
д»Җд№ҲжҳҜйҷҗйў‘е’ҢжңҚеҠЎйҷҚзә§ ?
В
иҰҒдҝқиҜҒдёҖдёӘеӨ§жөҒйҮҸеҜ№еӨ–жңҚеҠЎзҡ„зЁіе®ҡжҖ§, йҖҡеёёжҲ‘们еҫҲзӣёеҪ“жіЁж„ҸдёӨдёӘеҠҹиғҪжҺ§еҲ¶вҖҰ В дёҖдёӘжҳҜиҜ·жұӮзҡ„йҷҗжөҒпјҢдёҖдёӘжҳҜжңҚеҠЎйҷҚзә§еӨ„зҗҶпјҢд»–зҡ„ж„Ҹд№үеңЁдәҺдёҚдјҡи®©дҪ зҡ„жңҚеҠЎе…Ёзҳ«з—ӘдәҶпјҢдҪ еҸҜд»ҘйҖӮеҪ“зҡ„жҚҹеӨұзӮ№дёңиҘҝеҲ©зӣҠпјҢжқҘдҝқиҜҒжңҖеҹәзЎҖзҡ„еҠҹиғҪ, иҝҷе°ұжҳҜиҝҮиҪҪдҝқжҠӨ.
В
жҜҸдёӘжҺҘеҸЈжүҖиғҪжҸҗдҫӣзҡ„еҚ•дҪҚж—¶й—ҙжңҚеҠЎиғҪеҠӣжҳҜжңүйҷҗзҡ„гҖӮи¶…иҝҮжңҚеҠЎжңҚеҠЎзҡ„жүҝиҪҪиғҪеҠӣпјҢдёҖиҲ¬дјҡйҖ жҲҗж•ҙдёӘжҺҘеҸЈжңҚеҠЎеҒңйЎҝпјҢжҲ–иҖ…еә”з”Ё CrashжҜҒжҺүпјҢжҲ–иҖ…еёҰжқҘдёҖзі»еҲ—жңӘзҹҘе·ІзҹҘзҡ„иҝһй”ҒеҸҚеә”пјҢиҝҷж ·йҖ жҲҗж•ҙдёӘзі»з»ҹзҡ„жңҚеҠЎиғҪеҠӣдё§еӨұпјҢSO жңүеҝ…иҰҒеңЁжңҚеҠЎиғҪеҠӣи¶…йҷҗзҡ„жғ…еҶөдёӢе®һж—¶иҝҮиҪҪдҝқжҠӨгҖӮ еҫ®дҝЎжҠўзәўеҢ…е’Ңе°ҸзұіжҠўиҙӯдёӯпјҢжҲ‘们дјҡйҒҮеҲ°жңүдәәOKпјҢжңүдәәиў«еҸӢеҘҪзҡ„denyдәҶпјҢиҝҷжҳҜеӣ дёәжңҚеҠЎиҝҮиҪҪдҝқжҠӨдәҶ .
дёәд»Җд№ҲиҰҒеҒҡйҷҗжөҒйҷҗйў‘е’ҢйҷҚзә§?
йҰ–е…ҲеҒҮи®ҫеҮ дёӘжңүж„ҸжҖқзҡ„еңәжҷҜпјҢд»Һз”ЁжҲ·и®ҝй—®зҡ„и§’еәҰжқҘзңӢпјҢеҰӮжһңи®ҫжғіжңүдәәжғіжҡҙеҠӣзў°ж’һзҪ‘з«ҷзҡ„з”ЁжҲ·еҜҶз ҒпјӣжҲ–иҖ…黑客们е°қиҜ•еҗ„з§Қзҡ„sqlжіЁе…ҘпјӣжҲ–иҖ…жңүдәәccж”»еҮ»жҹҗдёӘеҫҲиҖ—иҙ№иө„жәҗзҡ„жҺҘеҸЈпјӣжҲ–иҖ…жңүдәәжғід»ҺжҹҗдёӘжҺҘеҸЈеӨ§йҮҸжҠ“еҸ–ж•°жҚ®жҺҘеҸЈзӯүзӯүгҖӮ В иҝҷж—¶еҖҷж ҮеҮҶзҡ„ж–№жі•жҳҜеҠ еә”з”Ёзә§зҡ„йҳІзҒ«еўҷпјҢд№ҹе°ұжҳҜе’ұ们иҜҙзҡ„waf, wafжҳҜиҮӘеёҰеңЁзәҝиЎҢдёәеҲҶжһҗзҡ„.
йҷӨжӯӨд№ӢеӨ–пјҢжҲ‘们еҸҜд»ҘжғіиұЎдҝғй”ҖжҠўиҙӯзҡ„йңҖжұӮпјҢеҪ“жҲ‘们已зҹҘжңҚеҠЎзҡ„еҸӘиғҪеә”зӯ”зәҰ500qps, дҪҶйҖҡиҝҮдҝғй”Җжҙ»еҠЁзҡ„еҠӣеәҰжҺЁжөӢеҸҜиғҪиҰҒи¶…иҝҮиҝҷдёӘж•°пјҢиҜ·жұӮж јеӨ–зҡ„еӨҡвҖҰ.В
иҝҷж—¶еҖҷе°ұиҰҒеҒҡиҝҮиҪҪдҝқжҠӨдәҶпјҢеўһеҠ Rate limitingиҜ·жұӮйҷҗйҖҹжҳҜдёӘзӣёеҪ“зӣҙжҺҘеҸҲжҳ“з”Ёзҡ„еҘҪеҠһжі•гҖӮ иҜ·жұӮеўһеҠ йҷҗйў‘еҗҺпјҢжҲ‘们еҗҺйқўжңүж—¶й—ҙиҝӣдёҖжӯҘи§ЈеҶіиҝҷдёӘй—®йўҳпјҢжҜ”еҰӮе°Ғе өжқҘжәҗжҲ–иҖ…зү№еҫҒвҖҰ В д№ҹе°ұжҳҜиҜҙ йҷҗйҖҹ жҳҜжңҖж №жң¬зҡ„иҰҒжұӮ. В йӮЈд№ҲеҜ№дәҺжҠўиҙӯзҡ„жӯЈеёёзҡ„иҜ·жұӮйҒҮеҲ°йҷҗйҖҹеҗҺпјҢйӮЈд№ҲжІЎеҠһжі•пјҢеҸӘиғҪжҳҜзІ—жҡҙзҡ„иёўдәәдәҶ, иҷҪ然жҚҹеӨұдәҶдёҖйғЁеҲҶи¶…йҷҗзҡ„жӯЈеёёиҜ·жұӮпјҢдҪҶжңҖе°‘иҝҳиғҪжҺҘе®ўвҖҰ дёҚиҮідәҺиҜ·жұӮйғҪжқҘдәҶпјҢеҗҺз«ҜжңҚеҠЎеӣ дёәеӨ„зҗҶдёҚиҝҮжқҘпјҢзӣҙжҺҘhangдҪҸдәҶ,жІЎеҫ—зҺ©дәҶвҖҰ
еҸҜд»ҘжғіиұЎжҲҗ жқ‘йҮҢзҡ„еңҹйі–з”өй—ёе®үиЈ…дәҶдҝқйҷ©дёқпјҢдёҖж—ҰжңүдәәдҪҝз”Ёи¶…еӨ§еҠҹзҺҮзҡ„и®ҫеӨҮпјҢдҝқйҷ©дёқе°ұдјҡзғ§ж–ӯд»ҘдҝқжҠӨеҗ„дёӘз”өеҷЁдёҚиў«ејәз”өжөҒз»ҷзғ§еқҸ. еҗҢзҗҶжҲ‘们зҡ„жҺҘеҸЈд№ҹйңҖиҰҒе®үиЈ…дёҠвҖңдҝқйҷ©дёқвҖқпјҢд»ҘйҳІжӯўйқһйў„жңҹзҡ„иҜ·жұӮеҜ№зі»з»ҹеҺӢеҠӣиҝҮеӨ§иҖҢеј•иө·зҡ„зі»з»ҹзҳ«з—ӘпјҢеҪ“жөҒйҮҸиҝҮеӨ§ж—¶пјҢеҸҜд»ҘйҮҮеҸ–жӢ’з»қжҲ–иҖ…еј•жөҒзӯүжңәеҲ¶гҖӮВ
еҶҚеӣһжәҜдёӢеҲҡжүҚзҡ„з”өе•Ҷдҝғй”ҖеңәжҷҜпјҢиҝҷеҜ№дәҺ вҖңжңҚеҠЎйҷҚзә§вҖқ зҡ„ж„Ҹд№үеҸҲжҳҜд»Җд№Ҳ? дёәе•ҘеҸҲиҰҒз”ЁжңҚеҠЎйҷҚзә§ ?
еҪ“жңҚеҠЎеҷЁеҺӢеҠӣеү§еўһзҡ„жғ…еҶөдёӢпјҢж №жҚ®еҪ“еүҚдёҡеҠЎжғ…еҶөеҸҠжөҒйҮҸеҜ№дёҖдәӣжңҚеҠЎе’ҢйЎөйқўжңүзӯ–з•Ҙзҡ„йҷҚзә§пјҢд»ҘжӯӨйҮҠж”ҫжңҚеҠЎеҷЁиө„жәҗд»ҘдҝқиҜҒж ёеҝғд»»еҠЎзҡ„жӯЈеёёиҝҗиЎҢгҖӮ
еҒҮе®ҡеҸҜд»ҘеҲҶдёәдёҖзә§жңҚеҠЎпјҢдәҢзә§жңҚеҠЎпјҢдёүзә§жңҚеҠЎпјҢжҜ”еҰӮеңЁзҙ§жҖҘжғ…еҶөдёӢпјҢеҠЎеҝ…дҝқиҜҒдёҖзә§жңҚеҠЎзҡ„зЁіе®ҡжҖ§пјҢ然еҗҺеҸҜд»ҘзүәзүІдәҢзә§е’Ңдёүзә§жңҚеҠЎпјҢиҝҷдёӘе°ұжҳҜжңҚеҠЎйҷҚзә§.В
еҰӮжһңиҝҳжҳҜдёҚжҮӮпјҢйӮЈд№ҲеҶҚдёҫдёҖдәӣдҫӢеӯҗ. В еҲҶзә§дҝқжҠӨдёӢВ з”өе•ҶйҮҢйқўеҹәжң¬жҹҘиҜўе’Ңж”Ҝд»ҳеҸҜд»Ҙз”ЁпјҢиҮідәҺиҜ„и®әгҖҒ买家з§ҖгҖҒиҒҠеӨ©гҖҒ收и—ҸгҖҒиҜ„еҲҶзӯүзӯүеҸҜд»Ҙе…Ҳж”ҫж”ҫпјҢжңҖе°‘дҝқиҜҒд№°дёңиҘҝеҲ°д»ҳж¬ҫиҝҷеҮ жӯҘзҡ„apiиғҪжӯЈеёё. В В еҸҲжҜ”еҰӮqqеҪ“еёҰе®ҪдёҚеӨҹж—¶ е…Ҳз Қи§Ҷйў‘йҖҡиҜқпјҢжҺҘзқҖз ҚиҜӯйҹігҖҒдј ж–Ү件гҖҒзҫӨиҒҠеӨ©гҖҒзҫӨеӣҫзүҮгҖҒеҗ„дҝЎжҒҜжҺЁйҖҒ. В жңҖеҗҺжңҖеҗҺиҮіе°‘иғҪдҝқз•ҷз”ЁжҲ·зҡ„еңЁзәҝзҠ¶жҖҒ. В д»ҘжӯӨзұ»жҺЁпјҢеҗ„з§ҚдәӢдҫӢвҖҰВ
жңҚеҠЎйҷҚзә§ж–№ејҸпјҡ
еҲҶзә§иҢғеӣҙжӢ’з»қ: В д№ҹе°ұжҳҜжҲ‘们дёҠйқўиҜҙеҲ°зҡ„и·Ҝж•°пјҢж №жҚ®uriжқҘеҢәеҲҶжҺҘеӨ„зҗҶеҸЈ, еҜ№дәҺеӨ§йҮҸзҡ„жҺҘеҸЈйҖӮеҗҲиө°nginx lua redis, еҪ“然дҪ еңЁеҗҺз«ҜеҒҡд№ҹеҸҜд»Ҙ.В
еўһеҲ ж”№жҹҘжҺҘеҸЈжӢ’з»қпјҡжӢ’з»қжүҖжңүеўһеҲ ж”№еҠЁдҪңпјҢеҸӘе…Ғи®ёжҹҘиҜў, й”ҷиҜҜйЎөйқўеҶ…е®№еҸҜеңЁCDNеҶ…иҺ·еҸ–гҖӮ еҰӮжһңжҳҜжҹҘиҜўпјҢйӮЈд№ҲзӣҙжҺҘиө°cache.В
延иҝҹжҢҒд№…еҢ–пјҡйЎөйқўи®ҝй—®з…§еёёпјҢдҪҶжҳҜж¶үеҸҠи®°еҪ•еҸҳжӣҙпјҢдјҡжҸҗзӨәзЁҚжҷҡиғҪзңӢеҲ°з»“жһңпјҢе°Ҷж•°жҚ®и®°еҪ•еҲ°ејӮжӯҘйҳҹеҲ—жҲ–еҸҜеӣһжәҜlogпјҢжңҚеҠЎжҒўеӨҚеҗҺжү§иЎҢгҖӮ
xxx: иҝҳжңүеҮ з§ҚвҖҰ.В
В
иҜҙе®ҢжңҚеҠЎйҷҚзә§еҗҺпјҢеҶҚиҒҠдёӢжңҚеҠЎиҜ·жұӮзҡ„йҷҗйў‘й—®йўҳ. В В
еңЁе“ӘйҮҢе®һзҺ°жҺҘеҸЈзҡ„йҷҗйҖҹйҷҗйў‘ ? В йҷҗйҖҹйҷҗйў‘зҡ„з®—жі•жңүеӨҡе°‘?В
жҺҘе…ҘеұӮзҡ„йҷҗжөҒ:
- еҹәдәҺnginxзҡ„limit_connжЁЎеқ—, з”ЁжқҘйҷҗеҲ¶зһ¬ж—¶е№¶еҸ‘иҝһжҺҘж•°.
- еҹәдәҺnginxзҡ„limit_reqжЁЎеқ—, йҷҗеҲ¶жҜҸз§’зҡ„е№іеқҮйҖҹзҺҮ.
- еҹәдәҺnginx lua redisе®ҡеҲ¶жЁЎеқ—, еҸҜе®һзҺ°еӨҡж—¶й—ҙеҢәй—ҙйҷҗйҖҹпјҢе…·дҪ“uriйҷҗйҖҹгҖҒз”ЁжҲ·еұӮйҷҗйҖҹзӯү, еҪ“然еҸҜеҲҶеёғејҸйҷҗйҖҹ.
еҗҺз«ҜжңҚеҠЎеұӮйҷҗйҖҹ:
- еҹәдәҺз”ЁжҲ·зә§еҲ«зҡ„йҷҗйҖҹ.
- еҹәдәҺapiзҡ„йҷҗйҖҹ.
- еҹәдәҺз”ЁжҲ·еҠ apiзҡ„йҷҗйҖҹ.
- еҹәдәҺжөҒйҮҸйҷҗйҖҹ
- зӯүзӯүвҖҰ
еҗҺз«Ҝе®һзҺ°зҡ„йҷҗйҖҹжҳҺжҳҫжӣҙеҠ з»ҶиҮҙзҒөжҙ»пјҢеүҚз«Ҝеӣ дёәжҳҜnginxжүҖд»ҘжҖ§иғҪиӮҜе®ҡжҳҜжңҖеҘҪзҡ„. зҗҶи®әдёҠжқҘиҜҙеҗҺз«ҜиғҪе®һзҺ°зҡ„еӨҚжқӮйҷҗйҖҹдҪ“зі»пјҢжҲ‘们еҸҜд»ҘеӨҚз”ЁеңЁеүҚз«ҜжҺҘе…ҘеұӮ. В nginx luaеҸҜд»Ҙи¶іеӨҹжҲ‘们жһ„е»әеӨҚжқӮзҡ„жҺҘеҸЈйҷҗйў‘дҪ“зі»дәҶ. В В еҰӮжһңе’ұ们жҳҜйӣҶзҫӨзҡ„еңәжҷҜпјҢйҮҸзә§еҸҲдёҚжҳҜеҗ“дәәзҡ„. В з”ЁеҗҺз«Ҝзҡ„йҷҗйҖҹе®Ңе…ЁеҸҜд»Ҙж”Ҝж’‘дёҖдёӘйҮҸзә§пјҢеӨҡдәҶдёҚж•ўиҜҙпјҢжҲ‘们й•ҝжңҹеҺӢжөӢеҚҒеҮ дёҮзҡ„йҷҗйў‘йҖҹеәҰжҳҜжІЎжңүй—®йўҳ, жіЁж„Ҹ еҺӢжөӢжәҗе’ҢжңҚеҠЎеӨ„зҗҶйғҪжҳҜйӣҶзҫӨ !!!В
жҲ‘们зҹҘйҒ“еҲҶеёғејҸйҷҗйҖҹ讲究зҡ„жҳҜеҝ«пјҢйӮЈд№Ҳredisе°ұи¶іеӨҹеҝ«зҡ„дәҶпјҢдёҖдёӘе®һдҫӢе®Ңе…ЁеҸҜд»ҘеҲ°7wзЁіе®ҡзҡ„ops. йӮЈд№ҲдёҖиҮҙжҖ§hash + redisеӨҡе®һдҫӢ .В
еҪ“然е…ұдә«зҡ„и®Ўж•°зҡ„nosqlжҳҜеҝ«дәҶпјҢеҗҺз«Ҝзҡ„жҖ§иғҪеҸҲжҖҺд№ҲдҝқиҜҒ? В дҪ зҡ„еҗҺз«ҜеҰӮжһңжҳҜйӮЈз§ҚbioжЁЎејҸпјҢжҜ”еҰӮphp-fpmгҖҒuwsgiгҖҒж—©жңҹapache prefork. В йӮЈе°ұжІЎеҫ—жүҜдәҶ. В
дёәе•ҘbioдёҚиЎҢ? В дҪ еңЁgoogleеҺ» !!! В еҪ“ж—¶еҗҺз«ҜжҳҜgolang beegoвҖҰ В еҗҺжқҘеӣ еҗ„з§Қжғ…еҶөеҸҳжӣҙжҲҗжёЈжёЈpythonпјҢwebжЎҶжһ¶жҳҜиҮӘе·ұз”Ёlibevж’ёзҡ„иҪ®еӯҗ, ж”ҜжҢҒеӨҡиҝӣзЁӢйӮЈз§Қ, жңҚеҠЎеҷЁеҠ еҲ°5еҸ°е·ҰеҸі, д№ҹжҳҜеҸҜд»ҘеҺӢеҲ°еҚҒеҮ дёҮзҡ„йҷҗйў‘йҖҹеәҰ.В
жҺҘе…ҘеұӮзҡ„йҷҗйҖҹзӣёеҜ№жқҘиҜҙзІ—жҡҙе‘Җ. В еғҸlimit_connгҖҒlimit_reqжҳҜеҸҜд»Ҙз”Ёipең°еқҖжҲ–request pathйҷҗйў‘зҡ„. дҪҶеҰӮжһңдҪ жғіиҰҒйӮЈз§Қз”ЁжҲ·еұӮзҡ„йҷҗйҖҹпјҢеҸҜд»ҘйҖҡиҝҮcookieжқҘжҺ§еҲ¶пјҢзҺ°еӯҳзҡ„limit_xxxжЁЎеқ—жңүзӮ№зІ—пјҢдёҚиғҪжӢҶеҲҶcookieпјҢ иҝҷж—¶еҖҷеҸӘиғҪдёҠnginx luaдәҶ.В
жҲ‘и§ҒиҝҮжңҖеӨҚжқӮзҡ„йҷҗйў‘жҳҜй’ҲеҜ№з”ЁжҲ·гҖҒuriгҖҒз”ЁжҲ·+uriгҖҒеӨҡж—¶й—ҙеҢәй—ҙеҲҶеҲ«жқҘйҷҗйҖҹзҡ„вҖҰ зү№иӣӢз–јвҖҰ. дёәдәҶи§ЈеҶідёҖж¬Ўж¬Ўзҡ„redis ioж—¶й—ҙж¶ҲиҖ—пјҢжҲ‘们дёҠдәҶredisеҶ…зҪ®lua. дҪҶжҳҜredis luaеҸҲдёҚж”ҜжҢҒи·ЁеӨҡе®һдҫӢеҸҠжңәеҷЁ. redis clusterд№ҹж— жі•дҪҝз”Ёlua. йӮЈд№ҲеҸӘиғҪжҸҗеүҚе®ҡд№ү规еҲҷпјҢе°ҪйҮҸhashеҲ°дёҖдёӘredis.В
В
жңҚеҠЎйҷҗйў‘йҷҗжөҒжңүиҝҷд№ҲеҮ з§Қж–№жі•пјҡ
- 第дёҖжҳҜ д»ӨзүҢжЎ¶йҷҗжөҒз®—жі•
- 第дәҢжҳҜ жјҸжЎ¶йҷҗжөҒз®—жі•
- 第дёүдёӘжҳҜ еҺҹеӯҗи®Ўж•°еҷЁзҡ„з®—жі•.В
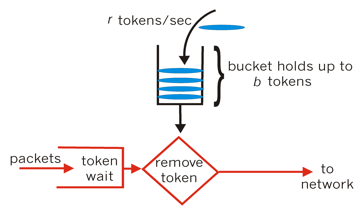
д»ӨзүҢжЎ¶з®—жі•:
1. жҜҸз§’дјҡжңү r дёӘд»ӨзүҢж”ҫе…ҘжЎ¶дёӯпјҢжҲ–иҖ…иҜҙпјҢжҜҸиҝҮ 1/r з§’жЎ¶дёӯеўһеҠ дёҖдёӘд»ӨзүҢВ
2. жЎ¶дёӯжңҖеӨҡеӯҳж”ҫ b дёӘд»ӨзүҢпјҢеҰӮжһңжЎ¶ж»ЎдәҶпјҢж–°ж”ҫе…Ҙзҡ„д»ӨзүҢдјҡиў«дёўејғВ
3. еҪ“дёҖдёӘ n еӯ—иҠӮзҡ„ж•°жҚ®еҢ…еҲ°иҫҫж—¶пјҢж¶ҲиҖ— n дёӘд»ӨзүҢпјҢ然еҗҺеҸ‘йҖҒиҜҘж•°жҚ®еҢ…В
4. еҰӮжһңжЎ¶дёӯеҸҜз”Ёд»ӨзүҢе°ҸдәҺ nпјҢеҲҷиҜҘж•°жҚ®еҢ…е°Ҷиў«зј“еӯҳжҲ–дёўејғ
В
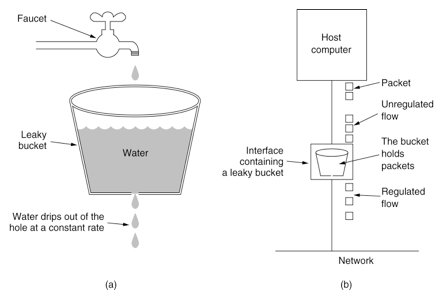
жјҸжЎ¶з®—жі•:
1. ж•°жҚ®иў«еЎ«е……еҲ°жЎ¶дёӯ,并д»Ҙеӣәе®ҡйҖҹзҺҮжіЁе…ҘзҪ‘з»ңдёӯ,иҖҢдёҚз®Ўж•°жҚ®жөҒзҡ„зӘҒеҸ‘жҖ§В
2. еҰӮжһңжЎ¶жҳҜз©әзҡ„,дёҚеҒҡд»»дҪ•дәӢжғ…В
3. дё»жңәеңЁжҜҸдёҖдёӘж—¶й—ҙзүҮеҗ‘зҪ‘з»ңжіЁе…ҘдёҖдёӘж•°жҚ®еҢ…,еӣ жӯӨдә§з”ҹдёҖиҮҙзҡ„ж•°жҚ®жөҒ
В
В
иҝҷдёӨдёӘз®—жі•жҳҜжңүеҢәеҲ«зҡ„: жјҸжЎ¶з®—жі•иғҪеӨҹејәиЎҢйҷҗеҲ¶ж•°жҚ®зҡ„дј иҫ“йҖҹзҺҮ, В иҖҢд»ӨзүҢжЎ¶з®—жі•еңЁиғҪеӨҹйҷҗеҲ¶ж•°жҚ®зҡ„е№іеқҮдј иҫ“йҖҹзҺҮеӨ–,иҝҳе…Ғи®ёжҹҗз§ҚзЁӢеәҰзҡ„зӘҒеҸ‘дј иҫ“.
В
В
и®Ўж•°еҷЁйҷҗйў‘:
з®ҖеҚ•зІ—жҡҙзҡ„зҙҜеҠ и®Ўж•°, и¶…иҝҮе°ұdenyпјҢжІЎи¶…иҝҮе°ұpass. В жҲ‘们еҸҜд»Ҙз”ЁеҪ“еүҚж—¶й—ҙзҡ„жҹҗдёӘеҚ•дҪҚеҸҠж–№жі•еҸӮж•°зҡ„md5еҒҡжҲҗkey. В valueжҳҜIntж•°еҖјпјҢ然еҗҺзҙҜеҠ и®Ўж•°е°ұеҸҜд»ҘдәҶ. В жҲ‘дёӘдәәиҝҳжҳҜжҜ”иҫғе–ңж¬ўи®Ўж•°еҷЁзҡ„йҷҗйў‘пјҢеҸҜд»Ҙи®ҫзҪ®еӨҡдёӘж—¶й—ҙеҢәй—ҙпјҢжҜ”еҰӮдёҖз§’й’ҹеҸҜд»Ҙ10дёӘпјҢдёҖеҲҶй’ҹеҸӘиғҪ200дёӘпјҢдёҖе°Ҹж—¶еҸӘиғҪ8000дёӘвҖҰВ В В и®Ўж•°йҷҗйў‘дёҚеҚ•еҚ•жҳҜйӮЈз§Қзұ»дјјеёёйҮҸе’Ңlengthж–№жі•еҜ№жҜ”йҷҗйў‘пјҢжҜ”еҰӮиҜҙпјҢж•°жҚ®еә“зҡ„иҝһжҺҘж•°пјҢеҚҸзЁӢжұ пјҢз§’жқҖ并еҸ‘. В иҖҢдё”д№ҹжҳҜеҸҜд»Ҙе®һзҺ° д»ӨзүҢжЎ¶еҸҠжјҸжЎ¶зҡ„з®—жі•зҡ„. В
В
е…¶е®һеүҚдёӨз§ҚйҷҗйҖҹйҷҗйў‘з®—жі•жӣҙеӨҡзҡ„з”ЁдәҺжҺҘе…ҘеұӮпјҢжҜ”еҰӮnginxпјҢiptables mark tc, зҪ‘з»ңи®ҫеӨҮqos зӯүзӯү.В . .
В
й’ҲеҜ№nginx limit_conn limit_reqйҷҗйҖҹзҡ„й…ҚзҪ®пјҢиҝҷйҮҢз®ҖеҚ•йҳҗиҝ°дёӢ:
ж·»еҠ limit_conn е’Ңlimit_req иҝҷдёӘеҸҳйҮҸеҸҜд»ҘеңЁhttp, server, locationдҪҝз”ЁпјҲеҰӮжһңдҪ йңҖиҰҒйҷҗеҲ¶йғЁеҲҶжңҚеҠЎпјҢеҸҜеңЁnginx/conf/domainsйҮҢйқўйҖүжӢ©зӣёеә”зҡ„serverжҲ–иҖ…locationж·»еҠ дёҠдҫҝеҸҜ) В дёҖиҲ¬йғҪжҳҜйҖүжӢ©жҖ§зҡ„ж·»еҠ йҷҗйў‘пјҢ жҜ”еҰӮй’ҲеҜ№зҷ»йҷҶгҖҒж”Ҝд»ҳжҺҘеҸЈеҸҜд»ҘеҠ locationеұӮйҷҗйў‘пјҢй’ҲеҜ№жҷ®йҖҡеўһеҲ ж”№жҹҘзҡ„йҖ»иҫ‘еҸҜе…ұз”ЁдёҖеҘ—йҷҗйў‘. В й’ҲеҜ№зҝ»йЎөйҖ’еҪ’зҡ„жҹҘиҜўеә”иҜҘзӢ¬з«ӢдёҖеҘ—йҷҗйў‘. В зұ»дјјзҡ„иҝҳжңүе…Ёж–ҮжҗңзҙўпјҢеөҢеҘ—иҜ„и®әзӯүзӯү.
В
еҸӮж•°иҜҰи§Ј( ж•°еҖјжҢүе…·дҪ“йңҖиҰҒе’ҢжңҚеҠЎеҷЁжүҝиҪҪиғҪеҠӣи®ҫзҪ®):
В



зӣёе…іжҺЁиҚҗ
еҚҺдёәдә‘дҪңдёәе…ЁзҗғйўҶе…Ҳзҡ„дҝЎжҒҜе’ҢйҖҡдҝЎжҠҖжңҜ(ICT)и§ЈеҶіж–№жЎҲжҸҗдҫӣе•ҶпјҢиҝ‘е№ҙжқҘеңЁдә‘и®Ўз®—йўҶеҹҹзҡ„дёҖзі»еҲ—з»„з»Үжһ¶жһ„и°ғж•ҙеј•иө·дәҶдёҡз•Ңзҡ„е№ҝжіӣе…іжіЁгҖӮй’ҲеҜ№еҚҺдёәдә‘зҡ„з»„з»Үжһ¶жһ„и°ғж•ҙе’Ңдә‘дёҡеҠЎзҡ„жҲҳз•Ҙең°дҪҚпјҢд»ҘдёӢжҳҜеҜ№з»ҷе®ҡж–Ү件еҶ…е®№зҡ„зҹҘиҜҶзӮ№жўізҗҶпјҡ 1. ...
жӯӨеӨ–пјҢй’ҲеҜ№зӣҙж’ӯдёӯзҡ„ж¶ҲжҒҜйЈҺжҡҙе’ҢжөҒйҮҸзӘҒеҲәпјҢеҸҜд»ҘйҮҮз”Ёж¶ҲжҒҜеҲҶзә§гҖҒдё»ж’ӯзӣҙж’ӯй—ҙеҲҶзә§гҖҒйҷҗйў‘зӯ–з•ҘпјҢд»ҘеҸҠзӣ‘жҺ§е’ҢиҮӘеҠЁйҷҚзә§жңәеҲ¶пјҢзЎ®дҝқзі»з»ҹзҡ„зЁіе®ҡиҝҗиЎҢгҖӮ еңЁдә’еҠЁзӣҙж’ӯйўҶеҹҹпјҢRTMPеҚҸи®®зҡ„з§’зә§ж—¶е»¶ж— жі•ж»Ўи¶іеӨҡз”ЁжҲ·йў‘з№Ғдә’еҠЁзҡ„йңҖжұӮгҖӮRTC...
жӯӨеӨ–пјҢдҪҝз”Ё QoSпјҲжңҚеҠЎиҙЁйҮҸпјүзӯ–з•ҘжқҘдјҳе…ҲеӨ„зҗҶе…ій”®жөҒйҮҸпјҢд»ҘеҸҠе®ҡжңҹжӣҙж–°еӣә件е’Ңе®үе…Ёи®ҫзҪ®д№ҹжҳҜдјҳеҢ–зҡ„йҮҚиҰҒйғЁеҲҶгҖӮ жҖ»д№ӢпјҢIEEE 802.11g жҠҖжңҜйҖҡиҝҮиһҚеҗҲй«ҳж•°жҚ®йҖҹзҺҮе’Ңеҗ‘дёӢе…је®№жҖ§пјҢеңЁзҹӯзЁӢж— зәҝйҖҡдҝЎйўҶеҹҹдёӯжүҫеҲ°дәҶдёҖдёӘе№іиЎЎзӮ№пјҢдёәз”ЁжҲ·...
е…¶е…је®№жҖ§д№ҹдҪ“зҺ°еңЁиғҪеӨҹиһҚеҗҲ移频гҖҒдәӨжөҒи®Ўж•°гҖҒUM-71д»ҘеҸҠжһҒйў‘зӯүеӨҡз§ҚдҝЎеҸ·еҲ¶ејҸпјҢдҪҝе…¶иғҪеӨҹеңЁеӨҚжқӮеӨҡеҸҳзҡ„й“Ғи·ҜзҺҜеўғдёӯеұ•зҺ°еҮәиүҜеҘҪзҡ„йҖӮеә”иғҪеҠӣе’ҢзЁіе®ҡжҖ§гҖӮ LKJ2000зі»з»ҹз»“жһ„еҲҶдёәиҪҰиҪҪйғЁеҲҶе’Ңең°йқўйғЁеҲҶпјҢеҗ„иҮӘжүҝиҪҪдёҚеҗҢзҡ„д»»еҠЎгҖӮиҪҰиҪҪйғЁеҲҶжҳҜ...
5. **з»қзјҳжЈҖжҹҘ**пјҡеҢ…жӢ¬иҫ“е…Ҙз«ҜдёҺеӨ–еЈігҖҒиҫ“еҮәз«ҜдёҺеӨ–еЈід»ҘеҸҠжҺ§еҲ¶еӣһи·ҜдёҺеӨ–еЈід№Ӣй—ҙзҡ„з»қзјҳз”өйҳ»е’Ңе·Ҙйў‘иҖҗеҺӢжЈҖжҹҘпјҢзЎ®дҝқи®ҫеӨҮеңЁз”өж°”е®үе…Ёж–№йқўз¬ҰеҗҲж ҮеҮҶгҖӮ 6. **жЈҖйӘҢз»“и®ә**пјҡжЈҖйӘҢе‘ҳе°Ҷж №жҚ®жүҖжңүжЈҖйӘҢйЎ№зӣ®зҡ„е®һйҷ…з»“жһңеЎ«еҶҷвҖңеҗҲж јвҖқжҲ–вҖңдёҚ...