|
精华帖 (0) :: 良好帖 (0) :: 新手帖 (0) :: 隐藏帖 (1)
|
|
|---|---|
| 作者 | 正文 |
|
发表时间:2009-06-18
最后修改:2009-06-18
【1】:先来认识下什么是Hertirex吧! 是IA的开放源代码,可扩展的,基于整个Web的,归档网络爬虫工程 Heritrix主要有三大部件:范围部件,边界部件,处理器链 Heritrix的其余部件有: 处理器链: Heritrix 1.0.0包含以下关键特性: Heritrix的局限:
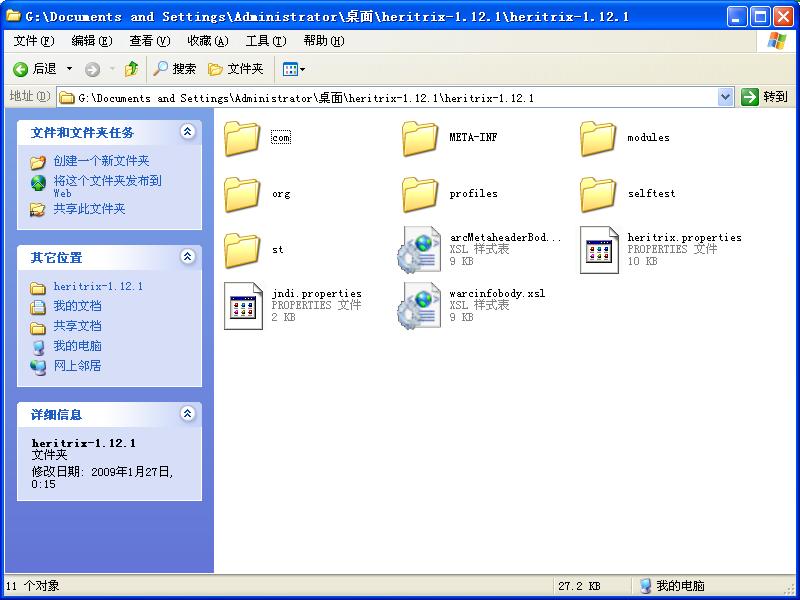
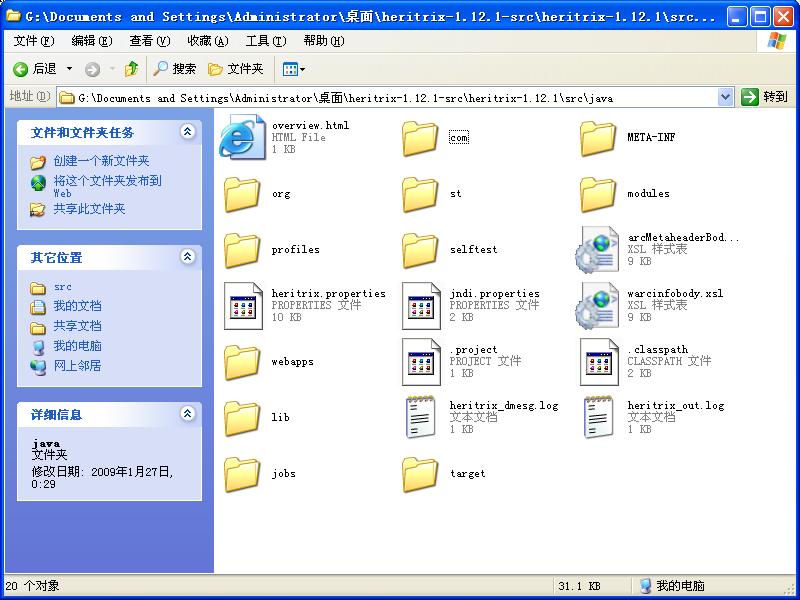
【2】:配置在我们的工程当中: (1):新建一个工程:Hertirex.(no web project). (2):在这里下载最新的Hertirex吧:http://sourceforge.net/project/showfiles.php?group_id=73833&package_id=73980 【3】:heritrix-1.14.3.zip 和 heritrix-1.14.3-src.zip。 (1)。先下载heritrix-1.14.3-src.zip和heritrix-1.14.3.zip。 (2)解压heritrix-1.14.3.jar到\heritrix-1.14.3\heritrix-1.14.3。解压得到的文件夹结构如图: 【3】:把以上目录的所有文件拷贝到heritrix-1.14.3-src\heritrix-1.14.3src\java文件夹下。目的是将java文件夹配置成一个完整的工程目录。 【4】:把\heritrix-1.14.3-src\heritrix-1.14.3\lib文件夹 拷贝到\heritrix-1.14.3-src\heritrix-1.14.3\src\java文件夹下。把lib下的jar包放入工程内部是为了便于管理。 【5】:把heritrix-1.14.3-src\heritrix-1.14.3\src\webapps文件夹拷贝到\heritrix-1.14.3-src\heritrix-1.14.3\src\java文件夹下。此时工程目录基本上完整了。得到的效果如图:
【6】:在Eclipse中新建一个Java Project,选择从现有源代码建立,源代码的路径指向\heritrix-1.14.3-src\heritrix-1.14.3\src\java。命名为Heritrix,点击ok。 【7】:这时在package explorer中应该会出现大量的编译错误标记。原因是没有把对应的jar包导入项目。在Java Build Path的Library选项卡中,把项目lib文件夹下的jar包全部加入Build Path。 【8】:在window->Preference->Java->Compiler中,将Compiler compliance level 设为5.0,也就是JDK1.5兼容的语法。目的是使Heritrix编译通过。否则Eclipse可能不认assert这个关键字。 【9】:用鼠标选中/Heritrix/org/archive/crawler/Heritrix.java,右键选择Run As Java Application,Console应该是没有输出的。原因是没有提供运行的参数(用户名/口令)。 一种方法是,修改项目根文件夹下的heritrix.properties文件,设置“heritrix.cmdline.admin = admin:admin”。正常运行时的输出如下: Heritrix version: 1.14.3
【10】:另外一种设定用户名和密码的方式是,在Run Dialog中的Arguments参数选项卡中,输入-admin=admin:admin,单击Apply,再单击Run即可运行。 【11】:运行Heritrix,在浏览器中输入http://localhost:8080/,用户名/密码为“admin/admin"
声明:ITeye文章版权属于作者,受法律保护。没有作者书面许可不得转载。
推荐链接
|
| 返回顶楼 | |
浏览 4691 次