这几天做一个小项目,分给我的模块是对于BOKECC体系网站的抓取。
从来没有用过python,这次来尝一下鲜,感觉还行~
BOKECC就是一个视频网站的解决方案,我的任务很简单,就是给定一个网址,我来抓取对应页面上的数据内容。
整个系统采用分布式架构,我来负责做爬虫节点。

简单来说就是整个系统可分布式部署,每个节点接收来自控制者的远程调用,独立完成任务,并向上级汇报完成情况。
这里采用暴露WebService的方式来提供接口。
|
功能需求点
|
概述
|
|
输入
|
提供webservice接口供主控调用,异步启动爬虫任务。
|
|
输出
|
1. 在正常接收、启动任务后立即给主控返回接收成功。
2. 在完成任务/任务失败后调用主控提供的回调接口。
3. 抓取成功后,将抓取数据保存至数据库。
|
|
错误处理
|
抓取异常情况下,应该将错误原因汇报给主控,并记录日志。
|
|
并发性需求
|
模块支持多线程并发调用。
|
|
|
|
BOKECC体系网站有非常多个,通过进行实际情况调研,发现各个页面在数据上有所不同(但大同小异),为了省事,我决定只用一套代码来爬取所有对应站点。那就要求我们的代码具有通用性。
另外,客户端要实现0配置,爬取的结果写入数据库。(数据库配置参与也应该由控制者——WEB接口调用者来决定)。所以我们在节点上维护一个数据库连接池。
大致流程如下:
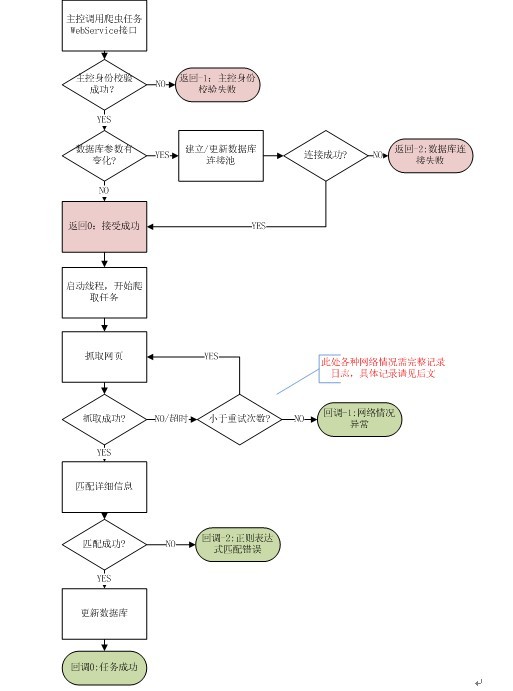
在实际编码过程中也没有严格遵守此流程,进行了相应的扩展,不过大体如上。
日志记录设计:
|
日志条目
|
级别
|
记录信息
|
|
WebService接口被调用
|
Info
|
调用方IP及各接口参数
|
|
主控身份校验失败
|
Warn
|
调用方IP
|
|
开始建立/更新数据库连接池
|
Info
|
数据库参数
|
|
数据库连接失败
|
Error,Notify
|
失败原因
|
|
数据库连接成功
|
Info
|
|
|
开始启动爬虫任务
|
Debug
|
|
|
开始抓取网页
|
Info
|
URL
|
|
一次网页抓取超时
|
Warn
|
当前重试次数
|
|
一次网页抓取异常
|
Warn
|
异常原因
|
|
重试范围内网页抓取失败
|
Error,Notify
|
|
|
网页抓取成功
|
Debug
|
|
|
开始内容匹配
|
Info
|
|
|
正则表达式匹配失败
|
Error,Notify
|
失败字段、失败原因
|
|
正则表达式匹配成功
|
Debug
|
|
|
开始更新数据库
|
Info
|
|
|
SQL操作
|
Debug
|
SQL语句
|
|
更新数据库完成
|
Debug
|
|
|
写数据库异常
|
Error,Notify
|
当前执行的SQL语句,异常原因
|
|
任务成功
|
Info
|
|
技术选型:
开发平台: windowsXP
部署平台: 跨平台
编程语言:python2.5
IDE+plug-in:MyEclipse 7.0 + pydev
具体使用的python技术:
|
功能
|
技术选型
|
|
网页抓取
|
urllib2
|
|
内容解析,正则表达
|
re
|
|
WebService
|
ZSI2.0
|
|
SOAP协议
|
SOAPpy(ZSI依赖)
|
|
XML
|
pyXML(ZSI依赖)
|
|
Web服务器
|
ZSI自带SOAP SERVER 或Apache
|
|
发布、部署
|
Windows平台:py2exe
|
下面一节将进入正式编码阶段。
分享到:





相关推荐
应用前景与挑战:基于Python的分布式多主题网络爬虫可应用到多个检索领域,但由于网络爬虫抓取过程中遇到的异常问题,如程序错误、系统死机、网页编码不规范等,还需进行优化以进一步提高爬虫的抓取效率和数据处理...
综上所述,Python抓取高德POI数据是一个涉及网络请求、数据解析、文件操作以及策略设计的过程。通过合理地编写和优化脚本,结合高德地图的API,我们可以有效地获取和管理大量的POI信息,服务于各种GIS应用和数据分析...
- **Scrapy爬虫框架**:Scrapy是一个用于Web抓取的强大Python框架,它可以高效地抓取网页数据,并支持多线程爬取。本项目利用Scrapy来开发爬虫逻辑,包括网页请求、响应处理以及数据解析等功能。 - **XPath网页提取...
Python爬虫入门教程-大规模网页抓取-分布式爬虫 另外如果说知识体系里的每一个知识点是图里的点,依赖关系是边的话,那么这个图一定不是一个有向无环图。因为学习A的经验可以帮助你学习B。因此,你不需要学习怎么样...
这是一个基于大数据分析的毕业设计项目,主要涉及到的技术栈包括Python爬虫、SpringBoot、MySQL数据库、Hadoop,以及前端的Vue.js和ElementUI组件库。接下来,我们将详细探讨这些技术在项目中的应用。 首先,Python...
合肥市二手房信息爬取与数据分析的知识点...以上所述的知识点,涵盖了从网络爬虫的设计、数据的抓取与预处理、分析方法的使用到数据分析在实际业务场景中的应用等多个方面的专业知识,是一篇专业性和实用性兼具的论文。
标题“抓取百度搜索结果——解密百度狗”所涉及的知识点主要集中在网络爬虫技术和搜索引擎的工作原理上。网络爬虫是一种自动获取网页信息的程序,它通过模拟浏览器的行为,发送HTTP请求到服务器,接收服务器返回的...
《虫术Python绝技》是梁睿坤先生关于Python爬虫技术的一本深入解析书籍,旨在教授读者如何高效地利用Python进行网络数据抓取。在当今大数据时代,网络爬虫作为获取海量信息的重要手段,其重要性不言而喻。本书以...
Python网络爬虫是一种用于自动化获取网页内容的技术,广泛应用于互联网数据收集、数据分析和信息挖掘等领域。在本实习报告中,我们将深入探讨Python网络爬虫的基本概念、常用的爬虫框架及其特性,以及通过实例演示...
4. **数据保存、展示**:将整理好的数据存储到本地文件,如数据库或Excel,使用matplotlib、pandas等库进行数据可视化展示。 5. **技术难点关键点**:处理动态加载、反爬机制、异常处理和IP代理池的搭建等。 **六、...
1. Python语言特性:Python是一种面向对象的动态类型语言,目前非常流行,被广泛应用于计算机程序设计中。 2. Python网络爬虫功能模块:Python提供了多个能够实现网络请求和数据解析的功能模块,如urllib库、...
Python1903笔记中的"12-spider"部分,主要涵盖了如何构建和使用Python爬虫进行网络数据抓取的相关知识。本文将详细阐述Python爬虫的基础概念、工作原理以及常用的技术和库,旨在帮助读者全面了解和掌握Python爬虫的...
本项目——“基于Python爬虫和Hadoop分布式文件系统(HDFS)的招聘信息采集与存储系统”,旨在利用Python爬虫技术获取网络上的招聘信息,并通过HDFS进行高效、安全的数据存储,为人力资源管理和数据分析提供有力支持...
10. **大规模数据抓取**:本书将探讨如何设计和实现能够处理大规模数据抓取任务的系统,包括分布式爬虫的设计思路。 11. **法律与伦理问题**:在进行Web抓取之前,了解相关的法律和伦理问题是十分必要的。本书会讨论...
Python爬虫是Python应用的一个重要领域,它允许程序员自动抓取互联网上的数据,用于数据分析、市场研究、搜索引擎优化等。Python有许多流行的爬虫库,如BeautifulSoup、Scrapy、Requests和PyQuery等,它们简化了网页...
`comcrawl-downloader` 是一个专门用于抓取和下载数据的分布式脚本工具,它被设计成通用型,能够适应各种不同的数据抓取需求。这个工具的核心目的是在大规模数据获取时提供高效、稳定且可扩展的解决方案。在了解`...
讲述了如何使用Redis进行数据去重,以及在大数据量下利用Bloom Filter算法减少空间消耗。 **第十章:Scrapy框架** 详细介绍了Scrapy框架,包括如何快速搭建爬虫以及Scrapy-Redis实现分布式爬虫的方法。 **第十一章...
5. **去重机制**:使用哈希表等数据结构记录已访问的URL,防止重复抓取同一网页,节省资源。 6. **分布式设计**:对于大规模的网络爬虫,如百度和谷歌的搜索引擎,采用分布式系统设计,利用成千上万的服务器并行工作...
实现内容包括用户信息、用户主页所有微博、微博搜索...——学习参考资料:仅用于个人学习使用! 本代码仅作学习交流,切勿用于商业用途,否则后果自负。若涉及侵权,请联系,会尽快处理! 未进行详尽测试,请自行调试!
它是一个完整的爬虫框架,包含爬虫、中间件、调度器、下载器等多个组件,支持分布式爬取,适合大规模的数据抓取。 7. **实战项目**:压缩包中的学习代码应该包含了各种实战项目的源码,比如抓取新闻、微博、商品...