- 浏览: 627311 次
- 性别:

- 来自: 杭州
-

文章分类
- 全部博客 (334)
- java core (12)
- struts2.x (2)
- spring (3)
- hibernate (8)
- jpa (6)
- maven (2)
- osgi (5)
- eclipse (4)
- struts2.x+spring2.x+hibernate 整合 (5)
- ebs (0)
- html (0)
- vaadin (1)
- css (0)
- jquery (0)
- javascript (0)
- svn (1)
- cvs (0)
- axas2.x (0)
- eclipse+maven (9)
- annotation (0)
- 基于OSGi的动态化系统搭建 (1)
- notenet (1)
- jboss eclipse (4)
- eclipse工具 (4)
- jdk1.6+maven3.0.3+nuxeo+svn+felix+cxf+spring+springDM (6)
- spring dm (1)
- Nexus介绍 (1)
- proxool listener (0)
- oracle (4)
- mysql (8)
- 搭建你的全文检索 (1)
- hibernatehibernatehibernate (0)
- cvsearchcvsearch (0)
- mycvseach (0)
- asdfasdfasdf (0)
- propertiey (0)
- hibernate annotation (0)
- libs (0)
- icam (2)
- start 数据库配置 (0)
- jboss (1)
- 让Eclipse启动时显示选择workspace的对话框 (1)
- table表头固定 (1)
- s2s3h4 (0)
- leaver (0)
- mycvsaerchddd (0)
- 关于jboss5.0.1部署 (4)
- bookmarks (0)
- PersistenceUnitDeployment (0)
- mycom (0)
- HKEY_CURRENT_USER = &H80000001 (0)
- syspath (1)
- css div (1)
- Dreamweaver CS5 (0)
- generate (0)
- mysql查看表结构命令 (1)
- LOG IN ERROR EMAIL TO SB (0)
- struts2 handle static resource (1)
- jsf (2)
- log4j (1)
- jbpm4.4 (2)
- down: jbpm4.4 (1)
- jstl1.2 (1)
- spring annotation (1)
- java design pattern (1)
- cache (1)
- ehcache (1)
- 11111 (0)
- myge (0)
- pom.xml (0)
- springquartz (0)
- OpenStack (9)
- hadoop (2)
- nginx (1)
- hadoop openstack (1)
- os (1)
- hadoop-2.6.0 zookeeper-3.4.6 hbase-0.98.9-hadoop2 集群 (5)
- hadoop2.7.0 ha Spark (2)
- tess (0)
- system (1)
- asdf (0)
- hbase (2)
- hbase create table error (1)
- ekl (1)
- gitignore (1)
- gitlab-ci.yml (1)
- shell (1)
- elasticsearch (2)
- Azkaban 3.0+ (1)
- centos用命令 (1)
- hive (1)
- kafka (1)
- CaptureBasic (0)
- CentOS7 (1)
- dev tools (1)
- README.md (1)
- Error (1)
- teamviewerd.service (1)
- scala (1)
- spark (1)
- standard (1)
- gitlab (1)
- IDEA (0)
- ApplicationContext (1)
- 传统数仓 (1)
- redis install (1)
- MYSQL AND COLUME (1)
- java版本选择 (1)
- hue (1)
- npm (1)
- es (1)
- 版本管理 (1)
- 升级npm版本 (1)
- git (1)
- 服务器参数设置 (1)
- 调大 IDEA 编译内存大小 (0)
- CentOS8安装GitLab (1)
- gitlab安装使用 (1)
最新评论
-
ssydxa219:
vim /etc/security/limits.confvi ...
ekl -
Gamehu520:
table中无数据
hbase 出现的问题 -
Xleer0102:
为什么都是只有问没有答,哭晕在厕所
hbase 出现的问题 -
jiajiao_5413:
itext table -
CoderDream:
不完整,缺com.tcs.org.demostic.pub.u ...
struts2.3.1.1+hibernate3.6.9Final+spring3.1.0+proxool+maven+annotation
1. jbpm4.4 测试环境搭建
2. Jbpm4.4+hibernate3.5.4+spring3.0.4+struts2.1. 整合环境搭建
3. jbpm4.4 基础知识
4. 整合过程中常见问题的解决
5. 请假流程例子( s2sh+jbpm )
6. 总结及参考文章
jbpm4.4 测试环境搭建
刚接触 jbpm 第一件事就是快速搭建环境,测试 jbpm 所给的例子。
Jbpm 是一个工作流引擎框架,如果没有 javaEE 开发环境, jbpm 也提供了安装脚本( ant ),
一键提供安装运行环境。同时也可以将 jbpm 整合到 eclipse 或者 myeclipse 中。
快速搭建环境的步骤是:
1. 安装 jbpm-myeclipse 插件,这个插件随 jbpm4.4 一起发布,位于 jbpm-4.4/install/src/gpd 目录下,这个安装好后,就可以在myeclipse 中编辑流程图了(可视化流程设计)
在myeclipse->help->myeclipse configuration centre->software->add site->add from archive file 选择jbpm-4.4/install/src/gpd 下的jbpm-gpd-site.zip
安装这个插件应该注意断网,避免其到网上更新。同时注意:需要选择
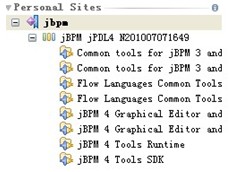 双击每一项,确保每一项被加入到了
双击每一项,确保每一项被加入到了
(说明:事实上不用选完,带source 的部件不用选择,为了省事就全部选择了)
提示:如果安装时不断网,jbpm 插件会自动到网上更新。同时会弹出一个错误窗口,安装速度异常缓慢。安装完成后,myeclipse 的references 菜单会变得面目全非。
2. 搭建 jbpm 运行环境。
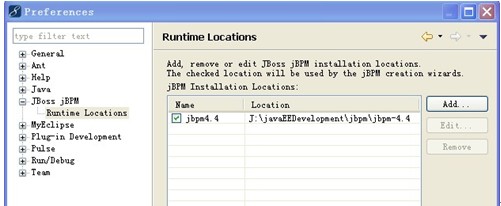
3 .然后配置jpdl 支持
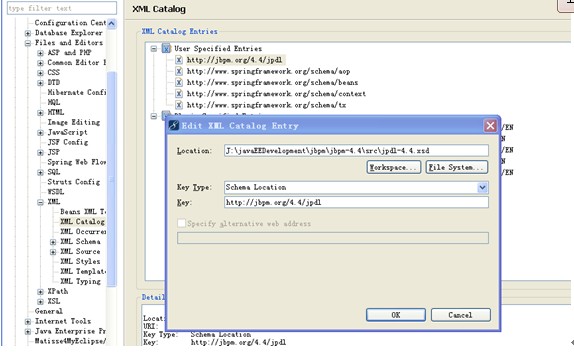
4. 确定是否配置jbpm 正确
在myeclipse->new->other->
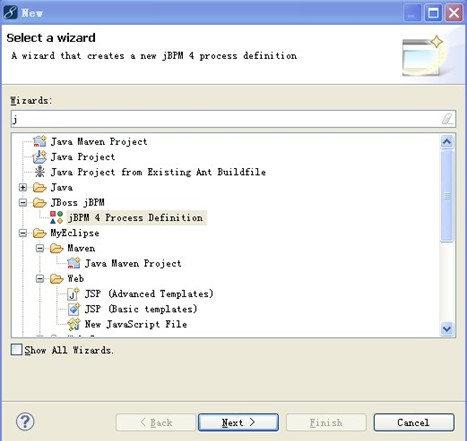
关于myeclipse 中配置jbpm 请参考jbpm 的帮助文档,文档给的是在eclipse 下配置jbpm 。
5. 测试运行环境:
新建一个 java 项目,将 jbpm-4.4/examples 下的 src 目录, copy 到项目中。然后引入相关 jar 包, jbpm.jar 和 lib 下的所有包,先不考虑 jar 包选择问题。 Src 中包括了 jbpm 中的基本元素的使用。如 start , state , end , sql , script , fork , join 等。然后跟着 jbpm 的帮助文档,一点一点的学习。

说说以上文件的作用:第一个是 jbpm 的配置文件,在这个文件又引入其他的文件,在被引入的文件有一个文件包含了
<hibernate-configuration> <cfg resource="jbpm.hibernate.cfg.xml" />
</hibernate-configuration> <hibernate-session-factory />
用于创建 hibernate 的 sessionfactory 并交给 jbpm 的 IOC 容器管理。
第二个文件是 hibernate 配置文件,里面包含了 jbpm 框架需要的表的 hbm.xml 配置文件。
Jbpm4.4+hibernate3.5.4+spring3.0.4+struts2.1. 整合环境搭建
我的开发环境:
tomcat6.0.28+mysql5.1.30+ Jbpm4.4+hibernate3.5.4+spring3.0.4+struts2.1.8+myeclipse8.6+java jdk 6.0.23
在搭建环境之前,先认识一下 jbpm 。 JBPM 在管理流程时,是需要数据库表的支持的,因为底层的逻辑有那么复杂。默认下载下来的配置,使用的是( hsqldb )内存数据库。实际应用中,我们就需要连接到我们的数据库里来。所以要事先建好相关的表,相应的 sql 文件在 /jbpm-4.4/install/src/db 下,当然,你也可以使用 hibernate 的 hibernate.hbm2ddl.auto 自动建表,本人建议自己用建表语句,会少很多麻烦(本人在此处可没少碰麻烦)。 如果不结合其他的框架进行整个开发( 如:spring 、hibernate),JBPM4 也有自己的一套IOC 容器, 能后将自己的服务配置到IOC 容器中, 能够很容易的运行容器所配置的服务, 这样它也能够在代码中减少一陀一陀的工厂类等代码的调用, 降低了偶核性, 但是如果结合spring 框架来进行整个开发的话, 那么就有两个容器, 两个SessionFactory, 但是系统中只考虑一个容器来。对服务进行管理, 那么我们就要将jbpm4 的服务移植到spring 的IOC 容器中, 让spring 来进行统一管理, 这样通过spring 的容器来管理服务、事务。
整合目标:将jbpm4 的IOC 移植到Spring 中,让spring 管理一个sessionfactory ,同时需要明确一点的是:jbpm4 对外提供服务是 ProcessEngine 。如:
private RepositoryService repositoryService ;
private ExecutionService executionService ;
private HistoryService historyService ;
private TaskService taskService ;
private IdentityService identityService ;
上面这些服务就是通过 ProcessEngine 获得的。
Spring 配置文件:
<!--jbpm4.4 工作流 -->
< bean id = "springHelper" class = "org.jbpm.pvm.internal.processengine.SpringHelper" >
< property name = "jbpmCfg" value = "jbpm.cfg.xml" />
</ bean >
< bean id = "sessionFactory"
class = "org.springframework.orm.hibernate3.LocalSessionFactoryBean" >
<!--
<property name="configLocation">
<value>classpath:jbpm.hibernate.cfg.xml</value> </property>
-->
< property name = "dataSource" ref = "dataSource" />
< property name = "hibernateProperties" >
< props >
< prop key = "hibernate.dialect" > org.hibernate.dialect.MySQLInnoDBDialect </ prop >
< prop key = "hibernate.show_sql" > true </ prop >
< prop key = "hibernate.connection.pool_size" > 1 </ prop >
< prop key = "hibernate.format_sql" > true </ prop >
< prop key = "hibernate.hbm2ddl.auto" > update </ prop >
<!--
<prop key="hibernate.current_session_context_class">thread</prop>
-->
</ props >
</ property >
< property name = "mappingLocations" >
< list >
< value > classpath:jbpm.execution.hbm.xml </ value >
< value > classpath:jbpm.history.hbm.xml </ value >
< value > classpath:jbpm.identity.hbm.xml </ value >
< value > classpath:jbpm.repository.hbm.xml </ value >
< value > classpath:jbpm.task.hbm.xml </ value >
</ list >
</ property >
</ bean >
< bean
class = "org.springframework.beans.factory.config.PropertyPlaceholderConfigurer" >
< property name = "locations" value = "classpath:jdbc.properties" ></ property >
</ bean >
< bean id = "dataSource"
class = "org.springframework.jdbc.datasource.DriverManagerDataSource" >
< property name = "driverClassName" value = "${jdbc.driverClassName}" />
< property name = "url" value = "${jdbc.url}" />
< property name = "username" value = "${jdbc.username}" />
< property name = "password" value = "${jdbc.password}" />
</ bean >
Jar 包选择:(没有选择,所以会有很多无用的)
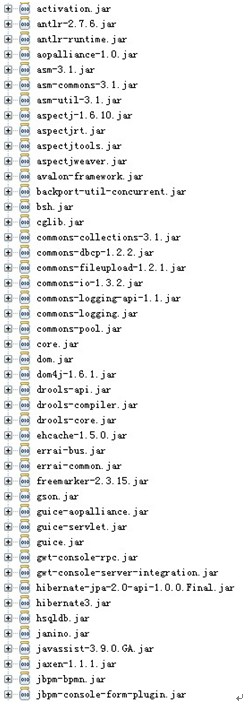
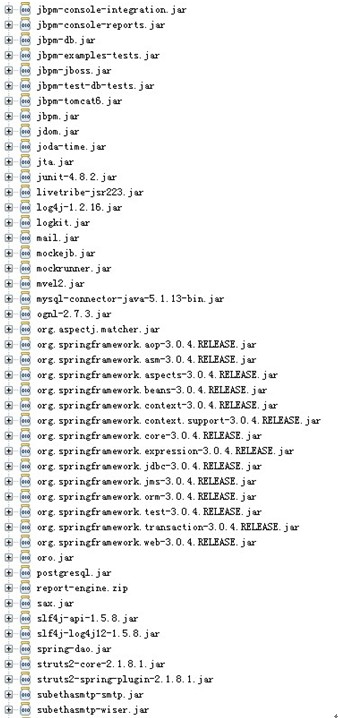

基础知识:
在 jbpm4.4 目录 install/src/db/create 下有:

这些 sql 脚本所创建的表是 jbpm 能正常工作所必须的。我们可以直接运行这些 sql 在数据库建立起相关的表(共 18 张,如下):
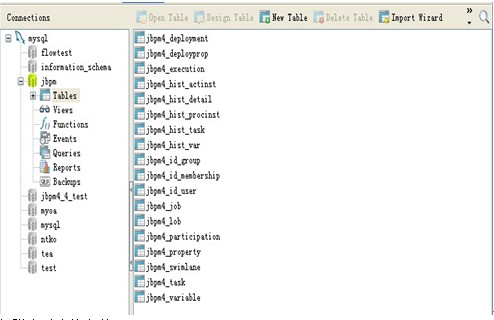
每张表对应的含义:
( 1 ) JBPM4_DEPLOYMENT
( 2 ) JBPM4_DEPLOYPROP
( 3 ) JBPM4_LOB :存储 上传一个包含 png 和 jpdl.xml 的 zip 包 的相关数据
jbpm4_deployment 表多了一条记录
jbpm4_deployprop 表多了四条记录 , 对应 langid,pdid,pdkey,pdversion
jbpm4_lob 表多了二条记录 , 保存流程图 png 图片和 jpdl.xml
( 4 ) JBPM4_HIST_PROCINST 与
( 5 ) JBPM4_HIST_ACTINST 分别存放的是 Process Instance 、 Activity Instance 的历史记
( 6 ) JBPM4_EXECUTION 主要是存放 JBPM4 的执行信息, Execution 机制代替了 JBPM3 的 Token 机制(详细参阅 JBPM4 的 PVM 机制)。
( 7 ) JBPM4_TASK 存放需要人来完成的 Activities ,需要人来参与完成的 Activity 被称为 Task 。
( 8 ) JBPM4_PARTICIPATION 存放 Participation 的信息, Participation 的种类有 Candidate 、 Client 、 Owner 、 Replaced Assignee 和 Viewer 。而具体的 Participation 既可以是单一用户,也可以是用户组。
( 9 ) JBPM4_SWIMLANE 。 Swim Lane 是一种 Runtime Process Role 。通过 Swim Lane ,多个 Task 可以一次分配到同一 Actor 身上。
( 10 ) JBPM4_VARIABLE 存的是进行时的临时变量。
( 11 ) JBPM4_HIST_DETAIL 保存 Variable 的变更记录。
( 12 ) JBPM4_HIST_VAR 保存历史的变量。
( 13 ) JBPM4_HIST_TASKTask 的历史信息。
( 14 ) JBPM4_ID_GROUP
( 15 ) JBPM_ID_MEMBERSHIP
( 16 ) JBPM4_ID_USER 这三张表很常见了,基本的权限控制,关于用户认证方面建议还是自己开发一套, JBPM4 的功能太简单了,使用中有很多需要难以满足。
( 17 ) JBPM4_JOB 存放的是 Timer 的定义。
( 18 ) JBPM4_PROPERTY
你可以直接运行脚本,整合中有hibernate ,所以就用hibernate 自动创建。事实上jbpm 也是采用的hibernate 作为其持久化工具。
jbpm 4.4 中一些概念( 转自family168)
1, 流程定义(ProcessDefinition): 对整个流程步骤的描述., 相当于我们在编程过程过程用到的类, 是个抽象的概念.
2. 流程实例(ProcessInstance) 代表着流程定义的特殊执行例子, 相当于我们常见的对象. 他是类的特殊化.
最典型的属性就是跟踪当前节点的指针.
3. 流程引擎(ProcessEngine), 服务接口可以从 ProcessEngine 中获得, 它是从 Configuration 构建的, 如下:
ProcessEngine processEngine = new Configuration()
.buildProcessEngine();
从流程引擎中可以获得如下的服务:
RepositoryService repositoryService = processEngine.getRepositoryService();
ExecutionService executionService = processEngine.getExecutionService();
TaskService taskService = processEngine.getTaskService();
HistoryService historyService = processEngine.getHistoryService();
ManagementService managementService = processEngine.getManagementService();
4. 部署流程(Deploying a process):
RepositoryService 包含了用来管理发布资源的所有方法,
如下可以发布流程定义.
String deploymentid = repositoryService.createDeployment()
.addResourceFromClasspath("*.jpdl.xml")
.deploy();
这个id 的格式是(key)-{version}.
5. 删除流程定义:
repositoryService.deleteDeployment(deploymentId); 可以用级联的方式, 也可以remove
6. 启动一个新的流程实例:
ProcessInstance processInstance = executionService.startProcessInstanceByKey("key");
如果启动指定版本的流程定义 , 用下面的方法 :
ProcessInstance processInstance =executionService.startProcessInstanceById("ID");
7. 使用变量
当一个新的流程实例启动时就会提供一组对象参数。将这些参数放在variables 变量里, 然后可以在流程实例创建和启动时使用。
Map<String,Object> variables = new HashMap<String,Object>();
variables.put("customer", "John Doe");
variables.put("type", "Accident");
variables.put("amount", new Float(763.74));
ProcessInstance processInstance =
executionService.startProcessInstanceByKey("ICL", variables);
8. 执行等待的流向:
当使用一个 state 活动时,执行(或流程实例) 会在到达state 的时候进行等待,
直到一个signal (也叫外部触发器)出现。 signalExecution 方法可以被用作这种情况。
执行通过一个执行id (字符串)来引用。
executionService.signalExecutionById(executionId);
9.TaskService 任务服务:
TaskService 的主要目的是提供对任务列表的访问途径。例子代码会展示出如何为id 为 johndoe 的
用户获得任务列表:
List<Task> taskList = taskService.findPersonalTasks("johndoe");
JBPM4 –ProcessEngine
在jBPM 内部通过各种服务相互作用。服务接口可以从ProcessEngine 中获得,它是从Configuration 构建的。
获得ProcessEngine : processEngine =Configuration.getProcessEngine ();
JBPM4 – RepositoryService
RepositoryService 包含了用来管理发布资源的所有方法。
部署流程
String deploymentid = repositoryService.createDeployment()
.addResourceFromClasspath("org/jbpm/examples/services/Order.jpdl.xml")
.deploy();
ZipInputStream zis = new ZipInputStream( this .getClass()
.getResourceAsStream( "/com/jbpm/source/leave.zip" ));
// 发起流程,仅仅就是预定义任务,即在系统中创建一个流程,这是全局的,与具体的登陆 用户无关。然后,在启动流程时,才与登陆用户关联起来
String did = repositoryService .createDeployment()
.addResourcesFromZipInputStream(zis).deploy();
通过上面的 addResourceFromClass 方法,流程定义 XML 的内容可以从文件,网址,字符串,输入流或 zip 输入流中获得。
每次部署都包含了一系列资源。每个资源的内容都是一个字节数组。 jPDL 流程文件都是以 .jpdl.xml 作为扩展名的。其他资源是任务表单和 java 类。
部署时要用到一系列资源,默认会获得多种流程定义和其他的归档类型。 jPDL 发布器会自动识别后缀名是 .jpdl.xml 的流程文件。
在部署过程中,会把一个 id 分配给流程定义。这个 id 的格式为 {key}-{version} , key 和 version 之间使用连字符连接。
如果没有提供 key (指在流程定义文件中,对流程的定义),会在名字的基础自动生成。生成的 key 会把所有不是字母和数字的字符替换成下划线。
同一个名称只能关联到一个 key ,反之亦然。
如果没有为流程文件提供版本号, jBPM 会自动为它分配一个版本号。请特别注意那些已经部署了的名字相同的流程文件的版本号。它会比已经部署的同一个 key 的流程定义里最大的版本号还大。没有部署相同 key 的流程定义的版本号会分配为 1 。
删除流程定义
删除一个流程定义会把它从数据库中删除。
repositoryService.deleteDeployment(deploymentId);
如果在发布中的流程定义还存在活动的流程实例,这个方法就会抛出异常。
如果希望级联删除一个发布中流程定义的所有流程实例,可以使用 deleteDeploymentCascade 。
JBPM4 – TaskService
TaskService 的主要目的是提供对任务列表的访问途径。 例子代码会展示出如何为 id 为 johndoe 的用户获得任务列表
List<Task> taskList = taskService.findPersonalTasks("johndoe");
一般来说,任务会对应一个表单,然后显示在一些用户接口中。 表单需要可以读写与任务相关的数据。
// read task variables
Set<String> variableNames = taskService.getVariableNames(taskId);
variables = taskService.getVariables(taskId, variableNames);
// write task variables
variables = new HashMap<String, Object>();
variables.put("category", "small");
variables.put("lires", 923874893);
taskService.setVariables(taskId, variables);
taskSerice 也用来完成任务。
taskService.completeTask(taskId);
taskService.completeTask(taskId, variables);
taskService.completeTask(taskId, outcome);
taskService.completeTask(taskId, outcome, variables);
这些 API 允许提供一个变量 map ,它在任务完成之前作为流程变量添加到流程里。 它也可能提供一个 “ 外出 outcome” ,这会用来决定哪个外出转移会被选中。 逻辑如下所示:
如果一个任务拥有一个没用名称的外向转移:
taskService.getOutcomes() 返回包含一个 null 值集合,。
taskService.completeTask(taskId) 会使用这个外向转移。
taskService.completeTask(taskId, null) 会使用这个外向转移。
taskService.completeTask(taskId, "anyvalue") 会抛出一个异常。
如果一个任务拥有一个有名字的外向转移:
taskService.getOutcomes() 返回包含这个转移名称的集合。
taskService.completeTask(taskId) 会使用这个单独的外向转移。
taskService.completeTask(taskId, null) 会抛出一个异常(因为这里没有无名称的转移)。
taskService.completeTask(taskId, "anyvalue") 会抛出一个异常。
taskService.completeTask(taskId, "myName") 会根据给定的名称使用转移。
如果一个任务拥有多个外向转移,其中一个转移没有名称,其他转移都有名称:
taskService.getOutcomes() 返回包含一个 null 值和其他转移名称的集合。
taskService.completeTask(taskId) 会使用没有名字的转移。
taskService.completeTask(taskId, null) 会使用没有名字的转移。
taskService.completeTask(taskId, "anyvalue") 会抛出异常。
taskService.completeTask(taskId, "myName") 会使用名字为 'myName' 的转移。
如果一个任务拥有多个外向转移,每个转移都拥有唯一的名字:
taskService.getOutcomes() 返回包含所有转移名称的集合。
taskService.completeTask(taskId) 会抛出异常,因为这里没有无名称的转移。
taskService.completeTask(taskId, null) 会抛出异常,因为这里没有无名称的转移。
taskService.completeTask(taskId, "anyvalue") 会抛出异常。
taskService.completeTask(taskId, "myName") 会使用名字为 'myName' 的转移。
任务可以拥有一批候选人。候选人可以是用户也可以是用户组。用户可以接收自己是候选人的任务。接收任务的意思是用户会被设置为被分配给任务的人。在那之后,其他用户就不能接收这个任务了。
人们不应该在任务做工作,除非他们被分配到这个任务上。用户界面应该显示表单,如果他们被分配到这个任务上,就允许用户完成任务。对于有了候选人,但是还没有分配的任务,唯一应该暴露的操作就是 “ 接收任务 ” 。
JBPM4 – ExecutionService
最新的流程实例 -- ByKey
下面是为流程定义启动一个新的流程实例的最简单也是 最常用的方法:
ProcessInstance processInstance = executionService.startProcessInstanceByKey ("ICL");
上面 service 的方法会去查找 key 为 ICL 的最新版本的流程定义, 然后在最新的流程定义里启动流程实例。
当 key 为 ICL 的流程部署了一个新版本, startProcessInstanceByKey 方法会自动切换到最新部署的版本。
原来已经启动的流程,还是按照启动时刻的版本执行。
指定流程版本 -- ById
换句话说,你如果想根据特定的版本启动流程实例, 便可以使用流程定义的 id 启动流程实例。如下所示:
ProcessInstance processInstance = executionService.startProcessInstanceById ("ICL-1");
使用 key
我们可以为新启动的流程实例分配一个 key( 注意: 这个 key 不是 process 的 key ,而是启动的 instance 的 key ) ,这个 key 是用户执行的时候定义的,有时它会作为 “ 业务 key” 引用。一个业务 key 必须在流程定义的所有版本范围内是唯一的。通常很容易在业务流程领域找到这种 key 。比如,一个订单 id 或者一个保险单号。
ProcessInstance processInstance = executionService.startProcessInstanceByKey ("ICL", "CL92837");
// 2 个参数:
// 第一个参数 processkey ,通过这个 key 启动 process 的一个实例
// 第二个参数为这里所说的实例 key(instance key)
key 可以用来创建流程实例的 id ,格式为 {process-key}.{execution-id} 。所以上面的代码会创建一个 id 为 ICL.CL92837 的流向( execution )。
如果没有提供用户定义的 key ,数据库就会把主键作为 key 。 这样可以使用如下方式获得 id :
ProcessInstance processInstance = executionService.startProcessInstanceByKey ("ICL");
String pid = processInstance.getId();
最好使用一个用户定义的 key 。 特别在你的应用代码中,找到这样的 key 并不困难。提供给一个用户定义的 key ,你可以组合流向的 id ,而不是执行一个基于流程变量的搜索 - 那种方式太消耗资源了。
使用变量
当一个新的流程实例启动时就会提供一组对象参数。 将这些参数放在 variables 变量里, 然后可以在流程实例创建和启动时使用。
Map<String,Object> variables = new HashMap<String,Object>();
variables.put("customer", "John Doe");
variables.put("type", "Accident");
variables.put("amount", new Float(763.74));
ProcessInstance processInstance = executionService.startProcessInstanceByKey ("ICL", variables);
启动 instance
启动 instance ,必须要知道 processdefinition 的信息: processdefinition 可以通过 2 种方式获取:
ByKey :通过 ProcessKey ,启动该 Process 的最新版本
ById : 通过 Process 的 ID ,启动该 Process 的特定的版本
其他的参数,其余还可以在启动 Instance 的时候,给流程 2 个参数:
InstanceKey :这个 instanceKey 必须在整个流程定义的所有范围版本中唯一,如果用户不给于提供,系统也会自己生成;
一个 Map<String, ?> 表:启动流程时候给予的变量信息
执行等待的流向
当使用一个 state 活动时,执行(或流程实例)会在到达 state 的时候进行等待,直到一个 signal (也叫外部触发器)出现。 signalExecution 方法可以被用作这种情况。执行通过一个执行 id (字符串)来引用。
在一些情况下,到达 state 的执行会是流程实例本身。但是这不是一直会出现的情况。在定时器和同步的情况,流程是执行树形的根节点。所以我们必须确认你的 signal 作用在正确的流程路径上。
获得正确的执行的比较好的方法是给 state 活动分配一个事件监听器,像这样:
<state name="wait">
<on event="start">
<event-listener class="org.jbpm.examples.StartExternalWork" />
</on>
...
</state>
在事件监听器 StartExternalWork 中,你可以执行那些需要额外完成的部分。在这个事件监听器里,你也可以通过 execution.getId() 获得确切的流程 id 。那个流程 id ,在额外的工作完成后,你会需要它来提供给 signal 操作的:
executionService.signalExecutionById (executionId);
这里有一个可选的(不是太推荐的)方式,来获得流程 id ,当流程到达 state 活动的时候。只可能通过这种方式获得执行 id ,如果你知道哪个 JBPM API 调用了之后,流程会进入 state 活动:
// assume that we know that after the next call
// the process instance will arrive in state external work
ProcessInstance processInstance = executionService.startProcessInstanceById(processDefinitionId);
// or ProcessInstance processInstance =
// executionService.signalProcessInstanceById(executionId);
Execution execution = processInstance.findActiveExecutionIn("external work");
String executionId = execution.getId();
JBPM4 – HistoryService
在流程实例执行的过程中,会不断触发事件。从那些事件中,运行和完成流程的历史信息会被收集到历史表中。
HistoryService 提供了 对那些信息的访问功能。
如果想查找某一特定流程定义的所有流程实例, 可以像这样操作:
List<HistoryProcessInstance> historyProcessInstances = historyService
.createHistoryProcessInstanceQuery()
.processDefinitionId("ICL-1")
.orderAsc(HistoryProcessInstanceQuery.PROPERTY_STARTTIME)
.list();
单独的活动流程也可以作为 HistoryActivityInstance 保存到历史信息中。
List<HistoryActivityInstance> histActInsts = historyService
.createHistoryActivityInstanceQuery()
.processDefinitionId("ICL-1")
.activityName("a")
.list();
也可以使用简易方法 avgDurationPerActivity 和 choiceDistribution 。可以通过 javadocs 获得这些方法的更多信息。
有时,我们需要获得指定流程实例已经过的节点的完整列表。下面的查询语句可以用来获得所有已经执行的节点列表:
List<HistoryActivityInstance> histActInsts = historyService
.createHistoryActivityInstanceQuery()
.processInstanceId("ICL.12345")
.list();
上面的查询与通过 execution id 查询有一些不同。有时 execution id 和流程实例 id 是不同的, 当一个节点中使用了定时器, execution id 中就会使用额外的后缀, 这就会导致当我们通过 execution id 查询时, 这个节点不会出现在结果列表中。
整合过程中常见问题的解决
错误 1 : java.lang.LinkageError: loader constraint violation: when resolving interface method "javax.servlet.jsp.JspApplicationContext.getExpressionFactory()Ljavax/el/ExpressionFactory;" the class loader (instance of org/apache/jasper/servlet/JasperLoader) of the current class, org/apache/jsp/index_jsp, and the class loader (instance of org/apache/catalina/loader/StandardClassLoader) for resolved class, javax/servlet/jsp/JspApplicationContext, have different Class objects for the type javax/el/ExpressionFactory used in the signature
错误的解决办法。( Tomcat6.0.28 )
exception
javax.servlet.ServletException: java.lang.LinkageError: loader constraint violation: when resolving interface method "javax.servlet.jsp.JspApplicationContext.getExpressionFactory()Ljavax/el/ExpressionFactory;" the class loader (instance of org/apache/jasper/servlet/JasperLoader) of the current class, org/apache/jsp/OnDuty/wfmanage_jsp, and the class loader (instance of org/apache/catalina/loader/StandardClassLoader) for resolved class, javax/servlet/jsp/JspApplicationContext, have different Class objects for the type javax/el/ExpressionFactory used in the signature org.apache.jasper.servlet.JspServlet.service(JspServlet.java:275) javax.servlet.http.HttpServlet.service(HttpServlet.java:717)
root cause
java.lang.LinkageError: loader constraint violation: when resolving interface method "javax.servlet.jsp.JspApplicationContext.getExpressionFactory()Ljavax/el/ExpressionFactory;" the class loader (instance of org/apache/jasper/servlet/JasperLoader) of the current class, org/apache/jsp/OnDuty/wfmanage_jsp, and the class loader (instance of org/apache/catalina/loader/StandardClassLoader) for resolved class, javax/servlet/jsp/JspApplicationContext, have different Class objects for the type javax/el/ExpressionFactory used in the signature org.apache.jsp.OnDuty.wfmanage_jsp._jspInit(wfmanage_jsp.java:27) org.apache.jasper.runtime.HttpJspBase.init(HttpJspBase.java:52) org.apache.jasper.servlet.JspServletWrapper.getServlet(JspServletWrapper.java:159) org.apache.jasper.servlet.JspServletWrapper.service(JspServletWrapper.java:329) org.apache.jasper.servlet.JspServlet.serviceJspFile(JspServlet.java:342) org.apache.jasper.servlet.JspServlet.service(JspServlet.java:267) javax.servlet.http.HttpServlet.service(HttpServlet.java:717)
原因是项目中WEB-INF/lib 中的三个jar 包 (juel.jar, juel-engine.jar, juel-impl.jar ) 和tomcat6 下lib 中jar 包( el-api.jar ) 冲突
解决方法:
方法一:换成tomcat5.5 一点问题也没有了(有新版本了还用老版本?)
方法二:将 juel.jar, juel-engine.jar, juel-impl.jar 这三个包复制到tomcat6 下lib 中,并删除原来的 el-api.jar ,切记要把WEB-INF/lib 中的juel.jar, juel-engine.jar, juel-impl.jar 删除。不然还是要冲突。
错误 2 : org.jbpm.api.JbpmException: No unnamed transitions were found for the task '??'
如果一个任务拥有一个没用名称的外向转移:
taskService.getOutcomes() 返回包含一个 null 值集合,。 taskService.completeTask(taskId) 会使用这个外向转移。 taskService.completeTask(taskId, null) 会使用这个外向转移。 taskService.completeTask(taskId, "anyvalue") 会抛出一个异常。
如果一个任务拥有一个有名字的外向转移:
gtaskService.getOutcomes() 返回包含这个转移名称的集合。 taskService.completeTask(taskId) 会使用这个单独的外向转移。 taskService.completeTask(taskId, null) 会抛出一个异常(因为这里没有无名称的转移)。 taskService.completeTask(taskId, "anyvalue") 会抛出一个异常。 taskService.completeTask(taskId, "myName") 会根据给定的名称使用转移。
如果一个任务拥有多个外向转移,其中一个转移没有名称,其他转移都有名称:
taskService.getOutcomes() 返回包含一个 null 值和其他转移名称的集合。 taskService.completeTask(taskId) 会使用没有名字的转移。 taskService.completeTask(taskId, null) 会使用没有名字的转移。 taskService.completeTask(taskId, "anyvalue") 会抛出异常。 taskService.completeTask(taskId, "myName") 会使用名字为 'myName' 的转移。
如果一个任务拥有多个外向转移,每个转移都拥有唯一的名字:
taskService.getOutcomes() 返回包含所有转移名称的集合。 taskService.completeTask(taskId) 会抛出异常,因为这里没有无名称的转移。 taskService.completeTask(taskId, null) 会抛出异常,因为这里没有无名称的转移。 taskService.completeTask(taskId, "anyvalue") 会抛出异常。 taskService.completeTask(taskId, "myName") 会使用名字为 'myName' 的转移。
解决方案:
根据以上分析,可得到解决方案:
1 、只拥有一个外向转移时(对应上文所述 1 、 2 情况):
Map map = new HashMap();
map.put("",…… ) // 各种参数
taskService.setVariables(taskId,map);
taskService.completeTask(taskId);
3 、拥有多个外向转移时(上文 3 、 4 种情况):
Map map = new HashMap();
map.put("",…… ) // 各种参数
taskService.setVariables(taskId,map);
// 如想转移至有名称的外向转移:
taskService.completeTask(taskId," 外向转移名称 ");
// 如想转移至无名称的外向转移:
taskService.completeTask(taskId);
错误3 :*.jpdl.xml 中文乱码问题。
在myeclipse 的配置文件myeclipse.ini 中加入:
-DFile.encoding=UTF-8
请假流程例子( s2sh+jbpm )
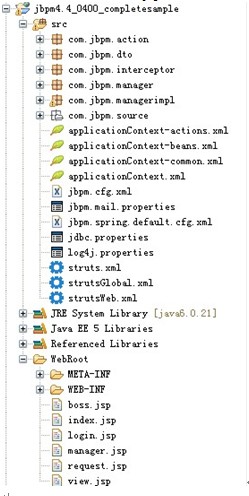
流程图:

<? xml version = "1.0" encoding = "UTF-8" ?>
< process name = "leave" xmlns = "http://jbpm.org/4.4/jpdl" >
< start g = "214,37,48,48" name = "start1" >
< transition g = "-47,-17" name = "to 申请 " to = " 申请 " />
</ start >
< task assignee = "#{owner}" form = "request.html" g = "192,126,92,52" name = " 申请 " >
< transition g = "-71,-17" name = "to 经理审批 " to = " 经理审批 " />
</ task >
< task assignee = "manager" form = "manager.html" g = "194,241,92,52" name = " 经理审批 " >
< transition g = "-29,-14" name = " 批准 " to = "exclusive1" />
< transition g = "105,267;103,152:-47,-17" name = " 驳回 " to = " 申请 " />
</ task >
< decision expr = "#{day > 3 ? ' 老板审批 ' : ' 结束 '}" g = "218,342,48,48" name = "exclusive1" >
< transition g = "415,367:-47,-17" name = " 老板审批 " to = " 老板审批 " />
< transition g = "-31,-16" name = " 结束 " to = "end1" />
</ decision >
< end g = "219,499,48,48" name = "end1" />
< task assignee = "boss" form = "boss.html" g = "370,408,92,52" name = " 老板审批 " >
< transition g = "415,524:-91,-18" name = " 结束 " to = "end1" />
</ task >
</ process >
步骤:
发布流程:将画好的流程图,发布到jbpm 框架中(放到jbpm 数据库中),这个流程是全局的,与用户无关。发布流程后会返回一个流程id ,我们会用流程id 得到 ProcessDefinition 流程定义。 发布方法如下:
public void deploy() {
// repositoryService.createDeployment().addResourceFromClasspath(
// "/com /jbpm /source/leave.jpdl.xml").deploy();
ZipInputStream zis = new ZipInputStream( this .getClass()
.getResourceAsStream( "/com/jbpm/source/leave.zip" ));
// 发起流程,仅仅就是预定义任务,即在系统中创建一个流程,这是全局的,与具体的登陆 用户无关。然后,在启动流程时,才与登陆用户关联起来
String did = repositoryService .createDeployment()
.addResourcesFromZipInputStream(zis).deploy();
}
启动流程:流程定义好后,并不能用,我们需要将其实例化,实例化流程将关联用户,同时将实例写入数据库中。启动流程方法如下:
public void start(String id, Map<String , Object> map) {
executionService .startProcessInstanceById(id, map);
}
流程一旦启动就通过start 节点,流到下一个任务节点。
获取待办任务列表:不同的用户登录后通过如下方式获得自己的待办任务
public List<Task> getTasks(String roleName) {
return taskService .findPersonalTasks(roleName);
}
在流程中每一个任务节点都关联了一个 action 请求,用于处理待办任务的视图( view )
不多说了,哥就相信源码: http://download.csdn.net/source/3223403
总结及参考文章:
参考文章:http://www.blogjava.net/paulwong/archive/2009/09/07/294114.html
http://zjkilly.iteye.com/blog/738426
http://fish119.iteye.com/blog/779379
http://alimama.iteye.com/blog/567651
其他参考资料: family168 网, http://code.google.com/p/family168/downloads/list
源码下载地址为:http://download.csdn.net/source/2671387
很多朋友要求我把jar包也上传,jar包下载地址为:
http://download.csdn.net/source/3084268
控制流程活动:

原子活动:



发表评论

-
data struct
2013-01-20 23:37 0第1章 绪论 1.1 简述下列术语:数据,数据元素、数 ... -
svn
2012-12-22 12:16 963下面是具体的步骤。 � ... -
hibernate调用存储过程
2012-07-05 21:31 1196一. 建表与初始化数据 在mysql的test数据库中建立一 ... -
solr
2012-03-12 14:55 17571.下載 Apache Solr Search Integra ... -
Could not instantiate bean class
2012-02-13 21:26 8330严重: Servlet.service() for servl ...
相关推荐
【JBPM4.4+Hibernate3.5.4+Spring3.0.4+Struts2.1.8整合】的整个过程涉及到多个关键组件的集成,这些组件都是Java企业级开发中的重要部分。首先,JBPM(Business Process Management)是一个开源的工作流引擎,它...
在日常的工作和学习中,你是否常常为处理复杂的数据、生成高质量的文本或者进行精准的图像识别而烦恼?DeepSeek 或许就是你一直在寻找的解决方案!它以其高效、智能的特点,在各个行业都展现出了巨大的应用价值。然而,想要充分发挥 DeepSeek 的优势,掌握从入门到精通的知识和技能至关重要。本文将从实际应用的角度出发,为你详细介绍 DeepSeek 的基本原理、操作方法以及高级技巧。通过系统的学习,你将能够轻松地运用 DeepSeek 解决实际问题,提升工作效率和质量,让自己在职场和学术领域脱颖而出。现在,就让我们一起开启这场实用又高效的学习之旅吧!
在日常的工作和学习中,你是否常常为处理复杂的数据、生成高质量的文本或者进行精准的图像识别而烦恼?DeepSeek 或许就是你一直在寻找的解决方案!它以其高效、智能的特点,在各个行业都展现出了巨大的应用价值。然而,想要充分发挥 DeepSeek 的优势,掌握从入门到精通的知识和技能至关重要。本文将从实际应用的角度出发,为你详细介绍 DeepSeek 的基本原理、操作方法以及高级技巧。通过系统的学习,你将能够轻松地运用 DeepSeek 解决实际问题,提升工作效率和质量,让自己在职场和学术领域脱颖而出。现在,就让我们一起开启这场实用又高效的学习之旅吧!
ACM动态规划模板-区间修改线段树问题模板
# 踏入C语言的奇妙编程世界 在编程的广阔宇宙中,C语言宛如一颗璀璨恒星,以其独特魅力与强大功能,始终占据着不可替代的地位。无论你是编程小白,还是有一定基础想进一步提升的开发者,C语言都值得深入探索。 C语言的高效性与可移植性令人瞩目。它能直接操控硬件,执行速度快,是系统软件、嵌入式开发的首选。同时,代码可在不同操作系统和硬件平台间轻松移植,极大节省开发成本。 学习C语言,能让你深入理解计算机底层原理,培养逻辑思维和问题解决能力。掌握C语言后,再学习其他编程语言也会事半功倍。 现在,让我们一起开启C语言学习之旅。这里有丰富教程、实用案例、详细代码解析,助你逐步掌握C语言核心知识和编程技巧。别再犹豫,加入我们,在C语言的海洋中尽情遨游,挖掘无限可能,为未来的编程之路打下坚实基础!
在日常的工作和学习中,你是否常常为处理复杂的数据、生成高质量的文本或者进行精准的图像识别而烦恼?DeepSeek 或许就是你一直在寻找的解决方案!它以其高效、智能的特点,在各个行业都展现出了巨大的应用价值。然而,想要充分发挥 DeepSeek 的优势,掌握从入门到精通的知识和技能至关重要。本文将从实际应用的角度出发,为你详细介绍 DeepSeek 的基本原理、操作方法以及高级技巧。通过系统的学习,你将能够轻松地运用 DeepSeek 解决实际问题,提升工作效率和质量,让自己在职场和学术领域脱颖而出。现在,就让我们一起开启这场实用又高效的学习之旅吧!
本项目为Python语言开发的PersonRelationKnowledgeGraph设计源码,总计包含49个文件,涵盖19个.pyc字节码文件、12个.py源代码文件、8个.txt文本文件、3个.xml配置文件、3个.png图片文件、2个.md标记文件、1个.iml项目配置文件、1个.cfg配置文件。该源码库旨在构建一个用于表示和查询人物关系的知识图谱系统。
在日常的工作和学习中,你是否常常为处理复杂的数据、生成高质量的文本或者进行精准的图像识别而烦恼?DeepSeek 或许就是你一直在寻找的解决方案!它以其高效、智能的特点,在各个行业都展现出了巨大的应用价值。然而,想要充分发挥 DeepSeek 的优势,掌握从入门到精通的知识和技能至关重要。本文将从实际应用的角度出发,为你详细介绍 DeepSeek 的基本原理、操作方法以及高级技巧。通过系统的学习,你将能够轻松地运用 DeepSeek 解决实际问题,提升工作效率和质量,让自己在职场和学术领域脱颖而出。现在,就让我们一起开启这场实用又高效的学习之旅吧!
rtsp实时预览接口URL:/evo-apigw/admin/API/MTS/Video/StartVideo HLS、FLV、RTMP实时预览接口方式 :接口URL/evo-apigw/admin/API/video/stream/realtime 参数名 必选 类型 说明 data true string Json串 +channelId true string 视频通道编码 +streamType true string 码流类型:1=主码流, 2=辅码流,3=辅码流2 +type true string 协议类型:hls,hlss,flv,flvs,ws_flv,wss_flv,rtmp hls:http协议,m3u8格式,端口7086; hlss:https协议,m3u8格式,端口是7096; flv:http协议,flv格式,端口7886; flvs:https协议,flv格式,端口是7896; ws_flv:ws协议,flv格式,端口是7886; wss_flv:wss协议,flv格式,端口是7896; rtmp:rtmp协议,端口是1975;
Simulink永磁风机飞轮储能系统二次调频技术研究:频率特性分析与参数优化,Simulink永磁风机飞轮储能二次调频技术:系统频率特性详解及参数优化研究参考详实文献及两区域系统应用,simulink永磁风机飞轮储能二次调频,系统频率特性如下,可改变调频参数改善频率。 参考文献详细,两区域系统二次调频。 ,核心关键词: 1. Simulink 2. 永磁风机 3. 飞轮储能 4. 二次调频 5. 系统频率特性 6. 调频参数 7. 改善频率 8. 参考文献 9. 两区域系统 以上关键词用分号(;)分隔,结果为:Simulink;永磁风机;飞轮储能;二次调频;系统频率特性;调频参数;改善频率;参考文献;两区域系统。,基于Simulink的永磁风机与飞轮储能系统二次调频研究:频率特性及调频参数优化
MATLAB驱动的ASR防滑转模型:PID与对照控制算法对比,冰雪路面条件下滑移率与车速轮速对照展示,MATLAB驱动的ASR防滑转模型:PID与对照控制算法对比,冰雪路面条件下滑移率与车速轮速对照图展示,MATLAB驱动防滑转模型ASR模型 ASR模型驱动防滑转模型 ?牵引力控制系统模型 选择PID控制算法以及对照控制算法,共两种控制算法,可进行选择。 选择冰路面以及雪路面,共两种路面条件,可进行选择。 控制目标为滑移率0.2,出图显示车速以及轮速对照,出图显示车辆轮胎滑移率。 模型简单,仅供参考。 ,MATLAB; ASR模型; 防滑转模型; 牵引力控制系统模型; PID控制算法; 对照控制算法; 冰路面; 雪路面; 控制目标; 滑移率; 车速; 轮速。,MATLAB驱动的ASR模型:PID与对照算法在冰雪路面的滑移率控制研究
芯片失效分析方法介绍 -深入解析芯片故障原因及预防措施.pptx
4131_127989170.html
内容概要:本文提供了一个全面的PostgreSQL自动化部署解决方案,涵盖智能环境适应、多平台支持、内存与性能优化以及安全性加强等重要方面。首先介绍了脚本的功能及其调用方法,随后详细阐述了操作系统和依赖软件包的准备过程、配置项的自动生成机制,还包括对实例的安全性和监控功能的强化措施。部署指南给出了具体的命令操作指导,便于新手理解和执行。最后强调了该工具对于不同硬件条件和服务需求的有效应对能力,特别是针对云计算环境下应用的支持特点。 适合人群:对PostgreSQL集群运维有一定基础并渴望提高效率和安全性的数据库管理员及工程师。 使用场景及目标:本脚本能够帮助企业在大规模部署时减少人工介入时间,确保系统的稳定性与高性能,适用于各类需要稳定可靠的数据库解决方案的企业或机构,特别是在大数据量和高并发事务处理场合。 其他说明:文中还提及了一些高级功能如自动备份、流复制等设置步骤,使得该方案不仅可以快速上线而且能满足后续维护和发展阶段的要求。同时提到的技术性能数据也为用户评估其能否满足业务需求提供了直观参考。
房地产开发合同[示范文本].doc
在日常的工作和学习中,你是否常常为处理复杂的数据、生成高质量的文本或者进行精准的图像识别而烦恼?DeepSeek 或许就是你一直在寻找的解决方案!它以其高效、智能的特点,在各个行业都展现出了巨大的应用价值。然而,想要充分发挥 DeepSeek 的优势,掌握从入门到精通的知识和技能至关重要。本文将从实际应用的角度出发,为你详细介绍 DeepSeek 的基本原理、操作方法以及高级技巧。通过系统的学习,你将能够轻松地运用 DeepSeek 解决实际问题,提升工作效率和质量,让自己在职场和学术领域脱颖而出。现在,就让我们一起开启这场实用又高效的学习之旅吧!
在日常的工作和学习中,你是否常常为处理复杂的数据、生成高质量的文本或者进行精准的图像识别而烦恼?DeepSeek 或许就是你一直在寻找的解决方案!它以其高效、智能的特点,在各个行业都展现出了巨大的应用价值。然而,想要充分发挥 DeepSeek 的优势,掌握从入门到精通的知识和技能至关重要。本文将从实际应用的角度出发,为你详细介绍 DeepSeek 的基本原理、操作方法以及高级技巧。通过系统的学习,你将能够轻松地运用 DeepSeek 解决实际问题,提升工作效率和质量,让自己在职场和学术领域脱颖而出。现在,就让我们一起开启这场实用又高效的学习之旅吧!
工程技术承包合同[示范文本].doc
蓝桥杯开发赛【作品源码】
在日常的工作和学习中,你是否常常为处理复杂的数据、生成高质量的文本或者进行精准的图像识别而烦恼?DeepSeek 或许就是你一直在寻找的解决方案!它以其高效、智能的特点,在各个行业都展现出了巨大的应用价值。然而,想要充分发挥 DeepSeek 的优势,掌握从入门到精通的知识和技能至关重要。本文将从实际应用的角度出发,为你详细介绍 DeepSeek 的基本原理、操作方法以及高级技巧。通过系统的学习,你将能够轻松地运用 DeepSeek 解决实际问题,提升工作效率和质量,让自己在职场和学术领域脱颖而出。现在,就让我们一起开启这场实用又高效的学习之旅吧!