
一.写数据
DataXceiver的writeBlock方法用于客户端(Client或DataNode)的写数据请求。
二.单一流程
- 读取客户端发送过来的消息(下文称之为“请求参数”)
- blockId:要写入块的block id。
- generationStamp:要写入块的block generationStamp。
- pipelineSize:num of datanodes in entire pipeline.整个管道里的datanode数,默认为3。
- isRecovery:是不是恢复操作。
- clientName:如果是DataNode到DataNode的请求,clientName为空。
- hasSrcDataNode:is src node info present.标识上一节点是DataNode。
- DatanodeInfo:如果hasSrcDataNode,读取此DatanodeInfo。
- numTargets:目标节点的数量。如果是Client的请求,则目标节点为3;如果是DataNode1的请求,则目标节点为2。
- DatanodeInfo[]:每个目标节点。
- checksum:校验数据。

- 根据上面要写入的block创建BlockReceiver。
- 创建流链,确保DataNode1到DataNode3都是通的。
- mirrorOut:stream to next target
- mirrorIn:reply from next target
- mirrorNode:the name:port String of next target
- mirrorSock:socket to next target
- replyOut:stream to prev target
- in:stream from prev target

- 调用BlockReceiver.receiveBlock(各种流)读取客户端数据写到本地,和读数据协议是一样的,参考http://zy19982004.iteye.com/blog/1881733。

三.整个流程
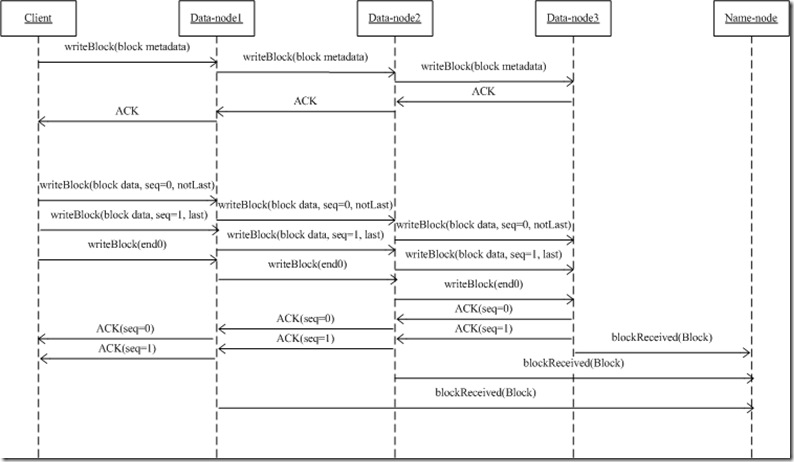
- 上述二是在某一节点上发生的行为,在整个写过程中,每个节点都会发生这个行为,于是形成了下列一个流程图。
- 当前节点会把writeBlock时接受到的请求参数通过mirrorOut继续发生给下一节点;下一节点收到请求,解析请求(二过程),决定是否发生AC应答...
- 如果整个流通道建立了,DataNode1读取client的数据,写到硬盘上,并同时把此数据流继续发送给DataNode2...边收边传
- 当前节点是怎么知道下一节点的?从客户端发生过来的流里面,读取到了目标节点DatanodeInfo[],mirrorNode = targets[0].getName();



相关推荐
hadoop-auth-3.1.1.jar hadoop-hdfs-3.1.1.jar hadoop-mapreduce-client-hs-3.1.1.jar hadoop-yarn-client-3.1.1.jar hadoop-client-api-3.1.1.jar hadoop-hdfs-client-3.1.1.jar hadoop-mapreduce-client-jobclient...
而Hadoop-LZO则是针对Hadoop优化的一种数据压缩库,旨在提高HDFS(Hadoop Distributed File System)上的数据压缩效率和读写性能。这个压缩库是由Groupon开发并维护的,它实现了LZO(Lempel-Ziv-Oberhumer)压缩算法...
1. **数据读写**:Flink通过Hadoop的InputFormat和OutputFormat接口,可以读取和写入Hadoop支持的各种数据源,如HDFS、HBase等。这使得Flink可以方便地访问Hadoop生态系统中的存储系统,进行大规模的数据处理。 2. ...
hadoop源码2.2.0 Apache Hadoop 2.2.0 is the GA release of Apache Hadoop 2.x. Users are encouraged to immediately move to 2.2.0 since this release is significantly more stable and is guaranteed to ...
编译hadoophadoop-3.2.2-src的源码
《深入剖析Hadoop 2.8.1源码:分布式系统的智慧结晶》 Hadoop,作为开源的大数据处理框架,自2006年诞生以来,一直是大数据领域的重要支柱。其2.8.1版本是Hadoop发展的一个关键节点,为用户提供了更稳定、高效的...
《Hadoop 2.5.0-cdh5.3.6 源码解析与应用探索》 Hadoop,作为大数据处理领域的核心组件,一直以来都备受关注。本篇将深入探讨Hadoop 2.5.0-cdh5.3.6版本的源码,解析其设计理念、架构以及主要功能,旨在帮助读者...
3. **配置Hadoop**:修改`etc/hadoop`目录下的配置文件,如`hadoop-env.sh`、`core-site.xml`、`hdfs-site.xml`和`mapred-site.xml`,设置Hadoop的相关参数,如HDFS的命名节点、数据节点路径等。 4. **格式化...
**HDFS源码分析** 1. **NameNode与DataNode**:HDFS的核心组件包括NameNode和DataNode。NameNode作为元数据管理节点,存储文件系统的命名空间信息和文件的块映射信息。DataNode则是数据存储节点,负责存储实际的...
在Java编程环境中,Hadoop分布式文件系统(HDFS)提供了丰富的Java API,使得开发者能够方便地与HDFS进行交互,包括文件的上传、下载、读写等操作。本篇文章将详细探讨如何使用HDFS Java API来实现文件上传的功能。 ...
标题中的“hadoop-common-2.6.0-bin-master”指的是Hadoop Common的2.6.0版本的源码编译后的二进制主目录,这个目录包含了运行Hadoop所需的各种基础工具和库。 在Windows 10环境下,由于操作系统本身的特性和Linux...
- 将示例数据上传到HDFS:`hadoop fs -put /path/to/input/input.txt hdfs://localhost:9000/user/hadoop/input` - 运行WordCount任务: ```bash hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-...
Hadoop 2.X HDFS源码剖析-高清-完整目录-2016年3月,分享给所有需要的人!
这个项目可能提供了在Hadoop环境中通过FTP进行文件传输的能力,使得非Hadoop用户也能方便地访问存储在HDFS上的数据。 描述 "在hadoop分布式文件系统上实现ftp服务" 暗示了这个压缩包包含了一个解决方案,允许用户...
02-hdfs源码跟踪之打开输入流总结.avi 03-mapreduce介绍及wordcount.avi 04-wordcount的编写和提交集群运行.avi 05-mr程序的本地运行模式.avi 06-job提交的逻辑及YARN框架的技术机制.avi 07-MR程序的几种提交...
在本教程中,我们将深入探讨如何使用...这个环境对于学习Hadoop、MapReduce编程以及进行数据处理实验非常有用。记得在操作过程中保持耐心,因为配置可能会有些复杂,但一旦设置成功,你将拥有一个强大的本地开发平台。
Hadoop是Apache软件基金会开发的一个开源分布式计算框架,它的核心组件包括HDFS(Hadoop Distributed File System)和MapReduce。这两个部分是Hadoop的核心基石,为大数据处理提供了基础架构。这里我们将深入探讨...