
وœ¬و–‡و،£é€‚用ن؛؛ه‘کï¼ڑç ”هڈ‘ه’Œè؟گç»´ه‘که·¥
- Zabbix
- Nagios
- Centreon
- Logstash
- Ganglia+Cacti
|
规هˆ™ï¼ڑو¨،ن»؟وˆ‘ن»¬هڈ‘çژ°é—®é¢کهگژه…ˆو£€وں¥و•°وچ®ه؛“ن¸»ن»ژهگŒو¥وک¯هگ¦وœ‰é—®é¢کçڑ„ن¹ وƒ¯
|
|
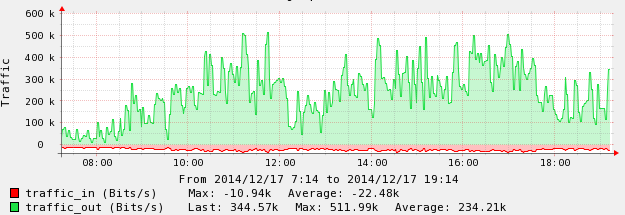
ه¤©وœ؛ç³»ç»ںهڈ‘çژ°وˆگهچ•é‡‘é¢وˆ–éھŒè¯پهˆ¸و•°وˆ–çںن؟،هڈ‘é€پو،و•°çژ¯و¯”ه¤§ه¹…ن¸‹é™چهگژ,هگ¯هٹ¨و£€وں¥è§„هˆ™ï¼Œ
è‡ھهٹ¨é€گن¸€و£€وں¥هگ„ç§چن»ژه؛“çڑ„ن¸»ن»ژهگŒو¥وƒ…ه†µم€‚
ه¦‚وœهڈ‘çژ°ن¸»ن»ژه»¶è؟ں超è؟‡éکˆه€¼ï¼Œهˆ™ه¤©وœ؛ DashBoard ه؛”وµ®ه‡؛ن¸¤و،ç؛¢è‰²è¦ه‘ٹوڈگç¤؛(هڈ¯ç‚¹ه‡»è؟›ه…¥ï¼‰ï¼ڑ
ه¦‚وœهڈ‘çژ°ن¸»ن»ژهگŒو¥ه¤±è´¥ه¯¼è‡´ن؛†هگŒو¥هپœو¢ï¼Œهˆ™ه؛”وµ®ه‡؛ن¸¤و،ç؛¢è‰²è¦ه‘ٹوڈگç¤؛(هڈ¯ç‚¹ه‡»è؟›ه…¥ï¼‰ï¼ڑ
|
آ ه¤§è‡´وƒ³و¥ï¼Œوژن¸¹هˆکه¥ژè؟ک需è¦پ解ه†³è؟™ن¹ˆه‡ ن¸ھهں؛ç،€é—®é¢کï¼ڑ
|
و•°وچ®ه؛“و‹“و‰‘ه…³ç³»
|
|
هœ¨ç›‘وژ§ç³»ç»ں里登记ن؛† DB çڑ„IPه’Œهˆ†ç»„هگژ,ه…¶ه®ه·²ç»ڈهڈ¯ن»¥وژ¢وµ‹هˆ° DB ن¹‹é—´çڑ„ن¸»ن»ژه…³ç³»ï¼ˆهŒ…و‹¬ç؛§èپ”ه…³ç³»ï¼‰ن؛†ï¼Œèƒ½è‡ھهٹ¨ç»کهˆ¶ه‡؛登记çڑ„و‰€وœ‰و•°وچ®ه؛“وœچهٹ،ه™¨ن¹‹é—´çڑ„ه…³ç³»م€‚ن¸¾ن¾‹ه¦‚ن¸‹ï¼ڑ
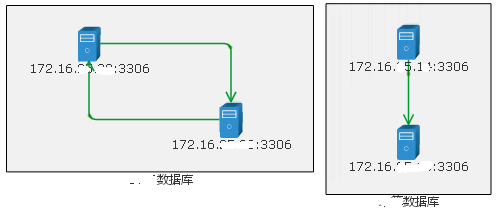 ه›¾2 è‡ھهٹ¨ç»کهˆ¶و•°وچ®ه؛“و‹“و‰‘
|
- ن¸چé‡چه¤چهˆ¶é€ è½®هگï¼›
- و—¢ç„¶و‰¾è½®هگ,那è؟™ن¸ھè½®هگه°±ه؛”该هڈھهپڑن¸€ن»¶ن؛‹ï¼Œن¸”وٹٹه®ƒهپڑهˆ°وœ€ه¥½م€‚
- grafana + influxdb
- statsd + graphite
- collectd + graphite
- grafana + graphite
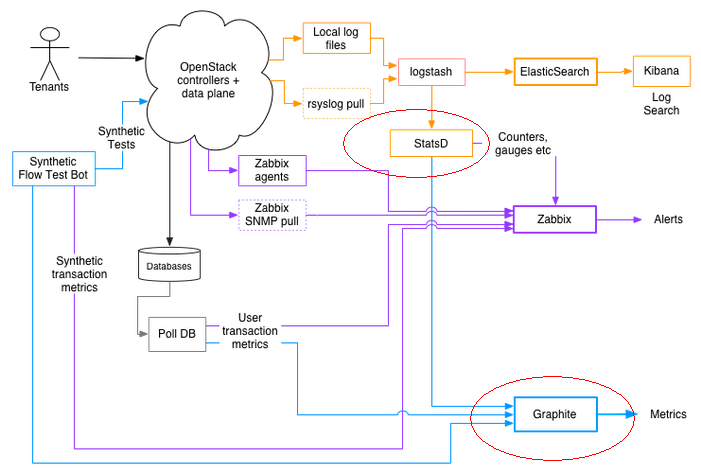
آ آ Graphiteآ وک¯ن¸€ن¸ھن¼پن¸ڑç؛§çڑ„监وژ§ه·¥ه…·ï¼Œç”¨ Python ç¼–ه†™ï¼Œé‡‡ç”¨ django و،†و¶ï¼Œsqlite و•°وچ®ه؛“هکه‚¨ï¼Œè‡ھوœ‰ç®€هچ•و–‡وœ¬هچڈè®®é€ڑ讯,ç»که›¾هٹں能ه¼؛ه¤§م€‚وœ€هˆç”±آ Chris Davis هœ¨ Orbitz ه·¥ن½œو—¶ï¼Œن½œن¸؛ن¸€ن¸ھè¾…هٹ©é،¹ç›®ه¼€هڈ‘çڑ„,وœ€ç»ˆوˆگن؛†ن¸€ن¸ھ监وژ§هں؛ç،€ه·¥ه…·ï¼Œه¦‚ن»–و‰€è¨€ï¼ŒGraphite provides real-timeآ visualizationآ andآ storageآ of numeric time-series data,é‡چ点解ه†³ï¼ڑ
- ه®و—¶هڈ¯è§†هŒ–
- و—¶é—´ه؛ڈهˆ—و•°وچ®çڑ„هکه‚¨
ن¸¥و ¼هœ°è¯´ï¼ŒGraphite هڈھوک¯ن¸€ن¸ھو ¹وچ®و•°وچ®ç»که›¾çڑ„ه·¥ه…·ï¼Œو•°وچ®و”¶é›†é€ڑه¸¸ç”±ç¬¬ن¸‰و–¹ه·¥ه…·وˆ–وڈ’ن»¶ه®Œوˆگ,ه®ƒè‡ھه¸¦ن؛† carbon ه’Œ whisper,è؟کهڈ¯و ¹وچ®ه…¶هچڈ议选用هˆ«çڑ„و•°وچ®و؛گن¾›ه…¶ç»که›¾م€‚ه®کو–¹وڈڈè؟°ï¼Œé¢„è®،用آ Ceresآ و›؟ن»£ Whisperم€‚
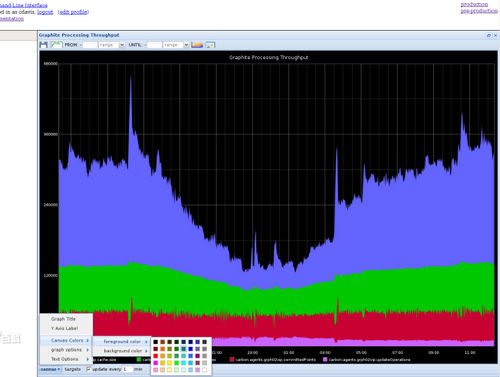
ه›¾4 graphiteه›¾ن¾‹
آ 简هچ•çڑ„و–‡وœ¬هچڈè®®ه’Œه¼؛ه¤§çڑ„ç»که›¾هٹں能ن½؟ه¾—ه®ƒهڈ¯ن»¥و–¹ن¾؟هœ°و‰©ه±•هˆ°ن»»ن½•éœ€è¦پ监وژ§çڑ„ç³»ç»ںن¸ٹم€‚豆瓣م€پGoogleم€پGitHubم€پInstagramم€پUberç‰ه…¬هڈ¸éƒ½ç”¨ه®ƒم€‚
آ
3.3.CollectD
آ Cè¯è¨€ه¼€هڈ‘çڑ„ collectd وک¯ن¸€ن¸ھ较ن¸؛هڈ¤è€پçڑ„ه·¥ه…·ï¼Œهƒڈ statsd ن¸€و ·ه®ƒن¹ںهپڑه‘¨وœںو€§و”¶é›†ç»ںè®،و•°وچ®ï¼Œcollectd è؟کç®،و•°وچ®هکه‚¨م€‚ه®ƒèƒ½ه¤ںé€ڑè؟‡وڈ’ن»¶و”¯وŒپو£€وµ‹هگ„ç§چهگ„و ·çڑ„ç³»ç»ںن؟،وپ¯ï¼Œه¦‚و•°وچ®ه؛“م€پUPSم€‚
آ è¦پوƒ³وں¥çœ‹ collectd و”¶é›†çڑ„ن؟،وپ¯ï¼Œè؟ک需è¦په®‰è£… web ç•Œé¢وˆ–者 Cacti,ن؛ژوک¯ه·¥ن½œو¨،ه¼ڈه°±وک¯ï¼ڑ
آ collectd ن½œن¸؛ه®ˆوٹ¤è؟›ç¨‹è؟گè،Œï¼Œو¯ڈéڑ” 10 秒و”¶é›†ن؟،وپ¯ï¼Œè€Œ Cacti و¯ڈéڑ”5هˆ†é’ںè؟گè،Œن¸€ن¸ھ PHP è„ڑوœ¬و¥و”¶é›†ن؟،وپ¯ï¼ˆن¸¤è€…çڑ„و—¶é—´é—´éڑ”هڈ¯é…چ置)م€‚
- schemaless(و— 结و„),هڈ¯ن»¥وک¯ن»»و„ڈو•°é‡ڈçڑ„هˆ—
- Scalable
- min, max, sum, count, mean, median ن¸€ç³»هˆ—ه‡½و•°ï¼Œو–¹ن¾؟ç»ںè®،
- Native HTTP API, ه†…ç½®httpو”¯وŒپ,ن½؟用http读ه†™
- Powerful Query Language,类ن¼¼SQL
- Built-in Explorer,è‡ھه¸¦ç®،çگ†ه·¥ه…·
3.5.Grafana
آ
آ آ grafana هˆ™ç±»ن¼¼ ES Kibana çڑ„هڈ¯è§†هŒ–é¢و؟,وœ‰ç€éه¸¸و¼‚ن؛®çڑ„ه›¾è،¨ه’Œه¸ƒه±€ï¼Œç›®ه‰چو”¯وŒپآ Graphiteم€پInfluxdb ه’Œ Opentsdb) +آ influxdb(هˆ†ه¸ƒه¼ڈو—¶ه؛ڈم€پن؛‹ن»¶ه’ŒوŒ‡و ‡و•°وچ®ه؛“)ç‰é…چوگم€‚
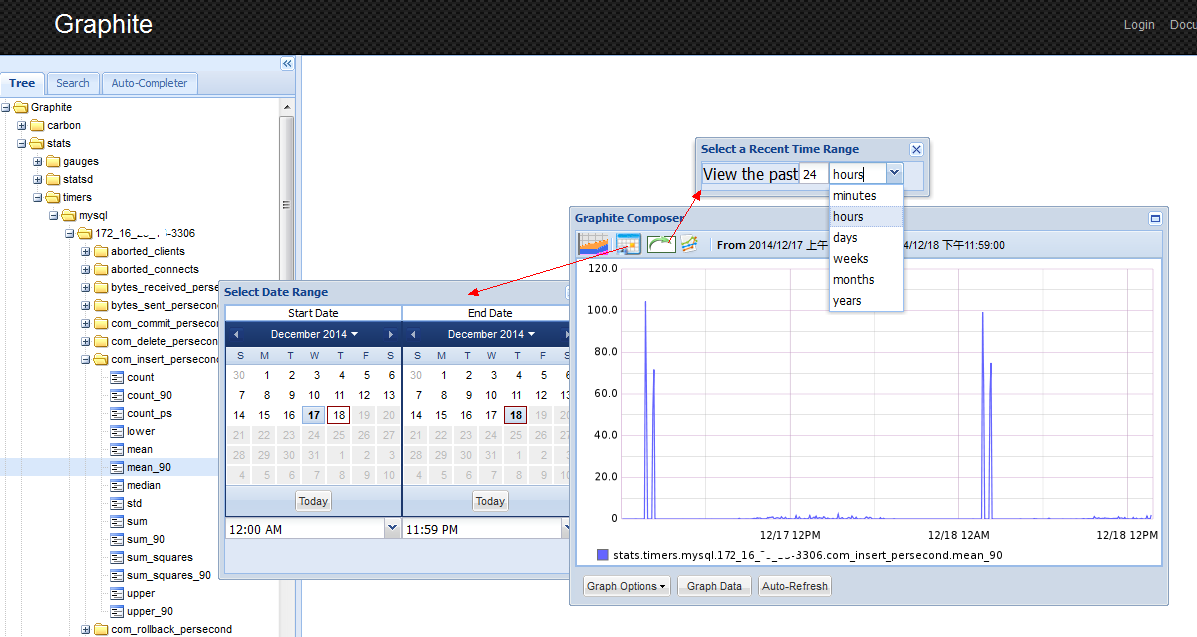
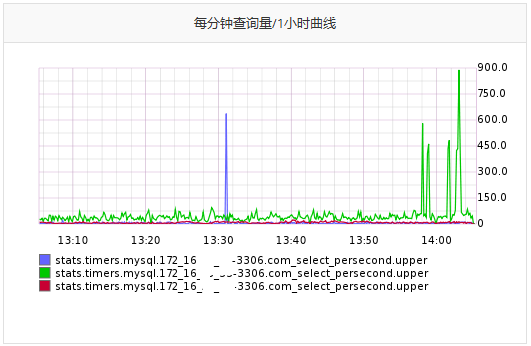
http://监وژ§ç³»ç»ںهںںهگچ/db/createImage/target/%5B%22stats.timers.mysql.172_16_999_991-3306.com_select_persecond.upper%22%2C%22stats.timers.mysql.172_16_999_992-3306.com_select_persecond.upper%22%2C%22stats.timers.mysql.172_16_999_993-3306.com_select_persecond.upper%22%5D/from/-1hour.html?width=492&n=0.8623758849623238
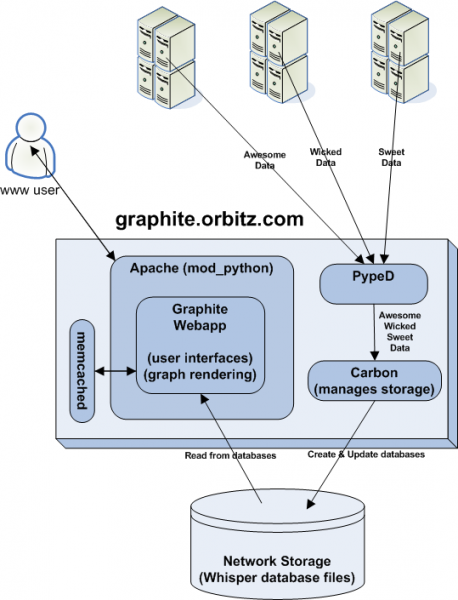
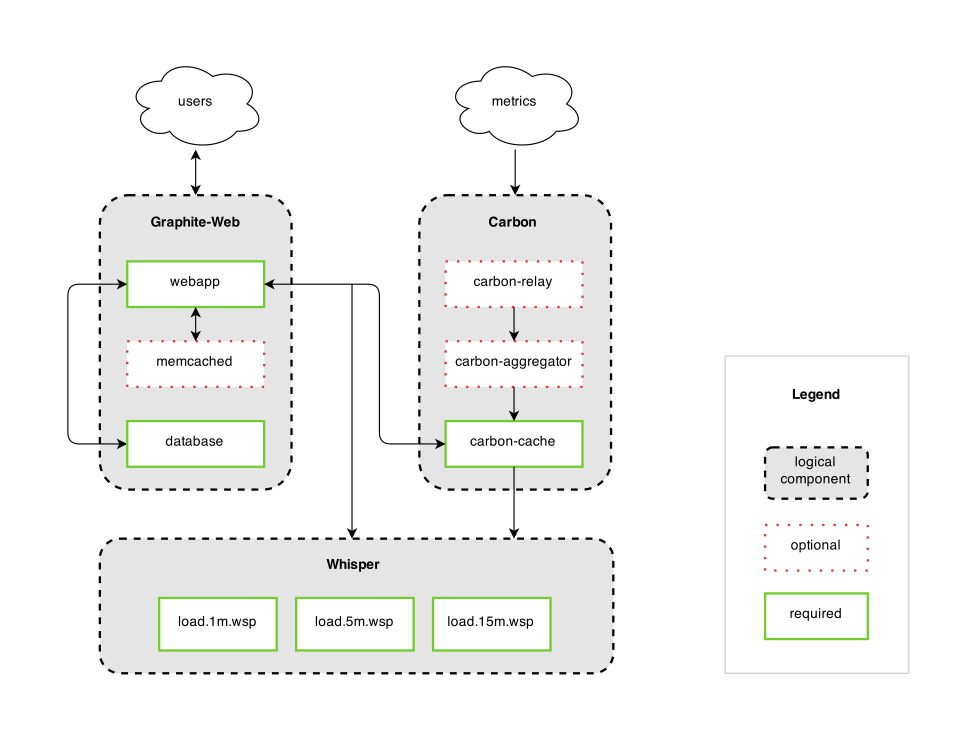
ه›¾10 graphite 逻辑ه›¾
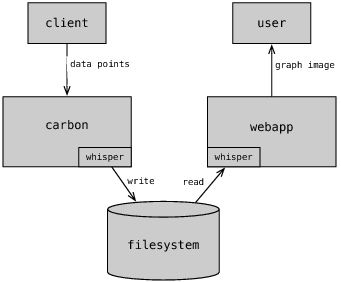
ه›¾11 Graphite و•°وچ®وµپ转ه›¾
- ه¤©وœ؛ه¹³هڈ°ن¸»هٹ¨و‹‰و•°وچ®ï¼Œن¸»è¦پ集ن¸هœ¨و•°وچ®ه؛“çڑ„ن¸»ن»ژهگŒو¥م€پو•°وچ®ه؛“çڑ„و‹“و‰‘ه…³ç³»ç‰è؟™و ·çڑ„ه…³ç³»ه‹و•°وچ®é‡‡é›†ن¸ٹم€‚
- ه…¶ن»–هœ؛و™¯ن¸‹ï¼Œهں؛وœ¬éƒ½éœ€è¦پ采集هچ•ç‚¹çٹ¶و€پçڑ„و•°وچ®ï¼Œهˆ™ç”±ه®¢وˆ·ç«¯è„ڑوœ¬ï¼ˆهچ³ agent)èژ·هڈ–و•°وچ®هگژ,ه†چوژ¨é€پهˆ°ه¤©وœ؛ه¹³هڈ°م€‚
[default_1min_for_1day]
pattern = .*
retentions = 10s:1d[stats]
pattern = ^stats.*
retentions = 10s:1d,30s:7d,1m:28d,15m:5y[business_monitoring]
pattern = ^business_monitoring\.
retentions = 1m:5yUnderstanding StatsD and Graphiteï¼ڑآ http://blog.pkhamre.com/2012/07/24/understanding-statsd-and-graphite/
çھçھçڑ„解ه†³و–¹و،ˆن»‹ç»چهˆ—è،¨ï¼ڑ
هں؛ن؛ژStatsD+Graphiteçڑ„و™؛能监وژ§è§£ه†³و–¹و،ˆ
#ç ”هڈ‘ن¸é—´ن»¶ن»‹ç»چ#ه®ڑو—¶ن»»هٹ،è°ƒه؛¦ن¸ژç®،çگ†JobCenter
#ç ”هڈ‘解ه†³و–¹و،ˆن»‹ç»چ#Recsys-Evaluate(وژ¨èچگ评وµ‹ï¼‰آ
#ç ”هڈ‘解ه†³و–¹و،ˆن»‹ç»چ#Tracing(鹰眼)
#ç ”هڈ‘解ه†³و–¹و،ˆن»‹ç»چ#هں؛ن؛ژوŒپن¹…هŒ–é…چç½®ن¸ه؟ƒçڑ„ن¸ڑهٹ،é™چç؛§
#ç ”هڈ‘ن¸é—´ن»¶ن»‹ç»چ#ه¼‚و¥و¶ˆوپ¯هڈ¯é وژ¨é€پNotify
#ç ”هڈ‘解ه†³و–¹و،ˆن»‹ç»چ#IdCenter(ه†…部ç»ںن¸€è®¤è¯پç³»ç»ں)
#ç ”هڈ‘解ه†³و–¹و،ˆن»‹ç»چ#هں؛ن؛ژESçڑ„وگœç´¢+ç›é€‰+وژ’ه؛ڈ解ه†³و–¹و،ˆ
#و•°وچ®وٹ€وœ¯é€‰ه‹#هچ³ه¸وں¥è¯¢Shib+Presto,集群ن»»هٹ،è°ƒه؛¦HUE+Oozie



相ه…³وژ¨èچگ
و€»ç»“,Statsdوک¯ن¸€ن¸ھه¼؛ه¤§çڑ„监وژ§ه·¥ه…·ï¼Œé€ڑè؟‡ç®€هچ•وک“用çڑ„وژ¥هڈ£و”¶é›†ه’Œèپڑهگˆو•°وچ®ï¼Œé…چهگˆهگژ端هکه‚¨ه’Œهڈ¯è§†هŒ–ه·¥ه…·ï¼Œن¸؛ITè؟گç»´وڈگن¾›ن؛†ن¸€ه¥—ه®Œو•´çڑ„监وژ§è§£ه†³و–¹و،ˆم€‚ه®ƒçڑ„çپµو´»و€§ه’Œهڈ¯و‰©ه±•و€§ن½؟ه…¶وˆگن¸؛许ه¤ڑه¤§ه‹ن؛’èپ”网ه…¬هڈ¸çڑ„首选监وژ§ه·¥ه…·م€‚
ن¸ژه…¶ن»–监وژ§ه·¥ه…·ï¼ˆه¦‚ Prometheusم€پGrafana وˆ– ELK Stack)é…چهگˆن½؟用,`node-statsd` هڈ¯ن»¥ه¸®هٹ©و„ه»؛ن¸€ن¸ھه…¨é¢çڑ„و€§èƒ½ç›‘وژ§ن½“系,ن»ژ而و›´ه¥½هœ°çگ†è§£ه؛”用程ه؛ڈçڑ„è؟گè،Œçٹ¶ه†µï¼Œهڈٹو—¶هڈ‘çژ°ه’Œè§£ه†³é—®é¢کم€‚ و€»ç»“,`node-statsd` وک¯ه‰چ端...
و€»çڑ„و¥è¯´ï¼ŒAlexcesaro-statsdوک¯ن¸€ن¸ھه¼؛ه¤§ن¸”é«کو•ˆçڑ„StatsDه®¢وˆ·ç«¯ï¼Œه®ƒçڑ„设è®،ه’Œه®çژ°ه……هˆ†è€ƒè™‘ن؛†و€§èƒ½ه’Œه†…هکç®،çگ†ï¼Œن¸؛需è¦په®و—¶ç›‘وژ§çڑ„ه؛”用وڈگن¾›ن؛†هڈ¯é çڑ„解ه†³و–¹و،ˆم€‚é€ڑè؟‡هڈ‚ن¸ژه’Œن½؟用è؟™و ·çڑ„ه¼€و؛گé،¹ç›®ï¼Œه¼€هڈ‘者ن¸چن»…هڈ¯ن»¥وڈگهچ‡è‡ھه·±çڑ„وٹ€وœ¯...
م€ٹهچ•وœ؛ 20 ن؛؟وŒ‡و ‡ï¼Œçں¥ن¹ژ Graphite وپ致ن¼کهŒ–ï¼پم€‹è؟™ç¯‡و–‡ç« 详细ن»‹ç»چن؛†çں¥ن¹ژهœ¨é¢ن¸´ه¤§è§„و¨،و•°وچ®ç›‘وژ§وŒ‘وˆکو—¶ï¼Œه¦‚ن½•ه¯¹ Graphite è؟›è،Œ...هگŒو—¶ï¼Œو–‡ç« è؟که±•ç¤؛ن؛†وœھو¥هڈ¯èƒ½çڑ„هڈ‘ه±•è¶‹هٹ؟,هچ³هˆ©ç”¨و–°ه‹هکه‚¨وٹ€وœ¯ه’Œو¶و„و¥وŒپç»ن¼کهŒ–监وژ§è§£ه†³و–¹و،ˆم€‚
Statsdوک¯ç”± Etsy ه¼€هڈ‘çڑ„ن¸€و¬¾è½»é‡ڈç؛§ن»£çگ†وœچهٹ،,ه®ƒè؟گè،Œهœ¨هگژ端وœچهٹ،ه™¨ن¸ٹ,وژ¥و”¶و¥è‡ھه؛”用çڑ„è®،و•°م€پè®،و—¶ç‰و€§èƒ½و•°وچ®ï¼Œه¹¶ه°†ه…¶èپڑهگˆهگژ转هڈ‘ç»™ه›¾ه½¢هŒ–ه±•ç¤؛ه·¥ه…·ï¼ˆه¦‚Graphiteوˆ–InfluxDB),用ن؛ژه®و—¶ç›‘وژ§ه’Œو•…éڑœوژ’وں¥م€‚é€ڑè؟‡ن½؟用Statsd,...
9. **社هŒ؛و”¯وŒپن¸ژو–‡و،£**ï¼ڑن½œن¸؛ه¼€و؛گé،¹ç›®ï¼Œstatsd-tagsوœ‰ç¤¾هŒ؛وڈگن¾›çڑ„و–‡و،£ه’Œé—®é¢ک解ç”,è؟™وœ‰هٹ©ن؛ژه¼€هڈ‘者هœ¨éپ‡هˆ°é—®é¢کو—¶و‰¾هˆ°è§£ه†³و–¹و،ˆم€‚ 10. **版وœ¬هچ‡ç؛§ن¸ژه…¼ه®¹و€§**ï¼ڑ3.2.1版هڈ¯èƒ½هŒ…هگ«ن؛†ن¸€ن؛›bugن؟®ه¤چم€پو€§èƒ½ن¼کهŒ–وˆ–و–°هٹں能م€‚هœ¨هچ‡ç؛§وˆ–...
"statsd-redis-backend"وک¯ن¸€ن¸ھé’ˆه¯¹و¤éœ€و±‚çڑ„解ه†³و–¹و،ˆï¼Œه®ƒç»“هگˆن؛†StatsDه’ŒRedisçڑ„ه¼؛ه¤§هٹں能,ن¸؛ه¼€هڈ‘者وڈگن¾›ن؛†ن¸€ç§چé«کو•ˆم€پçپµو´»çڑ„و•°وچ®ç»ںè®،ه’Œهکه‚¨هگژ端م€‚وœ¬و–‡ه°†و·±ه…¥وژ¢è®¨è؟™ن¸€ه·¥ه…·çڑ„و ¸ه؟ƒو¦‚ه؟µم€په·¥ن½œهژںçگ†ن»¥هڈٹه¦‚ن½•هœ¨ه®é™…é،¹ç›®ن¸ه؛”用...
**Pythonه؛“ django-statsd-unleashed 1.0.6** `django-statsd-unleashed` وک¯ن¸€ن¸ھPythonه؛“,ن¸“ن¸؛Djangoو،†و¶è®¾è®،,...é€ڑè؟‡è؟™ن¸ھه؛“,ن½ هڈ¯ن»¥ه®çژ°و›´ç²¾ç»†هŒ–çڑ„监وژ§ï¼Œهڈٹو—¶هڈ‘çژ°ه¹¶è§£ه†³و½œهœ¨é—®é¢ک,وڈگهچ‡و•´ن½“çڑ„ه¼€هڈ‘و•ˆçژ‡ه’Œه؛”用质é‡ڈم€‚
Sherlog.jsن¸ژهگژ端çڑ„Graphiteوˆ–Sentry结هگˆï¼Œهڈ¯ن»¥وڈگن¾›ه®Œو•´çڑ„端هˆ°ç«¯ç›‘وژ§è§£ه†³و–¹و،ˆم€‚ 5. **Fabric**ï¼ڑFabricوک¯ن¸€ن¸ھ用Pythonç¼–ه†™çڑ„ه‘½ن»¤ن»»هٹ،و‰§è،Œه؛“,ه®ƒç®€هŒ–ن؛†è؟œç¨‹وœچهٹ،ه™¨çڑ„è‡ھهٹ¨هŒ–و“چن½œï¼ŒهŒ…و‹¬éƒ¨ç½²م€پé…چç½®ç®،çگ†ç‰م€‚"ه®ˆوœ›è€…"هˆ©ç”¨...
ه¼€و؛گé،¹ç›®statsd-over-slf4j.zipوڈگن¾›ن؛†ن¸€ن¸ھه·§ه¦™çڑ„解ه†³و–¹و،ˆï¼Œه®ƒه°†Java StatsDه®¢وˆ·ç«¯ن¸ژSLF4J(Simple Logging Facade for Java)相结هگˆï¼Œن½؟ه¾—و—¥ه؟—و•°وچ®èƒ½ه¤ںو–¹ن¾؟هœ°ن¼ 输هˆ°StatsDوœچهٹ،ه™¨ï¼Œè؟›ن¸€و¥è؟›è،Œç»ںè®،ه’Œهˆ†وگم€‚وœ¬و–‡ه°†و·±ه…¥...
6. **监وژ§ن¸ژو—¥ه؟—ç³»ç»ں**ï¼ڑه»؛ç«‹ن؛†هں؛ن؛ژStatsdم€پGraphiteه’ŒGrafanaçڑ„监وژ§ن½“系,ن»¥هڈٹBansheeç‰و—¥ه؟—و”¶é›†هˆ†وگه·¥ه…·ï¼Œه®çژ°ن؛†ه…¨é¢çڑ„و€§èƒ½ç›‘وژ§ه’Œو•…éڑœوژ’وں¥èƒ½هٹ›م€‚ 综ن¸ٹو‰€è؟°ï¼Œé¥؟ن؛†ن¹ˆé€ڑè؟‡و„ه»؛ن¸€ه¥—ه®Œو•´çڑ„وœچهٹ،و²»çگ†ن½“系,ن¸چن»…وڈگهچ‡ن؛†...
و¤ه¤–,InfluxDBوڈگن¾›ن؛†Telegraf(采集ن»£çگ†ï¼‰م€پChronograf(界é¢ç»„ن»¶ï¼‰ه’ŒKapacitor(ه‘ٹè¦ç»„ن»¶ï¼‰ï¼Œو„ه»؛ن؛†ن¸€ن¸ھه®Œو•´çڑ„监وژ§è§£ه†³و–¹و،ˆم€‚而Graphite社هŒ؛ن¹ںوœ‰ن¸€ن؛›ç±»ن¼¼ç»„ن»¶ï¼Œه¦‚statsdه’Œgraphite-webم€‚ هœ¨ه…¼ه®¹و€§ه’Œهˆ†هڈ‘ç–ç•¥و–¹é¢...
é€ڑè؟‡ن¸ژه…¶ن»–组ن»¶ه¦‚Grafanaçڑ„é…چهگˆï¼Œهڈ¯ن»¥و„ه»؛ه‡؛ن¸€ه¥—ه®Œو•´çڑ„监وژ§è§£ه†³و–¹و،ˆï¼Œé€‚用ن؛ژçژ°ن»£ن؛‘هژںç”ںçژ¯ه¢ƒçڑ„监وژ§éœ€و±‚م€‚然而,هœ¨ç‰¹ه®ڑ需è¦پç²¾ç،®و•°وچ®çڑ„هœ؛و™¯ن¸‹ï¼ŒPrometheusهڈ¯èƒ½ن¸چوک¯وœ€ن½³é€‰و‹©م€‚هœ¨éƒ¨ç½²ه‰چ,ç،®ن؟网络é…چç½®و— 误وک¯è‡³ه…³é‡چè¦پçڑ„م€‚
虽然Mambo Collectorه·²ن¸چه†چوک¯وœ€و–°çڑ„解ه†³و–¹و،ˆï¼Œن½†ه…¶è®¾è®،çگ†ه؟µه’Œه®çژ°و–¹ه¼ڈه¯¹ن؛ژçگ†è§£ه¦‚ن½•é›†وˆگ监وژ§ه·¥ه…·ه’Œو•°وچ®ه؛“,ن»¥هڈٹه¦‚ن½•هˆ©ç”¨statsdè؟›è،Œو•°وچ®و”¶é›†ن»چ然هچپهˆ†وœ‰ç”¨م€‚ن½ هڈ¯ن»¥هڈ‚考ه…¶و؛گن»£ç پ,ه¦ن¹ ه¦‚ن½•و„ه»؛ç±»ن¼¼çڑ„و”¶é›†ه™¨ï¼Œوˆ–者ه¯»و‰¾...
é’ˆه¯¹è؟™ن؛›é—®é¢ک,解ه†³و–¹و،ˆé€ڑه¸¸و¶‰هڈٹوٹ€وœ¯é€‰ه‹ه’Œو¶و„设è®،م€‚ 首ه…ˆï¼Œوٹ€وœ¯é€‰ه‹وک¯è§£ه†³è؟™ن؛›é—®é¢کçڑ„ه…³é”®م€‚هœ¨é€‰و‹©و•°وچ®ه؛“وٹ€وœ¯و—¶ï¼Œéœ€è¦پ考虑ه¼€و؛گن¸ژé—و؛گçڑ„ه…ˆه¤©هں؛ه› م€‚ه¼€و؛گé،¹ç›®é€ڑه¸¸ه…·وœ‰و›´é«کçڑ„é€ڈوکژه؛¦م€پو´»è·ƒçڑ„社هŒ؛و”¯وŒپه’ŒوŒپç»çڑ„ç»´وٹ¤ï¼Œن½†...
**gostatsd** وک¯ن¸€ن¸ھهں؛ن؛ژ **Go** è¯è¨€ه®çژ°çڑ„网络ç»ںè®،ن»£çگ†ï¼Œه®ƒوک¯ Etsy çڑ„هژںه§‹ statsd ه®çژ°çڑ„ن¸€ن¸ھ...é€ڑè؟‡ه……هˆ†هˆ©ç”¨ Go è¯è¨€çڑ„ن¼کهٹ؟ه’Œ Atlassian çڑ„وŒپç»ç»´وٹ¤ï¼Œgostatsd 能ه¤ںن¸؛çژ°ن»£ن؛‘هژںç”ںçژ¯ه¢ƒوڈگن¾›é«کو•ˆم€پهڈ¯é çڑ„ç»ںè®،解ه†³و–¹و،ˆم€‚
Zabbixوک¯ن¸€و¬¾ه¼€و؛گ监وژ§è§£ه†³و–¹و،ˆï¼Œه®ƒوڈگن¾›ن؛†ه®و—¶ç›‘وژ§ç½‘络ه’Œه؛”用çڑ„هٹں能م€‚ 5. 监وژ§ن¸ژو—¥ه؟—هˆ†وگ - و¼”讲PPTوڈگهˆ°graphite+statsdم€پefk(Elasticsearch+Fluentd+Kibana)ن»¥هڈٹfluent-plugin-qqwryه’Œfluent-plugin-statsd,...
è؟™ن؛›ç»„ن»¶ه…±هگŒو„ه»؛ن؛†ن¸€ن¸ھه…¨é¢çڑ„监وژ§è§£ه†³و–¹و،ˆï¼Œè¦†ç›–ن؛†ن»ژهں؛ç،€و¶و„هˆ°ه؛”用وœچهٹ،çڑ„ه¤ڑن¸ھه±‚é¢ï¼Œç،®ن؟ن½ هڈ¯ن»¥هڈٹو—¶ن؛†è§£ç³»ç»ںè؟گè،Œçٹ¶ه†µه¹¶ه؛”ه¯¹هڈ¯èƒ½ه‡؛çژ°çڑ„é—®é¢کم€‚é€ڑè؟‡Prometheusçڑ„ه›¾ه½¢ç•Œé¢ï¼Œن½ هڈ¯ن»¥هڈ¯è§†هŒ–è؟™ن؛›وŒ‡و ‡ï¼Œهˆ›ه»؛è‡ھه®ڑن¹‰ن»ھè،¨و؟,...
3. **部署و¶و„**ï¼ڑJenkins被用ن½œهڈ‘ه¸ƒç³»ç»ں,结هگˆZabbixè؟›è،Œç³»ç»ں监وژ§ï¼ŒElasticsearchه’ŒGraphite + Statsdهˆ™وڈگن¾›و—¥ه؟—هکه‚¨ه’Œو€§èƒ½وŒ‡و ‡و”¶é›†م€‚ 4. **监وژ§ه‘ٹè¦و،†و¶**ï¼ڑFluentdن½œن¸؛و—¥ه؟—èپڑهگˆه·¥ه…·ï¼Œوگé…چfluent-plugin-qqwryه’Œ...
而هکه‚¨è§£ه†³و–¹و،ˆçڑ„选و‹©ه°†ç›´وژ¥ه½±ه“چهˆ°ç³»ç»ں能ه¤ںه¤„çگ†çڑ„و•°وچ®é‡ڈه’Œهژ†هڈ²و•°وچ®çڑ„ن؟هکو—¶é•؟م€‚هœ¨و£€ç´¢ه’Œه±•ç¤؛و–¹é¢ï¼Œç³»ç»ں需è¦پوœ‰é«کو•ˆçڑ„وں¥è¯¢وœ؛هˆ¶ه’Œçپµو´»çڑ„هڈ¯è§†هŒ–ه·¥ه…·ï¼Œن»¥é€‚ه؛”ن¸چهگŒçڑ„ن¸ڑهٹ،هœ؛و™¯ه’Œç”¨وˆ·éœ€و±‚م€‚ و¤ه¤–,系ç»ںçڑ„هڈ¯و‰©ه±•و€§ن¹ںوک¯ن¸€ن¸ھ...