
一:根节点<configuration>包含的属性:
scan:
当此属性设置为true时,配置文件如果发生改变,将会被重新加载,默认值为true。
scanPeriod:
设置监测配置文件是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。当scan为true时,此属性生效。默认的时间间隔为1分钟。
debug:
当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。
例如:
- <configuration scan="true" scanPeriod="60 seconds" debug="false">
- <!-- 其他配置省略-->
- </configuration>
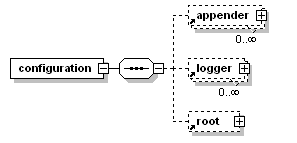
二:根节点<configuration>的子节点:
2.1设置上下文名称:<contextName>
每个logger都关联到logger上下文,默认上下文名称为“default”。但可以使用<contextName>设置成其他名字,用于区分不同应用程序的记录。一旦设置,不能修改。
- <configuration scan="true" scanPeriod="60 seconds" debug="false">
- <contextName>myAppName</contextName>
- <!-- 其他配置省略-->
- </configuration>
2.2设置变量: <property>
用来定义变量值的标签,<property> 有两个属性,name和value;其中name的值是变量的名称,value的值时变量定义的值。通过<property>定义的值会被插 入到logger上下文中。定义变量后,可以使“${}”来使用变量。
例如使用<property>定义上下文名称,然后在<contentName>设置logger上下文时使用。
- <configuration scan="true" scanPeriod="60 seconds" debug="false">
- <property name="APP_Name" value="myAppName" />
- <contextName>${APP_Name}</contextName>
- <!-- 其他配置省略-->
- </configuration>
2.3获取时间戳字符串:<timestamp>
两个属性 key:标识此<timestamp> 的名字;datePattern:设置将当前时间(解析配置文件的时间)转换为字符串的模式,遵循java.txt.SimpleDateFormat的格式。
例如将解析配置文件的时间作为上下文名称:
- <configuration scan="true" scanPeriod="60 seconds" debug="false">
- <timestamp key="bySecond" datePattern="yyyyMMdd'T'HHmmss"/>
- <contextName>${bySecond}</contextName>
- <!-- 其他配置省略-->
- </configuration>
2.4设置loger:
<loger>
用来设置某一个包或者具体的某一个类的日志打印级别、以及指定<appender>。<loger>仅有一个name属性,一个可选的level和一个可选的addtivity属性。
name:
用来指定受此loger约束的某一个包或者具体的某一个类。
level:
用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL 和 OFF,还有一个特俗值INHERITED或者同义词NULL,代表强制执行上级的级别。
如果未设置此属性,那么当前loger将会继承上级的级别。
addtivity:
是否向上级loger传递打印信息。默认是true。
<loger>可以包含零个或多个<appender-ref>元素,标识这个appender将会添加到这个loger。
<root>
也是<loger>元素,但是它是根loger。只有一个level属性,应为已经被命名为"root".
level:
用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL 和 OFF,不能设置为INHERITED或者同义词NULL。
默认是DEBUG。
<root>可以包含零个或多个<appender-ref>元素,标识这个appender将会添加到这个loger。
例如:
LogbackDemo.java类
- package logback;
- import org.slf4j.Logger;
- import org.slf4j.LoggerFactory;
- public class LogbackDemo {
- private static Logger log = LoggerFactory.getLogger(LogbackDemo.class);
- public static void main(String[] args) {
- log.trace("======trace");
- log.debug("======debug");
- log.info("======info");
- log.warn("======warn");
- log.error("======error");
- }
- }
logback.xml配置文件
第1种:只配置root
- <configuration>
- <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
- <!-- encoder 默认配置为PatternLayoutEncoder -->
- <encoder>
- <pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
- </encoder>
- </appender>
- <root level="INFO">
- <appender-ref ref="STDOUT" />
- </root>
- </configuration>
其中appender的配置表示打印到控制台(稍后详细讲解appender );
<root level="INFO">将root的打印级别设置为“INFO”,指定了名字为“STDOUT”的appender。
当执行logback.LogbackDemo类的main方法时,root将级别为“INFO”及大于“INFO”的日志信息交给已经配置好的名为“STDOUT”的appender处理,“STDOUT”appender将信息打印到控制台;
打印结果如下:
- 13:30:38.484 [main] INFO logback.LogbackDemo - ======info
- 13:30:38.500 [main] WARN logback.LogbackDemo - ======warn
- 13:30:38.500 [main] ERROR logback.LogbackDemo - ======error
第2种:带有loger的配置,不指定级别,不指定appender,
- <configuration>
- <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
- <!-- encoder 默认配置为PatternLayoutEncoder -->
- <encoder>
- <pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
- </encoder>
- </appender>
- <!-- logback为java中的包 -->
- <logger name="logback"/>
- <root level="DEBUG">
- <appender-ref ref="STDOUT" />
- </root>
- </configuration>
其中appender的配置表示打印到控制台(稍后详细讲解appender );
<logger name="logback" />将控制logback包下的所有类的日志的打印,但是并没用设置打印级别,所以继承他的上级<root>的日志级别“DEBUG”;
没有设置addtivity,默认为true,将此loger的打印信息向上级传递;
没有设置appender,此loger本身不打印任何信息。
<root level="DEBUG">将root的打印级别设置为“DEBUG”,指定了名字为“STDOUT”的appender。
当执行logback.LogbackDemo类的main方法时,因为LogbackDemo 在包logback中,所以首先执行<logger name="logback" />,将级别为“DEBUG”及大于“DEBUG”的日志信息传递给root,本身并不打印;
root接到下级传递的信息,交给已经配置好的名为“STDOUT”的appender处理,“STDOUT”appender将信息打印到控制台;
打印结果如下:
- 13:19:15.406 [main] DEBUG logback.LogbackDemo - ======debug
- 13:19:15.406 [main] INFO logback.LogbackDemo - ======info
- 13:19:15.406 [main] WARN logback.LogbackDemo - ======warn
- 13:19:15.406 [main] ERROR logback.LogbackDemo - ======error
第3种:带有多个loger的配置,指定级别,指定appender
- <configuration>
- <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
- <!-- encoder 默认配置为PatternLayoutEncoder -->
- <encoder>
- <pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
- </encoder>
- </appender>
- <!-- logback为java中的包 -->
- <logger name="logback"/>
- <!--logback.LogbackDemo:类的全路径 -->
- <logger name="logback.LogbackDemo" level="INFO" additivity="false">
- <appender-ref ref="STDOUT"/>
- </logger>
- <root level="ERROR">
- <appender-ref ref="STDOUT" />
- </root>
- </configuration>
其中appender的配置表示打印到控制台(稍后详细讲解appender );
<logger name="logback" />将控制logback包下的所有类的日志的打印,但是并没用设置打印级别,所以继承他的上级<root>的日志级别“DEBUG”;
没有设置addtivity,默认为true,将此loger的打印信息向上级传递;
没有设置appender,此loger本身不打印任何信息。
<logger name="logback.LogbackDemo" level="INFO" additivity="false">控制logback.LogbackDemo类的日志打印,打印级别为“INFO”;
additivity属性为false,表示此loger的打印信息不再向上级传递,
指定了名字为“STDOUT”的appender。
<root level="DEBUG">将root的打印级别设置为“ERROR”,指定了名字为“STDOUT”的appender。
当执行logback.LogbackDemo类的main方法时,先执行<logger name="logback.LogbackDemo" level="INFO" additivity="false">,将级别为“INFO”及大于“INFO”的日志信息交给此loger指定的名为“STDOUT”的 appender处理,在控制台中打出日志,不再向次loger的上级 <logger name="logback"/> 传递打印信息;
<logger name="logback"/>未接到任何打印信息,当然也不会给它的上级root传递任何打印信息;
打印结果如下:
- 14:05:35.937 [main] INFO logback.LogbackDemo - ======info
- 14:05:35.937 [main] WARN logback.LogbackDemo - ======warn
- 14:05:35.937 [main] ERROR logback.LogbackDemo - ======error
如果将<logger name="logback.LogbackDemo" level="INFO" additivity="false">修改为 <logger name="logback.LogbackDemo" level="INFO" additivity="true">那打印结果将是什么呢?
没错,日志打印了两次,想必大家都知道原因了,因为打印信息向上级传递,logger本身打印一次,root接到后又打印一次
打印结果如下:
- 14:09:01.531 [main] INFO logback.LogbackDemo - ======info
- 14:09:01.531 [main] INFO logback.LogbackDemo - ======info
- 14:09:01.531 [main] WARN logback.LogbackDemo - ======warn
- 14:09:01.531 [main] WARN logback.LogbackDemo - ======warn
- 14:09:01.531 [main] ERROR logback.LogbackDemo - ======error
- 14:09:01.531 [main] ERROR logback.LogbackDemo - ======error



相关推荐
logback 配置详解 logback 是由 log4j 创始人设计的另一个开源日志组件,它当前分为三个模块:logback-core、logback-classic 和 logback-access。logback-classic 是 log4j 的一个改良版本,同时它完整实现了 slf4...
Logback 是一款广泛使用的日志记录框架,它提供高效的日志记录功能,并允许灵活的配置。在本文中,我们将深入探讨 logback 的配置,重点放在配置文件中的关键元素上。 首先,配置文件的根节点是 `<configuration>`...
SpringBoot之LogBack配置详解 LogBack是基于Slf4j的日志框架,默认集成在Spring Boot中。默认情况下,Spring Boot是以INFO级别输出到控制台。LogBack的日志级别是:ALL 。 配置LogBack可以直接在application....
一个基础的`logback-spring.xml`配置文件通常包括以下几个部分: 1. ****:配置文件的根元素。 2. ****:用于读取Spring应用的属性配置,使日志配置更灵活。 3. ****:定义日志输出的目标,如控制台、文件、数据库...
springboot整合logback配置文件
slf4j日志demo项目 logback.xml配置详解,slf4j日志demo项目 logback.xml配置详解,slf4j日志demo项目 logback.xml配置详解,slf4j日志demo项目 logback.xml配置详解
其中包含logback.xml配制详解,所配制的jar包,maven配制,我们项目的配制,里面还包含日志打包等
标题"Logback的使用和logback.xml详解"暗示了我们要讨论的是一个日志管理框架——Logback,以及它的配置文件`logback.xml`。Logback是Java社区广泛使用的日志处理系统,由Ceki Gülcü创建,作为Log4j的后继者。它...
### Logback日志配置详解 #### 一、Logback简介 Logback 是一款非常流行的 Java 日志框架,它由 Ceki Gülcü 开发并维护,作为 log4j 的一个优秀替代品出现。Logback 相对于 log4j 有着更好的性能表现,并且拥有...
一个基本的`logback.xml`配置可能包括以下元素: ```xml <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> <pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n ...
Logback配置文件 Logback的配置主要通过`logback.xml`文件完成,这是一个XML格式的配置文件,用于定义日志级别、日志输出目的地、过滤器等。以下是一份基本的`logback.xml`配置示例: ```xml ...
为了解决这一问题,需要采用logback-spring.xml文件替代logback.xml文件,并利用Spring Boot提供的配置机制,通过在logback-spring.xml中使用${}语法来引用application.yml中定义的属性。这样logback-spring.xml中的...
3.3. 用 logback-test.xml 或 logback.xml 自动配置 ............................................... 19 3.4. 自动打印警告和错误消息 ...........................................................................
这是logback配置的核心,通过它可以定义日志级别(TRACE、DEBUG、INFO、WARN、ERROR、OFF),设置日志输出的目标(控制台、文件、网络等),以及定制日志格式。一个典型的`logback.xml`示例如下: ```xml ...
"Spring如何动态自定义logback日志目录详解" 本文主要介绍了如何在Spring框架中动态自定义logback日志目录的相关知识点。 一、日志输出格式的重要性 在日常开发中,日志输出格式的指定是非常重要的。一般情况下,...
SpringBoot 配置 Logback 日志管理过程详解 本文将详细介绍 SpringBoot 配置 Logback 日志管理过程的知识点,通过示例代码,帮助读者更好地理解Logback日志管理在 SpringBoot 中的应用。 Logback 简介 Logback 是...
Logback配置文件写法详解 Logback是一个流行的Java日志框架,提供了灵活的日志记录和管理功能。配置文件是Logback框架的核心组件,用于定义日志的输出方式、级别、格式等。在本文中,我们将详细介绍Logback配置文件...