SolrCloud 是基于Solr和Zookeeper的分布式搜索方案,是正在开发中的Solr4.0的核心组件之一,它的主要思想是使用Zookeeper作为集群的配置信息中心。
它有几个特色功能:
1)集中式的配置信息
2)自动容错
3)近实时搜索
4)查询时自动负载均衡

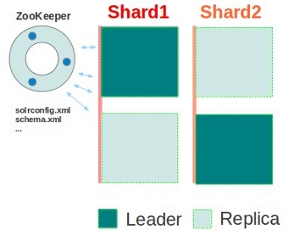
基本可以用上面这幅图来概述,这是一个拥有4个Solr节点的集群,索引分布在两个Shard里面,每个Shard包含两个Solr节点,一个是Leader节点,一个是Replica节点,此外集群中有一个负责维护集群状态信息的Overseer节点,它是一个总控制器。集群的所有状态信息都放在Zookeeper集群中统一维护。从图中还可以看到,任何一个节点都可以接收索引更新的请求,然后再将这个请求转发到文档所应该属于的那个Shard的Leader节点,Leader节点更新结束完成,最后将版本号和文档转发给同属于一个Shard的replicas节点。
下面我们来看一个简单的SolrCloud集群的配置过程。
首先去https://builds.apache.org/job/Solr-trunk/lastSuccessfulBuild/artifact/artifacts/下载Solr4.0的源码和二进制包,注意Solr4.0现在还在开发中,因此这里是Nightly Build版本。
示例1,简单的包含2个Shard的集群
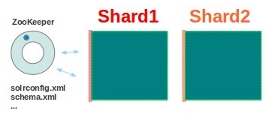
这个示例中,我们把一个collection的索引数据分布到两个shard上去,步骤如下:
为了弄2个solr服务器,我们拷贝一份example目录
cp -r example example2
然后启动第一个solr服务器,并初始化一个新的solr集群,
cd example
java -Dbootstrap_confdir=./solr/conf -Dcollection.configName=myconf -DzkRun -DnumShards=2 -jar start.jar
-DzkRun参数是启动一个嵌入式的Zookeeper服务器,它会作为solr服务器的一部分,-Dbootstrap_confdir参数是上传本地的配置文件上传到zookeeper中去,作为整个集群共用的配置文件,-DnumShards指定了集群的逻辑分组数目。
然后启动第二个solr服务器,并将其引向集群所在位置
cd example2
java -Djetty.port=7574 -DzkHost=localhost:9983 -jar start.jar
复制代码
-DzkHost=localhost:9983就是指明了Zookeeper集群所在位置
我们可以打开http://localhost:8983/solr/collection1/admin/zookeeper.jsp 或者http://localhost:8983/solr/#/cloud看看目前集群的状态,
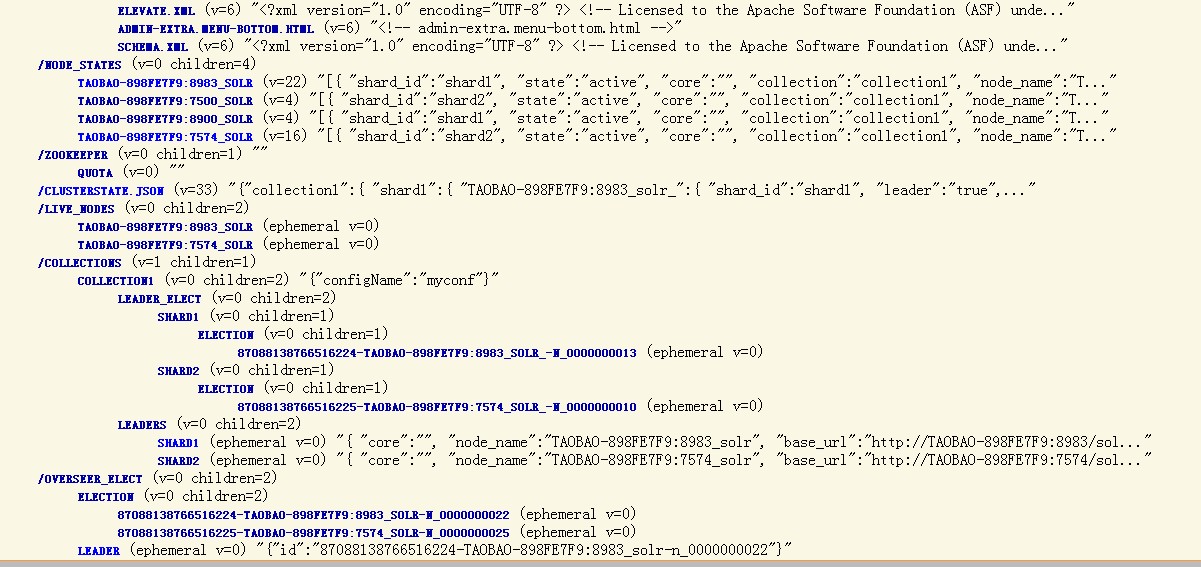
现在,我们可以试试索引一些文档,
cd exampledocs
java -Durl=http://localhost:8983/solr/collection1/update -jar post.jar ipod_video.xml
java -Durl=http://localhost:8983/solr/collection1/update -jar post.jar monitor.xml
java -Durl=http://localhost:8983/solr/collection1/update -jar post.jar mem.xml
最后,来试试分布式搜索吧:
http://localhost:8983/solr/collection1/select?q
Zookeeper维护的集群状态数据是存放在solr/zoo_data目录下的。
现在我们来剖析下这样一个简单的集群构建的基本流程:
先从第一台solr服务器说起:
1) 它首先启动一个嵌入式的Zookeeper服务器,作为集群状态信息的管理者,
2) 将自己这个节点注册到/node_states/目录下
3) 同时将自己注册到/live_nodes/目录下
4)创建/overseer_elect/leader,为后续Overseer节点的选举做准备,新建一个Overseer,
5) 更新/clusterstate.json目录下json格式的集群状态信息
6) 本机从Zookeeper中更新集群状态信息,维持与Zookeeper上的集群信息一致
7)上传本地配置文件到Zookeeper中,供集群中其他solr节点使用
8) 启动本地的Solr服务器,
9) Solr启动完成后,Overseer会得知shard中有第一个节点进来,更新shard状态信息,并将本机所在节点设置为shard1的leader节点,并向整个集群发布最新的集群状态信息。
10)本机从Zookeeper中再次更新集群状态信息,第一台solr服务器启动完毕。
然后来看第二台solr服务器的启动过程:
1) 本机连接到集群所在的Zookeeper,
2) 将自己这个节点注册到/node_states/目录下
3) 同时将自己注册到/live_nodes/目录下
4) 本机从Zookeeper中更新集群状态信息,维持与Zookeeper上的集群信息一致
5) 从集群中保存的配置文件加载Solr所需要的配置信息
6) 启动本地solr服务器,
7) solr启动完成后,将本节点注册为集群中的shard,并将本机设置为shard2的Leader节点,
8) 本机从Zookeeper中再次更新集群状态信息,第二台solr服务器启动完毕。
示例2,包含2个shard的集群,每个shard中有replica节点
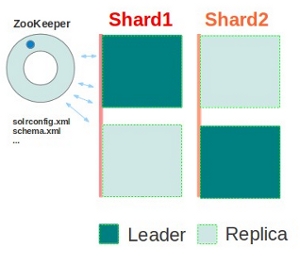
如图所示,集群包含2个shard,每个shard中有两个solr节点,一个是leader,一个是replica节点,
cp -r example exampleB
cp -r example2 example2B
cd exampleB
java -Djetty.port=8900 -DzkHost=localhost:9983 -jar start.jar
cd example2B
java -Djetty.port=7500 -DzkHost=localhost:9983 -jar start.jar
复制代码
我们可以打开http://localhost:8983/solr/collection1/admin/zookeeper.jsp 看看包含4个节点的集群的状态,
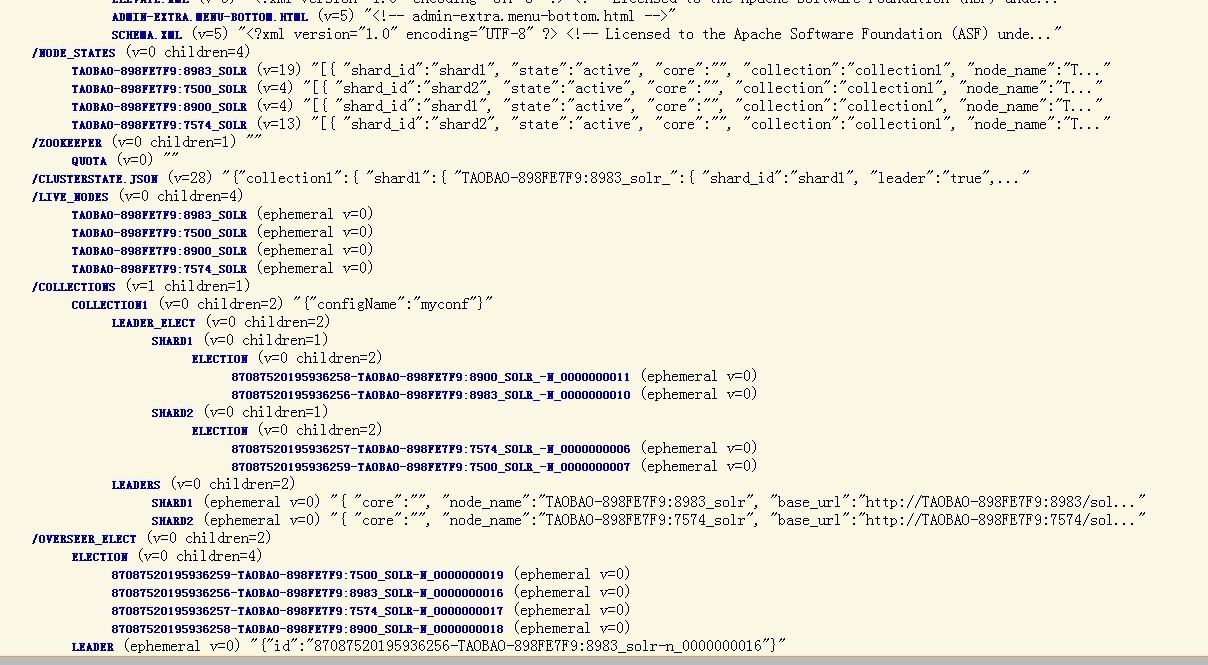
这个集群现在就具备容错性了,你可以试着干掉一个Solr服务器,然后再发送查询请求。背后的实质是集群的ov erseer会监测各个shard的leader节点,如果leader节点挂了,则会启动自动的容错机制,会从同一个shard中的其他replica节点集中重新选举出一个leader节点,甚至如果overseer节点自己也挂了,同样会自动在其他节点上启用新的overseer节点,这样就确保了集群的高可用性。
示例3 包含2个shard的集群,带shard备份和zookeeper集群机制
上一个示例中存在的问题是:尽管solr服务器可以容忍挂掉,但集群中只有一个zookeeper服务器来维护集群的状态信息,单点的存在即是不稳定的根源。如果这个zookeeper服务器挂了,那么分布式查询还是可以工作的,因为每个solr服务器都会在内存中维护最近一次由zookeeper维护的集群状态信息,但新的节点无法加入集群,集群的状态变化也不可知了。因此,为了解决这个问题,需要对Zookeeper服务器也设置一个集群,让其也具备高可用性和容错性。
有两种方式可选,一种是提供一个外部独立的Zookeeper集群,另一种是每个solr服务器都启动一个内嵌的Zookeeper服务器,再将这些Zookeeper服务器组成一个集群。 我们这里用后一种做示例:
cd example
java -Dbootstrap_confdir=./solr/conf -Dcollection.configName=myconf -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -DnumShards=2 -jar start.jar
cd example2
java -Djetty.port=7574 -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
cd exampleB
java -Djetty.port=8900 -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
cd example2B
java -Djetty.port=7500 -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
我们可以打开http://localhost:8983/solr/collection1/admin/zookeeper.jsp 看看包含4个节点的集群的状态,可以发现其实和上一个没有任何区别。
后续的文章将从实现层面对SolrCloud这个分布式搜索解决方案进行进一步的深入剖析。
分享到:





相关推荐
Apache Solr是一款开源的企业级搜索平台,由Apache软件基金会维护。它是基于Java的,提供了高效、可扩展的全文检索、数据分析和分布式搜索功能。Solr-8.11.1是该软件的一个特定版本,包含了从早期版本到8.11.1的所有...
Apache Solr 是一个开源的全文搜索引擎,由Apache软件基金会维护,是Lucene项目的一部分。它提供了高效、可扩展的搜索和导航功能,广泛应用于企业级的搜索应用中。Solr-8.11.1是该软件的一个特定版本,包含了最新的...
Solr,全称为Apache Solr,是Apache软件基金会的一个开源项目,主要用来处理全文搜索和企业级的搜索应用。它基于Java,利用Lucene库构建,提供了高效、可扩展的搜索和导航功能。Solr-9.0.0是该软件的最新版本,此...
Solr是Apache软件基金会的一个开源项目,它是基于Java的全文搜索服务器,被广泛应用于企业级搜索引擎的构建。源码分析是深入理解一个软件系统工作原理的重要途径,对于Solr这样的复杂系统尤其如此。这里我们将围绕...
Solr8.4.0 是 Apache Solr 的一个版本,这是一个高度可配置、高性能的全文搜索和分析引擎,广泛用于构建企业级搜索应用。 在 Solr 中,ikanalyzer 是一个重要的组件,它通过自定义Analyzer来实现中文的分词处理。...
### Solr3.5开发应用指导 #### 一、概述 **1.1 企业搜索引擎方案选型** 在选择企业搜索引擎方案时,考虑到多种因素,包括但不限于开发成本、可维护性和后期扩展性等。常见的几种方案包括: 1. **基于Lucene自行...
### Solr 4.7 服务搭建详细指南 #### 一、环境准备 为了搭建 Solr 4.7 服务,我们需要确保以下环境已经准备好: 1. **Java Development Kit (JDK) 1.7**:Solr 需要 Java 运行环境支持,这里我们选择 JDK 1.7 ...
Apache Solr 是一个开源的全文搜索引擎,广泛应用于各种企业级数据搜索和分析场景。增量更新是Solr的一个关键特性,它允许系统仅处理自上次完整索引以来发生更改的数据,从而提高了性能并降低了资源消耗。"apache-...
使用Solr内置的Jetty服务器启动Solr (1)借助X Shell上传solr的安装包到/usr/local/目录下,使用 tar -zxvf命令进行解压. (2)使用内置的Jetty来启动Solr服务器只需要在example目录下,执行start.jar程序即可,...
Apache Solr是一个流行的开源搜索引擎,它提供全文搜索、命中高亮、拼写建议等功能,广泛应用于网站内容管理和企业级信息检索。在Solr 5.x版本中,为了实现数据的定时更新,用户需要借助特定的扩展来实现定时生成...
Solr,全称为Apache Solr,是一款开源的企业级全文搜索引擎,由Apache软件基金会开发并维护。它是基于Java的,因此在使用Solr之前,确保你的系统已经安装了Java 8或更高版本是至关重要的。标题"solr-7.4.0.zip"表明...
Solr是Apache软件基金会开发的一款开源全文搜索引擎,它基于Java平台,是Lucene的一个扩展,提供了更为方便和强大的搜索功能。在Solr 6.2.0版本中,这个强大的分布式搜索引擎引入了许多新特性和改进,使其在处理大...
Solr是中国最流行的开源搜索引擎平台之一,而IK Analyzer是一款针对中文的高性能分词器,尤其在处理现代汉语的复杂情况时表现出色。本教程将详细解释如何在Solr中安装和使用IK分词器。 首先,让我们理解一下什么是...
Solr是Apache Lucene项目的一个子项目,是一个高性能、基于Java的企业级全文搜索引擎服务器。当你在尝试启动Solr时遇到404错误,这通常意味着Solr服务没有正确地启动或者配置文件设置不正确。404错误表示“未找到”...
Solr 数据导入调度器(solr-dataimport-scheduler.jar)是一个专门为Apache Solr 7.x版本设计的组件,用于实现数据的定期索引更新。在理解这个知识点之前,我们需要先了解Solr的基本概念以及数据导入处理...
Solr 是一个开源的企业级搜索平台,由Apache软件基金会维护,是Lucene项目的一部分。它提供了全文检索、命中高亮、拼写检查、缓存、近实时搜索等特性,广泛应用于网站内容搜索、电子商务产品搜索等领域。本次分享的...
Apache Solr是一款强大的开源搜索引擎,它能够高效地处理和索引大量数据,提供快速的全文检索、 faceting、高亮显示等高级功能。在实际应用中,为了保持搜索结果的实时性,我们往往需要将数据库中的数据实时或定时...
Solr是中国最流行的全文搜索引擎框架Apache Lucene的一个扩展,它提供了高级的搜索功能,并且能够进行复杂的全文检索、分布式搜索和处理大量数据。在Solr中,分词器(Tokenizer)是文本分析的重要组成部分,它负责将...
Solr是Apache软件基金会的一个开源项目,是一款强大的全文搜索引擎服务器,它提供了分布式、可扩展、高可用性的搜索和分析服务。最新的版本为windos solr-8.11.0,专为Windows操作系统设计,提供了丰富的功能和优化...
Solr是Apache软件基金会的一个开源项目,是一款强大的全文搜索引擎服务器,它提供了分布式、可扩展、高可用性的搜索和分析服务。此压缩包“最新版windows solr-8.8.2.zip”包含了Windows环境下Solr的最新版本8.8.2的...