
综è؟°
爬虫ه…¥é—¨ن¹‹هگژ,وˆ‘ن»¬وœ‰ن¸¤و،è·¯هڈ¯ن»¥èµ°م€‚
ن¸€ن¸ھوک¯ç»§ç»و·±ه…¥ه¦ن¹ ,ن»¥هڈٹه…³ن؛ژ设è®،و¨،ه¼ڈçڑ„ن¸€ن؛›çں¥è¯†ï¼Œه¼؛هŒ–Python相ه…³çں¥è¯†ï¼Œè‡ھه·±هٹ¨و‰‹é€ è½®هگ,继ç»ن¸؛è‡ھه·±çڑ„爬虫ه¢هٹ هˆ†ه¸ƒه¼ڈ,ه¤ڑç؛؟程ç‰هٹں能و‰©ه±•م€‚هڈ¦ن¸€و،è·¯ن¾؟وک¯ه¦ن¹ ن¸€ن؛›ن¼ک秀çڑ„و،†و¶ï¼Œه…ˆوٹٹè؟™ن؛›و،†و¶ç”¨ç†ں,هڈ¯ن»¥ç،®ن؟能ه¤ںه؛”ن»کن¸€ن؛›هں؛وœ¬çڑ„爬虫ن»»هٹ،,ن¹ںه°±وک¯و‰€è°“çڑ„解ه†³و¸©é¥±é—®é¢ک,然هگژه†چو·±ه…¥ه¦ن¹ ه®ƒçڑ„و؛گç پç‰çں¥è¯†ï¼Œè؟›ن¸€و¥ه¼؛هŒ–م€‚
ه°±ن¸ھن؛؛而言,ه‰چن¸€ç§چو–¹و³•ه…¶ه®ه°±وک¯è‡ھه·±هٹ¨و‰‹é€ è½®هگ,ه‰چن؛؛ه…¶ه®ه·²ç»ڈوœ‰ن؛†ن¸€ن؛›و¯”较ه¥½çڑ„و،†و¶ï¼Œهڈ¯ن»¥ç›´وژ¥و‹؟و¥ç”¨ï¼Œن½†وک¯ن¸؛ن؛†è‡ھه·±èƒ½ه¤ںç ”ç©¶ه¾—و›´هٹ و·±ه…¥ه’Œه¯¹çˆ¬è™«وœ‰و›´ه…¨é¢çڑ„ن؛†è§£ï¼Œè‡ھه·±هٹ¨و‰‹هژ»ه¤ڑهپڑم€‚هگژن¸€ç§چو–¹و³•ه°±وک¯ç›´وژ¥و‹؟و¥ه‰چن؛؛ه·²ç»ڈه†™ه¥½çڑ„و¯”较ن¼ک秀çڑ„و،†و¶ï¼Œو‹؟و¥ç”¨ه¥½ï¼Œé¦–ه…ˆç،®ن؟هڈ¯ن»¥ه®Œوˆگن½ وƒ³è¦په®Œوˆگçڑ„ن»»هٹ،,然هگژè‡ھه·±ه†چو·±ه…¥ç ”究ه¦ن¹ م€‚第ن¸€ç§چ而言,è‡ھه·±وژ¢ç´¢çڑ„ه¤ڑ,ه¯¹çˆ¬è™«çڑ„çں¥è¯†وژŒوڈ،ن¼ڑو¯”较é€ڈه½»م€‚第ن؛Œç§چ,و‹؟هˆ«ن؛؛çڑ„و¥ç”¨ï¼Œè‡ھه·±و–¹ن¾؟ن؛†ï¼Œهڈ¯وک¯هڈ¯èƒ½ه°±ن¼ڑو²،وœ‰ن؛†و·±ه…¥ç ”究و،†و¶çڑ„ه؟ƒوƒ…,è؟کوœ‰هڈ¯èƒ½و€è·¯è¢«وںç¼ڑم€‚
ن¸چè؟‡ن¸ھن؛؛而言,وˆ‘è‡ھه·±هپڈهگ‘هگژ者م€‚é€ è½®هگوک¯ن¸چ错,ن½†وک¯ه°±ç®—ن½ é€ è½®هگ,ن½ è؟™ن¸چن¹ںوک¯هœ¨هں؛ç،€ç±»ه؛“ن¸ٹé€ è½®هگن¹ˆï¼ں能و‹؟و¥ç”¨çڑ„ه°±و‹؟و¥ç”¨ï¼Œه¦ن؛†و،†و¶çڑ„ن½œç”¨وک¯ç،®ن؟è‡ھه·±هڈ¯ن»¥و»،足ن¸€ن؛›çˆ¬è™«éœ€و±‚,è؟™وک¯وœ€هں؛وœ¬çڑ„و¸©é¥±é—®é¢کم€‚ه€کè‹¥ن½ ن¸€ç›´هœ¨é€ è½®هگ,هˆ°وœ€هگژ都و²،é€ ه‡؛ن»€ن¹ˆو¥ï¼Œهˆ«ن؛؛و‰¾ن½ ه†™ن¸ھçˆ¬è™«ç ”ç©¶ن؛†è؟™ن¹ˆé•؟و—¶é—´ن؛†éƒ½ه†™ن¸چه‡؛و¥ï¼Œه²‚ن¸چوک¯وœ‰ç‚¹ه¾—ن¸چهپ؟ه¤±ï¼ںو‰€ن»¥ï¼Œè؟›éک¶çˆ¬è™«وˆ‘è؟کوک¯ه»؛è®®ه¦ن¹ ن¸€ن¸‹و،†و¶ï¼Œن½œن¸؛è‡ھه·±çڑ„ه‡ وٹٹو¦ه™¨م€‚至ه°‘,وˆ‘ن»¬هڈ¯ن»¥هپڑهˆ°ن؛†ï¼Œه°±هƒڈن½ و‹؟ن؛†وٹٹوھن¸ٹوˆکهœ؛ن؛†ï¼Œè‡³ه°‘,ن½ وک¯هڈ¯ن»¥و‰“ه‡»و•Œن؛؛çڑ„,و¯”ن½ ن¸€ç›´هœ¨ç£¨هˆ€ه¥½çڑ„ه¤ڑهگ§ï¼ں
و،†و¶و¦‚è؟°
هچڑن¸»وژ¥è§¦ن؛†ه‡ ن¸ھ爬虫و،†و¶ï¼Œه…¶ن¸و¯”较ه¥½ç”¨çڑ„وک¯ Scrapy ه’ŒPySpiderم€‚ه°±ن¸ھن؛؛而言,pyspiderن¸ٹو‰‹و›´ç®€هچ•ï¼Œو“چن½œو›´هٹ 简ن¾؟,ه› ن¸؛ه®ƒه¢هٹ ن؛† WEB ç•Œé¢ï¼Œه†™çˆ¬è™«è؟…é€ں,集وˆگن؛†phantomjs,هڈ¯ن»¥ç”¨و¥وٹ“هڈ–jsو¸²وں“çڑ„é،µé¢م€‚Scrapyè‡ھه®ڑن¹‰ç¨‹ه؛¦é«ک,و¯” PySpiderو›´ه؛•ه±‚ن¸€ن؛›ï¼Œé€‚هگˆه¦ن¹ ç ”ç©¶ï¼Œéœ€è¦په¦ن¹ çڑ„相ه…³çں¥è¯†ه¤ڑ,ن¸چè؟‡è‡ھه·±و‹؟و¥ç ”究هˆ†ه¸ƒه¼ڈه’Œه¤ڑç؛؟程ç‰ç‰وک¯éه¸¸هگˆé€‚çڑ„م€‚
هœ¨è؟™é‡Œهچڑن¸»ن¼ڑن¸€ن¸€وٹٹè‡ھه·±çڑ„ه¦ن¹ ç»ڈéھŒه†™ه‡؛و¥ن¸ژه¤§ه®¶هˆ†ن؛«ï¼Œه¸Œوœ›ه¤§ه®¶هڈ¯ن»¥ه–œو¬¢ï¼Œن¹ںه¸Œوœ›هڈ¯ن»¥ç»™ه¤§ه®¶ن¸€ن؛›ه¸®هٹ©م€‚
PySpider
PySpiderوک¯binuxهپڑçڑ„ن¸€ن¸ھ爬虫و¶و„çڑ„ه¼€و؛گهŒ–ه®çژ°م€‚ن¸»è¦پçڑ„هٹں能需و±‚وک¯ï¼ڑ
- وٹ“هڈ–م€پو›´و–°è°ƒه؛¦ه¤ڑ站点çڑ„特ه®ڑçڑ„é،µé¢
- 需è¦په¯¹é،µé¢è؟›è،Œç»“و„هŒ–ن؟،وپ¯وڈگهڈ–
- çپµو´»هڈ¯و‰©ه±•ï¼Œç¨³ه®ڑهڈ¯ç›‘وژ§
而è؟™ن¹ںوک¯ç»ه¤§ه¤ڑو•°python爬虫çڑ„需و±‚ —— ه®ڑهگ‘وٹ“هڈ–,结و„هŒ–هŒ–解وگم€‚ن½†وک¯é¢ه¯¹ç»“و„è؟¥ه¼‚çڑ„هگ„ç§چ网站,هچ•ن¸€çڑ„وٹ“هڈ–و¨،ه¼ڈه¹¶ن¸چن¸€ه®ڑ能و»،足,çپµو´»çڑ„وٹ“هڈ–وژ§هˆ¶وک¯ه؟…é،»çڑ„م€‚ن¸؛ن؛†è¾¾هˆ°è؟™ن¸ھç›®çڑ„,هچ•ç؛¯çڑ„é…چç½®و–‡ن»¶ه¾€ه¾€ن¸چه¤ںçپµو´»ï¼Œن؛ژوک¯ï¼Œé€ڑè؟‡è„ڑوœ¬هژ»وژ§هˆ¶وٹ“هڈ–وک¯وœ€هگژçڑ„选و‹©م€‚
而هژ»é‡چè°ƒه؛¦ï¼Œéکںهˆ—,وٹ“هڈ–,ه¼‚ه¸¸ه¤„çگ†ï¼Œç›‘وژ§ç‰هٹں能ن½œن¸؛و،†و¶ï¼Œوڈگن¾›ç»™وٹ“هڈ–è„ڑوœ¬ï¼Œه¹¶ن؟è¯پçپµو´»و€§م€‚وœ€هگژهٹ ن¸ٹwebçڑ„编辑调试çژ¯ه¢ƒï¼Œن»¥هڈٹwebن»»هٹ،监وژ§ï¼Œهچ³وˆگن¸؛ن؛†è؟™ه¥—و،†و¶م€‚
pyspiderçڑ„设è®،هں؛ç،€وک¯ï¼ڑن»¥pythonè„ڑوœ¬é©±هٹ¨çڑ„وٹ“هڈ–çژ¯و¨،ه‹çˆ¬è™«
- é€ڑè؟‡pythonè„ڑوœ¬è؟›è،Œç»“و„هŒ–ن؟،وپ¯çڑ„وڈگهڈ–,follow链وژ¥è°ƒه؛¦وٹ“هڈ–وژ§هˆ¶ï¼Œه®çژ°وœ€ه¤§çڑ„çپµو´»و€§
- é€ڑè؟‡webهŒ–çڑ„è„ڑوœ¬ç¼–ه†™م€پ调试çژ¯ه¢ƒم€‚webه±•çژ°è°ƒه؛¦çٹ¶و€پ
- وٹ“هڈ–çژ¯و¨،ه‹وˆگç†ں稳ه®ڑ,و¨،ه—间相ن؛’独立,é€ڑè؟‡و¶ˆوپ¯éکںهˆ—è؟وژ¥ï¼Œن»ژهچ•è؟›ç¨‹هˆ°ه¤ڑوœ؛هˆ†ه¸ƒه¼ڈçپµو´»و‹“ه±•
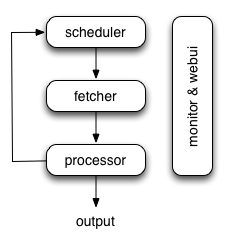
pyspiderçڑ„و¶و„ن¸»è¦پهˆ†ن¸؛ scheduler(调ه؛¦ه™¨ï¼‰, fetcher(وٹ“هڈ–ه™¨ï¼‰, processor(è„ڑوœ¬و‰§è،Œï¼‰ï¼ڑ
- هگ„ن¸ھ组ن»¶é—´ن½؟用و¶ˆوپ¯éکںهˆ—è؟وژ¥ï¼Œé™¤ن؛†schedulerوک¯هچ•ç‚¹çڑ„,fetcher ه’Œ processor 都وک¯هڈ¯ن»¥ه¤ڑه®ن¾‹هˆ†ه¸ƒه¼ڈ部署çڑ„م€‚ scheduler è´ںè´£و•´ن½“çڑ„è°ƒه؛¦وژ§هˆ¶
- ن»»هٹ،ç”± scheduler هڈ‘èµ·è°ƒه؛¦ï¼Œfetcher وٹ“هڈ–网é،µه†…ه®¹ï¼Œ processor و‰§è،Œé¢„ه…ˆç¼–ه†™çڑ„pythonè„ڑوœ¬ï¼Œè¾“ه‡؛结وœوˆ–ن؛§ç”ںو–°çڑ„وڈگ链ن»»هٹ،(هڈ‘ه¾€ scheduler),ه½¢وˆگé—çژ¯م€‚
- و¯ڈن¸ھè„ڑوœ¬هڈ¯ن»¥çپµو´»ن½؟用هگ„ç§چpythonه؛“ه¯¹é،µé¢è؟›è،Œè§£وگ,ن½؟用و،†و¶APIوژ§هˆ¶ن¸‹ن¸€و¥وٹ“هڈ–هٹ¨ن½œï¼Œé€ڑè؟‡è®¾ç½®ه›è°ƒوژ§هˆ¶è§£وگهٹ¨ن½œم€‚
Scrapy
Scrapyوک¯ن¸€ن¸ھن¸؛ن؛†çˆ¬هڈ–网站و•°وچ®ï¼Œوڈگهڈ–结و„و€§و•°وچ®è€Œç¼–ه†™çڑ„ه؛”用و،†و¶م€‚ هڈ¯ن»¥ه؛”用هœ¨هŒ…و‹¬و•°وچ®وŒ–وژک,ن؟،وپ¯ه¤„çگ†وˆ–هکه‚¨هژ†هڈ²و•°وچ®ç‰ن¸€ç³»هˆ—çڑ„程ه؛ڈن¸م€‚
ه…¶وœ€هˆوک¯ن¸؛ن؛†é،µé¢وٹ“هڈ– (و›´ç،®هˆ‡و¥è¯´, 网络وٹ“هڈ– )و‰€è®¾è®،çڑ„, ن¹ںهڈ¯ن»¥ه؛”用هœ¨èژ·هڈ–APIو‰€è؟”ه›çڑ„و•°وچ®(ن¾‹ه¦‚ Amazon Associates Web Services ) وˆ–者é€ڑ用çڑ„网络爬虫م€‚Scrapy用途ه¹؟و³›ï¼Œهڈ¯ن»¥ç”¨ن؛ژو•°وچ®وŒ–وژکم€پ监وµ‹ه’Œè‡ھهٹ¨هŒ–وµ‹è¯•
Scrapy ن½؟用ن؛† Twistedآ ه¼‚و¥ç½‘络ه؛“و¥ه¤„çگ†ç½‘络é€ڑ讯م€‚و•´ن½“و¶و„ه¤§è‡´ه¦‚ن¸‹

Scrapyن¸»è¦پهŒ…و‹¬ن؛†ن»¥ن¸‹ç»„ن»¶ï¼ڑ
- ه¼•و“ژ(Scrapy): 用و¥ه¤„çگ†و•´ن¸ھç³»ç»ںçڑ„و•°وچ®وµپه¤„çگ†, 触هڈ‘ن؛‹هٹ،(و،†و¶و ¸ه؟ƒ)
- è°ƒه؛¦ه™¨(Scheduler): 用و¥وژ¥هڈ—ه¼•و“ژهڈ‘è؟‡و¥çڑ„请و±‚, هژ‹ه…¥éکںهˆ—ن¸, ه¹¶هœ¨ه¼•و“ژه†چو¬،请و±‚çڑ„و—¶ه€™è؟”ه›. هڈ¯ن»¥وƒ³هƒڈوˆگن¸€ن¸ھURL(وٹ“هڈ–网é،µçڑ„网ه€وˆ–者说وک¯é“¾وژ¥ï¼‰çڑ„ن¼که…ˆéکںهˆ—, ç”±ه®ƒو¥ه†³ه®ڑن¸‹ن¸€ن¸ھè¦پوٹ“هڈ–çڑ„网ه€وک¯ن»€ن¹ˆ, هگŒو—¶هژ»é™¤é‡چه¤چçڑ„网ه€
- ن¸‹è½½ه™¨(Downloader): 用ن؛ژن¸‹è½½ç½‘é،µه†…ه®¹, ه¹¶ه°†ç½‘é،µه†…ه®¹è؟”ه›ç»™èœکè››(Scrapyن¸‹è½½ه™¨وک¯ه»؛ç«‹هœ¨twistedè؟™ن¸ھé«کو•ˆçڑ„ه¼‚و¥و¨،ه‹ن¸ٹçڑ„)
- 爬虫(Spiders): 爬虫وک¯ن¸»è¦په¹²و´»çڑ„, 用ن؛ژن»ژ特ه®ڑçڑ„网é،µن¸وڈگهڈ–è‡ھه·±éœ€è¦پçڑ„ن؟،وپ¯, هچ³و‰€è°“çڑ„ه®ن½“(Item)م€‚用وˆ·ن¹ںهڈ¯ن»¥ن»ژن¸وڈگهڈ–ه‡؛链وژ¥,让Scrapy继ç»وٹ“هڈ–ن¸‹ن¸€ن¸ھé،µé¢
- é،¹ç›®ç®،éپ“(Pipeline): è´ںè´£ه¤„çگ†çˆ¬è™«ن»ژ网é،µن¸وٹ½هڈ–çڑ„ه®ن½“,ن¸»è¦پçڑ„هٹں能وک¯وŒپن¹…هŒ–ه®ن½“م€پéھŒè¯په®ن½“çڑ„وœ‰و•ˆو€§م€پو¸…除ن¸چ需è¦پçڑ„ن؟،وپ¯م€‚ه½“é،µé¢è¢«çˆ¬è™«è§£وگهگژ,ه°†è¢«هڈ‘é€پهˆ°é،¹ç›®ç®،éپ“,ه¹¶ç»ڈè؟‡ه‡ ن¸ھ特ه®ڑçڑ„و¬،ه؛ڈه¤„çگ†و•°وچ®م€‚
- ن¸‹è½½ه™¨ن¸é—´ن»¶(Downloader Middlewares): ن½چن؛ژScrapyه¼•و“ژه’Œن¸‹è½½ه™¨ن¹‹é—´çڑ„و،†و¶ï¼Œن¸»è¦پوک¯ه¤„çگ†Scrapyه¼•و“ژن¸ژن¸‹è½½ه™¨ن¹‹é—´çڑ„请و±‚هڈٹه“چه؛”م€‚
- 爬虫ن¸é—´ن»¶(Spider Middlewares): ن»‹ن؛ژScrapyه¼•و“ژه’Œçˆ¬è™«ن¹‹é—´çڑ„و،†و¶ï¼Œن¸»è¦په·¥ن½œوک¯ه¤„çگ†èœکè››çڑ„ه“چه؛”输ه…¥ه’Œè¯·و±‚输ه‡؛م€‚
- è°ƒه؛¦ن¸é—´ن»¶(Scheduler Middewares): ن»‹ن؛ژScrapyه¼•و“ژه’Œè°ƒه؛¦ن¹‹é—´çڑ„ن¸é—´ن»¶ï¼Œن»ژScrapyه¼•و“ژهڈ‘é€پهˆ°è°ƒه؛¦çڑ„请و±‚ه’Œه“چه؛”م€‚
Scrapyè؟گè،Œوµپ程ه¤§و¦‚ه¦‚ن¸‹ï¼ڑ
- 首ه…ˆï¼Œه¼•و“ژن»ژè°ƒه؛¦ه™¨ن¸هڈ–ه‡؛ن¸€ن¸ھ链وژ¥(URL)用ن؛ژوژ¥ن¸‹و¥çڑ„وٹ“هڈ–
- ه¼•و“ژوٹٹURLه°پ装وˆگن¸€ن¸ھ请و±‚(Request)ن¼ ç»™ن¸‹è½½ه™¨ï¼Œن¸‹è½½ه™¨وٹٹ资و؛گن¸‹è½½ن¸‹و¥ï¼Œه¹¶ه°پ装وˆگه؛”ç”هŒ…(Response)
- 然هگژ,爬虫解وگResponse
- è‹¥وک¯è§£وگه‡؛ه®ن½“(Item),هˆ™ن؛¤ç»™ه®ن½“ç®،éپ“è؟›è،Œè؟›ن¸€و¥çڑ„ه¤„çگ†م€‚
- è‹¥وک¯è§£وگه‡؛çڑ„وک¯é“¾وژ¥ï¼ˆURL),هˆ™وٹٹURLن؛¤ç»™Schedulerç‰ه¾…وٹ“هڈ–
结è¯
آ
ه¯¹è؟™ن¸¤ن¸ھو،†و¶è؟›è،Œهں؛وœ¬çڑ„ن»‹ç»چن¹‹هگژ,وژ¥ن¸‹و¥وˆ‘ن¼ڑن»‹ç»چè؟™ن¸¤ن¸ھو،†و¶çڑ„ه®‰è£…ن»¥هڈٹو،†و¶çڑ„ن½؟用و–¹و³•ï¼Œه¸Œوœ›ه¯¹ه¤§ه®¶وœ‰ه¸®هٹ©م€‚



相ه…³وژ¨èچگ
è؟™ن¸ھ程ه؛ڈه±•ç¤؛ن؛†Pythonهœ¨è‡ھهٹ¨هŒ–م€پو•°وچ®هˆ†وگم€پو¸¸وˆڈه¼€هڈ‘ن»¥هڈٹ网络爬虫ç‰ه¤ڑن¸ھ领هںںçڑ„ه؛”用و½œهٹ›م€‚ن¸‹é¢ه°†è¯¦ç»†وژ¢è®¨ç›¸ه…³çں¥è¯†ç‚¹م€‚ 首ه…ˆï¼Œوˆ‘ن»¬è¦پçگ†è§£هڈŒè‰²çگƒه½©ç¥¨çڑ„هں؛وœ¬è§„هˆ™م€‚هڈŒè‰²çگƒه½©ç¥¨ç”±6ن¸ھç؛¢çگƒï¼ˆ1-33ن¸éڑڈوœ؛选و‹©ï¼‰ه’Œ1ن¸ھè“çگƒï¼ˆ1-16...
该هژ‹ç¼©هŒ…و–‡ن»¶â€œç½‘络爬虫-ه¤ڑè؟›ç¨‹çˆ¬هڈ–هœ¨ç؛؟课程ه¹¶هکه…¥MySQLو•°وچ®ه؛“-Pythonو؛گç پç¤؛ن¾‹.zipâ€وڈگن¾›ن؛†ن¸€ن¸ھPythonه®çژ°çڑ„网络爬虫é،¹ç›®ï¼Œو—¨هœ¨é€ڑè؟‡ه¤ڑè؟›ç¨‹وٹ€وœ¯وٹ“هڈ–هœ¨ç؛؟课程ن؟،وپ¯ï¼Œه¹¶ه°†و•°وچ®هکه‚¨هˆ°MySQLو•°وچ®ه؛“ن¸م€‚è؟™ن¸ھé،¹ç›®و¶µç›–ن؛†ن»¥ن¸‹ه‡ ...
وœ¬ن¸»é¢کèپڑ焦ن؛ژه¦‚ن½•هˆ©ç”¨Pythonçڑ„Seleniumو،†و¶و¥ه®çژ°è‡ھهٹ¨هˆ‡وچ¢وµڈ览ه™¨é،µé¢ï¼Œè؟™وک¯ن¸€ن¸ھéه¸¸ه®ç”¨çڑ„وٹ€وœ¯ï¼Œه°¤ه…¶ه¯¹ن؛ژé‚£ن؛›éœ€è¦پو¨،و‹ں用وˆ·ن؛¤ن؛’وˆ–者ه¤„çگ†هٹ¨و€پهٹ è½½ه†…ه®¹çڑ„网站م€‚ Seleniumوک¯ن¸€ن¸ھه¼؛ه¤§çڑ„è‡ھهٹ¨هŒ–وµ‹è¯•ه·¥ه…·ï¼Œه®ƒه…پ许ه¼€هڈ‘者و¨،و‹ں...
و€»çڑ„و¥è¯´ï¼Œè؟™ن¸ھهژ‹ç¼©هŒ…وڈگن¾›ن؛†ن¸€ن¸ھه¦ن¹ ه’Œه®è·µPythonه›¾ه½¢ه¤„çگ†ه’Œهڈ¯è§†هŒ–çڑ„ه¥½وœ؛ن¼ڑ,و¶µç›–ن؛†ن»ژهں؛ç،€هˆ°è؟›éک¶çڑ„ه¤ڑن¸ھه±‚و¬،م€‚و— è®؛وک¯è‡ھهٹ¨هŒ–وٹ¥ه‘ٹçڑ„ه›¾è،¨ç”ںوˆگ,è؟کوک¯و•°وچ®هˆ†وگçڑ„هڈ¯è§†هŒ–ه±•ç¤؛,ç”ڑ至وک¯و¸¸وˆڈه¼€هڈ‘ن¸çڑ„هٹ¨و€په›¾ه½¢ï¼Œéƒ½èƒ½ن»ژè؟™ن؛›و؛گç پ...
هœ¨وœ¬هژ‹ç¼©هŒ…ن¸ï¼Œوˆ‘ن»¬ه…³و³¨çڑ„وک¯ن½؟用Pythonè؟›è،Œç½‘络爬虫وٹ€وœ¯و¥وٹ“هڈ–هœ¨ç؛؟课程ن؟،وپ¯ï¼Œه¹¶ه°†ه…¶و•´çگ†هکه‚¨هˆ°Excelو–‡ن»¶ن¸çڑ„è؟‡ç¨‹م€‚è؟™ن¸ھه®ن¾‹و¶‰هڈٹهˆ°çڑ„ن¸»è¦پçں¥è¯†ç‚¹هŒ…و‹¬ç½‘络爬虫çڑ„هں؛ç،€م€پPython编程م€پ网é،µè§£وگن»¥هڈٹو•°وچ®ه¤„çگ†ه’Œهکه‚¨م€‚ 1. **...
هœ¨Python编程ن¸ï¼Œç½‘络爬虫وک¯ن¸€é،¹é‡چè¦پçڑ„وٹ€èƒ½ï¼Œç”¨ن؛ژè‡ھهٹ¨هŒ–هœ°وٹ“هڈ–ن؛’èپ”网ن¸ٹçڑ„و•°وچ®م€‚وœ¬ه®ن¾‹ن¸»è¦پوژ¢è®¨ه¦‚ن½•هœ¨çˆ¬è™«è؟‡ç¨‹ن¸ه®çژ°ه®و—¶وک¾ç¤؛ن¸‹è½½è؟›ه؛¦ï¼Œه¹¶ن»¥ç™¾هˆ†و¯”çڑ„ه½¢ه¼ڈه±•ç¤؛,è؟™ه¯¹ن؛ژه¤§ه‹و–‡ن»¶ن¸‹è½½وˆ–者ه¤„çگ†ه¤§é‡ڈو•°وچ®و—¶éه¸¸وœ‰ç”¨ï¼Œèƒ½ه¸®هٹ©...
4. **网络爬虫**ï¼ڑن¸؛ن؛†èژ·هڈ–网络ن¸ٹçڑ„ه¤ڑè¯è¨€èµ„و؛گ,软ن»¶هڈ¯èƒ½ن½؟用ن؛†Pythonçڑ„Scrapyم€پBeautifulSoupç‰ç½‘络爬虫و،†و¶م€‚è؟™ن؛›ه·¥ه…·هڈ¯ن»¥وٹ“هڈ–网é،µه†…ه®¹ï¼Œوڈگهڈ–需è¦پç؟»è¯‘çڑ„و–‡وœ¬ï¼Œç”ڑ至ن»ژهœ¨ç؛؟ç؟»è¯‘وœچهٹ،ن¸èژ·هڈ–结وœم€‚ 5. **و¸¸وˆڈه¼€هڈ‘**ï¼ڑ...
"èٹé؛»Python"وک¯ن¸€ن¸ھهڈ¯èƒ½وŒ‡çڑ„وک¯ه…¥é—¨وˆ–هˆç؛§ç؛§هˆ«çڑ„Pythonه¦ن¹ 资و؛گ,هڈ¯èƒ½وک¯وںگن¸ھ课程م€پو•™ç¨‹وˆ–ه¦ن¹ é،¹ç›®çڑ„هگچ称م€‚è؟™ن¸ھ资و؛گهڈ¯èƒ½و—¨هœ¨ه¸®هٹ©هˆه¦è€…ه¼€هگ¯ن»–ن»¬çڑ„Python编程ن¹‹و—…م€‚Pythonوک¯ن¸€ç§چه¹؟و³›ن½؟用çڑ„é«کç؛§ç¼–程è¯è¨€ï¼Œن»¥ه…¶ç®€و´پوکژن؛†çڑ„...
هœ¨è؟›è،Œç½‘络爬虫و—¶ï¼Œوœ‰و—¶ه€™وˆ‘ن»¬éœ€è¦په¤„çگ†ç½‘é،µن¸çڑ„هٹ¨و€پهٹ è½½ه…ƒç´ ,و¯”ه¦‚éھŒè¯پç په›¾ç‰‡م€‚éھŒè¯پç په›¾ç‰‡وک¯ç½‘ç«™ن¸؛ن؛†éک²و¢è‡ھهٹ¨هŒ–è„ڑوœ¬وˆ–وœ؛ه™¨ن؛؛و»¥ç”¨وœچهٹ،...هœ¨و•°وچ®هˆ†وگه’Œè‡ھهٹ¨هŒ–è؟‡ç¨‹ن¸ï¼Œو£ç،®ه¤„çگ†éھŒè¯پç پن¹ںوک¯ç،®ن؟爬虫و£ه¸¸è؟گè،Œçڑ„ه…³é”®و¥éھ¤ن¹‹ن¸€م€‚
هœ¨Python编程è¯è¨€ن¸ï¼Œ"画爱ه؟ƒ"وک¯ن¸€ç§چه¸¸è§پçڑ„ه›¾ه½¢ç»کهˆ¶ç»ƒن¹ ,ه®ƒهڈ¯ن»¥ه¸®هٹ©هˆه¦è€…ç†ںو‚‰Pythonçڑ„ه›¾ه½¢è¾“ه‡؛ه’Œوژ§هˆ¶ç»“و„م€‚è؟™ن¸ھهژ‹ç¼©هŒ…"Pythonو؛گç په®ن¾‹-画爱ه؟ƒ.zip"هŒ…هگ«ن؛†ن¸€ن¸ھه…·ن½“çڑ„Pythonن»£ç پç¤؛ن¾‹ï¼Œç”¨ن؛ژهœ¨ç»ˆç«¯وˆ–ه‘½ن»¤è،Œç•Œé¢ç»کهˆ¶ه‡؛...
Pythonن½œن¸؛网络爬虫çڑ„ه¸¸ç”¨è¯è¨€ï¼Œوڈگن¾›ن؛†ن¸°ه¯Œçڑ„ه؛“ه’Œو–¹و³•و¥ه¸®هٹ©وˆ‘ن»¬ه®Œوˆگè؟™é،¹ن»»هٹ،م€‚ن»¥ن¸‹وک¯ن¸€ن؛›ه…³é”®çں¥è¯†ç‚¹ï¼ڑ 1. **BeautifulSoupه؛“**ï¼ڑ用ن؛ژ解وگHTMLه’ŒXMLو–‡و،£ï¼Œهڈ¯ن»¥و–¹ن¾؟هœ°و‰¾هˆ°ه’Œوڈگهڈ–网é،µن¸çڑ„特ه®ڑه…ƒç´ م€‚ن¾‹ه¦‚,وˆ‘ن»¬هڈ¯ن»¥...
هœ¨ITè،Œن¸ڑن¸ï¼ŒPythonوک¯ن¸€ç§چه¹؟و³›ه؛”用çڑ„编程è¯è¨€ï¼Œه°¤ه…¶هœ¨è‡ھهٹ¨هŒ–م€پو•°وچ®هˆ†وگم€پو¸¸وˆڈه¼€هڈ‘ه’Œç½‘络爬虫ç‰é¢†هںںم€‚وœ¬èµ„و؛گ“程ه؛ڈè‡ھهٹ¨هŒ–-è؟وژ¥MySQLو•°وچ®ه؛“و—¶è‡ھهٹ¨ه¼€هگ¯وœچهٹ،ه™¨-Pythonه®ن¾‹و؛گç پ.zipâ€وڈگن¾›ن؛†ن¸€ن¸ھه…·ن½“çڑ„Pythonن»£ç په®ن¾‹ï¼Œ...
Pythonçڑ„requestsه؛“用ن؛ژهڈ‘é€پHTTP请و±‚,BeautifulSoup解وگHTMLه’ŒXMLو–‡و،£ï¼Œscrapyوک¯ن¸€ن¸ھه¼؛ه¤§çڑ„爬虫و،†و¶ï¼Œهڈ¯ن»¥و„ه»؛ه¤چو‚çڑ„爬虫é،¹ç›®م€‚ 7. **وٹ¥ه‘ٹç”ںوˆگ**ï¼ڑPythonçڑ„reportlabه؛“هڈ¯ن»¥ç”ںوˆگPDFوٹ¥ه‘ٹ,Jinja2و¨،و؟ه¼•و“ژهˆ™ç”¨ن؛ژ...
هœ¨Pythonن¸ه®çژ°ه®ڑو—¶çˆ¬هڈ–网é،µه†…ه®¹وک¯ه¸¸è§پ需و±‚,ه®ƒç»“هگˆن؛†ç½‘络爬虫وٹ€وœ¯ن¸ژن»»هٹ،è°ƒه؛¦وœ؛هˆ¶م€‚وœ¬و–‡ه°†و·±ه…¥وژ¢è®¨ه¦‚ن½•هˆ©ç”¨Pythonè؟›è،Œç½‘络爬虫çڑ„ه¼€هڈ‘,ه¹¶ه®çژ°ه®ڑو—¶ن»»هٹ،م€‚ 首ه…ˆï¼Œوˆ‘ن»¬éœ€è¦پن؛†è§£Pythonن¸çڑ„网络爬虫هں؛ç،€م€‚Pythonوœ‰è®¸ه¤ڑ...
6. **网络爬虫**ï¼ڑ虽然ن¸چه¸¸è§پ,ن½†ه¦‚وœن½ çڑ„è´؛هچ،ه®ن¾‹éœ€è¦پن»ژ网ن¸ٹوٹ“هڈ–特ه®ڑه›¾ç‰‡وˆ–ن؟،وپ¯ï¼ŒPythonçڑ„网络爬虫وٹ€وœ¯ï¼ˆه¦‚BeautifulSoupه’ŒScrapy)ه°±و´¾ن¸ٹ用هœ؛ن؛†م€‚è؟™هڈ¯ن»¥ه®çژ°è‡ھهٹ¨و”¶é›†ç½‘络ن¸ٹçڑ„è´؛هچ،ç´ وگم€‚ 7. **و¸¸وˆڈه¼€هڈ‘**ï¼ڑ虽然...
- وژ¢ç´¢هˆ†ه¸ƒه¼ڈ爬虫,ه¦‚ن½؟用Apache Nutchوˆ–Scrapy(Pythonو،†و¶ï¼‰م€‚ و€»ç»“,"Java网络爬虫(èœکè››)و؛گç پ_zhizhu.zip"وک¯ن¸€ن¸ھ适هگˆهˆه¦è€…ه®è·µه’Œç ”究çڑ„é،¹ç›®ï¼Œé€ڑè؟‡ه®ƒï¼Œن½ هڈ¯ن»¥و·±ه…¥çگ†è§£ç½‘络爬虫çڑ„ه·¥ن½œوµپ程,ه¦ن¹ Java JSPçڑ„ه®وˆک...
هœ¨وœ¬هژ‹ç¼©هŒ…“ه¾®ن؟،ç؛¢هŒ…وڈگ醒-Pythonو؛گç پç¤؛ن¾‹.zipâ€ن¸ï¼Œن¸»è¦پهŒ…هگ«ن؛†ن¸€ن¸ھن½؟用Python编程è¯è¨€ه®çژ°çڑ„ه¾®ن؟،ç؛¢هŒ…è‡ھهٹ¨وڈگ醒çڑ„هٹں能م€‚è؟™ن¸ھهٹں能ه¯¹ن؛ژç»ڈه¸¸هڈ‚ن¸ژه¾®ن؟،ç؛¢هŒ…و´»هٹ¨çڑ„用وˆ·و¥è¯´éه¸¸ه®ç”¨ï¼Œهڈ¯ن»¥éپ؟ه…چé”™è؟‡ن»»ن½•ç؛¢هŒ…وœ؛ن¼ڑم€‚ن»¥ن¸‹وک¯è؟™ن¸ھ...
Pythonçڑ„Webو،†و¶وڈگن¾›ن؛†ه¤„çگ†HTTP请و±‚م€پ路由م€پو¨،ه‹-视ه›¾-وژ§هˆ¶ه™¨ï¼ˆMVC)و¶و„ç‰هٹں能م€‚ 3. **و•°وچ®ه؛“**ï¼ڑهڈ¯èƒ½ن½؟用MySQLم€پPostgreSQLوˆ–SQLiteç‰ه…³ç³»ه‹و•°وچ®ه؛“هکه‚¨ه•†ه“پن؟،وپ¯م€پ订هچ•م€پ用وˆ·و•°وچ®ç‰م€‚ 4. **و”¯ن»کوژ¥هڈ£**ï¼ڑه•†هںژç³»ç»ں...
Pythonن½œن¸؛ن¸€ç§چé«کç؛§ç¼–程è¯è¨€ï¼Œه› ه…¶ç®€و´پوکژن؛†çڑ„è¯و³•ه’Œه¼؛ه¤§çڑ„هٹں能,被ه¹؟و³›ه؛”用ن؛ژهگ„ç§چ领هںں,هŒ…و‹¬è‡ھهٹ¨هŒ–م€پو•°وچ®هˆ†وگم€پ网络爬虫ه’Œو¸¸وˆڈه¼€هڈ‘ç‰م€‚وœ¬é،¹ç›®â€œPythonه®وˆکé،¹ç›®و؛گç پ-ه¦ç”ںن؟،وپ¯ç®،çگ†ç³»ç»ں-هگ«هڈ¯و‰§è،Œو–‡ن»¶â€وک¯ن¸€ن¸ھه…¸ه‹çڑ„...
è؟™ن¸ھه®ن¾‹ن¸»è¦په±•ç¤؛ن؛†Pythonهœ¨è‡ھهٹ¨هŒ–م€پو•°وچ®هˆ†وگم€پ网络爬虫ن»¥هڈٹو¸¸وˆڈه¼€هڈ‘ç‰ه¤ڑن¸ھ领هںںçڑ„ه؛”用و½œهٹ›م€‚让وˆ‘ن»¬و·±ه…¥وژ¢è®¨ن¸€ن¸‹è؟™ن¸ھو—¶é’ں程ه؛ڈ背هگژçڑ„Pythonçں¥è¯†م€‚ 1. **Pythonهں؛ç،€**ï¼ڑPythonوک¯ن¸€ç§چé«کç؛§ç¼–程è¯è¨€ï¼Œن»¥ه…¶ç®€و´پçڑ„è¯و³•ه’Œ...