
µû░µëïµÉ×hadoopµ£ÇÕñ┤þû╝ÕÉäþºìÕÉäµáÀþÜäÚù«Úóÿõ║å´╝îµêæµèèÞç¬ÕÀ▒ÚüçÕê░þÜäÚù«Úóÿõ╗ÑÕÅèÞºúÕå│Õè×µ│òÕñºÞç┤µò┤þÉåõ©Çõ©ïÕàê´╝îÕ©îµ£øÕ»╣õ¢áõ╗¼µ£ëµëÇÕ©«Õè®ÒÇé
õ©ÇÒÇühadoopÚøåþ¥ñÕ£¿namenodeµá╝Õ╝ÅÕîû´╝êbin/hadoop namenode -format´╝ëÕÉÄÚçìÕÉ»Úøåþ¥ñõ╝ÜÕç║þÄ░Õªéõ©ï
Incompatible namespaceIDS in ... :namenode namespaceID = ... ,datanode namespaceID=...
ÚöÖÞ»»´╝îÕăÕøáµÿ»µá╝Õ╝ÅÕîûnamenodeÕÉÄõ╝ÜÚçìµû░ÕêøÕ╗║õ©Çõ©¬µû░þÜänamespaceID,õ╗ÑÞç│õ║ÄÕÆîdatanodeõ©èÕăµ£ëþÜäõ©ìõ©ÇÞç┤ÒÇé
ÞºúÕå│µû╣µ│ò´╝Ü
- ÕêáÚÖñdatanode dfs.data.dirþø«Õ¢ò´╝êÚ╗ÿÞ«ñõ©║tmp/dfs/data´╝ëõ©ïþÜäµò░µì«µûçõ╗Â
- õ┐«µö╣dfs.data.dir/current/VERSION µûçõ╗´╝îµèènamespaceIDõ┐«µêÉõ©Änamenodeõ©èþø©ÕÉîÕì│ÕÅ»´╝êlogÚöÖÞ»»Úçîõ╝ܵ£ëµÅÉþñ║´╝ë
- Úçìµû░µîçիܵû░þÜädfs.data.dirþø«Õ¢ò
õ║îÒÇühadoopÚøåþ¥ñÕÉ»Õè¿start-all.shþÜäµùÂÕÇÖ´╝îslaveµÇ╗µÿ»µùáµ│òÕÉ»Õè¿datanode´╝îÕ╣Âõ╝ܵèÑÚöÖ´╝Ü
... could only be replicated to 0 nodes, instead of 1 ...
Õ░▒µÿ»µ£ëÞèéþé╣þÜäµáçÞ»åÕÅ»Þâ¢ÚçìÕñì´╝êõ©¬õ║║Þ«ñõ©║Þ┐Öõ©¬ÚöÖÞ»»þÜäÕăÕøá´╝ëÒÇéõ╣ƒÕÅ»Þ⢵£ëÕàÂõ╗ûÕăÕøá´╝îõ©Çõ©ïÞºúÕå│µû╣µ│òÞ»Àõ¥Øµ¼íÕ░ØÞ»ò´╝îµêæµÿ»ÞºúÕå│õ║åÒÇé
ÞºúÕå│µû╣µ│ò´╝Ü
- ÕêáÚÖñµëǵ£ëÞèéþé╣dfs.data.dirÕÆîdfs.tmp.dirþø«Õ¢ò´╝êÚ╗ÿÞ«ñõ©║tmp/dfs/dataÕÆîtmp/dfs/tmp´╝ëõ©ïþÜäµò░µì«µûçõ╗´╝øþäÂÕÉÄÚçìµû░hadoop namenode -format µá╝Õ╝ÅÕîûÞèéþé╣´╝øþäÂÕÉÄÕÉ»Õè¿ÒÇé
- Õªéµ×£µÿ»þ½»ÕÅúÞ«┐Úù«þÜäÚù«Úóÿ´╝îõ¢áÕ║öÞ»Ñþí«õ┐صëÇþö¿þÜäþ½»ÕÅúÚ⢵ëôÕ╝Ç´╝îµ»öÕªéhdfs://machine1:9000/ÒÇü50030ÒÇü50070õ╣ïþ▒╗þÜäÒÇéµëºÞíî#iptables -I INPUT -p tcp --dport 9000 -j ACCEPT Õæ¢õ╗ñÒÇéÕªéµ×£Þ┐ÿµ£ëµèÑÚöÖ´╝Ühdfs.DFSClient: Exception in createBlockOutputStream java.net.ConnectException: Connection refused´╝øÕ║ö޻ѵÿ»datanodeõ©èþÜäþ½»ÕÅúõ©ìÞâ¢Þ«┐Úù«´╝îÕê░datanodeõ©èõ┐«µö╣iptables´╝Ü#iptables -I INPUT -s machine1 -p tcp -j ACCEPT
- Þ┐ÿµ£ëÕÅ»Þ⢵ÿ»Úÿ▓þü½ÕóÖþÜäÚÖÉÕêÂÚøåþ¥ñÚù┤þÜäõ║Æþø©ÚÇÜõ┐íÒÇéÕ░ØÞ»òÕà│Úù¡Úÿ▓þü½ÕóÖÒÇé/etc/init.d/iptables stop
- µ£ÇÕÉÄÞ┐ÿµ£ëÕÅ»Þâ¢þúüþøÿþ®║Úù┤õ©ìÕñƒõ║å´╝îÞ»ÀµƒÑþ£ï df -al
- µêæÕ£¿ÞºúÕå│Þ┐Öõ©¬Úù«ÚóÿþÜäµùÂÕÇÖÞ┐ÿµ£ëõ║║Þ»┤´╝ÜÕàêÕÉÄÕÉ»Õè¿namenodeÒÇüdatanodeÕÅ»õ╗ÑÞºúÕå│Þ┐Öõ©¬Úù«Úóÿ´╝êµ£¼õ║║Õ░ØÞ»òÕÅæþÄ░µ▓íþö¿´╝îÕñºÕ«ÂÕÅ»õ╗ÑÞ»òÞ»ò´╝ë$hadoop-daemon.sh start namenode ´╝ø $hadoop-daemon.sh start datanode
õ©ëÒÇüþ¿ïÕ║ŵëºÞíîÕç║þÄ░Error: java.lang.NullPointerException
þ®║µîçÚÆêÕ╝éÕ©©´╝îþí«õ┐Øjavaþ¿ïÕ║ÅþÜ䵡úþí«ÒÇéÕÅÿÚçÅõ╗Çõ╣êþÜäõ¢┐þö¿ÕëìÕàêÕ«×õ¥ïÕîûÕú░µÿÄ´╝îõ©ìÞªüµ£ëµò░þ╗äÞÂèþòîõ╣ïþ▒╗þÜäþÄ░Þ▒íÒÇéµúǵƒÑþ¿ïÕ║ÅÒÇé
ÕøøÒÇüµëºÞíîÞç¬ÕÀ▒þÜäþ¿ïÕ║ÅþÜäµùÂÕÇÖ´╝î´╝êÕÉäþºì´╝ëµèÑÚöÖ´╝îÞ»Àþí«õ┐Øõ©Çõ©ïµâàÕåÁ´╝Ü
- ÕëìµÅÉÚ⢵ÿ»õ¢áþÜäþ¿ïÕ║ŵÿ»µ¡úþí«ÚÇÜÞ┐çþ╝ûÞ»æþÜä
- Úøåþ¥ñµ¿íÕ╝Åõ©ï´╝îÞ»ÀµèèÞªüÕñäþÉåþÜäµò░µì«ÕåÖÕê░HDFSÚçî´╝îÕ╣Âõ©öþí«õ┐ØHDFSÞÀ»Õ¥äµ¡úþí«
- µîçիܵëºÞíîþÜäjarÕîàþÜäÕàÑÕÅúþ▒╗ÕÉì´╝êµêæõ©ìþƒÑÚüôõ©║õ╗Çõ╣êµ£ëµùÂÕÇÖõ©ìµîçÕ«Üõ╣ƒµÿ»ÕÅ»õ╗ÑÞ┐ÉÞíîþÜä´╝ë
µ¡úþí«þÜäÕåÖµ│òþ▒╗õ╝╝´╝Ü
$ hadoop jar myCount.jar myCount input output
õ║öÒÇüsshµùáµ│òµ¡úÕ©©ÚÇÜõ┐íþÜäÚù«Úóÿ´╝îÞ┐Öõ©¬Úù«ÚóÿµêæÕ£¿µÉ¡Õ╗║þ»çÚçîµ£ëÞ»ªþ╗åµÅÉÕê░Þ┐çÒÇé
Õà¡ÒÇüþ¿ïÕ║Åþ╝ûÞ»æÚù«Úóÿ´╝îÕÉäþºìÕîàµ▓íµ£ëþÜäµâàÕåÁ´╝îÞ»Àþí«õ┐Øõ¢áµèèhadoopþø«Õ¢òõ©ï ÕÆîhadoop/libþø«Õ¢òõ©ïþÜäjarÕîàÚ⢵£ëÕ╝òÕàÑÒÇéÞ»ªþ╗åµâàÕåÁõ╣ƒµÿ»þ£ïµÉ¡Õ╗║þ»çÚçîþÜäµôìõ¢£ÒÇé
õ©âÒÇüHadoopÕÉ»Õè¿datanodeµùÂÕç║þÄ░Unrecognized option: -jvm ÕÆî Could not create the Java virtual machine.
Õ£¿hadoopÕ«ëÞúàþø«Õ¢ò/bin/hadoopõ©¡µ£ëÕªéõ©ïõ©Çµ«Áshell:
1 2 3 4 5 6 |
CLASS='org.apache.hadoop.hdfs.server.datanode.DataNode'
if [[ $EUID -eq 0 ]]; then
HADOOP_OPTS="$HADOOP_OPTS -jvm server $HADOOP_DATANODE_OPTS"
else
HADOOP_OPTS="$HADOOP_OPTS -server $HADOOP_DATANODE_OPTS"
fi
|
$EUID Þ┐ÖÚçîþÜäþö¿µêÀµáçÞ»å´╝îÕªéµ×£µÿ»rootþÜä޻ش╝îÞ┐Öõ©¬µáçÞ»åõ╝ܵÿ»0´╝îµëÇõ╗ÑÕ░¢ÚçÅõ©ìÞªüõ¢┐þö¿rootþö¿µêÀµØѵôìõ¢£hadoopÕ░▒ÕÑ¢õ║åÒÇéÞ┐Öõ╣ƒµÿ»µêæÕ£¿Úàìþ¢«þ»çÚçîµÅÉÕê░õ©ìÞªüõ¢┐þö¿rootþö¿µêÀþÜäÕăÕøáÒÇé
Õà½ÒÇüÕªéµ×£Õç║þÄ░þ╗êþ½»þÜäÚöÖÞ»»õ┐íµü»µÿ»´╝Ü
ERROR hdfs.DFSClient: Exception closing file /user/hadoop/musicdata.txt : java.io.IOException: All datanodes 10.210.70.82:50010 are bad. Aborting...
Þ┐ÿµ£ëjobtracker logþÜäµèÑÚöÖõ┐íµü»
Error register getProtocolVersion
java.lang.IllegalArgumentException: Duplicate metricsName:getProtocolVersion
ÕÆîÕÅ»Þâ¢þÜäõ©Çõ║øÞ¡ªÕæèõ┐íµü»´╝Ü
WARN hdfs.DFSClient: DataStreamer Exception: java.io.IOException: Broken pipe
WARN hdfs.DFSClient: DFSOutputStream ResponseProcessor exception for block blk_3136320110992216802_1063java.io.IOException: Connection reset by peer
WARN hdfs.DFSClient: Error Recovery for block blk_3136320110992216802_1063 bad datanode[0] 10.210.70.82:50010 put: All datanodes 10.210.70.82:50010 are bad. Aborting...
ÞºúÕå│Õè×µ│ò´╝Ü
- µƒÑþ£ïdfs.data.dirÕ▒׵ǺµëǵîçþÜäÞÀ»Õ¥äµÿ»ÕɪþúüþøÿÕÀ▓þ╗ŵ╗íõ║å´╝îÕªéµ×£µ╗íõ║åÕêÖÞ┐øÞíîÕñäþÉåÕÉÄÕåìµ¼íÕ░ØÞ»òhadoop fs -putµò░µì«ÒÇé
- Õªéµ×£þø©Õà│þúüþøÿµ▓íµ£ëµ╗í´╝îÕêÖÚ£ÇÞªüµÄƵƒÑþø©Õà│þúüþøÿµ▓íµ£ëÕØŵëçÕî║´╝îÚ£ÇÞªüµúǵÁïÒÇé
õ╣ØÒÇüÕªéµ×£Õ£¿µëºÞíîhadoopþÜäjarþ¿ïÕ║ŵùÂÕ¥ùÕê░µèÑÚöÖõ┐íµü»´╝Ü
java.io.IOException: Type mismatch in key from map: expected org.apache.hadoop.io.NullWritable, recieved org.apache.hadoop.io.LongWritable
µêûÞÇàþ▒╗õ╝╝´╝Ü
Status : FAILED java.lang.ClassCastException: org.apache.hadoop.io.LongWritable cannot be cast to org.apache.hadoop.io.Text
Úéúõ╣êõ¢áÚ£ÇÞªüÕ¡ªõ╣áhadoopµò░µì«þ▒╗Õ×ïÕÆî map/reduceµ¿íÕ×ïþÜäÕƒ║µ£¼þƒÑÞ»åÒÇéµêæþÜäÞ┐Öþ»çÞ»╗õ╣ªþ¼öÞ«░ÚçîÞ¥╣õ©¡Úù┤Úâ¿Õêåµ£ëõ╗ïþ╗ìhadoopÕ«Üõ╣ëþÜäµò░µì«þ▒╗Õ×ïÕÆîÞç¬Õ«Üõ╣ëµò░µì«þ▒╗Õ×ïþÜäµû╣µ│ò(õ©╗Þªüµÿ»Õ»╣writableþ▒╗þÜäÕ¡ªõ╣áÕÆîõ║åÞºú)´╝øÕÆîÞ┐Öþ»çÚçîÞ¥╣Þ»┤þÜäMapReduceþÜäþ▒╗Õ×ïÕÆîµá╝Õ╝ÅÒÇéõ╣ƒÕ░▒µÿ»ÒÇèhadoopµØâÕ¿üµîçÕìùÒÇïÞ┐Öµ£¼õ╣ªþÜäþ¼¼Õøøþ½áHadoop I/OÕÆîþ¼¼õ©âþ½áMapReduceþÜäþ▒╗Õ×ïÕÆîµá╝Õ╝ÅÒÇéÕªéµ×£õ¢áµÇÑõ║ÄÞºúÕå│Þ┐Öõ©¬Úù«Úóÿ´╝îµêæþÄ░Õ£¿õ╣ƒÕÅ»õ╗ÑÕæèÞ»ëõ¢áÞ┐àÚǃþÜäÞºúÕå│õ╣ïÚüô´╝îõ¢åÞ┐ÖÕè┐Õ┐àÕ¢▒Õôìõ¢áõ╗ÑÕÉÄÕ╝ÇÕÅæ´╝Ü
þí«õ┐Øõ©Çõ©ïµò░µì«þÜäõ©ÇÞç┤´╝Ü
... extends Mapper...
public void map(k1 k, v1 v, OutputCollector output)...
...
...extends Reducer...
public void reduce(k2 k,v2 v,OutputCollector output)...
...
job.setMapOutputKeyClass(k2.class);
job.setMapOutputValueClass(k2.class);job.setOutputKeyClass(k3.class);
job.setOutputValueClass(v3.class);
...
µ│¿µäÅ k* ÕÆî v*þÜäÕ»╣Õ║öÒÇéÕ╗║Þ««Þ┐ÿµÿ»þ£ïµêæÕêܵëìÞ»┤þÜäõ©ñõ©¬þ½áÞèéÒÇéÞ»ªþ╗åþƒÑÚüôÕàÂÕăþÉåÒÇé
ÕìüÒÇüÕªéµ×£þó░Õê░datanodeµèÑÚöÖÕªéõ©ï´╝Ü
ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: java.io.IOException: Cannot lock storage /data1/hadoop_data. The directory is already locked.
µá╣µì«ÚöÖÞ»»µÅÉþñ║µØÑþ£ï´╝îµÿ»þø«Õ¢òÞó½Úöüõ¢Å´╝îµùáµ│òÞ»╗ÕÅûÒÇéÞ┐ÖµùÂÕÇÖõ¢áÚ£ÇÞªüµƒÑþ£ïõ©Çõ©ïµÿ»Õɪµ£ëþø©Õà│Þ┐øþ¿ïÞ┐ÿÕ£¿Þ┐ÉÞíîµêûÞÇàslaveµ£║ÕÖ¿þÜäþø©Õà│hadoopÞ┐øþ¿ïÞ┐ÿÕ£¿Þ┐ÉÞíî´╝îþ╗ôÕÉêlinuxÞ┐Öõ┐®Õæ¢õ╗ñµØÑÞ┐øÞíÑþ£ï´╝Ü
netstat -nap
ps -aux | grep þø©Õà│PID
Õªéµ×£µ£ëhadoopþø©Õà│þÜäÞ┐øþ¿ïÞ┐ÿÕ£¿Þ┐ÉÞíî´╝îÕ░▒õ¢┐þö¿killÕæ¢õ╗ñÕ╣▓µÄëÕì│ÕÅ»ÒÇéþäÂÕÉÄÕåìÚçìµû░õ¢┐þö¿start-all.shÒÇé
Õìüõ©ÇÒÇüÕªéµ×£þó░Õê░jobtrackerµèÑÚöÖÕªéõ©ï´╝Ü
Shuffle Error: Exceeded MAX_FAILED_UNIQUE_FETCHES; bailing-out.
ÞºúÕå│µû╣Õ╝Å´╝îõ┐«µö╣datanodeÞèéþé╣Úçî/etc/hostsµûçõ╗ÂÒÇé
þ«ÇÕìòõ╗ïþ╗ìõ©ïhostsµá╝Õ╝Å´╝Ü
µ»ÅÞíîÕêåõ©║õ©ëõ©¬Úâ¿Õêå´╝Üþ¼¼õ©ÇÚâ¿Õêåþ¢æþ╗£IPÕ£░ÕØÇÒÇüþ¼¼õ║îÚâ¿Õêåõ©╗µ£║ÕÉìµêûÕƒƒÕÉìÒÇüþ¼¼õ©ëÚâ¿Õêåõ©╗µ£║Õê½ÕÉì
µôìõ¢£þÜäÞ»ªþ╗嵡ÑÚ¬ñÕªéõ©ï´╝Ü
1ÒÇüÚªûÕà굃Ñþ£ïõ©╗µ£║ÕÉìþº░´╝Ü
cat /proc/sys/kernel/hostname
õ╝Üþ£ïÕê░õ©Çõ©¬HOSTNAMEþÜäÕ▒׵Ǻ´╝îµèèÕÉÄÞ¥╣þÜäÕÇ╝µö╣µêÉIPÕ░▒OK´╝îþäÂÕÉÄÚÇÇÕç║ÒÇé
2ÒÇüõ¢┐þö¿Õæ¢õ╗ñ´╝Ü
hostname ***.***.***.***
µÿƒÕÅÀµìóµêÉþø©Õ║öþÜäIPÒÇé
3ÒÇüõ┐«µö╣hostsÚàìþ¢«þ▒╗õ╝╝ÕåàÕ«╣Õªéõ©ï´╝Ü
127.0.0.1  localhost.localdomain       localhost
::1      localhost6.localdomain6  localhost6
10.200.187.77   10.200.187.77   hadoop-datanode
Õªéµ×£Úàìþ¢«ÕÉÄÕç║þÄ░IPÕ£░ÕØÇÕ░▒Þí¿þñ║õ┐«µö╣µêÉÕèƒõ║å´╝îÕªéµ×£Þ┐ÿµÿ»µÿ¥þñ║õ©╗µ£║ÕÉìÕ░▒µ£ëÚù«Úóÿõ║å´╝îþ╗ºþ╗¡õ┐«µö╣Þ┐Öõ©¬hostsµûçõ╗´╝î
Õªéõ©ïÕø¥´╝Ü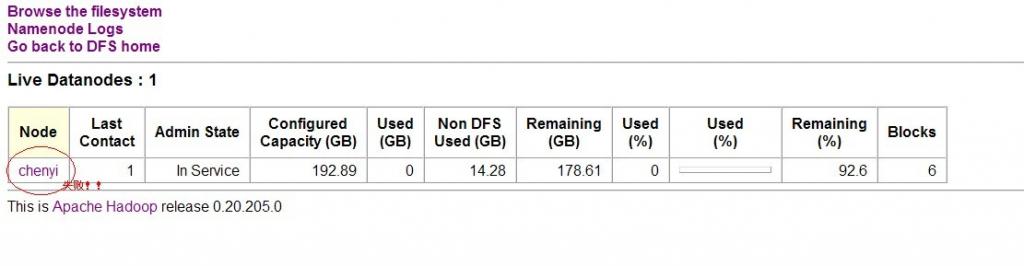
õ©èÕø¥µÅÉÚåÆõ©ï´╝îchenyiµÿ»õ©╗µ£║ÕÉìÒÇé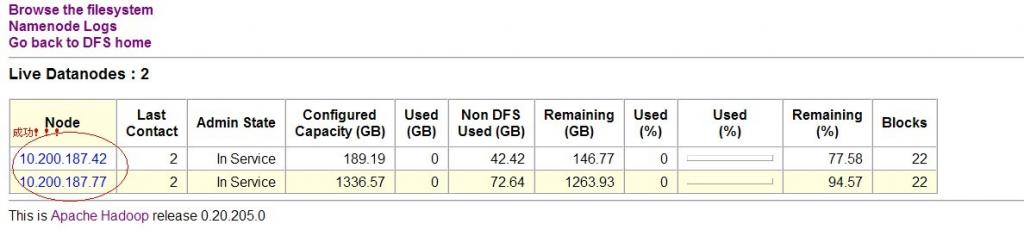
Õ¢ôÕ£¿µÁïÞ»òþÄ»ÕóâÚçî´╝îÞç¬ÕÀ▒ÕåìÕÄ╗Úâ¿þ¢▓õ©Çõ©¬ÕƒƒÕÉìµ£ìÕèíÕÖ¿´╝êõ©¬õ║║ÞºëÕ¥ùÕ¥êþ╣üþÉÉ´╝ë´╝îµëÇõ╗Ñþ«ÇÕìòÕ£░µû╣Õ╝Å´╝îÕ░▒þø┤µÄÑþö¿IPÕ£░ÕØǵ»öÞ¥âµû╣õ¥┐ÒÇéÕªéµ×£µ£ëõ║åÕƒƒÕÉìµ£ìÕèíÕÖ¿þÜä޻ش╝îÚéúÕ░▒þø┤µÄÑÞ┐øÞíîµÿáÕ░äÚàìþ¢«Õì│ÕÅ»ÒÇé
Õªéµ×£Þ┐ÿµÿ»Õç║þÄ░µ┤ùþëîÕç║ÚöÖÞ┐Öõ©¬Úù«Úóÿ´╝îÚéúõ╣êÕ░▒Þ»òÞ»òÕê½þÜäþ¢æÕÅïÞ»┤þÜäõ┐«µö╣Úàìþ¢«µûçõ╗ÂÚçîþÜähdfs-site.xmlµûçõ╗´╝îµÀ╗Õèáõ╗Ñõ©ïÕåàÕ«╣´╝Ü
dfs.http.address
*.*.*.*:50070┬áþ½»ÕÅúõ©ìÞªüµö╣´╝îµÿƒÕÅÀµìóµêÉIP´╝îÕøáõ©║hadoopõ┐íµü»õ╝áÞ¥ôÚ⢵ÿ»ÚÇÜÞ┐çHTTP´╝îÞ┐Öõ©¬þ½»ÕÅúµÿ»õ©ìÕÅÿþÜäÒÇé
 
Õìüõ©ÇÒÇüÕªéµ×£þó░Õê░jobtrackerµèÑÚöÖÕªéõ©ï´╝Ü
java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code *
Þ┐Öµÿ»javaµèøÕç║þÜäþ│╗þ╗ƒÞ┐öÕø×þÜäÚöÖÞ»»þáü´╝îÚöÖÞ»»þáüÞí¿þñ║þÜäµäŵÇØÞ»ªþ╗åþÜäÞ»Àþ£ïÞ┐ÖÚçîÒÇé
µêæÞ┐ÖÚçîµÿ»õ║østreamingþÜäphpþ¿ïÕ║ŵùÂÚüçÕê░þÜä´╝îÚüçÕê░þÜäÚöÖÞ»»þáüµÿ»code 2: No such file or directoryÒÇéÕì│µë¥õ©ìÕê░µûçõ╗µêûÞÇàþø«Õ¢òÒÇéÕÅæþÄ░Õæ¢õ╗ñþ½ƒþäÂÕ┐ÿÞ«░õ¢┐þö¿'php ****' Õ¥êÕØæ´╝îÕŪÕñûþ¢æõ©èþ£ïÕê░õ╣ƒÕÅ»Þ⢵ÿ»includeÒÇürequireþ¡ëÕæ¢õ╗ñÚÇáµêÉÒÇéÞ»ªþ╗åþÜäÞ»Àµá╣µì«Þç¬Þ║½µâàÕåÁÕÆîÚöÖÞ»»þáüõ┐«µö╣ÒÇé
õ©¬õ║║ÕăÕêø´╝îÞ¢¼Þ¢¢Þ»Àµ│¿µÿÄ´╝Üõ©ëµ▒ƒÕ░ŵ©í



þø©Õà│µÄ¿ÞìÉ
hadoopµÿ»õ©Çõ©¬Õñºµò░µì«ÕñäþÉåþÜäÕƒ║þíǵ×µ×ä´╝îõ¢åµÿ»Õ£¿Õ«×ÚÖàõ¢┐þö¿Þ┐çþ¿ïõ©¡þ╗ÅÕ©©õ╝Üþó░Õê░ÕÉäþºìÕÉäµáÀþÜäÚù«Úóÿ´╝îõ╗Ñõ©ïµÿ»ÞºúÕå│hadoopÚàìþ¢«Þ┐ÉÞíîÚöÖÞ»»þÜäõ©Çõ║øþ╗ÅÚ¬îµÇ╗þ╗ô´╝Ü õ©ÇÒÇühadoopÚøåþ¥ñÕ£¿namenodeµá╝Õ╝ÅÕîûÕÉÄÚçìÕÉ»Úøåþ¥ñõ╝ÜÕç║þÄ░Incompatible namespaceIDS...
ÔÇ£HadoopÕ¡ªõ╣áµÇ╗þ╗ôõ╣ïõ║ö´╝ÜHadoopþÜäÞ┐ÉÞíîþùòÞ┐╣.docÔÇØÕÅ»Þ⢵ÂëÕÅèþøæµÄºÕÆîµùÑÕ┐ùÞ«░Õ¢ò´╝îÞ┐Öµÿ»þÉåÞºúHadoopþ│╗þ╗ƒÞ┐ÉÞíîþèµÇüÕÆîÚù«ÚóÿµÄƵƒÑþÜäÚçìÞªüµëﵫÁÒÇéÚÇÜÞ┐çþøæµÄºHadoopÚøåþ¥ñþÜäµÇºÞ⢵îçµáç´╝îÕªéCPUÕê®þö¿þÄçÒÇüÕåàÕ¡ÿõ¢┐þö¿µâàÕåÁÒÇüþúüþøÿI/Oþ¡ë´╝îÕÅ»õ╗Ñõ╝ÿÕîûþ│╗þ╗ƒÚàìþ¢«...
Õªéµ×£Õ£¿µƒÑÞ»óµùÂÚüçÕê░ÔÇ£FAILED: Hive Internal Error: java.lang.RuntimeException(Error while making MR scratch directory - check filesystem config (null))ÔÇØ´╝îÞ┐ÖÚÇÜÕ©©µÿ»þö▒õ║ÄHadoopÚàìþ¢«Úù«ÚóÿÕ»╝Þç┤þÜäÒÇéÞºúÕå│µû╣µ│òÕªéõ©ï´╝Ü ...
- Úàìþ¢«ÕàÂõ╗ûþø©Õà│þÄ»ÕóâÕÅÿÚçÅ´╝îÕªé`HADOOP_CONF_DIR`´╝îµîçÕÉæHadoopÚàìþ¢«µûçõ╗ÂþÜäþø«Õ¢òÒÇé 2. **Úàìþ¢«EclipseµÅÆõ╗Â**´╝Ü - Õ«ëÞúàHadoopþø©Õà│þÜäEclipseµÅÆõ╗´╝îÕªé"Hadoop Eclipse Plugin"µêû"Big Data Tools"´╝îÕ«âõ╗¼µÅÉõ¥øõ║åõ©ÄHadoopÚøåþ¥ñ...
### HadoopÕ£¿WindowsþÄ»Õóâõ©ïþÜäÚàìþ¢«þƒÑÞ»åþé╣Þ»ªÞºú #### õ©ÇÒÇüHadoopþ«Çõ╗ï Hadoopµÿ»õ©Çõ©¬Þâ¢ÕñƒÕ»╣ÕñºÚçŵò░µì«Þ┐øÞíîÕêåÕ©âÕ╝ÅÕñäþÉåþÜäÞ¢»õ╗µíåµ×´╝îÕ«âõ©║þö¿µêÀµÅÉõ¥øõ║åÚ½ÿÕÅ»ÚØáµÇºÒÇüÚ½ÿµòêµÇºÒÇüÕÅ»µë®Õ▒òµÇºþÜäµò░µì«ÕñäþÉåÞâ¢ÕèøÒÇéHadoopþÜäµá©Õ┐âþ╗äõ╗ÂÕîàµï¼HDFS...
1. **µØâÚÖÉÚù«Úóÿ**´╝Üþí«õ┐صëǵ£ëþÜäHadoopÚàìþ¢«µûçõ╗ÂÕÆîµ£ìÕèíÚ⢵ÿ»õ╗Ñhadoopþö¿µêÀÞ║½õ╗¢Þ┐ÉÞíîþÜäÒÇé 2. **þ¢æþ╗£Úù«Úóÿ**´╝ܵúǵƒÑþ¢æþ╗£Úàìþ¢«µÿ»Õɪµ¡úþí«´╝îþí«õ┐Øõ©╗µ£║ÕÉìÞºúµ×ɵ¡úÕ©©ÒÇé 3. **µùÑÕ┐ùÚöÖÞ»»**´╝ܵƒÑÚÿàHadoopþÜäµùÑÕ┐ùµûçõ╗´╝îÚÇÜÕ©©õ¢ìõ║Ä`$HADOOP_HOME/...
õ©ïÚØóµÿ» Hadoop þÜäÕ«ëÞúàÚâ¿þ¢▓õ©ÄÚàìþ¢«Õ«×Ú¬îµÇ╗þ╗ôÒÇé õ©ÇÒÇüÕ«×Ú¬îþÄ»ÕóâÕçåÕñç Õ£¿Þ┐øÞíî Hadoop Õ«ëÞúàÚâ¿þ¢▓õ©ÄÚàìþ¢«Õ«×Ú¬îõ╣ïÕëì´╝îÚ£ÇÞªüÕçåÕñçÕÑ¢Õ«×Ú¬îþÄ»ÕóâÒÇéÞ┐ÖÚçîõ¢┐þö¿ VMware ÕÆî Ubuntu 12.04 LTS 64bit õ¢£õ©║ÞÖܵ£║þÜäµôìõ¢£þ│╗þ╗ƒÒÇéÚªûÕàê´╝îÚ£ÇÞªüÕ«ëÞúà JDK...
### HadoopÚàìþ¢«Þ»ªÞºú #### õ©ÇÒÇüþÄ»ÕóâµÉ¡Õ╗║õ©ÄÚàìþ¢«ÕëìÕçåÕñç **1.1 Õ«ëÞúàþÄ»Õóâ** - **µôìõ¢£þ│╗þ╗ƒ:** Ubuntu 14.04.3 LTS - **Hadoop þëêµ£¼:** hadoop-2.5.2 µêû hadoop-2.6.0 µêûµø┤Ú½ÿþëêµ£¼ - **Java þëêµ£¼:** Oracle JDK 7u80 **...
Õ«îµêÉõ©èÞ┐░ÕçåÕñçÕÀÑõ¢£ÕÉÄ´╝îµÄÑõ©ïµØÑÚ£ÇÞªüÚàìþ¢«µôìõ¢£þ│╗þ╗ƒþÄ»ÕóâÕÅÿÚçÅõ╗ѵö»µîüHadoopÞ┐ÉÞíî´╝Ü 1. **µÀ╗ÕèáHADOOP_HOME**´╝ÜÕ£¿þÄ»ÕóâÕÅÿÚçÅõ©¡µÀ╗ÕèáHADOOP_HOME´╝îÕàÂÕÇ╝õ©║HadoopÕ«ëÞúàþø«Õ¢òþÜäþ╗ØÕ»╣ÞÀ»Õ¥äÒÇé 2. **µø┤µû░PATHþÄ»ÕóâÕÅÿÚçÅ**´╝ÜÕ░åHadoopþÜä`bin`ÕÆî`...
µÇ╗þ╗ôµØÑÞ»┤´╝îÚàìþ¢«EclipseÕ╝ÇÕÅæHadoopÚí╣þø«µÂëÕÅèÕê░õ©ïÞ¢¢ÕÆîÕ«ëÞúàµÅÆõ╗ÂÒÇüÚàìþ¢«þÄ»ÕóâÕÅÿÚçÅÒÇüÕ╝òÕàÑHadoopÕ║ôõ╗ÑÕÅèÕ£¿Eclipseõ©¡Þ«¥þ¢«HadoopÞÀ»Õ¥äÒÇéÚÇÜÞ┐çÞ┐Öõ║øµ¡ÑÚ¬ñ´╝îÕ╝ÇÕÅæÞÇàÕÅ»õ╗ÑÕ£¿Windows 7õ©èþÜäEclipseþÄ»Õóâõ©¡Ú½ÿµòêÕ£░þ╝ûÕåÖÕÆîµÁïÞ»òHadoop MapReduce...
- Þ┐øÕàÑHadoopÚàìþ¢«þø«Õ¢ò`$HADOOP_HOME/etc/hadoop`ÒÇé - þ╝ûÞ¥æõ╗Ñõ©ïµá©Õ┐âÚàìþ¢«µûçõ╗´╝Ü - `hadoop-env.sh`´╝ÜÞ«¥þ¢«JavaÞÀ»Õ¥äÕÆîÕàÂõ╗ûþÄ»ÕóâÕÅÿÚçÅÒÇé - `core-site.xml`´╝ÜÚàìþ¢«HadoopþÜäÕƒ║µ£¼Õ▒׵Ǻ´╝îÕªéÚ╗ÿÞ«ñFS´╝êµûçõ╗Âþ│╗þ╗ƒ´╝ëÒÇé - `hdfs-...
µ£¼µûçÞ»ªþ╗åõ╗ïþ╗ìõ║åHadoop 1.2.1þÜäÕ«ëÞúàõ©ÄÚàìþ¢«µÁüþ¿ï´╝îÕîàµï¼þÄ»ÕóâÕçåÕñçÒÇüSSHÚàìþ¢«ÒÇüJDKÕ«ëÞúàÒÇüHadoopÚàìþ¢«µûçõ╗ÂÞ«¥þ¢«ÒÇüHadoopµá╝Õ╝ÅÕîûÕÅèÕÉ»Õè¿þ¡ëµ¡ÑÚ¬ñÒÇéÚÇÜÞ┐çµ£¼µëïÕåîþÜäµîçÕ╝ò´╝îµé¿ÕÅ»õ╗ÑÚí║Õê®Õ«îµêÉHadoopÚøåþ¥ñþÜäµÉ¡Õ╗║´╝îÕ╣µÄîµÅíÕƒ║µ£¼þÜäµòàÚÜ£µÄƵƒÑµû╣µ│òÒÇé...
Õ£¿ITÞíîõ©Üõ©¡´╝îHadoopµÿ»õ©Çõ©¬...þí«õ┐ØÕ«âõ╗¼µ¡úþí«Úàìþ¢«Õ╣ÂÕÅ»Þó½þ│╗þ╗ƒµë¥Õê░´╝îÕÅ»õ╗ÑÚü┐ÕàìÞ«©ÕñÜõ©ÄþÄ»ÕóâÚàìþ¢«þø©Õà│þÜäÚöÖÞ»»´╝îõ¢┐Õ¥ùÕ╝ÇÕÅæÞÇàÞâ¢Õñƒõ©ôµ│¿õ║ÄHadoopÕ║öþö¿þÜäþ╝ûÕåÖÕÆîµÁïÞ»òÒÇéõ║åÞºúÕÆîµÄîµÅíÞ┐Öõ║øÕƒ║þíÇþƒÑÞ»å´╝îÕ»╣õ║ÄÕ£¿Windowsõ©èÚ½ÿµòêÕ£░õ¢┐þö¿HadoopÞç│Õà│ÚçìÞªüÒÇé
5. **Úàìþ¢«µûçõ╗Â**´╝ÜÕ£¿Windowsõ©èÕÉ»Õè¿Hadoop´╝îÚ£ÇÞªüõ┐«µö╣HadoopÚàìþ¢«µûçõ╗´╝îÕªé`core-site.xml`ÒÇü`hdfs-site.xml`ÕÆî`mapred-site.xml`´╝îÞ«¥þ¢«µ¡úþí«þÜäÞÀ»Õ¥äÒÇüþ½»ÕÅúÕÆîÕÅéµò░´╝îõ╗ÑÚÇéÕ║öWindowsþÄ»ÕóâÒÇé 6. **þÄ»ÕóâÕÅÿÚçÅ**´╝Üþí«õ┐ØÞ«¥þ¢«µ¡úþí«þÜä...
µÇ╗þ╗ôÞÁÀµØÑ´╝îÚàìþ¢«HadoopÚøåþ¥ñµÿ»õ©Çõ©¬µÂëÕÅèþ¢æþ╗£Úàìþ¢«ÒÇüSSHµùáÕ»åþáüþÖ╗Õ¢òÒÇüþÄ»ÕóâÕÅÿÚçÅÞ«¥þ¢«ÒÇüHadoopÚàìþ¢«µûçõ╗Âõ┐«µö╣õ╗ÑÕÅèµ£ìÕèíÕÉ»Õè¿þÜäÕñìµØéÞ┐çþ¿ïÒÇ鵡úþí«Úàìþ¢«Þ┐Öõ║øÕÅéµò░µÿ»õ┐ØÞ»üHadoopÚøåþ¥ñÚ½ÿµòêþ¿│Õ«ÜÞ┐ÉÞíîþÜäÕƒ║þíÇÒÇéÚÜÅþØÇHadoopþëêµ£¼þÜäµø┤µû░´╝îÞ┐Öõ║øÚàìþ¢«...
2. **Úàìþ¢«HadoopþÄ»Õóâ**´╝ÜÕ£¿Eclipseõ©¡´╝îÚ£ÇÞªüÚàìþ¢«HadoopþÜäÞ┐ÉÞíîþÄ»Õóâ´╝îÕîàµï¼HadoopþÜäÕ«ëÞúàÞÀ»Õ¥äÒÇüHDFSÕ£░ÕØÇþ¡ëõ┐íµü»ÒÇé 3. **ÕêøÕ╗║HadoopÚí╣þø«**´╝ÜÕ£¿EclipseþÜäÔÇ£µûçõ╗ÂÔÇØÞÅ£Õìòõ©¡ÚÇëµï®ÔÇ£µû░Õ╗║ÔÇØ -> ÔÇ£ÕàÂõ╗ûÔÇØ´╝îÕ£¿Õ╝╣Õç║þÜäÕ»╣޻صíåõ©¡µë¥Õê░...
µÇ╗þ╗ôõ©Çõ©ï´╝îþ╝ûÞ»æÕÆîÞ┐ÉÞíîHadoop-0.20.1µ║ÉþáüÚ£ÇÞªüÕçåÕñçÕÉêÚÇéþÜäÕ╝ÇÕÅæþÄ»Õóâ´╝úþí«Õ»╝Õàѵ║Éõ╗úþáüÕê░EclipseÚí╣þø«´╝îÕÉ»Õè¿HadoopÚøåþ¥ñ´╝îµ£ÇÕÉÄþ╝ûÞ»æÕÆîÞ┐ÉÞíîµ║Éõ╗úþáüÒÇéÚÇÜÞ┐çÞ┐Öþºìµû╣Õ╝Å´╝îÕ╝ÇÕÅæÞÇàÕÅ»õ╗ѵÀ▒ÕàÑþÉåÞºúHadoopþÜäÕÀÑõ¢£µÁüþ¿ï´╝îÞ░âÞ»òõ╗úþáü´╝îõ╗ÑÕÅèÞ┐øÞíîÕ«ÜÕêÂ...
jb51þÜäÕç║þÄ░ÕÅ»Þ⢵äÅÕæ│þØÇõ©Çþºìþë╣Õ«ÜþÜäÚàìþ¢«µêûÚøåµêɵû╣µ│ò´╝îÞ┐ÖÕÅ»Þ⢵ÂëÕÅèÕê░Þç¬Õ«Üõ╣ëµÅÆõ╗ÂÞ«¥þ¢«´╝îµêûÞÇàµÿ»Õ£¿Eclipseõ©¡ÚøåµêÉþë╣Õ«ÜþÜäHadoopþëêµ£¼ÕÆîþø©Õà│ÕÀÑÕàÀÒÇéþö¿µêÀÕÅ»Þâ¢Ú£ÇÞªüõ©ïÞ¢¢Õ╣ÂÕ«ëÞúàÞ┐Öõ©¬jb51µÅÆõ╗´╝îþäÂÕÉĵîëþີîçÕ»╝Úàìþ¢«Eclipse´╝îõ╗Ñõ¥┐Þâ¢þø┤µÄÑÕ£¿IDE...
Õ£¿Hadoopõ©¡´╝îÞ┐ÖÕÅ»Þ⢵ÂëÕÅèÕê░HadoopÚàìþ¢«ÒÇüþÄ»ÕóâÕÅÿÚçŵêûõ¥ØÞÁûÕ║ôþÜäþ╝║Õñ▒ÒÇéÕ£¿Þ┐ÖþºìµâàÕåÁõ©ï´╝îµÀ╗Õèá`HADOOP_HOME`þÄ»ÕóâÕÅÿÚçŵÿ»ÞºúÕå│Úù«ÚóÿþÜäÕà│Úö«µ¡ÑÚ¬ñõ╣ïõ©ÇÒÇé`HADOOP_HOME`Õ║ö޻ѵîçÕÉæõ¢áþÜäHadoopÕ«ëÞúàþø«Õ¢ò´╝îÞ┐ÖµáÀHadoopþø©Õà│þ¿ïÕ║ŵëìÞ⢵ë¥Õê░Õ«âõ╗¼µëÇÚ£Ç...
µáçÚóÿ "Þ┐ÉÞíîhadoop jar" µÂëÕÅèÕê░þÜäµÿ»Õ£¿...µÇ╗þ╗ôµØÑÞ»┤´╝î"Þ┐ÉÞíîhadoop jar"µÿ»õ©Çõ©¬Õà│Úö«µ¡ÑÚ¬ñ´╝îÕ«âµÂÁþøûõ║åõ╗Äþ╝ûÕåÖJavaõ╗úþáüÕê░Õ£¿HadoopÚøåþ¥ñõ©èµëºÞíîÕêåÕ©âÕ╝ÅÞ«íþ«ùþÜäÕ«îµò┤µÁüþ¿ïÒÇéþÉåÞºúÕ╣Âþåƒþ╗âµÄîµÅíÞ┐Öõ©ÇÞ┐çþ¿ïÕ»╣õ║ÄÕ╝ÇÕÅæÕÆîþ╗┤µèñHadoopÕ║öþö¿Þç│Õà│ÚçìÞªüÒÇé