è؟‡هژ»و— è®؛و‚¨وک¯هœ¨ç”ںن؛§ن¸ن½؟用,è؟کوک¯è°ƒç ”Apache Flink,ن¼°è®،و‚¨و€»وک¯ن¼ڑé—®è؟™و ·ن¸€ن¸ھé—®é¢کï¼ڑوˆ‘该ه¦‚ن½•è®؟é—®ه’Œو›´و–°Flinkن؟هک点(savepoint)ن¸ن؟هکçڑ„stateï¼ںن¸چ用ه†چ询问ن؛†ï¼ŒApache Flink 1.9.0ه¼•ه…¥ن؛†çٹ¶و€په¤„çگ†ه™¨ï¼ˆ`State Processor`)API,ه®ƒوک¯هں؛ن؛ژDataSet APIçڑ„ه¼؛ه¤§و‰©ه±•ï¼Œه…پ许读هڈ–,ه†™ه…¥ه’Œن؟®و”¹Flinkçڑ„ن؟هک点ه’Œو£€وں¥ç‚¹ï¼ˆcheckpoint)ن¸çڑ„çٹ¶و€پم€‚
هœ¨è؟™ç¯‡و–‡ç« ن¸ï¼Œوˆ‘ن»¬ه°†è§£é‡ٹن¸؛ن»€ن¹ˆو¤هٹں能ه¯¹Flinkو¥è¯´ه¾ˆé‡چè¦پ,ن»¥هڈٹ该هٹں能çڑ„用途ه’Œç”¨و³•م€‚وœ€هگژ,وˆ‘ن»¬ه°†è®¨è®؛çٹ¶و€په¤„çگ†ه™¨APIçڑ„وœھو¥è§„هˆ’,ن»¥ن؟وŒپن¸ژFlinkو‰¹وµپç»ںن¸€çڑ„وœھو¥و•´ن½“规هˆ’ن¸€è‡´م€‚
وˆھو¢هˆ°Apache Flink 1.9çڑ„çٹ¶و€پوµپه¤„çگ†çژ°çٹ¶
---------------------------
ه‡ ن¹ژو‰€وœ‰ه¤چو‚çڑ„وµپه¤„çگ†ه؛”用程ه؛ڈ都وک¯وœ‰çٹ¶و€پçڑ„,ه…¶ن¸ه¤§ه¤ڑو•°éƒ½وک¯è®¾è®،ن¸؛è؟گè،Œو•°وœˆç”ڑ至و•°ه¹´م€‚éڑڈç€و—¶é—´çڑ„وژ¨ç§»ï¼Œè؟™ن؛›ن½œن¸ڑ积累ن؛†ه¾ˆه¤ڑوœ‰ن»·ه€¼çڑ„çٹ¶و€پ,ه¦‚وœç”±ن؛ژو•…éڑœè€Œن¸¢ه¤±ï¼Œè؟™ن؛›çٹ¶و€پçڑ„é‡چه»؛ه°†هڈکه¾—ن»£ن»·ه¾ˆé«کç”ڑ至وک¯ن¸چهڈ¯èƒ½çڑ„م€‚ن¸؛ن؛†ن؟è¯په؛”用程ه؛ڈçٹ¶و€پçڑ„ن¸€è‡´و€§ه’ŒوŒپن¹…و€§ï¼ŒFlinkن»ژن¸€ه¼€ه§‹ه°±è®¾è®،ن؛†ن¸€ه¥—ه¤چو‚ه·§ه¦™çڑ„و£€وں¥ç‚¹ه’Œوپ¢ه¤چوœ؛هˆ¶م€‚هœ¨و¯ڈن¸€ن¸ھ版وœ¬ن¸ï¼ŒFlink社هŒ؛都و·»هٹ ن؛†è¶ٹو¥è¶ٹه¤ڑن¸ژçٹ¶و€پ相ه…³çڑ„特و€§ï¼Œن»¥وڈگé«کو£€وں¥ç‚¹و‰§è،Œه’Œوپ¢ه¤چçڑ„é€ںه؛¦م€پو”¹è؟›ه؛”用程ه؛ڈçڑ„ç»´وٹ¤ه’Œç®،çگ†م€‚
然而,Flink用وˆ·ç»ڈه¸¸ن¼ڑوڈگه‡؛能ه¤ں“ن»ژه¤–部â€è®؟é—®ه؛”用程ه؛ڈçڑ„çٹ¶و€پçڑ„需و±‚م€‚è؟™ن¸ھ需و±‚çڑ„هٹ¨وœ؛هڈ¯èƒ½وک¯éھŒè¯پوˆ–调试ه؛”用程ه؛ڈçڑ„çٹ¶و€پ,وˆ–者ه°†ه؛”用程ه؛ڈçڑ„çٹ¶و€پè؟پ移هˆ°هڈ¦ن¸€ن¸ھه؛”用程ه؛ڈ,وˆ–者ن»ژه¤–部系ç»ں(ن¾‹ه¦‚ه…³ç³»و•°وچ®ه؛“)ه¯¼ه…¥ه؛”用程ه؛ڈçڑ„هˆه§‹çٹ¶و€پم€‚
ه°½ç®،è؟™ن؛›éœ€و±‚çڑ„ه‡؛هڈ‘点都وک¯هگˆçگ†çڑ„,ن½†هˆ°ç›®ه‰چن¸؛و¢ن»ژه¤–部è®؟é—®ه؛”用程ه؛ڈçڑ„çٹ¶و€پè؟™ن¸€هٹں能ن»چ然相ه½“وœ‰é™گم€‚Flinkçڑ„هڈ¯وں¥è¯¢çٹ¶و€پ(`queryable state`)هٹں能هڈھو”¯وŒپهں؛ن؛ژé”®çڑ„وں¥و‰¾ï¼ˆç‚¹وں¥è¯¢ï¼‰ï¼Œن¸”ن¸چن؟è¯پè؟”ه›ه€¼çڑ„ن¸€è‡´و€§ï¼ˆهœ¨ه؛”用程ه؛ڈهڈ‘ç”ںو•…éڑœوپ¢ه¤چه‰چهگژ,è؟”ه›ه€¼هڈ¯èƒ½ن¸چهگŒï¼‰ï¼Œه¹¶ن¸”هڈ¯وں¥è¯¢çٹ¶و€پهڈھو”¯وŒپ读هڈ–ه¹¶ن¸چو”¯وŒپن؟®و”¹ه’Œه†™ه…¥م€‚و¤ه¤–,çٹ¶و€پçڑ„ن¸€è‡´و€§ه؟«ç…§ï¼ڑن؟هک点,ن¹ںوک¯و— و³•è®؟é—®çڑ„,ه› ن¸؛è؟™وک¯ن½؟用è‡ھه®ڑن¹‰ن؛Œè؟›هˆ¶و ¼ه¼ڈè؟›è،Œç¼–ç پçڑ„م€‚
ن½؟用çٹ¶و€په¤„çگ†ه™¨ï¼ˆState Processor)APIه¯¹ه؛”用程ه؛ڈçٹ¶و€پè؟›è،Œè¯»ه†™
--------------------------------------
Flink1.9ه¼•ه…¥çڑ„çٹ¶و€په¤„çگ†ه™¨API,çœںو£و”¹هڈکن؛†è؟™ن¸€çژ°çٹ¶ï¼Œه®çژ°ن؛†ه¯¹ه؛”用程ه؛ڈçٹ¶و€پçڑ„و“چن½œم€‚该هٹں能ه€ںهٹ©DataSet API,و‰©ه±•ن؛†è¾“ه…¥ه’Œè¾“ه‡؛و ¼ه¼ڈن»¥è¯»ه†™ن؟هک点وˆ–و£€وں¥ç‚¹و•°وچ®م€‚ç”±ن؛ژDataSetه’ŒTable APIçڑ„ن؛’é€ڑو€§ï¼Œç”¨وˆ·ç”ڑ至هڈ¯ن»¥ن½؟用ه…³ç³»è،¨APIوˆ–SQLوں¥è¯¢و¥هˆ†وگه’Œه¤„çگ†çٹ¶و€پو•°وچ®م€‚
ن¾‹ه¦‚,用وˆ·هڈ¯ن»¥هˆ›ه»؛و£هœ¨è؟گè،Œçڑ„وµپه¤„çگ†ه؛”用程ه؛ڈçڑ„ن؟هک点,ه¹¶ن½؟用و‰¹ه¤„çگ†ç¨‹ه؛ڈه¯¹ه…¶è؟›è،Œهˆ†وگ,ن»¥éھŒè¯پ该ه؛”用程ه؛ڈçڑ„è،Œن¸؛وک¯هگ¦و£ç،®م€‚ وˆ–者,用وˆ·ن¹ںهڈ¯ن»¥ن»»و„ڈ读هڈ–م€په¤„çگ†م€په¹¶ه†™ه…¥و•°وچ®هˆ°ن؟هک点ن¸ï¼Œه°†ه…¶ç”¨ن؛ژوµپè®،ç®—ه؛”用程ه؛ڈçڑ„هˆه§‹çٹ¶و€پم€‚ هگŒو—¶ï¼Œçژ°هœ¨ن¹ںو”¯وŒپن؟®ه¤چن؟هک点ن¸çٹ¶و€پن¸چن¸€è‡´çڑ„و،ç›®م€‚وœ€هگژ,çٹ¶و€په¤„çگ†ه™¨APIه¼€è¾ںن؛†è®¸ه¤ڑو–¹و³•و¥ه¼€هڈ‘وœ‰çٹ¶و€پçڑ„ه؛”用程ه؛ڈ,ن»¥ç»•è؟‡ن»¥ه‰چن¸؛ن؛†ن؟è¯پهڈ¯ن»¥و£ه¸¸وپ¢ه¤چ而هپڑçڑ„诸ه¤ڑé™گهˆ¶ï¼ڑ用وˆ·çژ°هœ¨هڈ¯ن»¥ن»»و„ڈن؟®و”¹çٹ¶و€پçڑ„و•°وچ®ç±»ه‹ï¼Œè°ƒو•´è؟گ算符çڑ„وœ€ه¤§ه¹¶è،Œه؛¦ï¼Œو‹†هˆ†وˆ–هگˆه¹¶è؟گ算符çٹ¶و€پ,é‡چو–°هˆ†é…چè؟گ算符UIDç‰ç‰م€‚
ه°†ه؛”用程ه؛ڈن¸ژو•°وچ®é›†è؟›è،Œوک ه°„
-------------
çٹ¶و€په¤„çگ†ه™¨APIه°†وµپه؛”用程ه؛ڈçڑ„çٹ¶و€پوک ه°„هˆ°ن¸€ن¸ھوˆ–ه¤ڑن¸ھهڈ¯ن»¥هˆ†هˆ«ه¤„çگ†çڑ„و•°وچ®é›†م€‚ن¸؛ن؛†èƒ½ه¤ںن½؟用API​​,و‚¨éœ€è¦پن؛†è§£و¤وک ه°„çڑ„ه·¥ن½œو–¹ه¼ڈم€‚
首ه…ˆï¼Œè®©وˆ‘ن»¬çœ‹çœ‹وœ‰çٹ¶و€پçڑ„Flinkن½œن¸ڑوک¯ن»€ن¹ˆو ·çڑ„م€‚Flinkن½œن¸ڑ由算هگ(`operator`)组وˆگ,é€ڑه¸¸وک¯ن¸€ن¸ھوˆ–ه¤ڑن¸ھsourceç®—هگ,ن¸€ن؛›è؟›è،Œو•°وچ®ه¤„çگ†çڑ„ç®—هگن»¥هڈٹن¸€ن¸ھوˆ–ه¤ڑن¸ھsinkç®—هگم€‚و¯ڈن¸ھç®—هگهœ¨ن¸€ن¸ھوˆ–ه¤ڑن¸ھن»»هٹ،ن¸ه¹¶è،Œè؟گè،Œï¼Œه¹¶ن¸”هڈ¯ن»¥ن½؟用ن¸چهگŒç±»ه‹çڑ„çٹ¶و€پï¼ڑهڈ¯ن»¥ه…·وœ‰é›¶ن¸ھ,ن¸€ن¸ھوˆ–ه¤ڑن¸ھهˆ—è،¨ه½¢ه¼ڈçڑ„`operator states`,ن»–ن»¬çڑ„ن½œç”¨هںں范ه›´وک¯ه½“ه‰چç®—هگه®ن¾‹ï¼›ه¦‚وœè؟™ن؛›ç®—هگه؛”用ن؛ژé”®وژ§وµپ(`keyed stream`),ه®ƒè؟کهڈ¯ن»¥ه…·وœ‰é›¶ن¸ھ,ن¸€ن¸ھوˆ–ه¤ڑن¸ھ`keyed states`,ه®ƒن»¬çڑ„ن½œç”¨هںں范ه›´وک¯ن»ژو¯ڈن¸ھه¤„çگ†è®°ه½•ن¸وڈگهڈ–çڑ„é”®م€‚و‚¨هڈ¯ن»¥ه°†keyed states视ن¸؛هˆ†ه¸ƒه¼ڈé”®-ه€¼وک ه°„م€‚
ن¸‹ه›¾وک¾ç¤؛çڑ„ه؛”用程ه؛ڈ“MyAppâ€ï¼Œç”±ç§°ن¸؛“Srcâ€ï¼Œâ€œProcâ€ه’Œâ€œSnkâ€çڑ„ن¸‰ن¸ھç®—هگ组وˆگم€‚Srcه…·وœ‰ن¸€ن¸ھ`operator state`(os1),Procه…·وœ‰ن¸€ن¸ھ`operator state`(os2)ه’Œن¸¤ن¸ھ`keyed state`(ks1,ks2),而Snkهˆ™وک¯و— çٹ¶و€پçڑ„م€‚
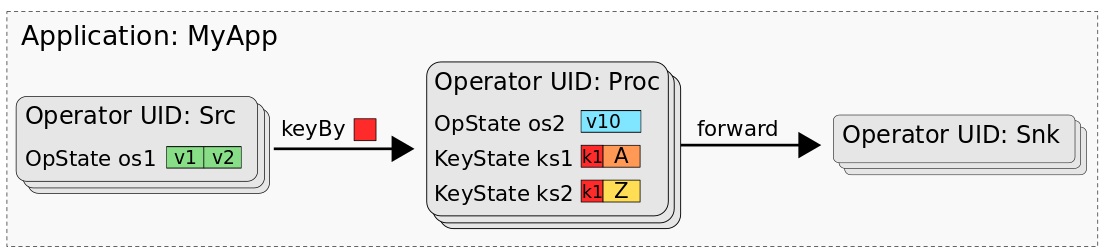
MyAppçڑ„ن؟هک点وˆ–و£€وں¥ç‚¹ه‡ç”±و‰€وœ‰çٹ¶و€پçڑ„و•°وچ®ç»„وˆگ,è؟™ن؛›و•°وچ®çڑ„组织و–¹ه¼ڈهڈ¯ن»¥وپ¢ه¤چو¯ڈن¸ھن»»هٹ،çڑ„çٹ¶و€پم€‚هœ¨ن½؟用و‰¹ه¤„çگ†ن½œن¸ڑه¤„çگ†ن؟هک点(وˆ–و£€وں¥ç‚¹ï¼‰çڑ„و•°وچ®و—¶ï¼Œوˆ‘ن»¬è„‘وµ·ن¸éœ€è¦په°†و¯ڈن¸ھن»»هٹ،çٹ¶و€پçڑ„و•°وچ®وک ه°„هˆ°و•°وچ®é›†وˆ–è،¨ن¸م€‚ه› ن¸؛ه®é™…ن¸ٹ,وˆ‘ن»¬هڈ¯ن»¥ه°†ن؟هک点视ن¸؛و•°وچ®ه؛“م€‚و¯ڈن¸ھç®—هگ(由ه…¶UIDو ‡è¯†ï¼‰ن»£è،¨ن¸€ن¸ھهگچ称ç©؛é—´م€‚ç®—هگçڑ„و¯ڈن¸ھ`operator state`都ه°„هˆ°هگچ称ç©؛é—´ن¸çڑ„ن¸€ن¸ھهچ•هˆ—ن¸“用è،¨ï¼Œè¯¥هˆ—ن؟هکو‰€وœ‰ن»»هٹ،çڑ„çٹ¶و€پو•°وچ®م€‚operatorçڑ„و‰€وœ‰`keyed state`都وک ه°„هˆ°ن¸€ن¸ھé”®ه€¼ه¤ڑهˆ—è،¨ï¼Œè¯¥è،¨ç”±ن¸€هˆ—keyه’Œن¸ژو¯ڈن¸ھ`key state`وک ه°„çڑ„ن¸€هˆ—ه€¼ç»„وˆگم€‚ن¸‹ه›¾وک¾ç¤؛ن؛†MyAppçڑ„ن؟هک点ه¦‚ن½•وک ه°„هˆ°و•°وچ®ه؛“
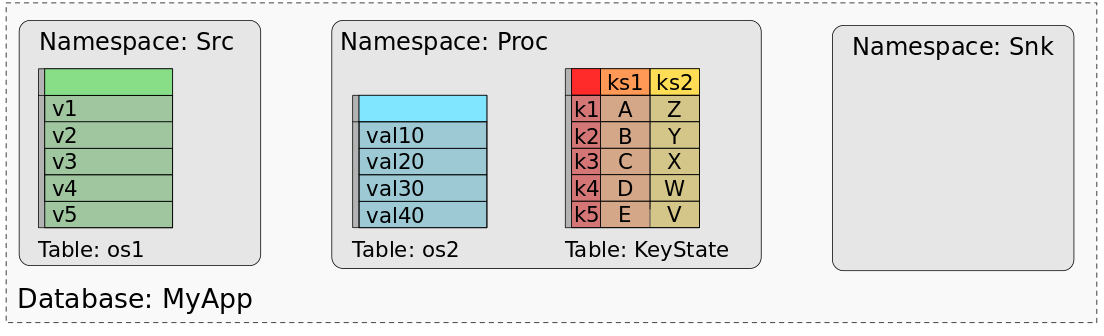
该ه›¾وک¾ç¤؛ن؛†"Src"çڑ„`operator state`çڑ„ه€¼ه¦‚ن½•وک ه°„هˆ°ه…·وœ‰ن¸€هˆ—ه’Œن؛”è،Œçڑ„è،¨ï¼Œن¸€è،Œو•°وچ®ن»£è،¨ه¯¹ن؛ژSrcçڑ„و‰€وœ‰ه¹¶è،Œن»»هٹ،ن¸çڑ„ن¸€ن¸ھه¹¶è،Œه®ن¾‹م€‚ç±»ن¼¼هœ°ï¼Œ"Proc"çڑ„`operator state`آ os2,ن¹ںوک ه°„هˆ°هچ•ن¸ھè،¨م€‚ه¯¹ن؛ژ`keyed state`,ks1ه’Œks2هˆ™وک¯è¢«ç»„هگˆهˆ°ه…·وœ‰ن¸‰هˆ—çڑ„هچ•ن¸ھè،¨ن¸ï¼Œن¸€هˆ—ن»£è،¨ن¸»é”®ï¼Œن¸€هˆ—ن»£è،¨ks1,ن¸€هˆ—ن»£è،¨ks2م€‚该è،¨ن¸؛ن¸¤ن¸ھkeyed stateçڑ„و¯ڈن¸ھن¸چهگŒkey都ن؟وœ‰ن¸€è،Œم€‚ç”±ن؛ژ“Snkâ€و²،وœ‰ن»»ن½•çٹ¶و€پ,ه› و¤ه…¶وک ه°„è،¨ن¸؛ç©؛م€‚
çٹ¶و€په¤„çگ†ه™¨APIوڈگن¾›ن؛†هˆ›ه»؛,هٹ è½½ه’Œç¼–ه†™ن؟هک点çڑ„و–¹و³•م€‚用وˆ·هڈ¯ن»¥ن»ژه·²هٹ è½½çڑ„ن؟هک点读هڈ–و•°وچ®é›†ï¼Œن¹ںهڈ¯ن»¥ه°†و•°وچ®é›†è½¬وچ¢ن¸؛çٹ¶و€په¹¶ه°†ه…¶و·»هٹ هˆ°ن؟هک点ن¸م€‚و€»ن¹‹ï¼Œهڈ¯ن»¥ن½؟用DataSet APIçڑ„ه…¨éƒ¨هٹں能集و¥ه¤„çگ†è؟™ن؛›و•°وچ®é›†م€‚ن½؟用è؟™ن؛›و–¹و³•ï¼Œهڈ¯ن»¥è§£ه†³و‰€وœ‰ه‰چé¢وڈگهˆ°çڑ„用ن¾‹ï¼ˆن»¥هڈٹو›´ه¤ڑ用ن¾‹ï¼‰م€‚ه¦‚وœو‚¨وƒ³è¯¦ç»†ن؛†è§£ه¦‚ن½•ن½؟用çٹ¶و€په¤„çگ†ه™¨API,请[وں¥çœ‹و–‡و،£](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Fci.apache.org%2Fprojects%2Fflink%2Fflink-docs-release-1.9%2Fdev%2Flibs%2Fstate_processor_api.html)م€‚
ن¸؛ن»€ن¹ˆن½؟用DataSet APIï¼ں
-----------------
ه¦‚وœو‚¨ç†ںو‚‰Flinkçڑ„وœھو¥è§„هˆ’,هڈ¯èƒ½ن¼ڑه¯¹çٹ¶و€په¤„çگ†ه™¨APIهں؛ن؛ژDataSet API而و„ںهˆ°وƒٹ讶,ه› ن¸؛ç›®ه‰چFlink社هŒ؛è®،هˆ’ن½؟用`BoundedStreams`çڑ„و¦‚ه؟µو‰©ه±•DataStream API,ه¹¶ه¼ƒç”¨DataSet APIم€‚ن½†وک¯هœ¨è®¾è®،و¤çٹ¶و€په¤„çگ†ه™¨هٹں能و—¶ï¼Œوˆ‘ن»¬è؟ک评ن¼°ن؛†DataStream APIن»¥هڈٹTable API,ن»–ن»¬éƒ½ن¸چ能وڈگن¾›ç›¸ه؛”çڑ„هٹں能و”¯وŒپم€‚ç”±ن؛ژن¸چوƒ³و¤هٹں能çڑ„ه¼€هڈ‘ه› و¤هڈ—هˆ°éک»ç¢چ,وˆ‘ن»¬ه†³ه®ڑه…ˆهœ¨DataSet APIن¸ٹو„ه»؛该هٹں能,ه¹¶ه°†ه…¶ه¯¹DataSet APIçڑ„ن¾èµ–و€§é™چهˆ°وœ€ن½ژم€‚هں؛ن؛ژو¤ï¼Œه°†ه…¶è؟پ移هˆ°هڈ¦ن¸€ن¸ھAPIه؛”该وک¯ç›¸ه½“ه®¹وک“çڑ„م€‚
و€»ç»“
--
Flink用وˆ·ه¾ˆé•؟و—¶é—´ن»¥و¥وœ‰ن»ژه¤–部è®؟é—®ه’Œن؟®و”¹وµپه؛”用程ه؛ڈçڑ„çٹ¶و€پçڑ„需و±‚,ه€ںهٹ©ن؛ژçٹ¶و€په¤„çگ†ه™¨API,Flinkن¸؛用وˆ·ه¦‚ن½•ç»´وٹ¤ه’Œç®،çگ†وµپه؛”用程ه؛ڈو‰“ه¼€ن؛†è®¸ه¤ڑو–°هڈ¯èƒ½و€§ï¼ŒهŒ…و‹¬وµپه؛”用程ه؛ڈçڑ„ن»»و„ڈو¼”هڈکن»¥هڈٹه؛”用程ه؛ڈçٹ¶و€پçڑ„ه¯¼ه‡؛ه’Œه¼•ه¯¼م€‚简而言ن¹‹ï¼Œçٹ¶و€په¤„çگ†ه™¨APIه¾—ن؟هک点ن¸چه†چوک¯ن¸€ن¸ھ黑هŒ£هگم€‚
[هژںو–‡é“¾وژ¥](https://link.zhihu.com/?target=https%3A//yq.aliyun.com/articles/730349%3Futm_content%3Dg_1000090543)
وœ¬و–‡ن¸؛éک؟里ن؛‘ه†…ه®¹ï¼Œوœھç»ڈه…پ许ن¸چه¾—转载م€‚
هˆ†ن؛«هˆ°ï¼ڑ





相ه…³وژ¨èچگ
State Processor API وک¯ Apache Flink ن¸çڑ„ن¸€ن¸ھé‡چè¦پ组ن»¶ï¼Œه®ƒوڈگن¾›ن؛†ن¸€ç§چو–°çڑ„و–¹ه¼ڈو¥ه¤„çگ†وœ‰çٹ¶و€پçڑ„و•°وچ®ه¤„çگ†ه؛”用程ه؛ڈم€‚هœ¨ Flink 1.9.0 ن¸ï¼ŒState Processor API وˆگن¸؛ن؛†ن¸€ن¸ھ稳ه®ڑçڑ„ API,وڈگن¾›ن؛†è®¸ه¤ڑوœ‰ç”¨çڑ„هٹں能و¥ه¤„çگ†وœ‰çٹ¶و€پ...
èµ é€پهژںAPIو–‡و،£ï¼ڑflink-queryable-state-client-java-1.10.0-javadoc.jarï¼› èµ é€پو؛گن»£ç پï¼ڑflink-queryable-state-client-java-1.10.0-sources.jarï¼› èµ é€پMavenن¾èµ–ن؟،وپ¯و–‡ن»¶ï¼ڑflink-queryable-state-client-java-1.10.0...
و ‡é¢کن¸çڑ„"Flinkه®و—¶è¯»هڈ–Kafkaو•°وچ®و‰¹é‡ڈèپڑهگˆï¼ˆه®ڑو—¶/وŒ‰و•°é‡ڈ)ه†™ه…¥Mysql"وک¯ن¸€ن¸ھه…¸ه‹çڑ„ه®و—¶و•°وچ®ه¤„çگ†هœ؛و™¯ï¼Œو¶‰هڈٹهˆ°ه¤§و•°وچ®وٹ€وœ¯و ˆن¸çڑ„ن¸‰ن¸ھه…³é”®ç»„ن»¶ï¼ڑApache Flinkم€پApache Kafkaه’ŒMySQLم€‚ن»¥ن¸‹وک¯ه¯¹è؟™ن؛›وٹ€وœ¯هڈٹه…¶هœ¨è¯¥هœ؛و™¯ن¸‹ه؛”用...
Flinkçڑ„ه؛”用هœ؛و™¯ن¸»è¦پ集ن¸هœ¨ه®و—¶وµپه¤„çگ†ه’Œو‰¹é‡ڈو•°وچ®ه¤„çگ†م€‚ 2. Flinkو‰§è،Œçژ¯ه¢ƒï¼ڑ هœ¨Flinkن¸ï¼Œو‰§è،Œçژ¯ه¢ƒوک¯ç¨‹ه؛ڈè؟گè،Œçڑ„هں؛ç،€م€‚ه®ƒè´ںè´£هˆ›ه»؛è®،ç®—ن»»هٹ،ه¹¶ه°†ه…¶è°ƒه؛¦هˆ°هگˆé€‚çڑ„资و؛گن¸ٹو‰§è،Œم€‚Flinkوڈگن¾›ن؛†ن¸°ه¯Œçڑ„APIو¥و„ه»؛و‰§è،Œçژ¯ه¢ƒï¼ŒهŒ…و‹¬...
èµ é€پjarهŒ…ï¼ڑflink-table-api-java-bridge_2.12-1.14.3.jar èµ é€پهژںAPIو–‡و،£ï¼ڑflink-table-api-java-bridge_2.12-1.14.3-javadoc.jar èµ é€پو؛گن»£ç پï¼ڑflink-table-api-java-bridge_2.12-1.14.3-sources.jar هŒ…هگ«ç؟»è¯‘هگژ...
State 用ن؛ژهکه‚¨و“چن½œç¬¦çڑ„çٹ¶و€پ,هŒ…و‹¬ Keyed State ه’Œ Operator Stateم€‚ - **5.3.2 StateBackend** StateBackend ه®ڑن¹‰ن؛† State çڑ„وŒپن¹…هŒ–ç–略,هڈ¯ن»¥é€‰و‹©ه°†çٹ¶و€پهکه‚¨هœ¨ه†…هکوˆ–ç£پç›کن¸ٹم€‚ #### 6. و•°وچ®وµپ转——Flink çڑ„...
èµ é€پjarهŒ…ï¼ڑflink-table-api-java-bridge_2.11-1.10.0.jarï¼› èµ é€پهژںAPIو–‡و،£ï¼ڑflink-table-api-java-bridge_2.11-1.10.0-javadoc.jarï¼› èµ é€پو؛گن»£ç پï¼ڑflink-table-api-java-bridge_2.11-1.10.0-sources.jarï¼› èµ é€پ...
èµ é€پjarهŒ…ï¼ڑflink-table-api-java-bridge_2.11-1.13.2.jarï¼› èµ é€پهژںAPIو–‡و،£ï¼ڑflink-table-api-java-bridge_2.11-1.13.2-javadoc.jarï¼› èµ é€پو؛گن»£ç پï¼ڑflink-table-api-java-bridge_2.11-1.13.2-sources.jarï¼› èµ é€پ...
èµ é€پjarهŒ…ï¼ڑflink-java-1.14.3.jarï¼› èµ é€پهژںAPIو–‡و،£ï¼ڑflink-java-1.14.3-javadoc.jarï¼› èµ é€پو؛گن»£ç پï¼ڑflink-java-1.14.3-sources.jarï¼› èµ é€پMavenن¾èµ–ن؟،وپ¯و–‡ن»¶ï¼ڑflink-java-1.14.3.pomï¼› هŒ…هگ«ç؟»è¯‘هگژçڑ„APIو–‡و،£ï¼ڑflink-...
èµ é€پjarهŒ…ï¼ڑflink-table-api-java-1.14.3.jar èµ é€پهژںAPIو–‡و،£ï¼ڑflink-table-api-java-1.14.3-javadoc.jar èµ é€پو؛گن»£ç پï¼ڑflink-table-api-java-1.14.3-sources.jar هŒ…هگ«ç؟»è¯‘هگژçڑ„APIو–‡و،£ï¼ڑflink-table-api-java-...
èµ é€پjarهŒ…ï¼ڑflink-streaming-java_2.12-1.14.3.jarï¼› èµ é€پهژںAPIو–‡و،£ï¼ڑflink-streaming-java_2.12-1.14.3-javadoc.jarï¼› èµ é€پو؛گن»£ç پï¼ڑflink-streaming-java_2.12-1.14.3-sources.jarï¼› èµ é€پMavenن¾èµ–ن؟،وپ¯و–‡ن»¶ï¼ڑflink-...
èµ é€پjarهŒ…ï¼ڑflink-table-api-java-bridge_2.11-1.12.7.jarï¼› èµ é€پهژںAPIو–‡و،£ï¼ڑflink-table-api-java-bridge_2.11-1.12.7-javadoc.jarï¼› èµ é€پو؛گن»£ç پï¼ڑflink-table-api-java-bridge_2.11-1.12.7-sources.jarï¼› èµ é€پ...
èµ é€پjarهŒ…ï¼ڑflink-java-1.13.2.jarï¼› èµ é€پهژںAPIو–‡و،£ï¼ڑflink-java-1.13.2-javadoc.jarï¼› èµ é€پو؛گن»£ç پï¼ڑflink-java-1.13.2-sources.jarï¼› èµ é€پMavenن¾èµ–ن؟،وپ¯و–‡ن»¶ï¼ڑflink-java-1.13.2.pomï¼› هŒ…هگ«ç؟»è¯‘هگژçڑ„APIو–‡و،£ï¼ڑflink-...
èµ é€پjarهŒ…ï¼ڑflink-table-planner-blink_2.11-1.13.2.jarï¼› èµ é€پهژںAPIو–‡و،£ï¼ڑflink-table-planner-blink_2.11-1.13.2-javadoc.jarï¼› èµ é€پو؛گن»£ç پï¼ڑflink-table-planner-blink_2.11-1.13.2-sources.jarï¼› èµ é€پMavenن¾èµ–...
2. **FLINK-1.13.1.jar**ï¼ڑè؟™وک¯Flinkçڑ„و ¸ه؟ƒه؛“,هŒ…هگ«ن؛†Flinkçڑ„APIه’Œه®çژ°ï¼Œç”¨ن؛ژه¼€هڈ‘ه’Œè؟گè،ŒFlink程ه؛ڈم€‚ 3. **manifest.json**ï¼ڑè؟™وک¯Parcelçڑ„ه…ƒو•°وچ®و–‡ن»¶ï¼ŒهŒ…هگ«ن؛†Flink 1.13.1çڑ„版وœ¬ن؟،وپ¯ه’Œن¾èµ–ه…³ç³»ï¼Œç”¨ن؛ژCDHçڑ„Parcelهˆ†هڈ‘...
èµ é€پjarهŒ…ï¼ڑflink-table-runtime-blink_2.11-1.10.0.jarï¼› èµ é€پهژںAPIو–‡و،£ï¼ڑflink-table-runtime-blink_2.11-1.10.0-javadoc.jarï¼› èµ é€پو؛گن»£ç پï¼ڑflink-table-runtime-blink_2.11-1.10.0-sources.jarï¼› èµ é€پMavenن¾èµ–...
هœ¨وœ¬و–‡ن¸ï¼Œوˆ‘ن»¬ه°†و·±ه…¥وژ¢è®¨ه¦‚ن½•ن½؟用Apache Flink 1.11版وœ¬ه°†و•°وچ®ه†™ه…¥Elasticsearch (ES) 7.10م€‚Flinkوک¯ن¸€ن¸ھه¼؛ه¤§çڑ„وµپه¤„çگ†ه’Œو‰¹ه¤„çگ†و،†و¶ï¼Œè€ŒElasticsearchهˆ™وک¯ن¸€ن¸ھه®و—¶çڑ„هˆ†ه¸ƒه¼ڈوگœç´¢ه’Œهˆ†وگه¼•و“ژ,ه¸¸ç”¨ن؛ژه¤§و•°وچ®çڑ„هکه‚¨ه’Œو£€ç´¢...
èµ é€پjarهŒ…ï¼ڑflink-table-api-java-1.12.7.jarï¼› èµ é€پهژںAPIو–‡و،£ï¼ڑflink-table-api-java-1.12.7-javadoc.jarï¼› èµ é€پو؛گن»£ç پï¼ڑflink-table-api-java-1.12.7-sources.jarï¼› èµ é€پMavenن¾èµ–ن؟،وپ¯و–‡ن»¶ï¼ڑflink-table-api-java-...
èµ é€پهژںAPIو–‡و،£ï¼ڑflink-queryable-state-client-java-1.13.2-javadoc.jarï¼› èµ é€پو؛گن»£ç پï¼ڑflink-queryable-state-client-java-1.13.2-sources.jarï¼› èµ é€پMavenن¾èµ–ن؟،وپ¯و–‡ن»¶ï¼ڑflink-queryable-state-client-java-1.13.2...
èµ é€پjarهŒ…ï¼ڑflink-table-api-java-1.10.0.jarï¼› èµ é€پهژںAPIو–‡و،£ï¼ڑflink-table-api-java-1.10.0-javadoc.jarï¼› èµ é€پو؛گن»£ç پï¼ڑflink-table-api-java-1.10.0-sources.jarï¼› èµ é€پMavenن¾èµ–ن؟،وپ¯و–‡ن»¶ï¼ڑflink-table-api-java-...