Sample Data
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0
-
Pearson correlation–based similarity
The Pearson correlation(Pearson Product Moment Correlation) is a number between –1 and 1 that measures the tendency of two series of numbers, paired up one-to-one, to move together. That is to say, it measures how likely a number in one series is to be relatively large when the corresponding number in the other series is high, and vice versa. It measures the tendency of the numbers to move together proportionally, such that there’s a roughly linear relationship between the values in one series and the other. When this tendency is high,the correlation is close to 1. When there appears to be little relationship at all, the value is near 0. When there appears to be an opposing relationship—one series’ numbers are high exactly when the other series’ numbers are low—the value is near –1.
It measures the tendency of two users’ preference values to move together—to be relatively high, or relatively low, on the same items.
Formula

The similarity computation can only operate on items that both users have expressed a preference for.

Pearson correlation problems
First, it doesn’t take into account the number of items in which two users’ preferences overlap, which is probably a weakness in the context of recommender engines.
Second, if two users overlap on only one item, no correlation can be computed because of how the computation is defined.
Finally, the correlation is also undefined if either series of preference values are all
identical.
Class Constructor
PearsonCorrelationSimilarity(DataModel dataModel)
PearsonCorrelationSimilarity(DataModel dataModel, Weighting weighting)
-
Euclidean distance based similarity
This implementation is based on the distance between users. This idea makes sense if you think of users as points in a space of many dimensions (as many dimensions as there are items), whose coordinates are preference values.
Formula
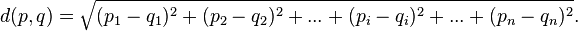 r=1/(1+d)
r=1/(1+d)

Class Constructor
EuclideanDistanceSimilarity(DataModel dataModel)
EuclideanDistanceSimilarity(DataModel dataModel, Weighting weighting)
-
cosine measure similarity
The cosine measure similarity is another similarity metric that depends on envisioning user preferences as points in space. Hold in mind the image of user preferences as points in an n-dimensional space. Now imagine two lines from the origin, or point (0,0,...,0), to each of these two points. When two users are similar, they’ll have similar ratings, and so will be relatively close in space—at least, they’ll be in roughly the same direction from the origin. The angle formed between these two lines will be relatively small. In contrast, when the two users are dissimilar, their points will be distant, and likely in different directions from the origin, forming a wide angle.
Formula

Class Constructor
PearsonCorrelationSimilarity(DataModel dataModel)
PearsonCorrelationSimilarity(DataModel dataModel, Weighting weighting)
-
Spearman correlation based similarity
The Spearman correlation is an interesting variant on the Pearson correlation, for our purposes. Rather than compute a correlation based on the original preference values, it computes a correlation based on the relative rank of preference values. Imagine that, for each user, their least-preferred item’s preference value is overwritten with a 1. Then the next-least-preferred item’s preference value is changed to 2, and so on. To illustrate this, imagine that you were rating movies and gave your least-preferred movie one star, the next-least favorite two stars, and so on. Then, a Pearson correlation is computed on the transformed values.

Class Constructor
SpearmanCorrelationSimilarity(DataModel dataModel)
Note:The Spearman correlation–based similarity metric is expensive to compute, and is therefore possibly more of academic interest than practical use.
CachingUserSimilarity
It is a UserSimilarity implementation that wraps another UserSimilarity implementation and caches its results. That is, it delegates computation to another, given implementation, and remembers those
results internally. Later, when it’s asked for a user-user similarity value that was previously computed, it can answer immediately rather than ask the given implementation to compute it again. In this way, you can add caching to any similarity implementation. When the cost of performing a computation is relatively high, as here, it can be worthwhile to employ. The cost, of course, is the memory consumed by the cache.
UserSimilarity similarity
= new CachingUserSimilarity(new SpearmanCorrelationSimilarity(model), model);
-
Ignoring preference values in similarity with the Tanimoto coefficient
The algorithm doesn’t care whether a user expresses a high or low preference for an item—only that the user expresses a preference at all.
Formula
 In other words, it’s the ratio of the size of the intersection to the size of the union of their preferred items.Note that this similarity metric doesn’t depend only on the items that both users have some preference for, but that either user has some preference for. Hence, all seven items appear in the calculation, unlike before.
In other words, it’s the ratio of the size of the intersection to the size of the union of their preferred items.Note that this similarity metric doesn’t depend only on the items that both users have some preference for, but that either user has some preference for. Hence, all seven items appear in the calculation, unlike before.
 Class Constructor
Class Constructor
TanimotoCoefficientSimilarity(DataModel dataModel)
-
Log-likelihood–based similarity
It is similar to the Tanimoto coefficient–based similarity, though it’s more difficult to understand intuitively. It’s another metric that doesn’t take account of individual preference values. Like the Tanimoto coeffi-
cient, it’s based on the number of items in common between two users, but its value is more an expression of how unlikely it is for two users to have so much overlap, given the total number of items out there and the number of items each user has a preference for.
With some statistical tests, this similarity metric attempts to determine just how strongly unlikely it is
that two users have no resemblance in their tastes; the more unlikely, the more similar the two should be. The resulting similarity value may be interpreted as a probability that the overlap isn’t due to chance.


Class Constructor
LogLikelihoodSimilarity(DataModel dataModel)
References
http://www.statisticshowto.com/what-is-the-pearson-correlation-coefficient/
http://www.socialresearchmethods.net/kb/statcorr.php
http://en.wikipedia.org/wiki/Cosine_similarity
Books

- 大小: 33 KB

- 大小: 4.7 KB

- 大小: 29 KB

- 大小: 2.8 KB

- 大小: 27.6 KB

- 大小: 32.7 KB

- 大小: 33 KB

- 大小: 21.7 KB

- 大小: 15.6 KB
分享到:




相关推荐
「防火墙」Exploring the Safari - 数据分析 数据安全 安全架构 安全知识 安全活动 云安全
标题《Art-Exploring-the-New-Android-KitKat-Runtime》中的知识点涵盖了Android KitKat操作系统版本中引入的新运行时环境(Runtime Environment),特别是ART(Android Runtime)的探索和分析。Android KitKat是...
### Exploring Expect: A Tcl-Based Toolkit for Automating Interactive Programs #### 概述 《Exploring Expect》这本书主要介绍了一个基于Tcl(Tool Command Language)的工具包——Expect,用于自动化处理交互...
Arduino-Exploring-Arduino-1st-Edition.zip,Jeremy Blumemexploring Arduino的书《探索Arduino》第一版的配套代码:第一版,Arduino是一家开源软硬件公司和制造商社区。Arduino始于21世纪初,深受电子制造商的欢迎,...
Build Swift playgrounds for others to use Teach yourself and others with Swift playgrounds Use Swift playgrounds in your development process
2. **Arduino板的选择** - **不同型号**:市场上有多种不同型号的Arduino板,例如Arduino Uno、Nano、Mega等,每种型号都有其特定的应用场景。 - **选择依据**:根据项目的具体需求(如所需的I/O数量、内存大小等...
这篇论文——"Stop-and-Go: Exploring Backdoor Attacks on Deep Reinforcement Learning-based Traffic Congestion Control Systems"揭示了DRL模型在交通管理中的潜在风险,即可能受到后门攻击(Backdoor Attack)...
This book is ideal for a one-semester course in statistics, offering a streamlined presentation of Introductory Statistics: Exploring the World through Data, by Gould/Ryan. Exploring the World through...
以下是关于“Exploring Transformer Basics”文档中的关键知识点总结。 ### 标题:Exploring Transformer Basics #### 变压器简介 变压器是一种利用电磁感应原理来改变交流电压水平的设备。它通常由三个主要部分...
标题中的“Project-Exploring-the-History-of-Lego”表明这是一个关于探究乐高积木历史的数据分析项目。在这个项目中,我们可能将深入研究乐高从成立以来的发展历程、产品的变化、销售趋势,以及可能影响其发展的...
DVB-S2 (Digital Video Broadcasting - Satellite 2) 是目前广泛应用于卫星广播的标准之一。该文探讨了如何将FTN技术融入现有的DVB-S2框架内,同时尽可能地保留原有标准的关键特性。这种融合旨在提升频谱效率,而不...
《SUMS88 探索数学——问题解决与证明》是由Daniel Grieser于2018年编著的一部数学教材,旨在帮助学生提升在解决问题和构建证明方面的能力。这本书深入浅出地探讨了数学的本质,特别是如何通过解决问题来理解和掌握...
This book starts with the benefits of .NET including its fundamental tasks and tools where you will learn .NET SDK tools and the ILDasm tool. This is followed by a detailed discussion on code ...
Beginning iPhone Development: Exploring the iPhone SDK by Dave Mark, Jeff LaMarche 一共两个压缩包
随着物联网设备的普及,这些问题变得更加复杂,因为它们可能成为黑客攻击的新目标,比如电动汽车充电器、汽车OBD2诊断适配器甚至家用电器。 针对物联网设备的攻击形式多样,包括通过无线更新“砖化”设备,利用不...