
参考:http://www.linkwan.com/gb/tech/htm/1310.htm
显卡的发展可以说是非常的快,人们对于视觉化上的要求也越来越高,随着用户对于图像处理上面的要求不断超出处理器的计算能力。另一方面CPU处理能力也不断强大,但在进入3D时代后,人们发现庞大的3D图像处理数据计算使得CPU越来越不堪重荷,并且远远超出其计算能力。图形计算需求日益增多,作为计算机的显示芯片也飞速发展。随后人们发现显示芯片的计算能力也无法满足快速增长的图形计算需求时,图形,图像计算等计算的功能被脱离出来单独成为一块芯片设计,这就是现在的图形计算处理器——GPU(Graphics Processing Unit),也就是显卡。
1999年8月,NVIDIA终于正式发表了具有跨世纪意义的产品NV10——GeForce 256。GeForce256是业界第一款256bit的GPU,也是全球第一个集成T&L(几何加速/转换)、动态光影、三角形设置/剪辑和四像素渲染等3D加速功能的图形引擎。通过T&L技术,显卡不再是简单像素填充机以及多边形生成器,它还将参与图形的几何计算从而将CPU从繁重的3D管道几何运算中解放出来。在这代产品中,NVIDIA推出了两个全新的名词——GPU以GeForce。所以从某种意义上说,GeForce 256开创了一个全新的3D图形时代,NVIDIA终于从追随者走向了领导者。再到后来GeForce 3开始引出可编程特性,能将图形硬件的流水线作为流处理器来解释,基于GPU的通用计算也开始出现。
到了Nvidia GeForce6800这一代GPU,功能相对以前更加丰富、灵活。顶点程序可以直接访问纹理,支持动态分支;象素着色器开始支持分支操作,包括循环和子函数调用,TMU支持64位浮点纹理的过滤和混合,ROP(象素输出单元)支持MRT(多目标渲染)等。象素和顶点可编程性得到了大大的扩展,访问方式更为灵活,这些对于通用计算而言更是重要突破。
真正意义的变革,是G80的出现,真正的改变随着DX10到来发生质的改变,基于DX10统一渲染架构下,显卡已经抛弃了以前传统的渲染管线,取而代之的是统一流处理器,除了用作图像渲染外,流处理器自身有着强大的运算能力。我们知道CPU主要采用串行的计算方式,由于串行运算的局限性,CPU也正在向并行计算发展,比如目前主流的双核、四核CPU,如果我们把这个概念放到现在的GPU身上,核心的一个流处理相当于一个“核”,GPU的“核”数量已经不再停留在单位数,而是几十甚至是上百个。下面看看G80的架构图:
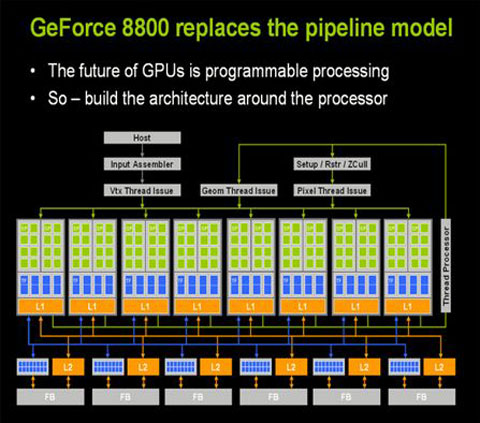
步入DX10时代,shader(流处理器)单元数量成为衡量显卡级别的重要参数之一
G80中拥有128个单独的ALU,因此非常适合并行计算,而且数值计算的速度远远优于CPU。
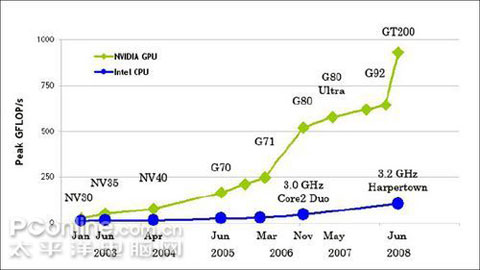
GPU运算能力越来越快,甚至超越CPU
早期的3D游戏,显卡只是为屏幕上显示像素提供一个缓存,所有的图形处理都是由CPU单独完成。图形渲染适合并行处理,擅长于执行串行工作的CPU实际上难以胜任这项任务。直到1995年,PC机领域第一款GPU 3dfx Voodoo出来以后,游戏的速度、画质才取得了一个飞跃。GPU的功能更新很迅速,平均每一年多便有新一代的GPU诞生,运算速度也越来越快。
综上所述,GPU并行处理的理论性能要远高于CPU。同时,我们也可以通过上面这组NVIDIA统计的近两年来GPU与CPU之间浮点运算能力提升对比表格来看一下。
Intel Core2Due G80 Chip 运算能力比较
24 GFLOPS 520 GFLOPS GPU快21.6倍
虽然我们看到CPU和GPU在运算能力上面的巨大差距,但是我们要看看他们设计之初所负责的工作。CPU设计之初所负责的是如何把一条一条的数据处理玩,CPU的内部结构可以分为控制单元、逻辑单元和存储单元三大部分,三个部分相互协调,便可以进行分析,判断、运算并控制计算机各部分协调工作。其中运算器主要完成各种算术运算(如加、减、乘、除)和逻辑运算( 如逻辑加、逻辑乘和非运算); 而控制器不具有运算功能,它只是读取各种指令,并对指令进行分析,作出相应的控制。通常,在CPU中还有若干个寄存器,它们可直接参与运算并存放运算的中间结果。CPU的工作原理就像一个工厂对产品的加工过程:进入工厂的原料(程序指令),经过物资分配部门(控制单元)的调度分配,被送往生产线(逻辑运算单元),生产出成品(处理后的数据)后,再存储在仓库(存储单元)中,最后等着拿到市场上去卖(交由应用程序使用)。在这个过程中,从控制单元开始,CPU就开始了正式的工作,中间的过程是通过逻辑运算单元来进行运算处理,交到存储单元代表工作的结束。数据从输入设备流经内存,等待CPU的处理。
而GPU却从最初的设计就能够执行并行指令,从一个GPU核心收到一组多边形数据,到完成所有处理并输出图像可以做到完全独立。由于最初GPU就采用了大量的执行单元,这些执行单元可以轻松的加载并行处理,而不像CPU那样的单线程处理。另外,现代的GPU也可以在每个指令周期执行更多的单一指令。例如,在某些特定环境下,Tesla架构可以同时执行MAD+MUL or MAD+SFU。
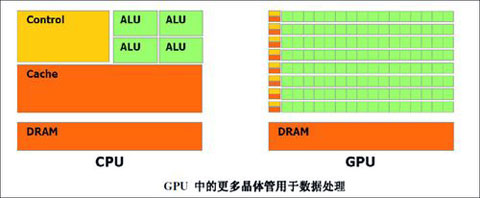
CPU和GPU的架构区别
可以看到GPU越来越强大,GPU为显示图像做了优化之外,在计算上已经超越了通用的CPU。如此强大的芯片如果只是作为显卡就太浪费了,因此NVidia推出CUDA,让显卡可以用于图像计算以外的目的,也就是超于游戏,使得GPU能够发挥其强大的运算能力。
N年前NVIDIA发布CUDA,这是一种专门针对GPU的C语言开发工具。与以往采用图形API接口指挥GPU完成各种运算处理功能不同,CUDA的出现使研究人员和工程师可以在熟悉的C语言环境下,自由地输入代码调用GPU的并行处理架构。这使得原先需要花费数天数周才能出结果的运算大大缩短到数几小时,甚至几分钟之内。
CUDA是用于GPU计算的开发环境,它是一个全新的软硬件架构,可以将GPU视为一个并行数据计算的设备,对所进行的计算进行分配和管理。在CUDA的架构中,这些计算不再像过去所谓的GPGPU架构那样必须将计算映射到图形API(OpenGL和Direct 3D)中,因此对于开发者来说,CUDA的开发门槛大大降低了。CUDA的GPU编程语言基于标准的C语言,因此任何有C语言基础的用户都很容易地开发CUDA的应用程序。
那么,如何使得CPU与GPU之间很好的进行程序之间的衔接呢?以GPGPU的概念来看,显卡仍然需要以传统的DirectX和OpenGL这样的API来实现,对于编程人员来说,这样的方法非常繁琐,而CUDA正是以GPGPU这个概念衍生而来的新的应用程序接口,不过CUDA则提供了一个更加简便的方案——C语言。
欢迎关注微信公众号——计算机视觉




相关推荐
CPU与GPU在并行运算上游很大区别,CPU和GPU之所以大不相同,是由于其设计目标的不同,它们分别针对了两种不同的应用场景。CPU需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和...
CPU和GPU的主要区别在于: 1. **设计目标**:CPU面向通用计算,强调逻辑控制和数据处理的灵活性;GPU专注于图形和并行计算,优化处理大量相同任务。 2. **核心数量与缓存**:CPU的核心数较少,每个核心具有较大缓存...
本项目旨在探讨和比较CPU与GPU在处理图片任务上的性能差异,特别地,通过C++编程语言并利用CUDA(Compute Unified Device Architecture)库来实现这一目标。CUDA是NVIDIA公司开发的一种并行计算平台,它允许程序员...
这是个关于GPU+CPU集群简介。介绍了我们实验室基于开源软件搭建的一个GPU+CPU集群架构
GPU 作用的原理、与 CPU、DSP 的区别 GPU(图形处理单元)是显示卡的心脏,也就相当于 CPU 在电脑中的作用,它决定了该显卡的档次和大部分性能,同时也是 2D 显示卡和 3D 显示卡的区别依据。GPU 使显卡减少了对 CPU...
基于CNN的Matlab图像分类教学示例:猫狗大战数据集训练与测试,包含GPU与CPU版本,基于CNN的Matlab图像分类:猫狗大战数据集4000样本训练与测试,含GPU与CPU版本,Matlab使用CNN卷积神经网络进行图像分类,使用了猫狗...
LabVIEW Paddle OCR:ONNXRuntime高效推理封装与调用,源码支持GPU&CPU高速运算,LabVIEW Paddle OCR:快速、跨平台、高效的推理工具,支持GPU和CPU的封装DLL与源码库函数详解,labview paddle ocr识别onnxruntime推理...
在IT领域,对系统资源的监控是至关重要的,特别是对于CPU和GPU这两个关键硬件组件的监控。"CPUGPU监控工具"就是专为此目的设计的软件,它能够定期收集并记录CPU和GPU的相关信息,帮助用户了解系统的运行状态,及时...
CPU与GPU对比 显卡:GTX 1066 CPU GPU 简单测试:GPU比CPU快5秒 补充知识:tensorflow使用CPU可以跑(运行),但是使用GPU却不能用的情况 在跑的时候可以让加些选项: with tf.Session(config=tf.ConfigProto...
Cpu-Z 是一款计算机的CPU检测软件。Cpu-Z适用于任意品牌和型号的监测工作,且检测的数据范围非常广泛、全面,将CPU涉及到的各个方面都...CPU & GPU检测工具,Cpu-Z CPU检测软件,GPU-Z 看清显卡的各项参数 GPU识别工具
《GPU与CPU的比较分析》 GPU(Graphics Processing Unit)与CPU(Central Processing Unit)是计算机硬件中的两个关键组件,各自承担着不同的计算任务。CPU是计算机的核心,负责执行各种通用计算任务,如操作系统...
【云计算-基于GPU与CPU协同计算的实时视频拼接技术研究】 本文主要探讨了在云计算环境中,如何利用GPU(Graphics Processing Unit)与CPU(Central Processing Unit)协同计算来实现视频拼接技术,尤其是在实时视频...
【标题】和【描述】提到的是一个关于“基于GPU与CPU协作的实时波束形成实现方法”的研究论文。这篇论文探讨了一种利用GPU(图形处理器)与CPU(中央处理器)协同工作的技术,用于实现宽带波束形成处理的实时化。 ...
本文探讨了GPU与CPU协同并行计算在地震资料处理中的应用,旨在提高计算效率,解决算法精度和计算速度之间的平衡问题。 GPU(Graphics Processing Unit)最初设计用于图形渲染,但其强大的并行计算能力使其在科学...
【GPU-CPU协作计算模式的应用研究】 随着计算机技术的飞速发展,高性能计算的需求日益增长,GPU(图形处理器)和CPU(中央处理器)的协作计算模式成为了解决复杂计算问题的有效途径。本文主要探讨了GPU-CPU协作计算...
- **加速比计算**:采用适当的加速比计算公式,如Amdahl定律,来评估多核CPU与GPU组合所带来的性能提升。 #### 多GPU的支持 随着计算需求的增长,单个GPU可能无法满足高性能计算的需求。在这种情况下,支持多GPU...
1. **单节点内CPU与GPU协同**:这一场景主要关注如何在单一计算节点内优化CPU和GPU之间的数据传输和计算负载分配,以实现最佳的并行效率。例如,通过智能调度策略和优化的内存管理技术,确保GPU在执行计算密集型任务...
这些命令和接口对于系统调优人员来说非常有用,他们可以根据系统需求调整CPU和GPU的工作状态,从而达到性能与功耗的平衡。此外,监控温度也是确保设备稳定运行的关键,因为过高温度可能导致设备自动降频或关机,甚至...