жі•иў«и°ғз”ЁеҗҺгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜдҝ®ж”№е°Ҷдҫқ然被flushиҝӣDirectoryпјҢе°ұеғҸж–°ж–Ү件дёҖж ·пјҲas new filesпјүпјҢдҪҶжҳҜеҚҙдёҚдјҡиў«жҸҗдәӨпјҲcommitпјүпјҲжІЎжңүж–°зҡ„еј•з”ЁйӮЈдәӣж–°ж–Ү件зҡ„segments_Nж–Ү件дјҡиў«еҶҷе…ҘпјҲwritten referencing the new filesпјүпјүзӣҙйҒ“close()ж–№жі•иў«и°ғз”ЁгҖӮеҰӮжһңеңЁи°ғз”Ёclose()д№ӢеүҚеҸ‘з”ҹдәҶжҹҗз§ҚдёҘйҮҚй”ҷиҜҜпјҲsomething goes terribly wrongпјүпјҲдҫӢеҰӮJVMеҙ©жәғдәҶпјүпјҢдәҺжҳҜзҙўеј•е°ҶеҸҚжҳ пјҲreflectпјүжІЎжңүд»»дҪ•дҝ®ж”№еҸ‘з”ҹиҝҮпјҲnone of changes madeпјүпјҲе®ғе°Ҷдҝқз•ҷе®ғејҖе§Ӣзҡ„зҠ¶жҖҒпјҲremain in its starting stateпјүпјүгҖӮдҪ иҝҳеҸҜд»Ҙи°ғз”Ёrollback()пјҢиҝҷж ·еҸҜд»Ҙе…ій—ӯйӮЈдәӣжІЎжңүжҸҗдәӨд»»дҪ•дҝ®ж”№ж“ҚдҪңзҡ„writersпјҢ并且清йҷӨжүҖжңүйӮЈдәӣе·Із»ҸflushдҪҶжҳҜзҺ°еңЁдёҚиў«еј•з”Ёзҡ„пјҲunreferencedпјүзҙўеј•ж–Ү件гҖӮиҝҷдёӘжЁЎејҸпјҲmodeпјүеҜ№йҳІжӯўпјҲpreventпјүreadersеңЁдёҖдёӘй”ҷиҜҜзҡ„ж—¶й—ҙйҮҚж–°еҲ·ж–°пјҲrefreshпјүйқһеёёжңүз”ЁпјҲдҫӢеҰӮеңЁдҪ е®ҢжҲҗжүҖжңүdeleteж“ҚдҪңеҗҺпјҢдҪҶжҳҜеңЁдҪ е®ҢжҲҗж·»еҠ ж“ҚдҪңеүҚзҡ„ж—¶еҖҷпјүгҖӮе®ғиҝҳиғҪиў«з”ЁжқҘе®һзҺ°з®ҖеҚ•зҡ„single-writerзҡ„дәӢеҠЎиҜӯд№үпјҲtransactional semanticsпјүпјҲвҖңall or noneвҖқпјүгҖӮдҪ иҝҳеҸҜд»Ҙжү§иЎҢдёӨжқЎиҜӯеҸҘпјҲtwo-phaseпјүзҡ„commitпјҢйҖҡиҝҮи°ғз”ЁprepareCommit()ж–№жі•пјҢд№ӢеҗҺеҶҚи°ғз”Ёcommit()ж–№жі•гҖӮиҝҷеңЁLuceneдёҺеӨ–йғЁиө„жәҗпјҲдҫӢеҰӮж•°жҚ®еә“пјүдәӨдә’зҡ„ж—¶еҖҷжҳҜеҫҲйңҖиҰҒзҡ„пјҢиҖҢдё”еҝ…йЎ»жү§иЎҢcommitжҲ–rollbackиҜҘдәӢеҠЎгҖӮ
В В
еҪ“autoCommitи®ҫдёәtrueзҡ„ж—¶еҖҷпјҢиҜҘwriterдјҡе‘ЁжңҹжҖ§ең°жҸҗдәӨе®ғиҮӘе·ұзҡ„ж•°жҚ®гҖӮе·ІиҝҮж—¶пјҡжіЁж„ҸеңЁ3.0зүҲжң¬дёӯпјҢIndexWriterе°ҶдёҚдјҡжҺҘ收autoCommit=trueпјҢе®ғдјҡзЎ¬и®ҫзҪ®пјҲhardwiredпјүдёәfalseгҖӮдҪ еҸҜд»ҘиҮӘе·ұеңЁйңҖиҰҒзҡ„ж—¶еҖҷз»Ҹеёёи°ғз”Ёcommit()ж–№жі•гҖӮиҝҷдёҚдҝқиҜҒд»Җд№Ҳж—¶еҖҷдёҖдёӘзЎ®е®ҡзҡ„commitдјҡеӨ„зҗҶгҖӮе®ғиў«жӣҫз»Ҹз”ЁжқҘеңЁжҜҸж¬Ўflushзҡ„ж—¶еҖҷеӨ„зҗҶпјҢдҪҶжҳҜзҺ°еңЁдјҡеңЁжҜҸж¬Ўе®ҢжҲҗmergeж“ҚдҪңеҗҺеӨ„зҗҶпјҢеҰӮ2.4зүҲжң¬дёӯеҚіеҰӮжӯӨгҖӮеҰӮжһңдҪ жғіејәиЎҢжү§иЎҢcommitпјҢиҜ·и°ғз”Ёcommitж–№жі•жҲ–иҖ…closeиҝҷдёӘwriterгҖӮдёҖж—ҰдёҖдёӘcommitе®ҢжҲҗеҗҺпјҢж–°жү“ејҖзҡ„IndexReaderе®һдҫӢе°ҶдјҡзңӢеҲ°зҙўеј•дёӯиҜҘcommitжӣҙж”№зҡ„ж•°жҚ®гҖӮеҪ“д»Ҙиҝҷз§ҚжЁЎејҸиҝҗиЎҢж—¶пјҢеҪ“дјҳеҢ–пјҲoptimizeпјүжҲ–иҖ…зүҮж–ӯеҗҲ并пјҲsegment mergesпјүжӯЈеңЁиҝӣиЎҢпјҲtake placeпјүзҡ„ж—¶еҖҷйңҖиҰҒе°Ҹеҝғең°йҮҚж–°еҲ·ж–°пјҲrefreshпјүдҪ зҡ„readersпјҢеӣ дёәиҝҷдёӨдёӘж“ҚдҪңдјҡз»‘е®ҡпјҲtie upпјүеҸҜи§Ӯзҡ„пјҲsubstantialпјүзЈҒзӣҳз©әй—ҙгҖӮ
В В
дёҚз®ЎпјҲRegardlessпјүautoCommitеҸӮж•°еҰӮдҪ•пјҢдёҖдёӘIndexReaderжҲ–иҖ…IndexSearcherеҸӘдјҡзңӢеҲ°зҙўеј•еңЁе®ғжү“ејҖзҡ„еҪ“ж—¶зҡ„зҠ¶жҖҒгҖӮд»»дҪ•еңЁзҙўеј•иў«жү“ејҖд№ӢеҗҺжҸҗдәӨеҲ°зҙўеј•дёӯзҡ„commitдҝЎжҒҜпјҢеңЁе®ғиў«йҮҚж–°жү“ејҖд№ӢеүҚйғҪдёҚдјҡи§ҒеҲ°гҖӮеҪ“дёҖжқЎзҙўеј•жҡӮж—¶пјҲfor a whileпјүе°ҶдёҚдјҡжңүжӣҙеӨҡзҡ„ж–ҮжЎЈиў«ж·»еҠ пјҢ并且жңҹжңӣпјҲdesiredпјүеҫ—еҲ°жңҖзҗҶжғіпјҲoptimalпјүзҡ„жЈҖзҙўжҖ§иғҪпјҲperformanceпјүпјҢдәҺжҳҜoptimize()ж–№жі•еә”иҜҘеңЁзҙўеј•иў«е…ій—ӯд№ӢеүҚиў«и°ғз”ЁгҖӮ
В В
жү“ејҖIndexWriterдјҡдёәдҪҝз”Ёзҡ„DirectoryеҲӣе»әдёҖдёӘlockж–Ү件гҖӮе°қиҜ•еҜ№зӣёеҗҢзҡ„Directoryжү“ејҖеҸҰдёҖдёӘIndexWriterе°ҶдјҡеҜјиҮҙпјҲlead toпјүдёҖдёӘLockObtainFailedExceptionејӮеёёгҖӮеҰӮжһңдёҖдёӘе»әз«ӢеңЁзӣёеҗҢзҡ„Directoryзҡ„IndexReaderеҜ№иұЎиў«з”ЁжқҘд»ҺиҝҷжқЎзҙўеј•дёӯеҲ йҷӨж–ҮжЎЈзҡ„ж—¶еҖҷпјҢиҝҷдёӘејӮеёёд№ҹдјҡиў«жҠӣеҮәгҖӮ
В В
专家пјҲExpertпјүпјҡIndexWriterе…Ғи®ёжҢҮе®ҡпјҲspecifyпјүдёҖдёӘеҸҜйҖүзҡ„пјҲoptionalпјүIndexDeletionPolicyе®һзҺ°гҖӮдҪ еҸҜд»ҘйҖҡиҝҮиҝҷдёӘжҺ§еҲ¶д»Җд№Ҳж—¶еҖҷдјҳе…Ҳзҡ„жҸҗдәӨпјҲprior commitпјүд»Һзҙўеј•дёӯиў«еҲ йҷӨгҖӮзјәзңҒзҡ„зӯ–з•ҘпјҲpolicyпјүжҳҜKeepOnlyLastCommitDeletionPolicyзұ»пјҢеңЁдёҖдёӘж–°зҡ„жҸҗдәӨе®ҢжҲҗзҡ„ж—¶еҖҷе®ғдјҡ马дёҠжүҖжңүзҡ„дјҳе…ҲжҸҗдәӨпјҲprior commitпјүпјҲиҝҷеҢ№й…Қ2.2зүҲжң¬д№ӢеүҚзҡ„иЎҢдёәпјүгҖӮеҲӣе»әдҪ иҮӘе·ұзҡ„зӯ–з•ҘиғҪеӨҹе…Ғи®ёдҪ жҳҺзЎ®ең°пјҲexplicitlyпјүдҝқз•ҷд»ҘеүҚзҡ„вҖқpoint in timeвҖқжҸҗдәӨпјҲcommitпјүеңЁзҙўеј•дёӯеӯҳеңЁпјҲaliveпјүдёҖж®өж—¶й—ҙгҖӮдёәдәҶи®©readersеҲ·ж–°еҲ°ж–°зҡ„жҸҗдәӨпјҢеңЁе®ғ们д№ӢдёӢжІЎжңүиў«еҲ йҷӨзҡ„ж—§зҡ„жҸҗдәӨпјҲwithout having the old commit deleted out from under themпјүгҖӮиҝҷеҜ№йӮЈдәӣдёҚж”ҜжҢҒвҖңеңЁжңҖеҗҺе…ій—ӯж—¶жүҚеҲ йҷӨвҖқиҜӯд№үпјҲвҖқdelete on last closeвҖқВ semanticsпјүзҡ„ж–Ү件系з»ҹпјҲfilesystemпјүеҰӮNFSпјҢиҖҢиҝҷжҳҜLuceneзҡ„вҖңpoint in timeвҖқжЈҖзҙўйҖҡеёёжүҖдҫқиө–зҡ„пјҲnormally rely onпјүгҖӮ
В В
专家пјҲExpertпјүпјҡIndexWriterе…Ғи®ёдҪ еҲҶеҲ«дҝ®ж”№MergePolicyе’ҢMergeSchedulerгҖӮMergePolicyдјҡеңЁиҜҘзҙўеј•дёӯзҡ„segmentжңүжӣҙж”№зҡ„д»»дҪ•ж—¶еҖҷиў«и°ғз”ЁгҖӮе®ғзҡ„и§’иүІжҳҜйҖүжӢ©е“ӘдёҖдёӘmergeжқҘеҒҡпјҢеҰӮжһңжңүпјҲif anyпјүеҲҷдј еӣһдёҖдёӘMergePolicy.MergeSpecificatioжқҘжҸҸиҝ°иҝҷдәӣmergesгҖӮе®ғиҝҳдјҡйҖүжӢ©mergesжқҘдёәoptimize()еҒҡеӨ„зҗҶпјҢзјәзңҒжҳҜLogByteSizeMergePolicyгҖӮ然еҗҺMergeSchedulerдјҡйҖҡиҝҮдј йҖ’иҝҷдәӣmergesжқҘиў«и°ғз”ЁпјҢ并且е®ғеҶіе®ҡд»Җд№Ҳж—¶еҖҷе’ҢжҖҺд№Ҳж ·жқҘжү§иЎҢиҝҷдәӣmergesеӨ„зҗҶпјҢзјәзңҒжҳҜConcurrentMergeSchedulerгҖӮ
В В
В В
4.2.2В org.apache.lucene.index.DocumentsWriter
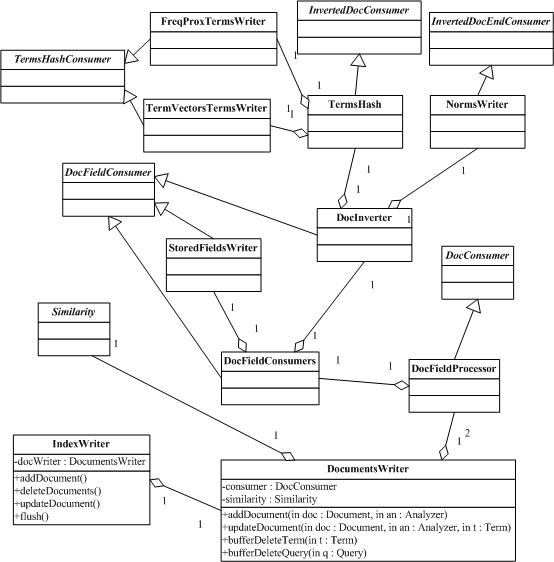
DocumentsWriterжҳҜз”ұIndexWriterи°ғз”ЁжқҘиҙҹиҙЈеӨ„зҗҶеӨҡдёӘж–ҮжЎЈзҡ„зұ»пјҢе®ғйҖҡиҝҮдёҺDirectoryзұ»еҸҠAnalyzerзұ»гҖҒScorerзұ»зӯүе°Ҷж–ҮжЎЈеҶ…е®№жҸҗеҸ–еҮәжқҘпјҢ并еҲҶи§ЈжҲҗдёҖз»„termеҲ—иЎЁеҶҚз”ҹжҲҗдёҖдёӘеҚ•дёҖзҡ„segmentжүҖйңҖиҰҒзҡ„ж•°жҚ®ж–Ү件пјҢеҰӮtermйў‘зҺҮгҖҒtermдҪҚзҪ®гҖҒtermеҗ‘йҮҸзӯүзҙўеј•ж–Ү件пјҢд»ҘдҫҝSegmentMergerе°Ҷе®ғеҗҲ并еҲ°з»ҹдёҖзҡ„segmentдёӯеҺ»гҖӮд»ҘдёӢжҳҜе®ғзҡ„зұ»еӣҫпјҡВ В В В В В В В В
В В В
В
 В В В
В В В
иҜҘзұ»еҸҜжҺҘ收еӨҡдёӘж·»еҠ зҡ„ж–ҮжЎЈпјҢ并且зӣҙжҺҘеҶҷжҲҗдёҖдёӘеҚ•зӢ¬зҡ„segmentж–Ү件гҖӮиҝҷжҜ”дёәжҜҸдёҖдёӘж–ҮжЎЈеҲӣе»әдёҖдёӘsegmentпјҲдҪҝз”ЁDocumentWriterпјүд»ҘеҸҠеҜ№йӮЈдәӣsegmentsжү§иЎҢеҗҲдҪңеӨ„зҗҶжӣҙжңүж•ҲзҺҮгҖӮ
В В
жҜҸдёҖдёӘж·»еҠ зҡ„ж–ҮжЎЈйғҪиў«дј йҖ’з»ҷDocConsumerзұ»пјҢе®ғеӨ„зҗҶиҜҘж–Ү档并且дёҺзҙўеј•й“ҫиЎЁдёӯпјҲindexing chainпјүе…¶е®ғзҡ„consumersзӣёдә’еҸ‘з”ҹдҪңз”ЁпјҲinteracts withпјүгҖӮзЎ®е®ҡзҡ„consumersпјҢе°ұеғҸStoredFieldWriterе’ҢTermVectorsTermsWriterпјҢжҸҗеҸ–дёҖдёӘж–ҮжЎЈзҡ„ж‘ҳиҰҒпјҲdigestпјүпјҢ并且马дёҠжҠҠеӯ—иҠӮеҶҷе…ҘвҖңж–ҮжЎЈеӯҳеӮЁвҖқж–Ү件пјҲжҜ”еҰӮе®ғ们дёҚдёәжҜҸдёҖдёӘж–ҮжЎЈж¶ҲиҖ—пјҲconsumeпјүеҶ…еӯҳRAMпјҢйҷӨдәҶеҪ“е®ғ们жӯЈеңЁеӨ„зҗҶж–ҮжЎЈзҡ„ж—¶еҖҷпјүгҖӮ
В В
е…¶е®ғзҡ„consumersпјҢжҜ”еҰӮFreqProxTermsWriterе’ҢNormsWriterпјҢдјҡзј“еӯҳеӯ—иҠӮеңЁеҶ…еӯҳдёӯпјҢеҸӘжңүеҪ“дёҖдёӘж–°зҡ„segmentеҲ¶йҖ еҮәзҡ„ж—¶еҖҷжүҚдјҡflushеҲ°зЈҒзӣҳдёӯгҖӮ
В В
дёҖж—ҰдҪҝз”Ёе®ҢжҲ‘们еҲҶй…Қзҡ„RAMзј“еӯҳпјҢжҲ–иҖ…е·Іж·»еҠ зҡ„ж–ҮжЎЈж•°зӣ®и¶іеӨҹеӨҡзҡ„ж—¶еҖҷпјҲиҝҷж—¶еҖҷжҳҜж №жҚ®ж·»еҠ зҡ„ж–ҮжЎЈж•°зӣ®иҖҢдёҚжҳҜRAMзҡ„дҪҝз”ЁзҺҮжқҘзЎ®е®ҡжҳҜеҗҰflushпјүпјҢжҲ‘们е°ҶеҲӣе»әдёҖдёӘзңҹе®һзҡ„segmentпјҢ并е°Ҷе®ғеҶҷе…ҘDirectoryдёӯеҺ»гҖӮВ
В
http://www.cnblogs.com/eaglet/archive/2009/02/16/1391502.html



зӣёе…іжҺЁиҚҗ
ж Үйўҳдёӯзҡ„".NET Lucene жәҗд»Јз Ғ"иЎЁжҳҺжҲ‘们е°ҶжҺўи®Ёзҡ„жҳҜеҰӮдҪ•еңЁ.NETзҺҜеўғдёӢеҲ©з”ЁLuceneиҝӣиЎҢжҗңзҙўеј•ж“Һзҡ„ејҖеҸ‘пјҢ并且дјҡж¶үеҸҠеҲ°жәҗд»Јз ҒеұӮйқўзҡ„и§ЈжһҗгҖӮжҸҸиҝ°дёӯжҸҗеҲ°зҡ„вҖңз®ҖеҚ•жҳ“з”ЁвҖқпјҢжҸӯзӨәдәҶLuceneзҡ„ж ёеҝғзү№жҖ§д№ӢдёҖпјҢеҚіе®ғеҜ№ејҖеҸ‘иҖ…еҸӢеҘҪпјҢжҳ“дәҺ...
гҖҠLuceneжәҗд»Јз Ғеү–жһҗгҖӢжҳҜдёҖжң¬ж·ұеәҰжҺўи®ЁJavaзүҲжң¬Luceneжҗңзҙўеј•ж“Һеә“зҡ„дё“дёҡд№ҰзұҚгҖӮLuceneжҳҜApacheиҪҜ件еҹәйҮ‘дјҡзҡ„дёҖдёӘејҖжәҗйЎ№зӣ®пјҢе№ҝжіӣеә”з”ЁдәҺе…Ёж–ҮжЈҖзҙўе’ҢдҝЎжҒҜжЈҖзҙўйўҶеҹҹгҖӮжң¬д№Ұж—ЁеңЁйҖҡиҝҮж·ұе…Ҙи§Јжһҗе…¶жәҗд»Јз ҒпјҢеё®еҠ©ејҖеҸ‘иҖ…зҗҶи§ЈLuceneзҡ„е·ҘдҪң...
гҖҠж·ұе…Ҙеү–жһҗLucene.NETпјҡеҹәдәҺжәҗд»Јз Ғзҡ„е®һдҫӢи§ЈжһҗгҖӢ Lucene.NETпјҢдҪңдёәApache Luceneзҡ„.NETзүҲжң¬пјҢжҳҜдёҖдёӘй«ҳжҖ§иғҪгҖҒе…Ёж–ҮжЈҖзҙўеә“пјҢдёә.NETејҖеҸ‘иҖ…жҸҗдҫӣдәҶејәеӨ§зҡ„ж–Үжң¬жҗңзҙўеҠҹиғҪгҖӮжң¬е®һдҫӢе°ҶеёҰжӮЁж·ұе…ҘзҗҶи§ЈLucene.NETзҡ„еҶ…йғЁжңәеҲ¶пјҢйҖҡиҝҮжәҗ...
- йҖҡиҝҮйҳ…иҜ»жәҗд»Јз ҒпјҢеҸҜд»ҘзҗҶи§ЈLuceneзҡ„еҶ…йғЁе·ҘдҪңеҺҹзҗҶпјҢеҰӮеҰӮдҪ•жһ„е»әзҙўеј•гҖҒжү§иЎҢжҹҘиҜўзӯүгҖӮ - еҲҶжһҗеҷЁйғЁеҲҶзҡ„жәҗз ҒжңүеҠ©дәҺдәҶи§Јж–Үжң¬йў„еӨ„зҗҶиҝҮзЁӢпјҢеҢ…жӢ¬еҲҶиҜҚгҖҒеҺ»йҷӨеҒңз”ЁиҜҚзӯүгҖӮ - жҺўз©¶жҹҘиҜўи§ЈжһҗеҷЁзҡ„е®һзҺ°пјҢжҺҢжҸЎеҰӮдҪ•е°ҶиҮӘ然иҜӯиЁҖиҪ¬еҢ–дёә...
гҖҠLucene-2.3.1 жәҗд»Јз Ғйҳ…иҜ»еӯҰд№ гҖӢ LuceneжҳҜApacheиҪҜ件еҹәйҮ‘дјҡзҡ„дёҖдёӘејҖж”ҫжәҗз ҒйЎ№зӣ®пјҢе®ғжҳҜдёҖдёӘй«ҳжҖ§иғҪгҖҒе…Ёж–Үжң¬жҗңзҙўеә“пјҢдёәејҖеҸ‘иҖ…жҸҗдҫӣдәҶеңЁJavaеә”з”ЁзЁӢеәҸдёӯе®һзҺ°е…Ёж–ҮжЈҖзҙўеҠҹиғҪзҡ„еҹәзЎҖжһ¶жһ„гҖӮжң¬зҜҮж–Үз« е°Ҷж·ұе…ҘжҺўи®ЁLucene 2.3.1зүҲжң¬...
еңЁиҝҷдёӘеҺӢзј©еҢ…ж–Ү件дёӯпјҢеҢ…еҗ«зҡ„жәҗд»Јз ҒзқҖйҮҚеұ•зӨәдәҶеҰӮдҪ•еҲ©з”ЁLuceneиҝӣиЎҢзҙўеј•еҲӣе»әе’Ңжҗңзҙўж“ҚдҪңпјҢиҝҷдәӣйғҪжҳҜLuceneзҡ„ж ёеҝғеҠҹиғҪгҖӮ йҰ–е…ҲпјҢи®©жҲ‘们дәҶи§ЈдёҖдёӢLuceneзҡ„зҙўеј•еҲӣе»әиҝҮзЁӢгҖӮеңЁLuceneдёӯпјҢж•°жҚ®иў«иҪ¬еҢ–дёәдёҖз§ҚдҫҝдәҺжҗңзҙўзҡ„з»“жһ„вҖ”вҖ”еҖ’жҺ’...
ејҖеҸ‘иҖ…еҸҜд»ҘжҹҘзңӢе’Ңдҝ®ж”№жәҗд»Јз ҒпјҢдәҶи§Јзҙўеј•жһ„е»әгҖҒжҹҘиҜўи§ЈжһҗгҖҒжҗңзҙўжү§иЎҢзӯүж ёеҝғжөҒзЁӢпјҢиҝҷеҜ№дәҺејҖеҸ‘иҮӘе®ҡд№үзҡ„жҗңзҙўеј•ж“ҺжҲ–жү©еұ•зҺ°жңүеҠҹиғҪйқһеёёжңүз”ЁгҖӮйҖҡиҝҮеӯҰд№ CLuceneпјҢдҪ еҸҜд»ҘжҺҢжҸЎеҰӮдҪ•еңЁC++дёӯе®һзҺ°й«ҳж•Ҳзҡ„ж–Үжң¬еҲҶжһҗгҖҒзҙўеј•жһ„е»әе’Ңжҗңзҙўзӯ–з•ҘгҖӮ...
ApacheйҮҮз”Ёзҡ„жҳҜApache License 2.0пјҢиҝҷжҳҜдёҖз§Қе®Ҫжқҫзҡ„ејҖжәҗи®ёеҸҜпјҢе…Ғи®ёз”ЁжҲ·иҮӘз”ұең°дҪҝз”ЁгҖҒеӨҚеҲ¶гҖҒдҝ®ж”№гҖҒеҗҲ并гҖҒеҸ‘еёғгҖҒеҲҶеҸ‘гҖҒеҶҚжҺҲжқғе’Ң/жҲ–й”Җе”®иҪҜ件пјҢеҗҢж—¶д№ҹе…Ғи®ёз”ЁжҲ·д»Ҙжәҗд»Јз ҒжҲ–зј–иҜ‘еҗҺзҡ„еҪўејҸеҲҶеҸ‘гҖӮдәҶи§Ји®ёеҸҜжқЎж¬ҫеҜ№дәҺйҒөеҫӘејҖжәҗзӨҫеҢә...
гҖҠж·ұе…ҘзҗҶи§ЈLukeпјҡLuceneзҙўеј•жҹҘзңӢе·Ҙе…·зҡ„жәҗд»Јз Ғи§ЈжһҗгҖӢ LukeпјҢдҪңдёәдёҖдёӘејҖжәҗзҡ„Luceneзҙўеј•жөҸи§ҲеҷЁпјҢдёәејҖеҸ‘иҖ…жҸҗдҫӣдәҶзӣҙжҺҘжҹҘзңӢе’ҢеҲҶжһҗLuceneзҙўеј•зҡ„иғҪеҠӣгҖӮе®ғдёҚд»…жҳҜдёҖдёӘејәеӨ§зҡ„е·Ҙе…·пјҢд№ҹжҳҜеӯҰд№ Luceneзҙўеј•жңәеҲ¶зҡ„йҮҚиҰҒйҖ”еҫ„гҖӮйҖҡиҝҮйҳ…иҜ»...
### Lucene3.0еҲӣе»әзҙўеј• еңЁLucene3.0дёӯеҲӣе»әзҙўеј•жҳҜдёҖдёӘе…ій”®еҠҹиғҪпјҢеҸҜд»Ҙеё®еҠ©з”ЁжҲ·еҝ«йҖҹең°жЈҖзҙўе’Ңз®ЎзҗҶеӨ§йҮҸзҡ„ж–Үжң¬ж•°жҚ®гҖӮжң¬зҜҮж–Үз« е°ҶиҜҰз»Ҷд»Ӣз»ҚеҰӮдҪ•дҪҝз”ЁLucene3.0жқҘеҲӣе»әзҙўеј•пјҢ并йҖҡиҝҮдёҖдёӘе…·дҪ“зҡ„дҫӢеӯҗжқҘжј”зӨәж•ҙдёӘиҝҮзЁӢгҖӮ #### дёҖгҖҒ...
иҝҷдёӘжәҗд»Јз ҒзүҲжң¬д»ЈиЎЁдәҶLucene 3.xзі»еҲ—зҡ„жңҖеҗҺдёҖдёӘзЁіе®ҡзүҲжң¬пјҢдёәејҖеҸ‘иҖ…жҸҗдҫӣдәҶж·ұе…ҘзҗҶи§ЈLuceneеҶ…йғЁжңәеҲ¶зҡ„е®қиҙөиө„жәҗгҖӮдёӢйқўе°ҶиҜҰз»ҶжҺўи®ЁLucene 3.6.2дёӯзҡ„е…ій”®зҹҘиҜҶзӮ№гҖӮ 1. **еҲҶиҜҚеҷЁпјҲTokenizersпјү**: Luceneзҡ„ж ёеҝғеҠҹиғҪд№ӢдёҖжҳҜ...
гҖҠж·ұе…ҘзҗҶи§ЈLucene 3.0.1пјҡеә“дёҺжәҗд»Јз Ғи§ЈжһҗгҖӢ LuceneжҳҜдёҖдёӘејҖжәҗе…Ёж–Үжҗңзҙўеј•ж“Һеә“пјҢз”ұApacheиҪҜ件еҹәйҮ‘дјҡејҖеҸ‘并з»ҙжҠӨгҖӮиҝҷдёӘвҖңlucene-3.0.1вҖқзүҲжң¬д»ЈиЎЁдәҶLuceneеңЁ2009е№ҙзҡ„дёҖдёӘйҮҚиҰҒйҮҢзЁӢзў‘пјҢе®ғжҸҗдҫӣдәҶејәеӨ§зҡ„ж–Үжң¬жЈҖзҙўеҠҹиғҪпјҢиў«е№ҝжіӣ...
1. **LuceneжҰӮиҝ°**: LuceneжҳҜApacheиҪҜ件еҹәйҮ‘дјҡзҡ„дёҖдёӘејҖж”ҫжәҗд»Јз ҒйЎ№зӣ®пјҢе®ғжҳҜJavaиҜӯиЁҖзј–еҶҷзҡ„дҝЎжҒҜжЈҖзҙўеә“гҖӮе®ғжҸҗдҫӣдәҶй«ҳзә§зҡ„зҙўеј•е’ҢжҗңзҙўеҠҹиғҪпјҢж”ҜжҢҒеҲҶиҜҚгҖҒеёғе°”иҝҗз®—гҖҒзҹӯиҜӯжҗңзҙўгҖҒиҝ‘дјјжҗңзҙўзӯүеӨҡз§ҚжҗңзҙўжЁЎејҸгҖӮ 2. **Luceneж ёеҝғ组件...
з”ұдәҺжҸҸиҝ°дёӯжҸҗеҲ°вҖңе·Ізј–иҜ‘пјҢдёҚеҗ«жәҗд»Јз ҒвҖқпјҢиҝҷж„Ҹе‘ізқҖжҸҗдҫӣзҡ„ж–Ү件жҳҜзј–иҜ‘еҗҺзҡ„дәҢиҝӣеҲ¶зүҲжң¬пјҢз”ЁжҲ·еҸҜд»ҘзӣҙжҺҘеңЁ.NETзҺҜеўғдёӯдҪҝз”ЁпјҢиҖҢж— йңҖиҮӘиЎҢзј–иҜ‘жәҗд»Јз ҒгҖӮ Lucene.Netзҡ„ж ёеҝғеҠҹиғҪеҢ…жӢ¬пјҡ 1. **е…Ёж–ҮжЈҖзҙў**пјҡLucene.Netж”ҜжҢҒеҜ№ж–Үжң¬...
йҖҡиҝҮйҳ…иҜ»е’ҢеҲҶжһҗжәҗд»Јз ҒпјҢжҲ‘们еҸҜд»ҘеӯҰд№ еҲ°еҰӮдҪ•ж“ҚдҪңLuceneзҙўеј•пјҢд»ҘеҸҠеҰӮдҪ•жһ„е»әзұ»дјјзҡ„е·Ҙе…·гҖӮ жҖ»з»“иҖҢиЁҖпјҢlukeдҪңдёәLuceneзҙўеј•зҡ„еҸҜи§ҶеҢ–е·Ҙе…·пјҢжһҒеӨ§ең°дҫҝеҲ©дәҶејҖеҸ‘иҖ…еҜ№зҙўеј•зҡ„зҗҶи§Је’Ңи°ғиҜ•гҖӮж— и®әжҳҜеҲқеӯҰиҖ…иҝҳжҳҜз»ҸйӘҢдё°еҜҢзҡ„ејҖеҸ‘дәәе‘ҳпјҢйғҪ...
LuceneжҳҜApacheиҪҜ件еҹәйҮ‘дјҡзҡ„дёҖдёӘејҖж”ҫжәҗд»Јз ҒйЎ№зӣ®пјҢе®ғжҳҜдёҖдёӘе…Ёж–Үжҗңзҙўеј•ж“Һеә“пјҢжҸҗдҫӣдәҶж–Үжң¬еҲҶжһҗгҖҒзҙўеј•е’Ңжҗңзҙўзҡ„еҹәжң¬еҠҹиғҪгҖӮ 1. **Luceneз®Җд»Ӣ** LuceneжҳҜдёҖдёӘй«ҳжҖ§иғҪгҖҒе…Ёж–Үжң¬жЈҖзҙўеә“пјҢеҸҜйӣҶжҲҗеҲ°еҗ„з§Қзі»з»ҹдёӯпјҢз”ЁдәҺжһ„е»әејәеӨ§зҡ„...
Luceneзҡ„ж ёеҝғеҠҹиғҪеҢ…жӢ¬ж–Үжң¬еҲҶжһҗгҖҒзҙўеј•еҲӣе»әгҖҒжҹҘиҜўи§Јжһҗе’Ңз»“жһңжҺ’еәҸгҖӮз”ұдәҺе…¶ејҖж”ҫжәҗд»Јз Ғзҡ„зү№жҖ§пјҢејҖеҸ‘иҖ…еҸҜд»Ҙж №жҚ®иҮӘе·ұзҡ„йңҖжұӮиҝӣиЎҢе®ҡеҲ¶е’Ңжү©еұ•гҖӮ дёүгҖҒLuceneзҡ„еә”з”ЁгҖҒзү№зӮ№еҸҠдјҳеҠҝ Luceneиў«е№ҝжіӣеә”з”ЁдәҺеҗ„з§ҚеңәжҷҜпјҢеҰӮзҪ‘з«ҷжҗңзҙўеј•ж“ҺгҖҒ...
Lucene.NetжҸҗдҫӣдәҶеӨҡз§ҚеҶ…зҪ®еҲҶжһҗеҷЁпјҢеҰӮж ҮеҮҶеҲҶжһҗеҷЁпјҲStandardAnalyzerпјүгҖҒзӣҳеҸӨеҲҶжһҗеҷЁпјҲPanguAnalyzerпјүпјҢд№ҹеҸҜиҮӘе®ҡд№үеҲҶжһҗеҷЁд»Ҙж»Ўи¶ізү№е®ҡзҡ„иҜӯиЁҖжҲ–дёҡеҠЎйңҖжұӮгҖӮ 3. **ж–ҮжЎЈпјҲDocumentпјү**пјҡж–ҮжЎЈжҳҜдҝЎжҒҜзҡ„еҹәжң¬еҚ•дҪҚпјҢеҸҜд»ҘеҢ…еҗ«еӨҡдёӘ...
гҖҠApache Lucene 2.9.4жәҗд»Јз Ғи§ЈжһҗгҖӢ Apache LuceneжҳҜдёҖдёӘејҖжәҗе…Ёж–Үжҗңзҙўеј•ж“Һеә“пјҢз”ұJavaзј–еҶҷпјҢиў«е№ҝжіӣеә”з”ЁдәҺеҗ„з§Қжҗңзҙўеә”з”Ёдёӯ...ж— и®әжҳҜеҜ№жҗңзҙўжҠҖжңҜзҡ„жҺўзҙўпјҢиҝҳжҳҜеңЁе®һйҷ…йЎ№зӣ®дёӯзҡ„еә”з”ЁпјҢж·ұе…Ҙз ”з©¶Luceneжәҗд»Јз ҒйғҪиғҪеёҰжқҘжһҒеӨ§зҡ„收зӣҠгҖӮ