
1.ТдѓУ┐░
сђђсђђуЏ«тЅЇ№╝їKafka т«ўуйЉТюђТќ░уЅѕ[0.10.1.1]№╝їти▓ж╗ўУ«цт░єТХѕУ┤╣уџё offset У┐ЂтЁЦтѕ░С║є Kafka СИђСИфтљЇСИ║┬а__consumer_offsets уџёTopicСИГсђѓтЁХт«ъ№╝їТЌЕтюе 0.8.2.2 уЅѕТюг№╝їти▓Тћ»ТїЂтГўтЁЦТХѕУ┤╣уџё offset тѕ░TopicСИГ№╝їтЈфТў»жѓБТЌХтђЎж╗ўУ«цТў»т░єТХѕУ┤╣уџё offset тГўТћЙтюе Zookeeper жЏєуЙцСИГсђѓжѓБуј░тюе№╝їт«ўТќ╣ж╗ўУ«цт░єТХѕУ┤╣уџёoffsetтГўтѓетюе Kafka уџёTopicСИГ№╝їтљїТЌХ№╝їС╣ЪС┐ЮуЋЎС║єтГўтѓетюе Zookeeper уџёТјЦтЈБ№╝їжђџУ┐Є┬аoffsets.storage т▒ъТђДТЮЦУ┐ЏУАїУ«Йуй«сђѓ
2.тєЁт«╣
сђђсђђтЁХт«ъ№╝їт«ўТќ╣У┐ЎТаиТјеУЇљ№╝їС╣ЪТў»ТюЅтЁХжЂЊуљєуџёсђѓС╣ІтЅЇуЅѕТюг№╝їKafkaтЁХт«ътГўтюеСИђСИфТ»ћУЙЃтцДуџёжџљТѓБ№╝їт░▒Тў»тѕЕуће Zookeeper ТЮЦтГўтѓеУ«░тйЋТ»ЈСИфТХѕУ┤╣УђЁ/у╗ёуџёТХѕУ┤╣У┐Џт║дсђѓУЎйуёХ№╝їтюеСй┐ућеУ┐ЄуеІтйЊСИГ№╝їJVMтИ«тіЕТѕЉС╗гт«їТѕљС║єУЄфСИђС║ЏС╝ўтїќ№╝їСйєТў»ТХѕУ┤╣УђЁжюђУдЂжбЉу╣Ђуџётј╗СИј Zookeeper У┐ЏУАїС║цС║њ№╝їУђїтѕЕућеZKClientуџёAPIТЊЇСйюZookeeperжбЉу╣ЂуџёWriteтЁХТюгУ║Фт░▒Тў»СИђСИфТ»ћУЙЃСйјТЋѕуџёAction№╝їт»╣С║јтљјТюЪТ░┤т╣│ТЅЕт▒ЋС╣ЪТў»СИђСИфТ»ћУЙЃтц┤уќ╝уџёжЌ«жбўсђѓтдѓТъюТюЪжЌ┤ Zookeeper жЏєуЙцтЈЉућЪтЈўтїќ№╝їжѓБ Kafka жЏєуЙцуџётљътљљжЄЈС╣ЪУиЪуЮђтЈЌтй▒тЊЇсђѓ
сђђсђђтюеТГцС╣Ітљј№╝їт«ўТќ╣тЁХт«ътЙѕТЌЕт░▒ТЈљтЄ║С║єУ┐ЂуД╗тѕ░ Kafka уџёТдѓт┐х№╝їтЈфТў»№╝їС╣ІтЅЇТў»СИђуЏ┤ж╗ўУ«цтГўтѓетюе ZookeeperжЏєуЙцСИГ№╝їжюђУдЂТЅІтіеуџёУ«Йуй«№╝їтдѓТъю№╝їт»╣ Kafka уџёСй┐ућеСИЇТў»тЙѕуєЪТѓЅуџёУ»Ю№╝їСИђУѕгТѕЉС╗гт░▒ТјЦтЈЌС║єж╗ўУ«цуџётГўтѓе№╝ѕтЇ│№╝џтГўтюе ZK СИГ№╝ЅсђѓтюеТќ░уЅѕ Kafka С╗ЦтЈіС╣ІтљјуџёуЅѕТюг№╝їKafka ТХѕУ┤╣уџёoffsetжЃйС╝џж╗ўУ«цтГўТћЙтюе Kafka жЏєуЙцСИГуџёСИђСИфтЈФ __consumer_offsets уџёtopicСИГсђѓ
сђђсђђтйЊуёХ№╝їтЁХт«ътЦ╣т«ъуј░уџётјЪуљєС╣ЪУ«ЕТѕЉС╗гтЙѕуєЪТѓЅ№╝їтѕЕуће Kafka УЄфУ║Фуџё Topic№╝їС╗ЦТХѕУ┤╣уџёGroup№╝їTopic№╝їС╗ЦтЈіPartitionтЂџСИ║у╗ётљѕ KeyсђѓТЅђТюЅуџёТХѕУ┤╣offsetжЃйТЈљС║цтєЎтЁЦтѕ░СИіУ┐░уџёTopicСИГсђѓтЏаСИ║У┐ЎжЃетѕєТХѕТЂ»Тў»жЮътИИжЄЇУдЂ№╝їС╗ЦУЄ│С║јТў»СИЇУЃйт«╣т┐ЇСИбТЋ░ТЇ«уџё№╝їТЅђС╗ЦТХѕТЂ»уџё acking у║ДтѕФУ«Йуй«СИ║С║є -1№╝їућЪС║ДУђЁуГЅтѕ░ТЅђТюЅуџё ISR жЃйТћХтѕ░ТХѕТЂ»тљјТЅЇС╝џтЙЌтѕ░ ack№╝ѕТЋ░ТЇ«т«ЅтЁеТђДТъЂтЦй№╝їтйЊуёХ№╝їтЁХжђЪт║дС╝џТюЅТЅђтй▒тЊЇ№╝ЅсђѓТЅђС╗Ц Kafka тЈѕтюетєЁтГўСИГу╗┤ТіцС║єСИђСИфтЁ│С║ј Group№╝їTopic тњї Partition уџёСИЅтЁЃу╗ёТЮЦу╗┤ТіцТюђТќ░уџё offset С┐АТЂ»№╝їТХѕУ┤╣УђЁУјитЈќТюђТќ░уџёoffsetуџёТЌХтђЎС╝џуЏ┤ТјЦС╗јтєЁтГўСИГУјитЈќсђѓ
3.т«ъуј░
сђђсђђжѓБТѕЉС╗гтдѓСйЋт«ъуј░УјитЈќУ┐ЎжЃетѕєТХѕУ┤╣уџё offset№╝їТѕЉС╗гтЈ»С╗ЦтюетєЁтГўСИГт«џС╣ЅСИђСИфMapжЏєтљѕ№╝їТЮЦу╗┤ТіцТХѕУ┤╣СИГТЅђТЇЋТЇЅтѕ░ offset№╝їтдѓСИІТЅђуц║№╝џ
protected static Map<GroupTopicPartition, OffsetAndMetadata> offsetMap = new ConcurrentHashMap<>();
сђђсђђуёХтљј№╝їТѕЉС╗гжђџУ┐ЄСИђСИфуЏЉтљгу║┐уеІТЮЦТЏ┤Тќ░тєЁтГўСИГуџёMap№╝їС╗БуаЂтдѓСИІТЅђуц║№╝џ

private static synchronized void startOffsetListener(ConsumerConnector consumerConnector) { Map<String, Integer> topicCountMap = new HashMap<String, Integer>(); topicCountMap.put(consumerOffsetTopic, new Integer(1)); KafkaStream<byte[], byte[]> offsetMsgStream = consumerConnector.createMessageStreams(topicCountMap).get(consumerOffsetTopic).get(0); ConsumerIterator<byte[], byte[]> it = offsetMsgStream.iterator(); while (true) { MessageAndMetadata<byte[], byte[]> offsetMsg = it.next(); if (ByteBuffer.wrap(offsetMsg.key()).getShort() < 2) { try { GroupTopicPartition commitKey = readMessageKey(ByteBuffer.wrap(offsetMsg.key())); if (offsetMsg.message() == null) { continue; } OffsetAndMetadata commitValue = readMessageValue(ByteBuffer.wrap(offsetMsg.message())); offsetMap.put(commitKey, commitValue); } catch (Exception e) { e.printStackTrace(); } } } }
сђђсђђтюеТІ┐тѕ░У┐ЎжЃетѕєТЏ┤Тќ░тљјуџёoffsetТЋ░ТЇ«№╝їТѕЉС╗гтЈ»С╗ЦжђџУ┐Є RPC т░єУ┐ЎжЃетѕєТЋ░ТЇ«тЁ▒С║ФтЄ║тј╗№╝їУ«Ет«бТѕиуФ»УјитЈќУ┐ЎжЃетѕєТЋ░ТЇ«т╣ХтЈ»УДєтїќсђѓRPC ТјЦтЈБтдѓСИІТЅђуц║№╝џ
namespace java org.smartloli.kafka.eagle.ipc service KafkaOffsetServer{ string query(1:string group,2:string topic,3:i32 partition), string getOffset(), string sql(1:string sql), string getConsumer(), string getActiverConsumer() }
сђђсђђУ┐ЎжЄї№╝їтдѓТъюТѕЉС╗гСИЇТЃ│тєЎТјЦтЈБТЮЦТЊЇСйю offset№╝їтЈ»С╗ЦжђџУ┐Є SQL ТЮЦТЊЇСйюТХѕУ┤╣уџё offset ТЋ░у╗ё№╝їСй┐ућеТќ╣т╝ЈтдѓСИІТЅђуц║№╝џ
- т╝ЋтЁЦСЙЮУхќJAR
<dependency> <groupId>org.smartloli</groupId> <artifactId>jsql-client</artifactId> <version>1.0.0</version> </dependency>
- Сй┐ућеТјЦтЈБ
JSqlUtils.query(tabSchema, tableName, dataSets, sql);
сђђсђђtabSchema№╝џУАеу╗ЊТъё№╝ЏtableName№╝џУАетљЇ№╝ЏdataSets№╝џТЋ░ТЇ«жЏє№╝Џsql№╝џТЊЇСйюуџёSQLУ»ГтЈЦсђѓ
4.жбёУДѕ
сђђсђђТХѕУ┤╣УђЁжбёУДѕтдѓСИІтЏЙТЅђуц║№╝џ
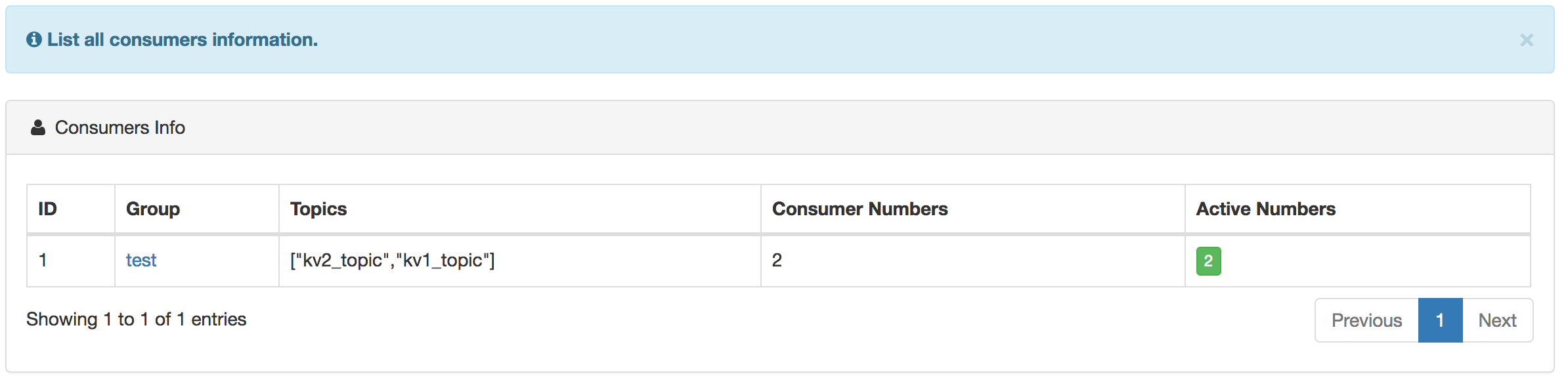
сђђсђђТГБтюеТХѕУ┤╣уџётЁ│у│╗тЏЙтдѓСИІТЅђуц║№╝џ

сђђсђђТХѕУ┤╣У»ду╗є offset тдѓСИІТЅђуц║№╝џ

сђђсђђТХѕУ┤╣тњїућЪС║ДуџёжђЪујЄтЏЙ№╝їтдѓСИІТЅђуц║№╝џ

5.Тђ╗у╗Њ
сђђсђђУ┐ЎжЄї№╝їУ»┤ТўјСИђСИІ№╝їтйЊ offset тГўтЁЦтѕ░ Kafka уџёtopicСИГтљј№╝їТХѕУ┤╣у║┐уеІIDС┐АТЂ»т╣ХТ▓АТюЅУ«░тйЋ№╝їСИЇУ┐Є№╝їТѕЉС╗гжђџУ┐ЄжўЁУ»╗KafkaТХѕУ┤╣у║┐уеІIDуџёу╗ёТѕљУДётѕЎтљј№╝їтЈ»С╗ЦТЅІтіеућЪТѕљ№╝їтЁХТХѕУ┤╣у║┐уеІIDућ▒№╝џGroup+ConsumerLocalAddress+Timespan+UUID(8bit)+PartitionId№╝їућ▒С║јТХѕУ┤╣УђЁтюетЁХС╗ќУіѓуѓ╣№╝їТѕЉС╗гТџѓТЌХТЌаТ│ЋуА«т«џConsumerLocalAddressсђѓТюђтљј№╝їТгбУ┐јтцДт«ХСй┐уће Kafka жЏєуЙцуЏЉТјД РђћРђћ[┬аKafka Eagle┬а]№╝ї[┬аТЊЇСйюТЅІтєї┬а]сђѓ
┬а
УйгУйй№╝џhttp://www.cnblogs.com/smartloli/p/6266453.html



уЏИтЁ│ТјеУЇљ
У┐ЎСИфтиЦтЁиСй┐тЙЌу«АуљєтЉўУЃйтцЪТЏ┤Тќ╣СЙ┐тю░у«Ауљєтњїу╗┤ТіцKafkaжЏєуЙц№╝їуЅ╣тѕФТў»т»╣С║јoffsetтђ╝уџёС┐«Тћ╣№╝їУ┐ЎТў»СИђСИфжЮътИИжЄЇУдЂуџёуЅ╣ТђД№╝їтЏаСИ║offsetТў»KafkaТХѕУ┤╣УђЁУиЪУИфТХѕТЂ»СйЇуй«уџётЁ│жћ«сђѓ ждќтЁѕ№╝їС║єУДБKafkaуџётЪ║ТюгТдѓт┐хсђѓKafkaТў»СИђСИфтѕєтИЃт╝ЈТхЂтцёуљєт╣│тЈ░...
тїЁтљФMac тњї windowsуЅѕТюг, тЈ»С╗ЦУ┐ъТјЦkafka№╝їжЮътИИТќ╣СЙ┐уџёТЪЦуюІtopicсђЂconsumerсђЂconsumer-group уГЅС┐АТЂ»сђѓ 1сђЂждќтЁѕтюеPropertiesжАхуГЙСИІтАФтєЎтЦй zookeeper тю░тЮђтњїуФ»тЈБ 2сђЂтєЇС╗ј AdvancedжАхуГЙСИІтАФтєЎ brokerтю░тЮђтњїуФ»тЈБ
ТюЅСИфтѕФтљїтГдтЈЇждѕСИіСИђТгАС╝ауџёТюЅжЃетѕєУхёТ║љТ▓АТюЅт«їтЁеТюгтю░тїќ№╝їТЅђС╗ЦС╗ітцЕуЅ╣тю░жЄЇТќ░у╝ќУ»ЉС║єСИђуЅѕжЄЇТќ░СИіС╝а№╝їтєЇТГцС╣ЪтњїС╣ІтЅЇСИІУййуџётљїтГдУ»┤тБ░Ті▒ТГЅсђѓтИїТюЏт»╣тцДт«ХТюЅућесђѓ
kafkaт«бТѕиуФ»offset kafkaт«бТѕиуФ»offset kafkaт«бТѕиуФ»offset kafkaт«бТѕиуФ»offset kafkaт«бТѕиуФ»offset kafkaт«бТѕиуФ»offset kafkaт«бТѕиуФ»offset kafkaт«бТѕиуФ»offset kafkaт«бТѕиуФ»offset kafkaт«бТѕиуФ»offset kafkaт«бТѕиуФ»offset ...
сђіKafka Tool Offset Explorer 2.2№╝џТ┤ът»ЪKafkaТЋ░ТЇ«ТхЂуџёуЦътЎесђІ тюетцДТЋ░ТЇ«тцёуљєжбєтЪЪ№╝їApache KafkaСйюСИ║СИђТгЙжФўТЋѕсђЂтЈ»ТЅЕт▒ЋуџёТХѕТЂ»СИГжЌ┤С╗Х№╝їТЅ«Т╝ћуЮђУЄ│тЁ│жЄЇУдЂуџёУДњУЅ▓сђѓУђїKafka Tool Offset Explorer 2.2тѕЎТў»СИђТгЙСИЊСИ║KafkaУ«ЙУ«Ауџё...
Уђї"offset kafkaуЏЉТјДтиЦтЁи"тѕЎТў»жњѕт»╣KafkaжЏєуЙцУ┐ЏУАїу«АуљєтњїуЏЉТјДуџёжЄЇУдЂУЙЁтіЕтиЦтЁи№╝їт«ЃтЁЂУ«ИућеТѕиТЪЦуюІтњїу«АуљєKafkaСИ╗жбўСИГуџёТХѕУ┤╣тЂЈуД╗жЄЈ№╝їУ┐Ўт»╣С║јуљєУДБтњїУ░ЃУ»ЋућЪС║ДУђЁтњїТХѕУ┤╣УђЁуџётљїТГЦуіХТђЂУЄ│тЁ│жЄЇУдЂсђѓ "offset explore"Тў»У┐Ўу▒╗тиЦтЁиуџётЁИтъІ...
kafka-0.9.0-жЄЇуй«offset-ResetOff.java№╝Џ
сђіKafka-Manager 1.3.3.22№╝џУДБтє│Unknown offset schema version 3т╝ѓтИИУ»дУДБсђІ тюетцДТЋ░ТЇ«тцёуљєжбєтЪЪ№╝їApache KafkaСйюСИ║СИђСИфжФўТЋѕсђЂтЈ»ТЅЕт▒Ћуџёт«ъТЌХТЋ░ТЇ«ТхЂт╣│тЈ░№╝їт╣┐Т│Џт║ћућеС║јТХѕТЂ»С╝ажђњтњїТЋ░ТЇ«жЏєТѕљсђѓуёХУђї№╝їтюет«ъжЎЁТЊЇСйюСИГ№╝їућеТѕитЈ»УЃй...
offsetExplore2 т«ъжЎЁСИіТў» Kafka уџёСИђСИфтиЦтЁи№╝їућеС║ју«АуљєтњїуЏЉТјД Apache Kafka СИГуџётЂЈуД╗жЄЈ№╝ѕoffset№╝Ѕсђѓтюе Kafka СИГ№╝їтЂЈуД╗жЄЈТў»ућеТЮЦТаЄУ»єТХѕУ┤╣УђЁтюеСИђСИфуЅ╣т«џтѕєтї║СИГуџёСйЇуй«уџёТаЄУ»єугд№╝їт«ЃтЈ»С╗ЦућеТЮЦУ«░тйЋТХѕУ┤╣УђЁТХѕУ┤╣ТХѕТЂ»уџёУ┐Џт║дсђѓ ...
KafkaOffsetMonitor ТюђТќ░уЅѕТюг 0.4.6 , google js ТЏ┐ТЇбти▓ТЏ┐ТЇб тєЁтцќтЈ»С╗ЦУ«┐жЌ«жАхжЮб
Kafka Tools 3.0№╝їу╗ЈУ┐ЄТћ╣тљЇТЏ┤Тќ░СИ║offsetexplorer№╝їСйюСИ║СИђСИфжњѕт»╣Apache KafkaуџётиЦтЁижЏє№╝їт«ЃуџётЄ║уј░СИ║у«АуљєтњїуЏЉТјДKafkaжЏєуЙцТЈљСЙЏС║єСИђуДЇтЁеТќ░уџёУДєУДњсђѓУЄф3.0уЅѕТюгУхи№╝їУ»ЦтиЦтЁижЏєт╝ђтДІТћ»ТїЂJAAS№╝ѕJava Authentication and ...
### Apache Flink тдѓСйЋу«Ауљє Kafka ТХѕУ┤╣УђЁ Offsets #### СИђсђЂFlinkСИјKafkaу╗Њтљѕт«ъуј░Checkpointing тюеТјбУ«еFlinkтдѓСйЋу«АуљєтњїтѕЕућеKafkaТХѕУ┤╣УђЁOffsetsуџёУ┐ЄуеІСИГ№╝їждќтЁѕУдЂуљєУДБFlinkСИјKafkaтдѓСйЋтЁ▒тљїт«ъуј░ТБђТЪЦуѓ╣№╝ѕCheckpointing...
тЁ▒ТюЅ3СИфт«ЅУБЁтїЁ: kafka:kafka_2.12-2.8.0.tgz zookeeper:apache-zookeeper-3.7.0-bin.tar.gz kafkaтЈ»УДєтїќтиЦтЁи:offsetexplorer_64bit.exe
Spring Boot СИГтдѓСйЋт«ъуј░ Kafka ТїЄт«џ Offset ТХѕУ┤╣ тюе Spring Boot СИГт«ъуј░ Kafka ТїЄт«џ Offset ТХѕУ┤╣Тў»жЮътИИжЄЇУдЂуџё№╝їуЅ╣тѕФТў»тюеућЪС║Дуј»тбЃСИГ№╝їжюђУдЂжЄЇТќ░ТХѕУ┤╣ТЪљСИф Offset уџёТЋ░ТЇ«ТЌХсђѓСИІжЮбТѕЉС╗гт░єУ»ду╗єС╗Іу╗ЇтдѓСйЋтюе Spring Boot СИГ...
Spring Boot жЏєуЙцу«АуљєтиЦтЁи KafkaAdminClient Сй┐ућеТќ╣Т│ЋУДБТъљ KafkaAdminClient Тў» Spring Boot жЏєуЙцу«АуљєтиЦтЁиСИГуџёСИђжЃетѕє№╝їСИ╗УдЂућеС║ју«АуљєтњїТБђУДє Kafka жЏєуЙцСИГуџёTopicсђЂBrokerсђЂACL уГЅт»╣У▒АсђѓСИІжЮбт░єУ»ду╗єС╗Іу╗Ї Kafka...
Offset Explorer№╝ѕтјЪтљЇKafka Tool№╝ЅТў»СИђТгЙућеС║ју«АуљєтњїСй┐ућеApache KafkaжЏєуЙцуџётЏЙтйбућеТѕиуЋїжЮб№╝ѕGUI№╝Ѕт║ћућеуеІт║Јсђѓт«ЃСИ║ућеТѕиТЈљСЙЏС║єуЏ┤УДѓуџёUIуЋїжЮб№╝їТќ╣СЙ┐т┐ФжђЪТЪЦуюІKafkaжЏєуЙцСИГуџёт»╣У▒АС╗ЦтЈіжЏєуЙцСИ╗жбўСИГтГўтѓеуџёТХѕТЂ»сђѓ - ТюђТќ░уЅѕТюгуџё...
- **ТХѕУ┤╣УђЁу╗ёжЄЇуй«**: `offset-reset` тЉйС╗цтЈ»С╗ЦтИ«тіЕСйат░єТХѕУ┤╣УђЁу╗ёуџётЂЈуД╗жЄЈжЄЇуй«тѕ░уЅ╣т«џСйЇуй«№╝їтдѓТюђТЌЕуџёУ«░тйЋТѕќТюђТќ░уџёУ«░тйЋсђѓ **5. ТЋ░ТЇ«ТЊЇСйю** - **ућЪС║ДТХѕТЂ»**: `produce` тЉйС╗цтЈ»С╗ЦтљЉТїЄт«џСИ╗жбўтЈЉжђЂТХѕТЂ»№╝їУ┐Ўт»╣С║јТхІУ»ЋтњїУ░ЃУ»Ћ...
kettle7.1уЅѕТюгТЋ┤тљѕkafka№╝їkafkaТЈњС╗ХтїЁтљФућЪС║ДУђЁсђЂТХѕУ┤╣УђЁсђѓуЏ┤ТјЦтюеkettleт«ЅУБЁуЏ«тйЋpluginsСИІтѕЏт╗║stepsуЏ«тйЋ№╝їт╣ХУДБтјІСИІУййТќЄС╗Хтѕ░kettle/plugins/stepsуЏ«тйЋсђѓтЁиСйЊтЈ»ТЪЦуюІТѕЉтЇџТќЄсђѓ
4. **ТЪЦуюІСИју«АуљєOffsets**№╝џKafkatoolтЁЂУ«ИућеТѕиТЪЦуюІТ»ЈСИфpartitionуџёТюђт░ЈтњїТюђтцДoffset№╝їС╗ЦтЈіconsumer groupуџётйЊтЅЇoffsetсђѓућеТѕиУ┐ўтЈ»С╗ЦТЅІтіеУ«Йуй«ТѕќжЄЇуй«offset№╝їУ┐Ўт»╣С║јУ░ЃУ»ЋтњїТхІУ»ЋТў»жЮътИИТюЅућеуџёсђѓ 5. **тѕЏт╗║СИјтѕажЎцTopic**№╝џ...
kafka-connect-storage-cloudТў»СИђтЦЌТЌетюеућеС║јтюеKafkaтњїтЁгтЁ▒С║ЉтГўтѓе№╝ѕСЙІтдѓAmazon S3№╝ЅС╣ІжЌ┤тцЇтѕХТЋ░ТЇ«сђѓ СИІжЮбтѕЌтЄ║С║єтйЊтЅЇтЈ»ућеуџёУ┐ъТјЦтЎе№╝џ жђѓућеС║јAmazon Simple Storage Service№╝ѕS3№╝ЅуџёKafka ConnectТјЦТћХтЎеУ┐ъТјЦтЎе тЈ»С╗Цтюе...