在solr中有两种方式实现MoreLikeThis:MoreLikeThisHandler和在SearchHandler中的MoreLikeThisComponent。
两种方式大同小异:
一是:将MoreLikeThis作为一个单独的Handler来处理,体现主体地位。
二是:将MoreLikeThis作为一个组件放到SearchHandler中,为Search加入了MLT的功能,是一种辅助功能。
这里我们借助方法一,来简单阐述MLT的实现步骤。
步骤1:
MLT是根据一篇文档(document)的相关字段进行“相似匹配”,例如:
http://localhost:8983/solr3.5/core0/mlt?q=id:82790&mlt.fl=ti,ab,mcn&mlt.mindf=1&mlt.mintf=1&fl=id,ti,score
这里我们提供的检索式为:q=id:82790,因此其只有唯一一个检索结果。
MLT第一步工作就是根据我们提供的检索式获取文档(document)。
步骤2:
MLT可以看成是一种特殊的检索,只是他的检索式是根据我们提供的一篇文档(document)生成的。
因此关键是怎么生成这个检索式!!!
MoreLikeThis.java
public Query like(int docNum) throws IOException {
if (fieldNames == null) {
// gather list of valid fields from lucene
Collection<String> fields = ir
.getFieldNames(IndexReader.FieldOption.INDEXED);
fieldNames = fields.toArray(new String[fields.size()]);
}
return createQuery(retrieveTerms(docNum));
}
在创建这个“神奇”的query之前,我们先要获得相关的原始term(retrieveTerms)。
public PriorityQueue<Object[]> retrieveTerms(int docNum) throws IOException {
Map<String,Int> termFreqMap = new HashMap<String,Int>();
for (int i = 0; i < fieldNames.length; i++) {
String fieldName = fieldNames[i];
TermFreqVector vector = ir.getTermFreqVector(docNum, fieldName);
// field does not store term vector info
if (vector == null) {
Document d = ir.document(docNum);
String text[] = d.getValues(fieldName);
if (text != null) {
for (int j = 0; j < text.length; j++) {
addTermFrequencies(new StringReader(text[j]), termFreqMap,
fieldName);
}
}
} else {
addTermFrequencies(termFreqMap, vector);
}
}
return createQueue(termFreqMap);
}
首先获取每一个字段的TermFreqVector,然后将其添加到TermFrequencies中,该过程是计算TF的过程,结果存放在map<String,Int>中,key为term,value为该term出现的次数(termFrequencies)。在该过程中需要降噪,及去掉一些无关紧要的term,其判断方式如下:
private boolean isNoiseWord(String term) {
int len = term.length();
if (minWordLen > 0 && len < minWordLen) {
return true;
}
if (maxWordLen > 0 && len > maxWordLen) {
return true;
}
if (stopWords != null && stopWords.contains(term)) {
return true;
}
return false;
}
主要两个依据:
1.term长度必须在minWordLen和maxWordLen范围内;
2.term不应出现在stopWords内。
我们再回到retrieveTerms方法中,他返回的是一个PriorityQueue<Object[]>,因此我们还要将之前创建的map<String,Int>(tf)进行一定的处理(重要)。
“Find words for a more-like-this query former.”
“Create a PriorityQueue from a word->tf map.”
该方法我们遍历所有的term,并取出其tf以及在所有指定字段(例如:mlt.fl=ti,ab,mcn)中最大的df。根据df和当前索引文档数计算idf,然后计算该term的score=tf*idf。
private PriorityQueue<Object[]> createQueue(Map<String,Int> words)
throws IOException {
// have collected all words in doc and their freqs
int numDocs = ir.numDocs();
FreqQ res = new FreqQ(words.size()); // will order words by score
Iterator<String> it = words.keySet().iterator();
while (it.hasNext()) { // for every word
String word = it.next();
int tf = words.get(word).x; // term freq in the source doc
if (minTermFreq > 0 && tf < minTermFreq) {
continue; // filter out words that don't occur enough times in the
// source
}
// go through all the fields and find the largest document frequency
String topField = fieldNames[0];
int docFreq = 0;
for (int i = 0; i < fieldNames.length; i++) {
int freq = ir.docFreq(new Term(fieldNames[i], word));
topField = (freq > docFreq) ? fieldNames[i] : topField;
docFreq = (freq > docFreq) ? freq : docFreq;
}
if (minDocFreq > 0 && docFreq < minDocFreq) {
continue; // filter out words that don't occur in enough docs
}
if (docFreq > maxDocFreq) {
continue; // filter out words that occur in too many docs
}
if (docFreq == 0) {
continue; // index update problem?
}
float idf = similarity.idf(docFreq, numDocs);
float score = tf * idf;
// only really need 1st 3 entries, other ones are for troubleshooting
res.insertWithOverflow(new Object[] {word, // the word
topField, // the top field
Float.valueOf(score), // overall score
Float.valueOf(idf), // idf
Integer.valueOf(docFreq), // freq in all docs
Integer.valueOf(tf)});
}
return res;
}
创建好PriorityQueue后,我们就可以将他转变成之前提到的那个“神奇”的query了。
“Create the More like query from a PriorityQueue”
构建一个BooleanQuery,按照score从大到小取出一定数量的term(maxQueryTerm)进行组建:
private Query createQuery(PriorityQueue<Object[]> q) {
BooleanQuery query = new BooleanQuery();
Object cur;
int qterms = 0;
float bestScore = 0;
while (((cur = q.pop()) != null)) {
Object[] ar = (Object[]) cur;
TermQuery tq = new TermQuery(new Term((String) ar[1], (String) ar[0]));
if (boost) {
if (qterms == 0) {
bestScore = ((Float) ar[2]).floatValue();
}
float myScore = ((Float) ar[2]).floatValue();
tq.setBoost(boostFactor * myScore / bestScore);
}
try {
query.add(tq, BooleanClause.Occur.SHOULD);
} catch (BooleanQuery.TooManyClauses ignore) {
break;
}
qterms++;
if (maxQueryTerms > 0 && qterms >= maxQueryTerms) {
break;
}
}
return query;
}
query.add(tq, BooleanClause.Occur.SHOULD);
这里简单理解就是——取出文档中(相关字段)最重要(tf*idf)的前N个term,组建一个BooleanQuery(Should关联)。
步骤3:
用第二步创建的query进行一次检索,取出得分最高的N篇文档即可。
原理分析:
(1)在MLT中主要是tf、idf,根据score(tf*idf)获取对分类最重要的term,并构建目标Query。
MLT可以理解为:找出给定文档同一类的其他文档。
在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)对于在某一特定文件里的词语 ti 来说,它的重要性可表示为:

以上式子中 ni,j 是该词在文件dj中的出现次数,而分母则是在文件dj中所有字词的出现次数之和。
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:

其中
- |D|:语料库中的文件总数
-
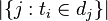 :包含词语ti的文件数目(即
:包含词语ti的文件数目(即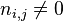 的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用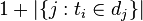
然后
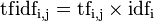
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
(2)根据提供的Query,利用lucene的打分算法,找到相似文档。
Lucene 将信息检索中的Boolean model (BM)和Vector Space Model (VSM)联合起来,实现了自己的评分机制。
具体内容参见:
http://lucene.apache.org/core/old_versioned_docs/versions/2_9_1/api/core/org/apache/lucene/search/Similarity.html
那么有哪些环节可以提高相似检索精度呢?
1.降噪环节需要强化,目前solr中是基于term长度和停用此表联合过滤。
例如将term的最小长度限定成2,即单个字不能作为计算的term,例如:
ab:扩印 ab:胶卷 ab:印机 ab:彩色 ab:传动轴 ab:两根 ab:垫板 ab:手轮 ab:齿轮 ab:从动 ab:传动 ab:设置 ab:自动 ab:电动机 mcn:g03b27/46 ab:电动 ab:上片 ab:上手 ab:支撑 ab:精确度 ab:动机 ab:压片 ab:以及 ab:机构 ab:下压
2.提高分词器的精度,并且对于行业性的业务最好提供行业性的词库,并且进行人工维护。
3.调整、改进相似度算法。
简单的我们试试将term的数量(构建目标query的term数量)进行控制,设置成10。例如:
ab:扩印 ab:胶卷 ab:印机 ab:彩色 ab:传动轴 ab:两根 ab:垫板 ab:手轮 ab:齿轮 ab:从动
以上实例只是一个简单说明,更多调整(挑战)还需要在实践中具体分析。
分享到:





相关推荐
solr-mongo-importer-1.1.0.jar solr-mongo-importer-1.1.0.jar solr-mongo-importer-1.1.0.jar
"apache-solr-dataimportscheduler-1.0.zip"是一个官方发布的54l版本,专门针对Solr 5.x的定时索引生成需求。 数据导入调度器(DataImportScheduler)是这个扩展的核心组件,它允许用户根据预设的时间间隔自动执行...
这个名为"apache-solr-3.5.0.jar"的压缩包包含两个关键组件:`apache-solr-core-3.5.0.jar`和`apache-solr-solrj-3.5.0.jar`,它们对于成功搭建Solr 3.5.0环境至关重要。 1. `apache-solr-core-3.5.0.jar`: 这是...
"apache-solr-dataimportscheduler.jar" 是一个专门为Solr设计的扩展包,用于实现自动化的数据增量更新调度。 首先,我们要理解Solr的数据导入过程。Solr使用DataImportHandler(DIH)来从关系型数据库、XML文件或...
solr-import-export-json最新代码solr-import-export-json最新代码solr-import-export-json最新代码solr-import-export-json最新代码solr-import-export-json最新代码solr-import-export-json最新代码solr-import-...
Solr-9.0.0是该软件的最新版本,此版本可能包含了一些新的特性和改进,比如性能优化、新的查询语法、更强大的分析器等。 在Solr-9.0.0的压缩包中,通常会包含以下组件: 1. **bin** 文件夹:这个目录下有启动和...
Solr-8.11.1是该软件的一个特定版本,包含了最新的特性和改进。 在"solr-8.11.1.tgz"这个压缩包中,我们可以期待找到以下关键组成部分: 1. **Solr WAR 文件**:这是核心的搜索服务器应用程序,通常命名为`solr....
Solr 数据导入调度器(solr-dataimport-scheduler.jar)是一个专门为Apache Solr 7.x版本设计的组件,用于实现数据的定期索引更新。在理解这个知识点之前,我们需要先了解Solr的基本概念以及数据导入处理...
首先,你需要从 Apache 官方网站下载 `solr-8.8.2.tgz` 文件。完成下载后,使用 `tar` 命令解压文件: ``` tar -zxvf solr-8.8.2.tgz ``` 2. **配置环境变量**: 为了方便使用 Solr 的命令行工具,可以将 Solr...
标题中的"solr-dataimporthandler的jar包"指的是 Solr 用于实现数据导入功能的两个核心 JAR 文件: 1. `solr-dataimporthandler-6.0.1.jar`:这是 DIH 的主库,包含了处理数据导入过程所需的类和方法。它提供了数据...
通过深入研究`solr-9.0.0-src.tgz`源码,开发者可以理解Solr的工作原理,定制自己的搜索解决方案,解决特定场景下的性能挑战,并为社区贡献新的功能和优化。同时,这也为学习和研究信息检索、全文搜索、分布式计算等...
标题"solr-7.4.0.zip"表明这是一个包含了Solr 7.4.0版本的压缩包文件,该版本发布于2018年,包含了完整的Solr服务器及其相关组件。 在描述中提到,“solr7需要java8环境”,这是因为Solr的运行依赖于Java平台,特别...
本文将深入探讨mmseg4j在Solr中的应用,以及如何在Solr 6.3版本中集成并使用mmseg4j-solr-2.4.0.jar这个库。 首先,mmseg4j是由李智勇开发的一个基于Java的中文分词工具,它的全称是“Minimum Match Segmentation ...
在"solr6--solr-dataimporthandler-scheduler-1.1"这个项目中,我们关注的重点是DIH的调度功能,也就是如何定期自动更新Solr索引。 DataImportHandler(DIH)是Solr的一个插件,用于从关系型数据库或其他结构化数据...
solr自动更新包
solr 增量更新所需要的包 solr-dataimporthandler-6.5.1 + solr-dataimporthandler-extras-6.5.1 + solr-data-import-scheduler-1.1.2
Solr-dataimportscheduler-1.1.1.jar 是一个针对Apache Solr的扩展插件,主要功能是实现数据的增量导入。Apache Solr是一个流行的开源全文搜索引擎,它提供了高效的搜索和索引能力,广泛应用于网站内容检索、产品...
在 Solr 的生态系统中,`solr-dataimport-scheduler-1.2.jar` 是一个非常重要的组件,它允许用户定时执行数据导入任务,这对于需要定期更新索引的应用场景尤其有用。这个特定的版本 `1.2` 已经被优化以兼容 `Solr ...
下载后会获得名为:solr_core.4.6.0 的zip包,解压后会获得solr-core-4.6.0.jar和 solr-solrj-4.6.0.jar两个文件,搭建solr全文检索环境必须要添加的包
- 将 C:\solr-4.9.0\example\resources\log4j.properties 复制到 C:\apache-tomcat-7.0.53\webapps\solr\WEB-INF\classes 3. **启动与测试** - 启动 Tomcat 服务器 - 在浏览器中访问 http://localhost:8080/solr...