以下内容根据演讲视频以及PPT整理而成。
本次分享主要围绕以下两个方面:
一、构建可闭环、可沉淀、可持续的企业级数据赋能体系的背景
二、开发者数据银行
**一、构建可闭环、可沉淀、可持续的企业级数据赋能体系的背景**
**1.数据“四化”**
如何让属于企业自己的不同触点的数据快速形成一个闭环,沉淀串联这些零散的数据能够快速应用去赋能业务?这涉及到四个关键词,一是业务数据化,企业所有触点是否为真,是否被打通。第二是数据资产化,能否可以像管理资产一样很好地管理数据。第三是资产应用化,企业的资产能否有效应用?如何借助数据资产赋能业务,最后是应用价值化。所有的应用最终一定是为增长、为获客而服务,必须要有价值。在这背后最重要的是场景必须可闭环,数据必须可沉淀,最终数据中台、数据能源才是可持续的。
**2.构建可闭环、可沉淀的数据赋能体系的意义与价值**
下图展示了一套可闭环、可沉淀、可持续的企业级数据赋能体系是如何构建的。下图友盟+会推出一个面向企业的数据银行。数据银行和业务是一种什么样的协作关系?开发者数据银行会基于云基础设施,如MaxComput等,不断帮助企业采集各种场景、触点的数据,做相应的数据治理、提纯、模型加工、形成各种应用服务,基于UMID打通能力,多账号归一,多端归一,支持不同的终端数据打通(移动客户端、服务端、客户端不同的平台), 帮助开发者完成全场景、全触点的数据资产沉淀及应用的管理。
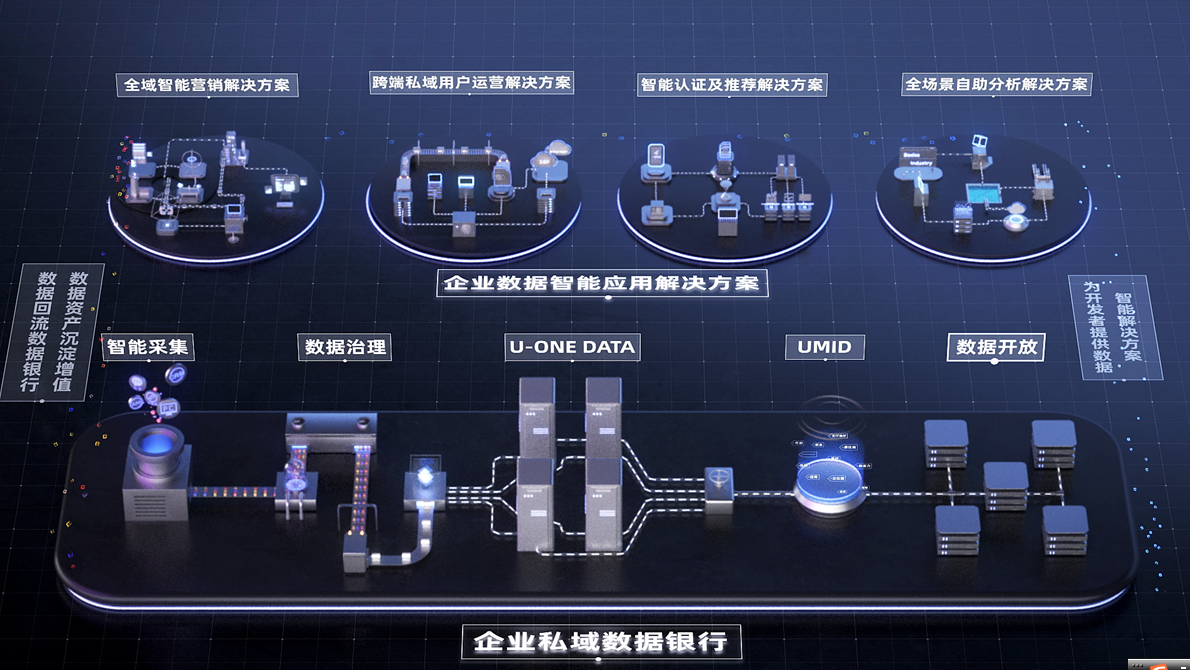
关于跨端用户运营会涉及两个问题,首先,公司每一次在媒体外投的数据是否已经回流?回流后是否能够对数据进行第二次应用?第二,通过你的营销是否将用户沉淀至用户池,跨端的用户是否有效运营起来了?其实除了营销,企业会有很多用户触点,如头条号、微博、抖音号等,用户资产的数据必须打通后才能发挥真正的价值,如果你在做你的搜索推荐,那么除了先进的模型算法之外,你的公司是否有数据底座,是否在收集回流归一各个触点的用户行为数据,并喂养给你的搜索引擎让它越来越智能;比如:此前投过广告的数据下次进行搜索时,你就应该推荐客户之前看过相关广告的内容。
**二、开发者数据银行**
每一家公司都需要构建属于自己的数据银行。比如在阿里巴巴的生态体系内,阿里在双11当天有上百万商家卖货,很多品牌商家都在阿里构建数据银行。同样,友盟+在数据智能服务领域已深耕九年,凭借服务百万家互联网企业的经验,面向开发者推出开发者数据银行,与MaxCompute形成一套核心解决方案服务用户。数据银行需要解决几个问题:第一,数据银行解决数据资产的管理和应用的问题,可以用采、建、管、用四个字来表达。首先是业务数据化和数据资产化,如何采集数据,并快速将端的数据形成数据资产。其次是资产应用,形成多种消息的推送,营销的拉新,包括App的推送,各种运营推荐,都是在数据银行上能够提供的服务。
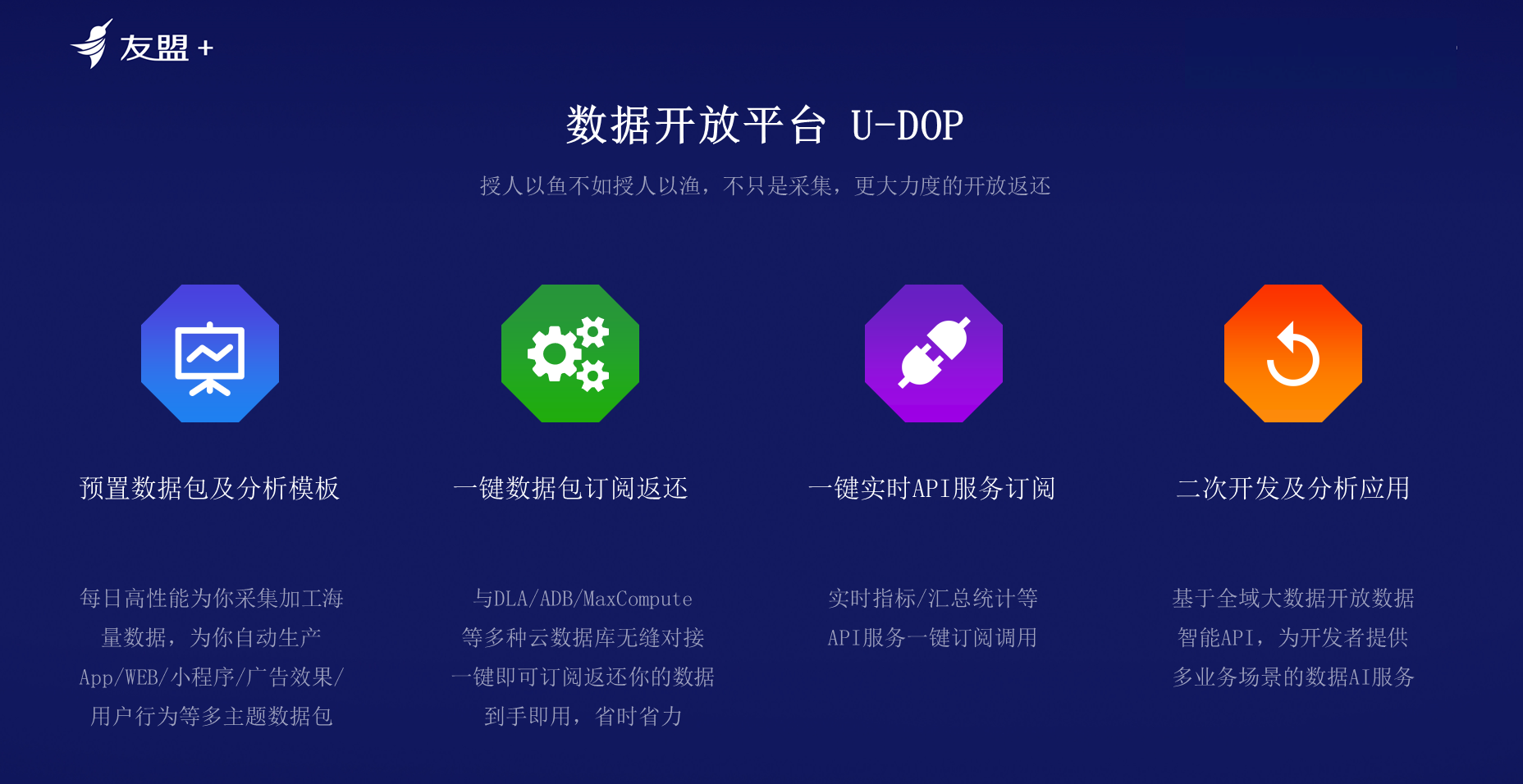
数据银行包括三类产品,从三个角度帮助用户解决问题。如下图所示,第一个产品是智能数据采集(U-SDC),第二个用户数据平台(U-CDP),帮助企业沉淀数据资产,高效服务业务部门、运营团队、市场等团队。第三个是数据开放平台(U-DOP),将采集到的数据通过友盟云之上与业务数据进行融合、分析,更全面的洞察用户,更场景化的应用数据。

**1、智能数据采集(U-SDC)**
无论AI或者智能引擎产品,本质是数据生产和采集。采集是数据质量的根本,数据采集的效率质量和效益都至关重要。数据采集工作需要关注是否全面掌控了公司的数据埋点?是否清楚某个场景应如何埋点?埋点后会产生什么样的数据?所埋的点是否正确有效?埋点是个长期运行的动作,需要不断验证埋点是否健康,最后一点回归到根本性的问题,如果埋点是错的,那么叠加的AI智能等所有内容也都会是错的。

**管理埋点**:埋点在大数据领域属于脏活累活,很多人不愿意做。常见的情况往往到了产品上线,需要使用数据的时候开始催促埋点。所以一家公司的埋点是否有人搞清楚?是否清楚这么多的埋点中哪些埋点正确,哪些异常?很多企业是不清楚的,这是一个残酷的现实。这是一个非常实际的问题,如果公司长期不清楚自己的埋点问题,便是在错误的数据上长期持续经营业务,越走越错。

**埋点智能方案推荐**:某家视频行业领域的公司的有两个团队,分别负责直播不同频道的业务,两个团队都会定义一些公司的埋点规范。但是数据规范性在两个团队不一致,如视频播放开始,A团队定义埋点全局参数叫Play,代表播放开始事件,B团队将其定义为Start。两个团队并不知道两个数据定义都不一致。案例中的问题看似不严重,但后续会发现公司数据不可持续,此时不论利用什么工具都不能解决问题。对于公司数据的管理一定要基于对业务场景的深刻理解,对业务场景进行标准、规范的定义。友盟+通过更多标准化的场景,包括为不同行业提供标准的埋点方案推荐来解决用户问题。友盟+聚合了非常多比较优秀的企业的实践,告诉用户如何埋点,埋点后能够解决哪些场景问题,同时会提供各种各样埋点智能推荐,针对技术团队沉淀公司基于场景的埋点解决方案的知识图谱。
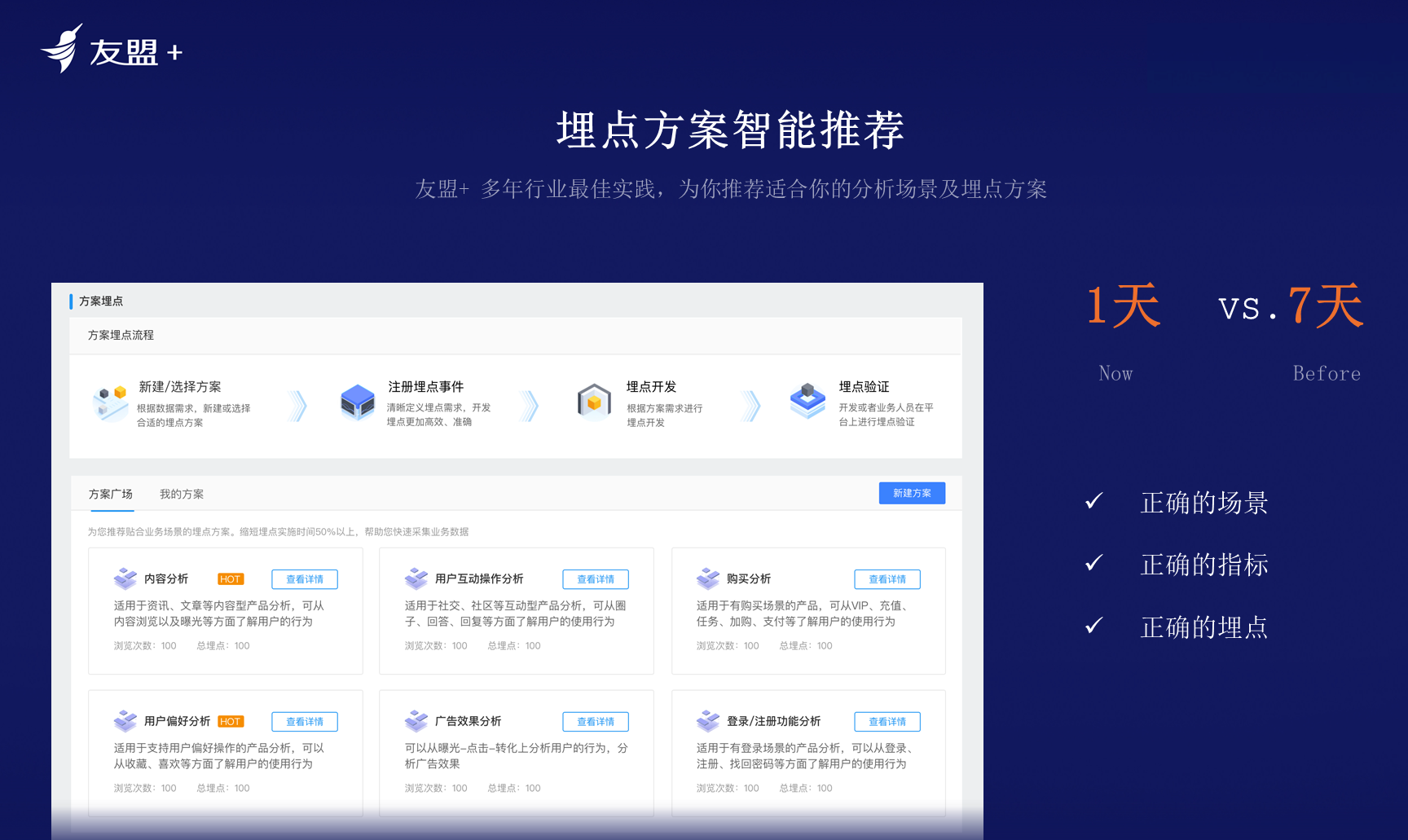
**智能埋点与智能验证**:开发做埋点是通过SDK代码,上报数据,后台打印日志。但并不意味数据上报则完成了埋点。如开发者直接将一个启动的日志埋在登录页面,突然有一天发现登陆数高于页面访问数近一倍。原因是该点同时被埋到了退出页面的加载进程中。即开发者错将一个点埋到两个位置。友盟+希望能够提供各种智能验证工具,比如当埋点上报时,会为开发者提供一个服务,如果埋点命名为“启动”,会有一系列的智能检测该埋点上报时所在的页面截图是否为正确的业务场景位置。智能埋点及其验证测试是非常重要的,友盟+会通过视觉切图计算验证埋点的正确性,为技术团队大幅减轻工作成本和压力。

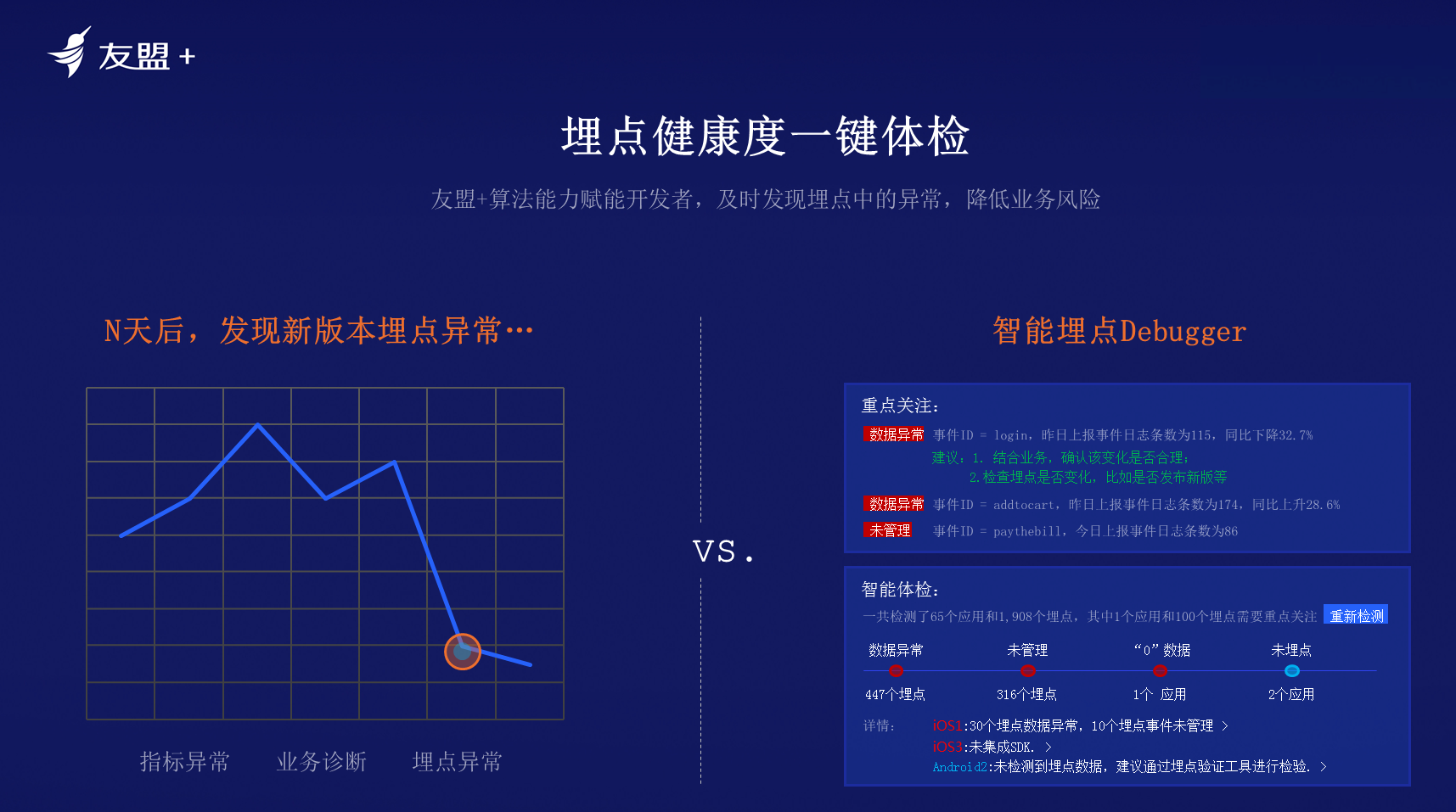
**埋点健康度一键体检**:当埋点全部完成,公司要做埋点健康度的验证,检查埋点是否符合规范,是否有异常点。埋点健康度是公司数据采集准确性的底座保证。数据团队和做客户端的开发团队经常会因为埋点问题产生矛盾。数据团队觉得数据有问题时一般归责为埋点问题,开发团队也会认为是数据团队配合问题。埋点的KPI就是先让埋点可视化,看到是由谁埋了哪个点,运行情况是否出现问题,是否按照规范埋点。如果埋点的规范度没有达到一定程度,团队是否应该承担责任?因此需要从管理角度、从组织层面以及产品能力层面解决公司埋点和采集的核心问题。
数据银行采集平台(U-SDC)会重点解决以上几个核心问题,使用户埋点可见、可控、可管,为用户埋点推荐合适的优秀方案,使用户埋点能够智能调试和验证,大幅降低埋点采集的成本,从而最终达成数据质量的根本性提升,使最终保存的数据资产有价值有质量。
**2\. 用户数据平台(U-CDP)**
数据采集之后,最重要的是解决用户资产问题。首先,用户资产管理一定要解决的问题是可信和归一。数据做了很多触点,每个请求在访问APP,其中很多是欺诈的流量,如何保证设备是可信的?基于UMID打通能力,多账号归一,多端归一,支持不同的终端数据打通(移动客户端、服务端、客户端不同的平台)的流转换关系洞察,归一完成后形成自动的标签生产库,使得私域的标签生产保持高效,并且能够赋能到业务团队,快速做标签、洞察、圈人,并且最终形成对客户的运营动作。

**是否清楚自己的用户资产**:用户数据平台(U-CDP)支持多源数据如何在很短时间一键接入平台,如移动客户端、服务端、客户端等源头。U-CDP保证可信识别和多端归一,通过全域数据识别,帮助用户做数据归一和提纯,过别打通后最终形成用户资产可视化,清楚公司触点来源,了解多少私域用户被沉淀下来。清楚上述问题再分析需要建哪些触点,需要增强哪些触点。最终沉淀下来的才真正是自己的私域数据资产。沉淀私域用户资产的一个前提是可运营,若不可运营、不可见,那么数据是无用的。

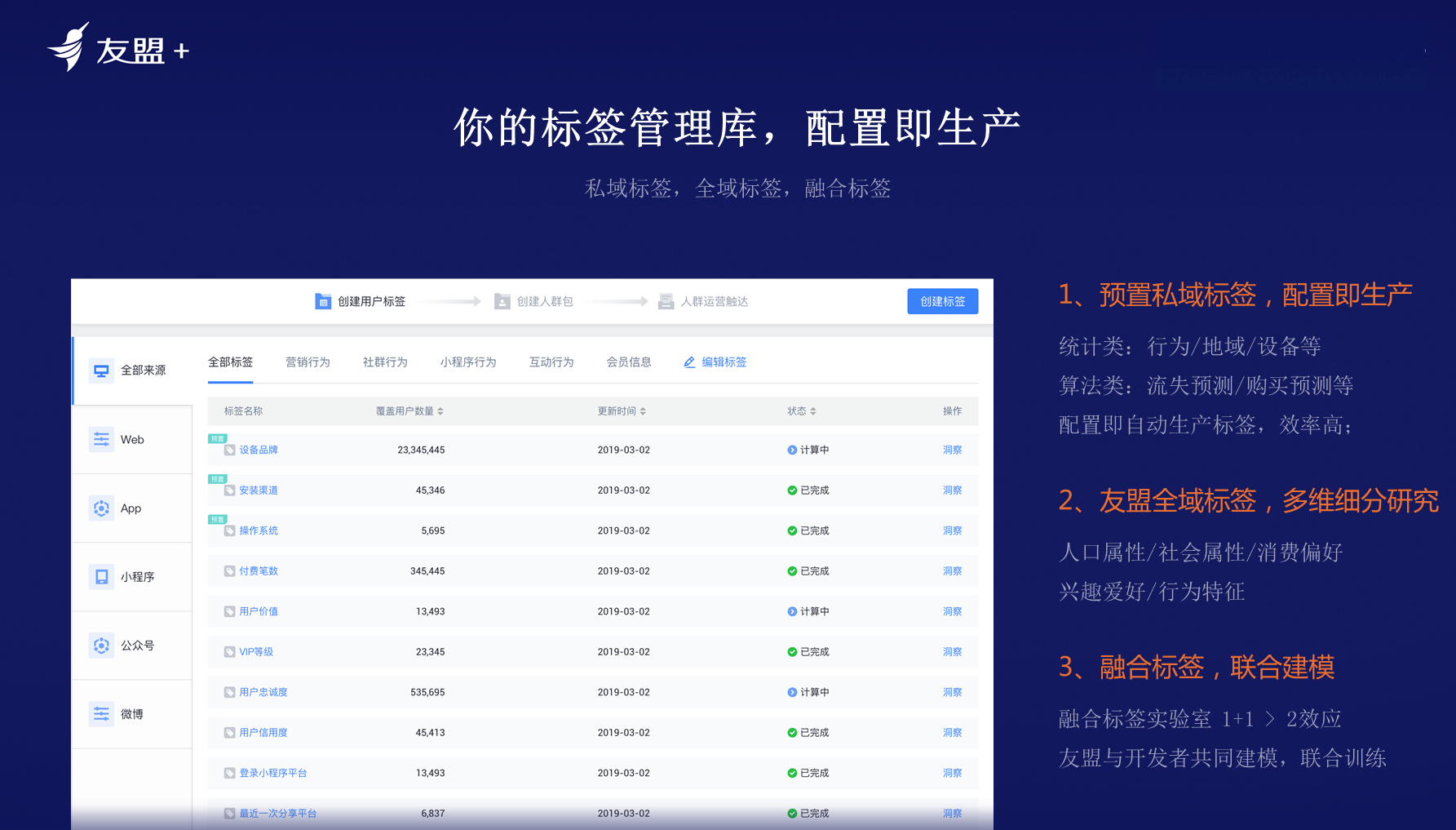
**用户的标签管理库,配置即生产**:业务团队总是对技术团队不满意,当运营团队要做一个活动,需要按照业务场景准备物料,准备活动的页面,还要再按照规则圈到一群想要触达的内存,然后对其进行运营。上述需求需要先和产品经理提需求,产品经理再去和算法、技术团队沟通然后写PRD,再等待几天将活动开发上线。往往流程特别长,完全无法满足运营团队快速迭代、快速试错、快速运营客户的诉求。而运营团队的需求并没有那么复杂,如运营团队只是想给最近30天访问过APP、看过小程序,同时这两天被广告命中的那部分人一个红包,但是很多企业面临技术排期。
运营团队感到不满,技术团队也缺少成就感,因为每天的工作基本是跑SQL等繁琐零碎的事情。企业需要思考的问题是如何高效解决上述生产场景。**友盟+希望数据银行提供预置私域标签的生产,不需要技团队做过多事,只需要将埋点做好。所有产品要去支持运营,能够在平台上面快速配置,快速生产,赋能业务团队,预置私域标签,配置即生产。此外,友盟+数据银行会提供一个不同的能力,既全域标签。私域标签只对客户进行圈选和洞察,友盟+会额外加持全域标签,告知不同用户的兴趣方向,从更多的维度去洞察和圈选用户。友盟+未来计划与其它企业联合建立一个标签实验室,贡献双方不同的数据,通过融合计算得出更好的标签效果以服务不同企业。**
**预置分析模型,自定义报告结构**:运营团队只需要预置分析模型,做交、并、差的各种组合,做各种洞察,洞察完成后保存自己的人群包,即可快速复用到每一个业务的运营和活动之中。自定义私域人群细分体系埋点完成后,在友盟云上采用MaxCompute数据仓库的方案,自动汇聚成一个人在多个端每一天的行为,自动形成用户的档案序列,自动配置完成。只要埋点是正确的,运营团队马上可以完成私域人群细分。友盟+希望把上述的轻量方案应用到解决实际生产中的各种各样支撑的问题。

**多种组合模式,找到想找的人**:如某装修建材公司,有一个Web网站,起初是通过Web网站以及QQ与客户联络。后面该公司又发展了APP和小程序的团队。客户可能同时出现在三处,问题时数据不互通,并且组织是分开运营的。其实本质问题是能否在APP端快速发现小程序的客户,再去客户端做投放,运营和回流。友盟+结合多种模式,无需等排期,帮助运营能找到合适的人。
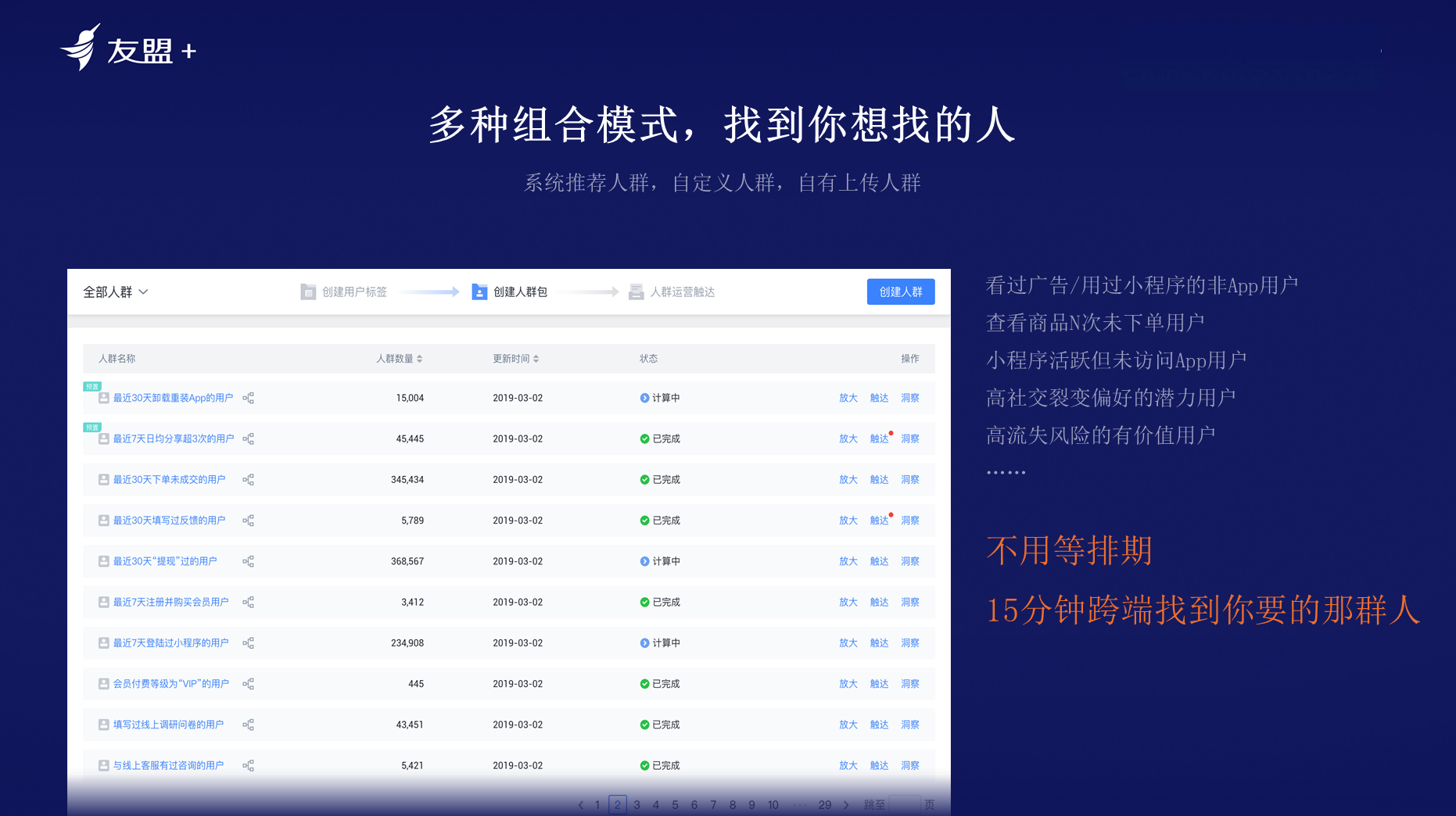
**多种通道触达、互动效果追踪**:U-CDP支持多种通道,无论是短信、EDM、还是APP的消息等都可以对接,所有的运营效果都可以实时可见。友盟+CDP本质上是和技术团队一起赋能业务团队,解决业务团队的效率问题,并增强业务团队运营能力,并沉淀下来用户数据资产。
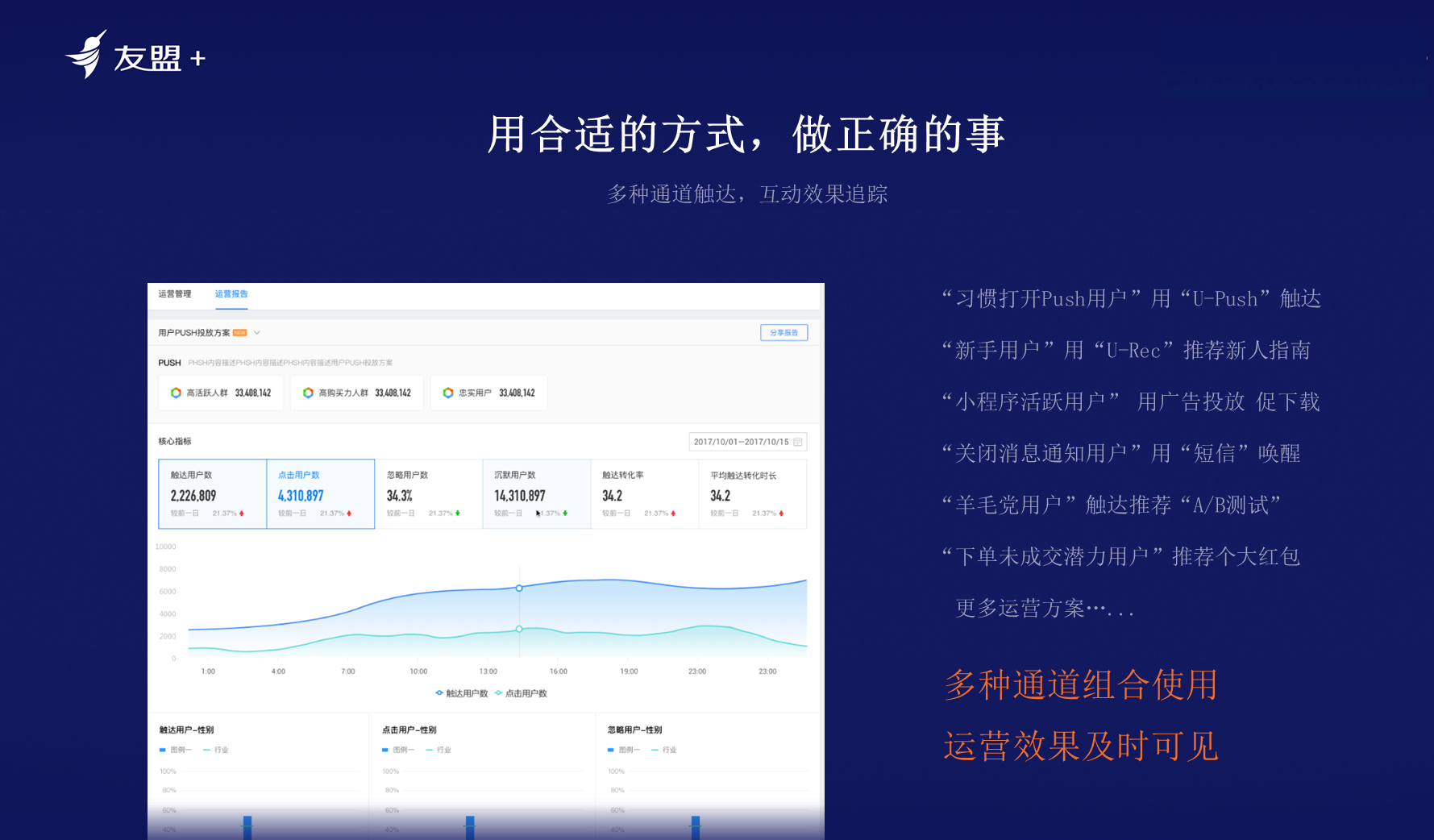
**3.数据开放平台(U-DOP)**
友盟+采集数据后将采集的数据与客户的数据进行融合,通过与MaxCompute进行云端的无缝对接,支持更大力度的开放返还。
**一键数据包订阅返还**:如下图所示,友盟云采集帮助客户快速采集移动客户端、服务端、客户端不同的平台等数据。如果客户自行加工单一的上述事情,处理时间会非常就且最终质量难以保证。基于UMID打通能力,多账号归一,多端归一,支持不同的终端数据打通,友盟+帮助客户做好加工,生成不同的数据包,只要客户使用SDK,数据包自动生成,自动将数据传送到MaxCompute中。然后可以借助DataWorks、DataV、QuickBI与客户的数据做数据融合,极大地降低成本。客户使用的不再是原始数据,而是经过友盟+加工处理过的数据。之后,用户就可以专注于业务产品的开发,业务场景的赋能,把精力放到业务创新而非原始的加工工作上。
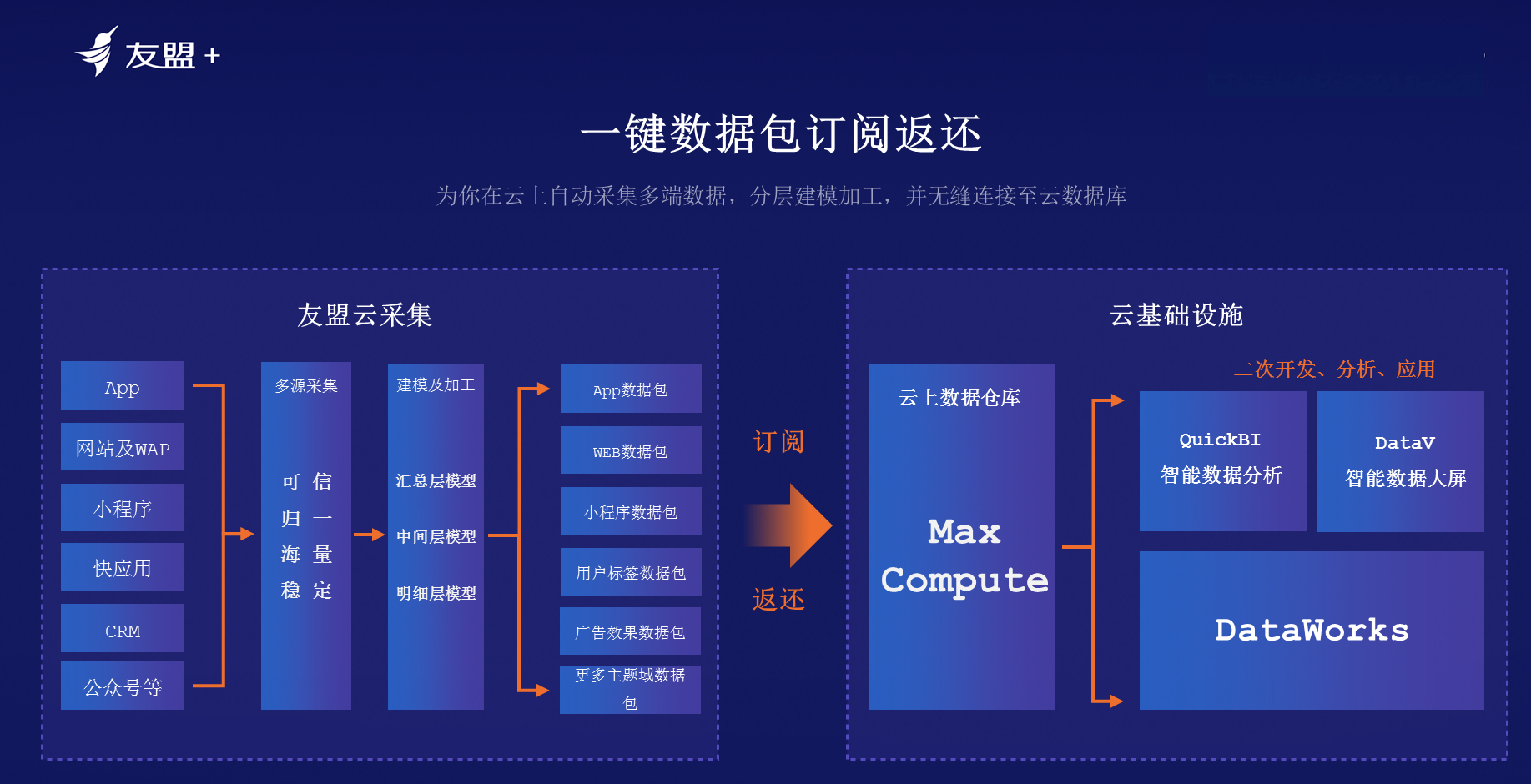
友盟+和MaxCompute云上数据仓库无缝对接,不仅可以提升处理性能,还可以增强使用的简易和便利性。友盟+会为用户预置好所有模型包、模型表,并且打通数据,数据即开即用。

**QuickBI智能数据分析展现**:下图是一位客户做的友盟+和QuickBI智能数据分析展现。数据融合、返还后,结合MaxCompute+QuickBI,做业务人员自助分析,**拖降式自助分析**和在线表格的分析,与原来其它的割裂数据放到一起做大量工作,由此分析师团队的效率获得了极大的提升。

**总结**:无论企业有多么强大的容器、数据库和算法,或者要做多么智能的场景应用,一定要先回到四个关键词:第一是业务数据化,管理好采集和数据质量。第二是数据资产化,让管理层清楚的看到用户资产的具体情况,涉及多少个端,多少个触点,每天产生的数据,沉淀下多少用户。第三是资产应用化,沉淀下来的数据能够快速变成哪些应用去服务业务团队,使业务团队认为技术、数据是在促进帮助业务团队做创新,而不是业务团队等待资源去赋能。其中最根本的一套理念是必须让所有的触点和业务行为的环节能够产生场景和数据的闭环,让场景和闭环能够沉淀数据资产,只有这样才能使一个企业的数据中台可持续,数据赋能可持续,数据能源才会越用越厚,越用越好。
[原文链接](https://link.zhihu.com/?target=https%3A//yq.aliyun.com/articles/730349%3Futm_content%3Dg_1000090543)
本文为阿里云内容,未经允许不得转载。
分享到:





相关推荐
最后,数据安全治理是保障数据不被非法访问、泄露或滥用的重要环节,企业需要建立健全的安全政策,实施技术防护措施,并进行持续的风险评估和审计。 通过亿信华辰提供的数据治理方案,政企可以实现从依赖人工管理...
数据中台是一套可持续“让企业的数据用起来”的机制,一种战略选择和组织形式,是依据企业特有的业务模式和组织架构,通过有形的产品和实施方法论支撑,构建一套持续不断把数据变成资产并服务于业务的机制。...
数据中台赋能企业数字化转型的四个成功因素 在数字化转型的过程中,数据中台扮演着至关重要的角色。要想成功地实现数字化转型,企业需要具备四个成功因素,即业务场景、数据质量、技术平台和组织运营。下面将对这四...
人工智能赋能可持续发展和投资白皮书 人工智能赋能可持续发展和投资白皮书是联合国可...白皮书是人工智能赋能可持续发展和投资的重要参考文献,对政策制定者、企业、投资者、学者和研究机构等都具有重要的参考价值。
报告中提及了计算机行业的网络基础、平台体系和安全保障三个层面,强调了企业内外网络改造升级、国家级平台建设和工业互联网安全工作的重要性。在推荐的企业中,东方国信、用友网络、宝信软件、汉得信息等工业互联网...
安全:赋能数据开放、激活数据价值
### 大模型和数据要素赋能企业数字化转型解决方案 #### 引言 随着信息技术的飞速发展,企业面临着前所未有的挑战和机遇。为了适应快速变化的市场环境,许多企业正在积极探索数字化转型之路。在这个过程中,大模型...
### 数据要素赋能新质生产力:场景创新发展报告(2024) #### 报告核心价值 本报告聚焦于数据要素如何作为新质生产力的核心驱动力,通过一系列高价值的场景创新发展案例来展示其在不同领域的应用及效果。报告强调...
后ERP时代的数据赋能
主题演讲:数据赋能与政府组织转型.pdf
【标题】:“6-1聚焦业务痛点:数据如何赋能公司发展+.pdf” 【描述】:“6-1聚焦业务痛点:数据...数据赋能不仅体现在辅助决策和提升效率上,更在于通过深度分析和数据产品化,形成一个持续的、积极的数据影响力循环。
随着社会对企业可持续发展的重视,ESG估值已经逐渐成为企业评估和投资者决策的重要参考因素。 一、ESG估值的背景和重要性 ESG估值的重要性源自于两个方面:一是ESG理念与当前全球的可持续发展战略高度契合,二是ESG...
《企业级数据中台产品和解决方案》 在当前数字化转型的大潮中,企业级数据中台已成为推动企业发展的关键因素。数据中台的出现标志着企业从传统的流程优先模式向数据优先模式转变,它不仅是信息化的升级,更是数字化...
微信小程序用户画像及行为研究:流量聚合升级,赋能生态闭环.pdf
互联网金融行业:数字货币或将发行,有望持续赋能现行金融体系.pdf
2022年中国工业互联网在供应链中的应用概览:持续赋能.pdf 2022年中国工业互联网在供应链中的应用概览:持续赋能.pdf 2022年中国工业互联网在供应链中的应用概览:持续赋能.pdf 2022年中国工业互联网在供应链中的...
数据中台赋能传统企业数字化转型 数据中台是指企业将数据作为核心资产,通过数据智能来驱动业务发展的思路和架构。它是企业数字化转型的关键一步,旨在帮助传统企业实现数字化转型,提高生产效率,促进产业创新和...
ESG估值白皮书 赋能全面绿色转型,推动可持续发展战略实施.pdf