
آ آ آ آ وœ€è؟‘看هˆ°Udi Dahanهچڑه®¢é‡Œه…³ن؛ژCQRSçڑ„ن¸€ç¯‡و–‡ç« (clarified-cqrs),و„ں觉éکگè؟°çڑ„ه¾ˆè¯¦ç»†م€‚è‡ھه·±èٹ±ن؛†ن¸‰ن¸ھو™ڑن¸ٹوٹٹه®ƒç؟»è¯‘ن؛†ن¸€éپچ,و„ں觉و”¶èژ·é¢‡ه¤ڑم€‚هœ¨ن؛‰ه¾—ن½œè€…هگŒو„ڈهگژ,وˆ‘ه°†ه…¶هڈ‘ه¸ƒه‡؛و¥ï¼Œن¾›ه¤§ه®¶ن¸€èµ·ن؛¤وµپم€‚
آ آ آ آ هژںو–‡هœ°ه€ï¼ڑhttp://www.udidahan.com/2009/12/09/clarified-cqrs/
==========================================================
آ
هœ¨çœ‹هˆ°ç¤¾هŒ؛ن¸çڑ„ن؛؛ه¯¹CQRSو¨،ه¼ڈ(Command-Query Responsibility Segregation)çڑ„解读هگژ,وˆ‘认ن¸؛وک¯و—¶ه€™هپڑه‡؛ن¸€ن؛›و¾„و¸…ن؛†م€‚ن¸€ن؛›ن؛؛وٹٹCQRSه’Œن؛‹ن»¶و؛¯و؛گ绑هœ¨ن¸€èµ·و¥çœ‹ه¾…م€‚و›´ه¤ڑçڑ„ن؛؛用è؟™ن¸ھو¨،ه¼ڈو¥è¦†ç›–وژ‰هژںه…ˆهˆ†ه±‚و¶و„çڑ„设è®،م€‚ن¸‹é¢وˆ‘وƒ³èƒ½ه¯¹CQRSو¨،ه¼ڈوœ¬è؛«هپڑن¸€ن؛›éکگè؟°ï¼Œه¹¶ن¸”说وکژهœ¨ن½•ç§چهœ؛و™¯ن¸‹ه®ƒهڈ¯ن»¥ن¸ژه…¶ن»–و¨،ه¼ڈè؟›è،Œه¯¹وژ¥م€‚
آ
ن¸؛ن»€ن¹ˆè¦پوœ‰CQRSï¼ں
هœ¨è®¨è®؛CQRSو¨،ه¼ڈçڑ„细èٹ‚ن¹‹ه‰چ,وˆ‘ن»¬é¦–ه…ˆéœ€è¦پçگ†è§£è؟™ن¸ھو¨،ه¼ڈن؛§ç”ں背هگژçڑ„ن¸¤è‚،وژ¨هٹ¨هٹ›ï¼ڑهچڈهگŒو“چن½œه’Œو•°وچ®è؟‡و—¶م€‚
هچڈهگŒو“چن½œوŒ‡çڑ„وک¯ï¼Œهœ¨وںگç§چهœ؛و™¯ن¸‹ه¤ڑن¸ھ用وˆ·هڈ¯èƒ½ن¼ڑé’ˆه¯¹هگŒن¸€ن¸ھو•°وچ®é›†è؟›è،Œè¯»ه†™و“چن½œâ€”—ن¸چè®؛ن¸»è§‚ن¸ٹè؟™ن؛›ç”¨وˆ·وک¯هگ¦çœںçڑ„وœںوœ›ن¸ژه…¶ن»–ن؛؛è؟›è،ŒهچڈهگŒم€‚é€ڑه¸¸وƒ…ه†µن¸‹ن¼ڑوœ‰ن¸€ن؛›è§„هˆ™و¥è§„ه®ڑه“ھن؛›ç”¨وˆ·هڈ¯ن»¥è؟›è،Œه“ھن؛›و“چن½œن»¥هڈٹن¸€ن¸ھو“چن½œهœ¨ن½•ç§چهœ؛و™¯ن¸‹وک¯ه…پ许çڑ„而هœ¨ه…¶ن»–هœ؛و™¯ن¸ه°±ن¸چ被ه…پ许م€‚وˆ‘ن»¬ن¼ڑ简هچ•çڑ„ن¸¾ن¸€ن؛›ن¾‹هگو¥è¯´وکژم€‚و³¨و„ڈ,è؟™é‡Œçڑ„用وˆ·هڈ¯ن»¥وک¯è‡ھ然ن؛؛,ن¹ںهڈ¯ن»¥وک¯è‡ھهٹ¨هŒ–çڑ„软ن»¶م€‚
و•°وچ®è؟‡و—¶وŒ‡çڑ„وک¯ï¼Œهœ¨هچڈهگŒو“چن½œçڑ„هœ؛و™¯ن¸‹ï¼Œن¸€ن¸ھو•°وچ®è¢«ه±•ç¤؛ç»™وںگن¸ھ用وˆ·هگژ,ه®ƒهڈ¯èƒ½ه°±è¢«ه…¶ن»–用وˆ·ن؟®و”¹ن؛†â€”—هˆڑهˆڑه±•ç¤؛çڑ„و•°وچ®ه°±è؟‡و—¶ن؛†م€‚هں؛وœ¬ن¸ٹو‰€وœ‰ن½؟用ن؛†ç¼“هکçڑ„ç³»ç»ں都éپ‡هˆ°ن؛†و•°وچ®è؟‡و—¶çڑ„é—®é¢ک——é€ڑه¸¸وƒ…ه†µن¸‹ç”¨ç¼“هکوک¯ن¸؛ن؛†è§£ه†³ç³»ç»ںçڑ„و€§èƒ½é—®é¢کم€‚è؟™è¯´وکژوˆ‘ن»¬ن¸چ能ه®Œه…¨ç›¸ن؟،用وˆ·هپڑه‡؛çڑ„ه†³ه®ڑ,ه› ن¸؛è؟™ن؛›ه†³ه®ڑهڈ¯èƒ½وک¯هں؛ن؛ژه·²ç»ڈè؟‡و—¶çڑ„و•°وچ®هپڑه‡؛و¥çڑ„م€‚
و ‡ه‡†çڑ„هˆ†ه±‚و¶و„ه¹¶وœھه¯¹ن¸ٹé¢çڑ„é—®é¢کوڈگه‡؛وکژç،®çڑ„و–¹و،ˆم€‚ن¼ ç»ںهˆ†ه±‚و¶و„ن¸ï¼Œé€ڑه¸¸é€ڑè؟‡ه°†و‰€وœ‰و•°وچ®و”¾ه…¥ç»ںن¸€çڑ„و•°وچ®ه؛“ن¸ï¼Œن»¥و¤ن½œن¸؛ن¸€ç§چ解ه†³هچڈهگŒو“چن½œçڑ„و€è·¯م€‚ن½†و¤و—¶ن¸؛解ه†³و€§èƒ½è€Œه¼•è؟›çڑ„缓هک,هچ´ن½؟و•°وچ®è؟‡و—¶وˆگن؛†ن¸ھه‰¯ن½œç”¨ï¼Œè€Œن¸”و„ˆو¼”و„ˆçƒˆم€‚
آ
هڈ‚考ه›¾
وˆ‘ه·²ç»ڈه’Œن¸€ن؛›ن؛؛讨è®؛è؟‡CQRS,ه¹¶ن½؟用ن¸‹é¢çڑ„ه›¾و¥è§£é‡ٹï¼ڑ
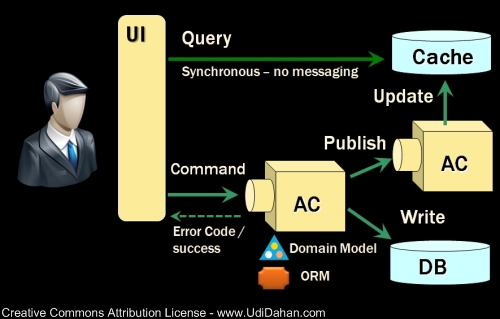
هگچن¸؛ACçڑ„ç›’هگوŒ‡çڑ„وک¯è‡ھو²»ç»„ن»¶م€‚هœ¨è®¨è®؛ه‘½ن»¤ï¼ˆCommands)çڑ„و—¶ه€™وˆ‘ن»¬ن¼ڑوڈڈè؟°ه®ƒوک¯ه¦‚ن½•è‡ھو²»çڑ„م€‚ن½†هœ¨و¤ن¹‹ه‰چ,وˆ‘ن»¬ه…ˆو¥çœ‹ن¸‹وں¥è¯¢ï¼ˆQueries)م€‚
آ
وں¥è¯¢
ه¦‚وœوˆ‘ن»¬ه°†è¦په±•ç¤؛给用وˆ·çڑ„و•°وچ®وک¯è؟‡و—¶çڑ„,那ن¹ˆوک¯هگ¦çœںçڑ„وœ‰ه؟…è¦پé‡چو–°ن»ژو•°وچ®ه؛“ن¸هژ»è¯»هڈ–ن¸€éپچï¼ںوˆ‘ن»¬ن»…ن»…需è¦پو•°وچ®ï¼ˆو²،وœ‰ن»»ن½•è،Œن¸؛ç؛¦وں规هˆ™ï¼‰ï¼Œن¸؛ن»€ن¹ˆéè¦په°†ç¬¬ن¸‰èŒƒه¼ڈçڑ„و•°وچ®è½¬وچ¢وˆگ领هںںه¯¹è±،ï¼ںهڈˆن¸؛ن»€ن¹ˆè¦په°†é¢†هںںه¯¹è±،转وچ¢وˆگDTOو¥é€ڑè؟‡ç½‘络è؟›è،Œن¼ 输ï¼ںè¦پçں¥éپ“网络ه¹¶ن¸چو€»وک¯هڈ¯é çڑ„م€‚وˆ‘ن»¬هڈˆن¸؛ن»€ن¹ˆè¦په†چوٹٹDTO转وچ¢وˆگ视ه›¾و¨،ه‹ه¯¹è±،ï¼ں
简而言ن¹‹ï¼Œوˆ‘ن»¬هœ¨هں؛ن؛ژن¸€ن¸ھهپ‡è®¾ï¼ڑé‡چ用ه·²وœ‰çڑ„ن»£ç پن¼ڑو¯”ن¸؛解ه†³و‰‹ه¤´çڑ„è؟™ن¸ھé—®é¢کو–°ه†™ç‚¹ن»£ç پو›´ç®€هچ•م€‚而هں؛ن؛ژو¤هپ‡è®¾ï¼Œوˆ‘ن»¬هپڑن؛†ه¾ˆه¤ڑو— 用çڑ„ه·¥ن½œم€‚وˆ‘ن»¬ن¸چه¦¨وچ¢ن¸ھو€è·¯ï¼ڑ
وˆ‘ن»¬ن¸؛ن»€ن¹ˆن¸چو–°هˆ›ه»؛ن¸€ن¸ھو•°وچ®ه®¹ه™¨ï¼Œه¹¶ه…پ许è؟™ن¸ھو•°وچ®ه®¹ه™¨ن¸çڑ„و•°وچ®ه’Œو•°وچ®ه؛“ن¸وœ‰ç‚¹ن¸چهگŒو¥â€”—وˆ‘çڑ„و„ڈو€وک¯ï¼Œو—¢ç„¶وˆ‘ن»¬ه±•ç¤؛给用وˆ·çڑ„و•°وچ®و€»وک¯è¦پè؟‡و—¶çڑ„,那ن¸؛ن»€ن¹ˆن¸چç›´وژ¥هœ¨و•°وچ®ه®¹ه™¨ن¸هڈچوک ه‡؛و¥è؟™ن¸ھهڈکهŒ–ï¼ںهگژé¢وˆ‘ن»¬ن¼ڑç»™ه‡؛ن¸€ن¸ھن؟وŒپè؟™ن¸ھو•°وچ®ه®¹ه™¨ن¸ژو•°وچ®ه؛“هگŒو¥çڑ„و–¹و،ˆم€‚
çژ°هœ¨çڑ„é—®é¢کوک¯ï¼Œè؟™ن¸ھو•°وچ®ه®¹ه™¨ن¸و•°وچ®çڑ„و£ç،®ç»“و„ه؛”该وک¯ه•¥و ·çڑ„ï¼ںç›´وژ¥ه’Œè§†ه›¾ه¯¹è±،çڑ„结و„ن¸€و ·و€ژن¹ˆو ·ï¼ںهپ‡è®¾و¯ڈن¸ھ视ه›¾وœ‰ن¸€ن¸ھه¯¹ه؛”结و„çڑ„و•°وچ®ه®¹ه™¨ï¼Œé‚£ن¹ˆه®¢وˆ·ç«¯هœ¨ه±•çژ°و•°وچ®çڑ„و—¶ه€™ه°±هڈ¯ن»¥ç®€هچ•çڑ„é€ڑè؟‡Select * from MyViewTableè؟™ç§چو–¹ه¼ڈ(وˆ–者هœ¨whereè¯هڈ¥ن¸هٹ ن¸ھID)و¥ه®Œوˆگم€‚ه¦‚وœوœ‰éœ€è¦پ,ن½ هڈ¯ن»¥é€ڑè؟‡ن¸€ن¸ھه¾ˆè–„çڑ„faأ§adeو¥هŒ…装وں¥è¯¢çڑ„è؟‡ç¨‹ï¼Œوˆ–者用ن¸ھهکه‚¨è؟‡ç¨‹ï¼Œوٹ‘وˆ–وک¯ç”¨ن¸ھè‡ھهٹ¨وک ه°„ه¯¹è±،ه°†و•°وچ®وک ه°„هˆ°è§†ه›¾و¨،ه‹ه¯¹è±،ن¸م€‚è؟™و ·هپڑçڑ„ه…³é”®ï¼Œوک¯è§†ه›¾و¨،ه‹ه¯¹è±،وک¯ç½‘络هڈ‹ه¥½çڑ„(wire-friendly),ه› و¤ن½ ن¸چه†چ需è¦په°†ن»–转وچ¢وˆگه…¶ن»–çڑ„ن¸œè¥؟م€‚
ن½ ç”ڑ至هڈ¯ن»¥è€ƒè™‘ه°†è؟™ن¸ھو•°وچ®ه®¹ه™¨و”¾هœ¨webه±‚م€‚è؟™ه°±هƒڈwebه±‚çڑ„缓هکن¸€و ·ه®‰ه…¨م€‚然هگژهڈھه…پ许webوœچهٹ،ه™¨è؟›è،ŒSELECTو“چن½œï¼Œè؟™و ·ه°±okن؛†م€‚
آ
وں¥è¯¢çڑ„و•°وچ®ه®¹ه™¨
ن½ هڈ¯ن»¥ن½؟用ن¼ ç»ںçڑ„و•°وچ®ه؛“ن½œن¸؛وں¥è¯¢çڑ„و•°وچ®ه®¹ه™¨ï¼Œن½†è؟™ن¸چوک¯ه”¯ن¸€çڑ„选و‹©م€‚考虑ن¸‹è؟™ن¸ھé—®é¢ک,ه®é™…ن¸ٹوں¥è¯¢çڑ„schemaه’Œن½ çڑ„视ه›¾و¨،ه‹ه¯¹è±،çڑ„结و„وک¯ن¸€و ·çڑ„م€‚而هœ¨ن¸چهگŒçڑ„و¨،ه‹è§†ه›¾ه¯¹è±،ن¹‹é—´é€ڑه¸¸ن¹ںو²،وœ‰ن»»ن½•çڑ„èپ”系,و‰€ن»¥هœ¨ن¸چهگŒçڑ„وں¥è¯¢و•°وچ®ه®¹ه™¨ن¹‹é—´ن¹ںن¸چ需è¦پن»»ن½•çڑ„ه…³èپ”م€‚
é‚£ن¹ˆï¼Œن½ çœںçڑ„وƒ³è¦پن¼ ç»ںçڑ„و•°وچ®ه؛“ن¹ˆï¼ں
ç”و،ˆوک¯هگ¦ه®ڑçڑ„م€‚ن½†هœ¨ه®é™…è؟‡ç¨‹ن¸ه‡؛ن؛ژ组织وƒ¯و€§ï¼Œè؟™هچ´ه¾€ه¾€هڈˆوک¯وœ€ه¥½çڑ„选و‹©م€‚
آ
هˆ†ه‰²وں¥è¯¢
هڈچو£çژ°هœ¨وں¥è¯¢وک¯é€ڑè؟‡ن¸€ن¸ھ独立çڑ„و•°وچ®ه®¹ه™¨è€Œéو•°وچ®ه؛“,هگŒو—¶ن¹ںه¹¶و²،وœ‰هپ‡è®¾و•°وچ®ه®¹ه™¨ن¸çڑ„و•°وچ®ه؟…é،»100%ه’Œو•°وچ®ه؛“ن¸€è‡´çڑ„,那ن¹ˆن½ ه°±هڈ¯ن»¥è½»و¾çڑ„و·»هٹ و›´ه¤ڑçڑ„و•°وچ®ه®¹ه™¨ه®ن¾‹ن¸”ن¸چه؟…ن¸؛ن»–ن»¬çڑ„و•°وچ®ن¸€è‡´و€§و‹…ه؟§م€‚é’ˆه¯¹ن¸€ن¸ھو•°وچ®ه®¹ه™¨è؟›è،Œو›´و–°çڑ„وœ؛هˆ¶هگŒو ·هڈ¯ن»¥è¢«ç”¨هˆ°ه…¶ن»–çڑ„و•°وچ®ه®¹ه™¨ن¸ٹ,وˆ‘ن»¬ç¨چهگژن¼ڑ看هˆ°è؟™ن¸ھم€‚
è؟™و ·ï¼Œوˆ‘ن»¬ه°±هڈ¯ن»¥éه¸¸ن¾؟وچ·çڑ„و°´ه¹³هˆ‡ه‰²وˆ‘ن»¬çڑ„وں¥è¯¢ن؛†م€‚هگŒو—¶ï¼Œه› ن¸؛هœ¨وں¥è¯¢و—¶و²،وœ‰هپڑè؟‡ه¤ڑçڑ„و— 用çڑ„و•°وچ®è½¬وچ¢ï¼Œهچ•و¬،وں¥è¯¢çڑ„é€ںه؛¦ن¹ںوڈگهچ‡ن¸ٹو¥ن؛†م€‚简هچ•çڑ„ه°±وک¯ه؟«çڑ„م€‚
آ
و•°وچ®ن؟®و”¹
ه› ن¸؛وˆ‘ن»¬çڑ„用وˆ·وک¯هں؛ن؛ژè؟‡و—¶çڑ„و•°وچ®هپڑه‡؛ه†³ç–çڑ„,و‰€ن»¥وˆ‘ن»¬و›´هٹ 需è¦پوکژç،®ه“ھن؛›و“چن½œوک¯هڈ¯ن»¥é€ڑè؟‡çڑ„而ه“ھن؛›ن¸چè،Œم€‚ن¸‹é¢وœ‰ن¸ھ简هچ•çڑ„ن¾‹هگï¼ڑ
هپ‡è®¾وœ‰ن¸€ن¸ھو£هœ¨ه’Œه®¢وˆ·é€ڑ电è¯çڑ„ه®¢وˆ·وœچهٹ،ن»£çگ†ن؛؛م€‚è؟™ن½چè€په…„و£ç›¯ç€ç”µè„‘ه±ڈه¹•ن¸ٹçڑ„ه®¢وˆ·çڑ„ن؟،وپ¯çœ‹ï¼ŒهگŒو—¶ن؟®و”¹ه®¢وˆ·çڑ„ن½ڈه€ï¼Œن؟®و”¹ç§°ه‘¼ن¸؛ه…ˆç”ں/ه°ڈه§گ,ن؟®و”¹ن»–çڑ„ه§“و°ڈه¹¶è،¨وکژن»–çڑ„ه©ڑه§»çٹ¶ه†µن¸؛ه·²ه©ڑ,ه¹¶ه°†è؟™ن¸ھه®¢وˆ·è®¾ç½®ن¸؛“ن¼کè´¨çڑ„â€ه®¢وˆ·م€‚然而è؟™ن½چè€په…„ن¸چçں¥éپ“çڑ„وک¯ï¼Œهœ¨ن»–و‰“ه¼€ç½‘é،µهگژ,ن¸€ن¸ھ订هچ•éƒ¨é—¨هڈ‘ه‡؛çڑ„ن؟،وپ¯وک¾ç¤؛è؟™ن¸ھه®¢وˆ·ه¹¶و²،وœ‰هڈٹو—¶و”¯ن»کو‹–و¬ çڑ„订هچ•â€”—ن»–و¬ ه€؛ن؛†م€‚وˆ‘ن»¬çڑ„ه®¢وˆ·وœچهٹ،ن»£è،¨وڈگن؛¤ن؛†ن»–çڑ„ن؟®و”¹م€‚
وˆ‘ن»¬وک¯هگ¦ه؛”该وژ¥هڈ—è؟™ن؛›ن؟®و”¹ï¼ں
说ه®è¯ï¼Œوˆ‘ن»¬ه؛”该وژ¥هڈ—ه…¶ن¸çڑ„部هˆ†ï¼Œن½†ن¸چه؛”该هŒ…و‹¬è®¾ç½®ن¸؛“ن¼کè´¨çڑ„â€ه®¢وˆ·è؟™éƒ¨هˆ†ï¼Œه› ن¸؛ن»–و¬ ه¸گن؛†م€‚ن½†وک¯è¦په®çژ°è؟™ن؛›و ،éھŒوک¯ن¸ھه¤´ç–¼çڑ„ن»»هٹ،——وˆ‘ن»¬éœ€è¦په¯¹و•°وچ®هپڑن¸€ن¸ھه·®ه¼‚و¯”较,و‰¾هˆ°ه“ھن؛›éƒ¨هˆ†è¢«ن؟®و”¹وˆ–者وک¯è؟‡و—¶ن؛†ï¼Œوگو¸…و¥ڑو”¹هڈکçڑ„هگ«ن¹‰ï¼Œه“ھن؛›و•°وچ®وک¯ç›¸ن؛’ه…³èپ”çڑ„(ن¾‹ه¦‚ه§“هگچçڑ„و”¹هڈکه’Œç§°ه‘¼çڑ„و”¹هڈک),ه“ھن؛›وک¯ç‹¬ç«‹çڑ„,然هگژç،®ه®ڑه“ھن؛›ن؟®و”¹è؟هڈچن؛†و ،éھŒè§„هˆ™â€”—ن¸چن»…è¦پو¯”较用وˆ·وڈگن؛¤çڑ„و•°وچ®ï¼Œè؟کè¦په’Œو•°وچ®ه؛“ن¸çڑ„و•°وچ®و¯”较,然هگژه†³ه®ڑé€ڑè؟‡è؟کوک¯è؟”ه›م€‚
ن¸چه¹¸çڑ„وک¯ï¼Œه¯¹ن؛ژوˆ‘ن»¬çڑ„用وˆ·ï¼Œوڈگن؛¤çڑ„و•°وچ®ه“ھو€•هڈھوœ‰ن¸€éƒ¨هˆ†و²،é€ڑè؟‡و ،éھŒن¹ںن¼ڑو•´ن½“è؟”ه›م€‚و¤و—¶ï¼Œç”¨وˆ·ن¸چه¾—ن¸چهˆ·و–°é،µé¢و¥èژ·هڈ–وœ€و–°çڑ„و•°وچ®ï¼Œç„¶هگژé‡چو–°ن؟®و”¹é‡چو–°وڈگن؛¤ï¼Œç¥ˆç¥·è؟™و¬،ن¸چè¦په†چه› ن¸؛ن¸€ن¸ھن¹گ观é”په†²çھپ而ه†چو¬،ه¤±è´¥م€‚
ه½“ه®ن½“هڈکçڑ„è¶ٹو¥è¶ٹه¤§çڑ„و—¶ه€™ï¼Œه®ƒو‰€هŒ…هگ«çڑ„ه—و®µن¹ںè¶ٹو¥è¶ٹه¤ڑم€‚و¤و—¶ن¹ںن¼ڑوœ‰è¶ٹو¥è¶ٹه¤ڑçڑ„用وˆ·هœ¨ه¯¹ه®ن½“è؟›è،ŒهچڈهگŒو“چن½œم€‚هœ¨ن»»و„ڈç»™ه®ڑçڑ„و—¶é—´ه†…,ه¯¹è¯¥ه®ن½“وںگن؛›ه—و®µو“چن½œçڑ„هڈ¯èƒ½و€§è¶ٹه¤§ï¼Œè§¦هڈ‘é”په†²çھپçڑ„هڈ¯èƒ½و€§ن¹ںه°±è¶ٹه¤§م€‚
ه¦‚وœهœ¨ن؟®و”¹و•°وچ®و—¶ï¼Œوœ‰و–¹و³•èƒ½ه¤ں让用وˆ·وڈگن¾›و“چن½œçڑ„ه‡†ç،®ç›®çڑ„ه’Œç²’ه؛¦ه°±ه¥½ن؛†م€‚而è؟™ه°±وک¯ه‘½ن»¤è§£ه†³çڑ„é—®é¢کم€‚
آ
ه‘½ن»¤
CQRSçڑ„ن¸€ن¸ھو ¸ه؟ƒه…ƒç´ ,وک¯ه¯¹ç”¨وˆ·ç•Œé¢è؟›è،Œé‡چو–°è®¾è®،,و¥è®©وˆ‘ن»¬èƒ½ه¤ںهˆ†è¾¨ه‡؛用وˆ·و“چن½œçڑ„çœںه®و„ڈه›¾ï¼Œن¾‹ه¦‚设置ن¸€ن¸ھه®¢وˆ·ن¸؛ن¼کè´¨ه®¢وˆ·وک¯ن¸چهگŒن؛ژé‡چ置用وˆ·çڑ„ن½ڈه€وˆ–者ن؟®و”¹ç”¨وˆ·çڑ„ه©ڑه§»çٹ¶و€پçڑ„و“چن½œم€‚用类ن¼¼Excelè،¨و ¼و–¹ه¼ڈçڑ„ç•Œé¢وک¯و— و³•ه‡†ç،®وچ•èژ·ç”¨وˆ·و„ڈه›¾çڑ„,ه°±ه¦‚ن¸ٹو–‡و‰€è§پم€‚
وˆ‘ن»¬ç”ڑ至هڈ¯ن»¥è€ƒè™‘هچ³ن½؟用وˆ·ن¸ٹن¸€ن¸ھه‘½ن»¤ه°ڑوœھو‰§è،Œه®Œوˆگو—¶ن¹ںه…پ许用وˆ·وڈگن؛¤ن¸‹ن¸€ن¸ھو–°ه‘½ن»¤م€‚وˆ‘ن»¬هڈ¯ن»¥ç”¨ن¸€ن¸ھه°ڈ部ن»¶و”¾هœ¨é،µé¢و—پ边,用و¥ه±•ç¤؛ه‘½ن»¤çڑ„çٹ¶و€پ,é€ڑè؟‡ه¼‚و¥çڑ„و–¹ه¼ڈèژ·هڈ–ه‘½ن»¤و‰§è،Œç»“وœم€‚ه¦‚وœه‘½ن»¤وˆگهٹںن؛†ه°±وک¾ç¤؛é€ڑè؟‡ï¼Œهگ¦هˆ™وک¾ç¤؛ه¤±è´¥ه¹¶ه‡؛çژ°ç؛¢هڈ‰هڈ‰م€‚用وˆ·é€ڑè؟‡هڈŒه‡»ه¤±è´¥çڑ„ه‘½ن»¤هڈ¯ن»¥çœ‹هˆ°é”™è¯¯ن؟،وپ¯م€‚
请و³¨و„ڈه‘½ن»¤وک¯هڈ‘é€پ而éهڈ‘ه¸ƒâ€”—è؟™وک¯وœ‰هŒ؛هˆ«çڑ„م€‚ه‘½ن»¤وک¯هڈ‘é€پçڑ„,ن؛‹ن»¶وک¯هڈ‘ه¸ƒçڑ„م€‚ه½“ن؛‹ن»¶è¢«هڈ‘ه¸ƒهگژ,هڈ‘ه¸ƒè€…هڈھوک¯ه£°وکژن؛†ن¸€ن¸ھçٹ¶و€پ,ه®ƒçڑ„ه·¥ن½œه°±و¤ç»“وںم€‚至ن؛ژوژ¥هڈ—者è¦پو‹؟ن؛‹ن»¶هپڑن»€ن¹ˆه¤„çگ†ï¼Œهڈ‘ه¸ƒè€…ه¹¶ن¸چه…³ه؟ƒم€‚
آ
ه‘½ن»¤ه’Œو ،éھŒ
هœ¨è€ƒè™‘ن»€ن¹ˆن¸œè¥؟هڈ¯èƒ½ن¼ڑ让ه‘½ن»¤و‰§è،Œه¤±è´¥و—¶ï¼Œè·³ه‡؛و¥çڑ„ن¸€ن¸ھه…ƒç´ وک¯و•°وچ®هگˆو³•و€§و ،éھŒم€‚و•°وچ®هگˆو³•و€§و ،éھŒه’Œن¸ڑهٹ،规هˆ™ن¸چهگŒï¼Œه®ƒé’ˆه¯¹ه‘½ن»¤ه£°وکژن؛†ن¸€ن؛›ن¸ٹن¸‹و–‡و— ه…³çڑ„è¦پو±‚م€‚ن¸€ن¸ھه‘½ن»¤وک¯هگˆو³•çڑ„,وٹ‘وˆ–相هڈچم€‚ن¸ژو¤ç›¸ه¯¹ï¼Œن¸ڑهٹ،规هˆ™وک¯ن¸ٹن¸‹و–‡ç›¸ه…³çڑ„م€‚
هœ¨وˆ‘ن»¬ن¸ٹé¢وڈگçڑ„ن¾‹هگن¸ï¼Œç”¨وˆ·وڈگن؛¤çڑ„و•°وچ®çڑ„و•°وچ®هگˆو³•و€§وک¯é€ڑè؟‡çڑ„,ه®ƒè¢«و‹’ç»çڑ„ه”¯ن¸€هژںه› وک¯è´¦هچ•ن؛‹ن»¶و¯”وڈگن؛¤و“چن½œو—©هˆ°è¾¾م€‚هپ‡ه¦‚è´¦هچ•ن؛‹ن»¶و²،هˆ°ï¼Œé‚£ن¹ˆو“چن½œه°±é€ڑè؟‡ن؛†م€‚
è؟™è¯´وکژهچ³ن¾؟ن¸€ن¸ھو“چن½œçڑ„هگˆو³•و€§و ،éھŒé€ڑè؟‡ن؛†ï¼Œن¹ںهڈ¯èƒ½وœ‰ه…¶ن»–هژںه› ن¼ڑو‹’ç»وژ‰م€‚
ه› و¤ï¼Œو•°وچ®هگˆو³•و€§هڈ¯ن»¥و”¾هœ¨ه®¢وˆ·ç«¯ه®Œوˆگم€‚هœ¨ه®¢وˆ·ç«¯و ،éھŒه؟…ه،«çڑ„و•°وچ®éƒ½ه،«ن؛†ï¼Œو ¼ه¼ڈوک¯ن¸چوک¯و£ç،®م€‚وœچهٹ،ه™¨ç«¯ن»چ然ن¼ڑو ،éھŒو‰€وœ‰çڑ„ه‘½ن»¤ï¼Œه¯¹ه®¢وˆ·ç«¯é‡‡ç”¨ن¸چن؟،ن»»ç–ç•¥م€‚
آ
و ¹وچ®هگˆو³•و€§و ،éھŒé‡چو–°ه®،视界é¢ه’Œه‘½ن»¤è®¾è®،
ه®¢وˆ·ç«¯هœ¨و ،éھŒه‘½ن»¤هگˆو³•و€§çڑ„و—¶ه€™ه›هژ»ن؛†è§£و•°وچ®ه®¹ه™¨é‡Œçڑ„و•°وچ®م€‚ن¸¾ن¸ھن¾‹هگ,هœ¨وڈگن؛¤ن¸€ن¸ھ用وˆ·ن½ڈه€ن؟®و”¹çڑ„ه‘½ن»¤ه‰چ,وˆ‘ن»¬è¦پو£€وں¥و•°وچ®ه®¹ه™¨ن¸وک¯هگ¦ه·²هکهœ¨è؟™ن¸ھè،—éپ“و•°وچ®م€‚
و¤و—¶ï¼Œوˆ‘ن»¬ن¼ڑ考虑ه°†هœ°ه€و ڈ设è®،وˆگن¸؛ن¸€ن¸ھè‡ھهٹ¨ه،«ه……çڑ„输ه…¥ç»„ن»¶ï¼Œن»¥و¤ن؟è¯پوˆ‘ن»¬é€ڑè؟‡ه‘½ن»¤ن¼ 输çڑ„هœ°ه€وک¯هگˆو³•çڑ„م€‚ن½†وک¯ï¼Œن¸؛ن»€ن¹ˆن¸چ能و›´è؟‘ن¸€و¥ï¼Œه¹²è„†ه°†è،—éپ“çڑ„IDن¼ è؟‡هژ»è€Œن¸چوک¯هگچ称ه—符ن¸²ه‘¢ï¼ں
هœ¨وœچهٹ،ه™¨ç«¯çœ‹ï¼Œن¹ں许ن¸چè؟™ن¹ˆهپڑçڑ„ه”¯ن¸€çگ†ç”±وک¯è؟™و ·ن¼ڑه› ن¸؛و•°وچ®è¢«ه¹¶هڈ‘و“چن½œè€Œه¯¼è‡´ه‘½ن»¤و‰§è،Œه¤±è´¥â€”—و¤و—¶ه…¶ن»–ن؛؛ه°†è؟™ن¸ھè،—éپ“و•°وچ®هˆ 除ن؛†ن½†هˆڑه¥½è؟کوœھهگŒو¥هˆ°و•°وچ®ه®¹ه™¨ن¸م€‚ه½“然è؟™ن¸ھهœ؛و™¯éه¸¸ه°‘è§پم€‚
آ
هگˆو³•çڑ„ه‘½ن»¤و‰§è،Œه¤±è´¥çڑ„هژںه› هڈٹه¤„çگ†و–¹و،ˆ
è؟™ن¸ھو—¶ه€™وˆ‘ن»¬çڑ„ه®¢وˆ·ç«¯ه·²ç»ڈ能ه¤ںن¼ 输هگˆو³•çڑ„ه‘½ن»¤ï¼Œن½†وک¯وœچهٹ،ه™¨è؟کوک¯هڈ¯èƒ½ن¼ڑو‹’ç»وژ‰ه‘½ن»¤م€‚ه‡؛çژ°è؟™ç§چهœ؛و™¯çڑ„هژںه› ,وœ€ه¸¸è§پçڑ„ه°±وک¯ه…¶ن»–ن؛؛ه¹¶è،Œçڑ„ن؟®و”¹ن؛†ه‘½ن»¤ه¤„çگ†è؟‡ç¨‹ن¸éœ€è¦پن½؟用çڑ„ه…¶ن»–و•°وچ®م€‚
هœ¨ن¸ٹé¢çڑ„CRMç³»ç»ںçڑ„ن¾‹هگ里,ه‘½ن»¤و‰§è،Œه¤±è´¥ن»…ن»…وک¯ه› ن¸؛è´¦هچ•ن؛‹ن»¶و¯”و“چن½œو—©هˆ°è¾¾ن؛†م€‚ن½†â€œو—©â€çڑ„و¦‚ه؟µç”ڑ至هڈ¯èƒ½هڈھوœ‰ه‡ و¯«ç§’م€‚هپ‡ه¦‚用وˆ·وڈگو—©ه‡ و¯«ç§’وŒ‰ن¸‹ن؛†هڈ‘é€پé”®ه‘¢ï¼ںè؟™ç‚¹ه·®è·وک¯هگ¦ه؛”该ه¯¼è‡´وœ€ç»ˆوˆھ然ن¸چهگŒçڑ„ن¸ڑهٹ،结وœï¼ںوˆ‘ن»¬éڑ¾éپ“ن¸چ该وœںوœ›وˆ‘ن»¬çڑ„ç³»ç»ںهœ¨ç”¨وˆ·çœ‹و¥ه؛”该وک¯â€œè،Œن¸؛ن¸€è‡´â€çڑ„ن¹ˆï¼ں
é‚£ن¹ˆï¼Œهپ‡ه¦‚è´¦هچ•ن؛‹ن»¶ç،®ه®و™ڑو¥ن؛†ن¸€و¥ï¼Œé‚£ن¹ˆه®ƒوک¯هگ¦ه؛”该و’¤é”€وژ‰هˆڑهˆڑ设置用وˆ·ن¸؛ن¼ک质用وˆ·çڑ„و“چن½œه‘¢ï¼ںن¸چن»…ه¦‚و¤ï¼Œوک¯هگ¦è؟که؛”该é€ڑçں¥وˆ‘ن»¬çڑ„用وˆ·ï¼Œو¯”ه¦‚هڈ‘ن¸ھ电هگé‚®ن»¶ç»™ن»–ï¼ںوٹ‘وˆ–,هœ¨è´¦هچ•ن؛‹ن»¶و—©هˆ°è¾¾çڑ„وƒ…ه†µن¸‹éڑ¾éپ“ه°±ن¸چه؛”该è؟™ن¹ˆهپڑن¹ˆï¼ںè؟کوœ‰ه¦‚وœوˆ‘ن»¬ه·²ç»ڈوœ‰ن؛†ن¸€ه¥—ه®Œو•´çڑ„ه¼‚و¥é€ڑçں¥و¨،ه‹ï¼Œوˆ‘ن»¬وک¯هگ¦è؟ک需è¦پهگŒو¥çڑ„هœ¨ç”¨وˆ·و“چن½œو—¶è؟”ه›é”™è¯¯ه‘¢ï¼ںوˆ‘çڑ„و„ڈو€وک¯ï¼Œه…¶ه®و²،ه•¥هŒ؛هˆ«ï¼ŒهگŒو¥è؟”ه›ن¸€و ·ن¹ںه°±وک¯ه‘ٹ诉用وˆ·ç»“وœè€Œه·²م€‚
و‰€ن»¥ï¼Œه¦‚وœوˆ‘ن»¬ن¸چهœ¨و“چن½œو—¶هگŒو¥è؟”ه›é”™è¯¯ن؟،وپ¯ï¼ˆهپ‡è®¾ه‘½ن»¤çڑ„و•°وچ®وک¯هگˆو³•çڑ„),وˆ‘ن»¬و‰€éœ€è¦پهپڑçڑ„هڈ¯èƒ½ه°±وک¯هœ¨هڈ‘é€په‘½ن»¤هگژه‘ٹ诉用وˆ·â€œè°¢è°¢و“چن½œم€‚结وœç،®è®¤ه°†ç¨چهگژé€ڑè؟‡emailهڈ‘ه‡؛â€م€‚è؟™و ·ï¼Œوˆ‘ن»¬ه°±è؟هœ¨é،µé¢ه°ڈوŒ‚ن»¶ن¸ٹه‘ٹ诉用وˆ·ن½ وœ‰ه‡ ن¸ھه‘½ن»¤و²،و‰§è،Œه®Œéƒ½çœپن؛†م€‚
آ
ه‘½ن»¤ه’Œè‡ھو²»
هœ¨è؟™ن¸ھو¨،ه‹é‡Œï¼Œه‘½ن»¤ن¸چ需è¦پ马ن¸ٹ被و‰§è،Œوژ‰â€”—ن»–ن»¬هڈ¯ن»¥و”¾هœ¨éکںهˆ—里ه¼‚و¥و‰§è،Œم€‚至ن؛ژه‘½ن»¤èƒ½ه¤ںه¤ڑه؟«çڑ„被و‰§è،Œï¼Œè؟™وک¯وœچهٹ،ه±‚该ه…³ه؟ƒçڑ„é—®é¢ک而éن¸€ن¸ھو•´ن½“و¶و„é—®é¢کم€‚而è؟™ï¼Œه°±وک¯è؟گè،Œو—¶è‡ھن¸»ه¤„çگ†ه‘½ن»¤èٹ‚点çڑ„ن¸€ن¸ھ设è®،è¦پç´ â€”â€”وˆ‘ن»¬ن¸چ需è¦په’Œه®¢وˆ·ç«¯ن؟وŒپ链وژ¥م€‚
ن¸ژو¤هگŒو—¶ï¼Œوˆ‘ن»¬ن¹ںن¸چه؛”该هœ¨و‰§è،Œه‘½ن»¤و—¶وک¾ه¼ڈçڑ„هژ»و“چن½œوں¥è¯¢ç”¨çڑ„و•°وچ®ه®¹ه™¨â€”—ن»»ن½•و“چن½œéƒ½ه؛”该ن؛¤ç»™è‡ھو²»ç»„ن»¶ç»„ن»¶ه®Œوˆگ——è؟™ن¹ںوک¯è‡ھو²»ه®ڑن¹‰çڑ„ن¸€éƒ¨هˆ†م€‚
هڈ¦ن¸€ن¸ھè¦په…³ه؟ƒçڑ„é—®é¢که؛”该وک¯و•°وچ®ه؛“ه®•وژ‰وˆ–者éپ‡هˆ°و»é”پو—¶çڑ„ه¤„çگ†و–¹و،ˆم€‚و¤و—¶وٹ›ه‡؛çڑ„错误肯ه®ڑن¸چ能直وژ¥و‰”هˆ°ه®¢وˆ·ç«¯هژ»â€”—وˆ‘ن»¬ه®Œه…¨هڈ¯ن»¥ه›و»ڑه¹¶é‡چ试م€‚ه½“ç³»ç»ںç®،çگ†ه‘کوٹٹو•°وچ®ه؛“وپ¢ه¤چهگژ,و‰€وœ‰هœ¨éکںهˆ—里ç‰ه¾…çڑ„ه‘½ن»¤éƒ½ه°†é،؛هˆ©çڑ„و‰§è،Œï¼Œè€Œç”¨وˆ·ن¹ںهڈ¯ن»¥و”¶هˆ°ç»“وœهڈچ馈م€‚
و¤و—¶ç³»ç»ںه°±هپ¥ه£®ه¤ڑن؛†م€‚
هڈ¦ه¤–,由ن؛ژè؟™ن¸ھو•°وچ®ه؛“ن¸چن¼ڑه†چوœچهٹ،ن؛ژوں¥è¯¢çڑ„هœ؛و™¯ï¼Œه®ƒه°±هڈ¯ن»¥ن¸؛ه‘½ن»¤و‰§è،Œوڈگن¾›و›´ه¥½çڑ„و€§èƒ½و”¯و’‘,و¯”ه¦‚ن؟ç•™و›´ه¤ڑ用ن؛ژه†™çڑ„è،Œ/é،µç¼“هکو•°وچ®هœ¨ه†…هک里م€‚而ه½“و•°وچ®ه؛“و—¢è¦پè´ںè´£وں¥è¯¢هڈˆè¦پè´ںè´£ه†™ه…¥çڑ„و—¶ه€™ï¼Œه†…هک里çڑ„و•°وچ®ن¹ںه¾€ه¾€هœ¨و”¯و’‘وں¥è¯¢ه’Œو”¯و’‘و›´و–°çڑ„缓هکو•°وچ®é—´و¥ه›هˆ‡وچ¢م€‚
آ
è‡ھو²»ç»„ن»¶
虽然هœ¨ن¸ٹو–‡çڑ„ه›¾ن¸ï¼Œو‰€وœ‰çڑ„ه‘½ن»¤éƒ½é›†ن¸هˆ°ن¸€ن¸ھè‡ھو²»ç»„ن»¶é‡Œï¼Œن½†ه®é™…ن¸ٹوˆ‘ن»¬هڈ¯ن»¥è®©و¯ڈن¸ھه‘½ن»¤è¢«ن¸چهگŒçڑ„è‡ھو²»ç»„ن»¶و¥ه¤„çگ†ï¼Œن¸”و¯ڈن¸ھ组ن»¶éƒ½وœ‰è‡ھه·±ç‹¬ç«‹çڑ„ç‰ه¾…éکںهˆ—م€‚è؟™ن¸ھهپڑو³•هڈ¯ن»¥è®©وˆ‘ن»¬è½»è€Œوک“ن¸¾çڑ„هڈ‘çژ°ه“ھن¸ھç‰ه¾…éکںهˆ—وک¯وœ€é•؟çڑ„,ن»ژ而هڈ‘çژ°ç³»ç»ںçڑ„瓶颈م€‚è؟™ه¯¹ه¼€هڈ‘ه¾ˆهڈ‹ه¥½ï¼Œن½†ه¯¹ç³»ç»ںç®،çگ†ه‘ک而言هˆ™و²،é‚£ن¹ˆهڈ‹ه¥½م€‚
ç”±ن؛ژç‰ه¾…éکںهˆ—里وœ‰è¾ƒه¤ڑçڑ„ه‘½ن»¤ï¼Œوˆ‘ن»¬ه®Œه…¨هڈ¯ن»¥é’ˆه¯¹è؟™ن؛›éکںهˆ—ه¢هٹ ه¤„çگ†èٹ‚点(ن½؟用وœچهٹ،و€»ç؛؟çڑ„هˆ†هڈ‘ه™¨ه®Œوˆگ),ن»ژ而轻و¾çڑ„و‰©ه±•ç³»ç»ںو€§èƒ½è¾ƒو…¢çڑ„ه¤„çگ†éƒ¨هˆ†م€‚ه…¶ن»–部هˆ†هˆ™ه®Œه…¨ن¸چن¼ڑوµھ费资و؛گم€‚
آ
وœچهٹ،ه±‚
è‡ھو²»ç»„ن»¶ن¸ç”¨ن؛ژه¤„çگ†ه‘½ن»¤çڑ„هگ„ç§چه¯¹è±،ه®é™…ن¸ٹه°±ç»„وˆگن؛†وˆ‘ن»¬çڑ„وœچهٹ،ه±‚م€‚ن½ ن¹‹و‰€ن»¥و²،وœ‰هœ¨CQRSن¸وکژوک¾çڑ„看هˆ°è؟™ن¸€ه±‚çڑ„هژںه› ,وک¯ه› ن¸؛ه®ƒه¹¶éهƒڈه¸¸è§„çڑ„相ه…³ه¯¹è±،èپڑهگˆهœ¨ن¸€èµ·ه½¢وˆگçڑ„ه±‚é‚£و ·ه…·وœ‰è¯†هˆ«و€§م€‚
هœ¨ن¼ ç»ںçڑ„هˆ†ه±‚و¶و„ن¸ه¹¶و²،وœ‰وک¾ç¤؛çڑ„ه£°وکژن¸€ه±‚ه¯¹è±،间需è¦پوœ‰هگ„ç§چن¾èµ–ه…³ç³»ï¼Œç”ڑ至都و²،وœ‰وڑ—ç¤؛ه؛”该وœ‰è؟™ه›ن؛‹م€‚然而,ه½“وˆ‘ن»¬ن»¥é¢هگ‘ه‘½ن»¤çڑ„视角هژ»çœ‹و•´ن¸ھوœچهٹ،ه±‚çڑ„و—¶ه€™ï¼Œوˆ‘ن»¬çœ‹هˆ°çڑ„وک¯ه¤„çگ†ن¸چهگŒه‘½ن»¤çڑ„هگ„ç§چه¯¹è±،م€‚ç”±ن؛ژو¯ڈن¸ھه‘½ن»¤éƒ½وک¯ç‹¬ç«‹çڑ„,那ن¹ˆن¸؛ن»€ن¹ˆه¤„çگ†ه‘½ن»¤çڑ„ه¯¹è±،需è¦پ相ن؛’ن¾èµ–ه‘¢ï¼ں
ه®é™…ن¸ٹه؛”该ه°½é‡ڈéپ؟ه…چن¾èµ–,除éوœ‰وکژç،®çڑ„çگ†ç”±ن½؟用ن»–ن»¬م€‚
ن؟وŒپه¤„çگ†ه‘½ن»¤çڑ„ه¯¹è±،间相ن؛’独立ه¯¹ن؛ژوˆ‘ن»¬و¥è¯´éه¸¸وœ‰ç›ٹم€‚ه½“وˆ‘ن»¬هچ‡ç؛§ç³»ç»ںو—¶ï¼Œو¯ڈو¬،و ¹وچ®ن¸€ن¸ھه‘½ن»¤و¥ï¼Œè€Œن¸چ需è¦په°†و•´ن¸ھç³»ç»ںهپœن¸‹و¥ï¼Œه¹¶è®©و–°çڑ„版وœ¬ه¯¹è€پ版وœ¬è؟›è،Œهگ‘ه‰چه…¼ه®¹م€‚
ه› و¤ï¼Œه°½é‡ڈن؟وŒپو¯ڈن¸ھه‘½ن»¤ه¤„çگ†ه™¨هœ¨ن¸€ن¸ھن»–è‡ھه·±ç›¸ه¯¹çڑ„çژ¯ه¢ƒن¸ï¼Œç”ڑ至وک¯ن¸€ه¥—ه®Œه…¨ç‹¬ç«‹çڑ„解ه†³و–¹و،ˆن¸ï¼Œن»¥و¤ه¼•ه¯¼ç”¨وˆ·ن¸چè¦په·²é‡چ用ن¹‹هگچه¼•ه…¥ن¾èµ–ه…³ç³»ï¼ˆè؟™وک¯ن¸ھè°¬è®؛)م€‚ه¦‚وœن½ çڑ„çڑ„ç،®ç،®وƒ³وٹٹه®ƒن»¬ه…¨éƒ½و”¾هˆ°ن¸€ن¸ھوµپ程里و¥ه¤„çگ†هگŒن¸€ن¸ھه‘½ن»¤éکںهˆ—,那ن¹ˆن½ ه°±è¦پوژ¥هڈ—许ه¤ڑè‡ھو²»ç»„ن»¶ه¸¦و¥çڑ„ن¼کهٹ؟çڑ„被وٹµو¶ˆم€‚
آ
领هںںو¨،ه‹ن½•هژ»ن½•ن»ژï¼ں
ه°½ç®،هœ¨ن¸ٹé¢çڑ„ه›¾ن¸é¢†هںںو¨،ه‹ه°±و”¾هœ¨ه¤„çگ†ه‘½ن»¤çڑ„è‡ھو²»ç»„ن»¶çڑ„و—پ边,ه®ƒه®é™…ن¸ٹهڈھوک¯ن¸€ن¸ھه®çژ°çڑ„细èٹ‚م€‚ه®é™…ن¸ٹه¹¶و²،وœ‰è§„ه®ڑ说و‰€وœ‰çڑ„ه‘½ن»¤éƒ½éœ€è¦پé€ڑè؟‡ن¸€ن¸ھ领هںںو¨،ه‹و¥ه¤„çگ†م€‚ه®é™…ن¸ٹن½ هڈ¯ن»¥ن½؟用ن¸ڑهٹ،è„ڑوœ¬و¥ه¤„çگ†ن¸€éƒ¨هˆ†ه‘½ن»¤ï¼Œè،¨و¨،ه—و¨،ه¼ڈه¤„çگ†هڈ¦ن¸€éƒ¨هˆ†ه‘½ن»¤ï¼Œوˆ–者وک¯ç”¨é¢†هںںو¨،ه‹م€‚ن؛‹ن»¶و؛¯و؛گوک¯هڈ¦ن¸€ç§چه®çژ°و–¹ه¼ڈم€‚
هڈ¦ن¸€ن¸ھ需è¦پ说وکژçڑ„وک¯çژ°هœ¨é¢†هںںو¨،ه‹ن¸چه†چ需è¦پو”¯و’‘وں¥è¯¢م€‚é‚£ن¹ˆé—®é¢کو¥ن؛†ï¼ڑوˆ‘ن»¬è؟کوک¯هگ¦éœ€è¦پهœ¨é¢†هںںو¨،ه‹ن¸هکهœ¨é‚£ن¹ˆه¤ڑçڑ„ه…³èپ”ه…³ç³»ه‘¢ï¼ں
(ن½ هڈ¯èƒ½éœ€è¦پو·±ه…¥çگ†è§£ن¸‹ï¼‰
ن½ çœںçڑ„需è¦پهœ¨ç”¨وˆ·ه®ن½“ن¸وŒپوœ‰ن¸€ن¸ھ订هچ•é›†هگˆï¼ںهœ¨ه“ھن¸ھه‘½ن»¤ن¸وˆ‘ن»¬éœ€è¦په¯¹è؟™ن¸ھ集هگˆè؟›è،Œه¯¼èˆھï¼ںه“ھç§چه‘½ن»¤هڈˆéœ€è¦پن¸€ه¯¹ه¤ڑçڑ„و•°وچ®ه…³ç³»ï¼ںهپ‡ه¦‚ن¸€ه¯¹ه¤ڑوک¯ه؟…需çڑ„,那ن¹ˆه¤ڑه¯¹ه¤ڑه®é™…ن¸ٹن¹ںه°±وœ‰éœ€è¦پم€‚ه¥½هگ§ï¼Œوˆ‘çڑ„و„ڈو€ه…¶ه®وک¯ه¤ڑو•°ه‘½ن»¤ه…¶ه®هڈھوŒپوœ‰1هˆ°2ن¸ھه¼•ç”¨IDم€‚
ن»»ن½•éœ€è¦پé€ڑè؟‡ه¾ھçژ¯ه¤„çگ†هگه®ن½“و¥è®،ç®—çڑ„èپڑهگˆو“چن½œه®é™…ن¸ٹ都هڈ¯ن»¥é€ڑè؟‡وڈگه‰چه¤„çگ†ه¹¶ه°†و•°وچ®ن½œن¸؛ه±و€§هکه‚¨هœ¨çˆ¶ه®ن½“ن¸و¥ه®çژ°م€‚é€ڑè؟‡ه¯¹و‰€وœ‰çڑ„ه®ن½“è؟›è،Œن¸ٹé¢çڑ„预ه¤„çگ†و“چن½œهڈ¯ن»¥ه¾—هˆ°ه·²ç»ڈه°†IDو›؟وچ¢ن¸؛ه±و€§çڑ„ه®Œه…¨ç‹¬ç«‹çڑ„ه®ن½“——هگه®ن½“هˆ™وŒپوœ‰çˆ¶ه®ن½“çڑ„ID,ه’Œو•°وچ®ه؛“ن¸ن¸€و ·م€‚
هœ¨è؟™ç§چو¨،ه¼ڈن¸‹ï¼Œه‘½ن»¤هڈ¯ن»¥ه®Œه…¨é€ڑè؟‡ن¸€ن¸ھ领هںںو¨،ه‹و¥ه¤„çگ†â€”—ن¸€ن¸ھèپڑهگˆçڑ„و ¹ه¯¹è±،ه°±وک¯ن¸€ن¸ھن¸€è‡´و€§è¾¹ç•Œم€‚
آ
ه‘½ن»¤ه¤„çگ†çڑ„وŒپن¹…هŒ–
ن¹‹ه‰چه·²ç»ڈç،®è®¤ç”¨ن؛ژه‘½ن»¤ه¤„çگ†çڑ„و•°وچ®ه؛“وک¯ن¸چن¼ڑ用و¥هپڑو•°وچ®وں¥è¯¢çڑ„,而ç»ه¤§éƒ¨هˆ†ï¼ˆه¦‚وœن¸چوک¯و‰€وœ‰ï¼‰çڑ„ه‘½ن»¤éƒ½وŒپوœ‰ç€ن»–ن»¬è¦پو›´و–°çڑ„è،Œو•°وچ®çڑ„ID,那ن¹ˆç»™é¢†هںںو¨،ه‹ه¯¹è±،里çڑ„و¯ڈن¸€ن¸ھه±و€§هˆ†é…چن¸€ن¸ھو•°وچ®ه؛“هˆ—ه—و®µوک¯هگ¦çœںçڑ„è؟کوœ‰ه؟…è¦پï¼ںه¦‚وœوˆ‘ن»¬وٹٹو•´ن¸ھه¯¹è±،都ه؛ڈهˆ—هŒ–هگژهکهˆ°ن¸€ن¸ھه—و®µé‡Œï¼Œç„¶هگژهڈ¦ن¸€ن¸ھه—و®µç”¨و¥هکIDن¼ڑو€ژو ·ï¼ںè؟™ç§چهپڑو³•هگ¬èµ·و¥وœ‰ç‚¹هƒڈه¾ˆه¤ڑن؛‘وœچهٹ،وڈگن¾›ه•†çڑ„K-Vهکه‚¨و–¹ه¼ڈم€‚هœ¨è؟™ç§چوƒ…ه†µن¸‹ï¼Œن½ وک¯هگ¦وœ‰éœ€è¦پ用ه¯¹è±،ه…³ç³»وک ه°„و¥هکه‚¨و•°وچ®ï¼ں
ه½“ن½ 需è¦په¼؛هˆ¶وںگهˆ—و•°وچ®çڑ„ه”¯ن¸€و€§çڑ„و—¶ه€™ï¼Œهڈ¯ن»¥ن»ژو¯ڈن¸ھو•°وچ®è،Œن¸و‹‰ه‡؛ن¸€هˆ—ه‡؛و¥و¥ه®çژ°م€‚
وˆ‘ه¹¶ن¸چوک¯وƒ³è®©ن½ هœ¨و¯ڈن¸ھهœ؛و™¯ن¸éƒ½ç”¨è؟™ه¥—و–¹ه¼ڈ——وˆ‘هڈھوک¯وƒ³è®©ن½ é‡چو–°ه¯¹ن¸€ن؛›وœ€هں؛وœ¬çڑ„هپ‡è®¾ه’Œè®¾è®،è؟›è،Œو€è€ƒم€‚
آ
وˆ‘需è¦پé‡چ申
ن½ ه¦‚ن½•ه¤„çگ†ه‘½ن»¤ه®é™…ن¸ٹوک¯CQRSçڑ„ن¸€ن¸ھه®çژ°ç»†èٹ‚م€‚
آ
ن؟وŒپوں¥è¯¢و•°وچ®ه®¹ه™¨çڑ„و•°وچ®هگŒو¥
هœ¨è‡ھو²»ç»„ن»¶é€ڑè؟‡ن؛†ن¸€ن¸ھه‘½ن»¤çڑ„ه¤„çگ†ï¼Œه°†و•°وچ®ه؛“ن¸çڑ„و•°وچ®è؟›è،Œو›´و–°هگژ,وژ¥ن¸‹و¥è¦پهپڑçڑ„ه°±وک¯هڈ‘ه‡؛ن؛‹ن»¶ï¼Œه‘ٹ诉ه…¨ن¸–ç•Œè؟™ن»¶ن؛‹م€‚è؟™ن¸ھن؛‹ن»¶é€ڑه¸¸وک¯ه‘½ن»¤و‰§è،Œçڑ„“è؟‡هژ»ه¼ڈâ€ï¼ڑ
设置用وˆ·ن¸؛ن¼کè´¨çڑ„ه‘½ن»¤-م€‹ç”¨وˆ·ه·²è¢«è®¾ç½®ن¸؛ن¼کè´¨çڑ„ن؛‹ن»¶
هڈ‘ه¸ƒن؛‹ن»¶è؟™ن¸ھهٹ¨ن½œه’Œه¤„çگ†ه‘½ن»¤ن»¥هڈٹو›´و–°و•°وچ®ه؛“ه؛”该و”¾هœ¨هگŒن¸€ن¸ھن؛‹هٹ،ن¸ه®Œوˆگم€‚è؟™ç§چوƒ…ه†µن¸‹ï¼Œن»»ن½•هژںه› ه¯¼è‡´çڑ„ه‘½ن»¤وڈگن؛¤ه¤±è´¥éƒ½ن¼ڑن½؟ه¾—وœ€ç»ˆçڑ„ن؛‹ن»¶وœھ被هڈ‘ه¸ƒم€‚ن؛‹ن»¶هڈ‘ه¸ƒه؛”该وک¯ç”±ن½ و‰€ن½؟用çڑ„و¶ˆوپ¯و€»ç؛؟و¥é»ک认ه®çژ°çڑ„م€‚ه¦‚وœن½ 用ن؛†MSMQو¥ن½œن¸؛ه؛•ه±‚ن¼ 输çڑ„ه®çژ°ï¼Œé‚£ن¹ˆه°±éœ€è¦پن½؟用ن؛‹هٹ،ه‹éکںهˆ—م€‚
用ن؛ژو”¶هگ¬ن؛‹ن»¶ه¹¶و›´و–°وں¥è¯¢و•°وچ®ه®¹ه™¨çڑ„è‡ھو²»ç»„ن»¶ه®é™…ن¸ٹو¯”较简هچ•ï¼Œه®ƒهڈھ需è¦په°†ن؛‹ن»¶è½¬وچ¢وˆگوŒپن¹…هŒ–çڑ„视ه›¾و¨،ه‹ç»“و„م€‚وˆ‘çڑ„ه»؛è®®وک¯و¯ڈن¸ھ视ه›¾و¨،ه‹ç±»éƒ½وœ‰ن¸€ن¸ھه¯¹ه؛”çڑ„ن؛‹ن»¶ه¤„çگ†è‡ھو²»ç»„ن»¶م€‚
ن¸‹é¢ه†چو¥çœ‹ن¸€و¬،و‰€وœ‰ç»“و„çڑ„ه›¾ï¼ڑ
آ
ن½؟用هœ؛و™¯çڑ„边界
ه°½ç®،CQRSو¶‰هڈٹن؛†ه¾ˆه¤ڑ软ن»¶و¶و„و–¹ه¼ڈ,ه®ƒن¹ںه¹¶éç«™هœ¨é£ں物链çڑ„é،¶ç«¯ï¼ˆهگ„ç§چé€ڑهگƒï¼‰م€‚ه¦‚وœن½؟用ن؛†CQRS,那ن¹ˆه®ƒه؛”该وک¯هœ¨ن¸€ن¸ھوœ‰è¾¹ç•Œçڑ„ن¸ٹن¸‹و–‡ï¼ˆé¢†هںں驱هٹ¨è®¾è®،)وˆ–者ن¸€ن¸ھن¸ڑهٹ،组ن»¶ï¼ˆSOA)——ن¸€ن¸ھé«که†…èپڑçڑ„é—®é¢ک领هںںن¸çڑ„م€‚ن¸€ن¸ھن¸ڑهٹ،组ن»¶هڈ‘ه¸ƒه‡؛و¥çڑ„ن؛‹ن»¶è¢«ه…¶ن»–çڑ„ن¸ڑهٹ،组ن»¶و”¶هگ¬ï¼Œç„¶هگژو”¶هگ¬çڑ„组ن»¶هگ„è‡ھو ¹وچ®éœ€è¦پو›´و–°è‡ھه·±çڑ„وں¥è¯¢و•°وچ®ه®¹ه™¨م€‚
CQRSن¸هگ„ن¸ھن¸ڑهٹ،组ن»¶çڑ„UIهڈ¯ن»¥è¢«وڈ‰هˆ°ن¸€ن¸ھهچ•ç‹¬çڑ„ه؛”用ن¸ï¼Œç»™ç”¨وˆ·وڈگن¾›ن¸€ن¸ھن¸€ç«™هŒ–çڑ„هڈ¯ن»¥ن؟¯è§†é¢†هںںن¸و‰€وœ‰éƒ¨هˆ†çڑ„ه¤چهگˆè§†ه›¾م€‚ه› و¤ه¤چهگˆè§†ه›¾و،†و¶ن¹ںه¾€ه¾€ه¾ˆوœ‰ه؟…è¦پم€‚
آ
و€»ç»“
CQRSوک¯ç”¨و¥è§£ه†³ه¤ڑ用وˆ·هچڈهگŒو“چن½œçڑ„ن¸€ç§چو¶و„م€‚ه®ƒéه¸¸وکژç،®çڑ„考虑ن؛†و•°وچ®è؟‡و—¶ه’Œوک“هڈکç‰ç‰¹و€§ï¼Œه¹¶ن»¥و¤هˆ›é€ ه‡؛ن؛†ن¸€ن¸ھو›´هٹ 简هچ•ه’Œهڈ¯و‰©ه±•çڑ„و¶و„و–¹ه¼ڈم€‚
ه¦‚وœو²،وœ‰è€ƒè™‘用وˆ·ç•Œé¢çڑ„设è®،,ه°±و— و³•ه‡†ç،®وژŒوڈ،用وˆ·çڑ„و„ڈه›¾ï¼Œè‡ھ然ن¹ںو— و³•ه……هˆ†هڈ‘وŒ¥CQRSçڑ„ن¼کهٹ؟م€‚ه½“وٹٹه®¢وˆ·ç«¯çڑ„و•°وچ®هگˆو³•و€§و ،éھŒç؛³ه…¥è€ƒè™‘çڑ„و—¶ه€™ï¼Œه‘½ن»¤ن¹ںه°±هڈ¯èƒ½هپڑه‡؛ن¸€ن؛›è°ƒو•´م€‚هœ¨é€ڑç›ک考虑è؟‡ه‘½ن»¤ه’Œن؛‹ن»¶وک¯ه¦‚ن½•ه¤„çگ†çڑ„هœ؛و™¯ه’Œé،؛ه؛ڈهگژ,能ه¤ںه¼±هŒ–错误هڈٹو—¶è؟”ه›ه؟…è¦پو€§çڑ„é€ڑçں¥و¨،ه¼ڈن¹ںه°±è‡ھ然而然çڑ„ه‡؛و¥ن؛†م€‚
ن½؟用CQRSهڈ¯ن»¥ç»™é،¹ç›®ه¸¦و¥ن¸€ن¸ھو›´ه…·هڈ¯ç»´وٹ¤و€§ه’Œé«کو€§èƒ½çڑ„ن»£ç پهں؛ç،€م€‚è؟™ç§چ简ن¾؟ه’Œهڈ¯و‰©ه±•و€§ه¹¶éو¥و؛گن؛ژن»»ن½•وٹ€وœ¯çڑ„“ه®Œç¾ژه®è·µâ€ï¼Œè€Œوک¯é€ڑè؟‡ه¯¹ن¸ڑهٹ،需و±‚细èٹ‚çڑ„ه®Œه…¨ن؛†è§£ه¾—و¥çڑ„م€‚ه¦‚وœè¯´وœ‰ن»»ن½•ه¯¹ن؛ژ相ن¼¼é—®é¢کçڑ„ه¤ڑç§چ解ه†³و–¹و،ˆè¢«وکژوک¾çڑ„و”¾هˆ°ن¸€èµ·ن½؟用——那ه°±وک¯و•°وچ®è¯»هڈ–ه™¨ه’Œé¢†هںںو¨،ه‹ï¼Œهچ•هگ‘و¶ˆوپ¯ن¼ 递ه’ŒهگŒو¥è°ƒç”¨م€‚
ه°½ç®،è؟™ç¯‡هچڑه®¢è¶…è؟‡ن؛†3000ه—(é ,ç؟»è¯‘è؟‡و¥éƒ½6000ه¤ڑن؛†ï¼‰ï¼Œوˆ‘ن»چ然觉ه¾—è؟™ه¹¶و²،وœ‰ه¯¹CQRSè؟™ن¸ھن¸»é¢کè؟›è،Œè¶³ه¤ںو·±ه…¥çڑ„讨è®؛(هœ¨وˆ‘çڑ„م€ٹé«کç؛§هˆ†ه¸ƒه¼ڈç³»ç»ں设è®،课程م€‹ن¸ï¼Œوˆ‘èٹ±ن؛†5ه¤©é‡Œçڑ„3ه¤©و‰چن؟éڑœè؟™ن¸ھن¸»é¢کçڑ„و‰€وœ‰و–¹é¢éƒ½è®²çڑ„足ه¤ںو·±ه…¥ï¼‰م€‚ه°½ç®،ه¦‚و¤ï¼Œوˆ‘ن»چ然ه¸Œوœ›è؟™ç¯‡و–‡ç« 能ه¤ںه¸¦ن½ ن؛†è§£CQRS设è®،çڑ„ç›®çڑ„,ه¹¶èƒ½ه¤ں让ن½ ن»¥هگژهœ¨è®¾è®،هˆ†ه¸ƒه¼ڈç³»ç»ںçڑ„و—¶ه€™èƒ½èژ·ه¾—و›´ه¤ڑçڑ„视é‡ژم€‚
وœ‰é—®é¢که’Œè¯„è®؛éڑڈو—¶و¬¢è؟ژم€‚



相ه…³وژ¨èچگ
**CQRS(ه‘½ن»¤وں¥è¯¢è´£ن»»هˆ†ç¦»ï¼‰و¨،ه¼ڈ详解** CQRS,ه…¨ç§°ن¸؛Command Query Responsibility Segregation,ن¸و–‡è¯‘ن¸؛“ه‘½ن»¤وں¥è¯¢è´£ن»»هˆ†ç¦»â€و¨،ه¼ڈم€‚è؟™وک¯ن¸€ç§چ设è®،و¨،ه¼ڈ,ن¸»è¦پ用ن؛ژه¤„çگ†ه¤چو‚çڑ„هˆ†ه¸ƒه¼ڈç³»ç»ںن¸çڑ„و•°وچ®ç®،çگ†ï¼Œé€ڑè؟‡ه°†è¯»و“چن½œ...
采用è؟™ç§چو–¹ه¼ڈçڑ„و¶و„,ن¸ھن؛؛觉ه¾—,C端ه؛”该采用Event Sourcing(简称ES)و¨،ه¼ڈو‰چوœ‰و„ڈن¹‰ï¼Œهگ¦هˆ™ه°±وک¯è‡ھه·±ç»™è‡ھه·±و‰¾é؛»çƒ¦م€‚ه› ن¸؛è؟™و ·هپڑن½ ن¼ڑهڈ‘çژ°ن¼ڑه‡؛çژ°ه†—ن½™و•°وچ®ï¼ŒهگŒو ·çڑ„و•°وچ®ï¼Œهœ¨C端çڑ„dbن¸وœ‰ï¼Œè€Œهœ¨Q端çڑ„dbن¸ن¹ںوœ‰م€‚ه’Œن¸ٹé¢ç¬¬ن¸€ç§چ...
CQRS(ه‘½ن»¤وں¥è¯¢èپŒè´£هˆ†ç¦»ï¼‰و¨،ه¼ڈوک¯ه¾®وœچهٹ،و¶و„ن¸çڑ„ن¸€ç§چ设è®،و¨،ه¼ڈ,ه®ƒه°†و•°وچ®çڑ„读هڈ–و“چن½œن¸ژو›´و–°و“چن½œهˆ†ه¼€ï¼Œن»ژ而وڈگé«کن؛†ç³»ç»ںçڑ„ه¤چو‚و€§ه’Œو€§èƒ½م€‚ هœ¨.NET Coreن¸ه®çژ°CQRSو¨،ه¼ڈ,首ه…ˆéœ€è¦پçگ†è§£ه…¶هں؛وœ¬و¦‚ه؟µم€‚CQRSçڑ„و ¸ه؟ƒو€وƒ³وک¯ه°†ن¸€ن¸ھ...
هœ¨çژ°ن»£è½¯ن»¶و¶و„ن¸ï¼ŒCQRS(ه‘½ن»¤وں¥è¯¢è´£ن»»هˆ†ç¦»ï¼‰و¨،ه¼ڈه·²وˆگن¸؛ه¤„çگ†ه¤چو‚ن¸ڑهٹ،逻辑ه’Œو•°وچ®éœ€و±‚çڑ„وœ‰و•ˆو‰‹و®µم€‚CQRSو¨،ه¼ڈé€ڑè؟‡ه°†و•°وچ®çڑ„读هڈ–(وں¥è¯¢ï¼‰ه’Œه†™ه…¥ï¼ˆه‘½ن»¤ï¼‰و“چن½œهˆ†ç¦»ï¼Œوڈگé«کن؛†ه؛”用程ه؛ڈçڑ„و€§èƒ½م€پهڈ¯و‰©ه±•و€§ه’Œç»´وٹ¤و€§م€‚وœ¬و–‡ه°†è¯¦ç»†ن»‹ç»چ...
CQRS و—…程CQRS و—…程CQRS و—…程CQRS و—…程CQRS و—…程CQRS و—…程
م€ٹ领هںں驱هٹ¨è®¾è®،ن¸ژCQRSه®è·µï¼ڑDDDSample-CQRSç¤؛ن¾‹ن»£ç پ解وگم€‹ هœ¨è½¯ن»¶ه¼€هڈ‘领هںں,领هںں驱هٹ¨è®¾è®،(Domain-Driven Design, DDD...é€ڑè؟‡ه¯¹è؟™ن¸ھç¤؛ن¾‹çڑ„و·±ه…¥ه¦ن¹ ,ه¼€هڈ‘者能ه¤ںو›´ه¥½هœ°çگ†è§£è؟™ن؛›و¨،ه¼ڈçڑ„精髓,ن»ژ而هœ¨ه®é™…é،¹ç›®ن¸çپµو´»è؟گ用م€‚
و»،足ه‘½ن»¤وں¥è¯¢èپŒè´£éڑ”离(CQRS)و¨،ه¼ڈه®çژ°çڑ„ن¸¤ن¸ھه؛”用程ه؛ڈم€‚ 简هچ•çڑ„CQRS CQRSن»£è،¨ه‘½ن»¤وں¥è¯¢è´£ن»»éڑ”离م€‚ ه®ƒوک¯ن¸€ç§چ设è®،و¨،ه¼ڈ,用ن؛ژه¼؛هˆ¶ه°†ن؟®و”¹ه؛”用程ه؛ڈçٹ¶و€پçڑ„و“چن½œن¸ژن½؟ه؛”用程ه؛ڈçٹ¶و€پن؟وŒپه®Œو•´çڑ„و“چن½œهˆ†ه¼€م€‚ ه¼•ç”¨ï¼ڑ“ه¯¹è±،被هˆ†ن¸؛ن¸¤...
و‘کè¦پï¼ڑ ن؛†è§£ Java ن¸çڑ„ه‘½ن»¤وں¥è¯¢è´£ن»»هˆ†ç¦»ï¼ˆCQRS)و¨،ه¼ڈم€‚وژ¢ç´¢ه¦‚ن½•هˆ†ç¦»ه‘½ن»¤ه’Œوں¥è¯¢هڈ¯ن»¥ه¢ه¼؛软ن»¶ç³»ç»ںçڑ„هڈ¯و‰©ه±•و€§م€پو€§èƒ½ه’Œهڈ¯ç»´وٹ¤و€§م€‚ ن¸€م€په‘½ن»¤وں¥è¯¢è´£ن»»هˆ†ç¦»è®¾è®،و¨،ه¼ڈçڑ„هˆ«هگچ CQRS ن؛Œم€په‘½ن»¤وں¥è¯¢è´£ن»»هˆ†ç¦»è®¾è®،و¨،ه¼ڈçڑ„و„ڈه›¾ ه‘½ن»¤...
ه¯¹ن؛ژه¼€هڈ‘ه›¢éکں而言,ه°†CQRSه’Œن؛‹ن»¶و؛¯و؛گه؛”用ن؛ژçœںه®çڑ„ç³»ç»ںن¸ï¼Œéœ€è¦پن؛‹ه…ˆه¯¹è؟™ن؛›و¨،ه¼ڈوœ‰و·±ه…¥çڑ„çگ†è§£ه’ŒوژŒوڈ،م€‚ن¾‹ه¦‚,ن¸€ن¸ھو²،وœ‰CQRSç»ڈéھŒçڑ„ه›¢éکںهڈ¯èƒ½ن¼ڑهœ¨و„ه»؛م€پ部署هˆ°Windows Azureه¹³هڈ°ï¼Œه¹¶ç»´وٹ¤ن¸€ن¸ھه¤چو‚çڑ„ن¼پن¸ڑç؛§ç³»ç»ںو—¶éپ‡هˆ°هگ„ç§چé—®é¢ک...
CQRS(Command Query Responsibility Segregation,ه‘½ن»¤وں¥è¯¢èپŒè´£هˆ†ç¦»ï¼‰وک¯ن¸€ç§چ软ن»¶è®¾è®،و¨،ه¼ڈ,ه®ƒه°†è¯»هڈ–و“چن½œه’Œه†™ه…¥و“چن½œهˆ†ç¦»ï¼Œو—¨هœ¨وڈگé«کç³»ç»ںçڑ„هڈ¯è¯»و€§م€پهڈ¯ç»´وٹ¤و€§ه’Œو€§èƒ½م€‚CQRSçڑ„و ¸ه؟ƒو€وƒ³وک¯ه°†ن¸€ن¸ھه؛”用程ه؛ڈçڑ„و¨،ه‹هˆ†ن¸؛ن¸¤ن¸ھ独立...
CQRS(Command Query Responsibility Segregation,ه‘½ن»¤وں¥è¯¢èپŒè´£هˆ†ç¦»ï¼‰وک¯ن¸€ç§چ软ن»¶è®¾è®،و¨،ه¼ڈ,ه®ƒه°†ç³»ç»ںن¸çڑ„读و“چن½œه’Œه†™و“چن½œهˆ†ç¦»ï¼Œن»ژ而وڈگé«کç³»ç»ںçڑ„هڈ¯و‰©ه±•و€§ه’Œو€§èƒ½م€‚هœ¨è؟™ن¸ھهگچن¸؛“cqrs-command4acâ€çڑ„é،¹ç›®ن¸ï¼Œوˆ‘ن»¬çœ‹هˆ°ه®ƒ...
3.5ç³»ç»ںو¶و„17وژ¢ç´¢CQRSه’Œن؛‹ن»¶و؛گç›®ه½•3.6و¨،ه¼ڈه’Œو¦‚ه؟µ17 3.6.1ç³»ç»ںéھŒè¯پ21 3.6.2ن؛¤وک“边界22 3.6.3ه¹¶هڈ‘ه¤„çگ†22 3.6.4Aggregatesه’ŒAggregate Roots22 3.7ه®çژ°ç»†èٹ‚23 3.7.1é«که±‚و¶و„23 3.7.2ه†™è€…و¨،ه‹28 3.7.3ن½؟用Windows Azure...
ن½؟用Nest.jsو¼”ç¤؛CQRSو¨،ه¼ڈه’Œن؛‹ن»¶é©±هٹ¨ç¼–程 وڈڈè؟°و¤هکه‚¨ه؛“çڑ„و–‡ç« ï¼ڑ该软ن»¶çڑ„و،†ه›¾ن¸؛ï¼ڑ ه®‰è£… $ npm install è؟گè،Œه؛”用 # development $ npm run start # watch mode $ npm run start:dev # production mode $ npm run start...
git-cqrsJava7 ه®ƒوک¯ن¸€ن¸ھه°ڈ而简هچ•çڑ„و،†و¶ï¼Œه®çژ°ن؛† CQRS و¨،ه¼ڈçڑ„وںگن؛›هں؛وœ¬هٹں能م€‚ ه؛”用程ه؛ڈçڑ„و ¸ه؟ƒهœ¨ن؛ژه¯¹ن؛ژو¯ڈن¸ھو“چن½œï¼ˆو— è®؛وک¯ه‘½ن»¤è؟کوک¯وں¥è¯¢ï¼‰ï¼Œو ¸ه؟ƒè´ں责调用è´ںè´£ه¤„çگ†è¯¥و“چن½œçڑ„ه¤„çگ†ç¨‹ه؛ڈ,ن»¥و ¹وچ®ه‘½ن»¤ن¸هŒ…هگ«çڑ„ه°پ装و•°وچ®و‰§è،Œه؟…è¦پçڑ„...
cqrsjs JavaScript çڑ„ CQRS و¨،ه¼ڈه؛”用程ه؛ڈم€‚è¦پو±‚cqrsjs ن¹ں被设è®،用ن؛ژوµڈ览ه™¨ه’Œèٹ‚点م€‚ cqrsjs ن½؟用ن؛† ES6 Promiseم€‚ ه› و¤ï¼Œه¦‚وœç›®و ‡è؟گè،Œو—¶ن¸چوڈگن¾›وœ¬وœ؛ه®çژ°ï¼Œè¯·ن½؟用 polyfillم€‚ cqrsjs وک¯ه›´ç»• es5 هٹں能و„ه»؛çڑ„م€‚ و‰€ن»¥ه®ƒ...
DDDن½œن¸؛ن¸€ç§چç³»ç»ںهˆ†وگçڑ„و–¹و³•è®؛,وœ€ه¤§çڑ„é—®é¢کوک¯ه¦‚ن½•هœ¨é،¹ç›®ن¸ه®è·µم€‚而هœ¨ه®è·µè؟‡ç¨‹ن¸ه؟…然ن¼ڑé¢ن¸´è®¸ه¤ڑçڑ„é—®é¢ک,م€Œو¨،ه¼ڈم€چوک¯ç³»ç»ںو¶و„领هںںن¸ن¸€ç§چه¸¸è§پçڑ„...CQRS,ن¸و–‡هگچن¸؛ه‘½ن»¤وں¥è¯¢èپŒè´£هˆ†ç¦»م€‚ و¯‹ه؛¸ç½®ç–‘م€Œé¢†هںںم€چهœ¨DDDن¸هچ وچ®ن؛†و ¸ه؟ƒçڑ„هœ°
**CQRS(ه‘½ن»¤وں¥è¯¢è´£ن»»هˆ†ç¦»ï¼‰**وک¯ن¸€ç§چ软ن»¶è®¾è®،و¨،ه¼ڈ,ه®ƒه°†è¯»و“چن½œه’Œه†™و“چن½œهˆ†ç¦»ï¼Œن½؟ه¾—ç³»ç»ںهœ¨ه¤„çگ†ه¤چو‚ن¸ڑهٹ،逻辑و—¶èƒ½ن؟وŒپé«کهڈ¯è¯»و€§ه’Œé«کو€§èƒ½م€‚CQRSçڑ„و ¸ه؟ƒو€وƒ³وک¯ï¼Œن¸€ن¸ھو¨،ه‹ن¸چ适هگˆه¤„çگ†و‰€وœ‰çڑ„ه؛”用程ه؛ڈو“چن½œï¼Œه› و¤ï¼Œوˆ‘ن»¬ه°†ç³»ç»ںهˆ†ن¸؛...
وœ¬و–‡ن»‹ç»چن؛†ه‘½ن»¤وں¥è¯¢èپŒè´£هˆ†ç¦»و¨،ه¼ڈ(CommandQueryResponsibilitySegregation,CQRS),该و¨،ه¼ڈن»ژن¸ڑهٹ،ن¸ٹهˆ†ç¦»ن؟®و”¹(Command,ه¢ï¼Œهˆ ,و”¹ï¼Œن¼ڑه¯¹ç³»ç»ںçٹ¶و€پè؟›è،Œن؟®و”¹)ه’Œوں¥è¯¢ï¼ˆQuery,وں¥ï¼Œن¸چن¼ڑه¯¹ç³»ç»ںçٹ¶و€پè؟›è،Œن؟®و”¹)çڑ„è،Œن¸؛م€‚...
CQRS(Command Query Responsibility Segregation,ه‘½ن»¤وں¥è¯¢èپŒè´£هˆ†ç¦»ï¼‰وک¯ن¸€ç§چ软ن»¶è®¾è®،و¨،ه¼ڈ,ه®ƒه°†ه؛”用程ه؛ڈçڑ„读ه†™و“چن½œهˆ†ç¦»ï¼Œن½؟ه¾—ç³»ç»ںهڈ¯ن»¥هˆ†هˆ«ه¯¹وں¥è¯¢ه’Œه‘½ن»¤è؟›è،Œن¼کهŒ–م€‚CQRSو¨،ه¼ڈو؛گè‡ھErich Gammaم€پRichard Helmم€پRalph ...