王斌讲过,基于 Server 的请求回放领域,一般分为离线回放和在线实时复制两种。
¬Ý
如果从应用层面进行复制,比如基于服务器的请求复制,实现起来相对简单,但也存在着若干缺点:
1ÔºâËØ∑ʱǧçÂà∂‰ªéÂ∫îÁî®Â±ÇÂá∫ÂèëÔºåÁ©øÈÄèÊ雷∏™ÂçèËÆÆÊÝàÔºåËøôÊÝ∑Â∞±ÂÆπÊòìÊå§ÂçÝÂ∫îÁî®ÁöÑ˵ÑÊ∫êÔºåÊØî¶ÇÂÆùË¥µÁöÑËøûÊé•ËµÑÊ∫ê Ôºå
2)测试跟实际应用耦合在一起,容易影响在线系统,
3Ôºâ‰πüÂõÝÊ≠§ÂæàÈöæÊîØÊíëÂéãÂäõ§ßÁöÑËØ∑ʱǧçÂà∂Ôºå
4)很难控制网络延迟。
ËÄåÂü∫‰∫éÂ∫ï±ÇÊï∞ÊçÆÂåÖÁöÑËØ∑ʱǧçÂà∂ÔºåÂè؉ª•ÂÅöÂà∞ÊóÝÈúÄÁ©øÈÄèÊ雷∏™ÂçèËÆÆÊÝàÔºåË∑ØÁ®ãÊúÄÁü≠ÁöÑÔºåÂè؉ª•‰ªéÊï∞ÊçÆÈìæË∑رÇÊäìËØ∑ʱÇÂåÖԺ剪éÊï∞ÊçÆÈìæË∑رÇÂèëÂåÖÔºåË∑ØÁ®ã‰∏ÄËà¨ÁöÑÔºåÂè؉ª•Âú®IP±ÇÊäìËØ∑ʱÇÂåÖԺ剪éIP±ÇÂèëÂá∫ÂéªÔºå‰∏çÁÆ°ÊÄé‰πà˵∞ÔºåÂè™Ë¶Å‰∏ç˵∞TCPÔºåÂØπÂú®Á∫øÁöÑÂΩ±ÂìçÂ∞±‰ºöÂ∞èÂæó§ö„ÄÇËøô‰πüÂ∞±ÊòØ TCPCopy ÁöÑÂü∫Êú¨ÊÄùË∑Ø„ÄÇ
¬Ý
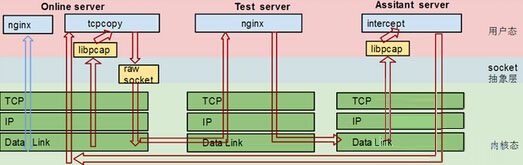
‰ªé‰ºÝÁªüÊû∂ÊûÑÁöÑ rawsocket+iptable+netlinkÔºåÂà∞Êñ∞Êû∂ÊûÑÁöÑ pacp+routeÔºåÂÆÉÁªèÂé܉∫܉∏âʨ°Êû∂ÊûÑË∞ÉÊï¥ÔºåÁé∞¶ljªäÁöÑ TCPCopy Âà܉∏∫‰∏â‰∏™ËßíËâ≤Ôºö
- Online Server(OS):上面要部署 TCPCopy,从数据链路层(pcap 接口)抓请求数据包,发包是从IP层发出去;
- Test Server(TS):最新的架构调整把 intercept 的工作从 TS 中 offload 出来。TS 设置路由信息,把 被测应用 的需要被捕获的响应数据包信息路由到 AS;
- Assistant Server(AS):这是一台独立的辅助服务器,原则上一定要用同网段的一台闲置服务器来充当辅助服务器。AS 在数据链路层截获到响应包,从中抽取出有用的信息,再返回给相应的 OS 上的 tcpcopy 进程。
¬Ý
请配合下图1理解:
图1 三个角色的数据流转方式
¬Ý
Online Server 上的抓包:
tcpcopy ÁöÑÊñ∞Êû∂ÊûÑÂú® OS ‰∏äÊäìËØ∑ʱÇÊï∞ÊçÆÂåÖȪòËƧÈááÁî® raw socket input Êé•Âè£ÊäìÂåÖ„ÄÇÁéãÊñåÂàôÊé®ËçêÈááÁî® pcap ÊäìÂåÖÔºåÂÆâË£ÖÂëΩ‰ª§Â¶Ç‰∏ãÔºö¬Ý
./configure --enable-advanced --enable-pcap
„ÄÄ„ÄÄmake
„ÄÄ„ÄÄmake install
ËøôÊÝ∑Â∞±Âè؉ª•Âú®ÂÜÖÊÝ∏ÊÄÅËøõË°åËøáʪ§ÔºåÂê¶ÂàôÂè™ËÉΩÂú®Áî®Êà∑ÊÄÅËøõË°åÂåÖÁöÑËøáʪ§ÔºåËÄå‰∏îÂú® intercept Á´ØÊàñËÄÖ tcpcopy Á´ØËÆæÁΩÆ filterÔºàÈÄöËøá -F ÂèÇÊï∞ÔºåÁ±ª‰ºº tcpdump ÁöÑ filterÔºâÔºåËææÂà∞˵∑§ö‰∏™ÂÆû‰æãÊù•ÂÖ±ÂêåÂÆåÊàêÊäìÂåÖÁöÑÂ∑•‰ΩúÔºåËøôÊÝ∑ÂèØÊâ©Â±ïÊÄßÂ∞±Êõ¥Âº∫ÔºåÈÄÇÂêà‰∫éË∂ÖÁ∫ßÈ´òÂπ∂ÂèëÁöÑÂú∫Âêà„ÄÇ
为了便于理解 pcap 抓包,下面简单描述一下 libpcap 的工作原理。
一个包的捕捉分为三个主要部分:
- 面向底层包捕获,
- 面向中间层的数据包过滤,
- 面向应用层的用户接口。
¬Ý
Ëøô‰∏é Linux Êìç‰ΩúÁ≥ªÁªüÂØπÊï∞ÊçÆÂåÖÁöѧÑÁêÜʵÅÁ®ãÊòØÁõ∏ÂêåÁöÑÔºàÁΩëÂç°->ÁΩëÂç°È©±Âä®->Êï∞ÊçÆÈìæË∑رÇ->IP±Ç->‰ºÝËæì±Ç->Â∫îÁî®Á®ãÂ∫èÔºâ„ÄÇÂåÖÊçïËé∑Êú∫Âà∂ÊòØÂú®Êï∞ÊçÆÈìæË∑رǢûÂä݉∏ĉ∏™ÊóÅË∑اÑÁêÜÔºàÂπ∂‰∏çÂπ≤Êâ∞Á≥ªÁªüËá™Ë∫´ÁöÑÁΩëÁªúÂçèËÆÆÊÝàÁöѧÑÁêÜÔºâÔºåÂØπÂèëÈÄÅÂíåÊé•Êî∂ÁöÑÊï∞ÊçÆÂåÖÈÄöËøáLinuxÂÜÖÊÝ∏ÂÅöËøáʪ§ÂíåÁºìÂÜ≤§ÑÁêÜÔºåÊúÄÂêéÁõ¥Ê镉ºÝÈÄíÁªô‰∏ä±ÇÂ∫îÁî®Á®ãÂ∫è„ÄǶlj∏ãÂõæ2ÊâÄÁ§∫Ôºö
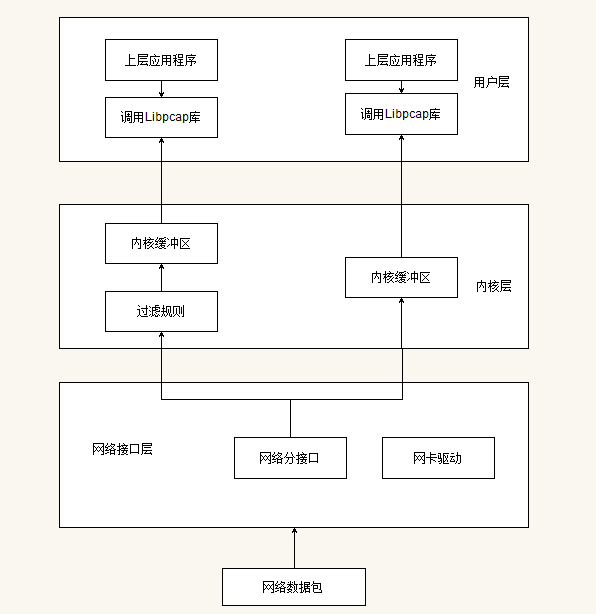
图2 libpcap的三部分
¬Ý
Online Server 上的发包:
¶ÇÂõæ1ÊâÄÁ§∫ÔºåÊñ∞Êû∂ÊûÑÂí剺ÝÁªüÊû∂Êûщ∏ÄÊÝ∑ÔºåOS ȪòËƧ‰ΩøÁî® raw socket output Êé•Âè£ÂèëÂåÖÔºåÊ≠§Êó∂ÂèëÂåÖÂëΩ‰ª§Â¶Ç‰∏ãÔºö¬Ý
./tcpcopy -x 80-测试机IP:测试机应用端口 -s 服务器IP -i eth0
其中 -i 参数指定 pcap 从哪个网卡抓取请求包。
Ê≠§Â§ñÔºåÊñ∞Êû∂ÊûÑËøòÊîØÊåÅÈÄöËøá pcap_injectÔºàÁºñËØëÊó∂ÂÄô¢ûÂäÝ--enable-dlinjectÔºâÊù•ÂèëÂåÖ„ÄÇ
¬Ý
Test Server 上的响应包路由:
ÈúÄ˶ÅÂú® Test Server ‰∏äÊ∑ªÂäÝÈùôÊÄÅË∑ØÁî±ÔºåÁ°Æ‰øùË¢´ÊµãËØïÂ∫îÁî®Á®ãÂ∫èÁöÑÂìçÂ∫îÂåÖË∑ØÁî±Âà∞ËæÖÂä©ÊµãËØïÊúçÂä°Âô®ÔºåËÄå‰∏çÊòØÂõûÂåÖÁªô Online Server„ÄÇ
¬Ý
Assistant Server 上的捕获响应包:
辅助服务器要确保没有开启路由模式 cat /proc/sys/net/ipv4/ip_forward,为0表示没有开启。
辅助服务器上的 intercept 进程通过 pcap 抓取测试机应用程序的响应包,将头部抽取后发送给 Online Server 上的 tcpcopy 进程,从而完成一次请求的复制。
¬Ý
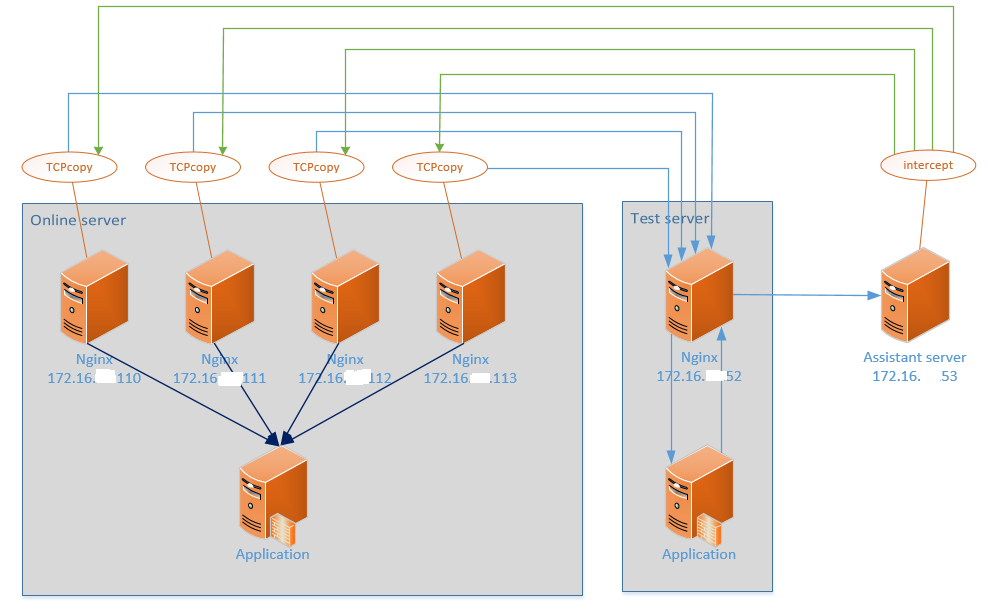
0x02,实作:仿真测试的拓扑
下面将列出本次仿真测试的线上环境拓扑图。
环境如下:
- Online Server
- 4个生产环境 Nginx
- 172.16.***.110
- 172.16.***.111
- 172.16.***.112
- 172.16.***.113
- Test Server
- 一个镜像环境的 Nginx
- Assistant Server
- 镜像环境里的一台独立服务器
拓扑如图3所示:
图3 压测环境拓扑
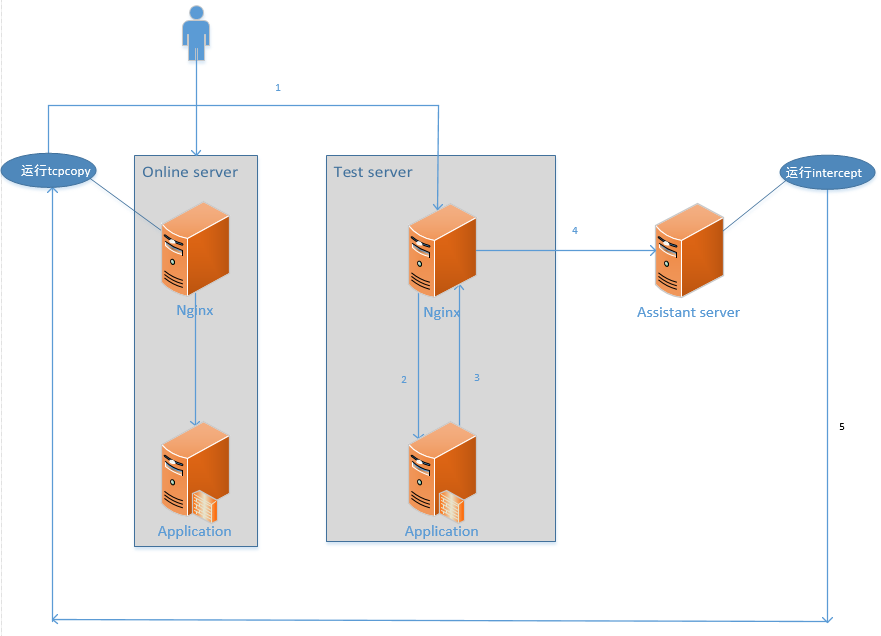
它的数据流转顺序如下图4所示:
图4 压测环境的数据流转顺序
¬Ý
0x03,实作:操作步骤
下面分别列出在 Online Server/Test Server/Assistant Server 上的操作步骤。
3.1 Online Server 上的操作:
下载并安装 tcpcopy 客户端;
git clone http://github.com/session-replay-tools/tcpcopy
./configure
make && make install
¬Ý¬Ý
安装完成后的各结构目录:
Configuration summary
¬Ý
¬Ý tcpcopy path prefix: "/usr/local/tcpcopy"
¬Ý tcpcopy binary file: "/usr/local/tcpcopy/sbin/tcpcopy"
¬Ý tcpcopy configuration prefix: "/usr/local/tcpcopy/conf"
¬Ý tcpcopy configuration file: "/usr/local/tcpcopy/conf/plugin.conf"
¬Ý tcpcopy pid file: "/usr/local/tcpcopy/logs/tcpcopy.pid"
¬Ý tcpcopy error log file: "/usr/local/tcpcopy/logs/error_tcpcopy.log"
¬Ý¬Ý
ËøêË°å tcpcopy ÂÆ¢Êà∑Á´ØÔºåÊúâÂáÝÁßçÂèØÈÄâÊñπºèÔºö
./tcpcopy -x 80-172.16.***.52:80 -s 172.16.***.53 -d ¬Ý ¬Ý ¬Ý¬Ý#Â֮ʵÅÈáè§çÂà∂
./tcpcopy -x 80-172.16.***.52:80 -s 172.16.***.53 -r 20 -d ¬Ý#§çÂà∂20%ÁöÑʵÅÈáè
./tcpcopy -x 80-172.16.***.52:80 -s 172.16.***.53 -n 2 -d ¬Ý ¬Ý#Êîæ§ß2ÂÄçʵÅÈáè
¬Ý
3.2 Test Server 上的操作:
Ê∑ªÂäÝÈùôÊÄÅË∑ØÁî±Ôºö
route add -net 0.0.0.0/0 gw 172.16.***.53
¬Ý
3.3 Assistant Server 上的操作:
下载并安装 intercept 服务端;
git clone http://github.com/session-replay-tools/intercept
./configure
make && make install
¬Ý
安装完成后的各结构目录:
Configuration summary
¬Ý intercept path prefix: "/usr/local/intercept"
¬Ý intercept binary file: "/usr/local/intercept/sbin/intercept"
¬Ý intercept configuration prefix: "/usr/local"
¬Ý intercept configuration file: "/usr/local/intercept/"
¬Ý intercept pid file: "/usr/local/intercept/logs/intercept.pid"
¬Ý intercept error log file: "/usr/local/intercept/logs/error_intercept.log"
¬Ý
运行 intercept 服务端;
./intercept -i eth0 -F 'tcp and src port 80' -d
¬Ý
Âõæ5 Áîü‰∫ßÁéØ¢ÉÂíåÈïúÂÉèÁéØ¢ÉÊï∞ÊçƉºÝËæìʵÅÁ®ãÂõæ
对照上图5,再简单解释一下工作原理:
- TCPcopy 从数据链路层 copy 端口请求,然后更改目的 ip 和目的端口。
- Â∞܉øÆÊîπËøáÁöÑÊï∞ÊçÆÂåÖ‰ºÝÈÄÅÁªôÊï∞ÊçÆÈìæË∑رÇÔºåÂπ∂‰∏î‰øùÊåÅ tcp ËøûÊé•ËØ∑ʱDŽÄÇ
- 通过数据链路层从 online server 发送到 test server。
- 在数据链路层解封装后到达 nginx 响应的服务端口。
- 等用户请求的数据返回结果后,回包走数据链路层。
- 通过数据链路层将返回的结果从 test server 发送到 assistant server。注:test server 只有一条默认路由指向 assistant server。
- 数据到达 assistant server 后被 intercept 进程截获。
- 过滤相关信息将请求状态发送给 online server 的 tcpcopy,关闭 tcp 连接。
0x04,可能会遇到的问题
ÁéãÊñåËá™Â∑±ËÆ≤Ôºö˶ÅÊÉ≥Áî®Â•Ω tcpcopyÔºåÈúÄ˶ÅÁÜüÊÇâÁ≥ªÁªüÁü•ËØÜÔºåÂåÖÊã¨Â¶Ç‰ΩïÈ´òÊïàÁéáÊäìÂåÖÔºå¶ljΩïÂÆö‰ΩçÁ≥ªÁªüÁì∂È¢àÔºå¶ljΩïÈÉ®ÁΩ≤ʵãËØïÂ∫îÁî®Á≥ªÁªüÔºå¶ljΩïÊäìÂåÖÂàÜÊûê„ÄÇÂ∏∏ËßÅÈóÆÈ¢òÊúâÔºö1ÔºâÈÉ®ÁΩ≤ʵãËØïÁ≥ªÁªü‰∏çÂà∞‰ΩçÔºåËĶÂêàÁ∫ø‰∏äÁ≥ªÁªüÔºå2ÔºâÂøΩËßÜÁ≥ªÁªüÁì∂È¢àÈóÆÈ¢òÔºå3Ôºâ‰∏çÁü•ÈÅì¶ljΩïÂÆö‰ΩçÈóÆÈ¢òÔºå4Ôºâ˵ÑÊ∫ê‰∏çÂà∞‰ΩçÔºå˵ÑÊ∫êÁ¥ßºÝºïÂèëÁöÑÈóÆÈ¢ò „ÄÇ
¬Ý
1)ip_conntrack
2014Âπ¥6ÊúàÔºåÂæÆÂçöÁöÑÂîêÁ¶èÊûóÊõæËØ¥Ôºö‚ÄúTcpcopy ºïʵÅÂ∑•ÂÖ∑ÊòØÁ∫ø‰∏äÈóÆÈ¢òÊéíÊü•ÁöÑÁªù‰Ω≥‰πãÈÄâÔºå‰Ω܉ΩøÁî®ËÄÖÂæàÂ∞ëÊúâ‰∫∫ÂéªÂÖ≥Ê≥®ÂºÄÂêØ tcpcopy ÊúçÂä°Êó∂ÔºåÂêåÊó∂‰ºöºÄÂêØ ip_conntrack ÂÜÖÊÝ∏Ê®°ÂùóÔºåËøô‰∏™Ê®°ÂùóË¥üË¥£ËøΩË∏™ÊâÄÊúâ tcp ÈìæÊé•ÁöÑÁä∂ÊÄÅÔºåËÄå‰∏îÂÆÉÁöÑÂÜÖÈÉ®Â≠òÂÇ®ÊúâÈïøÂ∫¶ÈôêÂà∂Ôºå‰∏ÄÊó¶Ë∂ÖËøáÔºåÊâÄÊúâÊñ∞ª∫ÈìæÊé•ÈÉΩ‰ºö§±Ë¥•„ÄÇ‚Äù
王斌则
ÂõûÂ∫îËØ¥Ôºö‚ÄúºÄÂêØ tcpcopyÔºåËá™Ë∫´‰∏牺öÂéªÂºÄÂêØ ip_conntrack ÂÜÖÊÝ∏Ê®°Âùó„ÄǺĉ∏çºÄÂêØ ip_conntrack ÂÜÖÊÝ∏Ê®°ÂùóÔºåÊòØÁî®Êà∑Ëá™Â∑±ÂÜ≥ÂÆöÁöÑÔºåË∑ü tcpcopy Ê≤°ÂÖ≥Á≥ª„ÄÇ‚Äù‰ªñ
还建议:“
ÂΩìËøûÊé•Êï∞ÈáèÈùûÂ∏∏§öÁöÑÊó∂ÂÄôÔºåÊú¨Ë∫´Â∞±Â∫îËØ•ÂÖ≥Èó≠ ip_conntrackÔºåÂê¶Âàô‰∏•ÈáçÂΩ±ÂìçÊÄßËÉΩ„ÄÇËá≥‰∫é tcpcopyÔºåȪòËƧÊò؉ªé ip ±ÇÂèëÂåÖÁöÑÔºåÊâĉª•‰πü‰ºöË¢´ ip_conntrack Âπ≤Ê∂âÔºåÊñáÊ°£‰∏≠‰πüÊúâÊèèËø∞ÔºåÂÖ∂ÂÆû‰πüÂè؉ª•ÈááÁî® --enable-dlinject Êù•ÂèëÂåÖÔºåÈÅøºÄip±ÇÁöÑip_conntrack„ÄǶÇÊûúÊ≤°ÊúâÊä•‚Äúip_conntrack: table full, dropping packet‚ÄùÔºå‰∏ÄËà¨ÊóÝÈúÄÂéªÊìçÂøÉip_conntrack„ÄÇ‚Äù‰ª•Âèä‚ÄúÁ∫ø‰∏äËøûÊ镉∏ç§öÁöÑÂú∫ÂêàÔºåºÄÂêØ ip_conntrack Âπ∂Ê≤°ÊúâÈóÆÈ¢ò„ÄÇÁ∫ø‰∏äËøûÊé•ÊØîËæɧöÁöÑÂú∫ÂêàÔºåÊúÄ•ΩÂÖ≥Èó≠ ip_conntrackÔºåÊàñËÄÖÂØπÁ∫ø‰∏äÂ∫îÁî®Á≥ªÁªüÁ´ØÂè£ËÆæÁΩÆ NOTRACKÔºåËá≥Â∞ëÊàëÂë®Âõ¥ÁöÑÁ≥ªÁªüÈÉΩÊòØËøôÊÝ∑ÁöÑÔºåËøôÊò؉∏∫ÊÄßËÉΩËÄÉËôëÔºå‰πüÊò؉∏ÄÁßç•ΩÁöÑËøêÁª¥‰πÝÊÉØ„ÄÇ‚Äù
¬Ý
2)少量丢包
如何发现 TCPCopy 丢包多还是少呢?
ÁéãÊñåËá™Â∑±Áß∞ÔºåÂú®Êüê‰∫õÂú∫Êô؉∏ãÔºåpcap ÊäìÂåÖ‰∏¢ÂåÖÁéቺöËøúÈ´ò‰∫é raw socket ÊäìÂåÖÔºåÂõÝÊ≠§ÊúÄ•ΩÂà©Áî® pf_ring Êù•ËæÖÂä©ÊàñËÄÖÈááÁî® raw socket Êù•ÊäìÂåÖ„ÄÇ
丢包率需要在测试环境中按照定量请求发送进行对比才能展开计算,另外还需要对日志内容进行分析,有待测试。
¬Ý





相关推荐
2019,国产芯片迎来亟待真刀真枪验证的一年.pdf
要培养符合企业需求的职业人才,必须有明确的人才培养方案,创新实践教学体系,并在师资建设、实训基地建设、教材建设等方面进行落实。 参考文献中列举的资料对于理解职业教育中的实践教学创新提供了宝贵的参考,如...
* Êé•ËøëÁî®Êà∑ÔºöÁúüÊ≠£ÁêÜËߣÁî®Êà∑ÔºåÂÖâÈùÝÁ©∫ÊÉ≥Êò؉∏çË°åÁöÑÔºåÂæóÁúüÂàÄÁúüÊû™ÂéªÊé•Ëø뉪ñ‰ª¨„ÄÇËÖæËÆØ10-100-1000Ê≥ïÂàôÔºöÂõ¢ÈòüÊØèÊúàÈÄöËøáÁîµËØù/Èù¢ÂØπÈù¢ÁöÑÊñπºèËÆøË∞à10‰∏™Áî®Êà∑ÔºåÂõû§ç100‰∏™Áî®Êà∑Âú®ËÆ∫ÂùõÊàñÂæÆÂçö‰∏äÁöÑÂèëÂ∏ñÔºåÈòÖËت1000‰∏™Áî®Êà∑ÁöÑÂèçȶà„ÄÇ * ‰∫ÜËߣÁî®Êà∑Ôºö...
41. **ÊîÄÁôªÈ´òÂ≥∞„ÄÅÁúüÂàÄÁúüÊû™„ÄÅ•ãËøõËÄÖ„ÄźÄÊãìËÄÖ„ÄÅ•âÁåÆËÄÖ**ÔºöȺìÂä±ÊäÄÊú؉∫∫Âëò‰∏çÊñ≠Â≠¶‰πÝÔºåÂãá‰∫éÂÆûË∑µÔºå‰∏∫ÁßëÊäÄËøõÊ≠•Ë¥°ÁåÆÂäõÈáè„ÄÇ ‰ª•‰∏äËøô‰∫õÁêÜÂøµÂíåÊÄÅÂ∫¶ÈÉΩÊòØIT‰∏ì‰∏ö‰∫∫£´Âú®Êó•Â∏∏Â∑•‰Ωú‰∏≠Â∫îÂΩìÁßâÊåÅÁöÑÂéüÂàôÔºåÂÆɉª¨ÂØπ‰∫éÊé®Âä®ÁΩëÁªúÊäÄÊúØÁöÑÂèë±ïÂíåÂ∫îÁî®...
Linux+Oracle 11g+RAC+12cc+adg中国史上最详细生产系统下实施文档 我保证:这是史上最详细的生产系统oracle全流程下真刀真枪实战文档。
‰π¶‰∏≠Êóݧ™Â§öÈïøÁØá§ßËÆ∫ÔºåÂÖ®ÈÉ®ÊòØÁúüÂàÄÁúüÊû™ÁöÑÂÆûÊìç„Äljπ¶‰∏≠Ê∂âÂèäÁöÑÊäÄÂ∑ßÂíåÊñπÊ≥ïÔºåÈÉΩÊò؉ΩúËÄÖ‰ªéÂÆûÈôÖÊìç‰Ωú‰∏≠ÊĪÁªìÂá∫Êù•ÁöÑÊàêÂäüÁªèÈ™å„ÄÇÂêåÊó∂Ôºå‰ΩúËÄÖÁöÑËÆ∏§öÂ≠¶ÁîüÔºå‰πüÈÉΩÁî®Ëá™Â∑±ÁöÑÂÆûÈôÖË°åÂä®ÔºåÈ™åËØʼn∫ÜËøô‰∫õÊñπÊ≥ïÁöÑÂèØË°åÊÄßÔºåÊâĉª•Êú¨‰π¶ÁöÑÂê´ÈáëÈáèÈùûÂ∏∏È´ò„ÄÇ
ÁÇπÈ¢òÂ∞±Âà∞Ê≠§‰∏∫Ê≠¢‰∫ÜÔºåËÆ©Êà뉪¨ÁúüÂàÄÁúüÊû™Êù•ËØ¥ËØ¥ÊâßË°åÁéØ¢ÉÂêß„ÄÇÂÖà‰ªéÂ֮±ÄÊâßË°åÁéآɺÄÂßãԺ剪ñ§щ∫éÊ雷∏™ÊâßË°åÁéØ¢ÉÁöÑÊúħñÈù¢ÔºåÂπ∂‰∏îÊò؉Ωú‰∏∫windowÂØπ˱°ÁöѱûÊÄßÊ∑ªÂäÝÁöÑ„ÄÇ ‰∏æ‰∏™‰æãÂ≠êÔºö ‰ª£ÁÝŶlj∏ã: <html> <head> <script type=
Âè؉ª•Áî®"ÈíàÈîãÁõ∏ÂØπ"Êàñ"ÁúüÂàÄÁúüÊû™"Êù•Ë°®Á§∫ÊØî˵õÁöÑÊøÄÁÉàÁ®ãÂ∫¶„ÄÇ - "ȶñȺ݉∏§Á´Ø"ÔºöÂΩ¢ÂÆπÁäπ˱´‰∏çÂÜ≥ÔºåÁ¨¶ÂêàÂÜ≥Á≠ñËÄÖÂú®Â§ÑÁêÜÊ•ºÂ∏ÇÈóÆÈ¢òÊó∂Â∫îÊûúÊñ≠ÁöÑÊÄÅÂ∫¶„ÄÇ 2. ËØ≠ÁóÖÂàÜÊûê - AÈ°πÊ≤°ÊúâËØ≠ÁóÖÔºåË°®Ëø∞Ê∏ÖÊô∞ÔºåÈĪËæëÂêàÁêÜ„ÄÇ - BÈ°πÊê≠ÈÖç‰∏çÂΩìÔºå"ÂÆåÂñÑ"‰∏çËÉΩ‰∏é...
ÂâçÈù¢Âü∫Á°ÄÁü•ËØ܉ªãÁªçÂÆåÊØïÔºåÊú¨ËäǺÄÂßãÁúüÂàÄÁúüÊû™ÁöÑÁߪʧ牪£ÁÝʼn∫Ü„ÄÇÊú¨ËäÇÂ∞ÜWanlix3.3ËäÇÁöщª£ÁÝʼnªéARM7ÂÜÖÊÝ∏ÁߪʧçÂà∞TIÂíåSTÁöÑcortexÂÜÖÊÝ∏ÁöÑËäØÁâá‰∏äÔºåÁߪʧçÂÆåÊàêÂêéÈÄöËøá‰∏≤Âè£ÊâìÂç∞Âè؉ª•ÁúãÂà∞ÁߪʧçÁöÑÊïàÊûú„ÄÇ Â¶ÇÊûú‰ΩÝÊúâSTM32ÁöÑÊùøÂ≠êÔºåÁé∞Âú®Â∞±Âè؉ª•Ë∑ëԺŠ...
ÂØπ‰∫éÊô∫ËÉΩÁªàÁ´ØÈ¢ÜÂüüËÄåË®ÄÔºå2012Âπ¥Ê≥®ÂÆöÊò؉∏ĉ∏™ÂÖÖʪ°‰∫âËÆÆÁöÑÂ𥉪لÄÇËøôÊÝ∑Áöщ∫âËÆÆÔºåÊó¢ÊúâʵƉ∫éË°®Èù¢ÂΩ¢ÂºèÁöÑÁúüÂàÄÁúüÊû™Ôºå‰πüÊúâÈöê‰∫éÊ∑±Â±ÇÂÖ≥Á≥ªÁöÑÂà©Ê∂¶Âçöºà„ÄÇÂú®Ê≠§ËøáÁ®ã‰∏≠ÔºåÊìç‰ΩúÁ≥ªÁªüÂíåÁªàÁ´ØÂéÇÂï܉∏≠‰πüÂá∫Áé∞‰∫ÜÊñ∞È≤úÁöÑÈù¢Â≠îÔºåËÆ©Â∏ÇÂú∫ÂÖÖʪ°‰∫ÜÁñëÊÉë‰∏éÂèòÊï∞„ÄÇ
在《MCU低功耗设计(一)理论》中,我们介绍了节能的原理,本文用万用表和MCU电路板,真刀真枪地测试功耗值。简单,但绝对真实的测试数据,看看官方宣称低功耗与实测结果有多大差距,Let’s go!
AppScan是对网站等WEB应用进行安全攻击,通过真刀真枪的攻击,来检查网站是否存在安全漏洞,在使用AppScan的时候,要配置的第一个就是要检查的网站的地址,配置了以后,AppScan就会利用“探索”技术去发现这个网站...
清华大学水利系毕业班同学在党的领导下贯彻了教育结合生产劳动的方针,进行了北京郊区十三个水库的设计,通过真刀真枪的毕业设计,不但完成了实际设计任务,提高了教学的质量,同时也提出了很多解决生产问题的科学...
‰∏Ä„ÄÅÂâçˮĉ∏∫ÁùÄË¥ØÂΩªÊïôËÇ≤‰∏éÁîü‰∫ßÂä≥Âä®Áõ∏ÁªìÂêàÁöÑÊñπÈíàÔºåÂú®ÂÖöÁöÑÈ¢ÜÂغ‰∏ãÊà뉪¨Êé•Âèó‰∫ܧßÂûãÊ∞¥Â∫ìËÆæËÆ°Â∑•‰ΩúÔºåËøõË°åÁúüÂàÄÁúüÊû™ÂÅöÊØï‰∏öËÆæËÆ°„ÄÇ˶ÅÊĪË∑ØÁ∫øÁöÑÂÖâËæâÁÖßËÄĉ∏ãÔºå‰∏∫‰∫ܧöÂø´Â•ΩÁúÅÂú∞ÂÆåÊàêÁîü‰∫߉ªªÂä°ÔºåÂÖöÊĪÊîØÊèêÂá∫‰∫Ü‚ÄúÁ槉ºóÊêûÁßëÁÝî‚ÄùÁöÑÂè∑Âè¨ÔºåÊà뉪¨ÁÝ¥Èô§...
‰∏Ä„Äŧ©ÁÑ∂Èì∫ÁõñÁöÑÊèêÂá∫ÂèäÂÖ∂ÊÑè‰πâÂú®ÁúüÂàÄÁúüÊû™ÁöÑÊØï‰∏öËÆæËÆ°‰∏≠ÔºåÊà뉪¨Êé•Âèó‰∫ÜÈ´òÂ≤©Âè£Ê∞¥Â∫ìËÆæËÆ°ÁöщªªÂä°„ÄÇÈ´òÂ≤©Âè£Ê≤ü‰ΩçÊñºÊòåÂπ≥±±Âå∫ÔºåʵÅÂüüÈù¢ÁßØÔºëÔºíÔºêÂπ≥ÊñπÂÖ¨ÈáåÔºåÊ≤≥Â∫äÁÝÇÂçµË¶ÜÁõñ±ÇÊ∑±ËææÔºñÔºïÂÖ¨Â∞∫ÔºåÂÖ∂Ê∏óʵÅÁ≥ªÊï∞Áî±ÔºëÔºêÔºçÔºëÂà∞ÔºëÔºêÔºçÔºíÂÖ¨ÂàÜÔºèÁßí„ÄÇÂõÝÊ≠§...
Âú®ÂÆûÂú∞Ëê•Èîĉ∏≠ÔºåÊàëÂ∞ÜÈì∂Ë°åÂüπËÆ≠ÊâÄÂ≠¶ÁöÑÁü•ËØÜÂíåÊäÄÂ∑ßËøêÁî®Âà∞ÂÆûÈôÖÂ∑•‰Ωú‰πã‰∏≠Ôºå‰∏牪ÖÊèêÂçá‰∫ÜÊàëÁöÑËê•ÈîÄÊäÄËÉΩÔºå‰πüËÆ©Êàë‰ΩìÈ™åÂà∞‰∫ÜÂú®Â∏ÇÂú∫‰∏≠‚ÄúÁúüÂàÄÁúüÊû™‚ÄùÊâìÊãºÁöÑʪãÂë≥„ÄÇÂ∞ΩÁÆ°‰ºöÈÅáÂà∞Êå´ÊäòÂíåÂõ∞ÈöæÔºå‰ΩÜÊØè‰∏Äʨ°ÁöÑÂä™ÂäõÈÉΩËÆ©ÊàëÁ¶ªÊàêÂäüÊõ¥Ëøë‰∏ÄÊ≠•„ÄÇ Âú®ÂÆû‰πÝ...