
转:http://blog.csdn.net/java3344520/article/details/5515497
如何看懂ORACLE执行计划
一、什么是执行计划
An explain plan is a representation of the access path that is taken when a query is executed within Oracle.
二、如何访问数据
At the physical level Oracle reads blocks of data. The smallest amount of data read is a single Oracle block, the largest is constrained by operating system limits (and multiblock i/o). Logically Oracle finds the data to read by using the following methods:
Full Table Scan (FTS) --全表扫描
Index Lookup (unique & non-unique) --索引扫描(唯一和非唯一)
Rowid --物理行id
三、执行计划层次关系
When looking at a plan, the rightmost (ie most inndented) uppermost operation is the first thing that is executed.--采用最右最上最先执行的原则看层次关系,在同一级如果某个动作没有子ID就最先执行
1.一个简单的例子:
SQL> select /*+parallel (e 4)*/ * from emp e;
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=1 Card=82 Bytes=7134)
1 0 TABLE ACCESS* (FULL) OF 'EMP' (Cost=1 Card=82 Bytes=7134):Q5000
--[:Q5000]表示是并行方式
1 PARALLEL_TO_SERIAL SELECT /*+ NO_EXPAND ROWID(A1) */ A1."EMPNO"
,A1."ENAME",A1."JOB",A1."MGR",A1."HI
优化模式是CHOOSE的情况下,看Cost参数是否有值来决定采用CBO还是RBO:
SELECT STATEMENT [CHOOSE] Cost=1234 --Cost有值,采用CBO
SELECT STATEMENT [CHOOSE] --Cost为空,采用RBO(9I是如此显示的)
2.层次的父子关系的例子:
PARENT1
**FIRST CHILD
****FIRST GRANDCHILD
**SECOND CHILD
Here the same principles apply, the FIRST GRANDCHILD is the initial operation then the FIRST CHILD followed by the SECOND CHILD and finally the PARENT collates the output.
四、例子解说
Execution Plan
----------------------------------------------------------
0 **SELECT STATEMENT Optimizer=CHOOSE (Cost=3 Card=8 Bytes=248)
1 0 **HASH JOIN (Cost=3 Card=8 Bytes=248)
2 1 ****TABLE ACCESS (FULL) OF 'DEPT' (Cost=1 Card=3 Bytes=36)
3 1 ****TABLE ACCESS (FULL) OF 'EMP' (Cost=1 Card=16 Bytes=304)
左侧的两排数据,前面的是序列号ID,后面的是对应的PID(父ID)。
A shortened summary of this is:
Execution starts with ID=0: SELECT STATEMENT but this is dependand on it's child objects
So it executes its first child step: ID=1 PID=0 HASH JOIN but this is dependand on it's child objects
So it executes its first child step: ID=2 PID=1 TABLE ACCESS (FULL) OF 'DEPT'
Then the second child step: ID=3 PID=2 TABLE ACCESS (FULL) OF 'EMP'
Rows are returned to the parent step(s) until finished
五、表访问方式
1.Full Table Scan (FTS) 全表扫描
In a FTS operation, the whole table is read up to the high water mark (HWM). The HWM marks the last block in the table that has ever had data written to it. If you have deleted all the rows then you will still read up to the HWM. Truncate resets the HWM back to the start of the table. FTS uses multiblock i/o to read the blocks from disk. --全表扫描模式下会读数据到表的高水位线(HWM即表示表曾经扩展的最后一个数据块),读取速度依赖于Oracle初始化参数db_block_multiblock_read_count(我觉得应该这样翻译:FTS扫描会使表使用上升到高水位(HWM),HWM标识了表最后写入数据的块,如果你用DELETE删除了所有的数据表仍然处于高水位(HWM),只有用TRUNCATE才能使表回归,FTS使用多IO从磁盘读取数据块).
Query Plan
------------------------------------
SELECT STATEMENT [CHOOSE] Cost=1
**INDEX UNIQUE SCAN EMP_I1 --如果索引里就找到了所要的数据,就不会再去访问表
2.Index Lookup 索引扫描
There are 5 methods of index lookup:
index unique scan --索引唯一扫描
Method for looking up a single key value via a unique index. always returns a single value, You must supply AT LEAST the leading column of the index to access data via the index.
eg:SQL> explain plan for select empno,ename from emp where empno=10;
index range scan --索引局部扫描
Index range scan is a method for accessing a range values of a particular column. AT LEAST the leading column of the index must be supplied to access data via the index. Can be used for range operations (e.g. > < <> >= <= between) .
eg:SQL> explain plan for select mgr from emp where mgr = 5;
index full scan --索引全局扫描
Full index scans are only available in the CBO as otherwise we are unable to determine whether a full scan would be a good idea or not. We choose an index Full Scan when we have statistics that indicate that it is going to be more efficient than a Full table scan and a sort. For example we may do a Full index scan when we do an unbounded scan of an index and want the data to be ordered in the index order.
eg: SQL> explain plan for select empno,ename from big_emp order by empno,ename;
index fast full scan --索引快速全局扫描,不带order by情况下常发生
Scans all the block in the index, Rows are not returned in sorted order, Introduced in 7.3 and requires V733_PLANS_ENABLED=TRUE and CBO, may be hinted using INDEX_FFS hint, uses multiblock i/o, can be executed in parallel, can be used to access second column of concatenated indexes. This is because we are selecting all of the index.
eg: SQL> explain plan for select empno,ename from big_emp;
index skip scan --索引跳跃扫描,where条件列是非索引的前导列情况下常发生
Index skip scan finds rows even if the column is not the leading column of a concatenated index. It skips the first column(s) during the search.
eg:SQL> create index i_emp on emp(empno, ename);
SQL> select /*+ index_ss(emp i_emp)*/ job from emp where ename='SMITH';
3.Rowid 物理ID扫描
This is the quickest access method available.Oracle retrieves the specified block and extracts the rows it is interested in. --Rowid扫描是最快的访问数据方式
六、表连接方式
七、运算符
1.sort --排序,很消耗资源
There are a number of different operations that promote sorts:
(1)order by clauses (2)group by (3)sort merge join –-这三个会产生排序运算
2.filter --过滤,如not in、min函数等容易产生
Has a number of different meanings, used to indicate partition elimination, may also indicate an actual filter step where one row source is filtering, another, functions such as min may introduce filter steps into query plans.
3.view --视图,大都由内联视图产生(可能深入到视图基表)
When a view cannot be merged into the main query you will often see a projection view operation. This indicates that the 'view' will be selected from directly as opposed to being broken down into joins on the base tables. A number of constructs make a view non mergeable. Inline views are also non mergeable.
eg: SQL> explain plan for
select ename,tot from emp,(select empno,sum(empno) tot from big_emp group by empno) tmp
where emp.empno = tmp.empno;
Query Plan
------------------------
SELECT STATEMENT [CHOOSE]
**HASH JOIN
**TABLE ACCESS FULL EMP [ANALYZED]
**VIEW
****SORT GROUP BY
******INDEX FULL SCAN BE_IX
4.partition view --分区视图
Partition views are a legacy technology that were superceded by the partitioning option. This section of the article is provided as reference for such legacy systems.
示例:假定A、B、C都是不是小表,且在A表上一个组合索引:A(a.col1,a.col2) ,注意a.col1列为索引的引导列。考虑下面的查询:
select A.col4 from A , B , C
where B.col3 = 10 and A.col1 = B.col1 and A.col2 = C.col2 and C.col3 = 5;
Execution Plan
------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 MERGE JOIN
2 1 SORT (JOIN)
3 2 NESTED LOOPS
4 3 TABLE ACCESS (FULL) OF 'B'
5 3 TABLE ACCESS (BY INDEX ROWID) OF 'A'
6 5 INDEX (RANGE SCAN) OF 'INX_COL12A' (NON-UNIQUE)
7 1 SORT (JOIN)
8 7 TABLE ACCESS (FULL) OF 'C'
Statistics(统计信息参数,参见另外个转载的文章)
--------------------------------------
0 recursive calls(归调用次数)
8 db block gets(从磁盘上读取的块数,即通过update/delete/select for update读的次数)
6 consistent gets(从内存里读取的块数,即通过不带for update的select 读的次数)
0 physical reads(物理读—从磁盘读到数据块数量,一般来说是'consistent gets' + 'db block gets')
0 redo size (重做数——执行SQL的过程中,产生的重做日志的大小)
551 bytes sent via SQL*Net to client
430 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
2 sorts (memory) (在内存中发生的排序)
0 sorts (disk) (在硬盘中发生的排序)
6 rows processed
在表做连接时,只能2个表先做连接,然后将连接后的结果作为一个row source,与剩下的表做连接,在上面的例子中,连接顺序为B与A先连接,然后再与C连接:
B <---> A <---> C
col3=10 col3=5
如果没有执行计划,分析一下,上面的3个表应该拿哪一个作为第一个驱动表?从SQL语句看来,只有B表与C表上有限制条件,所以第一个驱动表应该为这2个表中的一个,到底是哪一个呢?
B表有谓词B.col3 = 10,这样在对B表做全表扫描的时候就将where子句中的限制条件(B.col3 = 10)用上,从而得到一个较小的row source, 所以B表应该作为第一个驱动表。而且这样的话,如果再与A表做关联,可以有效利用A表的索引(因为A表的col1列为leading column)。
上面的查询中C表上也有谓词(C.col3 = 5),有人可能认为C表作为第一个驱动表也能获得较好的性能。让我们再来分析一下:如果C表作为第一个驱动表,则能保证驱动表生成很小的row source,但是看看连接条件A.col2 = C.col2,此时就没有机会利用A表的索引,因为A表的col2列不为leading column,这样nested loop的效率很差,从而导致查询的效率很差。所以对于NL连接选择正确的驱动表很重要。
因此上面查询比较好的连接顺序为(B - - > A) - - > C。如果数据库是基于代价的优化器,它会利用计算出的代价来决定合适的驱动表与合适的连接顺序。一般来说,CBO都会选择正确的连接顺序,如果CBO选择了比较差的连接顺序,我们还可以使用ORACLE提供的hints来让CBO采用正确的连接顺序。如下所示
select /*+ ordered */ A.col4
from B,A,C
where B.col3 = 10 and A.col1 = B.col1 and A.col2 = C.col2 and C.col3 = 5
既然选择正确的驱动表这么重要,那么让我们来看一下执行计划,到底各个表之间是如何关联的,从而得到执行计划中哪个表应该为驱动表:
在执行计划中,需要知道哪个操作是先执行的,哪个操作是后执行的,这对于判断哪个表为驱动表有用处。判断之前,如果对表的访问是通过rowid,且该rowid的值是从索引扫描中得来得,则将该索引扫描先从执行计划中暂时去掉。然后在执行计划剩下的部分中,判断执行顺序的指导原则就是:最右、最上的操作先执行。具体解释如下:
得到去除妨碍判断的索引扫描后的执行计划:Execution Plan
-------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 MERGE JOIN
2 1 SORT (JOIN)
3 2 NESTED LOOPS
4 3 TABLE ACCESS (FULL) OF 'B'
5 3 TABLE ACCESS (BY INDEX ROWID) OF 'A'
6 5 INDEX (RANGE SCAN) OF 'INX_COL12A' (NON-UNIQUE)
7 1 SORT (JOIN)
8 7 TABLE ACCESS (FULL) OF 'C'
看执行计划的第3列,即字母部分,每列值的左面有空格作为缩进字符。在该列值左边的空格越多,说明该列值的缩进越多,该列值也越靠右。如上面的执行计划所示:第一列值为6的行的缩进最多,即该行最靠右;第一列值为4、5的行的缩进一样,其靠右的程度也一样,但是第一列值为4的行比第一列值为5的行靠上;谈论上下关系时,只对连续的、缩进一致的行有效。
从这个图中我们可以看到,对于NESTED LOOPS部分,最右、最上的操作是TABLE ACCESS (FULL) OF 'B',所以这一操作先执行,所以该操作对应的B表为第一个驱动表(外部表),自然,A表就为内部表了。从图中还可以看出,B与A表做嵌套循环后生成了新的row source ,对该row source进行来排序后,与C表对应的排序了的row source(应用了C.col3 = 5限制条件)进行SMJ连接操作。所以从上面可以得出如下事实:B表先与A表做嵌套循环,然后将生成的row source与C表做排序—合并连接。
通过分析上面的执行计划,我们不能说C表一定在B、A表之后才被读取,事实上,B表有可能与C表同时被读入内存,因为将表中的数据读入内存的操作可能为并行的。事实上许多操作可能为交叉进行的,因为ORACLE读取数据时,如果就是需要一行数据也是将该行所在的整个数据块读入内存,而且有可能为多块读。
看执行计划时,我们的关键不是看哪个操作先执行,哪个操作后执行,而是关键看表之间连接的顺序(如得知哪个为驱动表,这需要从操作的顺序进行判断)、使用了何种类型的关联及具体的存取路径(如判断是否利用了索引)
在从执行计划中判断出哪个表为驱动表后,根据我们的知识判断该表作为驱动表(就像上面判断ABC表那样)是否合适,如果不合适,对SQL语句进行更改,使优化器可以选择正确的驱动表。
**********************************************
转:http://blog.csdn.net/tianlesoftware/article/details/5827245
如果要分析某条SQL的性能问题,通常我们要先看SQL的执行计划,看看SQL的每一步执行是否存在问题。 如果一条SQL平时执行的好好的,却有一天突然性能很差,如果排除了系统资源和阻塞的原因,那么基本可以断定是执行计划出了问题。
看懂执行计划也就成了SQL优化的先决条件。 这里的SQL优化指的是SQL性能问题的定位,定位后就可以解决问题。
一. 查看执行计划的三种方法
1.1 设置autotrace
|
序号 |
命令 |
解释 |
|
1 |
SET AUTOTRACE OFF |
此为默认值,即关闭Autotrace |
|
2 |
SET AUTOTRACE ON EXPLAIN |
只显示执行计划 |
|
3 |
SET AUTOTRACE ON STATISTICS |
只显示执行的统计信息 |
|
4 |
SET AUTOTRACE ON |
包含2,3两项内容 |
|
5 |
SET AUTOTRACE TRACEONLY |
与ON相似,但不显示语句的执行结果 |
SQL> set autotrace on
SQL> select * from dave;
ID NAME
---------- ----------
8 安庆
1 dave
2 bl
1 bl
2 dave
3 dba
4 sf-express
5 dmm
已选择8行。
执行计划
----------------------------------------------------------
Plan hash value: 3458767806
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 8 | 64 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| DAVE | 8 | 64 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
4 consistent gets
0 physical reads
0 redo size
609 bytes sent via SQL*Net to client
416 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
8 rows processed
SQL>
1.2 使用SQL
SQL>EXPLAIN PLAN FOR sql语句;
SQL>SELECT plan_table_output FROM TABLE(DBMS_XPLAN.DISPLAY('PLAN_TABLE'));
示例:
SQL> EXPLAIN PLAN FOR SELECT * FROM DAVE;
已解释。
SQL> SELECT plan_table_output FROM TABLE(DBMS_XPLAN.DISPLAY('PLAN_TABLE'));
或者:
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 3458767806
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 8 | 64 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| DAVE | 8 | 64 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------
已选择8行。
执行计划
----------------------------------------------------------
Plan hash value: 2137789089
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 8168 | 16336 | 29 (0)| 00:00:01 |
| 1 | COLLECTION ITERATOR PICKLER FETCH| DISPLAY | 8168 | 16336 | 29 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
25 recursive calls
12 db block gets
168 consistent gets
0 physical reads
0 redo size
974 bytes sent via SQL*Net to client
416 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
8 rows processed
SQL>
1.3 使用Toad,PL/SQL Developer工具
二. Cardinality(基数)/ rows
Cardinality值表示CBO预期从一个行源(row source)返回的记录数,这个行源可能是一个表,一个索引,也可能是一个子查询。 在Oracle 9i中的执行计划中,Cardinality缩写成Card。 在10g中,Card值被rows替换。
这是9i的一个执行计划,我们可以看到关键字Card:
执行计划
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=1 Bytes=402)
1 0 TABLE ACCESS (FULL) OF 'TBILLLOG8' (Cost=2 Card=1 Bytes=402)
Oracle 10g的执行计划,关键字换成了rows:
执行计划
----------------------------------------------------------
Plan hash value: 2137789089
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 8168 | 16336 | 29 (0)| 00:00:01 |
| 1 | COLLECTION ITERATOR PICKLER FETCH| DISPLAY | 8168 | 16336 | 29 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Cardinality的值对于CBO做出正确的执行计划来说至关重要。 如果CBO获得的Cardinality值不够准确(通常是没有做分析或者分析数据过旧造成),在执行计划成本计算上就会出现偏差,从而导致CBO错误的制定出执行计划。
在多表关联查询或者SQL中有子查询时,每个关联表或子查询的Cardinality的值对主查询的影响都非常大,甚至可以说,CBO就是依赖于各个关联表或者子查询Cardinality值计算出最后的执行计划。
对于多表查询,CBO使用每个关联表返回的行数(Cardinality)决定用什么样的访问方式来做表关联(如Nested loops Join 或 hash Join)。
多表连接的三种方式详解 HASH JOIN MERGE JOIN NESTED LOOP
http://blog.csdn.net/tianlesoftware/archive/2010/08/20/5826546.aspx
对于子查询,它的Cardinality将决定子查询是使用索引还是使用全表扫描的方式访问数据。
三. SQL 的执行计划
生成SQL的执行计划是Oracle在对SQL做硬解析时的一个非常重要的步骤,它制定出一个方案告诉Oracle在执行这条SQL时以什么样的方式访问数据:索引还是全表扫描,是Hash Join还是Nested loops Join等。 比如说某条SQL通过使用索引的方式访问数据是最节省资源的,结果CBO作出的执行计划是全表扫描,那么这条SQL的性能必然是比较差的。
Oracle SQL的硬解析和软解析
http://blog.csdn.net/tianlesoftware/archive/2010/04/08/5458896.aspx
示例:
SQL> SET AUTOTRACE TRACEONLY; -- 只显示执行计划,不显示结果集
SQL> select * from scott.emp a,scott.emp b where a.empno=b.mgr;
已选择13行。
执行计划
----------------------------------------------------------
Plan hash value: 992080948
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 13 | 988 | 6 (17)| 00:00:01 |
| 1 | MERGE JOIN | | 13 | 988 | 6 (17)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| EMP | 14 | 532 | 2 (0)| 00:00:01 |
| 3 | INDEX FULL SCAN | PK_EMP | 14 | | 1 (0)| 00:00:01 |
|* 4 | SORT JOIN | | 13 | 494 | 4 (25)| 00:00:01 |
|* 5 | TABLE ACCESS FULL | EMP | 13 | 494 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("A"."EMPNO"="B"."MGR")
filter("A"."EMPNO"="B"."MGR")
5 - filter("B"."MGR" IS NOT NULL)
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
11 consistent gets
0 physical reads
0 redo size
2091 bytes sent via SQL*Net to client
416 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
13 rows processed
SQL>
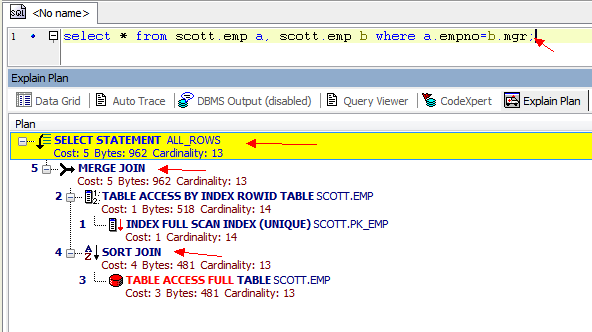
图片是Toad工具查看的执行计划。 在Toad 里面,很清楚的显示了执行的顺序。 但是如果在SQLPLUS里面就不是那么直接。 但我们也可以判断:一般按缩进长度来判断,缩进最大的最先执行,如果有2行缩进一样,那么就先执行上面的。
3.1 执行计划中字段解释:
ID: 一个序号,但不是执行的先后顺序。执行的先后根据缩进来判断。
Operation: 当前操作的内容。
Rows: 当前操作的Cardinality,Oracle估计当前操作的返回结果集。
Cost(CPU):Oracle 计算出来的一个数值(代价),用于说明SQL执行的代价。
Time:Oracle 估计当前操作的时间。
3.2 谓词说明:
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("A"."EMPNO"="B"."MGR")
filter("A"."EMPNO"="B"."MGR")
5 - filter("B"."MGR" IS NOT NULL)
Access: 表示这个谓词条件的值将会影响数据的访问路劲(表还是索引)。
Filter:表示谓词条件的值不会影响数据的访问路劲,只起过滤的作用。
在谓词中主要注意access,要考虑谓词的条件,使用的访问路径是否正确。
3.3 统计信息说明:
db block gets : 从buffer cache中读取的block的数量
consistent gets: 从buffer cache中读取的undo数据的block的数量
physical reads: 从磁盘读取的block的数量
redo size: DML生成的redo的大小
sorts (memory) :在内存执行的排序量
sorts (disk) :在磁盘上执行的排序量
Physical Reads通常是我们最关心的,如果这个值很高,说明要从磁盘请求大量的数据到Buffer Cache里,通常意味着系统里存在大量全表扫描的SQL语句,这会影响到数据库的性能,因此尽量避免语句做全表扫描,对于全表扫描的SQL语句,建议增 加相关的索引,优化SQL语句来解决。
关于physical reads ,db block gets 和consistent gets这三个参数之间有一个换算公式:
数据缓冲区的使用命中率=1 - ( physical reads / (db block gets + consistent gets) )。
用以下语句可以查看数据缓冲区的命中率:
SQL>SELECT name, value FROM v$sysstat WHERE name IN ('db block gets', 'consistent gets','physical reads');
查询出来的结果Buffer Cache的命中率应该在90%以上,否则需要增加数据缓冲区的大小。
Recursive Calls: Number of recursive calls generated at both the user and system level.
Oracle Database maintains tables used for internal processing. When it needs to change these tables, Oracle Database generates an internal SQL statement, which in turn generates a recursive call. In short, recursive calls are basically SQL performed on behalf of your SQL. So, if you had to parse the query, for example, you might have had to run some other queries to get data dictionary information. These would be recursive calls. Space management, security checks, calling PL/SQL from SQL—all incur recursive SQL calls。
DB Block Gets: Number of times a CURRENT block was requested.
Current mode blocks are retrieved as they exist right now, not in a consistent read fashion. Normally, blocks retrieved for a query are retrieved as they existed when the query began. Current mode blocks are retrieved as they exist right now, not from a previous point in time. During a SELECT, you might see current mode retrievals due to reading the data dictionary to find the extent information for a table to do a full scan (because you need the "right now" information, not the consistent read). During a modification, you will access the blocks in current mode in order to write to them. (DB Block Gets:请求的数据块在buffer能满足的个数)
当前模式块意思就是在操作中正好提取的块数目,而不是在一致性读的情况下而产生的块数。正常的情况下,一个查询提取的块是在查询开始的那个时间点上存在的数据块,当前块是在这个时刻存在的数据块,而不是在这个时间点之前或者之后的数据块数目。
Consistent Gets: Number of times a consistent read was requested for a block.
This is how many blocks you processed in "consistent read" mode. This will include counts of blocks read from the rollback segment in order to roll back a block. This is the mode you read blocks in with a SELECT, for example. Also, when you do a searched UPDATE/DELETE, you read the blocks in consistent read mode and then get the block in current mode to actually do the modification. (Consistent Gets: 数据请求总数在回滚段Buffer中的数据一致性读所需要的数据块)
这里的概念是在处理你这个操作的时候需要在一致性读状态上处理多少个块,这些块产生的主要原因是因为由于在你查询的过程中,由于其他会话对数据块进行操 作,而对所要查询的块有了修改,但是由于我们的查询是在这些修改之前调用的,所以需要对回滚段中的数据块的前映像进行查询,以保证数据的一致性。这样就产 生了一致性读。
Physical Reads: Total number of data blocks read from disk. This number equals the value of "physical reads direct" plus all reads into buffer cache. (Physical Reads:实例启动后,从磁盘读到Buffer Cache数据块数量)
就是从磁盘上读取数据块的数量,其产生的主要原因是:
(1) 在数据库高速缓存中不存在这些块
(2) 全表扫描
(3) 磁盘排序
它们三者之间的关系大致可概括为:
逻辑读指的是Oracle从内存读到的数据块数量。一般来说是'consistent gets' + 'db block gets'。当在内存中找不到所需的数据块的话就需要从磁盘中获取,于是就产生了'physical reads'。
Sorts(disk):
Number of sort operations that required at least one disk write. Sorts that require I/O to disk are quite resource intensive. Try increasing the size of the initialization parameter SORT_AREA_SIZE.
bytes sent via SQL*Net to client:
Total number of bytes sent to the client from the foreground processes.
bytes received via SQL*Net from client:
Total number of bytes received from the client over Oracle Net.
SQL*Net roundtrips to/from client:
Total number of Oracle Net messages sent to and received from the client.
更多内容参考Oracle联机文档:
Statistics Descriptions
http://download.oracle.com/docs/cd/E11882_01/server.112/e10820/stats002.htm#i375475
3.4 动态分析
如果在执行计划中有如下提示:
Note
------------
-dynamic sampling used for the statement
这提示用户CBO当前使用的技术,需要用户在分析计划时考虑到这些因素。 当出现这个提示,说明当前表使用了动态采样。 我们从而推断这个表可能没有做过分析。
这里会出现两种情况:
(1) 如果表没有做过分析,那么CBO可以通过动态采样的方式来获取分析数据,也可以或者正确的执行计划。
(2) 如果表分析过,但是分析信息过旧,这时CBO就不会在使用动态采样,而是使用这些旧的分析数据,从而可能导致错误的执行计划。
总结:
在看执行计划的时候,除了看执行计划本身,还需要看谓词和提示信息。 通过整体信息来判断SQL 效率。
************************************
转:http://database.51cto.com/art/200611/34273.htm
一.相关的概念
Rowid的概念:rowid是一个伪列,既然是伪列,那么这个列就不是用户定义,而是系统自己给加上的。对每个表都有一个rowid的伪列,但是表中并不物理存储ROWID列的值。不过你可以像使用其它列那样使用它,但是不能删除改列,也不能对该列的值进行修改、插入。一旦一行数据插入数据库,则rowid在该行的生命周期内是唯一的,即即使该行产生行迁移,行的rowid也不会改变。
Recursive SQL概念:有时为了执行用户发出的一个sql语句,Oracle必须执行一些额外的语句,我们将这些额外的语句称之为'recursive calls'或'recursive SQL statements'。如当一个DDL语句发出后,ORACLE总是隐含的发出一些recursive SQL语句,来修改数据字典信息,以便用户可以成功的执行该DDL语句。当需要的数据字典信息没有在共享内存中时,经常会发生Recursive calls,这些Recursive calls会将数据字典信息从硬盘读入内存中。用户不比关心这些recursive SQL语句的执行情况,在需要的时候,ORACLE会自动的在内部执行这些语句。当然DML语句与SELECT都可能引起recursive SQL。简单的说,我们可以将触发器视为recursive SQL。
Row Source(行源):用在查询中,由上一操作返回的符合条件的行的集合,即可以是表的全部行数据的集合;也可以是表的部分行数据的集合;也可以为对上2个row source进行连接操作(如join连接)后得到的行数据集合。
Predicate(谓词):一个查询中的WHERE限制条件
Driving Table(驱动表):该表又称为外层表(OUTER TABLE)。这个概念用于嵌套与HASH连接中。如果该row source返回较多的行数据,则对所有的后续操作有负面影响。注意此处虽然翻译为驱动表,但实际上翻译为驱动行源(driving row source)更为确切。一般说来,是应用查询的限制条件后,返回较少行源的表作为驱动表,所以如果一个大表在WHERE条件有有限制条件(如等值限制),则该大表作为驱动表也是合适的,所以并不是只有较小的表可以作为驱动表,正确说法应该为应用查询的限制条件后,返回较少行源的表作为驱动表。在执行计划中,应该为靠上的那个row source,后面会给出具体说明。在我们后面的描述中,一般将该表称为连接操作的row source 1。
Probed Table(被探查表):该表又称为内层表(INNER TABLE)。在我们从驱动表中得到具体一行的数据后,在该表中寻找符合连接条件的行。所以该表应当为大表(实际上应该为返回较大row source的表)且相应的列上应该有索引。在我们后面的描述中,一般将该表称为连接操作的row source 2。
组合索引(concatenated index):由多个列构成的索引,如create index idx_emp on emp(col1, col2, col3, ……),则我们称idx_emp索引为组合索引。在组合索引中有一个重要的概念:引导列(leading column),在上面的例子中,col1列为引导列。当我们进行查询时可以使用”where col1 = ? ”,也可以使用”where col1 = ? and col2 = ?”,这样的限制条件都会使用索引,但是”where col2 = ? ”查询就不会使用该索引。所以限制条件中包含先导列时,该限制条件才会使用该组合索引。
可选择性(selectivity):比较一下列中唯一键的数量和表中的行数,就可以判断该列的可选择性。如果该列的”唯一键的数量/表中的行数”的比值越接近1,则该列的可选择性越高,该列就越适合创建索引,同样索引的可选择性也越高。在可选择性高的列上进行查询时,返回的数据就较少,比较适合使用索引查询。
二.oracle访问数据的存取方法
1) 全表扫描(Full Table Scans, FTS)
为实现全表扫描,Oracle读取表中所有的行,并检查每一行是否满足语句的WHERE限制条件一个多块读操作可以使一次I/O能读取多块数据块(db_block_multiblock_read_count参数设定),而不是只读取一个数据块,这极大的减少了I/O总次数,提高了系统的吞吐量,所以利用多块读的方法可以十分高效地实现全表扫描,而且只有在全表扫描的情况下才能使用多块读操作。在这种访问模式下,每个数据块只被读一次。
使用FTS的前提条件:在较大的表上不建议使用全表扫描,除非取出数据的比较多,超过总量的5% -- 10%,或你想使用并行查询功能时。
使用全表扫描的例子:
~~~~~~~~~~~~~~~~~~~~~~~~
SQL> explain plan for select * from dual;
|
2) 通过ROWID的表存取(Table Access by ROWID或rowid lookup)
行的ROWID指出了该行所在的数据文件、数据块以及行在该块中的位置,所以通过ROWID来存取数据可以快速定位到目标数据上,是Oracle存取单行数据的最快方法。
这种存取方法不会用到多块读操作,一次I/O只能读取一个数据块。我们会经常在执行计划中看到该存取方法,如通过索引查询数据。
使用ROWID存取的方法:
SQL> explain plan for select * from dept where rowid = 'AAAAyGAADAAAAATAAF'; |
3)索引扫描(Index Scan或index lookup)
我们先通过index查找到数据对应的rowid值(对于非唯一索引可能返回多个rowid值),然后根据rowid直接从表中得到具体的数据,这种查找方式称为索引扫描或索引查找(index lookup)。一个rowid唯一的表示一行数据,该行对应的数据块是通过一次i/o得到的,在此情况下该次i/o只会读取一个数据库块。
在索引中,除了存储每个索引的值外,索引还存储具有此值的行对应的ROWID值。索引扫描可以由2步组成:(1) 扫描索引得到对应的rowid值。 (2) 通过找到的rowid从表中读出具体的数据。每步都是单独的一次I/O,但是对于索引,由于经常使用,绝大多数都已经CACHE到内存中,所以第1步的I/O经常是逻辑I/O,即数据可以从内存中得到。但是对于第2步来说,如果表比较大,则其数据不可能全在内存中,所以其I/O很有可能是物理I/O,这是一个机械操作,相对逻辑I/O来说,是极其费时间的。所以如果多大表进行索引扫描,取出的数据如果大于总量的5% -- 10%,使用索引扫描会效率下降很多。如下列所示:
|
SQL> explain plan for select empno, ename from emp where empno=10; |
但是如果查询的数据能全在索引中找到,就可以避免进行第2步操作,避免了不必要的I/O,此时即使通过索引扫描取出的数据比较多,效率还是很高的
|
进一步讲,如果sql语句中对索引列进行排序,因为索引已经预先排序好了,所以在执行计划中不需要再对索引列进行排序
|
SQL> explain plan for select empno, ename from emp |
从这个例子中可以看到:因为索引是已经排序了的,所以将按照索引的顺序查询出符合条件的行,因此避免了进一步排序操作。
根据索引的类型与where限制条件的不同,有4种类型的索引扫描:
索引唯一扫描(index unique scan)
索引范围扫描(index range scan)
索引全扫描(index full scan)
索引快速扫描(index fast full scan)
(1) 索引唯一扫描(index unique scan)
通过唯一索引查找一个数值经常返回单个ROWID。如果存在UNIQUE 或PRIMARY KEY 约束(它保证了语句只存取单行)的话,Oracle经常实现唯一性扫描。
使用唯一性约束的例子:
SQL> explain plan for
select empno,ename from emp where empno=10;
Query Plan
------------------------------------
SELECT STATEMENT [CHOOSE] Cost=1
TABLE ACCESS BY ROWID EMP [ANALYZED]
INDEX UNIQUE SCAN EMP_I1
(2) 索引范围扫描(index range scan)
使用一个索引存取多行数据,在唯一索引上使用索引范围扫描的典型情况下是在谓词(where限制条件)中使用了范围操作符(如>、<、<>、>=、<=、between)
使用索引范围扫描的例子:
|
在非唯一索引上,谓词col = 5可能返回多行数据,所以在非唯一索引上都使用索引范围扫描。
使用index rang scan的3种情况:
(a) 在唯一索引列上使用了range操作符(> < <> >= <= between)
(b) 在组合索引上,只使用部分列进行查询,导致查询出多行
(c) 对非唯一索引列上进行的任何查询。
(3) 索引全扫描(index full scan)
与全表扫描对应,也有相应的全索引扫描。而且此时查询出的数据都必须从索引中可以直接得到。
全索引扫描的例子:
e.g. SQL> explain plan for select empno, ename from big_emp order by empno,ename; |
(4) 索引快速扫描(index fast full scan)
扫描索引中的所有的数据块,与 index full scan很类似,但是一个显著的区别就是它不对查询出的数据进行排序,即数据不是以排序顺序被返回。在这种存取方法中,可以使用多块读功能,也可以使用并行读入,以便获得最大吞吐量与缩短执行时间。
索引快速扫描的例子:
BE_IX索引是一个多列索引:
big_emp (empno,ename)
SQL> explain plan for select empno,ename from big_emp; |
只选择多列索引的第2列:
|
三.表之间的连接
Join是一种试图将两个表结合在一起的谓词,一次只能连接2个表,表连接也可以被称为表关联。在后面的叙述中,我们将会使用”row source”来代替”表”,因为使用row source更严谨一些,并且将参与连接的2个row source分别称为row source1和row source 2。Join过程的各个步骤经常是串行操作,即使相关的row source可以被并行访问,即可以并行的读取做join连接的两个row source的数据,但是在将表中符合限制条件的数据读入到内存形成row source后,join的其它步骤一般是串行的。有多种方法可以将2个表连接起来,当然每种方法都有自己的优缺点,每种连接类型只有在特定的条件下才会发挥出其最大优势。
row source(表)之间的连接顺序对于查询的效率有非常大的影响。通过首先存取特定的表,即将该表作为驱动表,这样可以先应用某些限制条件,从而得到一个较小的row source,使连接的效率较高,这也就是我们常说的要先执行限制条件的原因。一般是在将表读入内存时,应用where子句中对该表的限制条件。
根据2个row source的连接条件的中操作符的不同,可以将连接分为等值连接(如WHERE A.COL3 = B.COL4)、非等值连接(WHERE A.COL3 > B.COL4)、外连接(WHERE A.COL3 = B.COL4(+))。上面的各个连接的连接原理都基本一样,所以为了简单期间,下面以等值连接为例进行介绍。
在后面的介绍中,都已:
SELECT A.COL1, B.COL2
FROM A, B
WHERE A.COL3 = B.COL4;
为例进行说明,假设A表为Row Soruce1,则其对应的连接操作关联列为COL 3;B表为Row Soruce2,则其对应的连接操作关联列为COL 4;
连接类型:
目前为止,无论连接操作符如何,典型的连接类型共有3种:
排序 - - 合并连接(Sort Merge Join (SMJ) )
嵌套循环(Nested Loops (NL) )
哈希连接(Hash Join)
排序 - - 合并连接(Sort Merge Join, SMJ)
内部连接过程:
1) 首先生成row source1需要的数据,然后对这些数据按照连接操作关联列(如A.col3)进行排序。
2) 随后生成row source2需要的数据,然后对这些数据按照与sort source1对应的连接操作关联列(如B.col4)进行排序。
3) 最后两边已排序的行被放在一起执行合并操作,即将2个row source按照连接条件连接起来
下面是连接步骤的图形表示:
MERGE
/\
SORTSORT
||
Row Source 1Row Source 2
如果row source已经在连接关联列上被排序,则该连接操作就不需要再进行sort操作,这样可以大大提高这种连接操作的连接速度,因为排序是个极其费资源的操作,特别是对于较大的表。预先排序的row source包括已经被索引的列(如a.col3或b.col4上有索引)或row source已经在前面的步骤中被排序了。尽管合并两个row source的过程是串行的,但是可以并行访问这两个row source(如并行读入数据,并行排序).
SMJ连接的例子:
|
SQL> explain plan for Query Plan |
排序是一个费时、费资源的操作,特别对于大表。基于这个原因,SMJ经常不是一个特别有效的连接方法,但是如果2个row source都已经预先排序,则这种连接方法的效率也是蛮高的。
嵌套循环(Nested Loops, NL)
这个连接方法有驱动表(外部表)的概念。其实,该连接过程就是一个2层嵌套循环,所以外层循环的次数越少越好,这也就是我们为什么将小表或返回较小row source的表作为驱动表(用于外层循环)的理论依据。但是这个理论只是一般指导原则,因为遵循这个理论并不能总保证使语句产生的I/O次数最少。有时不遵守这个理论依据,反而会获得更好的效率。如果使用这种方法,决定使用哪个表作为驱动表很重要。有时如果驱动表选择不正确,将会导致语句的性能很差、很差。
内部连接过程:
Row source1的Row 1 ---------------- Probe ->Row source 2
Row source1的Row 2 ---------------- Probe ->Row source 2
Row source1的Row 3 ---------------- Probe ->Row source 2
…….
Row source1的Row n ---------------- Probe ->Row source 2
从内部连接过程来看,需要用row source1中的每一行,去匹配row source2中的所有行,所以此时保持row source1尽可能的小与高效的访问row source2(一般通过索引实现)是影响这个连接效率的关键问题。这只是理论指导原则,目的是使整个连接操作产生最少的物理I/O次数,而且如果遵守这个原则,一般也会使总的物理I/O数最少。但是如果不遵从这个指导原则,反而能用更少的物理I/O实现连接操作,那尽管违反指导原则吧!因为最少的物理I/O次数才是我们应该遵从的真正的指导原则,在后面的具体案例分析中就给出这样的例子。
在上面的连接过程中,我们称Row source1为驱动表或外部表。Row Source2被称为被探查表或内部表。
在NESTED LOOPS连接中,Oracle读取row source1中的每一行,然后在row sourc2中检查是否有匹配的行,所有被匹配的行都被放到结果集中,然后处理row source1中的下一行。这个过程一直继续,直到row source1中的所有行都被处理。这是从连接操作中可以得到第一个匹配行的最快的方法之一,这种类型的连接可以用在需要快速响应的语句中,以响应速度为主要目标。
如果driving row source(外部表)比较小,并且在inner row source(内部表)上有唯一索引,或有高选择性非唯一索引时,使用这种方法可以得到较好的效率。NESTED LOOPS有其它连接方法没有的的一个优点是:可以先返回已经连接的行,而不必等待所有的连接操作处理完才返回数据,这可以实现快速的响应时间。
如果不使用并行操作,最好的驱动表是那些应用了where 限制条件后,可以返回较少行数据的的表,所以大表也可能称为驱动表,关键看限制条件。对于并行查询,我们经常选择大表作为驱动表,因为大表可以充分利用并行功能。当然,有时对查询使用并行操作并不一定会比查询不使用并行操作效率高,因为最后可能每个表只有很少的行符合限制条件,而且还要看你的硬件配置是否可以支持并行(如是否有多个CPU,多个硬盘控制器),所以要具体问题具体对待。
NL连接的例子:
Query Plan |
哈希连接(Hash Join, HJ)
这种连接是在oracle 7.3以后引入的,从理论上来说比NL与SMJ更高效,而且只用在CBO优化器中。
较小的row source被用来构建hash table与bitmap,第2个row source被用来被hansed,并与第一个row source生成的hash table进行匹配,以便进行进一步的连接。Bitmap被用来作为一种比较快的查找方法,来检查在hash table中是否有匹配的行。特别的,当hash table比较大而不能全部容纳在内存中时,这种查找方法更为有用。这种连接方法也有NL连接中所谓的驱动表的概念,被构建为hash table与bitmap的表为驱动表,当被构建的hash table与bitmap能被容纳在内存中时,这种连接方式的效率极高。
HASH连接的例子:
Query Plan |
要使哈希连接有效,需要设置HASH_JOIN_ENABLED=TRUE,缺省情况下该参数为TRUE,另外,不要忘了还要设置hash_area_size参数,以使哈希连接高效运行,因为哈希连接会在该参数指定大小的内存中运行,过小的参数会使哈希连接的性能比其他连接方式还要低。
总结一下,在哪种情况下用哪种连接方法比较好:
排序 - - 合并连接(Sort Merge Join, SMJ):
a) 对于非等值连接,这种连接方式的效率是比较高的。
b) 如果在关联的列上都有索引,效果更好。
c) 对于将2个较大的row source做连接,该连接方法比NL连接要好一些。
d) 但是如果sort merge返回的row source过大,则又会导致使用过多的rowid在表中查询数据时,数据库性能下降,因为过多的I/O。
嵌套循环(Nested Loops, NL):
a) 如果driving row source(外部表)比较小,并且在inner row source(内部表)上有唯一索引,或有高选择性非唯一索引时,使用这种方法可以得到较好的效率。
b) NESTED LOOPS有其它连接方法没有的的一个优点是:可以先返回已经连接的行,而不必等待所有的连接操作处理完才返回数据,这可以实现快速的响应时间。
哈希连接(Hash Join, HJ):
a) 这种方法是在oracle7后来引入的,使用了比较先进的连接理论,一般来说,其效率应该好于其它2种连接,但是这种连接只能用在CBO优化器中,而且需要设置合适的hash_area_size参数,才能取得较好的性能。
b) 在2个较大的row source之间连接时会取得相对较好的效率,在一个row source较小时则能取得更好的效率。
c) 只能用于等值连接中
笛卡儿乘积(Cartesian Product)
当两个row source做连接,但是它们之间没有关联条件时,就会在两个row source中做笛卡儿乘积,这通常由编写代码疏漏造成(即程序员忘了写关联条件)。笛卡尔乘积是一个表的每一行依次与另一个表中的所有行匹配。在特殊情况下我们可以使用笛卡儿乘积,如在星形连接中,除此之外,我们要尽量使用笛卡儿乘积,否则,自己想结果是什么吧!
注意在下面的语句中,在2个表之间没有连接。
Query Plan |
CARTESIAN关键字指出了在2个表之间做笛卡尔乘积。假如表emp有n行,dept表有m行,笛卡尔乘积的结果就是得到n * m行结果。



相关推荐
"Oracle 执行计划详解" Oracle 执行计划是数据库性能优化的关键。为了更好地理解和优化 Oracle 数据库的执行计划,我们需要了解执行计划的生成过程、优化方法和执行计划的解读方法。 执行计划生成过程 执行计划的...
Oracle执行计划参数解释,Oracle SQL优化的基础是看懂Oracle的执行计划,本文当系统整理了Oracle执行计划里面的各种参数。
Oracle 执行计划解读 Oracle 执行计划是一种查询执行路径的表示形式,它展示了 Oracle 数据库在执行查询时访问数据的路径。下面是 Oracle 执行计划的详细解读,包括执行计划的定义、访问数据的方式、执行计划层次...
### Oracle执行计划分析 #### 一、概述 在Oracle数据库管理中,优化SQL查询性能是一项至关重要的任务。其中,理解并分析SQL执行计划是提升查询效率的关键步骤之一。执行计划是指Oracle数据库根据特定的SQL语句所...
Oracle执行计划是数据库管理系统在处理SQL语句时的预估工作流程,它是Oracle优化器根据当前数据分布、索引情况和系统资源等信息选择的最佳执行策略。了解和分析执行计划对于提升SQL语句的性能至关重要。 一、生成...
Oracle 执行计划是数据库管理系统在处理SQL查询时制定的一系列步骤,用于高效地检索和处理数据。它是Oracle数据库优化器(Optimizer)根据统计信息、成本估算和已存在的索引等信息生成的。优化器有两种主要的工作...
### Oracle执行计划深入解析 #### 引言 在数据库领域,尤其对于大型企业级应用,Oracle数据库因其强大的功能和稳定性而被广泛采用。在Oracle中,执行计划是数据库优化器根据SQL语句特性生成的一系列步骤,用于指导...
Oracle 执行计划详解是数据库管理系统中一个非常重要的概念。本文将详细介绍 Oracle 执行计划的相关概念、访问数据的存取方法、表之间的连接等内容,并对总结和概述,以便于理解和记忆。 一、相关的概念 1. Rowid ...
除了以上概念,Oracle执行计划还包括其他访问方法,如索引扫描(Index Scan)、索引唯一扫描(Index Unique Scan)、索引快速全扫描(Index Fast Full Scan)以及各种类型的连接操作,如嵌套循环(Nested Loop)、...
ORACLE 执行计划和 SQL 调优 ORACLE 执行计划和 SQL 调优是关系数据库管理系统中非常重要的概念。执行计划是 Oracle 优化器生成的,用于描述如何访问数据库中的数据的计划。execute plan 中包括了访问路径、表扫描...
Oracle执行计划详解,包括oracle执行顺序和索引详细介绍
《Oracle执行计划与SQL优化实例》这一主题深入探讨了数据库管理与优化的关键方面,尤其针对Oracle数据库环境。本文旨在解析并扩展此PPTX文件中提及的重要知识点,涵盖执行计划的概念、获取方法、解读技巧以及SQL优化...
ORACLE执行计划和SQL调优
oracle执行计划详细解释
Oracle 执行计划 Oracle 执行计划是 Oracle 数据库中的一种机制,用于确定如何访问存储器,得到需要的结果集。执行计划的主要内容包括访问方式和访问顺序。下面是 Oracle 执行计划的详细知识点: 一、执行计划的...
总之,Oracle执行计划的稳定性与数据库性能紧密相关,理解并掌握优化器的工作原理以及如何控制执行计划的选择,是优化数据库性能的关键。在基于代价的优化器模式下,虽然存在执行计划不稳定的可能,但通过合理管理和...
总之,Oracle执行计划的稳定性对于数据库的高效运行具有重要意义。通过合理管理统计信息、选择合适的优化器模式、利用SQL提示和监控工具,可以有效控制执行计划的稳定性,从而提升数据库的整体性能。
"Oracle 执行计划" Oracle 执行计划是 Oracle 数据库中的一种机制,用于优化 SQL 语句的执行过程。它决定了如何访问存储器,得到需要的结果集。执行计划的主要内容包括访问方式和访问顺序。 Oracle 执行计划的生成...