
еИЖеЄГеЉПзОѓеҐГдЄ≠е§Іе§ЪжХ∞жЬНеК°жШѓеЕБиЃЄйГ®еИЖ姱賕пЉМдєЯеЕБиЃЄжХ∞жНЃдЄНдЄАиЗіпЉМдљЖжЬЙдЇЫжЬАеЯЇз°АзЪДжЬНеК°жШѓйЬАи¶БйЂШеПѓйЭ†жАІпЉМйЂШдЄАиЗіжАІзЪДпЉМињЩдЇЫжЬНеК°жШѓеЕґдїЦеИЖеЄГеЉПжЬНеК°ињРиљђзЪДеЯЇз°АпЉМжѓФе¶Вnaming serviceгАБеИЖеЄГеЉПlockз≠ЙпЉМињЩдЇЫеИЖеЄГеЉПзЪДеЯЇз°АжЬНеК°жЬЙдї•дЄЛи¶Бж±ВпЉЪ
- йЂШеПѓзФ®жАІ
- йЂШдЄАиЗіжАІ
- йЂШжАІиГљ
еѓєдЇОињЩзІНжЬЙдЇЫжМСжИШCAPеОЯеИЩ¬†зЪДжЬНеК°иѓ•е¶ВдљХиЃЊиЃ°пЉМжШѓдЄАдЄ™жМСжИШпЉМдєЯжШѓдЄАдЄ™дЄНйФЩзЪДз†Фз©ґиѓЊйҐШпЉМApacheзЪДZooKeeperдєЯиЃЄзїЩдЇЖжИСдїђдЄАдЄ™дЄНйФЩзЪДз≠Фж°ИгАВZooKeeperжШѓдЄАдЄ™еИЖеЄГеЉПзЪДпЉМеЉАжФЊжЇРз†БзЪДеИЖеЄГеЉПеЇФзФ®з®ЛеЇПеНПи∞ГжЬНеК°пЉМ¬†еЃГжЪійЬ≤дЇЖдЄАдЄ™зЃАеНХзЪДеОЯиѓ≠йЫЖпЉМеИЖеЄГеЉПеЇФзФ®з®ЛеЇПеПѓдї•еЯЇдЇОеЃГеЃЮзО∞еРМж≠•жЬНеК°пЉМйЕНзљЃзїіжК§еТМеСљеРНжЬНеК°з≠ЙгАВеЕ≥дЇОZooKeeperжЫіе§Ъдњ°жБѓеПѓдї•еПВиІБ¬†еЃШжЦєжЦЗж°£
ZooKeeperзЪДеЯЇжЬђдљњзФ®
жР≠дЄАдЄ™еИЖеЄГеЉПзЪДZooKeeperзОѓеҐГжѓФиЊГзЃАеНХпЉМеЯЇжЬђж≠•й™§е¶ВдЄЛпЉЪ
1пЉЙеЬ®еРДжЬНеК°еЩ®еЃЙи£Е¬†ZooKeeper
дЄЛиљљZooKeeperеРОеЬ®еРДжЬНеК°еЩ®дЄКињЫи°МиІ£еОЛеН≥еПѓ
tar -xzf zookeeper-3.2.2.tar.gz
2пЉЙйЕНзљЃйЫЖзЊ§зОѓеҐГ
еИЖеИЂеРДжЬНеК°еЩ®зЪДzookeeperеЃЙи£ЕзЫЃељХдЄЛеИЫеїЇеРНдЄЇzoo.cfgзЪДйЕНзљЃжЦЗдїґпЉМеЖЕеЃєе°ЂеЖЩе¶ВдЄЛпЉЪ
 
- # The number of milliseconds of each tick  
- tickTime=2000  
- # The number of ticks that the initial  
- # synchronization phase can take  
- initLimit=10  
- # The number of ticks that can pass between  
- # sending a request and getting an acknowledgement  
- syncLimit=5  
- # the directory where the snapshot is stored.  
- dataDir=/home/admin/zookeeper-3.2.2/data  
- # the port at which the clients will connect  
- clientPort=2181  
- server.1=zoo1:2888:3888  
- server.2=zoo2:2888:3888  
 
 
еЕґдЄ≠zoo1еТМzoo2еИЖеИЂеѓєеЇФйЫЖзЊ§дЄ≠еРДжЬНеК°еЩ®зЪДжЬЇеЩ®еРНжИЦipпЉМserver.1еТМserver.2дЄ≠1еТМ2еИЖеИЂеѓєеЇФеРДжЬНеК°еЩ®зЪДzookeeper idпЉМidзЪДиЃЊзљЃжЦєж≥ХдЄЇеЬ®dataDirйЕНзљЃзЪДзЫЃељХдЄЛеИЫеїЇеРНдЄЇmyidзЪДжЦЗдїґпЉМеєґжККidдљЬдЄЇеЕґжЦЗдїґеЖЕеЃєеН≥еПѓпЉМеЬ®жЬђдЊЛдЄ≠е∞±еИЖдЄЇиЃЊзљЃдЄЇ1еТМ2гАВеЕґдїЦйЕНзљЃеЕЈдљУеРЂдєЙеПѓиІБеЃШжЦєжЦЗж°£гАВ
3пЉЙеРѓеК®йЫЖзЊ§зОѓеҐГ
еИЖеИЂеЬ®еРДжЬНеК°еЩ®дЄЛињРи°МzookeeperеРѓеК®иДЪжЬђ
/home/admin/zookeeper-3.2.2/bin/zkServer.sh start
4пЉЙеЇФзФ®zookeeper
еЇФзФ®zookeeperеПѓдї•еЬ®жШѓshellдЄ≠жЙІи°МеСљдї§пЉМдєЯеПѓдї•еЬ®javaжИЦcдЄ≠и∞ГзФ®з®ЛеЇПжО•еП£гАВ
еЬ®shellдЄ≠жЙІи°МеСљдї§пЉМеПѓињРи°Мдї•дЄЛеСљдї§пЉЪ
bin/zkCli.sh -server 10.20.147.35:2181
еЕґдЄ≠¬†10.20.147.35дЄЇйЫЖзЊ§дЄ≠дїїдЄАеП∞жЬЇеЩ®зЪДipжИЦжЬЇеЩ®еРНгАВжЙІи°МеРОеПѓињЫеЕ•zookeeperзЪДжУНдљЬйЭҐжЭњпЉМеЕЈдљУе¶ВдљХжУНдљЬеПѓиІБеЃШжЦєжЦЗж°£
еЬ®javaдЄ≠йАЪињЗи∞ГзФ®з®ЛеЇПжО•еП£жЭ•еЇФзФ®zookeeperиЊГдЄЇе§НжЭВдЄАзВєпЉМйЬАи¶БдЇЖиІ£watchеТМcallbackз≠Йж¶ВењµпЉМдЄНињЗиѓХй™МжЬАзЃАеНХзЪДCURDеАТдЄНйЬАи¶БињЩдЇЫпЉМеП™йЬАи¶БдљњзФ®ZooKeeperињЩдЄ™з±їеН≥еПѓпЉМеЕЈдљУжµЛиѓХдї£з†Бе¶ВдЄЛпЉЪ
 
- public static void main(String[] args) {  
-     try {  
-         ZooKeeper zk = new ZooKeeper("10.20.147.35:2181", 30000, null);  
-         String name = zk.create("/company", "alibaba".getBytes(),  
-                 Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT_SEQUENTIAL);  
-         Stat stat = new Stat();  
-         System.out.println(new String(zk.getData(name, null, stat)));  
-         zk.setData(name, "taobao".getBytes(), stat.getVersion(), null, null);  
-         System.out.println(new String(zk.getData(name, null, stat)));  
-         stat = zk.exists(name, null);  
-         zk.delete(name, stat.getVersion(), null, null);  
-         System.out.println(new String(zk.getData(name, null, stat)));  
-     } catch (Exception e) {  
-         e.printStackTrace();  
-     }  
- }  
 
 
дї•дЄКдї£з†БжѓФиЊГзЃАеНХпЉМжЯ•зЬЛдЄАдЄЛzooKeeperзЪДapi docе∞±зЯ•йБУе¶ВдљХдљњзФ®дЇЖ
ZooKeeperзЪДеЃЮзО∞жЬЇзРЖ
ZooKeeperзЪДеЃЮзО∞жЬЇзРЖжШѓжИСзЬЛињЗзЪДеЉАжЇРж°ЖжЮґдЄ≠жЬАе§НжЭВзЪДпЉМеЃГзЪДиІ£еЖ≥жШѓеИЖеЄГеЉПзОѓеҐГдЄ≠зЪДдЄАиЗіжАІйЧЃйҐШпЉМињЩдЄ™еЬЇжЩѓдєЯеЖ≥еЃЪдЇЖеЕґеЃЮзО∞зЪДе§НжЭВжАІгАВзЬЛдЇЖдЄ§дЄЙ姩зЪДжЇРз†БињШжШѓжЬЙдЇЫжСЄдЄНзЭАе§іиДСпЉМжЬЙдЇЫиґЕеЗЇдЇЖжИСзЪДиГљеКЫпЉМдЄНињЗйАЪињЗзЬЛжЦЗж°£еТМеЕґдїЦйЂШдЇЇеЖЩзЪДжЦЗзЂ†е§ІиЗіжЄЕж•ЪеЃГзЪДеОЯзРЖеТМеЯЇжЬђзїУжЮДгАВ
1пЉЙZooKeeperзЪДеЯЇжЬђеОЯзРЖ
ZooKeeperжШѓдї•Fast PaxosзЃЧж≥ХдЄЇеЯЇз°АзЪДпЉМеЬ®еЙНдЄАзѓЗ¬†blog¬†дЄ≠е§ІиЗідїЛзїНдЇЖдЄАдЄЛpaxosпЉМиАМж≤°жЬЙжПРеИ∞зЪДжШѓpaxosе≠ШеЬ®жіїйФБзЪДйЧЃйҐШпЉМдєЯе∞±жШѓељУжЬЙе§ЪдЄ™¬†proposerдЇ§йФЩжПРдЇ§жЧґпЉМжЬЙеПѓиГљдЇТзЫЄжОТжЦ•еѓЉиЗіж≤°жЬЙдЄАдЄ™proposerиГљжПРдЇ§жИРеКЯпЉМиАМFast PaxosдљЬдЇЖдЄАдЇЫдЉШеМЦпЉМйАЪињЗйАЙдЄЊдЇІзФЯдЄАдЄ™leaderпЉМеП™жЬЙleaderжЙНиГљжПРдЇ§proposeпЉМеЕЈдљУзЃЧж≥ХеПѓиІБFast Paxos¬†гАВеЫ†ж≠§пЉМи¶БжГ≥еЉДеЊЧZooKeeperй¶ЦеЕИеЊЧеѓєFast PaxosжЬЙжЙАдЇЖиІ£гАВ
2пЉЙZooKeeperзЪДеЯЇжЬђињРиљђжµБз®Л
ZooKeeperдЄїи¶Бе≠ШеЬ®дї•дЄЛдЄ§дЄ™жµБз®ЛпЉЪ
- йАЙдЄЊLeader
- еРМж≠•жХ∞жНЃ
йАЙдЄЊLeaderињЗз®ЛдЄ≠зЃЧж≥ХжЬЙеЊИе§ЪпЉМдљЖи¶БиЊЊеИ∞зЪДйАЙдЄЊж†ЗеЗЖжШѓдЄАиЗізЪДпЉЪ
- Leaderи¶БеЕЈжЬЙжЬАйЂШзЪДzxid¬†
- йЫЖзЊ§дЄ≠е§Іе§ЪжХ∞зЪДжЬЇеЩ®еЊЧеИ∞еУНеЇФеєґfollowйАЙеЗЇзЪДLeader
еРМж≠•жХ∞жНЃињЩдЄ™жµБз®ЛжШѓZooKeeperзЪДз≤ЊйЂУжЙАеЬ®пЉМеєґдЄФе∞±жШѓFast PaxosзЃЧж≥ХзЪДеЕЈдљУеЃЮзО∞гАВдЄАдЄ™зЙЫдЇЇзФїдЇЖдЄАдЄ™ZooKeeperжХ∞жНЃжµБеК®еЫЊпЉМжѓФиЊГзЫіиІВеЬ∞жППињ∞дЇЖZooKeeperжШѓе¶ВдљХеРМж≠•жХ∞жНЃзЪДгАВ
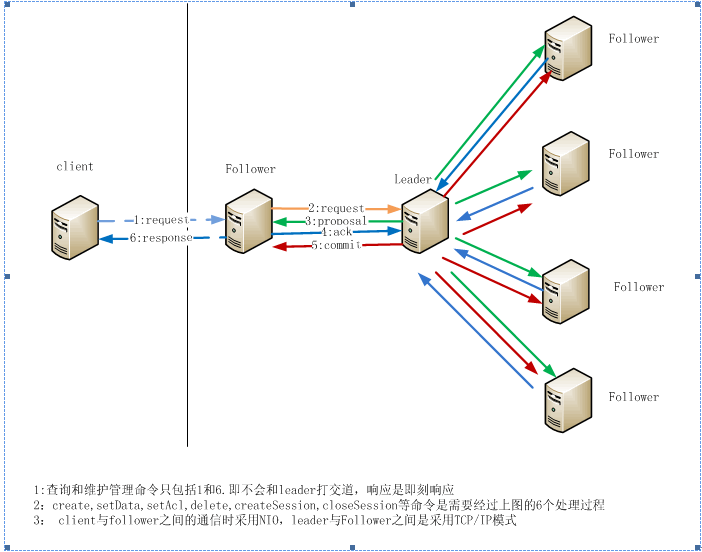
дї•дЄКдЄ§дЄ™ж†ЄењГжµБз®ЛжИСжЪВжЧґињШдЄНиГљжВЯйАПеЕґдЄ≠зЪДз≤ЊйЂУпЉМињЩдєЯеТМжИСињШж≤°жЬЙеЃМеЕ®зРЖиІ£Fast PaxosзЃЧж≥ХжЬЙеЕ≥пЉМжЬЙеЊЕеРОзї≠жЈ±еЕ•е≠¶дє†
ZooKeeperзЪДеЇФзФ®йҐЖеЯЯ
TimеЬ®blogдЄ≠жПРеИ∞дЇЖPaxosжЙАиГљеЇФзФ®зЪДеЗ†дЄ™дЄїи¶БеЬЇжЩѓпЉМеМЕжЛђdatabase replicationгАБnaming serviceгАБconfigйЕНзљЃзЃ°зРЖгАБaccess control listз≠Йз≠ЙпЉМињЩдєЯжШѓZooKeeperеПѓдї•еЇФзФ®зЪДеЗ†дЄ™дЄїи¶БеЬЇжЩѓгАВж≠§е§ЦпЉМ¬†ZooKeeperеЃШжЦєжЦЗж°£дЄ≠жПРеИ∞дЇЖеЗ†дЄ™жЫідЄЇеЯЇз°АзЪДеИЖеЄГеЉПеЇФзФ®пЉМињЩдєЯзЃЧжШѓZooKeeperзЪДе¶ЩзФ®еРІ
1пЉЙеИЖеЄГеЉПBarrier
BarrierжШѓдЄАзІНжОІеИґеТМеНПи∞Ге§ЪдЄ™дїїеК°иІ¶еПСжђ°еЇПзЪДжЬЇеИґпЉМзЃАеНХиѓіжЭ•е∞±жШѓжРЮдЄ™йЧЄйЧ®жККжђ≤жЙІи°МзЪДдїїеК°зїЩжЛ¶дљПпЉМз≠ЙжЙАжЬЙдїїеК°йГље§ДдЇОеПѓдї•жЙІи°МзЪДзКґжАБжЧґпЉМжЙНжФЊеЉАйЧЄйЧ®гАВеЃГзЪДжЬЇзРЖеПѓдї•иІБдЄЛеЫЊжЙАз§ЇпЉЪ
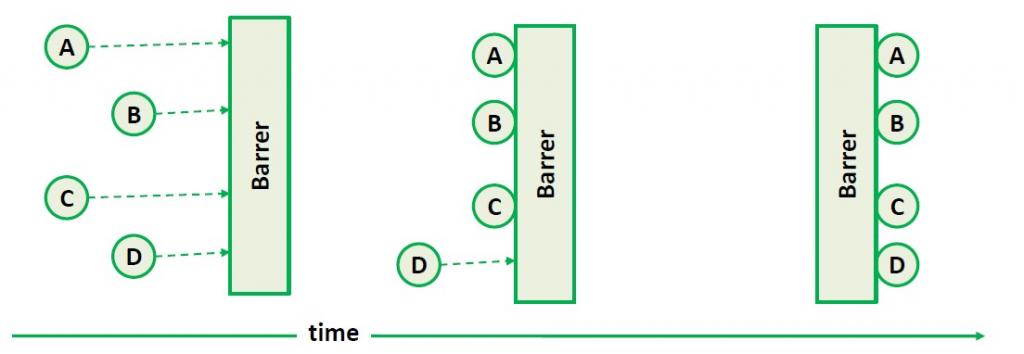
еЬ®еНХжЬЇдЄКJDKжПРдЊЫдЇЖCyclicBarrierињЩдЄ™з±їжЭ•еЃЮзО∞ињЩдЄ™жЬЇеИґпЉМдљЖеЬ®еИЖеЄГеЉПзОѓеҐГдЄ≠JDKе∞±жЧ†иГљдЄЇеКЫдЇЖгАВеЬ®еИЖеЄГеЉПйЗМеЃЮзО∞BarrerйЬАи¶БйЂШдЄАиЗіжАІеБЪдњЭйЪЬпЉМеЫ†ж≠§¬†ZooKeeperеПѓдї•жіЊдЄКзФ®еЬЇпЉМжЙАйЗЗеПЦзЪДжЦєж°Ие∞±жШѓзФ®дЄАдЄ™NodeдљЬдЄЇBarrerзЪДеЃЮдљУпЉМйЬАи¶Б襀BarrerзЪДдїїеК°йАЪињЗи∞ГзФ®exists()ж£АжµЛињЩдЄ™NodeзЪДе≠ШеЬ®пЉМељУйЬАи¶БжЙУеЉАBarrierзЪДжЧґеАЩпЉМеИ†жОЙињЩдЄ™NodeпЉМZooKeeperзЪДwatchжЬЇеИґдЉЪйАЪзЯ•еИ∞еРДдЄ™дїїеК°еПѓдї•еЉАеІЛжЙІи°МгАВ
2пЉЙ¬†еИЖеЄГеЉП¬†Queue
дЄО¬†Barrierз±їдЉЉ¬†еИЖеЄГеЉПзОѓеҐГдЄ≠¬†еЃЮзО∞QueueдєЯйЬАи¶БйЂШдЄАиЗіжАІеБЪдњЭйЪЬпЉМ¬†ZooKeeperжПРдЊЫдЇЖдЄАдЄ™зІНзЃАеНХзЪДжЦєеЉПпЉМZooKeeperйАЪињЗдЄАдЄ™NodeжЭ•зїіжК§QueueзЪДеЃЮдљУпЉМзФ®еЕґchildrenжЭ•е≠ШеВ®QueueзЪДеЖЕеЃєпЉМеєґдЄФ¬†ZooKeeperзЪДcreateжЦєж≥ХдЄ≠жПРдЊЫдЇЖй°ЇеЇПйАТеҐЮзЪДж®°еЉПпЉМдЉЪиЗ™еК®еЬ∞еЬ®nameеРОйЭҐеК†дЄКдЄАдЄ™йАТеҐЮзЪДжХ∞е≠ЧжЭ•жПТеЕ•жЦ∞еЕГзі†гАВеПѓдї•зФ®еЕґ¬†childrenжЭ•жЮДеїЇдЄАдЄ™queueзЪДжХ∞жНЃзїУжЮДпЉМofferзЪДжЧґеАЩдљњзФ®createпЉМtakeзЪДжЧґеАЩжМЙзЕІchildrenзЪДй°ЇеЇПеИ†йЩ§зђђдЄАдЄ™еН≥еПѓгАВ¬†ZooKeeperдњЭйЪЬдЇЖеРДдЄ™serverдЄКжХ∞жНЃжШѓдЄАиЗізЪДпЉМеЫ†ж≠§дєЯе∞±еЃЮзО∞дЇЖдЄАдЄ™¬†еИЖеЄГеЉП¬†QueueгАВtakeеТМofferзЪДеЃЮдЊЛдї£з†Бе¶ВдЄЛжЙАз§ЇпЉЪ
 
- /** 
-  * Removes the head of the queue and returns it, blocks until it succeeds. 
-  * @return The former head of the queue 
-  * @throws NoSuchElementException 
-  * @throws KeeperException 
-  * @throws InterruptedException 
-  */  
- public byte[] take() throws KeeperException, InterruptedException {  
-     TreeMap<Long,String> orderedChildren;  
-     // Same as for element.  Should refactor this.  
-     while(true){  
-         LatchChildWatcher childWatcher = new LatchChildWatcher();  
-         try{  
-             orderedChildren = orderedChildren(childWatcher);  
-         }catch(KeeperException.NoNodeException e){  
-             zookeeper.create(dir, new byte[0], acl, CreateMode.PERSISTENT);  
-             continue;  
-         }  
-         if(orderedChildren.size() == 0){  
-             childWatcher.await();  
-             continue;  
-         }  
-         for(String headNode : orderedChildren.values()){  
-             String path = dir +"/"+headNode;  
-             try{  
-                 byte[] data = zookeeper.getData(path, false, null);  
-                 zookeeper.delete(path, -1);  
-                 return data;  
-             }catch(KeeperException.NoNodeException e){  
-                 // Another client deleted the node first.  
-             }  
-         }  
-     }  
- }  
- /** 
-  * Inserts data into queue. 
-  * @param data 
-  * @return true if data was successfully added 
-  */  
- public boolean offer(byte[] data) throws KeeperException, InterruptedException{  
-     for(;;){  
-         try{  
-             zookeeper.create(dir+"/"+prefix, data, acl, CreateMode.PERSISTENT_SEQUENTIAL);  
-             return true;  
-         }catch(KeeperException.NoNodeException e){  
-             zookeeper.create(dir, new byte[0], acl, CreateMode.PERSISTENT);  
-         }  
-     }  
- }  
 
3пЉЙеИЖеЄГеЉПlock
еИ©зФ®¬†ZooKeeperеЃЮзО∞¬†еИЖеЄГеЉПlockпЉМдЄїи¶БжШѓйАЪињЗдЄАдЄ™NodeжЭ•дї£и°®дЄАдЄ™LockпЉМељУдЄАдЄ™clientеОїжЛњйФБзЪДжЧґеАЩпЉМдЉЪеЬ®ињЩдЄ™NodeдЄЛеИЫеїЇдЄАдЄ™иЗ™еҐЮеЇПеИЧзЪДchildпЉМзДґеРОйАЪињЗgetChildren()жЦєеЉПжЭ•checkеИЫеїЇзЪДchildжШѓдЄНжШѓжЬАйЭ†еЙНзЪДпЉМе¶ВжЮЬжШѓеИЩжЛњеИ∞йФБпЉМеР¶еИЩе∞±и∞ГзФ®exist()жЭ•checkзђђдЇМйЭ†еЙНзЪДchildпЉМеєґеК†дЄКwatchжЭ•зЫСиІЖгАВељУжЛњеИ∞йФБзЪДchildжЙІи°МеЃМеРОељТињШйФБпЉМељТињШйФБдїЕдїЕйЬАи¶БеИ†йЩ§иЗ™еЈ±еИЫеїЇзЪДchildпЉМињЩжЧґwatchжЬЇеИґдЉЪйАЪзЯ•еИ∞жЙАжЬЙж≤°жЬЙжЛњеИ∞йФБзЪДclientпЉМињЩдЇЫchildе∞±дЉЪж†єжНЃеЙНйЭҐжЙАиЃ≤зЪДжЛњйФБиІДеИЩжЭ•зЂЮдЇЙйФБгАВ
 



зЫЄеЕ≥жО®иНР
1. йЕНзљЃзЃ°зРЖпЉЪйЫЖдЄ≠е≠ШеВ®еТМзЃ°зРЖеИЖеЄГеЉПз≥їзїЯзЪДйЕНзљЃдњ°жБѓпЉМжЙАжЬЙиКВзВєйГљеПѓдї•дїОZookeeperиОЈеПЦжЬАжЦ∞йЕНзљЃпЉМз°ЃдњЭйЕНзљЃзЪДдЄАиЗіжАІгАВ 2. еРНзІ∞жЬНеК°пЉЪдЄЇеИЖеЄГеЉПзїДдїґжПРдЊЫеСљеРНжЬНеК°пЉМе¶ВжЬНеК°еПСзО∞пЉМеЃҐжИЈзЂѓеПѓдї•йАЪињЗеРНзІ∞жЙЊеИ∞жЬНеК°жПРдЊЫиАЕзЪДеЬ∞еЭАгАВ 3...
гАКдїОPaxosеИ∞ZookeeperеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµгАЛдЄОгАКZooKeeper-еИЖеЄГеЉПињЗз®ЛеНПеРМжКАжЬѓиѓ¶иІ£гАЛињЩдЄ§жЬђдє¶жЈ±еЕ•жОҐиЃ®дЇЖеИЖеЄГеЉПз≥їзїЯдЄ≠зЪДдЄАдЄ™йЗНи¶Бж¶ВењµвАФвАФдЄАиЗіжАІпЉМдї•еПКе¶ВдљХйАЪињЗZooKeeperињЩдЄАеЈ•еЕЈжЭ•еЃЮзО∞йЂШжХИзЪДеИЖеЄГеЉПеНПеРМгАВ...
дїОPaxosеИ∞ZookeeperеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµ.pdfдїОPaxosеИ∞ZookeeperеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµ.pdfдїОPaxosеИ∞ZookeeperеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµ.pdfдїОPaxosеИ∞ZookeeperеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµ.pdfдїОPaxosеИ∞ZookeeperеИЖеЄГеЉП...
гАКдїОPAXOSеИ∞ZOOKEEPERпЉЪеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµгАЛжШѓдЄАжЬђжЈ±еЕ•жОҐиЃ®еИЖеЄГеЉПз≥їзїЯдЄ≠дЄАиЗіжАІйЧЃйҐШзЪДиСЧдљЬгАВеЬ®ељУдїКе§ІжХ∞жНЃеТМдЇСиЃ°зЃЧзЪДжЧґдї£иГМжЩѓдЄЛпЉМеИЖеЄГеЉПз≥їзїЯзЪДеЇФзФ®иґКжЭ•иґКеєњж≥ЫпЉМиАМеЕґдЄ≠зЪДж†ЄењГжМСжИШдєЛдЄАе∞±жШѓе¶ВдљХдњЭиѓБжХ∞жНЃзЪДдЄАиЗіжАІгАВ...
гАКдїОPaxosеИ∞ZookeeperеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµгАЛжШѓдЄАжЬђжЈ±еЕ•жОҐиЃ®еИЖеЄГеЉПз≥їзїЯдЄАиЗіжАІйЧЃйҐШзЪДиСЧдљЬпЉМеЕґдЄ≠йЗНзВєиЃ≤иІ£дЇЖPaxosзЃЧж≥ХдЄОZookeeperеЬ®еЃЮйЩЕеЇФзФ®дЄ≠зЪДзРЖиЃЇдЄОеЃЮиЈµгАВPaxosжШѓеИЖеЄГеЉПиЃ°зЃЧйҐЖеЯЯдЄ≠иСЧеРНзЪДеЕ±иѓЖзЃЧж≥ХпЉМдЄЇиІ£еЖ≥еИЖеЄГеЉП...
гАКдїОPaxosеИ∞ZookeeperпЉЪеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµгАЛињЩжЬђдє¶жЈ±еЕ•жµЕеЗЇеЬ∞жОҐиЃ®дЇЖеИЖеЄГеЉПз≥їзїЯдЄ≠зЪДдЄАдЄ™йЗНи¶Бж¶ВењµвАФвАФдЄАиЗіжАІпЉМдї•еПКе¶ВдљХеЬ®еЃЮйЩЕжУНдљЬдЄ≠йАЪињЗPaxosзЃЧж≥ХеТМZookeeperеЃЮзО∞ињЩдЄАж¶ВењµгАВеИЖеЄГеЉПдЄАиЗіжАІжШѓеИЖеЄГеЉПз≥їзїЯиЃЊиЃ°зЪДж†ЄењГпЉМ...
йАЪињЗе≠¶дє†гАКдїОPaxosеИ∞ZookeeperпЉЪеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµгАЛпЉМжИСдїђдЄНдїЕдЇЖиІ£дЇЖPaxosзЃЧж≥ХзЪДеЯЇжЬђжАЭжГ≥дї•еПКеЕґеЬ®иІ£еЖ≥еИЖеЄГеЉПдЄАиЗіжАІйЧЃйҐШдЄКзЪДйЗНи¶БдљЬзФ®пЉМињШжЈ±еЕ•дЇЖиІ£дЇЖZookeeperињЩдЄАйЂШжХИеПѓйЭ†зЪДеНПи∞ГжЬНеК°ж°ЖжЮґжШѓе¶ВдљХеЬ®еЃЮйЩЕеЬЇжЩѓдЄ≠еЇФзФ®...
еИЖеЄГеЉПиЃЊиЃ°дЄОеЉАеПСжШѓзО∞дї£дЇТиБФзљСжЮґжЮДдЄ≠зЪДйЗНи¶БзїДжИРйГ®еИЖпЉМеЃГеЕБиЃЄжИСдїђе∞Же§ІеЮЛе§НжЭВз≥їзїЯеИЖиІ£дЄЇе§ЪдЄ™зЫЄдЇТеНПдљЬзЪДзЛђзЂЛжЬНеК°гАВеЬ®ињЩдЄ™з≥їеИЧзЪДзђђдЄАйГ®еИЖпЉМжИСдїђе∞ЖйЗНзВєеЕ≥ж≥®ZookeeperвАФвАФдЄАдЄ™еєњж≥ЫдљњзФ®зЪДеИЖеЄГеЉПеНПи∞ГжЬНеК°гАВZookeeperзФ±Apache...
ZooKeeper зЪДиЃЊиЃ°зЫЃж†ЗжШѓзЃАеМЦеИЖеЄГеЉПз≥їзїЯдЄ≠зЪДжХ∞жНЃдЄАиЗіжАІйЧЃйҐШпЉМдЄЇеИЖеЄГеЉПеЇФзФ®жПРдЊЫзїЯдЄАзЪДжЬНеК°зЫЃељХеТМйЕНзљЃзЃ°зРЖгАВеЬ® Apache ZooKeeper 3.7.0 зЙИжЬђдЄ≠пЉМеЃГеМЕеРЂдЇЖеѓєеЕИеЙНзЙИжЬђзЪДжФєињЫеТМжЦ∞еКЯиГљпЉМдї•жЫіе•љеЬ∞йАВеЇФзО∞дї£еИЖеЄГеЉПз≥їзїЯзЪДе§НжЭВ...
гАКPaxosеИ∞ZookeeperвАФвАФеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµгАЛжШѓдЄАжЬђжЈ±еЕ•жОҐиЃ®еИЖеЄГеЉПдЄАиЗіжАІйЧЃйҐШзЪДдє¶з±НпЉМеѓєдЇОзРЖиІ£еєґеЇФзФ®ZookeeperињЩдЄАеЕ≥йФЃзЪДеИЖеЄГеЉПеНПи∞Гз≥їзїЯеЕЈжЬЙйЗНи¶БдїЈеАЉгАВжЬђдє¶жЧ®еЬ®еЄЃеК©иѓїиАЕжОМжП°еИЖеЄГеЉПзОѓеҐГдЄ≠зЪДжХ∞жНЃдЄАиЗіжАІеОЯзРЖпЉМеєґ...
дїОPaxosеИ∞Zookeeper еИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµ еА™иґЕ,еЃМжХізЙИ
йАЪињЗйШЕиѓїгАКдїОPAXOSеИ∞ZOOKEEPERеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµгАЛпЉМеЉАеПСиАЕдЄНдїЕеПѓдї•жЈ±еЕ•зРЖиІ£еИЖеЄГеЉПдЄАиЗіжАІзЪДйЗНи¶БжАІеТМжМСжИШпЉМињШиГљиОЈеЊЧеЃЮзФ®зЪДеЈ•еЕЈеТМжЦєж≥ХпЉМеЄЃеК©дїЦдїђеЬ®еИЖеЄГеЉПз≥їзїЯзЪДиЃЊиЃ°еТМеЃЮзО∞дЄ≠еЃЮзО∞йЂШжХИгАБеПѓйЭ†зЪДеНПи∞ГеТМдЄАиЗіжАІгАВ...
еЃГжШѓдЄАдЄ™дЄЇеИЖеЄГеЉПеЇФзФ®жПРдЊЫдЄАиЗіжАІжЬНеК°зЪДиљѓдїґпЉМжПРдЊЫзЪДеКЯиГљеМЕжЛђпЉЪйЕНзљЃзїіжК§гАБеЯЯеРНжЬНеК°гАБеИЖеЄГеЉПеРМж≠•гАБзїДжЬНеК°з≠ЙгАВ ZooKeeperзЪДзЫЃж†Зе∞±жШѓе∞Би£Ее•ље§НжЭВжШУеЗЇйФЩзЪДеЕ≥йФЃжЬНеК°пЉМе∞ЖзЃАеНХжШУзФ®зЪДжО•еП£еТМжАІиГљйЂШжХИгАБеКЯиГљз®≥еЃЪзЪДз≥їзїЯжПРдЊЫзїЩзФ®жИЈ...
ZookeeperжШѓзФ±ApacheиљѓдїґеЯЇйЗСдЉЪеЉАеПСзЪДдЄАдЄ™еЉАжЇРй°єзЫЃпЉМдЄїи¶БзФ®дЇОиІ£еЖ≥еИЖеЄГеЉПеЇФзФ®дЄ≠зЪДжХ∞жНЃдЄАиЗіжАІйЧЃйҐШпЉМжПРдЊЫиѓЄе¶ВеСљеРНжЬНеК°гАБйЕНзљЃзЃ°зРЖгАБйЫЖзЊ§зЃ°зРЖз≠Йе§ЪзІНеКЯиГљгАВеЬ®ињЩдЄ™жЬАжЦ∞зЙИзЪДиѓ¶иІ£дЄ≠пЉМдљЬиАЕиѓ¶зїЖдїЛзїНдЇЖZookeeperзЪДж†ЄењГж¶ВењµгАБиЃЊиЃ°...
ZookeeperжШѓдЄАжђЊеЉАжЇРзЪДеИЖеЄГеЉПеНПи∞ГжЬНеК°ж°ЖжЮґпЉМеЃГдЄїи¶БзФ®дЇОиІ£еЖ≥еИЖеЄГеЉПеЇФзФ®дЄ≠еЄЄиІБзЪДдЄАиЗіжАІйЧЃйҐШпЉМе¶ВеСљеРНжЬНеК°гАБйЕНзљЃзЃ°зРЖгАБйЫЖзЊ§зЃ°зРЖеТМеИЖеЄГеЉПйФБз≠ЙгАВZookeeperйАЪињЗжПРдЊЫзЃАеНХзЪДAPIпЉМдљњеЊЧеЉАеПСиАЕиГље§ЯиљїжЭЊеЬ∞еИ©зФ®еЕґеЉЇе§ІзЪДеКЯиГљжЭ•жЮДеїЇ...
еЃГзЪДиЃЊиЃ°зЫЃж†ЗжШѓзЃАеНХгАБйЂШжХИдЄФйЂШеПѓзФ®пЉМйАЪињЗдЄАиЗіжАІеНПиЃЃдњЭиѓБжХ∞жНЃзЪДдЄАиЗіжАІгАВ еЬ®еЃЙи£ЕZookeeper 3.2.2ињЩдЄ™з®≥еЃЪзЙИжЬђжЧґпЉМй¶ЦеЕИеПѓдї•дїОеЃШжЦєзљСзЂЩhttp://hadoop.apache.org/zookeeper/дЄЛиљљжЬАжЦ∞зЙИжЬђгАВеѓєдЇОеНХжЬЇж®°еЉПзЪДеЃЙи£ЕпЉМеП™йЬАиІ£еОЛ...
дїОPaxosеИ∞Zookeeper еИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµ