IPv4Õ«×ķÖģõĖŖµś»õĖĆõĖ¬Ķó½Ķ«ŠĶ«ĪńÜäÕŠłÕŗēÕ╝║ńÜäÕŹÅĶ««’╝īĶ┐£Ķ┐£µ▓Īµ£ēTCPńŁēõ╝ĀĶŠōÕ▒éÕŹÅĶ««Ķ«ŠĶ«ĪńÜäÕźĮŃĆéÕ»╣õ║ÄÕ«āńÜäÕŹćń║¦ńēł’╝īIPv6’╝īÕ«×ķÖģõĖŖµłæõ╣¤õĖƵĀĘõĖŹń£ŗÕźĮ’╝īĶÖĮńäČÕ«āĶ¦ŻÕå│õ║åÕŠłÕżÜķŚ«ķóś’╝īµē®Õ▒Ģõ║åÕ£░ÕØĆń®║ķŚ┤’╝īÕó×ÕŖĀõ║åÕŹÅĶ««ÕĀåµĀłÕī¢ńÜäµö»µīü...
1.Õ£░ÕØĆń®║ķŚ┤ÕÆīĶĘ»ńö▒µ©ĪÕØŚ
Õ»╣õ║ÄIPv4ĶĆīĶ©Ć’╝īÕģČĶĄĘÕłØńÜäÕ£░ÕØĆń®║ķŚ┤µś»Õłåń▒╗ńÜä’╝īµŁżµŚČńÜäĶĘ»ńö▒ĶĪ©ÕøĀµŁżõ╣¤µś»Õłåń▒╗ńÜä’╝īµ£ĆµśŠńäČńÜäķ½śµĢłńÄćÕ«×ńÄ░µ¢╣Õ╝ÅÕ░▒µś»µ»ÅõĖĆń▒╗Õł½õĖĆÕ╝ĀĶĪ©’╝īĶĘ»ńö▒ÕÖ©ķ£ĆĶ”üÕ£©µ¤źĶĪ©ķĆ╗ĶŠæõ╣ŗÕēŹµ£ēõĖĆõĖ¬Õłåń▒╗ÕÖ©µØźÕ░åIPµĢ░µŹ«µŖźńÜäńø«ńÜäÕ£░ÕØĆÕłåń▒╗’╝īńäČÕÉĵĀ╣µŹ«Õłåń▒╗ń╗ōµ×£µØźµ¤źµēŠńøĖÕ║öńÜäĶĘ»ńö▒ĶĪ©ŃĆé
µŁżÕÉÄ’╝īIPÕ£░ÕØĆÕÅłÕÅ»õ╗źÕłÆÕłåÕŁÉńĮæõ║å’╝īÕÉīµŚČÕÅłµ£ēõ║åĶČģńĮæõĖĆĶ»┤’╝īńäČÕÉÄÕ░▒µś»ĶĘ»ńö▒µ▒ćĶüÜ’╝īµēƵ£ēĶ┐ÖõĖĆÕłćķāĮķ£ĆĶ”üÕ¤║õ║ÄÕłåń▒╗ńÜäĶĘ»ńö▒ĶĪ©ķĪ╣ńö¤µłÉń«Śµ│Ģõ╗źÕÅŖµ¤źµēŠń«Śµ│ĢõĮ£ńøĖÕ║öńÜäõ┐«µö╣ŃĆéCiscońÜäĶĘ»ńö▒ÕÖ©Õ░▒µö»µīüõĖżń¦ŹķĆ╗ĶŠæ’╝īõĖĆń¦Źµś»Õłåń▒╗ńÜä’╝īÕÅ”õĖĆõĖ¬µś»µŚĀń▒╗ńÜäŃĆé
ń╗łõ║Ä’╝īCIDRÕć║ńÄ░õ║å’╝īĶĘ»ńö▒µ¤źµēŠń«Śµ│Ģõ╣¤ńøĖÕ║öńÜäÕÅśµłÉõ║åŌĆ£µ£ĆķĢ┐ÕēŹń╝ĆÕī╣ķģŹń«Śµ│ĢŌĆØ’╝īĶ┐Öń¦Źń«Śµ│Ģń╗¤õĖĆõ║åµēƵ£ēńÜäĶĘ»ńö▒µ¤źµēŠń«Śµ│Ģ’╝īÕ┐ģĶ”üµŚČõŠ»õ╣¤ÕÅ»õ╗źķĆĆÕī¢Õł░Õģ╝Õ«╣Õłåń▒╗ĶĘ»ńö▒ńÜäń©ŗÕ║”ŃĆéĶĘ»ńö▒µ©ĪÕØŚÕ”éõĮĢÕ«×ńÄ░õĖŹķćŹĶ”ü’╝īķćŹĶ”üńÜ䵜»õĮĀµś»µŖŖIPÕ£░ÕØĆÕĮōµłÉõĖĆõĖ¬Õ╣│ÕØ”ńÜäń®║ķŚ┤ń£ŗÕæó’╝īĶ┐śµś»Õ░åÕ«āń£ŗµłÉõĖĆõĖ¬Õłåń║¦ńÜäÕ£░ÕØĆń®║ķŚ┤Õæó’╝¤õĖŠõĖ¬õŠŗÕŁÉÕɦ’╝ī32õĮŹń│╗ń╗¤õĖŁńÜäÕåģÕŁśÕ£░ÕØĆõ╣¤µś»32õĮŹ’╝īÕÆīIPÕ£░ÕØĆõĖƵĀĘ’╝īµłæõ╗¼ń£ŗÕł░ÕżäńÉåÕÖ©ÕÆīõĖ╗µØ┐ĶŖ»ńēćń╗äõĖŁÕŁśÕ£©ķéŻõ╣łÕżÜń▓ŠÕʦńÜäÕ░ÅĶŖ»ńēć’╝īÕ«āõ╗¼ń▓ŠÕʦńÜäķĆ╗ĶŠæµŁŻµś»Õ£©ÕżäńÉåĶĘ»ńö▒ÕÆīÕ£░ÕØĆÕÅśµŹó’╝īµŁŻµś»Õ«āõ╗¼Ķ«®ÕģāÕÖ©õ╗Čõ╣ŗķŚ┤õ╗źÕÅŖÕģČõĖÄÕż¢Ķ«Šõ╣ŗķŚ┤ńÜäŌĆ£ń╗ØÕ”Öõ║ÆĶüöŌĆصłÉõĖ║ÕÅ»ĶāĮ’╝īńäČĶĆīĶ┐Öń¦Źń▓ŠÕ”ÖńÜäķĆ╗ĶŠæÕ╣ČõĖŹµś»ńø┤µÄźĶó½Ķ«ŠĶ«ĪÕć║µØźńÜä’╝īĶĆīµś»Õ£©µ£ēõ║åÕłåń║¦ńÜäÕ£░ÕØĆń®║ķŚ┤õ╣ŗÕÉĵēŹĶ«ŠĶ«ĪńÜäŃĆéķĪĄĶĪ©õ╣ŗń▒╗ńÜäÕżäńÉåķĆ╗ĶŠæµŁŻµś»ÕüÜĶ┐ÖõĖ¬ńÜäŃĆé
Õ”éµ×£õĮĀõĖŹÕ»╣Õ£░ÕØĆõĮ£Ķ¦äÕłÆ’╝īĶĆīÕŬµś»Õ░åÕģČõĮ£õĖ║õĖĆõĖ¬Õ╣│ÕØ”ńÜäõĖĆń╗┤ń®║ķŚ┤ń£ŗÕŠģńÜäĶ»Ø’╝īÕ«āµĀćńż║ńÜäõĖ£Ķź┐µŚ®µÖÜõ╝ÜõĖŹÕÅ»µÄ¦ŃĆéÕÅ”Õż¢Õ░▒µś»Õ”éõĮĢÕłåń║¦ńÜäķŚ«ķóś’╝īĶĄĘÕłØIPÕ£░ÕØĆĶó½ÕłåµłÉõ║å5õĖ¬ń▒╗Õł½’╝īĶ┐Öµś»õĖĆń¦ŹÕø║Õ«ÜńÜäÕłåń║¦µ¢╣Õ╝Å’╝īĶĆīÕ”éõ╗ŖńÜäCIDRÕłÖµś»õĖĆń¦Źµø┤ÕŖĀÕŖ©µĆüńÜäÕłåń║¦µ¢╣Õ╝Å’╝īõ║īĶĆģńøĖµ»öÕÉäµ£ēÕŹāń¦ŗ’╝īõ╝░Ķ«Īµ│ĢÕ«×ńÄ░ń«ĆÕŹĢ’╝īµĢłńÄćķ½ś’╝īõĮåµś»ń«ĪńÉåõĖŹõŠ┐’╝īÕŖ©µĆüµ│ĢÕłÖµø┤Õ«╣µśōµ╗ĪĶČ│ÕŖ©µĆüńÜäķ£Ćµ▒éŃĆéÕ”éµ×£µłæõ╗¼ń£ŗĶĘ»ńö▒µ¤źµēŠńÜäÕ«×ńÄ░ń«Śµ│Ģ’╝īCiscońÜä256ÕÅēµĀæµś»õĖĆń¦ŹÕø║Õ«ÜńÜäń«Śµ│Ģ’╝īĶĆīLinuxńÜäTrieµĀæÕłÖµś»ÕŖ©µĆüńÜäń«Śµ│ĢŃĆé
Õ”éõĖ╗µØ┐ĶŖ»ńēćń╗äĶ¦äÕłÆõĖƵĀĘ’╝īIPÕ£░ÕØĆĶ¦äÕłÆńÜäÕźĮÕØÅõ╣¤õ╝ÜÕĮ▒ÕōŹÕł░ŌĆ£õĖ¢ńĢīõ║ÆĶüöńĮæŌĆØĶ┐ÖÕØŚÕż¦õĖ╗µØ┐ńÜäĶ«ŠĶ«ĪŃĆéõ╗Ćõ╣łõ║ŗõĖƵŚ”µ£ēõ║║ÕÅéõĖÄÕ░▒ÕżŹµØéõ║å’╝īµłæõ╗¼õĖŹõ╝ÜĶĪīĶĄ░õ║ĵĢŻńāŁńēćõ╣ŗķŚ┤’╝īńäČĶĆīµłæõ╗¼ÕŹ┤µ»ÅÕż®ķāĮÕ£©µĢ▓Õć╗ńØĆķö«ńøśŃĆé
2.Õłåń╗äõ║żµŹó
IPÕŹÅĶ««µś»Õłåń╗äõ║żµŹóńÜäµĀĖÕ┐āÕŹÅĶ««’╝īµś»µ▓Öµ╝ÅńÜäõĖŁÕ┐āŃĆéÕøĀµŁżÕ«āĶó½Ķ«ŠĶ«ĪµłÉõ║åµ£Ćń«ĆÕŹĢńÜ䵌ĀĶ┐×µÄźÕŹÅĶ««ŃĆéÕÅ»µś»µü░µü░Õ£©µĀĖÕ┐āńĮæõĖŖ’╝īµŁŻµ£ēõĖĆĶéĪÕŖ┐ÕŖøÕüÅń”╗õ║åIPÕŹÅĶ««ńÜäÕłØĶĪĘ’╝īĶ┐ÖÕ░▒µś»Õ¤║õ║ĵĀćńŁŠńÜäÕŹÅĶ««’╝īµ»öÕ”éMPLSŃĆéMPLSÕ«×ķÖģõĖŖµś»õĖĆõĖ¬µ£ēĶ┐׵ğńÜäÕŹÅĶ««’╝īÕŬõĖŹĶ┐ćĶ┐ÖõĖ¬Ķ┐׵ğõĖŹµś»Õ╗║ń½ŗÕ£©ń½»Õł░ń½»ńÜä’╝īĶĆīµś»Õłåń╗äõ║żµŹóµäÅõ╣ēõĖŖńÜä’╝īÕ░åŌĆ£Õ¤║õ║ÄõĖŗõĖĆĶĘ│µ¤źµēŠńÜäĶĘ»ńö▒ŌĆØÕÅśµłÉõ║åŌĆ£Õ¤║õ║ĵĀćńŁŠńÜäõ║żµŹóĶĘ»ńö▒ŌĆØ’╝īĶ┐ÖµśÄµśŠÕó×ÕŖĀõ║åµĢłńÄćŃĆé
õ╗źÕŠĆMPLSõ╣ŗń▒╗ńÜäÕŹÅĶ««Õć║µØźõ╗źÕēŹ’╝īÕŹ│õĮ┐µś»CiscoĶ┐Öń▒╗ÕĘ©Õż┤õ╣¤ÕŬµś»õĮ┐ńö©CEFõ╣ŗń▒╗ńÜäµŖƵ£»µØźÕŖĀķƤĶĮ¼ÕÅæ’╝īµ▓Īµ£ēµśÄĶ»┤’╝īńäČĶĆīCEFÕ«×ÕłÖÕ░▒µś»õĖĆń¦Źõ║żµŹóµŖƵ£»’╝īÕ£©CEFõ╣ŗÕēŹ’╝īõĮ┐ńö©ńÜäCacheõ╣ŗń▒╗ńÜäÕŖĀķƤµŖƵ£»ŃĆéCEFÕ░åĶĘ»ńö▒ÕÆīĶĮ¼ÕÅæõ║żµŹóńøĖÕłåń”╗’╝īõĖŹÕåŹõĖ║µĢ░µŹ«ÕīģÕåŹÕÄ╗µ¤źµēŠĶĘ»ńö▒ĶĪ©’╝īĶĆīµś»ÕģłµĀ╣µŹ«ĶĘ»ńö▒ĶĪ©ńö¤µłÉõĖĆÕ╝ĀŌĆ£ĶĮ¼ÕÅæĶĪ©ŌĆØ’╝īńäČÕÉĵĢ░µŹ«ÕīģķĆÜĶ┐ćŌĆ£õ║żµŹóµŖƵ£»ŌĆØńø┤µÄźµĀ╣µŹ«ĶĮ¼ÕÅæĶĪ©µØźĶó½ÕÅæķĆüÕł░ÕÉłķĆéńÜäķōŠĶĘ»ŃĆéĶ┐ÖÕ╝ĀĶĮ¼ÕÅæĶĪ©µś»Õ”éõĮĢÕ╗║ń½ŗńÜäÕæó’╝¤Õ«×ķÖģõĖŖµś»ŌĆ£ķ╗śķ╗śÕ£░ŌĆØÕ╗║ń½ŗńÜä’╝īń│╗ń╗¤Õ£©µ▓Īµ£ēÕīģĶ”üÕÅæķĆüńÜ䵌ČÕĆÖ’╝īķ╗śķ╗śÕ£░ķĆÜĶ┐ćARPÕŠŚÕł░µ»ÅõĖƵØĪĶĘ»ńö▒õĖŗõĖĆĶĘ│ńÜäķōŠĶĘ»Õ▒éÕ£░ÕØĆ’╝īńäČÕÉĵ×äÕ╗║ĶĮ¼ÕÅæĶĪ©...
MPLSÕŬµś»µø┤ÕŖĀķĆ╗ĶŠæÕī¢ńÜäCEF’╝īÕ«āõ╣¤µś»ķ╗śķ╗śÕ£░Õ╗║ń½ŗĶĄĘµĀćńŁŠ-ń½»ÕÅŻµśĀÕ░äĶĪ©’╝īķĆÜĶ┐ćµĀćńŁŠõ║żµŹóÕŹÅĶ««ÕÅ»õ╗źÕŠłÕ«╣µśōÕüÜÕł░ŃĆéńäČÕÉÄÕ£©IPµĢ░µŹ«µŖźńÜäÕż¢ĶĪ©µēōõĖŖµĀćńŁŠ’╝īµ»ÅõĖĆõĖ¬ŌĆ£MPLSõ║żµŹóµ£║ŌĆØÕ¤║õ║ĵĀćńŁŠĶ┐øĶĪīÕ┐½ķƤõ║żµŹó’╝īÕ£©µŚĀĶ┐׵ğńÜäIPÕŹÅĶ««Õż¢ķØóķ╗śķ╗śµ×äÕ╗║õ║åõĖƵØĪĶÖܵŗ¤ńÜäµĀćńŁŠķĆÜķüō’╝īÕ╣ČõĖöõĖ║õ║åĶāĮĶĪ©ńÄ░IPÕ£░ÕØĆÕłåń║¦ńÜäķĆ╗ĶŠæ’╝īµĀćńŁŠÕÅ»õ╗źÕĄīÕźŚ’╝īµĀ╣µŹ«µĀćńŁŠÕ▒éµ¼ĪńÜäõĖŹÕÉī’╝īµłæõ╗¼õ╣¤Õ░▒ĶāĮµśĀÕ░äÕł░µ»ÅõĖĆÕ▒éµĀćńŁŠµēĆõ╗ŻĶĪ©ńÜäIPÕ£░ÕØĆń║¦Õł½ŃĆéÕĀåµĀłÕī¢ńÜäµĀćńŁŠÕŹÅĶ««µēĆĶ”üĶĪ©ĶŠŠńÜ䵣ŻÕ”éCIDRõĖŁńÜäÕēŹń╝Ć(prefix’╝īµÄ®ńĀü)µēĆĶ”üĶĪ©ĶŠŠńÜäµäŵĆØõĖƵĀĘŃĆé
3.IPv4ÕŹÅĶ««Õż┤õĖŁńÜäIdentificationÕŁŚµ«Ą
IPv4Õż┤õĖŁµ£ēõĖĆõĖ¬IdentificationÕŁŚµ«Ą’╝īÕ«āÕÅ»õ║åõĖŹÕŠŚÕĢŖ’╝īÕģ│õ║ÄÕ«āńÜäĶ«©Ķ«║ÕÅ»Ķ░ōÕżÜń¤ŻŃĆéńäČĶĆīÕ«āÕŹ┤ÕŬõĖŹĶ┐ćÕÆīÕłåńēćķćŹń╗äµ£ēÕģ│ń│╗(ÕÅ»ĶāĮĶ┐śÕÆīÕÄŗń╝®µ£ēÕģ│)’╝īÕ”éµ×£µ▓Īµ£ēÕłåµ«ĄķćŹń╗ä’╝īµłæõ╗¼Õ«īÕģ©ÕÅ»õ╗źµÆćµÄēĶ┐ÖõĖ¬ÕŁŚµ«ĄŃĆéÕ«āńÜäÕŁśÕ£©Õ░▒µś»õĖ║õ║åµĀćńż║Õ▒×õ║ÄÕÉīõĖĆõĖ¬IPµĢ░µŹ«µŖźńÜäIPÕłåńēćŃĆé
IdentificationÕŬµ£ē16õĮŹ’╝īÕøĀµŁżÕŬĶāĮÕ£©65535’╝īĶ┐ÖÕ£©Õ┐½ķƤńĮæń╗£õĖŖÕŠłÕ┐½Õ░▒õ╝ÜÕø×ń╗Ģ’╝īõĖ║õ║åÕŹÅĶ««ńÜäń┤¦Õćæ’╝īĶ»źÕŁŚµ«ĄÕÅłõĖŹĶāĮÕż¬Õż¦’╝īÕøĀµŁżÕ░▒Õ«ÜÕ£©õ║å16õĮŹŃĆéĶć│õ║ÄÕ”éõĮĢķś▓µŁóÕø×ń╗Ģ’╝īRFC791Õ╣ȵ▓Īµ£ēń╗åĶ»┤’╝Ü
Identification
The choice of the Identifier for a datagram is based on the need to
provide a way to uniquely identify the fragments of a particular
datagram. The protocol module assembling fragments judges fragments
to belong to the same datagram if they have the same source,
destination, protocol, and Identifier. Thus, the sender must choose
the Identifier to be unique for this source, destination pair and
protocol for the time the datagram (or any fragment of it) could be
alive in the internet.
It seems then that a sending protocol module needs to keep a table
of Identifiers, one entry for each destination it has communicated
with in the last maximum packet lifetime for the internet.
However, since the Identifier field allows 65,536 different values,
some host may be able to simply use unique identifiers independent
of destination.
It is appropriate for some higher level protocols to choose the
identifier. For example, TCP protocol modules may retransmit an
identical TCP segment, and the probability for correct reception
would be enhanced if the retransmission carried the same identifier
as the original transmission since fragments of either datagram
could be used to construct a correct TCP segment.Õ«×ķÖģõĖŖ’╝īõĮ┐ńö©õĖĆõĖ¬ÕŁŚµ«ĄµŚĀµ│ĢµĀćńż║ŌĆ£Õö»õĖƵƦŌĆØ’╝īķéŻÕ░▒õĮ┐ńö©ÕżÜõĖ¬ÕŁŚµ«Ą’╝īõ║ĵś»µ║ÉÕ£░ÕØĆ’╝īńø«ńÜäÕ£░ÕØĆ’╝īÕŹÅĶ««ķāĮńö©õĖŖõ║å(ńö▒õ║ÄIPÕŹÅĶ««ÕŬĶāĮµÄ¦ÕłČÕł░Õ«āĶć¬ÕĘ▒ńÜäÕŁŚµ«Ą’╝īÕøĀµŁżõĖŹĶāĮÕüćÕ«Üõ╗╗õĮĢńī£µĄŗ’╝īµēĆõ╗źÕ░▒õĖŹĶāĮõĮ┐ńö©5Õģāń┤Āõ║å’╝īµ»Ģń½¤ÕāÅÕŠłÕżÜÕŹÅĶ««µ▓Īµ£ēń½»ÕÅŻńÜäµ”éÕ┐Ą)ŃĆéĶ┐ÖõĖŗÕÅ»õ╗źõ║å’╝īÕ¤║µ£¼õĖŹõ╝ÜÕø×ń╗Ģõ║å’╝īÕ£©LinuxńÜäÕ«×ńÄ░õĖŖ’╝īķÆłÕ»╣µ»ÅõĖĆõĖ¬ńø«ńÜäÕ£░’╝īķāĮń╗æÕ«Üõ║åõĖĆõĖ¬peerÕŁŚµ«Ą’╝īÕģČIDÕ£©peerń╗ōµ×äõĮōõĖŁ’╝īõ╣¤Õ░▒µś»Ķ»┤’╝īLinuxÕ«×ńÄ░ńÜ䵜»ķÆłÕ»╣µ»ÅõĖĆõĖ¬ńø«ńÜäÕ£░ńÜäIdentification’╝īĶĆīõĖŹµś»Õģ©Õ▒ĆńÜäŃĆéÕ»╣õ║ÄŌĆ£õĖŹĶāĮÕłåµ«ĄŌĆØńÜäIPµĢ░µŹ«µŖź’╝īÕ░▒µŚĀµēĆĶ░ōõ║å’╝īÕ░▒ń«ŚķćŹÕżŹõ║åõ╣¤µŚĀµēĆĶ░ōŃĆé
RFCõĖŁĶ┐śĶ»┤õ║å’╝īÕ╗║Ķ««Ķ«®ķ½śÕ▒éÕŹÅĶ««ÕÄ╗ń╗┤µŖżĶ┐ÖõĖ¬IdentificationÕŁŚµ«Ą’╝īõĖŹĶ┐ćĶ┐ÖµĀĘÕÅ»ĶāĮõ╝ÜÕĖ”µØźÕŠłÕżÜń½×µĆü’╝īõĖŹÕł®õ║ÄÕżÜÕżäńÉåÕÖ©Õ╣ČĶĪīŃĆé
ķÖżµŁżõ╣ŗÕż¢’╝īIPÕłåµ«ĄńÜäIdentificationĶ┐śõ╝ÜĶó½NATĶ«ŠÕżćÕå▓ÕłĘµÄē’╝īõĮ┐ÕŠŚµĢ░µŹ«ÕłåńēćÕł░ĶŠŠńø«ńÜäÕ£░ńÜ䵌ČÕĆÖķćŹń╗äÕż▒Ķ┤źŃĆéRFCÕŬµś»Ķ»┤Identificationńö▒ÕÉäõĖ¬õĖ╗µ£║ÕłåÕł½Ķć¬ĶĪīõ║¦ńö¤’╝īµ▓Īµ£ēµÅÉÕł░õ╗╗õĮĢÕģČõ╗¢ńÜä’╝īÕøĀµŁżµ»öÕ”éĶ»┤ÕåģńĮæõĖżÕÅ░õĖ╗µ£║H1ÕÆīH2ÕÉīµŚČõĮ┐ńö©httpń╗Åńö▒SNATÕł░ĶŠŠÕÉīõĖĆÕÅ░ńø«ńÜäÕ£░S1’╝īµü░ÕʦõĖżõĖ¬õĖ╗µ£║ńÜäõĖżõĖ¬Õłåµ«ĄńÜäIdentificationńøĖÕÉī’╝īń®┐ĶČŖSNATĶ«ŠÕżćńÜ䵌ČķŚ┤õ╣¤ńøĖÕĘ«õĖŹõ╣ģ’╝īÕ«āõ╗¼ńÜäµ║ÉÕ£░ÕØĆõ╝ÜĶó½µö╣µłÉńøĖÕÉīńÜäNATĶ«ŠÕżćńÜäÕż¢ńĮæÕÅŻÕ£░ÕØĆ’╝īS1µ£Ćń╗łõ╝ÜĶ«żõĖ║µØźĶć¬H1ÕÆīH2ńÜäÕłåńē浜»ÕÉīõĖĆõĖ¬IPµĢ░µŹ«µŖźńÜäÕłåńēć’╝īÕøĀõĖ║µīēńģ¦RFCńÜäĶ»┤µ│Ģ’╝īÕ«āõ╗¼ńÜäµ║ÉÕ£░ÕØĆ’╝īńø«ńÜäÕ£░ÕØĆ’╝īÕŹÅĶ««’╝īIdentificationÕŁŚµ«ĄÕØćńøĖÕÉī...
4.LinuxńÜäNATÕ«×ńÄ░
LinuxõĖ║õ║åķü┐ÕģŹIPÕłåńēćńÜäNATķŚ«ķóś’╝īÕ«āµś»Ķ┐ÖµĀĘÕ«×ńÄ░ńÜä’╝ÜÕ£©Ķ┐øĶĪīĶ┐׵ğĶ┐ĮĶĖ¬õ╣ŗÕēŹ’╝īõ╝ÜĶ┐øĶĪīÕłåńēćķćŹń╗ä’╝īõ╗ÄĶĆīķü┐ÕģŹõ║åõĖŖĶ┐░ńÜäķŚ«ķóś’╝īńäČĶĆīńē║ńē▓õ║åµĢłńÄćŃĆéĶ¦üõĖŗķØóńÜäHOOKķÆ®ÕŁÉõ╝śÕģłń║¦Õ«Üõ╣ē’╝Ü
enum nf_ip_hook_priorities {
NF_IP_PRI_FIRST = INT_MIN,
NF_IP_PRI_CONNTRACK_DEFRAG = -400,
...
NF_IP_PRI_CONNTRACK = -200,
...
};ÕÅ”õĖĆõĖ¬µ¢╣Õ╝ÅÕ░▒µś»õĖŹõĖ║NATķćŹń╗äÕłåńēć’╝īĶ¦üõĖŗÕøŠ(Ķ»źÕøŠÕ£©õ╣ŗÕēŹńÜäµ¢ćÕŁŚõĖŁńö©Ķ┐ć’╝īńäČĶĆīń¼¼õĖĆõĖ¬YES/NOńö╗ÕÅŹõ║å)’╝Ü
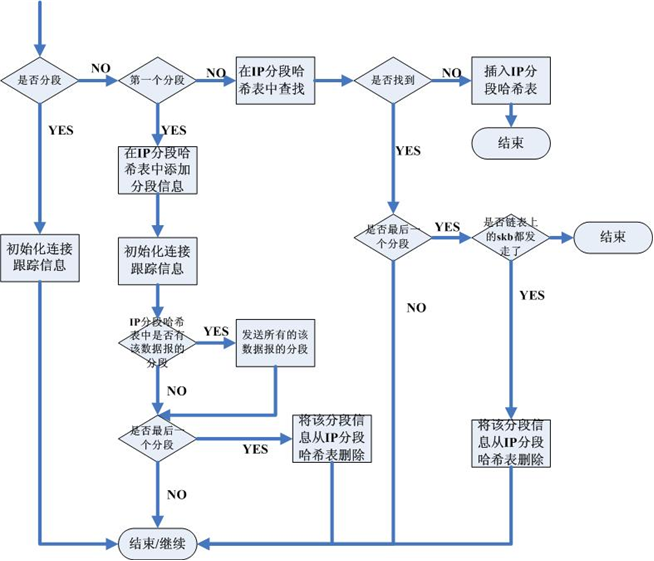
µłæõ╗¼ķ£ĆĶ”üÕ£©ip_conntrackõ╗źÕÅŖÕłåńēćõ┐Īµü»ĶĪ©ķĪ╣õĖŁõ┐ØÕŁśõĖĆõĖ¬NATĶ«ŠÕżćµ¢░ńö¤µłÉńÜäIdentification’╝īÕ”éµ×£Ķ«ŠÕżćÕ»╣µĢ░µŹ«µŖźĶ┐øĶĪīõ║åNAT’╝īķéŻõ╣łÕ░▒Ķ┐×Identificationõ╣¤õĖĆÕ╣ČĶĮ¼µŹóõ║åŃĆéÕ”éõĖŗÕøŠµēĆńż║’╝Ü
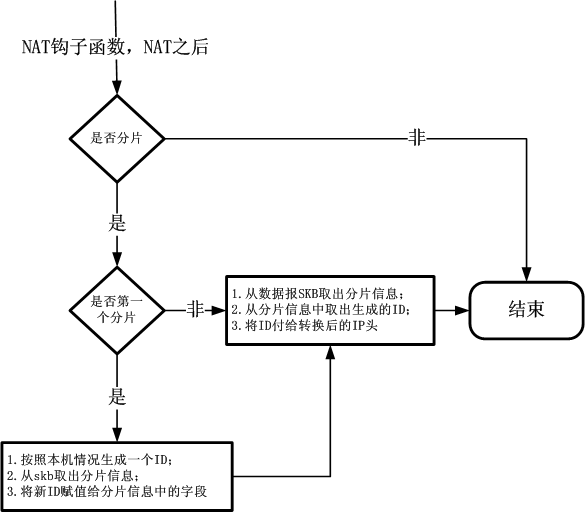
Õłåõ║½Õł░’╝Ü




ńøĖÕģ│µÄ©ĶŹÉ
µ£¼µ¢ćÕ░åĶ»”ń╗åõ╗ŗń╗ŹNAT-PT’╝łNetwork Address Translation-Protocol Translation’╝īķÖäÕĖ”ÕŹÅĶ««ĶĮ¼µŹóńÜäńĮæń╗£Õ£░ÕØĆĶĮ¼µŹó’╝ēµŖƵ£»’╝īĶ»źµŖƵ£»µś»õĖĆń¦ŹĶ¦ŻÕå│IPv4ÕÆīIPv6ńĮæń╗£õ╣ŗķŚ┤ńÜäõ║ÆķĆÜķŚ«ķóśńÜäĶ¦ŻÕå│µ¢╣µĪłŃĆé NAT-PTµ£║ÕłČń«Ćõ╗ŗ NAT-PTµś»õĖĆń¦ŹÕ£░ÕØĆĶĮ¼µŹó...
ŃĆɵĀćķóśŃĆæ’╝ÜŌĆ£IEEE-IPv4-ICMPv4-ARPÕŹÅĶ««ŌĆØõĖ╗Ķ”üµČĄńø¢õ║åńĮæń╗£ķĆÜõ┐ĪõĖŁńÜäÕćĀõĖ¬µĀĖÕ┐āÕŹÅĶ««’╝īÕīģµŗ¼IEEE 802.3ŃĆüIPv4ŃĆüICMPv4ÕÆīARPŃĆé ŃĆɵÅÅĶ┐░ŃĆæ’╝ÜŌĆ£ipv4’╝īIEEE-IPv4-ICMPv4-ARPÕŹÅĶ««ŌĆصīćńÜ䵜»Õ£©IPv4ńĮæń╗£ńÄ»ÕóāõĖŗ’╝īÕ”éõĮĢķģŹńĮ«ÕÆīńÉåĶ¦ŻIEEE ...
6.8.1 Packet Tracer - Configure NAT for IPv4 Cisco Packet Tracer µĆØń¦æµ©Īµŗ¤ÕÖ© µŁŻńĪ«ńŁöµĪłµ¢ćõ╗Č ÕÅ»ńø┤µÄźõĖŖõ║żµŁŻńĪ«ńŁöµĪłµ¢ćõ╗Č µ£¼ńŁöµĪłńēłµØāÕĮÆmewhakuµēƵ£ē’╝īõĖźń”üÕåŹµ¼ĪĶĮ¼ĶĮĮ’╝ü’╝ü’╝ü Copyright @mewhaku 2022 All Rights ...
µĀćńŁŠõĖŁńÜäŌĆ£ipv4__ipv6ŌĆØĶĪ©µśÄõ║åõĖżń¦ŹńĮæń╗£ÕŹÅĶ««’╝īĶĆīŌĆ£linux_nat-ptŌĆØŃĆüŌĆ£linux_ipv6_natptŌĆØŃĆüŌĆ£linux-usermode-natptŌĆØÕÆīŌĆ£nat_ptŌĆØÕłÖµČēÕÅŖÕł░LinuxõĖŗńÜäNAT-PT’╝łńĮæń╗£Õ£░ÕØĆĶĮ¼µŹó-ÕŹÅĶ««ń┐╗Ķ»æ’╝ēµŖƵ£»ÕÆīńö©µłĘµ©ĪÕ╝ÅńÜäÕ«×ńÄ░ŃĆé...
IPv4õĖÄIPv6õĖÜÕŖĪ-NAT-PTµŖƵ£»õ╗ŗń╗Ź-D.docx
1. **IPv4Õ£░ÕØĆķ¬īĶ»ü**’╝Üipv4helperÕÅ»ĶāĮµÅÉõŠøÕćĮµĢ░µØźµŻĆµ¤źÕŁŚń¼”õĖ▓µś»ÕÉ”µś»µ£ēµĢłńÜäIPv4Õ£░ÕØĆ’╝īńĪ«õ┐ØĶŠōÕģźńÜäµĢ░µŹ«µĀ╝Õ╝ŵŁŻńĪ«ŃĆé 2. **IPv4ĶĮ¼µŹó**’╝ÜÕ║ōÕÅ»ĶāĮµö»µīüÕ░åIPv4Õ£░ÕØĆÕ£©ńé╣ÕłåÕŹüĶ┐øÕłČµĀ╝Õ╝ÅÕÆīµĢ┤µĢ░õ╣ŗķŚ┤Ķ┐øĶĪīĶĮ¼µŹó’╝īµł¢ĶĆģĶ┐øĶĪīÕģČõ╗¢ÕĮóÕ╝ÅńÜäĶĪ©ńż║’╝ī...
"IPv4ÕŹÅĶ««&IPv6" IPv4ÕŹÅĶ««µś»Ķ¦äĶīāĶ«Īń«Śµ£║ńĮæń╗£õĖŁµĢ░µŹ«õ╝ĀķĆüńÜäõĖĆÕźŚÕŹÅĶ««’╝īÕĮōÕēŹõĮ┐ńö©ńÜ䵜»IPv4’╝īIPv6µŁŻÕ£©Ķ»Ģķ¬īķśČµ«ĄŃĆéIPv4õĮ┐ńö©32õĮŹÕ£░ÕØĆ’╝īÕøĀµŁżµ£ĆÕżÜÕÅ»ĶāĮµ£ē4294967296(=2^32)õĖ¬Õ£░ÕØĆŃĆé IPv4Õ£░ÕØĆńÜäµĀ╝Õ╝ŵś»Õ░å32õĮŹÕ£░ÕØĆÕłåõĖ║õĖżõĖ¬ķā©Õłå’╝Ü...
IPÕ£░ÕØĆ’╝łInternet Protocol Address’╝ēµś»õ║ÆĶüöńĮæÕŹÅĶ««õĖŁńö©õ║ÄÕö»õĖƵĀćĶ»åĶ┐×µÄźÕł░õ║ÆĶüöńĮæõĖŖńÜäµ»ÅõĖĆõĖ¬Ķ«ŠÕżćńÜäõĖĆń¦ŹķĆ╗ĶŠæÕ£░ÕØĆŃĆéIPÕ£░ÕØĆÕłåõĖ║IPv4ÕÆīIPv6õĖżń¦ŹõĖ╗Ķ”üńēłµ£¼’╝īµ£¼µ¢ćµĪŻõĖ╗Ķ”üõ╗ŗń╗Źõ║åIPv4Õ£░ÕØĆńÜäµŖƵ£»ń╗åĶŖéÕÅŖÕģČõĖÄIPv6ńÜäÕ¤║µ£¼Õ»╣µ»öŃĆé #### ...
IPv4 õĖÄ IPv6 õĖÜÕŖĪ-Õ┐½ķƤĶĮ¼ÕÅæµŖƵ£»õ╗ŗń╗Ź IPv4 õĖÄ IPv6 õĖÜÕŖĪ-Õ┐½ķƤĶĮ¼ÕÅæµŖƵ£»µś»ÕĮōÕēŹńĮæń╗£µŖƵ£»õĖŁńÜäõĖĆń¦ŹÕģ│ķö«µŖƵ£»’╝īÕ«āĶāĮÕż¤Õż¦Õż¦µÅÉķ½śĶĘ»ńö▒ÕÖ©ńÜäµŖźµ¢ćĶĮ¼ÕÅæµĢłńÄćŃĆ鵣żµŖƵ£»ķĆÜĶ┐ćķććńö©ķ½śķƤń╝ōÕŁśµØźÕżäńÉåµŖźµ¢ć’╝īõ╗ÄĶĆīÕćÅÕ░æµŖźµ¢ćńÜäĶĮ¼ÕÅæµŚČķŚ┤’╝īµÅÉķ½ś IP ...
IPv4õĖÄIPv6õĖÜÕŖĪ-ķܦķüōµŖƵ£»õ╗ŗń╗Ź-D.docx
Õ£© IPv4 õĖÜÕŖĪõĖŁ’╝īDHCP µŖƵ£»õĖ╗Ķ”üńö©õ║ÄĶ¦ŻÕå│ IPv4 Õ£░ÕØĆń®║ķŚ┤ńÜäķÖÉÕłČķŚ«ķóśŃĆéÕ£© IPv6 õĖÜÕŖĪõĖŁ’╝īDHCP µŖƵ£»õĖ╗Ķ”üńö©õ║ÄÕ«×ńÄ░Ķć¬ÕŖ©Õī¢ńÜä IPv6 Õ£░ÕØĆÕłåķģŹ’╝īµÅÉķ½ś IPv6 ńĮæń╗£ńÜäÕÅ»ķØĀµĆ¦ÕÆīÕÅ»µē®Õ▒ĢµĆ¦ŃĆé DHCP µŖƵ£»µś»Õ«×ńÄ░Ķć¬ÕŖ©Õī¢ńÜäIPÕ£░ÕØĆÕłåķģŹńÜäķćŹĶ”ü...
IPÕ£░ÕØĆ’╝łInternet Protocol Address’╝ēµś»õ║ÆĶüöńĮæÕŹÅĶ««õĖŁńö©õ║ÄÕö»õĖƵĀćĶ»åĶ┐×µÄźÕł░õ║ÆĶüöńĮæõĖŖńÜäµ»ÅõĖĆõĖ¬Ķ«ŠÕżćńÜäõĖĆń¦ŹķĆ╗ĶŠæÕ£░ÕØĆŃĆéIPÕ£░ÕØĆÕłåõĖ║IPv4ÕÆīIPv6õĖżń¦ŹõĖ╗Ķ”üńēłµ£¼’╝īµ£¼µ¢ćµĪŻõĖ╗Ķ”üÕģ│µ│©IPv4Õ£░ÕØĆÕÅŖÕģȵŖƵ£»ńē╣µĆ¦ŃĆé #### IPÕ£░ÕØĆńÜäÕłåń▒╗õĖÄĶĪ©ńż║ ...
µ£¼ĶĄäµ║ÉõĖ║ŌĆ£Õ¤║õ║ÄeNSPńÜäIPv6 IPv4õ║ÆķĆܵŖƵ£»-NAT64ķģŹńĮ«Õ«×õŠŗŌĆØÕÆīŌĆ£IPv6 over IPv4 ISATAPķܦķüōķģŹńĮ«Õ«×õŠŗŌĆØ’╝īÕīģÕɽµŗōµēæÕøŠŃĆüķģŹńĮ«µ¢ćõ╗ČŃĆüńøĖÕģ│µĢ░µŹ«ÕīģµŖōÕÅ¢ŃĆéÕÅ»õŠøÕŹÄõĖ║Ķ«żĶ»üÕżćĶĆāõ║║ÕæśÕÅŖĶ«Īń«Śµ£║ńĮæń╗£ńł▒ÕźĮĶĆģÕŁ”õ╣Āõ║żµĄüõĮ┐ńö©
õĖ║õ║åÕ║öÕ»╣Ķ┐ÖõĖƵīæµłś’╝īÕģ©ńÉāńĮæń╗£ńżŠÕī║ÕĘ▓ń╗ÅĶĮ¼ÕÉæIPv6’╝īõĖĆõĖ¬µÅÉõŠøÕćĀõ╣ĵŚĀķÖÉÕ£░ÕØĆń®║ķŚ┤ńÜäµ¢░ÕŹÅĶ««ŃĆéńäČĶĆī’╝īńö▒õ║ÄIPv4ÕÆīIPv6ńĮæń╗£Õ╣ČÕŁśńÜäńÄ░Õ«×’╝īĶ┐ćµĖĪµŖƵ£»µłÉõĖ║õ║åõĖĆõĖ¬Õģ│ķö«ķóåÕ¤¤ŃĆéÕŹÄõĖ║õĮ£õĖ║ńĮæń╗£Ķ«ŠÕżćÕÆīĶ¦ŻÕå│µ¢╣µĪłńÜäķóåÕģłµÅÉõŠøÕĢå’╝īµÅÉÕć║õ║åŌĆ£IPv4-over-...
IPv4õĖÄIPv6õĖÜÕŖĪ-FTPÕÆīTFTPµŖƵ£»õ╗ŗń╗Ź-D.docx
IPv4õĖÄIPv6õĖÜÕŖĪ-ARPµö╗Õć╗ķś▓ĶīāµŖƵ£»ńÖĮńÜ«õ╣”-D.docx
õĮåńö▒õ║ÄIPv6Õ£░ÕØĆń®║ķŚ┤ńÜäÕĘ©Õż¦µē®Õ▒Ģ’╝īõĮ┐ÕŠŚÕ£©IPv6ńÄ»ÕóāõĖŁķā©ńĮ▓FTPÕÆīTFTPµø┤õĖ║ńüĄµ┤╗ÕÆīµ¢╣õŠ┐ŃĆéńē╣Õł½µś»Õ»╣õ║ÄķéŻõ║øķ£ĆĶ”üĶĘ©ńĮæń╗£õ╝ĀĶŠōÕż¦ķćŵ¢ćõ╗ČńÜäÕ║öńö©Õ£║µÖ»’╝īIPv6µÅÉõŠøõ║åµø┤ÕżÜńÜäõ╝śÕŖ┐ŃĆé - **IPv6Õ»╣FTPńÜäÕĮ▒ÕōŹ**’╝ÜIPv6Õ»╣FTPÕŹÅĶ««µ£¼Ķ║½µ▓Īµ£ēÕż¬Õż¦ńÜä...
IPv4õĖÄIPv6õĖÜÕŖĪ-IPv6Õ¤║ńĪƵŖƵ£»õ╗ŗń╗Ź.pdf