
ŔŻČŔŻŻ´╝Ühttp://blog.csdn.net/pzhtpf/article/details/7559943
 
1´╝ëňč║ŠťČŠÇŁŠâ│´╝ÜňťĘŔŽüŠÄĺň║ĆšÜäńŞÇš╗䊼░ńŞş´╝îÚÇëňç║ŠťÇň░ĆšÜäńŞÇńެŠĽ░ńŞÄšČČńŞÇńެńŻŹšŻ«šÜ䊼░ń║ĄŠŹó´╝Ť
šäÂňÉÄňťĘňëęńŞőšÜ䊼░ňŻôńŞşň揊뿊ťÇň░ĆšÜäńŞÄšČČń║îńެńŻŹšŻ«šÜ䊼░ń║ĄŠŹó´╝îňŽéŠşĄňż¬šÄ»ňł░ňÇ劼░šČČń║îńެŠĽ░ňĺÇňÉÄńŞÇńެŠĽ░Š»öŔżâńŞ║ŠşóŃÇé
´╝ł2´╝ëň«×ńżő´╝Ü

 
´╝ł3´╝ëšöĘjavaň«×šÄ░
- publicclass selectSort {  
-   
-     public selectSort(){  
-   
-        int a[]={1,54,6,3,78,34,12,45};  
-   
-        int position=0;  
-   
-        for(int i=0;i<a.length;i++){  
-   
-              
-   
-            int j=i+1;  
-   
-            position=i;  
-   
-            int temp=a[i];  
-   
-            for(;j<a.length;j++){  
-   
-            if(a[j]<temp){  
-   
-               temp=a[j];  
-   
-               position=j;  
-   
-            }  
-   
-            }  
-   
-            a[position]=a[i];  
-   
-            a[i]=temp;  
-   
-        }  
-   
-        for(int i=0;i<a.length;i++)  
-   
-            System.out.println(a[i]);  
-   
-     }  
-   
- }  
 
 
4´╝îňáćŠÄĺň║Ć
´╝ł1´╝ëňč║ŠťČŠÇŁŠâ│´╝ÜňáćŠÄĺň║ĆŠś»ńŞÇšžŹŠáĹňŻóÚÇëŠőęŠÄĺň║Ć´╝»ň»╣šŤ┤ŠÄąÚÇëŠőęŠÄĺň║ĆšÜ䊝늼łŠö╣Ŕ┐ŤŃÇé
ňáćšÜäň«Üń╣ëňŽéńŞő´╝ÜňůĚŠťënńެňůâš┤ášÜäň║ĆňłŚ´╝łh1,h2,...,hn),ňŻôńŞöń╗ůňŻôŠ╗íŔÂ│´╝łhi>=h2i,hi>=2i+1´╝늳ľ´╝łhi<=h2i,hi<=2i+1´╝ë(i=1,2,...,n/2)ŠŚÂšž░ń╣őńŞ║ňáćŃÇéňťĘŔ┐ÖÚçîňƬŔ«ĘŔ«║Š╗íŔÂ│ňëŹŔÇůŠŁíń╗šÜäňáćŃÇéšö▒ňáćšÜäň«Üń╣ëňĆ»ń╗ąšťőňç║´╝îňáćÚíÂňůâš┤á´╝łňŹ│šČČńŞÇńެňůâš┤á´╝ëň┐ůńŞ║ŠťÇňĄžÚí╣´╝łňĄžÚíÂňáć´╝ëŃÇéň«îňůĘń║îňĆëŠáĹňĆ»ń╗ąňżłšŤ┤Ŕžéňť░ŔíĘšĄ║ňáćšÜäš╗ôŠ×äŃÇéňáćÚíÂńŞ║Šá╣´╝îňůÂň«âńŞ║ňĚŽňşÉŠáĹŃÇüňĆ│ňşÉŠáĹŃÇéňłŁňžőŠŚÂŠŐŐŔŽüŠÄĺň║ĆšÜ䊼░šÜäň║ĆňłŚšťőńŻťŠś»ńŞÇŠúÁÚí║ň║ĆňşśňéĘšÜäń║îňĆëŠáĹ´╝îŔ░⊼┤ň«âń╗ČšÜäňşśňéĘň║Ć´╝îńŻ┐ń╣őŠłÉńŞ║ńŞÇńެňáć´╝îŔ┐ÖŠŚÂňáćšÜäŠá╣ŔŐéšé╣šÜ䊼░ŠťÇňĄžŃÇéšäÂňÉÄň░ćŠá╣ŔŐéšé╣ńŞÄňáćšÜ䊝ÇňÉÄńŞÇńެŔŐéšé╣ń║ĄŠŹóŃÇéšäÂňÉÄň»╣ňëŹÚŁó(n-1)ńެŠĽ░Ú珊ľ░Ŕ░⊼┤ńŻ┐ń╣őŠłÉńŞ║ňáćŃÇéńżŁŠşĄš▒╗ŠÄĘ´╝┤ňł░ňƬŠťëńŞĄńެŔŐéšé╣šÜäňáć´╝îň╣Âň»╣ň«âń╗ČńŻťń║ĄŠŹó´╝ÇňÉÄňżŚňł░ŠťënńެŔŐéšé╣šÜ䊝ëň║Ćň║ĆňłŚŃÇéń╗Äš«ŚŠ│ĽŠĆĆŔ┐░ŠŁąšťő´╝îňáćŠÄĺň║ĆÚťÇŔŽüńŞĄńެŔ┐çšĘő´╝îńŞÇŠś»ň╗║šźőňáć´╝îń║»ňáćÚíÂńŞÄňáćšÜ䊝ÇňÉÄńŞÇńެňůâš┤áń║ĄŠŹóńŻŹšŻ«ŃÇéŠëÇń╗ąňáćŠÄĺň║ĆŠťëńŞĄńެň篊Ľ░š╗䊳ÉŃÇéńŞÇŠś»ň╗║ňáćšÜ䊪ŚÚÇĆň篊Ľ░´╝îń║»ňĆŹňĄŹŔ░âšöĘŠŞŚÚÇĆň篊Ľ░ň«×šÄ░ŠÄĺň║ĆšÜäň篊Ľ░ŃÇé
´╝ł2´╝ëň«×ńżő´╝Ü
ňłŁňžőň║ĆňłŚ´╝Ü46,79,56,38,40,84
ň╗║ňáć´╝Ü
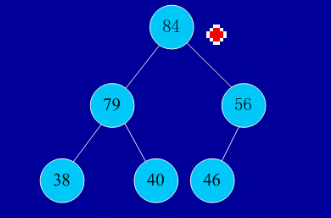
ń║ĄŠŹó´╝îń╗ÄňáćńŞşŔŞóňç║ŠťÇňĄžŠĽ░
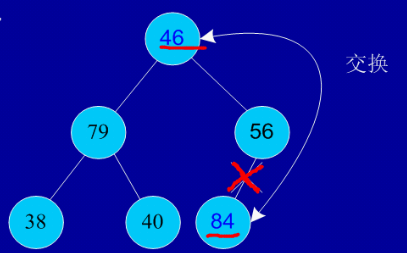
 
ňëęńŻÖš╗ôšé╣ňćŹň╗║ňáć´╝îňćŹń║ĄŠŹóŔŞóňç║ŠťÇňĄžŠĽ░
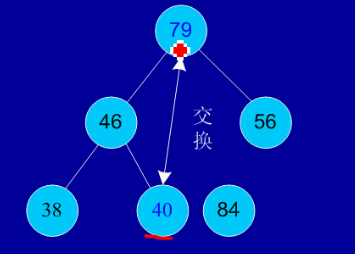
 
ńżŁŠČíš▒╗ŠÄĘ´╝ÜŠťÇňÉÄňáćńŞşňëęńŻÖšÜ䊝ÇňÉÄńŞĄńެš╗ôšé╣ń║ĄŠŹó´╝îŔŞóňç║ńŞÇńެ´╝îŠÄĺň║Ćň«îŠłÉŃÇé
´╝ł3´╝ëšöĘjavaň«×šÄ░
 
- import java.util.Arrays;  
-   
-    
-   
- publicclass HeapSort {  
-   
-      inta[]={49,38,65,97,76,13,27,49,78,34,12,64,5,4,62,99,98,54,56,17,18,23,34,15,35,25,53,51};  
-   
-     public  HeapSort(){  
-   
-        heapSort(a);  
-   
-     }  
-   
-     public  void heapSort(int[] a){  
-   
- ┬á┬á┬á┬á┬á┬á┬á┬áSystem.out.println("ň╝ÇňžőŠÄĺň║Ć");┬á┬á
-   
-         int arrayLength=a.length;  
-   
- ┬á┬á┬á┬á┬á┬á┬á┬á//ňż¬šÄ»ň╗║ňáć┬á┬á
-   
-         for(int i=0;i<arrayLength-1;i++){  
-   
- ┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á//ň╗║ňáć┬á┬á
-   
-             buildMaxHeap(a,arrayLength-1-i);  
-   
- ┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á//ń║ĄŠŹóňáćÚíÂňĺÇňÉÄńŞÇńެňůâš┤á┬á┬á
-   
-             swap(a,0,arrayLength-1-i);  
-   
-             System.out.println(Arrays.toString(a));  
-   
-         }  
-   
-     }  
-   
-    
-   
-     private  void swap(int[] data, int i, int j) {  
-   
-         // TODO Auto-generated method stub  
-   
-         int tmp=data[i];  
-   
-         data[i]=data[j];  
-   
-         data[j]=tmp;  
-   
-     }  
-   
- ┬á┬á┬á┬á//ň»╣dataŠĽ░š╗äń╗Ä0ňł░lastIndexň╗║ňĄžÚíÂňáć┬á┬á
-   
-     privatevoid buildMaxHeap(int[] data, int lastIndex) {  
-   
-         // TODO Auto-generated method stub  
-   
- ┬á┬á┬á┬á┬á┬á┬á┬á//ń╗ÄlastIndexňĄäŔŐéšé╣´╝łŠťÇňÉÄńŞÇńެŔŐéšé╣´╝ëšÜäšłÂŔŐéšé╣ň╝Çňžő┬á┬á
-   
-         for(int i=(lastIndex-1)/2;i>=0;i--){  
-   
- ┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á//kń┐ŁňşśŠşúňťĘňłĄŠľşšÜäŔŐéšé╣┬á┬á
-   
-             int k=i;  
-   
- ┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á//ňŽéŠ×ťňŻôňëŹkŔŐéšé╣šÜäňşÉŔŐéšé╣ňşśňťĘ┬á┬á
-   
-             while(k*2+1<=lastIndex){  
-   
- ┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á//kŔŐéšé╣šÜäňĚŽňşÉŔŐéšé╣šÜäš┤óň╝Ľ┬á┬á
-   
-                 int biggerIndex=2*k+1;  
-   
- ┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á//ňŽéŠ×ťbiggerIndexň░Ćń║ÄlastIndex´╝îňŹ│biggerIndex+1ń╗úŔíĘšÜäkŔŐéšé╣šÜäňĆ│ňşÉŔŐéšé╣ňşśňťĘ┬á┬á
-   
-                 if(biggerIndex<lastIndex){  
-   
- ┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á//ŔőąŠ×ťňĆ│ňşÉŔŐéšé╣šÜäňÇ╝ŔżâňĄž┬á┬á
-   
-                     if(data[biggerIndex]<data[biggerIndex+1]){  
-   
- ┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á//biggerIndexŠÇ╗Šś»Ŕ«░ňŻĽŔżâňĄžňşÉŔŐéšé╣šÜäš┤óň╝Ľ┬á┬á
-   
-                         biggerIndex++;  
-   
-                     }  
-   
-                 }  
-   
- ┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á//ňŽéŠ×ťkŔŐéšé╣šÜäňÇ╝ň░Ćń║ÄňůÂŔżâňĄžšÜäňşÉŔŐéšé╣šÜäňÇ╝┬á┬á
-   
-                 if(data[k]<data[biggerIndex]){  
-   
- ┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á//ń║ĄŠŹóń╗ľń╗Č┬á┬á
-   
-                     swap(data,k,biggerIndex);  
-   
- ┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á//ň░ćbiggerIndexŔÁőń║łk´╝îň╝Çňžőwhileňż¬šÄ»šÜäńŞőńŞÇŠČíňż¬šÄ»´╝îÚ珊ľ░ń┐ŁŔ»ükŔŐéšé╣šÜäňÇ╝ňĄžń║ÄňůÂňĚŽňĆ│ňşÉŔŐéšé╣šÜäňÇ╝┬á┬á
-   
-                     k=biggerIndex;  
-   
-                 }else{  
-   
-                     break;  
-   
-                 }  
-   
-             }  
-   
-         }  
-   
-     }  
-   
-    
-   
-    
-   
- }  



šŤŞňů│ŠÄĘŔŹÉ
ń╗ąńŞŐŠś»ňů│ń║ÄÔÇťš«ÇňŹĽÚÇëŠőęŠÄĺň║ĆňĆŐňáćŠÄĺň║ĆÔÇŁšÜäŠáŞň┐âščąŔ»ćšé╣ŃÇéÚÇÜŔ┐çšÉćŔžúŔ┐ÖńŞĄšžŹŠÄĺň║Ćš«ŚŠ│ĽšÜäňĚąńŻťňÄčšÉć´╝îňĆ»ń╗ąŠŤ┤ňąŻňť░Ŕ┐ÉšöĘň«âń╗ČŔžúňć│ň«×ÚÖůÚŚ«ÚóśŃÇéňťĘň«×ÚÖůš╝ľšĘőńŞş´╝îŠá╣ŠŹ«ŠĽ░ŠŹ«ŔžäŠĘíŃÇüŠś»ňÉŽÚťÇŔŽüšĘ│ň«ÜŠÄĺň║Ćń╗ąňĆŐňćůňşśÚÖÉňłÂšşëňŤáš┤á´╝îÚÇëŠőęňÉłÚÇéšÜäŠÄĺň║Ćš«ŚŠ│ĽŠś»...
ńŞőÚŁóň░ćŔ»Žš╗ćŔ«ĘŔ«║š«ÇňŹĽÚÇëŠőęŠÄĺň║ĆňĺîňáćŠÄĺň║ĆŔ┐ÖńŞĄšžŹš«ŚŠ│Ľ´╝îň╣š╗ôňÉłC++ń╗úšáüň«×šÄ░Ŕ┐ŤŔíîŔžúŠ×ÉŃÇé ### š«ÇňŹĽÚÇëŠőęŠÄĺň║Ć š«ÇňŹĽÚÇëŠőęŠÄĺň║ĆšÜäš«ŚŠ│ĽŠÁüšĘőňŽéńŞő´╝Ü 1. ń╗ÄňżůŠÄĺň║ĆšÜ䊼░š╗äńŞşŠëżňł░ŠťÇň░Ćňůâš┤á´╝îŔ«░ńŻťňŻôň돊ťÇň░ĆňÇ╝ŃÇé 2. ň░ćňŻôň돊ťÇň░ĆňÇ╝ńŞÄŠĽ░š╗äšÜäšČČńŞÇ...
´╝ł1´╝ë ň«îŠłÉ5šžŹňŞŞšöĘňćůÚâĘŠÄĺň║Ćš«ŚŠ│ĽšÜäŠ╝öšĄ║´╝î5šžŹŠÄĺň║Ćš«ŚŠ│ĽńŞ║´╝Üň┐źÚÇčŠÄĺň║Ć´╝┤ŠÄąŠĆĺňůąŠÄĺň║Ć´╝îÚÇëŠőęŠÄĺň║Ć´╝îňáćŠÄĺň║Ć´╝îňŞîň░öŠÄĺň║Ć´╝Ť ´╝ł2´╝ë ňżůŠÄĺň║Ćňůâš┤áńŞ║ŠĽ┤ŠĽ░´╝îŠÄĺň║Ćň║ĆňłŚňşśňéĘňťĘŠĽ░ŠŹ«Šľçń╗ÂńŞş´╝îŔŽüŠ▒éŠÄĺň║Ćňůâš┤áńŞŹň░Ĺń║Ä30ńެ´╝Ť ´╝ł3´╝ë Š╝öšĄ║šĘőň║Ćň╝Çňžő´╝î...
ň«×šÄ░ń╗ąńŞőňŞŞšöĘšÜäňćůÚâĘŠÄĺň║Ćš«ŚŠ│Ľň╣ÂŔ┐ŤŔíîŠÇžŔ⯊»öŔżâ´╝Ü"šŤ┤ŠÄąŠĆĺňůąŠÄĺň║Ć"," ŠŐśňŹŐŠĆĺňůąŠÄĺň║Ć"," 2ÔÇöŔĚ»ŠĆĺňůąŠÄĺň║Ć"," ŔíĘŠĆĺňůąŠÄĺň║Ć"," ňŞîň░öŠÄĺň║Ć"," ŔÁĚŠ│íŠÄĺň║Ć"," ň┐źÚÇčŠÄĺň║Ć"," š«ÇňŹĽÚÇëŠőęŠÄĺň║Ć"," ŠáĹňŻóÚÇëŠőęŠÄĺň║Ć"," ňáćŠÄĺň║Ć"," ňŻĺň╣ŠÄĺň║Ć"," Úôżň╝Ć...
ŠťČńŞ╗ÚóśŠÂÁšŤľń║ćňůşšžŹš╗ĆňůŞšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝ÜňŞîň░öŠÄĺň║ĆŃÇüňáćŠÄĺň║ĆŃÇüň┐źÚÇčŠÄĺň║ĆŃÇüš«ÇňŹĽÚÇëŠőęŠÄĺň║ĆŃÇüŠĆĺňůąŠÄĺň║ĆňĺîňćĺŠ│íŠÄĺň║ĆŃÇéŔ┐Öń║Ťš«ŚŠ│ĽňÉ䊝ëšë╣šé╣´╝îÚÇéšöĘń║ÄńŞŹňÉîšÜäňť║ŠÖ»´╝îńŞőÚŁóň░ćÚÇÉńŞÇŔ»Žš╗ćń╗őš╗ŹŃÇé 1. **ňŞîň░öŠÄĺň║Ć**´╝ÜňŞîň░öŠÄĺň║ĆŠś»šö▒Donald ShellŠĆÉňç║šÜä...
ŠťČŔ»ŁÚóśńŞ╗ŔŽüŠÄóŔ«ĘňůşšžŹňćůÚâĘŠÄĺň║Ćš«ŚŠ│Ľ´╝ÜšŤ┤ŠÄąŠĆĺňůąŠÄĺň║ĆŃÇüňŞîň░öŠÄĺň║ĆŃÇüňćĺŠ│íŠÄĺň║ĆŃÇüň┐źÚÇčŠÄĺň║ĆŃÇüÚÇëŠőęŠÄĺň║Ćń╗ąňĆŐňáćŠÄĺň║ĆŃÇéŔ┐ÖňůşšžŹŠÄĺň║Ćš«ŚŠ│ĽňÉ䊝ëń╝śňŐú´╝îÚÇéšöĘń║ÄńŞŹňÉîšÜäňť║ŠÖ»´╝îŠÄąńŞőŠŁąŠłĹń╗Čň░ćÚÇÉńŞÇŔ┐ŤŔíîŔ»Žš╗ćÚśÉŔ┐░ŃÇé 1. **šŤ┤ŠÄąŠĆĺňůąŠÄĺň║Ć**´╝Ü šŤ┤ŠÄą...
ŠťČŔÁäŠ║ÉŠĆÉńżŤń║ćńŞâňĄžš╗ĆňůŞŠÄĺň║Ćš«ŚŠ│ĽšÜäň«×šÄ░šĘőň║Ć´╝îňîůŠőČň┐źÚÇčŠÄĺň║ĆŃÇüňćĺŠ│íŠÄĺň║ĆŃÇüÚÇëŠőęŠÄĺň║ĆŃÇüňŻĺň╣ŠÄĺň║ĆŃÇüŠĆĺňůąŠÄĺň║ĆŃÇüňŞîň░öŠÄĺň║ĆňĺîňáćŠÄĺň║ĆŃÇéńŞőÚŁóň░ćÚÇÉńŞÇŔ»Žš╗ćń╗őš╗ŹŔ┐Öń║ŤŠÄĺň║Ćš«ŚŠ│ĽňĆŐňůÂňÄčšÉćŃÇé 1. ň┐źÚÇčŠÄĺň║Ć´╝Üšö▒C.A.R. HoareŠĆÉňç║´╝»ńŞÇšžŹÚççšöĘ...
ŠťČŠľçň░ćŠĚ▒ňůąŠÄóŔ«ĘňŤŤšžŹňťĘC++ńŞşň«×šÄ░šÜäňŞŞŔžüŠÄĺň║Ćš«ŚŠ│Ľ´╝ÜŠĆĺňůąŠÄĺň║ĆŃÇüňćĺŠ│íŠÄĺň║ĆŃÇüňáćŠÄĺň║Ćňĺîň┐źÚÇčŠÄĺň║ĆŃÇéŔ┐Öń║Ťš«ŚŠ│ĽňÉ䊝ëšë╣šé╣´╝îÚÇéšöĘń║ÄńŞŹňÉîšÜäňť║ŠÖ»´╝îšÉćŔžúň╣ŠÄîŠĆíň«âń╗Čň»╣ń║ÄŠĆÉňŹçš╝ľšĘőŔâŻňŐŤŔç│ňů│ÚçŹŔŽüŃÇé 1. **ŠĆĺňůąŠÄĺň║Ć**´╝Ü ŠĆĺňůąŠÄĺň║ĆŠś»ńŞÇšžŹš«ÇňŹĽšÜä...
ŠťČŠľçň░ćŠĚ▒ňůąŠÄóŔ«ĘJavaš╝ľšĘőŔ»şŔĘÇńŞşň«×šÄ░šÜäńŞâšžŹńŞ╗ŔŽüŠÄĺň║Ćš«ŚŠ│Ľ´╝ÜšŤ┤ŠÄąŠĆĺňůąŠÄĺň║ĆŃÇüňŞîň░öŠÄĺň║ĆŃÇüÚÇëŠőęŠÄĺň║ĆŃÇüňáćŠÄĺň║ĆŃÇüňćĺŠ│íŠÄĺň║ĆŃÇüň┐źÚÇčŠÄĺň║Ćń╗ąňĆŐňŻĺň╣ŠÄĺň║ĆŃÇ銻ƚžŹš«ŚŠ│ĽÚ⯊ťëňůšőČšë╣ŠÇž´╝îÚÇéšöĘń║ÄńŞŹňÉîšÜäňť║ŠÖ»ňĺ░ŠŹ«šë╣ŠÇžŃÇé 1. **šŤ┤ŠÄąŠĆĺňůąŠÄĺň║Ć**´╝Ü...
ňćĺŠ│íŠÄĺň║ĆŃÇüň┐źÚÇčŠÄĺň║ĆŃÇüš«ÇňŹĽŠĆĺňůąŠÄĺň║ĆŃÇüňŞîň░öŠÄĺň║ĆŃÇüš«ÇňŹĽÚÇëŠőęŠÄĺň║ĆňĺîňáćŠÄĺň║ĆŠś»ŠĽ░ŠŹ«š╗ôŠ×äńŞşňŞŞŔžüšÜäňůşšžŹňč║ŠťČŠÄĺň║Ćš«ŚŠ│Ľ´╝îň«âń╗ČňÉ䊝ëšë╣šé╣ňĺîň║öšöĘňť║ŠÖ»´╝»ňşŽń╣ኼ░ŠŹ«š╗ôŠ×äň┐ůŔÇâšÜäščąŔ»ćšé╣ŃÇé ňćĺŠ│íŠÄĺň║ĆŠś»ńŞÇšžŹš«ÇňŹĽšŤ┤ŔžéšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îňůÂňč║ŠťČŠÇŁŠâ│Šś»...
ńŞőÚŁóň░ćŔ»Žš╗ćŔ«▓ŔžúŔ┐Ö7šžŹŠÄĺň║Ćš«ŚŠ│Ľ´╝Üň┐źÚÇčŠÄĺň║ĆŃÇüňŻĺň╣ŠÄĺň║ĆŃÇüŠĆĺňůąŠÄĺň║ĆŃÇüÚÇëŠőęŠÄĺň║ĆŃÇüňćĺŠ│íŠÄĺň║ĆŃÇüňáćŠÄĺň║Ćń╗ąňĆŐňŞîň░öŠÄĺň║ĆŃÇé 1. **ň┐źÚÇčŠÄĺň║Ć**´╝Üšö▒C.A.R. HoareŠĆÉňç║šÜä´╝îÚççšöĘňłćŠ▓╗šşľšĽąŃÇéňč║ŠťČŠÇŁŠâ│Šś»ÚÇëňĆľńŞÇńެňč║ňçćňůâš┤á´╝îÚÇÜŔ┐çńŞÇŔÂčŠÄĺň║Ćň░ćňżů...
ń╗ąńŞőŠś»ňů│ń║Ä"ňćĺŠ│íŠÄĺň║Ć´╝îÚÇëŠőęŠÄĺň║Ć´╝îŠĆĺňůąŠÄĺň║Ć´╝îňŞîň░öŠÄĺň║Ć´╝îňáćŠÄĺň║Ć´╝îňŻĺň╣ŠÄĺň║Ć´╝îň┐źÚÇčŠÄĺň║Ć"Ŕ┐ÖńŞâšžŹňŞŞŔžüŠÄĺň║Ćš«ŚŠ│ĽšÜäŠ║Éšáüň«×šÄ░ňĆŐšŤŞňů│ščąŔ»ćšé╣šÜäŔ»Žš╗ćŔžúÚçŐ´╝Ü 1. **ňćĺŠ│íŠÄĺň║Ć**´╝ÜňćĺŠ│íŠÄĺň║ĆŠś»ńŞÇšžŹš«ÇňŹĽšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îň«âÚçŹňĄŹňť░ÚüŹňÄćňżůŠÄĺň║ĆšÜä...
ŠťČńŞ╗Úóśň░ćŔ»Žš╗ćŠÄóŔ«ĘňŞîň░öŠÄĺň║ĆŃÇüňćĺŠ│íŠÄĺň║ĆŃÇüňáćŠÄĺň║Ćšşëš╗ĆňůŞšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îŔ┐Öń║ŤÚ⯊ś»ŠĽ░ŠŹ«š╗ôŠ×äńŞÄš«ŚŠ│ĽňşŽń╣áńŞşšÜäŠáŞň┐âňćůň«╣´╝îň░ĄňůÂň»╣ń║ÄňîŚÚé«ŠĽ░ŠŹ«š╗ôŠ×äŔ»żšĘőŠŁąŔ»┤´╝îšÉćŔžúň╣ŠÄîŠĆíŔ┐Öń║ŤŠÄĺň║ĆŠľ╣Š│ĽŔç│ňů│ÚçŹŔŽüŃÇé 1. **ŠĆĺňůąŠÄĺň║Ć**´╝Ü ŠĆĺňůąŠÄĺň║ĆŠś»ńŞÇšžŹ...
ŠťČš»çŠľçšźáň░ćŔ»Žš╗ćŔ«▓ŔžúňŤŤšžŹš╗ĆňůŞšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝Üň┐źÚÇčŠÄĺň║ĆŃÇüňćĺŠ│íŠÄĺň║ĆŃÇüÚÇëŠőęŠÄĺň║ĆňĺîňáćŠÄĺň║ĆŃÇé **ň┐źÚÇčŠÄĺň║Ć**´╝îšö▒C.A.R. HoareňťĘ1960ň╣┤ŠĆÉňç║´╝»ńŞÇšžŹŠĽłšÄçŔżâÚźśšÜäňłćŠ▓╗š«ŚŠ│ĽŃÇéň«âšÜäňč║ŠťČŠÇŁŠâ│Šś»ÚÇëňĆľńŞÇńެÔÇťňč║ňçćÔÇŁňůâš┤á´╝îÚÇÜŔ┐çńŞÇŔÂčŠÄĺň║Ćň░ćňżů...
ŠťČÚí╣šŤ«ŠÂÁšŤľń║ćń║öšžŹš╗ĆňůŞšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝Üň┐źÚÇčŠÄĺň║ĆŃÇüňáćŠÄĺň║ĆŃÇüňŻĺň╣ŠÄĺň║ĆŃÇüŠĆĺňůąŠÄĺň║ĆňĺîÚÇëŠőęŠÄĺň║ĆŃÇéŠÄąńŞőŠŁą´╝Ĺń╗Čň░ćŠĚ▒ňůąŠÄóŔ«ĘŔ┐Öń║Ťš«ŚŠ│ĽšÜäňÄčšÉćŃÇüň«×šÄ░ňĆŐŠÇžŔ⯚ë╣šé╣ŃÇé 1. **ň┐źÚÇčŠÄĺň║Ć**´╝Ü ň┐źÚÇčŠÄĺň║Ćšö▒C.A.R. HoareňťĘ1960ň╣┤ŠĆÉňç║´╝»ńŞÇšžŹÚççšöĘ...
ŠĽ░ŠŹ«š╗ôŠ×äŠÄĺň║Ć ňáćŠÄĺň║Ć ňáćŠÄĺň║ĆŠś»ńŞÇšžŹňŞŞšöĘšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îň«âńŻ┐šöĘňĄžňáćŔ┐ŤŔíîŠÄĺň║ĆŃÇéńŞőÚŁóŠś»ňáćŠÄĺň║ĆšÜäŔ»Žš╗ćščąŔ»ćšé╣Ŕ»┤ŠśÄ´╝Ü ňáćŠÄĺň║Ćň«Üń╣ë ňáćŠÄĺň║ĆŠś»ńŞÇšžŹŠ»öŔżâŠÄĺň║Ćš«ŚŠ│Ľ´╝îň«âńŻ┐šöĘňĄžňáć´╝łmax heap´╝늣ąň»╣ŠĽ░š╗äŔ┐ŤŔíîŠÄĺň║ĆŃÇéňáćŠÄĺň║ĆšÜ䊌ÂÚŚ┤ňĄŹŠŁéň║ŽńŞ║O...
ŠťČŠľçň░ćŠĚ▒ňůąŠÄóŔ«Ęń║öšžŹňŞŞšöĘšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝Üň┐źÚÇčŠÄĺň║ĆŃÇüňŻĺň╣ŠÄĺň║ĆŃÇüÚÇëŠőęŠÄĺň║ĆŃÇüŔ░óň░öŠÄĺň║ĆňĺîňáćŠÄĺň║ĆŃÇé **ň┐źÚÇčŠÄĺň║Ć** Šś»šö▒C.A.R. HoareňťĘ1960ň╣┤ŠĆÉňç║šÜä´╝»ńŞÇšžŹŠĽłšÄçŔżâÚźśšÜäňłćŠ▓╗šşľšĽąŃÇéňůÂňč║ŠťČŠÇŁŠâ│Šś»ÚÇÜŔ┐çńŞÇŔÂčŠÄĺň║Ćň░ćňżůŠÄĺň║ĆšÜ䊼░ŠŹ«ňłćňë▓ŠłÉ...
ŠÄĺň║Ćš«ŚŠ│ĽŠ▒çŠÇ╗´╝łÚÇëŠőęŠÄĺň║ĆŃÇüšŤ┤ŠÄąŠĆĺňůąŠÄĺň║ĆŃÇüňćĺŠ│íŠÄĺň║ĆŃÇüňŞîň░öŠÄĺň║ĆŃÇüň┐źÚÇčŠÄĺň║ĆŃÇüňáćŠÄĺň║Ć´╝ë ŠťČŔÁäŠ║Éń╗őš╗Źń║ćňůşšžŹňŞŞšöĘšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝ÜÚÇëŠőęŠÄĺň║ĆŃÇüšŤ┤ŠÄąŠĆĺňůąŠÄĺň║ĆŃÇüňćĺŠ│íŠÄĺň║ĆŃÇüňŞîň░öŠÄĺň║ĆŃÇüň┐źÚÇčŠÄĺň║ĆňĺîňáćŠÄĺň║ĆŃÇéńŞőÚŁóň»╣Š»ĆšžŹš«ŚŠ│ĽŔ┐ŤŔíîŔ»Žš╗ćń╗őš╗Ź´╝Ü...
ń╗ąńŞőŠś»ňů│ń║Ä"ŠĆĺňůąŠÄĺň║ĆŃÇüÚÇëŠőęŠÄĺň║ĆŃÇüňŞîň░öŠÄĺň║ĆŃÇüňáćŠÄĺň║ĆŃÇüňćĺŠ│íŃÇüňĆîňÉĹňćĺŠ│íŃÇüň┐źÚÇčŠÄĺň║ĆŃÇüňŻĺň╣ŠÄĺň║ĆŃÇüÚÇĺňŻĺšÜäňŻĺň╣ŠÄĺň║ĆŃÇüňč║ŠĽ░ŠÄĺň║Ć"Ŕ┐ÖňŹüňĄžš╗ĆňůŞŠÄĺň║Ćš«ŚŠ│ĽšÜäŔ»Žš╗ćŔžúÚçŐ´╝Ü 1. ŠĆĺňůąŠÄĺň║Ć´╝ÜŠĆĺňůąŠÄĺň║ĆŠś»ńŞÇšžŹš«ÇňŹĽšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îň«âÚÇÜŔ┐çŠ×äň╗║Šťëň║Ć...
- ňáćŠÄĺň║ĆňłęšöĘń║ćňáćŔ┐ÖšžŹŠĽ░ŠŹ«š╗ôŠ×ä´╝îňůłň░ćňżůŠÄĺň║Ćň║ĆňłŚŠ×äÚÇኳÉńŞÇńެňĄžÚíÂňá抳ľň░ĆÚíÂňáć´╝îšäÂňÉÄň░ćňáćÚíÂňůâš┤áńŞÄŠťźň░żňůâš┤áń║ĄŠŹó´╝îŔ░⊼┤ňëęńŞőšÜäňůâš┤áÚ珊ľ░Š×äÚÇኳÉňáć´╝┤ňł░ŠĽ┤ńެň║ĆňłŚŠťëň║ĆŃÇé - C# ň«×šÄ░ňáćŠÄĺň║ĆŠŚÂ´╝îńŞ╗ŔŽüŠÂëňĆŐň╗║ňáćŃÇüń║ĄŠŹóňáćÚíÂňĺîŔ░⊼┤ňáćšÜä...