- жөҸи§Ҳ: 2694086 ж¬Ў
- жқҘиҮӘ: жқӯе·һ
-

ж–Үз« еҲҶзұ»
- е…ЁйғЁеҚҡе®ў (1188)
- webwork (4)
- зҪ‘ж‘ҳ (18)
- java (103)
- hibernate (1)
- Linux (85)
- иҒҢдёҡеҸ‘еұ• (1)
- activeMQ (2)
- netty (14)
- svn (1)
- webx3 (12)
- mysql (81)
- css (1)
- HTML (6)
- apache (3)
- жөӢиҜ• (2)
- javascript (1)
- еӮЁеӯҳ (1)
- jvm (5)
- code (13)
- еӨҡзәҝзЁӢ (12)
- Spring (18)
- webxs (2)
- python (119)
- duitang (0)
- mongo (3)
- nosql (4)
- tomcat (4)
- memcached (20)
- з®—жі• (28)
- django (28)
- shell (1)
- е·ҘдҪңжҖ»з»“ (5)
- solr (42)
- beansdb (6)
- nginx (3)
- жҖ§иғҪ (30)
- ж•°жҚ®жҺЁиҚҗ (1)
- maven (8)
- tonado (1)
- uwsgi (5)
- hessian (4)
- ibatis (3)
- Security (2)
- HTPP (1)
- gevent (6)
- иҜ»д№Ұ笔记 (1)
- Maxent (2)
- mogo (0)
- thread (3)
- жһ¶жһ„ (5)
- NIO (5)
- жӯЈеҲҷ (1)
- lucene (5)
- feed (4)
- redis (17)
- TCP (6)
- test (0)
- pythonпјҢcode (1)
- PIL (3)
- guava (2)
- jython (4)
- httpclient (2)
- cache (3)
- signal (1)
- dubbo (7)
- HTTP (4)
- json (3)
- java socket (1)
- io (2)
- socket (22)
- hash (2)
- Cassandra (1)
- еҲҶеёғејҸж–Ү件系з»ҹ (5)
- Dynamo (2)
- gc (8)
- scp (1)
- rsync (1)
- mecached (0)
- mongoDB (29)
- Thrift (1)
- scribe (2)
- жңҚеҠЎеҢ– (3)
- й—®йўҳ (83)
- mat (1)
- classloader (2)
- javaBean (1)
- ж–ҮжЎЈйӣҶеҗҲ (27)
- ж¶ҲжҒҜйҳҹеҲ— (3)
- nginxпјҢж–ҮжЎЈйӣҶеҗҲ (1)
- dboss (12)
- libevent (1)
- иҜ»д№Ұ (0)
- ж•°еӯҰ (3)
- жөҒзЁӢ (0)
- HBase (34)
- иҮӘеҠЁеҢ–жөӢиҜ• (1)
- ubuntu (2)
- 并еҸ‘ (1)
- sping (1)
- еӣҫеҪў (1)
- freemarker (1)
- jdbc (3)
- dbcp (0)
- sharding (1)
- жҖ§иғҪжөӢиҜ• (1)
- и®ҫи®ЎжЁЎејҸ (2)
- unicode (1)
- OceanBase (3)
- jmagick (1)
- gunicorn (1)
- url (1)
- form (1)
- е®үе…Ё (2)
- nlp (8)
- libmemcached (1)
- 规еҲҷеј•ж“Һ (1)
- awk (2)
- жңҚеҠЎеҷЁ (1)
- snmpd (1)
- btrace (1)
- д»Јз Ғ (1)
- cygwin (1)
- mahout (3)
- з”өеӯҗд№Ұ (1)
- жңәеҷЁеӯҰд№ (5)
- ж•°жҚ®жҢ–жҺҳ (1)
- nltk (6)
- pool (1)
- log4j (2)
- жҖ»з»“ (11)
- c++ (1)
- javaжәҗд»Јз Ғ (1)
- ocr (1)
- еҹәзЎҖз®—жі• (3)
- SA (1)
- 笔记 (1)
- ml (4)
- zokeeper (0)
- jms (1)
- zookeeper (5)
- zkclient (1)
- hadoop (13)
- mq (2)
- git (9)
- й—®йўҳпјҢio (1)
- storm (11)
- zk (1)
- жҖ§иғҪдјҳеҢ– (2)
- example (1)
- tmux (1)
- зҺҜеўғ (2)
- kyro (1)
- ж—Ҙеҝ—зі»з»ҹ (3)
- hdfs (2)
- python_socket (2)
- date (2)
- elasticsearch (1)
- jetty (1)
- ж ‘ (1)
- жұҪиҪҰ (1)
- mdrill (1)
- иҪҰ (1)
- ж—Ҙеҝ— (1)
- web (1)
- зј–иҜ‘еҺҹзҗҶ (1)
- дҝЎжҒҜжЈҖзҙў (1)
- жҖ§иғҪпјҢlinux (1)
- spam (1)
- еәҸеҲ—еҢ– (1)
- fabric (2)
- guice (1)
- disruptor (1)
- executor (1)
- logback (2)
- ејҖжәҗ (1)
- и®ҫи®Ў (1)
- зӣ‘жҺ§ (3)
- english (1)
- й—®йўҳи®°еҪ• (1)
- Bitmap (1)
- дә‘и®Ўз®— (1)
- й—®йўҳжҺ’жҹҘ (1)
- highchat (1)
- mac (3)
- docker (1)
- jdk (1)
- иЎЁиҫҫејҸ (1)
- зҪ‘з»ң (1)
- ж—¶й—ҙз®ЎзҗҶ (1)
- ж—¶й—ҙеәҸеҲ— (1)
- OLAP (1)
- Big Table (0)
- sql (1)
- kafka (1)
- md5 (1)
- springboot (1)
- spring security (1)
- Spring Boot (3)
- mybatis (1)
- java8 (1)
- еҲҶеёғејҸдәӢеҠЎ (1)
- йҷҗжөҒ (1)
- Shadowsocks (0)
- 2018 (1)
- жңҚеҠЎжІ»зҗҶ (1)
- и®ҫи®ЎеҺҹеҲҷ (1)
- log (0)
- perftools (1)
зӨҫеҢәзүҲеқ—
- жҲ‘зҡ„иө„и®Ҝ ( 0)
- жҲ‘зҡ„и®әеқӣ ( 98)
- жҲ‘зҡ„й—®зӯ” ( 0)
еӯҳжЎЈеҲҶзұ»
- 2019-11 ( 1)
- 2019-01 ( 3)
- 2018-12 ( 1)
- жӣҙеӨҡеӯҳжЎЈ...
жңҖж–°иҜ„и®ә
-
siphlinaпјҡ
иҜҫзЁӢвҖ”вҖ”еҹәдәҺPythonж•°жҚ®еҲҶжһҗдёҺжңәеҷЁеӯҰд№ жЎҲдҫӢе®һжҲҳж•ҷзЁӢеҲҶдә«зҪ‘зӣҳ ...
PythonжңәеҷЁеӯҰд№ еә“ -
san_yunпјҡ
leibnitz еҶҷйҒ“hi,жҲ‘жғізҹҘйҒ“,ж— и®әеңЁ92иҝҳжҳҜ94зүҲжң¬, ...
hbaseзҡ„иЎҢй”ҒдёҺеӨҡзүҲжң¬е№¶еҸ‘жҺ§еҲ¶(MVCC) -
leibnitzпјҡ
hi,жҲ‘жғізҹҘйҒ“,ж— и®әеңЁ92иҝҳжҳҜ94зүҲжң¬,жӣҙж–°ж—¶(еҰӮPuts)йғҪ ...
hbaseзҡ„иЎҢй”ҒдёҺеӨҡзүҲжң¬е№¶еҸ‘жҺ§еҲ¶(MVCC) -
107xпјҡ
дёҚй”ҷпјҢи°ўи°ўпјҒ
Latent Semantic Analysis(LSA/ LSI)з®—жі•з®Җд»Ӣ -
107xпјҡ
дёҚй”ҷпјҢи°ўи°ўпјҒ
PythonжңәеҷЁеӯҰд№ еә“
жңҖе·ҰеүҚзјҖеҺҹзҗҶдёҺзӣёе…ідјҳеҢ–
й«ҳж•ҲдҪҝз”Ёзҙўеј•зҡ„йҰ–иҰҒжқЎд»¶жҳҜзҹҘйҒ“д»Җд№Ҳж ·зҡ„жҹҘиҜўдјҡдҪҝз”ЁеҲ°зҙўеј•пјҢиҝҷдёӘй—®йўҳе’ҢB+Treeдёӯзҡ„вҖңжңҖе·ҰеүҚзјҖеҺҹзҗҶвҖқжңүе…іпјҢдёӢйқўйҖҡиҝҮдҫӢеӯҗиҜҙжҳҺжңҖе·ҰеүҚзјҖеҺҹзҗҶгҖӮ
иҝҷйҮҢе…ҲиҜҙдёҖдёӢиҒ”еҗҲзҙўеј•зҡ„жҰӮеҝөгҖӮеңЁдёҠж–ҮдёӯпјҢжҲ‘们йғҪжҳҜеҒҮи®ҫзҙўеј•еҸӘеј•з”ЁдәҶеҚ•дёӘзҡ„еҲ—пјҢе®һйҷ…дёҠпјҢMySQLдёӯзҡ„зҙўеј•еҸҜд»Ҙд»ҘдёҖе®ҡйЎәеәҸеј•з”ЁеӨҡдёӘеҲ—пјҢиҝҷз§Қзҙўеј•еҸ«еҒҡиҒ” еҗҲзҙўеј•пјҢдёҖиҲ¬зҡ„пјҢдёҖдёӘиҒ”еҗҲзҙўеј•жҳҜдёҖдёӘжңүеәҸе…ғз»„<a1, a2, вҖҰ, an>пјҢе…¶дёӯеҗ„дёӘе…ғзҙ еқҮдёәж•°жҚ®иЎЁзҡ„дёҖеҲ—пјҢе®һйҷ…дёҠиҰҒдёҘж је®ҡд№үзҙўеј•йңҖиҰҒз”ЁеҲ°е…ізі»д»Јж•°пјҢдҪҶжҳҜиҝҷйҮҢжҲ‘дёҚжғіи®Ёи®әеӨӘеӨҡе…ізі»д»Јж•°зҡ„иҜқйўҳпјҢеӣ дёәйӮЈж ·дјҡжҳҫеҫ—еҫҲжһҜзҮҘпјҢжүҖ д»ҘиҝҷйҮҢе°ұдёҚеҶҚеҒҡдёҘж је®ҡд№үгҖӮеҸҰеӨ–пјҢеҚ•еҲ—зҙўеј•еҸҜд»ҘзңӢжҲҗиҒ”еҗҲзҙўеј•е…ғзҙ ж•°дёә1зҡ„зү№дҫӢгҖӮ
д»Ҙemployees.titlesиЎЁдёәдҫӢпјҢдёӢйқўе…ҲжҹҘзңӢе…¶дёҠйғҪжңүе“Әдәӣзҙўеј•пјҡ
SHOW INDEX FROM employees.titles; +--------+------------+----------+--------------+-------------+-----------+-------------+------+------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Null | Index_type | +--------+------------+----------+--------------+-------------+-----------+-------------+------+------------+ | titles | 0 | PRIMARY | 1 | emp_no | A | NULL | | BTREE | | titles | 0 | PRIMARY | 2 | title | A | NULL | | BTREE | | titles | 0 | PRIMARY | 3 | from_date | A | 443308 | | BTREE | | titles | 1 | emp_no | 1 | emp_no | A | 443308 | | BTREE | +--------+------------+----------+--------------+-------------+-----------+-------------+------+------------+
д»Һз»“жһңдёӯеҸҜд»ҘеҲ°titlesиЎЁзҡ„дё»зҙўеј•дёә<emp_no, title, from_date>пјҢиҝҳжңүдёҖдёӘиҫ…еҠ©зҙўеј•<emp_no>гҖӮдёәдәҶйҒҝе…ҚеӨҡдёӘзҙўеј•дҪҝдәӢжғ…еҸҳеӨҚжқӮпјҲMySQLзҡ„SQLдјҳеҢ–еҷЁеңЁеӨҡзҙўеј•ж—¶иЎҢдёәжҜ” иҫғеӨҚжқӮпјүпјҢиҝҷйҮҢжҲ‘们е°Ҷиҫ…еҠ©зҙўеј•dropжҺүпјҡ
ALTER TABLE employees.titles DROP INDEX emp_no;
иҝҷж ·е°ұеҸҜд»Ҙдё“еҝғеҲҶжһҗзҙўеј•PRIMARYзҡ„иЎҢдёәдәҶгҖӮ
жғ…еҶөдёҖпјҡе…ЁеҲ—еҢ№й…ҚгҖӮ
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND title='Senior Engineer' AND from_date='1986-06-26'; +----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+ | 1 | SIMPLE | titles | const | PRIMARY | PRIMARY | 59 | const,const,const | 1 | | +----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
еҫҲжҳҺжҳҫпјҢеҪ“жҢүз…§зҙўеј•дёӯжүҖжңүеҲ—иҝӣиЎҢзІҫзЎ®еҢ№й…ҚпјҲиҝҷйҮҢзІҫзЎ®еҢ№й…ҚжҢҮвҖң=вҖқжҲ–вҖңINвҖқеҢ№й…Қпјүж—¶пјҢзҙўеј•еҸҜд»Ҙиў«з”ЁеҲ°гҖӮиҝҷйҮҢжңүдёҖзӮ№йңҖиҰҒжіЁж„ҸпјҢзҗҶи®әдёҠзҙўеј•еҜ№йЎәеәҸжҳҜж•Ҹж„ҹ зҡ„пјҢдҪҶжҳҜз”ұдәҺMySQLзҡ„жҹҘиҜўдјҳеҢ–еҷЁдјҡиҮӘеҠЁи°ғж•ҙwhereеӯҗеҸҘзҡ„жқЎд»¶йЎәеәҸд»ҘдҪҝз”ЁйҖӮеҗҲзҡ„зҙўеј•пјҢдҫӢеҰӮжҲ‘们е°Ҷwhereдёӯзҡ„жқЎд»¶йЎәеәҸйў еҖ’пјҡ
EXPLAIN SELECT * FROM employees.titles WHERE from_date='1986-06-26' AND emp_no='10001' AND title='Senior Engineer'; +----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+ | 1 | SIMPLE | titles | const | PRIMARY | PRIMARY | 59 | const,const,const | 1 | | +----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
ж•ҲжһңжҳҜдёҖж ·зҡ„гҖӮ
жғ…еҶөдәҢпјҡжңҖе·ҰеүҚзјҖеҢ№й…ҚгҖӮ
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001'; +----+-------------+--------+------+---------------+---------+---------+-------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+---------------+---------+---------+-------+------+-------+ | 1 | SIMPLE | titles | ref | PRIMARY | PRIMARY | 4 | const | 1 | | +----+-------------+--------+------+---------------+---------+---------+-------+------+-------+
еҪ“жҹҘиҜўжқЎд»¶зІҫзЎ®еҢ№й…Қзҙўеј•зҡ„е·Ұиҫ№иҝһз»ӯдёҖдёӘжҲ–еҮ дёӘеҲ—ж—¶пјҢеҰӮ<emp_no>жҲ–<emp_no, title>пјҢжүҖд»ҘеҸҜд»Ҙиў«з”ЁеҲ°пјҢдҪҶжҳҜеҸӘиғҪз”ЁеҲ°дёҖйғЁеҲҶпјҢеҚіжқЎд»¶жүҖз»„жҲҗзҡ„жңҖе·ҰеүҚзјҖгҖӮдёҠйқўзҡ„жҹҘиҜўд»ҺеҲҶжһҗз»“жһңзңӢз”ЁеҲ°дәҶPRIMARYзҙўеј•пјҢдҪҶжҳҜ key_lenдёә4пјҢиҜҙжҳҺеҸӘз”ЁеҲ°дәҶзҙўеј•зҡ„第дёҖеҲ—еүҚзјҖгҖӮ
жғ…еҶөдёүпјҡжҹҘиҜўжқЎд»¶з”ЁеҲ°дәҶзҙўеј•дёӯеҲ—зҡ„зІҫзЎ®еҢ№й…ҚпјҢдҪҶжҳҜдёӯй—ҙжҹҗдёӘжқЎд»¶жңӘжҸҗдҫӣгҖӮ
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND from_date='1986-06-26'; +----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+ | 1 | SIMPLE | titles | ref | PRIMARY | PRIMARY | 4 | const | 1 | Using where | +----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
жӯӨж—¶зҙўеј•дҪҝз”Ёжғ…еҶөе’Ңжғ…еҶөдәҢзӣёеҗҢпјҢеӣ дёәtitleжңӘжҸҗдҫӣпјҢжүҖд»ҘжҹҘиҜўеҸӘз”ЁеҲ°дәҶзҙўеј•зҡ„第дёҖеҲ—пјҢиҖҢеҗҺйқўзҡ„from_dateиҷҪ然д№ҹеңЁзҙўеј•дёӯпјҢдҪҶжҳҜз”ұдәҺ titleдёҚеӯҳеңЁиҖҢж— жі•е’Ңе·ҰеүҚзјҖиҝһжҺҘпјҢеӣ жӯӨйңҖиҰҒеҜ№з»“жһңиҝӣиЎҢжү«жҸҸиҝҮж»Өfrom_dateпјҲиҝҷйҮҢз”ұдәҺemp_noе”ҜдёҖпјҢжүҖд»ҘдёҚеӯҳеңЁжү«жҸҸпјүгҖӮеҰӮжһңжғіи®© from_dateд№ҹдҪҝз”Ёзҙўеј•иҖҢдёҚжҳҜwhereиҝҮж»ӨпјҢеҸҜд»ҘеўһеҠ дёҖдёӘиҫ…еҠ©зҙўеј•<emp_no, from_date>пјҢжӯӨж—¶дёҠйқўзҡ„жҹҘиҜўдјҡдҪҝз”ЁиҝҷдёӘзҙўеј•гҖӮйҷӨжӯӨд№ӢеӨ–пјҢиҝҳеҸҜд»ҘдҪҝз”ЁдёҖз§Қз§°д№ӢдёәвҖңйҡ”зҰ»еҲ—вҖқзҡ„дјҳеҢ–ж–№жі•пјҢе°Ҷemp_noдёҺfrom_date д№Ӣй—ҙзҡ„вҖңеқ‘вҖқеЎ«дёҠгҖӮ
йҰ–е…ҲжҲ‘们зңӢдёӢtitleдёҖе…ұжңүеҮ з§ҚдёҚеҗҢзҡ„еҖјпјҡ
SELECT DISTINCT(title) FROM employees.titles; +--------------------+ | title | +--------------------+ | Senior Engineer | | Staff | | Engineer | | Senior Staff | | Assistant Engineer | | Technique Leader | | Manager | +--------------------+
еҸӘжңү7з§ҚгҖӮеңЁиҝҷз§ҚжҲҗдёәвҖңеқ‘вҖқзҡ„еҲ—еҖјжҜ”иҫғе°‘зҡ„жғ…еҶөдёӢпјҢеҸҜд»ҘиҖғиҷ‘з”ЁвҖңINвҖқжқҘеЎ«иЎҘиҝҷдёӘвҖңеқ‘вҖқд»ҺиҖҢеҪўжҲҗжңҖе·ҰеүҚзјҖпјҡ
EXPLAIN SELECT * FROM employees.titles
WHERE emp_no='10001'
AND title IN ('Senior Engineer', 'Staff', 'Engineer', 'Senior Staff', 'Assistant Engineer', 'Technique Leader', 'Manager')
AND from_date='1986-06-26';
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 59 | NULL | 7 | Using where |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
иҝҷж¬Ўkey_lenдёә59пјҢиҜҙжҳҺзҙўеј•иў«з”Ёе…ЁдәҶпјҢдҪҶжҳҜд»Һtypeе’ҢrowsзңӢеҮәINе®һйҷ…дёҠжү§иЎҢдәҶдёҖдёӘrangeжҹҘиҜўпјҢиҝҷйҮҢжЈҖжҹҘдәҶ7дёӘkeyгҖӮзңӢдёӢдёӨз§ҚжҹҘиҜўзҡ„жҖ§иғҪжҜ”иҫғпјҡ
SHOW PROFILES; +----------+------------+-------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+-------------------------------------------------------------------------------+ | 10 | 0.00058000 | SELECT * FROM employees.titles WHERE emp_no='10001' AND from_date='1986-06-26'| | 11 | 0.00052500 | SELECT * FROM employees.titles WHERE emp_no='10001' AND title IN ... | +----------+------------+-------------------------------------------------------------------------------+
вҖңеЎ«еқ‘вҖқеҗҺжҖ§иғҪжҸҗеҚҮдәҶдёҖзӮ№гҖӮеҰӮжһңз»ҸиҝҮemp_noзӯӣйҖүеҗҺдҪҷдёӢеҫҲеӨҡж•°жҚ®пјҢеҲҷеҗҺиҖ…жҖ§иғҪдјҳеҠҝдјҡжӣҙеҠ жҳҺжҳҫгҖӮеҪ“然пјҢеҰӮжһңtitleзҡ„еҖјеҫҲеӨҡпјҢз”ЁеЎ«еқ‘е°ұдёҚеҗҲйҖӮдәҶпјҢеҝ…йЎ»е»әз«Ӣиҫ…еҠ©зҙўеј•гҖӮ
жғ…еҶөеӣӣпјҡжҹҘиҜўжқЎд»¶жІЎжңүжҢҮе®ҡзҙўеј•з¬¬дёҖеҲ—гҖӮ
EXPLAIN SELECT * FROM employees.titles WHERE from_date='1986-06-26'; +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+ | 1 | SIMPLE | titles | ALL | NULL | NULL | NULL | NULL | 443308 | Using where | +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
з”ұдәҺдёҚжҳҜжңҖе·ҰеүҚзјҖпјҢзҙўеј•иҝҷж ·зҡ„жҹҘиҜўжҳҫ然用дёҚеҲ°зҙўеј•гҖӮ
жғ…еҶөдә”пјҡеҢ№й…ҚжҹҗеҲ—зҡ„еүҚзјҖеӯ—з¬ҰдёІгҖӮ
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND title LIKE 'Senior%';
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+ | 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 56 | NULL | 1 | Using where | +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
жӯӨж—¶еҸҜд»Ҙз”ЁеҲ°зҙўеј•пјҢдҪҶжҳҜеҰӮжһңйҖҡй…Қз¬ҰдёҚжҳҜеҸӘеҮәзҺ°еңЁжң«е°ҫпјҢеҲҷж— жі•дҪҝз”Ёзҙўеј•гҖӮ
жғ…еҶөе…ӯпјҡиҢғеӣҙжҹҘиҜўгҖӮ
EXPLAIN SELECT * FROM employees.titles WHERE emp_no<'10010' and title='Senior Engineer'; +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+ | 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 4 | NULL | 16 | Using where | +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
иҢғеӣҙеҲ—еҸҜд»Ҙз”ЁеҲ°зҙўеј•пјҲеҝ…йЎ»жҳҜжңҖе·ҰеүҚзјҖпјүпјҢдҪҶжҳҜиҢғеӣҙеҲ—еҗҺйқўзҡ„еҲ—ж— жі•з”ЁеҲ°зҙўеј•гҖӮеҗҢж—¶пјҢзҙўеј•жңҖеӨҡз”ЁдәҺдёҖдёӘиҢғеӣҙеҲ—пјҢеӣ жӯӨеҰӮжһңжҹҘиҜўжқЎд»¶дёӯжңүдёӨдёӘиҢғеӣҙеҲ—еҲҷж— жі•е…Ёз”ЁеҲ°зҙўеј•гҖӮ
EXPLAIN SELECT * FROM employees.titles WHERE emp_no<'10010' AND title='Senior Engineer' AND from_date BETWEEN '1986-01-01' AND '1986-12-31'; +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+ | 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 4 | NULL | 16 | Using where | +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
еҸҜд»ҘзңӢеҲ°зҙўеј•еҜ№з¬¬дәҢдёӘиҢғеӣҙзҙўеј•ж— иғҪдёәеҠӣгҖӮиҝҷйҮҢзү№еҲ«иҰҒиҜҙжҳҺMySQLдёҖдёӘжңүж„ҸжҖқзҡ„ең°ж–№пјҢйӮЈе°ұжҳҜд»…з”ЁexplainеҸҜиғҪж— жі•еҢәеҲҶиҢғеӣҙзҙўеј•е’ҢеӨҡеҖјеҢ№й…ҚпјҢеӣ дёәеңЁtypeдёӯиҝҷдёӨиҖ…йғҪжҳҫзӨәдёәrangeгҖӮеҗҢж—¶пјҢз”ЁдәҶвҖңbetweenвҖқ并дёҚж„Ҹе‘ізқҖе°ұжҳҜиҢғеӣҙжҹҘиҜўпјҢдҫӢеҰӮдёӢйқўзҡ„жҹҘиҜўпјҡ
EXPLAIN SELECT * FROM employees.titles WHERE emp_no BETWEEN '10001' AND '10010' AND title='Senior Engineer' AND from_date BETWEEN '1986-01-01' AND '1986-12-31'; +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+ | 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 59 | NULL | 16 | Using where | +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
зңӢиө·жқҘжҳҜз”ЁдәҶдёӨдёӘиҢғеӣҙжҹҘиҜўпјҢдҪҶдҪңз”ЁдәҺemp_noдёҠзҡ„вҖңBETWEENвҖқе®һйҷ…дёҠзӣёеҪ“дәҺвҖңINвҖқпјҢд№ҹе°ұжҳҜиҜҙemp_noе®һйҷ…жҳҜеӨҡеҖјзІҫзЎ®еҢ№й…ҚгҖӮеҸҜд»ҘзңӢеҲ°иҝҷдёӘжҹҘиҜўз”ЁеҲ°дәҶзҙўеј•е…ЁйғЁдёүдёӘеҲ—гҖӮеӣ жӯӨеңЁMySQLдёӯиҰҒи°Ёж…Һең°еҢәеҲҶеӨҡеҖјеҢ№й…Қе’ҢиҢғеӣҙеҢ№й…ҚпјҢеҗҰеҲҷдјҡеҜ№MySQLзҡ„иЎҢдёәдә§з”ҹеӣ°жғ‘гҖӮ
жғ…еҶөдёғпјҡжҹҘиҜўжқЎд»¶дёӯеҗ«жңүеҮҪж•°жҲ–иЎЁиҫҫејҸгҖӮ
еҫҲдёҚе№ёпјҢеҰӮжһңжҹҘиҜўжқЎд»¶дёӯеҗ«жңүеҮҪж•°жҲ–иЎЁиҫҫејҸпјҢеҲҷMySQLдёҚдјҡдёәиҝҷеҲ—дҪҝз”Ёзҙўеј•пјҲиҷҪ然жҹҗдәӣеңЁж•°еӯҰж„Ҹд№үдёҠеҸҜд»ҘдҪҝз”ЁпјүгҖӮдҫӢеҰӮпјҡ
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND left(title, 6)='Senior'; +----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+ | 1 | SIMPLE | titles | ref | PRIMARY | PRIMARY | 4 | const | 1 | Using where | +----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
иҷҪ然иҝҷдёӘжҹҘиҜўе’Ңжғ…еҶөдә”дёӯеҠҹиғҪзӣёеҗҢпјҢдҪҶжҳҜз”ұдәҺдҪҝз”ЁдәҶеҮҪж•°leftпјҢеҲҷж— жі•дёәtitleеҲ—еә”з”Ёзҙўеј•пјҢиҖҢжғ…еҶөдә”дёӯз”ЁLIKEеҲҷеҸҜд»ҘгҖӮеҶҚеҰӮпјҡ
EXPLAIN SELECT * FROM employees.titles WHERE emp_no - 1='10000'; +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+ | 1 | SIMPLE | titles | ALL | NULL | NULL | NULL | NULL | 443308 | Using where | +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
жҳҫ然иҝҷдёӘжҹҘиҜўзӯүд»·дәҺжҹҘиҜўemp_noдёә10001зҡ„еҮҪж•°пјҢдҪҶжҳҜз”ұдәҺжҹҘиҜўжқЎд»¶жҳҜдёҖдёӘиЎЁиҫҫејҸпјҢMySQLж— жі•дёәе…¶дҪҝз”Ёзҙўеј•гҖӮзңӢжқҘMySQLиҝҳжІЎжңүжҷәиғҪеҲ° иҮӘеҠЁдјҳеҢ–еёёйҮҸиЎЁиҫҫејҸзҡ„зЁӢеәҰпјҢеӣ жӯӨеңЁеҶҷжҹҘиҜўиҜӯеҸҘж—¶е°ҪйҮҸйҒҝе…ҚиЎЁиҫҫејҸеҮәзҺ°еңЁжҹҘиҜўдёӯпјҢиҖҢжҳҜе…ҲжүӢе·Ҙз§ҒдёӢд»Јж•°иҝҗз®—пјҢиҪ¬жҚўдёәж— иЎЁиҫҫејҸзҡ„жҹҘиҜўиҜӯеҸҘгҖӮ
зҙўеј•йҖүжӢ©жҖ§дёҺеүҚзјҖзҙўеј•
既然зҙўеј•еҸҜд»ҘеҠ еҝ«жҹҘиҜўйҖҹеәҰпјҢйӮЈд№ҲжҳҜдёҚжҳҜеҸӘиҰҒжҳҜжҹҘиҜўиҜӯеҸҘйңҖиҰҒпјҢе°ұе»әдёҠзҙўеј•пјҹзӯ”жЎҲжҳҜеҗҰе®ҡзҡ„гҖӮеӣ дёәзҙўеј•иҷҪ然еҠ еҝ«дәҶжҹҘиҜўйҖҹеәҰпјҢдҪҶзҙўеј•д№ҹжҳҜжңүд»Јд»·зҡ„пјҡзҙўеј•ж–Ү件 жң¬иә«иҰҒж¶ҲиҖ—еӯҳеӮЁз©әй—ҙпјҢеҗҢж—¶зҙўеј•дјҡеҠ йҮҚжҸ’е…ҘгҖҒеҲ йҷӨе’Ңдҝ®ж”№и®°еҪ•ж—¶зҡ„иҙҹжӢ…пјҢеҸҰеӨ–пјҢMySQLеңЁиҝҗиЎҢж—¶д№ҹиҰҒж¶ҲиҖ—иө„жәҗз»ҙжҠӨзҙўеј•пјҢеӣ жӯӨзҙўеј•е№¶дёҚжҳҜи¶ҠеӨҡи¶ҠеҘҪгҖӮдёҖиҲ¬дёӨз§Қжғ… еҶөдёӢдёҚе»әи®®е»әзҙўеј•гҖӮ
第дёҖз§Қжғ…еҶөжҳҜиЎЁи®°еҪ•жҜ”иҫғе°‘пјҢдҫӢеҰӮдёҖдёӨеҚғжқЎз”ҡиҮіеҸӘжңүеҮ зҷҫжқЎи®°еҪ•зҡ„иЎЁпјҢжІЎеҝ…иҰҒе»әзҙўеј•пјҢи®©жҹҘиҜўеҒҡе…ЁиЎЁжү«жҸҸе°ұеҘҪдәҶгҖӮиҮідәҺеӨҡе°‘жқЎи®°еҪ•жүҚз®—еӨҡпјҢиҝҷдёӘдёӘдәәжңүдёӘдәәзҡ„зңӢжі•пјҢжҲ‘дёӘдәәзҡ„з»ҸйӘҢжҳҜд»Ҙ2000дҪңдёәеҲҶз•ҢзәҝпјҢи®°еҪ•ж•°дёҚи¶…иҝҮ 2000еҸҜд»ҘиҖғиҷ‘дёҚе»әзҙўеј•пјҢи¶…иҝҮ2000жқЎеҸҜд»Ҙй…Ңжғ…иҖғиҷ‘зҙўеј•гҖӮ
еҸҰдёҖз§ҚдёҚе»әи®®е»әзҙўеј•зҡ„жғ…еҶөжҳҜзҙўеј•зҡ„йҖүжӢ©жҖ§иҫғдҪҺгҖӮжүҖи°“зҙўеј•зҡ„йҖүжӢ©жҖ§пјҲSelectivityпјүпјҢжҳҜжҢҮдёҚйҮҚеӨҚзҡ„зҙўеј•еҖјпјҲд№ҹеҸ«еҹәж•°пјҢCardinalityпјүдёҺиЎЁи®°еҪ•ж•°пјҲ#Tпјүзҡ„жҜ”еҖјпјҡ
Index Selectivity = Cardinality / #T
жҳҫ然йҖүжӢ©жҖ§зҡ„еҸ–еҖјиҢғеӣҙдёә(0, 1]пјҢйҖүжӢ©жҖ§и¶Ҡй«ҳзҡ„зҙўеј•д»·еҖји¶ҠеӨ§пјҢиҝҷжҳҜз”ұB+Treeзҡ„жҖ§иҙЁеҶіе®ҡзҡ„гҖӮдҫӢеҰӮпјҢдёҠж–Үз”ЁеҲ°зҡ„employees.titlesиЎЁпјҢеҰӮжһңtitleеӯ—ж®өз»Ҹеёёиў«еҚ•зӢ¬жҹҘиҜўпјҢжҳҜеҗҰйңҖиҰҒе»әзҙўеј•пјҢжҲ‘们зңӢдёҖдёӢе®ғзҡ„йҖүжӢ©жҖ§пјҡ
SELECT count(DISTINCT(title))/count(*) AS Selectivity FROM employees.titles; +-------------+ | Selectivity | +-------------+ | 0.0000 | +-------------+
titleзҡ„йҖүжӢ©жҖ§дёҚи¶і0.0001пјҲзІҫзЎ®еҖјдёә0.00001579пјүпјҢжүҖд»Ҙе®һеңЁжІЎжңүд»Җд№Ҳеҝ…иҰҒдёәе…¶еҚ•зӢ¬е»әзҙўеј•гҖӮ
жңүдёҖз§ҚдёҺзҙўеј•йҖүжӢ©жҖ§жңүе…ізҡ„зҙўеј•дјҳеҢ–зӯ–з•ҘеҸ«еҒҡеүҚзјҖзҙўеј•пјҢе°ұжҳҜз”ЁеҲ—зҡ„еүҚзјҖд»Јжӣҝж•ҙдёӘеҲ—дҪңдёәзҙўеј•keyпјҢеҪ“еүҚзјҖй•ҝеәҰеҗҲйҖӮж—¶пјҢеҸҜд»ҘеҒҡеҲ°ж—ўдҪҝеҫ—еүҚзјҖзҙўеј•зҡ„йҖүжӢ©жҖ§ жҺҘиҝ‘е…ЁеҲ—зҙўеј•пјҢеҗҢж—¶еӣ дёәзҙўеј•keyеҸҳзҹӯиҖҢеҮҸе°‘дәҶзҙўеј•ж–Ү件зҡ„еӨ§е°Ҹе’Ңз»ҙжҠӨејҖй”ҖгҖӮдёӢйқўд»Ҙemployees.employeesиЎЁдёәдҫӢд»Ӣз»ҚеүҚзјҖзҙўеј•зҡ„йҖүжӢ©е’ҢдҪҝ з”ЁгҖӮ
д»Һеӣҫ12еҸҜд»ҘзңӢеҲ°employeesиЎЁеҸӘжңүдёҖдёӘзҙўеј•<emp_no>пјҢйӮЈд№ҲеҰӮжһңжҲ‘们жғіжҢүеҗҚеӯ—жҗңзҙўдёҖдёӘдәәпјҢе°ұеҸӘиғҪе…ЁиЎЁжү«жҸҸдәҶпјҡ
EXPLAIN SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido'; +----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+ | 1 | SIMPLE | employees | ALL | NULL | NULL | NULL | NULL | 300024 | Using where | +----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
еҰӮжһңйў‘з№ҒжҢүеҗҚеӯ—жҗңзҙўе‘ҳе·ҘпјҢиҝҷж ·жҳҫ然ж•ҲзҺҮеҫҲдҪҺпјҢеӣ жӯӨжҲ‘们еҸҜд»ҘиҖғиҷ‘е»әзҙўеј•гҖӮжңүдёӨз§ҚйҖүжӢ©пјҢе»ә<first_name>жҲ–<first_name, last_name>пјҢзңӢдёӢдёӨдёӘзҙўеј•зҡ„йҖүжӢ©жҖ§пјҡ
SELECT count(DISTINCT(first_name))/count(*) AS Selectivity FROM employees.employees; +-------------+ | Selectivity | +-------------+ | 0.0042 | +-------------+ SELECT count(DISTINCT(concat(first_name, last_name)))/count(*) AS Selectivity FROM employees.employees; +-------------+ | Selectivity | +-------------+ | 0.9313 | +-------------+
<first_name>жҳҫ然йҖүжӢ©жҖ§еӨӘдҪҺпјҢ<first_name, last_name>йҖүжӢ©жҖ§еҫҲеҘҪпјҢдҪҶжҳҜfirst_nameе’Ңlast_nameеҠ иө·жқҘй•ҝеәҰдёә30пјҢжңүжІЎжңүе…јйЎҫй•ҝеәҰе’ҢйҖүжӢ©жҖ§зҡ„еҠһжі•пјҹеҸҜд»ҘиҖғиҷ‘з”Ё first_nameе’Ңlast_nameзҡ„еүҚеҮ дёӘеӯ—з¬Ұе»әз«Ӣзҙўеј•пјҢдҫӢеҰӮ<first_name, left(last_name, 3)>пјҢзңӢзңӢе…¶йҖүжӢ©жҖ§пјҡ
SELECT count(DISTINCT(concat(first_name, left(last_name, 3))))/count(*) AS Selectivity FROM employees.employees; +-------------+ | Selectivity | +-------------+ | 0.7879 | +-------------+
йҖүжӢ©жҖ§иҝҳдёҚй”ҷпјҢдҪҶзҰ»0.9313иҝҳжҳҜжңүзӮ№и·қзҰ»пјҢйӮЈд№ҲжҠҠlast_nameеүҚзјҖеҠ еҲ°4пјҡ
SELECT count(DISTINCT(concat(first_name, left(last_name, 4))))/count(*) AS Selectivity FROM employees.employees; +-------------+ | Selectivity | +-------------+ | 0.9007 | +-------------+
иҝҷж—¶йҖүжӢ©жҖ§е·Із»ҸеҫҲзҗҶжғідәҶпјҢиҖҢиҝҷдёӘзҙўеј•зҡ„й•ҝеәҰеҸӘжңү18пјҢжҜ”<first_name, last_name>зҹӯдәҶжҺҘиҝ‘дёҖеҚҠпјҢжҲ‘们жҠҠиҝҷдёӘеүҚзјҖзҙўеј• е»әдёҠпјҡ
ALTER TABLE employees.employees ADD INDEX `first_name_last_name4` (first_name, last_name(4));
жӯӨж—¶еҶҚжү§иЎҢдёҖйҒҚжҢүеҗҚеӯ—жҹҘиҜўпјҢжҜ”иҫғеҲҶжһҗдёҖдёӢдёҺе»әзҙўеј•еүҚзҡ„з»“жһңпјҡ
SHOW PROFILES; +----------+------------+---------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+---------------------------------------------------------------------------------+ | 87 | 0.11941700 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' | | 90 | 0.00092400 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' | +----------+------------+---------------------------------------------------------------------------------+
жҖ§иғҪзҡ„жҸҗеҚҮжҳҜжҳҫи‘—зҡ„пјҢжҹҘиҜўйҖҹеәҰжҸҗй«ҳдәҶ120еӨҡеҖҚгҖӮ
еүҚзјҖзҙўеј•е…јйЎҫзҙўеј•еӨ§е°Ҹе’ҢжҹҘиҜўйҖҹеәҰпјҢдҪҶжҳҜе…¶зјәзӮ№жҳҜдёҚиғҪз”ЁдәҺORDER BYе’ҢGROUP BYж“ҚдҪңпјҢд№ҹдёҚиғҪз”ЁдәҺCovering indexпјҲеҚіеҪ“зҙўеј•жң¬иә«еҢ…еҗ«жҹҘиҜўжүҖйңҖе…ЁйғЁж•°жҚ®ж—¶пјҢдёҚеҶҚи®ҝй—®ж•°жҚ®ж–Ү件жң¬иә«пјүгҖӮ
InnoDBзҡ„дё»й”®йҖүжӢ©дёҺжҸ’е…ҘдјҳеҢ–
еңЁдҪҝз”ЁInnoDBеӯҳеӮЁеј•ж“Һж—¶пјҢеҰӮжһңжІЎжңүзү№еҲ«зҡ„йңҖиҰҒпјҢиҜ·ж°ёиҝңдҪҝз”ЁдёҖдёӘдёҺдёҡеҠЎж— е…ізҡ„иҮӘеўһеӯ—ж®өдҪңдёәдё»й”®гҖӮ
з»ҸеёёзңӢеҲ°жңүеё–еӯҗжҲ–еҚҡе®ўи®Ёи®әдё»й”®йҖүжӢ©й—®йўҳпјҢжңүдәәе»әи®®дҪҝз”ЁдёҡеҠЎж— е…ізҡ„иҮӘеўһдё»й”®пјҢжңүдәәи§үеҫ—жІЎжңүеҝ…иҰҒпјҢе®Ңе…ЁеҸҜд»ҘдҪҝз”ЁеҰӮеӯҰеҸ·жҲ–иә«д»ҪиҜҒеҸ·иҝҷз§Қе”ҜдёҖеӯ—ж®өдҪңдёәдё»й”®гҖӮ дёҚи®әж”ҜжҢҒе“Әз§Қи®әзӮ№пјҢеӨ§еӨҡж•°и®әжҚ®йғҪжҳҜдёҡеҠЎеұӮйқўзҡ„гҖӮеҰӮжһңд»Һж•°жҚ®еә“зҙўеј•дјҳеҢ–и§’еәҰзңӢпјҢдҪҝз”ЁInnoDBеј•ж“ҺиҖҢдёҚдҪҝз”ЁиҮӘеўһдё»й”®з»қеҜ№жҳҜдёҖдёӘзіҹзі•зҡ„дё»ж„ҸгҖӮ
дёҠж–Үи®Ёи®әиҝҮInnoDBзҡ„зҙўеј•е®һзҺ°пјҢInnoDBдҪҝз”ЁиҒҡйӣҶзҙўеј•пјҢж•°жҚ®и®°еҪ•жң¬иә«иў«еӯҳдәҺдё»зҙўеј•пјҲдёҖйў—B+Treeпјүзҡ„еҸ¶еӯҗиҠӮзӮ№дёҠгҖӮиҝҷе°ұиҰҒжұӮеҗҢдёҖдёӘеҸ¶еӯҗиҠӮ зӮ№еҶ…пјҲеӨ§е°ҸдёәдёҖдёӘеҶ…еӯҳйЎөжҲ–зЈҒзӣҳйЎөпјүзҡ„еҗ„жқЎж•°жҚ®и®°еҪ•жҢүдё»й”®йЎәеәҸеӯҳж”ҫпјҢеӣ жӯӨжҜҸеҪ“жңүдёҖжқЎж–°зҡ„и®°еҪ•жҸ’е…Ҙж—¶пјҢMySQLдјҡж №жҚ®е…¶дё»й”®е°Ҷе…¶жҸ’е…ҘйҖӮеҪ“зҡ„иҠӮзӮ№е’ҢдҪҚзҪ®пјҢеҰӮжһң йЎөйқўиҫҫеҲ°иЈ…иҪҪеӣ еӯҗпјҲInnoDBй»ҳи®Өдёә15/16пјүпјҢеҲҷејҖиҫҹдёҖдёӘж–°зҡ„йЎөпјҲиҠӮзӮ№пјүгҖӮ
еҰӮжһңиЎЁдҪҝз”ЁиҮӘеўһдё»й”®пјҢйӮЈд№ҲжҜҸж¬ЎжҸ’е…Ҙж–°зҡ„и®°еҪ•пјҢи®°еҪ•е°ұдјҡйЎәеәҸж·»еҠ еҲ°еҪ“еүҚзҙўеј•иҠӮзӮ№зҡ„еҗҺз»ӯдҪҚзҪ®пјҢеҪ“дёҖйЎөеҶҷж»ЎпјҢе°ұдјҡиҮӘеҠЁејҖиҫҹдёҖдёӘж–°зҡ„йЎөгҖӮеҰӮдёӢеӣҫжүҖзӨәпјҡ
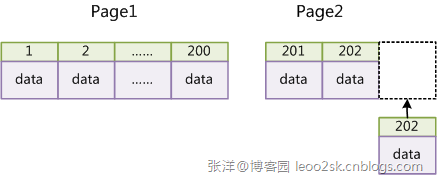
еӣҫ13
иҝҷж ·е°ұдјҡеҪўжҲҗдёҖдёӘзҙ§еҮ‘зҡ„зҙўеј•з»“жһ„пјҢиҝ‘дјјйЎәеәҸеЎ«ж»ЎгҖӮз”ұдәҺжҜҸж¬ЎжҸ’е…Ҙж—¶д№ҹдёҚйңҖиҰҒ移еҠЁе·Іжңүж•°жҚ®пјҢеӣ жӯӨж•ҲзҺҮеҫҲй«ҳпјҢд№ҹдёҚдјҡеўһеҠ еҫҲеӨҡејҖй”ҖеңЁз»ҙжҠӨзҙўеј•дёҠгҖӮ
еҰӮжһңдҪҝз”ЁйқһиҮӘеўһдё»й”®пјҲеҰӮжһңиә«д»ҪиҜҒеҸ·жҲ–еӯҰеҸ·зӯүпјүпјҢз”ұдәҺжҜҸж¬ЎжҸ’е…Ҙдё»й”®зҡ„еҖјиҝ‘дјјдәҺйҡҸжңәпјҢеӣ жӯӨжҜҸж¬Ўж–°зәӘеҪ•йғҪиҰҒиў«жҸ’еҲ°зҺ°жңүзҙўеј•йЎөеҫ—дёӯй—ҙжҹҗдёӘдҪҚзҪ®пјҡ
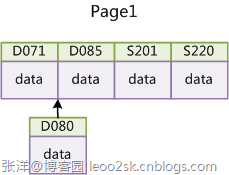
еӣҫ14
жӯӨж—¶MySQLдёҚеҫ—дёҚдёәдәҶе°Ҷж–°и®°еҪ•жҸ’еҲ°еҗҲйҖӮдҪҚзҪ®иҖҢ移еҠЁж•°жҚ®пјҢз”ҡиҮізӣ®ж ҮйЎөйқўеҸҜиғҪе·Із»Ҹиў«еӣһеҶҷеҲ°зЈҒзӣҳдёҠиҖҢд»Һзј“еӯҳдёӯжё…жҺүпјҢжӯӨж—¶еҸҲиҰҒд»ҺзЈҒзӣҳдёҠиҜ»еӣһжқҘпјҢиҝҷеўһеҠ дәҶ еҫҲеӨҡејҖй”ҖпјҢеҗҢж—¶йў‘з№Ғзҡ„移еҠЁгҖҒеҲҶйЎөж“ҚдҪңйҖ жҲҗдәҶеӨ§йҮҸзҡ„зўҺзүҮпјҢеҫ—еҲ°дәҶдёҚеӨҹзҙ§еҮ‘зҡ„зҙўеј•з»“жһ„пјҢеҗҺз»ӯдёҚеҫ—дёҚйҖҡиҝҮOPTIMIZE TABLEжқҘйҮҚе»ә表并дјҳеҢ–еЎ«е……йЎөйқўгҖӮ
еӣ жӯӨпјҢеҸӘиҰҒеҸҜд»ҘпјҢиҜ·е°ҪйҮҸеңЁInnoDBдёҠйҮҮз”ЁиҮӘеўһеӯ—ж®өеҒҡдё»й”®гҖӮ
В
еҺҹж–Ү жө…и°Ҳmysqlзҙўеј•иғҢеҗҺзҡ„ж•°жҚ®з»“жһ„еҸҠз®—жі• пјҡhttp://blog.linezing.com/2011/07/%E6%B5%85%E8%B0%88mysql%E7%B4%A2%E5%BC%95%E8%83%8C%E5%90%8E%E7%9A%84%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%8F%8A%E7%AE%97%E6%B3%95


- 2012-07-27 10:42
- жөҸи§Ҳ 829
- иҜ„и®ә(0)
- еҲҶзұ»:йқһжҠҖжңҜ
- жҹҘзңӢжӣҙеӨҡ
еҸ‘иЎЁиҜ„и®ә

-
MySQL дёӯзҡ„йҮҚеҒҡж—Ҙеҝ—пјҢеӣһж»ҡж—Ҙеҝ— пјҢд»ҘеҸҠдәҢиҝӣеҲ¶ж—Ҙеҝ—зҡ„з®ҖеҚ•жҖ»з»“
2018-06-06 17:44 1207ImportNewВ 5еӨ©еүҚ пјҲзӮ№еҮ»дёҠж–№е…¬дј—еҸ·пјҢеҸҜеҝ«йҖҹе…іжіЁпјү ... -
mysql и®ҫзҪ®еӯ—з¬ҰйӣҶ дёӯж–Үд№ұз Ғ
2016-02-04 15:45 2929дёҖгҖҒзҷ»еҪ•MySQLжҹҘзңӢз”ЁSHOW VARIABLES LIK ... -
mysql slow logжҺ§еҲ¶
2014-08-28 10:15 5377еҸӮиҖғе®ҳж–№ж–ҮжЎЈпјҡhttp://dev.mysql.com/do ... -
MySQLж•°жҚ®еә“InnoDBеӯҳеӮЁеј•ж“Һ Buffer Pool Flush ListиҜҰи§Ј
2014-08-21 10:36 1268еҺҹж–Үпјҡhttp://www.zhdba.com/mysqlo ... -
Percona-Serverе®үиЈ…и®°еҪ•
2014-07-28 23:05 1436жң¬ж–ҮжЎЈи®°еҪ•е®үиЈ…Percona-ServerејҖеҸ‘зҺҜеўғпјҢйқһз”ҹдә§ ... -
mysqlеҲӣе»әз”ЁжҲ·жқғйҷҗ
2014-07-11 17:01 795mysql жқғйҷҗеҰӮдёӢпјҡ root@localhost : ... -
mysql groupжөӢиҜ•и„ҡжң¬
2014-06-25 15:38 881sqlж•°жҚ®иҜӯеҸҘпјҡ CREATE TABLE `access ... -
mysqlжҖ§иғҪдјҳеҢ–д№Ӣ show profile
2014-06-20 10:46 2472еҫҲжјӮдә®зҡ„з»“жһң,жІЎжңүcreating sort index ... -
MYSQL INNODBдёӯGAP LOCKеј•иө·жӯ»й”Ғзҡ„й—®йўҳ
2014-06-06 13:08 2332е…ҲдәҶи§ЈдёҖдёӢд»Җд№ҲжҳҜGAP LOCK еңЁINNODBдёӯпјҢrec ... -
MySQLеҮәзҺ°Waiting for table metadata lockзҡ„еңәжҷҜжө…жһҗ
2014-04-23 14:27 726еҺҹж–Үпјҡhttp://ctripmysqldba.iteye ... -
mysql зҙўеј•еҺҹзҗҶ
2014-03-27 20:02 513еҜ№дәҺиҝҷжқЎSQL: from message where ... -
mysqlдёӯgroupзҡ„е®һзҺ°
2014-01-24 10:31 774еҗҢеӯҰй—®еҲ°group byзҡ„е®һзҺ°п ... -
MySQL Innodbж—Ҙеҝ—жңәеҲ¶ж·ұе…ҘеҲҶжһҗ
2013-12-02 22:28 01.1.В LogВ &В Checkpoint In ... -
дјҳеҢ–дёҙж—¶иЎЁдҪҝз”ЁпјҢSQLиҜӯеҸҘжҖ§иғҪжҸҗеҚҮ100еҖҚ
2013-12-02 22:25 968гҖҗй—®йўҳзҺ°иұЎгҖ‘ зәҝдёҠmysqlж•°жҚ®еә“зҲҶеҮәдёҖдёӘж…ўжҹҘиҜўпјҢDBAи§Ӯ ... -
д№ҹиҜҙеҝ«йҖҹе…ій—ӯMySQL/InnoDB
2013-09-21 13:56 814еҺҹж–Үпјҡhttp://www.orczhou.com/ind ... -
е…ідәҺmysqlдјҳеҢ–дёҖдәӣжҖ»з»“
2013-09-21 08:41 1093жңҖиҝ‘еңЁеҒҡmysqlж•°жҚ®еә“зҡ„д ... -
robbinи°ҲMySQL InnoDBжҖ§иғҪи°ғж•ҙзҡ„дёҖзӮ№е®һи·ө
2013-09-21 08:13 780еӣ дёәJavaEyeзҪ‘з«ҷзҡ„ж•°жҚ®еә ... -
mysqlж–ҮжЎЈйӣҶеҗҲ
2013-09-05 12:11 872зҗҶи§ЈMySQLвҖ”вҖ”зҙўеј•дёҺдјҳеҢ– зҗҶи§ЈMySQLвҖ”вҖ”жһ¶жһ„дёҺжҰӮеҝө ... -
mysql binlogз»ҶиҠӮ
2013-09-05 12:06 1067еҺҹжқҘmysql binlogеҶ…е®№жҳҜе…ҲдҝқеӯҳеңЁtrx_cacheдёӯ ... -
MySQLеҰӮдҪ•йҒҝе…ҚдҪҝз”Ёswap
2013-09-04 09:52 1095еҺҹж–Үпјҡ http://www.taobaodba.com/ ...
зӣёе…іжҺЁиҚҗ
scratchе°‘е„ҝзј–зЁӢйҖ»иҫ‘жҖқз»ҙжёёжҲҸжәҗз Ғ-еҹҺе ЎжҲҳдәү.zip
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮжЎЈжұҮйӣҶдәҶжқҘиҮӘеӯ—иҠӮи·іеҠЁгҖҒи…ҫи®ҜгҖҒйҮ‘еұұWPSгҖҒи·ҹи°ҒеӯҰе’ҢзҷҫеәҰзӯүеӨ§еҺӮзҡ„Goе·ҘзЁӢеёҲйқўиҜ•йўҳпјҢж¶өзӣ–е№ҝжіӣзҡ„жҠҖжңҜйўҶеҹҹгҖӮдё»иҰҒеҢ…жӢ¬GoиҜӯиЁҖзү№жҖ§пјҲеҰӮgoroutineи°ғеәҰгҖҒchannelжңәеҲ¶пјүгҖҒж“ҚдҪңзі»з»ҹпјҲиҝӣзЁӢй—ҙйҖҡдҝЎгҖҒзәҝзЁӢи°ғеәҰпјүгҖҒи®Ўз®—жңәзҪ‘з»ңпјҲTCP/IPеҚҸи®®ж ҲгҖҒHTTPеҚҸи®®пјүгҖҒж•°жҚ®з»“жһ„дёҺз®—жі•пјҲжҺ’еәҸз®—жі•гҖҒLRUзј“еӯҳпјүгҖҒж•°жҚ®еә“пјҲMySQLзҙўеј•дјҳеҢ–гҖҒRedisеҶ…йғЁжңәеҲ¶пјүгҖҒеҲҶеёғејҸзі»з»ҹпјҲиҙҹиҪҪеқҮиЎЎгҖҒжңҚеҠЎеҸ‘зҺ°пјүзӯүж–№йқўзҡ„зҹҘиҜҶзӮ№гҖӮйҖҡиҝҮиҝҷдәӣй—®йўҳпјҢдёҚд»…иҖғеҜҹеә”иҒҳиҖ…зҡ„зҗҶи®әеҹәзЎҖпјҢиҝҳжөӢиҜ•е…¶е®һйҷ…йЎ№зӣ®з»ҸйӘҢе’ҢжҠҖжңҜж·ұеәҰгҖӮ йҖӮеҗҲдәәзҫӨпјҡжңүдёҖе®ҡGoиҜӯиЁҖзј–зЁӢз»ҸйӘҢе’Ңи®Ўз®—жңәеҹәзЎҖзҹҘиҜҶзҡ„ејҖеҸ‘иҖ…пјҢзү№еҲ«жҳҜеҮҶеӨҮеә”иҒҳдә’иҒ”зҪ‘еӨ§еҺӮзҡ„дёӯзә§еҸҠд»ҘдёҠж°ҙе№ізҡ„еҗҺз«Ҝе·ҘзЁӢеёҲжҲ–е…Ёж Ҳе·ҘзЁӢеёҲгҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж Үпјҡв‘ её®еҠ©жұӮиҒҢиҖ…е…ЁйқўеӨҚд№ GoиҜӯиЁҖеҸҠе…¶зӣёе…ійўҶеҹҹзҡ„ж ёеҝғжҰӮеҝөпјӣв‘ЎдёәйқўиҜ•е®ҳжҸҗдҫӣжңүд»·еҖјзҡ„еҸӮиҖғйўҳзӣ®пјҢзЎ®дҝқеҖҷйҖүдәәе…·еӨҮи§ЈеҶіеӨҚжқӮй—®йўҳзҡ„иғҪеҠӣпјӣв‘ўжҢҮеҜје·ҘзЁӢеёҲж·ұе…ҘзҗҶ解并жҺҢжҸЎдјҒдёҡзә§еә”з”ЁејҖеҸ‘жүҖйңҖзҡ„е…ій”®жҠҖиғҪгҖӮ йҳ…иҜ»е»әи®®пјҡз”ұдәҺйўҳзӣ®иҰҶзӣ–йқўе№ҝдё”йҡҫеәҰиҫғй«ҳпјҢе»әи®®иҜ»иҖ…з»“еҗҲиҮӘиә«жғ…еҶөйҖүжӢ©йҮҚзӮ№еӨҚд№ ж–№еҗ‘пјҢеҗҢж—¶й…ҚеҗҲе®һйҷ…зј–з Ғз»ғд№ еҠ ж·ұзҗҶи§ЈгҖӮеҜ№дәҺжҜҸдёӘзҹҘиҜҶзӮ№пјҢдёҚд»…иҰҒи®°дҪҸзӯ”жЎҲпјҢжӣҙиҰҒзҗҶи§ЈиғҢеҗҺзҡ„еҺҹзҗҶпјҢиҝҷж ·жүҚиғҪеңЁйқўиҜ•дёӯзҒөжҙ»еә”еҜ№еҗ„з§ҚеҸҳдҪ“й—®йўҳгҖӮ
scratchе°‘е„ҝзј–зЁӢйҖ»иҫ‘жҖқз»ҙжёёжҲҸжәҗз Ғ-е Ўеһ’д№ӢеӨңпјҲеҗғйёЎжёёжҲҸпјү.zip
е°‘е„ҝзј–зЁӢscratchйЎ№зӣ®жәҗд»Јз Ғж–Ү件жЎҲдҫӢзҙ жқҗ-жҙҫ.zip
scratchе°‘е„ҝзј–зЁӢйҖ»иҫ‘жҖқз»ҙжёёжҲҸжәҗз Ғ-Scratch еҶ’йҷ©.zip
2025 йЈһзү№иҲөжңә, ArduinoзүҲжң¬
scratchе°‘е„ҝзј–зЁӢйҖ»иҫ‘жҖқз»ҙжёёжҲҸжәҗз Ғ-иәІйҒҝ.zip
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮиҜҰз»Ҷд»Ӣз»ҚдәҶеҲ©з”ЁPFC5.0иҝӣиЎҢзәӨз»ҙж··еҮқеңҹдёүзӮ№ејҜжӣІжЁЎжӢҹзҡ„ж–№жі•гҖӮйҰ–е…ҲпјҢдҪңиҖ…еұ•зӨәдәҶеҰӮдҪ•йҖҡиҝҮе®ҡд№үзәӨз»ҙзҡ„дҪ“з§Ҝеҗ«йҮҸгҖҒй•ҝеәҰгҖҒеҚҠеҫ„е’ҢеҲҡеәҰзӯүе…ій”®еҸӮж•°жқҘжһ„е»әзәӨз»ҙзҪ‘з»ңгҖӮжҺҘзқҖпјҢжҸҸиҝ°дәҶдёүзӮ№ејҜжӣІеҠ иҪҪзҡ„е…·дҪ“е®һзҺ°ж–№ејҸпјҢеҢ…жӢ¬еҠ иҪҪйҖҹзҺҮжҺ§еҲ¶е’Ңз»ҲжӯўжқЎд»¶и®ҫе®ҡгҖӮжңҖеҗҺпјҢжҸҗдҫӣдәҶеҗҺеӨ„зҗҶж–№жі•пјҢеҰӮз»ҳеҲ¶е№¶еҜјеҮәеҠӣ-дҪҚ移жӣІзәҝеӣҫпјҢд»ҘдҫҝдәҺеҲҶжһҗжқҗж–ҷз ҙеқҸжңәеҲ¶гҖӮж–Үдёӯиҝҳз»ҷеҮәдәҶиӢҘе№Іе®һз”Ёе»әи®®пјҢеҰӮзәӨз»ҙеҚҠеҫ„зҡ„йҖүжӢ©иҢғеӣҙгҖҒеҠ иҪҪйҖҹзҺҮзҡ„еҲқе§ӢеҖјд»ҘеҸҠдёҚеҗҢзұ»еһӢзәӨз»ҙзҡ„жҺҘи§ҰжЁЎеһӢйҖүжӢ©гҖӮ йҖӮеҗҲдәәзҫӨпјҡд»ҺдәӢжқҗж–ҷ科еӯҰе°Өе…¶жҳҜж··еҮқеңҹжқҗж–ҷз ”з©¶зҡ„дё“дёҡдәәеЈ«пјҢд»ҘеҸҠеҜ№зҰ»ж•Је…ғжі•е’Ңж•°еҖјжЁЎжӢҹж„ҹе…ҙи¶Јзҡ„з§‘з ”е·ҘдҪңиҖ…гҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж ҮпјҡйҖӮз”ЁдәҺеёҢжңӣж·ұе…ҘдәҶи§ЈзәӨз»ҙж··еҮқеңҹеҠӣеӯҰжҖ§иғҪзҡ„з ”з©¶дәәе‘ҳпјҢж—ЁеңЁеё®еҠ©д»–们жҺҢжҸЎPFC5.0иҪҜ件зҡ„ж“ҚдҪңжҠҖе·§пјҢдјҳеҢ–жЁЎжӢҹеҸӮж•°и®ҫзҪ®пјҢжҸҗй«ҳе®һйӘҢж•ҲзҺҮгҖӮ е…¶д»–иҜҙжҳҺпјҡж–ҮдёӯжҸҗдҫӣзҡ„д»Јз ҒзүҮж®өеҸҜд»ҘзӣҙжҺҘеә”з”ЁдәҺе®һйҷ…йЎ№зӣ®дёӯпјҢеҗҢж—¶йҷ„еёҰдәҶдёҖдәӣе®һи·өз»ҸйӘҢеҲҶдә«пјҢжңүеҠ©дәҺеҲқеӯҰиҖ…еҝ«йҖҹе…Ҙ门并йҒҝе…Қеёёи§Ғй”ҷиҜҜгҖӮ
е°‘е„ҝзј–зЁӢscratchйЎ№зӣ®жәҗд»Јз Ғж–Ү件жЎҲдҫӢзҙ жқҗ-з”ҹеӯҳV1пјҲжңүBAGпјү.zip
е°‘е„ҝзј–зЁӢscratchйЎ№зӣ®жәҗд»Јз Ғж–Ү件жЎҲдҫӢзҙ жқҗ-жҠ«иҗЁжңәеҷЁдәә.zip
е°‘е„ҝзј–зЁӢscratchйЎ№зӣ®жәҗд»Јз Ғж–Ү件жЎҲдҫӢзҙ жқҗ-ж°”зҗғж»‘йӣӘжқҝ.zip
е°‘е„ҝзј–зЁӢscratchйЎ№зӣ®жәҗд»Јз Ғж–Ү件жЎҲдҫӢзҙ жқҗ-дҪҝе‘ҪеҸ¬е”ӨпјҲиӢҸиҒ”жҸ’ж——пјү.zip
1. GPIOжЁЎжӢҹI2C е®һжҲҳйЎ№зӣ®пјҢж №жҚ®жӯЈзӮ№еҺҹеӯҗ STM32F407ZGT6 иҝӣиЎҢжӣҙж”№пјӣ 2. еҸҜйҖӮй…ҚSTM32гҖҒGD32гҖҒHC32зӯүMCUпјӣ
scratchе°‘е„ҝзј–зЁӢйҖ»иҫ‘жҖқз»ҙжёёжҲҸжәҗз Ғ-зҷҫзұіеҶІеҲә.zip
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮжЎЈжұҮжҖ»дәҶи“қжЎҘжқҜеҺҶе№ҙиҜ•йўҳеҸҠз»ғд№ иө„жәҗпјҢж¶өзӣ–зј–зЁӢзұ»иҜ•йўҳзІҫйҖүгҖҒ硬件дёҺеҚ•зүҮжңәиҜ•йўҳгҖҒз»ғд№ иө„жәҗдёҺйўҳеә“д»ҘеҸҠеӨҮиҖғе»әи®®гҖӮзј–зЁӢзұ»иҜ•йўҳзІҫйҖүеҢ…жӢ¬еҹәзЎҖз®—жі•йўҳпјҲеҰӮж•°з»„жұӮе’ҢгҖҒиҙЁеӣ ж•°еҲҶи§ЈпјүгҖҒз»Ҹе…ёз®—жі•жЎҲдҫӢпјҲеҰӮжңҖеӨ§еӯҗеәҸеҲ—е’ҢгҖҒе…°йЎҝиҡӮиҡҒжЁЎжӢҹпјүе’Ңж•°жҚ®з»“жһ„еә”з”ЁпјҲеҰӮеӯ—з¬Ұе…ЁжҺ’еҲ—пјүгҖӮ硬件дёҺеҚ•зүҮжңәиҜ•йўҳдё»иҰҒж¶үеҸҠе®ўи§ӮйўҳиҖғзӮ№пјҢеҰӮBUCKз”өи·Ҝе’Ңз”өжәҗи®ҫи®ЎгҖӮз»ғд№ иө„жәҗдёҺйўҳеә“йғЁеҲҶд»Ӣз»ҚдәҶзңҹйўҳе№іеҸ°пјҲеҰӮDotcppгҖҒCSDNдё“йўҳпјүе’Ңдё“йЎ№и®ӯз»ғеҢ…пјҲеҰӮPythonйўҳеә“гҖҒJavaзҷҫйўҳйӣҶгҖҒC++зңҹйўҳи§ЈжһҗпјүгҖӮеӨҮиҖғе»әи®®еҲҶдёәеҲҶйҳ¶ж®өз»ғд№ пјҲж–°жүӢйҳ¶ж®өгҖҒиҝӣйҳ¶жҸҗеҚҮпјүе’ҢжЁЎжӢҹе®һжҲҳпјҲеҰӮдҪҝз”ЁDotcppдј°еҲҶзі»з»ҹиҝӣиЎҢйҷҗж—¶и®ӯз»ғпјүпјҢејәи°ғжҢүе№ҙд»Ҫе’Ңз»„еҲ«еҲҶзұ»з»ғд№ пјҢејәеҢ–д»Јз Ғе®һзҺ°дёҺи°ғиҜ•иғҪеҠӣгҖӮ; йҖӮеҗҲдәәзҫӨпјҡеҮҶеӨҮеҸӮеҠ и“қжЎҘжқҜз«һиөӣзҡ„еӯҰз”ҹеҸҠзј–зЁӢзҲұеҘҪиҖ…гҖӮ; дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж Үпјҡв‘ й’ҲеҜ№дёҚеҗҢзј–зЁӢиҜӯиЁҖе’ҢйҡҫеәҰзә§еҲ«зҡ„йўҳзӣ®иҝӣиЎҢдё“йЎ№и®ӯз»ғпјӣв‘ЎйҖҡиҝҮеҺҶе№ҙзңҹйўҳе’ҢжЁЎжӢҹе®һжҲҳжҸҗй«ҳи§ЈйўҳйҖҹеәҰе’ҢеҮҶзЎ®жҖ§пјӣв‘ўжҺҢжҸЎз®—жі•и®ҫи®ЎгҖҒж•°жҚ®з»“жһ„еә”з”ЁеҸҠ硬件еҹәзЎҖзҹҘиҜҶгҖӮ; йҳ…иҜ»е»әи®®пјҡжӯӨж–ҮжЎЈжҸҗдҫӣдәҶдё°еҜҢзҡ„иҜ•йўҳе’Ңз»ғд№ иө„жәҗпјҢе»әи®®ж №жҚ®иҮӘиә«ж°ҙе№ійҖүжӢ©еҗҲйҖӮзҡ„йўҳзӣ®иҝӣиЎҢз»ғд№ пјҢ并结еҗҲзңҹйўҳе№іеҸ°зҡ„дј°еҲҶзі»з»ҹе’ҢзӨҫеҢәејҖжәҗд»Јз ҒиҝӣиЎҢеҜ№жҜ”дјҳеҢ–пјҢйҖҗжӯҘжҸҗеҚҮзј–зЁӢиғҪеҠӣе’Ңз«һиөӣж°ҙе№ігҖӮ
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮиҜҰз»Ҷд»Ӣз»ҚдәҶ30kWеӮЁиғҪPCSпјҲз”өеҠӣиҪ¬жҚўзі»з»ҹпјүеҺҹзҗҶеӣҫзҡ„и®ҫи®ЎиҰҒзӮ№еҸҠе…¶йҮҸдә§еҢ–иҝҮзЁӢдёӯйңҖиҰҒжіЁж„Ҹзҡ„жҠҖжңҜз»ҶиҠӮгҖӮйҰ–е…Ҳйҳҗиҝ°дәҶеӮЁиғҪPCSзҡ„еҹәжң¬жҰӮеҝөе’ҢйҮҚиҰҒжҖ§пјҢжҺҘзқҖж·ұе…ҘжҺўи®ЁдәҶдё»жӢ“жү‘з»“жһ„зҡ„йҖүжӢ©пјҢзү№еҲ«жҳҜеҸҢзә§ејҸз»“жһ„зҡ„дјҳеҠҝд»ҘеҸҠ关键组件еҰӮIGBTзҡ„й©ұеҠЁж—¶еәҸй…ҚзҪ®гҖӮйҡҸеҗҺи®Ёи®әдәҶжҺ§еҲ¶з®—жі•зҡ„жҷәиғҪеҢ–ж”№иҝӣпјҢеҢ…жӢ¬еҠ е…ҘеүҚйҰҲиЎҘеҒҝд»ҘжҸҗй«ҳзі»з»ҹзҡ„зЁіе®ҡжҖ§гҖӮжӯӨеӨ–пјҢиҝҳејәи°ғдәҶEMCи®ҫи®ЎгҖҒPCBеёғеұҖгҖҒе…ғ件йҖүжӢ©зӯүж–№йқўзҡ„жіЁж„ҸдәӢйЎ№пјҢ并еҲҶдә«дәҶдёҖдәӣе®һйҷ…з”ҹдә§дёӯйҒҮеҲ°зҡ„й—®йўҳеҸҠи§ЈеҶіж–№жЎҲгҖӮжңҖеҗҺжҸҗеҲ°дәҶиҮӘеҠЁеҢ–жөӢиҜ•ж–№жі•е’Ңж•Јзғӯз®ЎзҗҶзӯ–з•ҘпјҢзЎ®дҝқдә§е“ҒеңЁеҗ„з§ҚзҺҜеўғдёӢзҡ„еҸҜйқ иҝҗиЎҢгҖӮ йҖӮеҗҲдәәзҫӨпјҡд»ҺдәӢеӮЁиғҪзі»з»ҹи®ҫи®ЎгҖҒз”өеҠӣз”өеӯҗдә§е“Ғз ”еҸ‘зҡ„е·ҘзЁӢеёҲе’ҢжҠҖжңҜдәәе‘ҳгҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж Үпјҡеё®еҠ©иҜ»иҖ…жҺҢжҸЎ30kWеӮЁиғҪPCSд»ҺеҺҹзҗҶеӣҫи®ҫи®ЎеҲ°йҮҸдә§е®һж–Ҫзҡ„е…ЁжөҒзЁӢе…ій”®жҠҖжңҜпјҢжҸҗеҚҮдә§е“Ғзҡ„жҖ§иғҪе’ҢеҸҜйқ жҖ§пјҢйҒҝе…Қеёёи§Ғй”ҷиҜҜгҖӮ е…¶д»–иҜҙжҳҺпјҡж–ҮдёӯжҸҗдҫӣдәҶе…·дҪ“зҡ„д»Јз ҒзүҮж®өе’Ңе®һи·өз»ҸйӘҢпјҢжңүеҠ©дәҺзҗҶи§Је’Ңеә”з”Ёзӣёе…ізҗҶи®әгҖӮ
е°‘е„ҝзј–зЁӢscratchйЎ№зӣ®жәҗд»Јз Ғж–Ү件жЎҲдҫӢзҙ жқҗ-е–·ж°”еҢ…еӨҡеҫ·.zip
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–Үж·ұе…ҘжҺўи®ЁдәҶйҪҝиҪ®е•®еҗҲжҖ§иғҪеҸҠе…¶еҠЁжҖҒзү№жҖ§пјҢзү№еҲ«жҳҜзӣҙйҪҝиҪ®зҡ„еҹәзЎҖеҸӮж•°и®Ўз®—гҖҒжёҗејҖзәҝз»ҳеҲ¶д»ҘеҸҠжҺҘи§ҰеҠӣд»ҝзңҹзҡ„е…·дҪ“е®һзҺ°гҖӮйҰ–е…Ҳд»Ӣз»ҚдәҶйҪҝиҪ®зҡ„еҹәжң¬еҸӮж•°еҰӮжЁЎж•°гҖҒйҪҝж•°гҖҒеҺӢеҠӣи§’зӯүпјҢ并з»ҷеҮәдәҶе…·дҪ“зҡ„и®Ўз®—е®һдҫӢгҖӮжҺҘзқҖиҜҰз»Ҷи®Іи§ЈдәҶеҰӮдҪ•еҲ©з”ЁPythonиҝӣиЎҢжёҗејҖзәҝзҡ„ж•°еӯҰе»ә模并з»ҳеӣҫеұ•зӨәпјҢејәи°ғдәҶиҝҷз§ҚжӣІзәҝеҜ№дәҺзЎ®дҝқйҪҝиҪ®е№ізЁідј еҠЁзҡ„йҮҚиҰҒжҖ§гҖӮ然еҗҺи®Ёи®әдәҶйҪҝиҪ®еңЁе•®еҗҲиҝҮзЁӢдёӯжҺҘи§ҰеҠӣзҡ„еҸҳеҢ–规еҫӢпјҢжҸҗдҫӣдәҶз®ҖеҢ–зҡ„Pythonд»Јз ҒжқҘжЁЎжӢҹиҝҷдёҖзҺ°иұЎгҖӮжңҖеҗҺжҢҮеҮәпјҢеңЁе®һйҷ…е·ҘзЁӢйЎ№зӣ®дёӯеә”еҪ“еҖҹеҠ©дё“дёҡзҡ„иҪҜ件еҢ…еҰӮPyDyжҲ–ADAMSжқҘиҝӣиЎҢжӣҙеҠ зІҫзЎ®зҡ„еҠЁеҠӣеӯҰеҲҶжһҗпјҢеҗҢж—¶иӮҜе®ҡдәҶиҮӘиЎҢзј–еҶҷд»Јз Ғзҡ„д»·еҖјеңЁдәҺиғҪеӨҹжӣҙеҘҪең°зҗҶи§Је’ҢжҺ’жҹҘй—®йўҳгҖӮ йҖӮеҗҲдәәзҫӨпјҡжңәжў°е·ҘзЁӢйўҶеҹҹзҡ„з ”з©¶дәәе‘ҳгҖҒе·ҘзЁӢеёҲд»ҘеҸҠзӣёе…ідё“дёҡзҡ„еӯҰз”ҹгҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж Үпјҡв‘ её®еҠ©иҜ»иҖ…жҺҢжҸЎйҪҝиҪ®еҹәжң¬зҗҶи®әзҹҘиҜҶпјӣв‘ЎжҢҮеҜјиҜ»иҖ…иҝҗз”ЁPythonзј–зЁӢжҠҖиғҪе®ҢжҲҗз®ҖеҚ•зҡ„йҪҝиҪ®жҖ§иғҪеҲҶжһҗд»»еҠЎпјӣв‘ўдёәеҗҺз»ӯж·ұе…Ҙз ”з©¶жҸҗдҫӣжҖқи·Ҝе’ҢжҠҖжңҜж”ҜжҢҒгҖӮ йҳ…иҜ»е»әи®®пјҡз”ұдәҺж–Үдёӯж¶үеҸҠиҫғеӨҡзҡ„дё“дёҡжңҜиҜӯе’Ңж•°еӯҰе…¬ејҸпјҢе»әи®®иҜ»иҖ…жҸҗеүҚеӨҚд№ зӣёе…іеҹәзЎҖзҹҘиҜҶпјҢ并е°қиҜ•иҝҗиЎҢжҸҗдҫӣзҡ„д»Јз ҒзүҮж®өеҠ ж·ұзҗҶи§ЈгҖӮжӯӨеӨ–пјҢеҜ№дәҺжғіиҰҒиҝӣдёҖжӯҘжҺўзҙўиҜҘйўҶеҹҹзҡ„иҜ»иҖ…жқҘиҜҙпјҢеҸҜд»ҘеҸӮиҖғж–Үжң«жҸҗеҲ°зҡ„дё“дёҡе·Ҙе…·еҢ…иҝӣиЎҢжӣҙеӨҚжқӮзҡ„з ”з©¶гҖӮ
е°‘е„ҝзј–зЁӢscratchйЎ№зӣ®жәҗд»Јз Ғж–Ү件жЎҲдҫӢзҙ жқҗ-д»»еҠЎ.zip
е°‘е„ҝзј–зЁӢscratchйЎ№зӣ®жәҗд»Јз Ғж–Ү件жЎҲдҫӢзҙ жқҗ-ж—¶е…үеӨ§зӣ—.zip