
Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。
从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,无一不向Hadoop靠拢。Hadoop也从小众的高富帅领域,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通过“大数据”概念不断创新,推出科技进步。
作为IT界的开发人员,我们也要跟上节奏,抓住机遇,跟着Hadoop一起雄起!
![]()
前言
Web日志包含着网站最重要的信息,通过日志分析,我们可以知道网站的访问量,哪个网页访问人数最多,哪个网页最有价值等。一般中型的网站(10W的PV以上),每天会产生1G以上Web日志文件。大型或超大型的网站,可能每小时就会产生10G的数据量。
对于日志的这种规模的数据,用Hadoop进行日志分析,是最适合不过的了。
目录
- Web日志分析概述
- 需求分析:KPI指标设计
- 算法模型:Hadoop并行算法
- 架构设计:日志KPI系统架构
- 程序开发1:用Maven构建Hadoop项目
- 程序开发2:MapReduce程序实现
1. Web日志分析概述
Web日志由Web服务器产生,可能是Nginx, Apache, Tomcat等。从Web日志中,我们可以获取网站每类页面的PV值(PageView,页面访问量)、独立IP数;稍微复杂一些的,可以计算得出用户所检索的关键词排行榜、用户停留时间最高的页面等;更复杂的,构建广告点击模型、分析用户行为特征等等。
在Web日志中,每条日志通常代表着用户的一次访问行为,例如下面就是一条nginx日志:
222.68.172.190 - - [18/Sep/2013:06:49:57 +0000] "GET /images/my.jpg HTTP/1.1" 200 19939
"http://www.angularjs.cn/A00n" "Mozilla/5.0 (Windows NT 6.1)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
拆解为以下8个变量
- remote_addr: 记录客户端的ip地址, 222.68.172.190
- remote_user: 记录客户端用户名称, –
- time_local: 记录访问时间与时区, [18/Sep/2013:06:49:57 +0000]
- request: 记录请求的url与http协议, “GET /images/my.jpg HTTP/1.1″
- status: 记录请求状态,成功是200, 200
- body_bytes_sent: 记录发送给客户端文件主体内容大小, 19939
- http_referer: 用来记录从那个页面链接访问过来的, “http://www.angularjs.cn/A00n”
- http_user_agent: 记录客户浏览器的相关信息, “Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36″
注:要更多的信息,则要用其它手段去获取,通过js代码单独发送请求,使用cookies记录用户的访问信息。
利用这些日志信息,我们可以深入挖掘网站的秘密了。
少量数据的情况
少量数据的情况(10Mb,100Mb,10G),在单机处理尚能忍受的时候,我可以直接利用各种Unix/Linux工具,awk、grep、sort、join等都是日志分析的利器,再配合perl, python,正则表达工,基本就可以解决所有的问题。
例如,我们想从上面提到的nginx日志中得到访问量最高前10个IP,实现很简单:
~ cat access.log.10 | awk '{a[$1]++} END {for(b in a) print b"\t"a[b]}' | sort -k2 -r | head -n 10
163.177.71.12 972
101.226.68.137 972
183.195.232.138 971
50.116.27.194 97
14.17.29.86 96
61.135.216.104 94
61.135.216.105 91
61.186.190.41 9
59.39.192.108 9
220.181.51.212 9
海量数据的情况
当数据量每天以10G、100G增长的时候,单机处理能力已经不能满足需求。我们就需要增加系统的复杂性,用计算机集群,存储阵列来解决。在Hadoop出现之前,海量数据存储,和海量日志分析都是非常困难的。只有少数一些公司,掌握着高效的并行计算,分步式计算,分步式存储的核心技术。
Hadoop的出现,大幅度的降低了海量数据处理的门槛,让小公司甚至是个人都能力,搞定海量数据。并且,Hadoop非常适用于日志分析系统。
2.需求分析:KPI指标设计
下面我们将从一个公司案例出发来全面的解释,如何用进行海量Web日志分析,提取KPI数据。
案例介绍
某电子商务网站,在线团购业务。每日PV数100w,独立IP数5w。用户通常在工作日上午10:00-12:00和下午15:00-18:00访问量最大。日间主要是通过PC端浏览器访问,休息日及夜间通过移动设备访问较多。网站搜索浏量占整个网站的80%,PC用户不足1%的用户会消费,移动用户有5%会消费。
通过简短的描述,我们可以粗略地看出,这家电商网站的经营状况,并认识到愿意消费的用户从哪里来,有哪些潜在的用户可以挖掘,网站是否存在倒闭风险等。
KPI指标设计
- PV(PageView): 页面访问量统计
- IP: 页面独立IP的访问量统计
- Time: 用户每小时PV的统计
- Source: 用户来源域名的统计
- Browser: 用户的访问设备统计
注:商业保密限制,无法提供电商网站的日志。
下面的内容,将以我的个人网站为例提取数据进行分析。
百度统计,对我个人网站做的统计!http://www.fens.me
基本统计指标: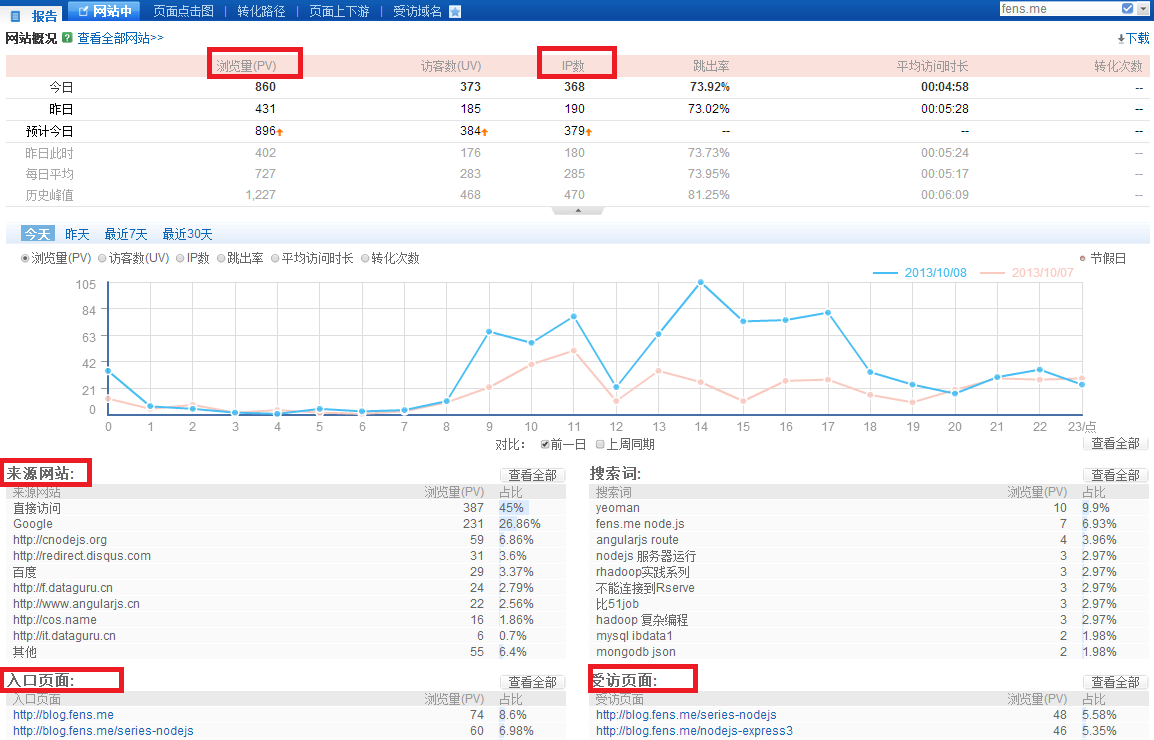
用户的访问设备统计指标: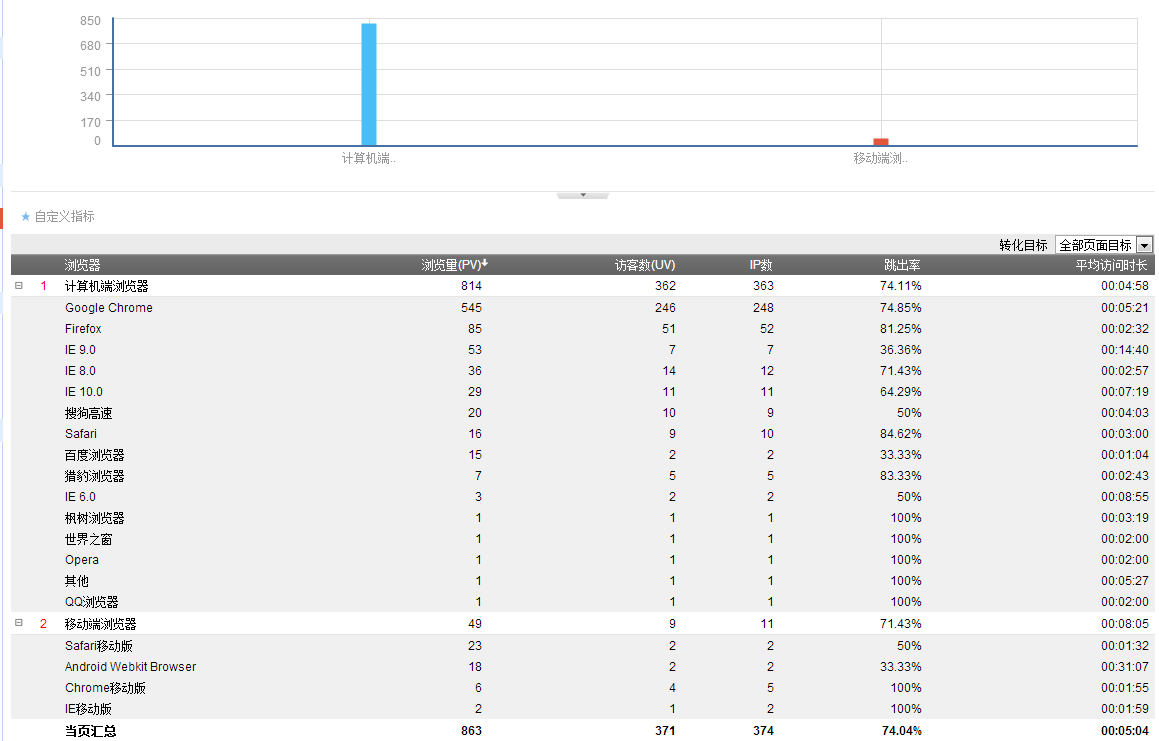
从商业的角度,个人网站的特征与电商网站不太一样,没有转化率,同时跳出率也比较高。从技术的角度,同样都关注KPI指标设计。
3.算法模型:Hadoop并行算法
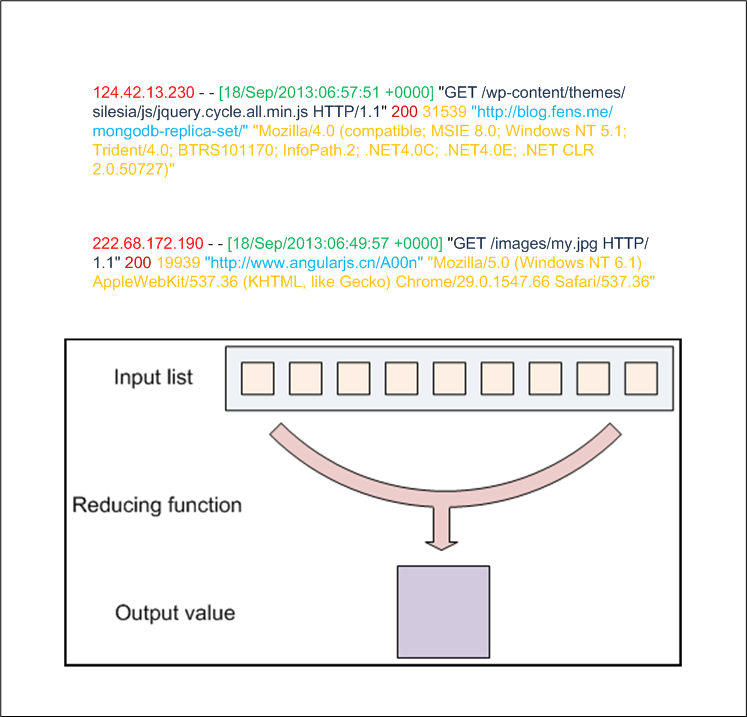
并行算法的设计:
注:找到第一节有定义的8个变量
PV(PageView): 页面访问量统计
- Map过程{key:$request,value:1}
- Reduce过程{key:$request,value:求和(sum)}
IP: 页面独立IP的访问量统计
- Map: {key:$request,value:$remote_addr}
- Reduce: {key:$request,value:去重再求和(sum(unique))}
Time: 用户每小时PV的统计
- Map: {key:$time_local,value:1}
- Reduce: {key:$time_local,value:求和(sum)}
Source: 用户来源域名的统计
- Map: {key:$http_referer,value:1}
- Reduce: {key:$http_referer,value:求和(sum)}
Browser: 用户的访问设备统计
- Map: {key:$http_user_agent,value:1}
- Reduce: {key:$http_user_agent,value:求和(sum)}
4.架构设计:日志KPI系统架构
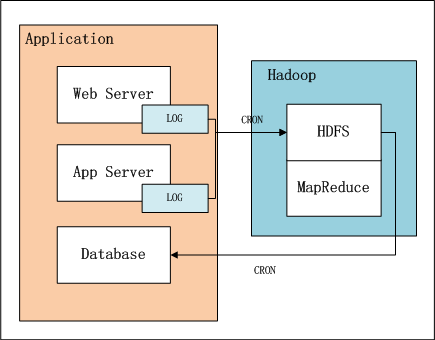
上图中,左边是Application业务系统,右边是Hadoop的HDFS, MapReduce。
- 日志是由业务系统产生的,我们可以设置web服务器每天产生一个新的目录,目录下面会产生多个日志文件,每个日志文件64M。
- 设置系统定时器CRON,夜间在0点后,向HDFS导入昨天的日志文件。
- 完成导入后,设置系统定时器,启动MapReduce程序,提取并计算统计指标。
- 完成计算后,设置系统定时器,从HDFS导出统计指标数据到数据库,方便以后的即使查询。
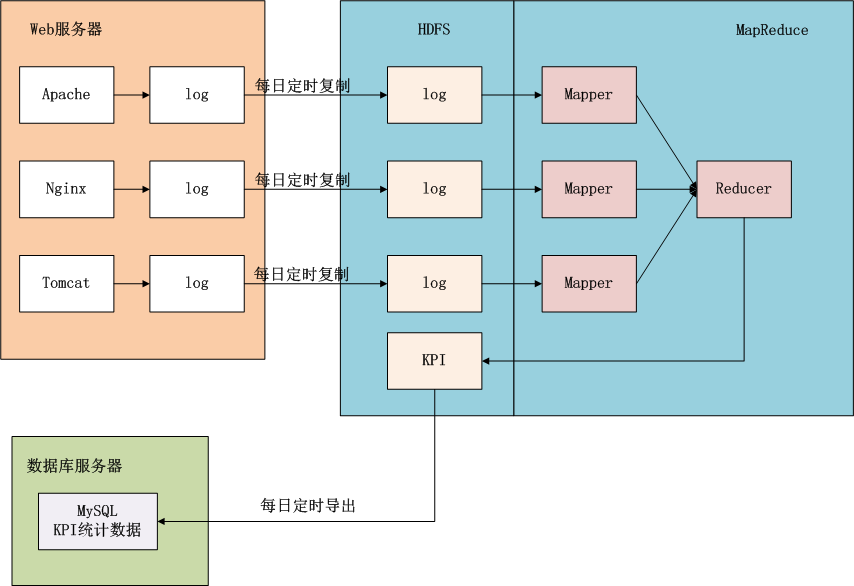
上面这幅图,我们可以看得更清楚,数据是如何流动的。蓝色背景的部分是在Hadoop中的,接下来我们的任务就是完成MapReduce的程序实现。
5.程序开发1:用Maven构建Hadoop项目
请参考文章:用Maven构建Hadoop项目
win7的开发环境 和 Hadoop的运行环境 ,在上面文章中已经介绍过了。
我们需要放日志文件,上传的HDFS里/user/hdfs/log_kpi/目录,参考下面的命令操作
~ hadoop fs -mkdir /user/hdfs/log_kpi
~ hadoop fs -copyFromLocal /home/conan/datafiles/access.log.10 /user/hdfs/log_kpi/
我已经把整个MapReduce的实现都放到了github上面:
https://github.com/bsspirit/maven_hadoop_template/releases/tag/kpi_v16.程序开发2:MapReduce程序实现
开发流程:
- 对日志行的解析
- Map函数实现
- Reduce函数实现
- 启动程序实现
1). 对日志行的解析
新建文件:org.conan.myhadoop.mr.kpi.KPI.java
package org.conan.myhadoop.mr.kpi;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Locale;
/*
* KPI Object
*/
public class KPI {
private String remote_addr;// 记录客户端的ip地址
private String remote_user;// 记录客户端用户名称,忽略属性"-"
private String time_local;// 记录访问时间与时区
private String request;// 记录请求的url与http协议
private String status;// 记录请求状态;成功是200
private String body_bytes_sent;// 记录发送给客户端文件主体内容大小
private String http_referer;// 用来记录从那个页面链接访问过来的
private String http_user_agent;// 记录客户浏览器的相关信息
private boolean valid = true;// 判断数据是否合法
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append("valid:" + this.valid);
sb.append("\nremote_addr:" + this.remote_addr);
sb.append("\nremote_user:" + this.remote_user);
sb.append("\ntime_local:" + this.time_local);
sb.append("\nrequest:" + this.request);
sb.append("\nstatus:" + this.status);
sb.append("\nbody_bytes_sent:" + this.body_bytes_sent);
sb.append("\nhttp_referer:" + this.http_referer);
sb.append("\nhttp_user_agent:" + this.http_user_agent);
return sb.toString();
}
public String getRemote_addr() {
return remote_addr;
}
public void setRemote_addr(String remote_addr) {
this.remote_addr = remote_addr;
}
public String getRemote_user() {
return remote_user;
}
public void setRemote_user(String remote_user) {
this.remote_user = remote_user;
}
public String getTime_local() {
return time_local;
}
public Date getTime_local_Date() throws ParseException {
SimpleDateFormat df = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss", Locale.US);
return df.parse(this.time_local);
}
public String getTime_local_Date_hour() throws ParseException{
SimpleDateFormat df = new SimpleDateFormat("yyyyMMddHH");
return df.format(this.getTime_local_Date());
}
public void setTime_local(String time_local) {
this.time_local = time_local;
}
public String getRequest() {
return request;
}
public void setRequest(String request) {
this.request = request;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public String getBody_bytes_sent() {
return body_bytes_sent;
}
public void setBody_bytes_sent(String body_bytes_sent) {
this.body_bytes_sent = body_bytes_sent;
}
public String getHttp_referer() {
return http_referer;
}
public String getHttp_referer_domain(){
if(http_referer.length()<8){
return http_referer;
}
String str=this.http_referer.replace("\"", "").replace("http://", "").replace("https://", "");
return str.indexOf("/")>0?str.substring(0, str.indexOf("/")):str;
}
public void setHttp_referer(String http_referer) {
this.http_referer = http_referer;
}
public String getHttp_user_agent() {
return http_user_agent;
}
public void setHttp_user_agent(String http_user_agent) {
this.http_user_agent = http_user_agent;
}
public boolean isValid() {
return valid;
}
public void setValid(boolean valid) {
this.valid = valid;
}
public static void main(String args[]) {
String line = "222.68.172.190 - - [18/Sep/2013:06:49:57 +0000] \"GET /images/my.jpg HTTP/1.1\" 200 19939 \"http://www.angularjs.cn/A00n\" \"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36\"";
System.out.println(line);
KPI kpi = new KPI();
String[] arr = line.split(" ");
kpi.setRemote_addr(arr[0]);
kpi.setRemote_user(arr[1]);
kpi.setTime_local(arr[3].substring(1));
kpi.setRequest(arr[6]);
kpi.setStatus(arr[8]);
kpi.setBody_bytes_sent(arr[9]);
kpi.setHttp_referer(arr[10]);
kpi.setHttp_user_agent(arr[11] + " " + arr[12]);
System.out.println(kpi);
try {
SimpleDateFormat df = new SimpleDateFormat("yyyy.MM.dd:HH:mm:ss", Locale.US);
System.out.println(df.format(kpi.getTime_local_Date()));
System.out.println(kpi.getTime_local_Date_hour());
System.out.println(kpi.getHttp_referer_domain());
} catch (ParseException e) {
e.printStackTrace();
}
}
}
从日志文件中,取一行通过main函数写一个简单的解析测试。
控制台输出:
222.68.172.190 - - [18/Sep/2013:06:49:57 +0000] "GET /images/my.jpg HTTP/1.1" 200 19939 "http://www.angularjs.cn/A00n" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
valid:true
remote_addr:222.68.172.190
remote_user:-
time_local:18/Sep/2013:06:49:57
request:/images/my.jpg
status:200
body_bytes_sent:19939
http_referer:"http://www.angularjs.cn/A00n"
http_user_agent:"Mozilla/5.0 (Windows
2013.09.18:06:49:57
2013091806
www.angularjs.cn
我们看到日志行,被正确的解析成了kpi对象的属性。我们把解析过程,单独封装成一个方法。
private static KPI parser(String line) {
System.out.println(line);
KPI kpi = new KPI();
String[] arr = line.split(" ");
if (arr.length > 11) {
kpi.setRemote_addr(arr[0]);
kpi.setRemote_user(arr[1]);
kpi.setTime_local(arr[3].substring(1));
kpi.setRequest(arr[6]);
kpi.setStatus(arr[8]);
kpi.setBody_bytes_sent(arr[9]);
kpi.setHttp_referer(arr[10]);
if (arr.length > 12) {
kpi.setHttp_user_agent(arr[11] + " " + arr[12]);
} else {
kpi.setHttp_user_agent(arr[11]);
}
if (Integer.parseInt(kpi.getStatus()) >= 400) {// 大于400,HTTP错误
kpi.setValid(false);
}
} else {
kpi.setValid(false);
}
return kpi;
}
对map方法,reduce方法,启动方法,我们单独写一个类来实现
下面将分别介绍MapReduce的实现类:
- PV:org.conan.myhadoop.mr.kpi.KPIPV.java
- IP: org.conan.myhadoop.mr.kpi.KPIIP.java
- Time: org.conan.myhadoop.mr.kpi.KPITime.java
- Browser: org.conan.myhadoop.mr.kpi.KPIBrowser.java
1). PV:org.conan.myhadoop.mr.kpi.KPIPV.java
package org.conan.myhadoop.mr.kpi;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class KPIPV {
public static class KPIPVMapper extends MapReduceBase implements Mapper<object, text,="" intwritable="" style="margin: 0pt; padding: 0pt;"> {
private IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, OutputCollector<text, intwritable="" style="margin: 0pt; padding: 0pt;"> output, Reporter reporter) throws IOException {
KPI kpi = KPI.filterPVs(value.toString());
if (kpi.isValid()) {
word.set(kpi.getRequest());
output.collect(word, one);
}
}
}
public static class KPIPVReducer extends MapReduceBase implements Reducer<text, intwritable,="" text,="" intwritable="" style="margin: 0pt; padding: 0pt;"> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterator values, OutputCollector<text, intwritable="" style="margin: 0pt; padding: 0pt;"> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
result.set(sum);
output.collect(key, result);
}
}
public static void main(String[] args) throws Exception {
String input = "hdfs://192.168.1.210:9000/user/hdfs/log_kpi/";
String output = "hdfs://192.168.1.210:9000/user/hdfs/log_kpi/pv";
JobConf conf = new JobConf(KPIPV.class);
conf.setJobName("KPIPV");
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
conf.setMapOutputKeyClass(Text.class);
conf.setMapOutputValueClass(IntWritable.class);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(KPIPVMapper.class);
conf.setCombinerClass(KPIPVReducer.class);
conf.setReducerClass(KPIPVReducer.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input));
FileOutputFormat.setOutputPath(conf, new Path(output));
JobClient.runJob(conf);
System.exit(0);
}
}
在程序中会调用KPI类的方法
KPI kpi = KPI.filterPVs(value.toString());通过filterPVs方法,我们可以实现对PV,更多的控制。
在KPK.java中,增加filterPVs方法
/**
* 按page的pv分类
*/
public static KPI filterPVs(String line) {
KPI kpi = parser(line);
Set pages = new HashSet();
pages.add("/about");
pages.add("/black-ip-list/");
pages.add("/cassandra-clustor/");
pages.add("/finance-rhive-repurchase/");
pages.add("/hadoop-family-roadmap/");
pages.add("/hadoop-hive-intro/");
pages.add("/hadoop-zookeeper-intro/");
pages.add("/hadoop-mahout-roadmap/");
if (!pages.contains(kpi.getRequest())) {
kpi.setValid(false);
}
return kpi;
}
在filterPVs方法,我们定义了一个pages的过滤,就是只对这个页面进行PV统计。
我们运行一下KPIPV.java
2013-10-9 11:53:28 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-9 11:53:28 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-9 11:53:28 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commiting
2013-10-9 11:53:30 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: hdfs://192.168.1.210:9000/user/hdfs/log_kpi/access.log.10:0+3025757
2013-10-9 11:53:30 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: hdfs://192.168.1.210:9000/user/hdfs/log_kpi/access.log.10:0+3025757
2013-10-9 11:53:30 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_m_000000_0' done.
2013-10-9 11:53:30 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-9 11:53:30 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-9 11:53:30 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-9 11:53:30 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 213 bytes
2013-10-9 11:53:30 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-9 11:53:30 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_r_000000_0 is done. And is in the process of commiting
2013-10-9 11:53:30 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-9 11:53:30 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0001_r_000000_0 is allowed to commit now
2013-10-9 11:53:30 org.apache.hadoop.mapred.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0001_r_000000_0' to hdfs://192.168.1.210:9000/user/hdfs/log_kpi/pv
2013-10-9 11:53:31 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 0%
2013-10-9 11:53:33 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-9 11:53:33 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_r_000000_0' done.
2013-10-9 11:53:34 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-9 11:53:34 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0001
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: Counters: 20
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=3025757
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=183
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=545
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=6051514
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=83472
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=183
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=217
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: Map input records=14619
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=16
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=2004
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=376569856
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: Map input bytes=3025757
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=110
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: Combine input records=76
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=8
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=8
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: Combine output records=8
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=8
2013-10-9 11:53:34 org.apache.hadoop.mapred.Counters log
信息: Map output records=76
用hadoop命令查看HDFS文件
~ hadoop fs -cat /user/hdfs/log_kpi/pv/part-00000
/about 5
/black-ip-list/ 2
/cassandra-clustor/ 3
/finance-rhive-repurchase/ 13
/hadoop-family-roadmap/ 13
/hadoop-hive-intro/ 14
/hadoop-mahout-roadmap/ 20
/hadoop-zookeeper-intro/ 6
这样我们就得到了,刚刚日志文件中的,指定页面的PV值。
指定页面,就像网站的站点地图一样,如果没有指定所有访问链接都会被找出来,通过“站点地图”的指定,我们可以更容易地找到,我们所需要的信息。
后面,其他的统计指标的提取思路,和PV的实现过程都是类似的,大家可以直接下载源代码,运行看到结果!!



相关推荐
总结,基于Hadoop的Web日志分析是一个复杂而重要的过程,涵盖了数据预处理、统计分析、结果导出和数据可视化等多个环节。通过对这些知识点的深入理解和应用,可以有效地利用Web日志数据,提升网站运营效率和用户体验...
针对传统分布式模型在海量日志并行处理时的可扩展性和并行程序编写困难的问题, 提出了基于Hive的Web海量搜索日志分析机制。利用HQL语言以及Hadoop分布式文件系统(HDFS)和MapReduce编程模式对海量搜索日志进行分析...
在设计基于Hadoop/Hive的Web日志分析系统中,首先要明确系统的目标和需求,即高效地存储、管理和分析Web日志数据。这涉及到如何采集和清洗原始Web日志数据,如何建立适合于分析的数据模型,以及如何高效执行分析查询...
基于Hadoop的Web日志挖掘是指使用Hadoop大数据处理技术对Web日志进行挖掘和分析的过程。Web日志挖掘是指从Web日志中提取有价值的信息,以便更好地了解用户行为、优化网站性能和改进网站设计。 在基于Hadoop的Web...
基于Hadoop网站流量日志数据分析系统 1、典型的离线流数据分析系统 2、技术分析 - Hadoop - nginx - flume - hive - mysql - springboot + mybatisplus+vcharts nginx + lua 日志文件埋点的 基于Hadoop网站流量...
标题中的“Hadoop网站KPI使用数据”表明这是一个与Hadoop相关的项目,主要涉及的是对网站性能关键指标(KPIs)的监控和分析。在大数据处理领域,Hadoop是一个开源框架,它允许分布式存储和处理大规模数据集。在这个...
2. **日志分析**:收集和分析Hadoop的日志文件,从中提取KPI信息。 3. **第三方工具**:例如Cloudera Manager、Ambari等,提供更丰富的监控和告警功能。 4. **自定义脚本**:编写脚本定期收集和汇总KPI,结合可视化...
为了验证基于Hadoop的Web日志挖掘平台的有效性和效率,研究者们在Hadoop集群上进行了实验,使用改进后的混合算法对大量的Web日志文件进行了处理。实验结果表明,相比于传统单一节点的数据挖掘系统,基于Hadoop的Web...
至此,我们通过Python网络爬虫手段进行数据抓取,将我们网站数据(2013-05-30,2013-05-31)保存为两个日志文件,由于文件大小超出我们一般的分析工具处理的范围,故借助Hadoop来完成本次的实践。 使用python对原始...
基于Hadoop的Web日志分析项目源码(日志的清洗、统计分析、统计结果的导出、指标数据的Web展示)+项目说明.zip 包含如下 【主要分析统计的指标数据】 浏览量PV 访客数UV IP数 跳出率 【系统架构设计】 【数据库表结构...
基于Hadoop网站流量日志数据分析系统项目源码+教程.zip网站流量日志数据分析系统 典型的离线流数据分析系统 技术分析 hadoop nginx flume hive sqoop mysql springboot+mybatisplus+vcharts 基于Hadoop网站流量日志...
总结来说,这个项目展示了Hadoop在大数据处理中的核心作用,即通过分布式计算处理海量日志数据,利用MapReduce进行数据清洗和转换,再结合Hive和MySQL进行数据存储和分析。这一实践过程对于理解和掌握大数据处理流程...
总结来说,基于Hadoop的Web日志分析是利用大数据技术解决实际问题的典型应用,它能够帮助我们从海量的Web日志数据中挖掘有价值的信息,为企业决策提供数据支持。通过不断学习和实践,我们可以更好地掌握Hadoop及相关...
"基于Hadoop的Web日志分析项目源码"是一个使用Apache Hadoop框架进行Web服务器日志分析的软件项目。Hadoop是大数据处理领域的核心工具,以其分布式计算能力和高容错性而闻名,常用于海量数据的存储和处理。 【描述...
本项目“大数据——基于Hadoop的网站日志分析系统(附带Web展示页面)”聚焦于利用Hadoop生态工具对网站日志进行深度挖掘,并通过Web界面展示分析结果。以下是该项目涉及的关键技术点: 1. **Hadoop**:Hadoop是...
在本课程设计中,学生将通过 Hadoop 平台,利用 MapReduce 编程统计《哈姆雷特》的词频,即计算每个词汇出现的次数。这个任务展示了 MapReduce 在文本分析和数据挖掘中的应用。在 map 阶段,每个单词被提取并计数,...
### 基于Hadoop的日志统计分析系统的设计与实现 #### 概述 随着互联网技术的迅猛发展,各类应用程序和服务所产生的日志数据量日益增长。这些数据包含了丰富的信息,对于理解用户行为、优化系统性能以及提升服务...
在IT行业中,Hadoop是一个广泛使用的开源框架,主要用于大数据处理和分析。它的核心特性包括分布式存储(HDFS)和分布式计算(MapReduce),这使得它能够处理和存储PB级别的数据。本篇将深入探讨如何利用Hadoop按...
在这一部分,读者将学习如何利用Hadoop进行日志分析、数据分析、机器学习等操作,掌握数据仓库的概念以及如何构建大数据仓库,同时会探讨Hadoop生态系统中其他重要组件如Hive、Pig、Sqoop和Flume的使用方法。...
总的来说,大数据Hadoop MapReduce词频统计是大数据分析的重要应用之一,它揭示了文本数据的内在结构,为文本挖掘、信息检索等应用提供了基础。通过理解和掌握这一技术,开发者可以更好地应对现代数据驱动决策的需求...