
先聊聊业务。我们媒资这边目前的核心数据是乐视视频的乐视meta和专门存储电视剧,综艺节目,体育赛事这种长视频的作品库。乐视视频的数据都是多方审核的,需要很多运营。但是作品库部分却是弱运营的,运营都不超过10个人。结果做了两个app,日活都有四五百万的样子。我们其实都有各样的技术储备,很容易可以抓取人家数据,自己套上一个壳子在线解码。但是我们逼格很高,都不这么做的。乐视是个非常注重版权的公司。我名下都有近百个专利了。
撇开这个项目,先看这边一般web项目的常用JVM配置。
|
1
2
3
4
5
6
|
<jvm-arg>-Xms4g</jvm-arg><jvm-arg>-Xmx4g</jvm-arg><jvm-arg>-Xss1m</jvm-arg><jvm-arg>-Xmn1g</jvm-arg><jvm-arg>-XX:MaxPermSize=128M</jvm-arg><jvm-arg>-XX:MaxTenuringThreshold=3</jvm-arg> |
这个配置resin的服务器业务不是特别复杂的情况下,承载单台QPS4k的并发是不成问题的。下面的图拿来只是觉得我们邹老师画的好看,里面涵盖了很多系统,只要是web server这个配置都是够用的。我们线上机器都是32G24核高配物理机。其实负载都在2点多。就是说用8G4核虚拟机完全够用。但是我们的服务相当重要,运维哥哥那边虚拟化做的不太好,不是很稳定的,线上我们都不这么用。所以,JVM http://www.fhadmin.org/配置基本上多一点少一点点线上效果不是很明显。
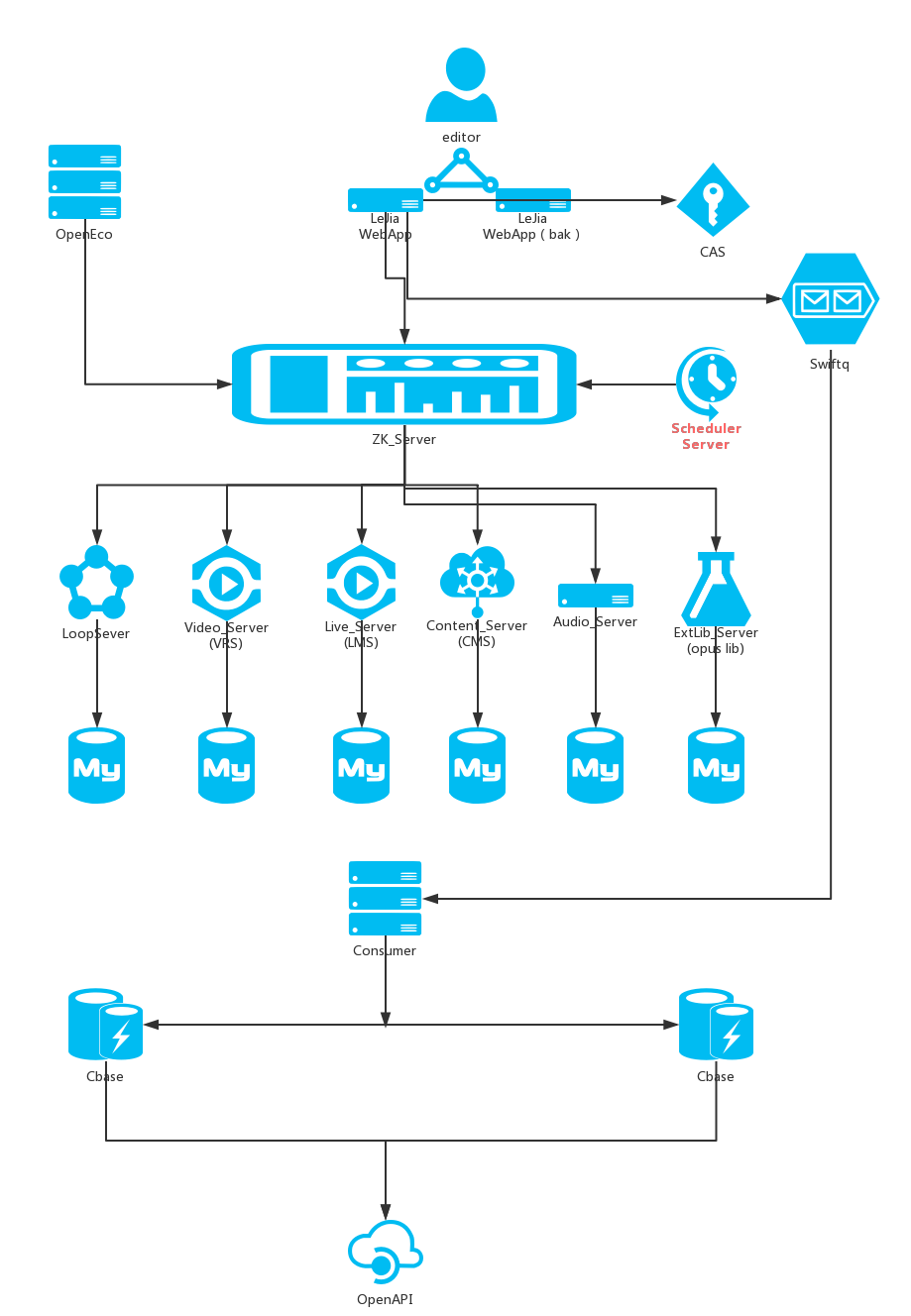
离线数据是推送给乐视视频的搜索部门,乐视视频的日活是千万级。当然搜索哥哥那边也在搞全网搜索,覆盖广,再加上快和准是他们的目标。但是最最基本的视频内容来源是我这边出的。下面图是整体业务架构,下面标的技术是主要的性能消耗点。有些红色的线是我儿子画的,不想这么浪费一张A4纸就当手稿用了 http://www.fhadmin.org/。提倡环保,人人有责。
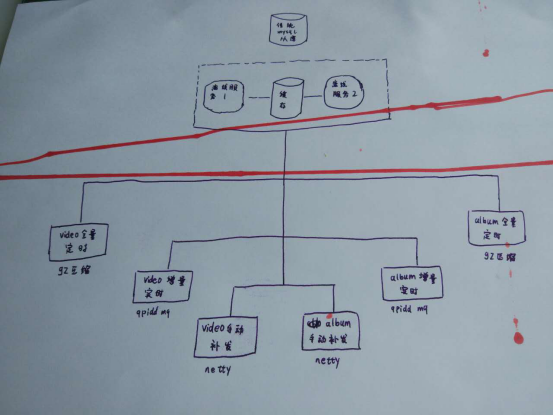
调优之前先说说这个mysql从库。因为这个项目是好多年前就开始做了,依然用的是一主多从的拓扑,binlog复制的集群模式。从库用的是通知模式,除非主库有大的事务操作,时延也就是ms级都还好。写数据QPS也就几十,多加几个从库IO也不会瓶颈。主要问题是主库单点,从库的复制根据分布式系统的CAP理论,保证的是可用性和分区容忍性。一致性级别也就是个最终一致性。上学的时候都学过,单个数据库事务用的是ACID模型,记得当年考试的必考点就是事务的原子性,一致性,隔离性,持久性。我竟然还记得。但是一说集群,特别是如今nosql时代,说的也就只能是BASE理论了。binlog采用的是DML语句复制和一旦发现DML语句无法精确复制时就会采用基于行的复制。记得出现过一次事故, http://www.fhadmin.org/数据库表结构有更新,导致执行语句错误,数据同步停止。
我来公司后新开发的项目都是用的公司的云数据库。这个稍微高级一点,用的是Percona XtraDB Cluster做的集群。它是一个mysql高可用和可扩展的解决方案。可以同步复制,事务要么在所有节点提交或不提交。多主复制,任意节点都可以写操作。缺点,我没测试过,从原理来说,写肯定比传统一主多从慢。因为从弱一致的异步冗余变成了强一致的同步冗余了嘛。而且必须是innodb引擎。我们的所谓云,也就是做了一个去中心化。
离线服务是用了两台机器,用memcached缓存一个更新时间点的时间戳做增量实时的通讯,定时全量和手动补发是一个简单两台服务器热备。
说说缓存集群。memcached集群既然使用的moxi代理,那么它的集群对客户端来说就是透明的,客户端没有办法自己修改其轮询和容灾策略。但是这种代理的有一个好处就是可以管道处理,合并重复的key,一定程度上提高了效率。关于memcached集群,昨天我们大领导找来云存储的大神给我们讲讲视频存储是怎么做的。其中提到了他们那边用的SSDB的集群。和memcached集群是一样的。先说说存储那边的大体逻辑,重新在大脑里膜拜一下大神。发现我儿子有当侦探的潜质,他的涂鸦让我想起福尔摩斯<血字的研究>。
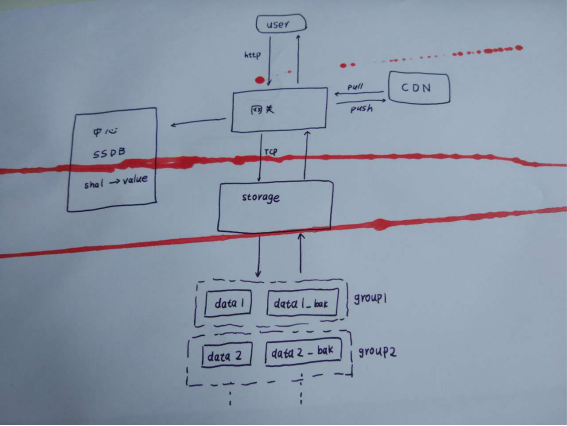
我们部门那边上传视频到云存储,先要进行一个初始化。这个初始化会采用摘要算法计算一下文件的sha1,如果视频已经存在,直接返回状态,这样对于一些用户就可以实现秒传了。但是对于flash因为这个语言要计算其摘要必须将整个文件全都加载到内存,我们是用其他方法来生成sha1的。这个shal传到云存储那边通过SSDB经过二次开发自己实现的一个nosql数据库,这些键值对的nosql数据库查找,如果没初始化过,返回初始化token。这个token里包含了上传到哪个节点等信息。用户上传的介质就可以直接通过网关与存储通信了。存储那边对于每个上产的视频都有主备。一个主备作为一个组。组内自己有个程序做磁盘同步。会有磁盘检查剩余空间。新传视频会在未满的集群中均匀分布。上传完成后一些热点视频会以推送的方法分发到CDN节点上,供CDN加速用。其他视频需要CND自己来拉取。当然CDN那边也有自己的策略。先在边缘节点查找,找不到再来中心节点找,最后没有在来存储这边。
大体流程就是这样。问了下大神哥哥SSDB的集群是怎么做的。他们也是通过代理的。代理上存有vbucket映射表。集群各个节点间本身不通信。需要进行一些哈希计算来找节点的bucket。如果需要添加节点,迁移过程中还是先打到原节点。等迁移完成,映射表更新再往新节点上分发。这样做的好处是避免了rebalance的巨大开销。在人人网的时候,7年前我们的memcached集群出过一次事故。当时我们leader升级了客户端,算法变了,导致全部缓存都不命中。所以这种基于算法和实质上相互关联的集群和gossip的集群不同,对客户端有依赖。
qpidd的MQ集群。问过管理MQ的运维童鞋,为啥选这个。他说activeMq和rabbitMq太轻量,性能不行。Kafka又丢消息,所以才选的这个。不过去公司外面问问,貌似知道的人不多。我们部门要把支付的业务接过来,他们那边是自己搭建了一个kafka的Mq用来集中处理日志的。
netty部分我在前面的文章中很详细的介绍了实战经验,有感兴趣的可以自己找一下。
gz压缩主要是递归操作,如果线程栈开的特别大,压缩过程中CPU上升会特别快,需要注意。



相关推荐
- **深入理解原理**:随着系统规模的扩大,可能会遇到各种复杂的问题,只有深入了解系统的工作原理才能有效定位并解决问题。 - **对待问题的态度**:遇到问题时不应轻易放弃,而是应该深入挖掘其根源,从根本上解决...
大数据中台技术架构是现代企业数字化转型的关键组成部分,它旨在构建一个高效、可扩展的数据处理平台,为企业提供统一的数据服务,支持快速响应业务需求。以下是对该架构的详细概述: 1. 数据采集传输: - Flume ...
Data Mining和HCIA-Big Data三个级别,分别对应开发工程师、解决方案工程师、系统设计、大数据架构师、行业数据建模专家、大数据算法专家、数据挖掘工程师、大数据工程师、产品经理、项目经理、售前工程师、售后技术...
该认证涵盖了大数据技术创新方面,包括大数据行业发展趋势、关键组件原理和架构介绍、华为大数据平台FusionInsight HD、核心组件操作实战、大数据集群综合实验等。 华为大数据认证体系的核心思想是培养大数据专业...
- 该产品采用全托管模式,用户只需关注业务逻辑,无需了解底层计算集群的架构原理。 - 支持通过可视化图形拖拽快速构建实时计算作业,以及可视化页面向导方式创建实时ETL作业。 - 是实现数据资产化的重要工具之一...
- **Hive简介**:Hive提供了一种声明式的数据查询语言HQL,它将SQL语句翻译成MapReduce任务,使得非Java背景的分析师也能轻松操作Hadoop集群上的大数据。 - **Hive与MapReduce的关系**:Hive的数据存储在HDFS上,...
《深入探索Android QQ开发技术》 在移动互联网时代,Android平台上的QQ...通过研究Android QQ,开发者不仅可以学习到实用的技术,还能了解到大型应用的架构设计和优化策略,对于个人技能提升和职业发展具有重要意义。
通过对 Hive 的深入理解和实践,开发者和数据分析师能够更有效地处理大数据,实现复杂的数据分析任务。Hive 的源码阅读可以帮助理解其内部工作原理,提升定制化开发的能力。同时,掌握 Hive 的工具使用,可以提高...
《高性能MySQL》是数据库管理员、开发人员和系统架构师必备的一本经典著作,它深入探讨了MySQL的各个方面,包括性能优化、高可用性、备份、恢复、复制和安全性等。这本书的第三版更是包含了最新的MySQL技术和最佳...
Hadoop是Apache软件基金会开发的一个开源分布式计算框架,它的核心设计思想是...无论是数据分析师、数据科学家还是系统管理员,都需要了解Hadoop的核心原理和最佳实践,以便有效地利用这一强大的工具处理大规模数据。
总的来说,这本书将引导你深入探索大数据的世界,通过学习Hadoop和Spark,你将能够设计和实施高效的大数据解决方案,应对各种规模和复杂性的数据挑战。无论你是数据科学家、工程师还是分析师,掌握这些知识都将极大...
通过学习这份资料,你可以快速了解这些组件的基本工作原理和相互之间的协同作用,为进一步深入学习和应用Hadoop生态系统打下坚实基础。在实际应用中,这些技术通常结合使用,以解决大数据环境下的存储、计算和分析...
4. **Hadoop Common**:包含了Hadoop框架中通用的工具和服务,如网络通信、文件系统操作等,是整个Hadoop生态的基础。 **Hive介绍** 1. **Hive是什么**:Hive是一个基于Hadoop的数据仓库工具,可以将结构化的数据...
再次提到Hive,这里可能更深入地介绍了Hive的架构、工作原理以及与其他Hadoop组件的集成。Hive的主要优势在于其易用性,使得非Java背景的分析师也能对大数据进行分析。但同时,由于依赖于MapReduce,它的实时查询...
6. **接口支持**:Hive提供了多种接口,包括JDBC和ODBC,使得各种BI工具和应用能无缝连接和操作Hive数据。 **Hive的架构与组件** 1. **Hive Metastore**:存储元数据,如表结构、分区信息、列信息等,通常以RDBMS...
标题 "Hadoop Share" 暗示了这是一个关于Hadoop分布式计算框架的分享,可能包含了相关的学习资源或实践经验。在描述中提到了一个博客链接...通过深入理解Hadoop和Hive,开发者和数据分析师能够更好地管理和处理大数据。
**Hive编程指南(书签版)概述...通过深入阅读和实践,数据分析师和开发人员能够更好地利用Hive进行大数据处理,提升工作效率。书签版的便利性使得学习路径更为清晰,让初学者能够更快地掌握Hive的核心概念和实际应用。