
жң¬ж–Үе°Ҷз”ұжө…е…Ҙж·ұиҜҰз»Ҷд»Ӣз»ҚJavaеҶ…еӯҳеҲҶй…Қзҡ„еҺҹзҗҶпјҢд»Ҙеё®еҠ©ж–°жүӢжӣҙиҪ»жқҫзҡ„еӯҰд№ JavaгҖӮиҝҷзұ»ж–Үз« зҪ‘дёҠжңүеҫҲеӨҡпјҢдҪҶеӨ§еӨҡжҜ”иҫғйӣ¶зўҺгҖӮжң¬ж–Үд»Һи®ӨзҹҘиҝҮзЁӢи§’еәҰеҮәеҸ‘пјҢе°ҶеёҰз»ҷиҜ»иҖ…дёҖдёӘзі»з»ҹзҡ„д»Ӣз»ҚгҖӮ
иҝӣе…ҘжӯЈйўҳеүҚйҰ–е…ҲиҰҒзҹҘйҒ“зҡ„жҳҜJavaзЁӢеәҸиҝҗиЎҢеңЁJVM(Java Virtual MachineпјҢJavaиҷҡжӢҹжңә)дёҠпјҢеҸҜд»ҘжҠҠJVMзҗҶи§ЈжҲҗJavaзЁӢеәҸе’Ңж“ҚдҪңзі»з»ҹд№Ӣй—ҙзҡ„жЎҘжўҒпјҢJVMе®һзҺ°дәҶJavaзҡ„е№іеҸ°ж— е…іжҖ§пјҢз”ұжӯӨеҸҜи§ҒJVMзҡ„йҮҚиҰҒжҖ§гҖӮжүҖд»ҘеңЁеӯҰд№ JavaеҶ…еӯҳеҲҶй…ҚеҺҹзҗҶзҡ„ж—¶еҖҷдёҖе®ҡиҰҒзүўи®°иҝҷдёҖеҲҮйғҪжҳҜеңЁJVMдёӯиҝӣиЎҢзҡ„пјҢJVMжҳҜеҶ…еӯҳеҲҶй…ҚеҺҹзҗҶзҡ„еҹәзЎҖдёҺеүҚжҸҗгҖӮ
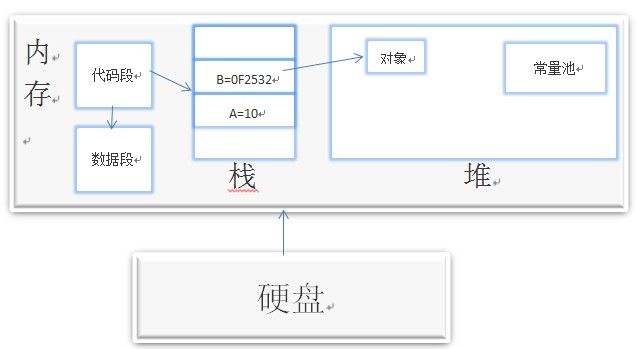
з®ҖеҚ•йҖҡдҝ—зҡ„и®ІпјҢдёҖдёӘе®Ңж•ҙзҡ„JavaзЁӢеәҸиҝҗиЎҢиҝҮзЁӢдјҡж¶үеҸҠд»ҘдёӢеҶ…еӯҳеҢәеҹҹпјҡ
В
l еҜ„еӯҳеҷЁпјҡJVMеҶ…йғЁиҷҡжӢҹеҜ„еӯҳеҷЁпјҢеӯҳеҸ–йҖҹеәҰйқһеёёеҝ«пјҢзЁӢеәҸдёҚеҸҜжҺ§еҲ¶гҖӮ
l ж ҲпјҡдҝқеӯҳеұҖйғЁеҸҳйҮҸзҡ„еҖјпјҢеҢ…жӢ¬пјҡ1.з”ЁжқҘдҝқеӯҳеҹәжң¬ж•°жҚ®зұ»еһӢзҡ„еҖјпјӣ2.дҝқеӯҳзұ»зҡ„е®һдҫӢпјҢеҚіе ҶеҢәеҜ№иұЎзҡ„еј•з”Ё(жҢҮй’Ҳ)гҖӮд№ҹеҸҜд»Ҙз”ЁжқҘдҝқеӯҳеҠ иҪҪж–№жі•ж—¶зҡ„её§гҖӮ
l е Ҷпјҡз”ЁжқҘеӯҳж”ҫеҠЁжҖҒдә§з”ҹзҡ„ж•°жҚ®пјҢжҜ”еҰӮnewеҮәжқҘзҡ„еҜ№иұЎгҖӮжіЁж„ҸеҲӣе»әеҮәжқҘзҡ„еҜ№иұЎеҸӘеҢ…еҗ«еұһдәҺеҗ„иҮӘзҡ„жҲҗе‘ҳеҸҳйҮҸпјҢ并дёҚеҢ…жӢ¬жҲҗе‘ҳж–№жі•гҖӮеӣ дёәеҗҢдёҖдёӘзұ»зҡ„еҜ№иұЎжӢҘжңүеҗ„иҮӘзҡ„жҲҗе‘ҳеҸҳйҮҸпјҢеӯҳеӮЁеңЁеҗ„иҮӘзҡ„е ҶдёӯпјҢдҪҶжҳҜ他们е…ұдә«иҜҘзұ»зҡ„ж–№жі•пјҢ并дёҚжҳҜжҜҸеҲӣе»әдёҖдёӘеҜ№иұЎе°ұжҠҠжҲҗе‘ҳж–№жі•еӨҚеҲ¶дёҖж¬ЎгҖӮ
l еёёйҮҸжұ пјҡJVMдёәжҜҸдёӘе·ІеҠ иҪҪзҡ„зұ»еһӢз»ҙжҠӨдёҖдёӘеёёйҮҸжұ пјҢеёёйҮҸжұ е°ұжҳҜиҝҷдёӘзұ»еһӢз”ЁеҲ°зҡ„еёёйҮҸзҡ„дёҖдёӘжңүеәҸйӣҶеҗҲгҖӮеҢ…жӢ¬зӣҙжҺҘеёёйҮҸ(еҹәжң¬зұ»еһӢпјҢString)е’ҢеҜ№е…¶д»–зұ»еһӢгҖҒж–№жі•гҖҒеӯ—ж®өзҡ„з¬ҰеҸ·еј•з”Ё(1)гҖӮжұ дёӯзҡ„ж•°жҚ®е’Ңж•°з»„дёҖж ·йҖҡиҝҮзҙўеј•и®ҝй—®гҖӮз”ұдәҺеёёйҮҸжұ еҢ…еҗ«дәҶдёҖдёӘзұ»еһӢжүҖжңүзҡ„еҜ№е…¶д»–зұ»еһӢгҖҒж–№жі•гҖҒеӯ—ж®өзҡ„з¬ҰеҸ·еј•з”ЁпјҢжүҖд»ҘеёёйҮҸжұ еңЁJavaзҡ„еҠЁжҖҒй“ҫжҺҘдёӯиө·дәҶж ёеҝғдҪңз”ЁгҖӮеёёйҮҸжұ еӯҳеңЁдәҺе ҶдёӯгҖӮ
l д»Јз Ғж®өпјҡз”ЁжқҘеӯҳж”ҫд»ҺзЎ¬зӣҳдёҠиҜ»еҸ–зҡ„жәҗзЁӢеәҸд»Јз ҒгҖӮ
l ж•°жҚ®ж®өпјҡз”ЁжқҘеӯҳж”ҫstaticе®ҡд№үзҡ„йқҷжҖҒжҲҗе‘ҳгҖӮ
В
дёӢйқўжҳҜеҶ…еӯҳиЎЁзӨәеӣҫпјҡ
В
В
В
В
В
дёҠеӣҫдёӯеӨ§иҮҙжҸҸиҝ°дәҶJavaеҶ…еӯҳеҲҶй…ҚпјҢжҺҘдёӢжқҘйҖҡиҝҮе®һдҫӢиҜҰз»Ҷи®Іи§ЈJavaзЁӢеәҸжҳҜеҰӮдҪ•еңЁеҶ…еӯҳдёӯиҝҗиЎҢзҡ„пјҲжіЁпјҡд»ҘдёӢеӣҫзүҮеј•з”ЁиҮӘе°ҡеӯҰе Ӯ马士е…өиҖҒеёҲзҡ„J2SEиҜҫ件пјҢеӣҫеҸідҫ§жҳҜзЁӢеәҸд»Јз ҒпјҢе·Ұдҫ§жҳҜеҶ…еӯҳеҲҶй…ҚзӨәж„ҸеӣҫпјҢжҲ‘дјҡдёҖдёҖеҠ дёҠжіЁйҮҠпјүгҖӮ
В
йў„еӨҮзҹҘиҜҶпјҡ
В
1.дёҖдёӘJavaж–Ү件пјҢеҸӘиҰҒжңүmainе…ҘеҸЈж–№жі•пјҢжҲ‘们е°ұи®ӨдёәиҝҷжҳҜдёҖдёӘJavaзЁӢеәҸпјҢеҸҜд»ҘеҚ•зӢ¬зј–иҜ‘иҝҗиЎҢгҖӮ
2.ж— и®әжҳҜжҷ®йҖҡзұ»еһӢзҡ„еҸҳйҮҸиҝҳжҳҜеј•з”Ёзұ»еһӢзҡ„еҸҳйҮҸ(дҝ—з§°е®һдҫӢ)пјҢйғҪеҸҜд»ҘдҪңдёәеұҖйғЁеҸҳйҮҸпјҢ他们йғҪеҸҜд»ҘеҮәзҺ°еңЁж ҲдёӯгҖӮеҸӘдёҚиҝҮжҷ®йҖҡзұ»еһӢзҡ„еҸҳйҮҸеңЁж ҲдёӯзӣҙжҺҘдҝқеӯҳе®ғжүҖеҜ№еә”зҡ„еҖјпјҢиҖҢеј•з”Ёзұ»еһӢзҡ„еҸҳйҮҸдҝқеӯҳзҡ„жҳҜдёҖдёӘжҢҮеҗ‘е ҶеҢәзҡ„жҢҮй’ҲпјҢйҖҡиҝҮиҝҷдёӘжҢҮй’ҲпјҢе°ұеҸҜд»ҘжүҫеҲ°иҝҷдёӘе®һдҫӢеңЁе ҶеҢәеҜ№еә”зҡ„еҜ№иұЎгҖӮеӣ жӯӨпјҢжҷ®йҖҡзұ»еһӢеҸҳйҮҸеҸӘеңЁж ҲеҢәеҚ з”ЁдёҖеқ—еҶ…еӯҳпјҢиҖҢеј•з”Ёзұ»еһӢеҸҳйҮҸиҰҒеңЁж ҲеҢәе’Ңе ҶеҢәеҗ„еҚ дёҖеқ—еҶ…еӯҳгҖӮ
В
зӨәдҫӢпјҡ
В

В
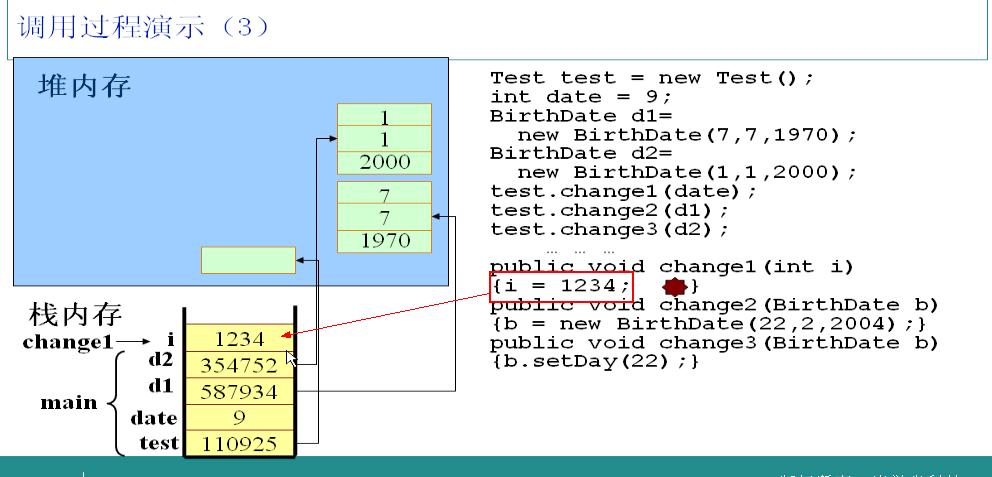
1.JVMиҮӘеҠЁеҜ»жүҫmainж–№жі•пјҢжү§иЎҢ第дёҖеҸҘд»Јз ҒпјҢеҲӣе»әдёҖдёӘTestзұ»зҡ„е®һдҫӢпјҢеңЁж ҲдёӯеҲҶй…ҚдёҖеқ—еҶ…еӯҳпјҢеӯҳж”ҫдёҖдёӘжҢҮеҗ‘е ҶеҢәеҜ№иұЎзҡ„жҢҮй’Ҳ110925гҖӮ
2.еҲӣе»әдёҖдёӘintеһӢзҡ„еҸҳйҮҸdateпјҢз”ұдәҺжҳҜеҹәжң¬зұ»еһӢпјҢзӣҙжҺҘеңЁж Ҳдёӯеӯҳж”ҫdateеҜ№еә”зҡ„еҖј9гҖӮ
3.еҲӣе»әдёӨдёӘBirthDateзұ»зҡ„е®һдҫӢd1гҖҒd2пјҢеңЁж ҲдёӯеҲҶеҲ«еӯҳж”ҫдәҶеҜ№еә”зҡ„жҢҮй’ҲжҢҮеҗ‘еҗ„иҮӘзҡ„еҜ№иұЎгҖӮ他们еңЁе®һдҫӢеҢ–ж—¶и°ғз”ЁдәҶжңүеҸӮж•°зҡ„жһ„йҖ ж–№жі•пјҢеӣ жӯӨеҜ№иұЎдёӯжңүиҮӘе®ҡд№үеҲқе§ӢеҖјгҖӮ
В

В
и°ғз”ЁtestеҜ№иұЎзҡ„change1ж–№жі•пјҢ并且д»ҘdateдёәеҸӮж•°гҖӮJVMиҜ»еҲ°иҝҷж®өд»Јз Ғж—¶пјҢжЈҖжөӢеҲ°iжҳҜеұҖйғЁеҸҳйҮҸпјҢеӣ жӯӨдјҡжҠҠiж”ҫеңЁж ҲдёӯпјҢ并且жҠҠdateзҡ„еҖјиөӢз»ҷiгҖӮ
В
В
жҠҠ1234иөӢз»ҷiгҖӮеҫҲз®ҖеҚ•зҡ„дёҖжӯҘгҖӮ
В

В
change1ж–№жі•жү§иЎҢе®ҢжҜ•пјҢз«ӢеҚійҮҠж”ҫеұҖйғЁеҸҳйҮҸiжүҖеҚ з”Ёзҡ„ж Ҳз©әй—ҙгҖӮ
В
В
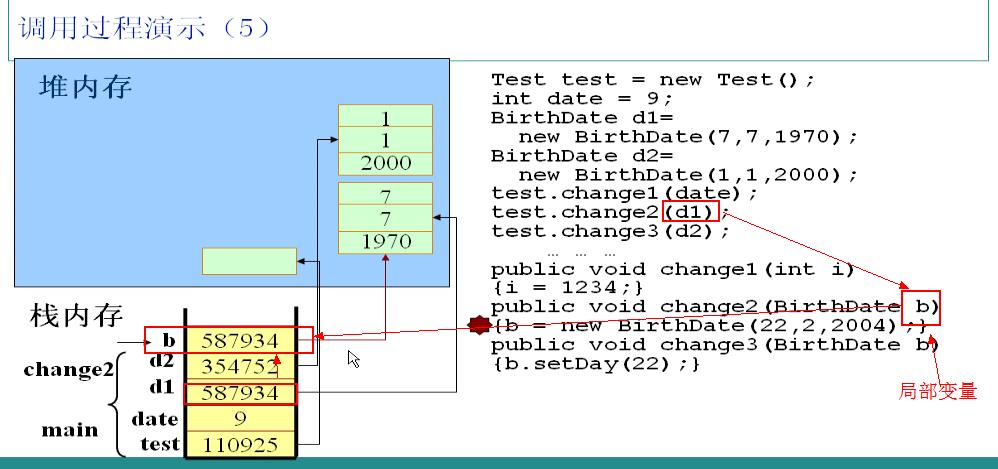
и°ғз”ЁtestеҜ№иұЎзҡ„change2ж–№жі•пјҢд»Ҙе®һдҫӢd1дёәеҸӮж•°гҖӮJVMжЈҖжөӢеҲ°change2ж–№жі•дёӯзҡ„bеҸӮж•°дёәеұҖйғЁеҸҳйҮҸпјҢз«ӢеҚіеҠ е…ҘеҲ°ж ҲдёӯпјҢз”ұдәҺжҳҜеј•з”Ёзұ»еһӢзҡ„еҸҳйҮҸпјҢжүҖд»Ҙbдёӯдҝқеӯҳзҡ„жҳҜd1дёӯзҡ„жҢҮй’ҲпјҢжӯӨж—¶bе’Ңd1жҢҮеҗ‘еҗҢдёҖдёӘе Ҷдёӯзҡ„еҜ№иұЎгҖӮеңЁbе’Ңd1д№Ӣй—ҙдј йҖ’жҳҜжҢҮй’ҲгҖӮ
В

В
change2ж–№жі•дёӯеҸҲе®һдҫӢеҢ–дәҶдёҖдёӘBirthDateеҜ№иұЎпјҢ并且иөӢз»ҷbгҖӮеңЁеҶ…йғЁжү§иЎҢиҝҮзЁӢжҳҜпјҡеңЁе ҶеҢәnewдәҶдёҖдёӘеҜ№иұЎпјҢ并且жҠҠиҜҘеҜ№иұЎзҡ„жҢҮй’ҲдҝқеӯҳеңЁж Ҳдёӯзҡ„bеҜ№еә”з©әй—ҙпјҢжӯӨж—¶е®һдҫӢbдёҚеҶҚжҢҮеҗ‘е®һдҫӢd1жүҖжҢҮеҗ‘зҡ„еҜ№иұЎпјҢдҪҶжҳҜе®һдҫӢd1жүҖжҢҮеҗ‘зҡ„еҜ№иұЎе№¶ж— еҸҳеҢ–пјҢиҝҷж ·ж— жі•еҜ№d1йҖ жҲҗд»»дҪ•еҪұе“ҚгҖӮ
В

В
change2ж–№жі•жү§иЎҢе®ҢжҜ•пјҢз«ӢеҚійҮҠж”ҫеұҖйғЁеј•з”ЁеҸҳйҮҸbжүҖеҚ зҡ„ж Ҳз©әй—ҙпјҢжіЁж„ҸеҸӘжҳҜйҮҠж”ҫдәҶж Ҳз©әй—ҙпјҢе Ҷз©әй—ҙиҰҒзӯүеҫ…иҮӘеҠЁеӣһ收гҖӮ
В
В
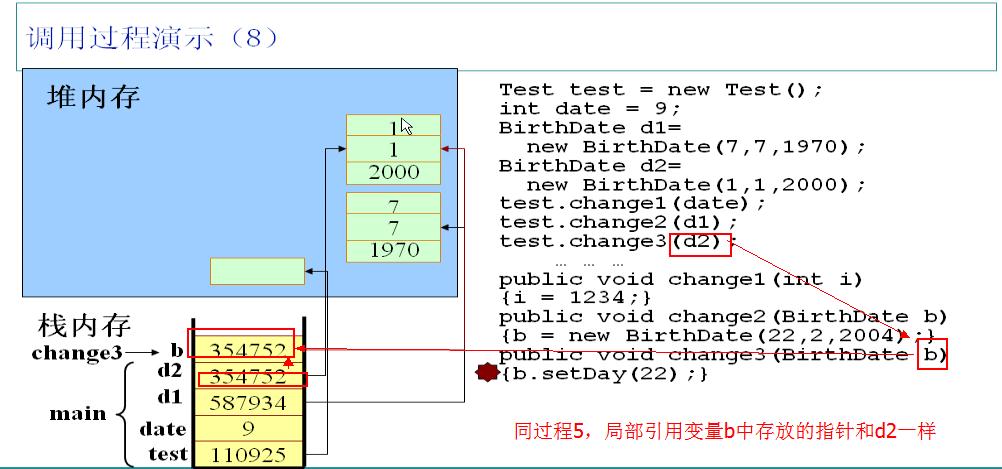
и°ғз”Ёtestе®һдҫӢзҡ„change3ж–№жі•пјҢд»Ҙе®һдҫӢd2дёәеҸӮж•°гҖӮеҗҢзҗҶпјҢJVMдјҡеңЁж ҲдёӯдёәеұҖйғЁеј•з”ЁеҸҳйҮҸbеҲҶй…Қз©әй—ҙпјҢ并且жҠҠd2дёӯзҡ„жҢҮй’Ҳеӯҳж”ҫеңЁbдёӯпјҢжӯӨж—¶d2е’ҢbжҢҮеҗ‘еҗҢдёҖдёӘеҜ№иұЎгҖӮеҶҚи°ғз”Ёе®һдҫӢbзҡ„setDayж–№жі•пјҢе…¶е®һе°ұжҳҜи°ғз”Ёd2жҢҮеҗ‘зҡ„еҜ№иұЎзҡ„setDayж–№жі•гҖӮ
В

В
и°ғз”Ёе®һдҫӢbзҡ„setDayж–№жі•дјҡеҪұе“Қd2пјҢеӣ дёәдәҢиҖ…жҢҮеҗ‘зҡ„жҳҜеҗҢдёҖдёӘеҜ№иұЎгҖӮ
В

В
change3ж–№жі•жү§иЎҢе®ҢжҜ•пјҢз«ӢеҚійҮҠж”ҫеұҖйғЁеј•з”ЁеҸҳйҮҸbгҖӮ
В
д»ҘдёҠе°ұжҳҜJavaзЁӢеәҸиҝҗиЎҢж—¶еҶ…еӯҳеҲҶй…Қзҡ„еӨ§иҮҙжғ…еҶөгҖӮе…¶е®һд№ҹжІЎд»Җд№ҲпјҢжҺҢжҸЎдәҶжҖқжғіе°ұеҫҲз®ҖеҚ•дәҶгҖӮж— йқһе°ұжҳҜдёӨз§Қзұ»еһӢзҡ„еҸҳйҮҸпјҡеҹәжң¬зұ»еһӢе’Ңеј•з”Ёзұ»еһӢгҖӮдәҢиҖ…дҪңдёәеұҖйғЁеҸҳйҮҸпјҢйғҪж”ҫеңЁж ҲдёӯпјҢеҹәжң¬зұ»еһӢзӣҙжҺҘеңЁж ҲдёӯдҝқеӯҳеҖјпјҢеј•з”Ёзұ»еһӢеҸӘдҝқеӯҳдёҖдёӘжҢҮеҗ‘е ҶеҢәзҡ„жҢҮй’ҲпјҢзңҹжӯЈзҡ„еҜ№иұЎеңЁе ҶйҮҢгҖӮдҪңдёәеҸӮж•°ж—¶еҹәжң¬зұ»еһӢе°ұзӣҙжҺҘдј еҖјпјҢеј•з”Ёзұ»еһӢдј жҢҮй’ҲгҖӮ
В
е°Ҹз»“пјҡ
В
1.еҲҶжё…д»Җд№ҲжҳҜе®һдҫӢд»Җд№ҲжҳҜеҜ№иұЎгҖӮClass a= new Class();жӯӨж—¶aеҸ«е®һдҫӢпјҢиҖҢдёҚиғҪиҜҙaжҳҜеҜ№иұЎгҖӮе®һдҫӢеңЁж ҲдёӯпјҢеҜ№иұЎеңЁе ҶдёӯпјҢж“ҚдҪңе®һдҫӢе®һйҷ…дёҠжҳҜйҖҡиҝҮе®һдҫӢзҡ„жҢҮй’Ҳй—ҙжҺҘж“ҚдҪңеҜ№иұЎгҖӮеӨҡдёӘе®һдҫӢеҸҜд»ҘжҢҮеҗ‘еҗҢдёҖдёӘеҜ№иұЎгҖӮ
2.ж Ҳдёӯзҡ„ж•°жҚ®е’Ңе Ҷдёӯзҡ„ж•°жҚ®й”ҖжҜҒ并дёҚжҳҜеҗҢжӯҘзҡ„гҖӮж–№жі•дёҖж—Ұз»“жқҹпјҢж Ҳдёӯзҡ„еұҖйғЁеҸҳйҮҸз«ӢеҚій”ҖжҜҒпјҢдҪҶжҳҜе ҶдёӯеҜ№иұЎдёҚдёҖе®ҡй”ҖжҜҒгҖӮеӣ дёәеҸҜиғҪжңүе…¶д»–еҸҳйҮҸд№ҹжҢҮеҗ‘дәҶиҝҷдёӘеҜ№иұЎпјҢзӣҙеҲ°ж ҲдёӯжІЎжңүеҸҳйҮҸжҢҮеҗ‘е Ҷдёӯзҡ„еҜ№иұЎж—¶пјҢе®ғжүҚй”ҖжҜҒпјҢиҖҢдё”иҝҳдёҚжҳҜ马дёҠй”ҖжҜҒпјҢиҰҒзӯүеһғеңҫеӣһ收жү«жҸҸж—¶жүҚеҸҜд»Ҙиў«й”ҖжҜҒгҖӮ
3.д»ҘдёҠзҡ„ж ҲгҖҒе ҶгҖҒд»Јз Ғж®өгҖҒж•°жҚ®ж®өзӯүзӯүйғҪжҳҜзӣёеҜ№дәҺеә”з”ЁзЁӢеәҸиҖҢиЁҖзҡ„гҖӮжҜҸдёҖдёӘеә”з”ЁзЁӢеәҸйғҪеҜ№еә”е”ҜдёҖзҡ„дёҖдёӘJVMе®һдҫӢпјҢжҜҸдёҖдёӘJVMе®һдҫӢйғҪжңүиҮӘе·ұзҡ„еҶ…еӯҳеҢәеҹҹпјҢдә’дёҚеҪұе“ҚгҖӮ并且иҝҷдәӣеҶ…еӯҳеҢәеҹҹжҳҜжүҖжңүзәҝзЁӢе…ұдә«зҡ„гҖӮиҝҷйҮҢжҸҗеҲ°зҡ„ж Ҳе’Ңе ҶйғҪжҳҜж•ҙдҪ“дёҠзҡ„жҰӮеҝөпјҢиҝҷдәӣе Ҷж ҲиҝҳеҸҜд»Ҙз»ҶеҲҶгҖӮ
4.зұ»зҡ„жҲҗе‘ҳеҸҳйҮҸеңЁдёҚеҗҢеҜ№иұЎдёӯеҗ„дёҚзӣёеҗҢпјҢйғҪжңүиҮӘе·ұзҡ„еӯҳеӮЁз©әй—ҙ(жҲҗе‘ҳеҸҳйҮҸеңЁе Ҷдёӯзҡ„еҜ№иұЎдёӯ)гҖӮиҖҢзұ»зҡ„ж–№жі•еҚҙжҳҜиҜҘзұ»зҡ„жүҖжңүеҜ№иұЎе…ұдә«зҡ„пјҢеҸӘжңүдёҖеҘ—пјҢеҜ№иұЎдҪҝз”Ёж–№жі•зҡ„ж—¶еҖҷж–№жі•жүҚиў«еҺӢе…Ҙж ҲпјҢж–№жі•дёҚдҪҝз”ЁеҲҷдёҚеҚ з”ЁеҶ…еӯҳгҖӮ
В
д»ҘдёҠеҲҶжһҗеҸӘж¶үеҸҠдәҶж Ҳе’Ңе ҶпјҢиҝҳжңүдёҖдёӘйқһеёёйҮҚиҰҒзҡ„еҶ…еӯҳеҢәеҹҹпјҡеёёйҮҸжұ пјҢиҝҷдёӘең°ж–№еҫҖеҫҖеҮәзҺ°дёҖдәӣиҺ«еҗҚе…¶еҰҷзҡ„й—®йўҳгҖӮеёёйҮҸжұ жҳҜе№Іеҳӣзҡ„дёҠиҫ№е·Із»ҸиҜҙжҳҺдәҶпјҢд№ҹжІЎеҝ…иҰҒзҗҶи§ЈеӨҡд№Ҳж·ұеҲ»пјҢеҸӘиҰҒи®°дҪҸе®ғз»ҙжҠӨдәҶдёҖдёӘе·ІеҠ иҪҪзұ»зҡ„еёёйҮҸе°ұеҸҜд»ҘдәҶгҖӮжҺҘдёӢжқҘз»“еҗҲдёҖдәӣдҫӢеӯҗиҜҙжҳҺеёёйҮҸжұ зҡ„зү№жҖ§гҖӮ
В
йў„еӨҮзҹҘиҜҶпјҡ
В
еҹәжң¬зұ»еһӢе’Ңеҹәжң¬зұ»еһӢзҡ„еҢ…иЈ…зұ»гҖӮеҹәжң¬зұ»еһӢжңүпјҡbyteгҖҒshortгҖҒcharгҖҒintгҖҒlongгҖҒbooleanгҖӮеҹәжң¬зұ»еһӢзҡ„еҢ…иЈ…зұ»еҲҶеҲ«жҳҜпјҡByteгҖҒShortгҖҒCharacterгҖҒIntegerгҖҒLongгҖҒBooleanгҖӮжіЁж„ҸеҢәеҲҶеӨ§е°ҸеҶҷгҖӮдәҢиҖ…зҡ„еҢәеҲ«жҳҜпјҡеҹәжң¬зұ»еһӢдҪ“зҺ°еңЁзЁӢеәҸдёӯжҳҜжҷ®йҖҡеҸҳйҮҸпјҢеҹәжң¬зұ»еһӢзҡ„еҢ…иЈ…зұ»жҳҜзұ»пјҢдҪ“зҺ°еңЁзЁӢеәҸдёӯжҳҜеј•з”ЁеҸҳйҮҸгҖӮеӣ жӯӨдәҢиҖ…еңЁеҶ…еӯҳдёӯзҡ„еӯҳеӮЁдҪҚзҪ®дёҚеҗҢпјҡеҹәжң¬зұ»еһӢеӯҳеӮЁеңЁж ҲдёӯпјҢиҖҢеҹәжң¬зұ»еһӢеҢ…иЈ…зұ»еӯҳеӮЁеңЁе ҶдёӯгҖӮдёҠиҫ№жҸҗеҲ°зҡ„иҝҷдәӣеҢ…иЈ…зұ»йғҪе®һзҺ°дәҶеёёйҮҸжұ жҠҖжңҜпјҢеҸҰеӨ–дёӨз§Қжө®зӮ№ж•°зұ»еһӢзҡ„еҢ…иЈ…зұ»еҲҷжІЎжңүе®һзҺ°гҖӮеҸҰеӨ–пјҢStringзұ»еһӢд№ҹе®һзҺ°дәҶеёёйҮҸжұ жҠҖжңҜгҖӮ
В
В
е®һдҫӢпјҡ
- publicВ classВ testВ {В В
- В В В В publicВ staticВ voidВ main(String[]В args)В {В В В В В В
- В В В В В В В В objPoolTest();В В
- В В В В }В В
- В В
- В В В В publicВ staticВ voidВ objPoolTest()В {В В
- В В В В В В В В intВ iВ =В 40;В В
- В В В В В В В В intВ i0В =В 40;В В
- В В В В В В В В IntegerВ i1В =В 40;В В
- В В В В В В В В IntegerВ i2В =В 40;В В
- В В В В В В В В IntegerВ i3В =В 0;В В
- В В В В В В В В IntegerВ i4В =В newВ Integer(40);В В
- В В В В В В В В IntegerВ i5В =В newВ Integer(40);В В
- В В В В В В В В IntegerВ i6В =В newВ Integer(0);В В
- В В В В В В В В DoubleВ d1=1.0;В В
- В В В В В В В В DoubleВ d2=1.0;В В
- В В В В В В В В В В
- В В В В В В В В System.out.println("i=i0\t"В +В (iВ ==В i0));В В
- В В В В В В В В System.out.println("i1=i2\t"В +В (i1В ==В i2));В В
- В В В В В В В В System.out.println("i1=i2+i3\t"В +В (i1В ==В i2В +В i3));В В
- В В В В В В В В System.out.println("i4=i5\t"В +В (i4В ==В i5));В В
- В В В В В В В В System.out.println("i4=i5+i6\t"В +В (i4В ==В i5В +В i6));В В В В В В
- В В В В В В В В System.out.println("d1=d2\t"В +В (d1==d2));В В В
- В В В В В В В В В В
- В В В В В В В В System.out.println();В В В В В В В В В В
- В В В В }В В
- }В В
public class test {
public static void main(String[] args) {
objPoolTest();
}
public static void objPoolTest() {
int i = 40;
int i0 = 40;
Integer i1 = 40;
Integer i2 = 40;
Integer i3 = 0;
Integer i4 = new Integer(40);
Integer i5 = new Integer(40);
Integer i6 = new Integer(0);
Double d1=1.0;
Double d2=1.0;
System.out.println("i=i0\t" + (i == i0));
System.out.println("i1=i2\t" + (i1 == i2));
System.out.println("i1=i2+i3\t" + (i1 == i2 + i3));
System.out.println("i4=i5\t" + (i4 == i5));
System.out.println("i4=i5+i6\t" + (i4 == i5 + i6));
System.out.println("d1=d2\t" + (d1==d2));
System.out.println();
}
}
В
В
з»“жһңпјҡ
- i=i0В В В В trueВ В
- i1=i2В В В trueВ В
- i1=i2+i3В В В В В В В В trueВ В
- i4=i5В В В falseВ В
- i4=i5+i6В В В В В В В В trueВ В
- d1=d2В В В falseВ В
i=i0 true i1=i2 true i1=i2+i3 true i4=i5 false i4=i5+i6 true d1=d2 false
В
з»“жһңеҲҶжһҗпјҡ
В
1.iе’Ңi0еқҮжҳҜжҷ®йҖҡзұ»еһӢ(int)зҡ„еҸҳйҮҸпјҢжүҖд»Ҙж•°жҚ®зӣҙжҺҘеӯҳеӮЁеңЁж ҲдёӯпјҢиҖҢж ҲжңүдёҖдёӘеҫҲйҮҚиҰҒзҡ„зү№жҖ§пјҡж Ҳдёӯзҡ„ж•°жҚ®еҸҜд»Ҙе…ұдә«гҖӮеҪ“жҲ‘们е®ҡд№үдәҶint i = 40;пјҢеҶҚе®ҡд№үint i0 = 40;иҝҷж—¶еҖҷдјҡиҮӘеҠЁжЈҖжҹҘж ҲдёӯжҳҜеҗҰжңү40иҝҷдёӘж•°жҚ®пјҢеҰӮжһңжңүпјҢi0дјҡзӣҙжҺҘжҢҮеҗ‘iзҡ„40пјҢдёҚдјҡеҶҚж·»еҠ дёҖдёӘж–°зҡ„40гҖӮ
2.i1е’Ңi2еқҮжҳҜеј•з”Ёзұ»еһӢпјҢеңЁж ҲдёӯеӯҳеӮЁжҢҮй’ҲпјҢеӣ дёәIntegerжҳҜеҢ…иЈ…зұ»гҖӮз”ұдәҺIntegerеҢ…иЈ…зұ»е®һзҺ°дәҶеёёйҮҸжұ жҠҖжңҜпјҢеӣ жӯӨi1гҖҒi2зҡ„40еқҮжҳҜд»ҺеёёйҮҸжұ дёӯиҺ·еҸ–зҡ„пјҢеқҮжҢҮеҗ‘еҗҢдёҖдёӘең°еқҖпјҢеӣ жӯӨi1=12гҖӮ
3.еҫҲжҳҺжҳҫиҝҷжҳҜдёҖдёӘеҠ жі•иҝҗз®—пјҢJavaзҡ„ж•°еӯҰиҝҗз®—йғҪжҳҜеңЁж ҲдёӯиҝӣиЎҢзҡ„пјҢJavaдјҡиҮӘеҠЁеҜ№i1гҖҒi2иҝӣиЎҢжӢҶз®ұж“ҚдҪңиҪ¬еҢ–жҲҗж•ҙеһӢпјҢеӣ жӯӨi1еңЁж•°еҖјдёҠзӯүдәҺi2+i3гҖӮ
4.i4е’Ңi5еқҮжҳҜеј•з”Ёзұ»еһӢпјҢеңЁж ҲдёӯеӯҳеӮЁжҢҮй’ҲпјҢеӣ дёәIntegerжҳҜеҢ…иЈ…зұ»гҖӮдҪҶжҳҜз”ұдәҺ他们еҗ„иҮӘйғҪжҳҜnewеҮәжқҘзҡ„пјҢеӣ жӯӨдёҚеҶҚд»ҺеёёйҮҸжұ еҜ»жүҫж•°жҚ®пјҢиҖҢжҳҜд»Һе Ҷдёӯеҗ„иҮӘnewдёҖдёӘеҜ№иұЎпјҢ然еҗҺеҗ„иҮӘдҝқеӯҳжҢҮеҗ‘еҜ№иұЎзҡ„жҢҮй’ҲпјҢжүҖд»Ҙi4е’Ңi5дёҚзӣёзӯүпјҢеӣ дёә他们жүҖеӯҳжҢҮй’ҲдёҚеҗҢпјҢжүҖжҢҮеҗ‘еҜ№иұЎдёҚеҗҢгҖӮ
5.иҝҷд№ҹжҳҜдёҖдёӘеҠ жі•иҝҗз®—пјҢе’Ң3еҗҢзҗҶгҖӮ
6.d1е’Ңd2еқҮжҳҜеј•з”Ёзұ»еһӢпјҢеңЁж ҲдёӯеӯҳеӮЁжҢҮй’ҲпјҢеӣ дёәDoubleжҳҜеҢ…иЈ…зұ»гҖӮдҪҶDoubleеҢ…иЈ…зұ»жІЎжңүе®һзҺ°еёёйҮҸжұ жҠҖжңҜпјҢеӣ жӯӨDoubled1=1.0;зӣёеҪ“дәҺDouble d1=new Double(1.0);пјҢжҳҜд»Һе ҶnewдёҖдёӘеҜ№иұЎпјҢd2еҗҢзҗҶгҖӮеӣ жӯӨd1е’Ңd2еӯҳж”ҫзҡ„жҢҮй’ҲдёҚеҗҢпјҢжҢҮеҗ‘зҡ„еҜ№иұЎдёҚеҗҢпјҢжүҖд»ҘдёҚзӣёзӯүгҖӮ
В
е°Ҹз»“пјҡ
В
1.д»ҘдёҠжҸҗеҲ°зҡ„еҮ з§Қеҹәжң¬зұ»еһӢеҢ…иЈ…зұ»еқҮе®һзҺ°дәҶеёёйҮҸжұ жҠҖжңҜпјҢдҪҶ他们з»ҙжҠӨзҡ„еёёйҮҸд»…д»…жҳҜгҖҗ-128иҮі127гҖ‘иҝҷдёӘиҢғеӣҙеҶ…зҡ„еёёйҮҸпјҢеҰӮжһңеёёйҮҸеҖји¶…иҝҮиҝҷдёӘиҢғеӣҙпјҢе°ұдјҡд»Һе ҶдёӯеҲӣе»әеҜ№иұЎпјҢдёҚеҶҚд»ҺеёёйҮҸжұ дёӯеҸ–гҖӮжҜ”еҰӮпјҢжҠҠдёҠиҫ№дҫӢеӯҗж”№жҲҗInteger i1 = 400; Integer i2 = 400;пјҢеҫҲжҳҺжҳҫи¶…иҝҮдәҶ127пјҢж— жі•д»ҺеёёйҮҸжұ иҺ·еҸ–еёёйҮҸпјҢе°ұиҰҒд»Һе Ҷдёӯnewж–°зҡ„IntegerеҜ№иұЎпјҢиҝҷж—¶i1е’Ңi2е°ұдёҚзӣёзӯүдәҶгҖӮ
2.Stringзұ»еһӢд№ҹе®һзҺ°дәҶеёёйҮҸжұ жҠҖжңҜпјҢдҪҶжҳҜзЁҚеҫ®жңүзӮ№дёҚеҗҢгҖӮStringеһӢжҳҜе…ҲжЈҖжөӢеёёйҮҸжұ дёӯжңүжІЎжңүеҜ№еә”еӯ—з¬ҰдёІпјҢеҰӮжһңжңүпјҢеҲҷеҸ–еҮәжқҘпјӣеҰӮжһңжІЎжңүпјҢеҲҷжҠҠеҪ“еүҚзҡ„ж·»еҠ иҝӣеҺ»гҖӮ
В
еҮЎжҳҜж¶үеҸҠеҶ…еӯҳеҺҹзҗҶпјҢдёҖиҲ¬йғҪжҳҜеҚҡеӨ§зІҫж·ұзҡ„йўҶеҹҹпјҢеҲҮеӢҝеҗ¬дҝЎдёҖ家д№ӢиЁҖпјҢеӨҡиҜ»дәӣж–Үз« гҖӮжҲ‘еңЁиҝҷеҸӘжҳҜжө…жһҗпјҢйҮҢиҫ№иҝҳжңүеҫҲеӨҡзҢ«и…»пјҢе°ұз•ҷз»ҷиҜ»иҖ…жҺўзҙўжҖқиҖғдәҶгҖӮеёҢжңӣжң¬ж–ҮиғҪеҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҒ
В
и„ҡжіЁпјҡ
В
(1) з¬ҰеҸ·еј•з”ЁпјҢйЎҫеҗҚжҖқд№үпјҢе°ұжҳҜдёҖдёӘз¬ҰеҸ·пјҢз¬ҰеҸ·еј•з”Ёиў«дҪҝз”Ёзҡ„ж—¶еҖҷпјҢжүҚдјҡи§ЈжһҗиҝҷдёӘз¬ҰеҸ·гҖӮеҰӮжһңзҶҹжӮүlinuxжҲ–unixзі»з»ҹзҡ„пјҢеҸҜд»ҘжҠҠиҝҷдёӘз¬ҰеҸ·еј•з”ЁзңӢдҪңдёҖдёӘж–Ү件зҡ„иҪҜй“ҫжҺҘпјҢеҪ“дҪҝз”ЁиҝҷдёӘиҪҜиҝһжҺҘзҡ„ж—¶еҖҷпјҢжүҚдјҡзңҹжӯЈи§Јжһҗе®ғпјҢеұ•ејҖе®ғжүҫеҲ°е®һйҷ…зҡ„ж–Ү件
еҜ№дәҺз¬ҰеҸ·еј•з”ЁпјҢеңЁзұ»еҠ иҪҪеұӮйқўдёҠи®Ёи®әжҜ”иҫғеӨҡпјҢжәҗз Ғзә§еҲ«еҸӘжҳҜдёҖдёӘеҪўејҸдёҠзҡ„и®Ёи®әгҖӮ
еҪ“дёҖдёӘзұ»иў«еҠ иҪҪж—¶пјҢиҜҘзұ»жүҖз”ЁеҲ°зҡ„еҲ«зҡ„зұ»зҡ„з¬ҰеҸ·еј•з”ЁйғҪдјҡдҝқеӯҳеңЁеёёйҮҸжұ пјҢе®һйҷ…д»Јз Ғжү§иЎҢзҡ„ж—¶еҖҷпјҢйҰ–ж¬ЎйҒҮеҲ°жҹҗдёӘеҲ«зҡ„зұ»ж—¶пјҢJVMдјҡеҜ№еёёйҮҸжұ зҡ„иҜҘзұ»зҡ„з¬ҰеҸ·еј•з”Ёеұ•ејҖпјҢиҪ¬дёәзӣҙжҺҘеј•з”ЁпјҢиҝҷж ·дёӢж¬ЎеҶҚйҒҮеҲ°еҗҢж ·зҡ„зұ»еһӢж—¶пјҢJVMе°ұдёҚеҶҚи§ЈжһҗпјҢиҖҢзӣҙжҺҘдҪҝз”ЁиҝҷдёӘе·Із»Ҹиў«и§ЈжһҗиҝҮзҡ„зӣҙжҺҘеј•з”ЁгҖӮ
йҷӨдәҶдёҠиҝ°зҡ„зұ»еҠ иҪҪиҝҮзЁӢзҡ„з¬ҰеҸ·еј•з”ЁиҜҙжі•пјҢеҜ№дәҺжәҗз Ғзә§еҲ«жқҘиҜҙпјҢе°ұжҳҜдҫқз…§еј•з”Ёзҡ„и§ЈжһҗиҝҮзЁӢжқҘеҢәеҲ«д»Јз Ғдёӯжҹҗдәӣж•°жҚ®еұһдәҺз¬ҰеҸ·еј•з”ЁиҝҳжҳҜзӣҙжҺҘеј•з”ЁпјҢеҰӮпјҢSystem.out.println("test" +"abc");//иҝҷйҮҢеҸ‘з”ҹзҡ„ж•ҲжһңзӣёеҪ“дәҺзӣҙжҺҘеј•з”ЁпјҢиҖҢеҒҮи®ҫжҹҗдёӘStrings = "abc"; System.out.println("test" + s);//иҝҷйҮҢзҡ„еҸ‘з”ҹзҡ„ж•ҲжһңзӣёеҪ“дәҺз¬ҰеҸ·еј•з”ЁпјҢеҚіжҠҠsеұ•ејҖи§ЈжһҗпјҢд№ҹе°ұзӣёеҪ“дәҺsжҳҜ"abc"зҡ„дёҖдёӘз¬ҰеҸ·й“ҫжҺҘпјҢд№ҹе°ұжҳҜиҜҙеңЁзј–иҜ‘зҡ„ж—¶еҖҷпјҢclassж–Ү件并没жңүзӣҙжҺҘеұ•зңӢsпјҢиҖҢжҠҠиҝҷдёӘsзңӢдҪңдёҖдёӘз¬ҰеҸ·пјҢеңЁе®һйҷ…зҡ„д»Јз Ғжү§иЎҢж—¶пјҢжүҚдјҡеұ•ејҖиҝҷдёӘгҖӮ
В
еҸӮиҖғж–Үз« пјҡ
В
В
javaеҶ…еӯҳеҲҶй…Қз ”з©¶пјҡhttp://www.blogjava.net/Jack2007/archive/2008/05/21/202018.html
JavaеёёйҮҸжұ иҜҰи§Јд№ӢдёҖйҒ“жҜ”иҫғиӣӢз–јзҡ„йқўиҜ•йўҳпјҡhttp://www.cnblogs.com/DreamSea/archive/2011/11/20/2256396.html
jvmеёёйҮҸжұ пјҡhttp://www.cnblogs.com/wenfeng762/archive/2011/08/14/2137820.html
ж·ұе…ҘJavaж ёеҝғ JavaеҶ…еӯҳеҲҶй…ҚеҺҹзҗҶзІҫи®Іпјҡhttp://developer.51cto.com/art/201009/225071.htm



зӣёе…іжҺЁиҚҗ
JavaеҶ…еӯҳеҲҶй…ҚжҳҜJavaзј–зЁӢдёӯйқһеёёйҮҚиҰҒзҡ„жҰӮеҝөпјҢе®ғж¶үеҸҠеҲ°зЁӢеәҸиҝҗиЎҢж—¶зҡ„ж•°жҚ®еӯҳеӮЁе’Ңз®ЎзҗҶгҖӮJavaзЁӢеәҸеңЁJVMпјҲJava Virtual MachineпјҢJavaиҷҡжӢҹжңәпјүдёҠиҝҗиЎҢпјҢJVMдҪңдёәдёҖдёӘе№іеҸ°ж— е…ізҡ„жү§иЎҢзҺҜеўғпјҢиҙҹиҙЈJavaзЁӢеәҸзҡ„еҶ…еӯҳз®ЎзҗҶе’Ңжү§иЎҢгҖӮзҗҶи§Ј...
жң¬ж–Үе°Ҷз”ұжө…е…Ҙж·ұиҜҰз»Ҷд»Ӣз»ҚJavaеҶ…еӯҳеҲҶй…Қзҡ„еҺҹзҗҶпјҢд»Ҙеё®еҠ©ж–°жүӢжӣҙиҪ»жқҫзҡ„еӯҰд№ JavaгҖӮиҝҷзұ»ж–Үз« зҪ‘дёҠжңүеҫҲеӨҡпјҢдҪҶеӨ§еӨҡжҜ”иҫғйӣ¶зўҺгҖӮжң¬ж–Үд»Һи®ӨзҹҘиҝҮзЁӢи§’еәҰеҮәеҸ‘пјҢе°ҶеёҰз»ҷиҜ»иҖ…дёҖдёӘзі»з»ҹзҡ„д»Ӣз»ҚгҖӮиҝӣе…ҘжӯЈйўҳеүҚйҰ–е…ҲиҰҒзҹҘйҒ“зҡ„жҳҜJavaзЁӢеәҸиҝҗиЎҢеңЁJVM...
### Javaдёӯе ҶеҶ…еӯҳдёҺж ҲеҶ…еӯҳеҲҶй…Қжө…жһҗ #### дёҖгҖҒеј•иЁҖ еңЁJavaзј–зЁӢиҜӯиЁҖдёӯпјҢеҶ…еӯҳз®ЎзҗҶжҳҜдёҖйЎ№иҮіе…ійҮҚиҰҒзҡ„жҠҖжңҜгҖӮзЁӢеәҸиҝҗиЎҢж—¶жүҖдҪҝз”Ёзҡ„еҶ…еӯҳдё»иҰҒеҲҶдёәдёӨзұ»пјҡе ҶеҶ…еӯҳпјҲHeap Memoryпјүе’Ңж ҲеҶ…еӯҳпјҲStack MemoryпјүгҖӮзҗҶи§ЈиҝҷдёӨз§ҚеҶ…еӯҳзұ»еһӢзҡ„...
### еҶ…еӯҳеҲҶй…ҚеҷЁdlmalloc2.8.3жәҗз Ғжө…жһҗ #### 1. иҫ№з•Ңж Үи®°жі• dlmallocйҮҮз”Ёиҫ№з•Ңж Үи®°жі•еҜ№еҶ…еӯҳиҝӣиЎҢй«ҳж•Ҳз®ЎзҗҶгҖӮиҝҷз§Қж–№жі•йҖҡиҝҮе°ҶеҸҜз”ЁеҶ…еӯҳеҲҶеүІжҲҗдёҖзі»еҲ—еӣәе®ҡеӨ§е°Ҹзҡ„еқ—пјҲchunkпјүпјҢжҜҸдёӘеқ—йғҪжңүзү№е®ҡзҡ„еӨҙйғЁе’Ңе°ҫйғЁдҝЎжҒҜз”ЁдәҺиҝҪиёӘе…¶зҠ¶жҖҒ...
еҶ…еӯҳеҲҶй…ҚеҷЁжҳҜж“ҚдҪңзі»з»ҹдёӯиҮіе…ійҮҚиҰҒзҡ„组件пјҢе®ғиҙҹиҙЈз®ЎзҗҶзі»з»ҹзҡ„еҶ…еӯҳиө„жәҗпјҢзЎ®дҝқзЁӢеәҸиғҪеӨҹй«ҳж•ҲгҖҒеҸҜйқ ең°иҺ·еҸ–е’ҢйҮҠж”ҫеҶ…еӯҳгҖӮdlmallocжҳҜдёҖдёӘз”ұDoug Leaзј–еҶҷзҡ„ејҖжәҗеҶ…еӯҳеҲҶй…ҚеҷЁпјҢиў«е№ҝжіӣеә”з”ЁдәҺеҗ„з§Қзі»з»ҹе’ҢиҪҜ件дёӯпјҢеҢ…жӢ¬и®ёеӨҡCе’ҢC++еә“гҖӮеңЁ...
dlmallocеҶ…еӯҳеҲҶй…ҚеҷЁжәҗз Ғжө…жһҗ еҶ…еӯҳеҲҶй…ҚеҷЁdlmalloc_2.8.3жәҗз Ғжө…жһҗжҳҜеӯҰд№ Linux з»Ҹе…ёд»Јз Ғзҡ„йҮҚиҰҒиө„жәҗпјҢжң¬ж–Үе°ҶеҜ№dlmallocзҡ„жәҗз ҒиҝӣиЎҢиҜҰз»ҶеҲҶжһҗпјҢжҺўзҙўе…¶еҶ…еӯҳеҲҶй…Қе’Ңеӣһ收жңәеҲ¶гҖӮ иҫ№з•Ңж Үи®°жі• dlmallocдҪҝз”Ёиҫ№з•Ңж Үи®°жі•жқҘз®ЎзҗҶ...
### еҶ…еӯҳеҲҶй…ҚеҷЁdlmalloc 2.8.3жәҗз Ғжө…жһҗ #### 1. жҰӮиҝ° dlmallocжҳҜдёҖдёӘй«ҳж•Ҳдё”е№ҝжіӣдҪҝз”Ёзҡ„еҶ…еӯҳеҲҶй…ҚеҷЁпјҢжңҖеҲқз”ұDoug LeaејҖеҸ‘пјҢзӣ®еүҚжңҖж–°зҡ„зүҲжң¬дёә2.8.3гҖӮз”ұдәҺе…¶й«ҳж•ҲжҖ§е’ҢзҒөжҙ»жҖ§пјҢе®ғеңЁLinuxзі»з»ҹе’Ңе…¶д»–зҺҜеўғдёӯеҫ—еҲ°дәҶе№ҝжіӣеә”з”ЁпјҢ...
JavaеЈ°йҹіжҠҖжңҜжө…жһҗ еңЁJavaдё–з•ҢйҮҢпјҢеӨҡеӘ’дҪ“жҠҖжңҜзҡ„йӣҶжҲҗдёҖзӣҙжҳҜејҖеҸ‘иҖ…е…іжіЁзҡ„з„ҰзӮ№пјҢе…¶дёӯеЈ°йҹіжҠҖжңҜе°Өдёәе…ій”®гҖӮжң¬ж–Үе°Ҷж·ұе…ҘжҺўи®ЁJavaеҜ№еЈ°йҹіеӨ„зҗҶзҡ„ж”ҜжҢҒпјҢеҢ…жӢ¬Appletдёӯзҡ„еЈ°йҹіж’ӯж”ҫгҖҒJavaеә”з”ЁзЁӢеәҸдёӯзҡ„еЈ°йҹіеӨ„зҗҶд»ҘеҸҠJavaXдёӯSoundеҢ…зҡ„...
еҶ…еӯҳеҲҶй…ҚеҷЁжҳҜж“ҚдҪңзі»з»ҹе’Ңеә”з”ЁзЁӢеәҸдёӯдёҚеҸҜжҲ–зјәзҡ„йғЁеҲҶпјҢе®ғ们иҙҹиҙЈеңЁиҝӣзЁӢзҡ„иҷҡжӢҹең°еқҖз©әй—ҙдёӯй«ҳж•Ҳең°еҲҶй…Қе’ҢйҮҠж”ҫеҶ…еӯҳгҖӮжң¬ж–ҮжЎЈе°Ҷж·ұе…Ҙи§Јжһҗdlmalloc 2.8.3зүҲжң¬зҡ„жәҗз ҒпјҢжҸӯзӨәе…¶еҶ…еӯҳз®ЎзҗҶзӯ–з•Ҙе’Ңе®һзҺ°жңәеҲ¶гҖӮ 1. **жң¬ж–ҮжЎЈд»Ӣз»Қ** ...
зҗҶи§ЈCеҶ…еӯҳеҲҶй…Қзҡ„дә”з§Қж–№жі•еҸҠе…¶еҢәеҲ«еҜ№дәҺзј–еҶҷй«ҳж•ҲгҖҒж— еҶ…еӯҳжі„жјҸзҡ„д»Јз ҒиҮіе…ійҮҚиҰҒгҖӮд»ҘдёӢжҳҜиҝҷдә”з§Қж–№жі•зҡ„иҜҰз»Ҷд»Ӣз»Қпјҡ 1. ж ҲеҶ…еӯҳеҲҶй…Қпјҡж ҲеҶ…еӯҳжҳҜз”ұзј–иҜ‘еҷЁиҮӘеҠЁз®ЎзҗҶзҡ„еҢәеҹҹпјҢдё»иҰҒз”ЁдәҺеӯҳж”ҫеҮҪж•°еҸӮж•°гҖҒеұҖйғЁеҸҳйҮҸзӯүгҖӮеҪ“еҮҪж•°и°ғз”Ёж—¶пјҢиҝҷдәӣ...
JavaMemoryModelз®Җз§°JMM,жҳҜдёҖзі»еҲ—зҡ„JavaиҷҡжӢҹжңәе№іеҸ°еҜ№ејҖеҸ‘иҖ…жҸҗдҫӣзҡ„еӨҡзәҝзЁӢзҺҜеўғдёӢзҡ„еҶ…еӯҳеҸҜи§ҒжҖ§гҖҒжҳҜеҗҰеҸҜд»ҘйҮҚжҺ’еәҸзӯүй—®йўҳзҡ„ж— е…іе…·дҪ“е№іеҸ°зҡ„з»ҹдёҖзҡ„дҝқиҜҒгҖӮ(еҸҜиғҪеңЁжңҜиҜӯдёҠдёҺJavaиҝҗиЎҢж—¶еҶ…еӯҳеҲҶеёғжңүжӯ§д№үпјҢеҗҺиҖ…жҢҮе ҶгҖҒж–№жі•еҢәгҖҒзәҝзЁӢж Ҳ...
еңЁйҳ…иҜ»гҖҠи®ҫи®ЎжЁЎејҸжө…жһҗгҖӢиҝҷзҜҮи®әж–Үж—¶пјҢжҲ‘们еҸҜд»Ҙжңҹеҫ…дҪңиҖ…еҜ№иҝҷдәӣжЁЎејҸзҡ„ж·ұе…Ҙи§ЈжһҗпјҢеҢ…жӢ¬е®ғ们зҡ„йҖӮз”ЁеңәжҷҜгҖҒеҰӮдҪ•еңЁJavaдёӯе®һзҺ°пјҢд»ҘеҸҠеҰӮдҪ•йҖҡиҝҮе®һдҫӢжқҘзҗҶи§Је®ғ们зҡ„ж•ҲжһңгҖӮжӯӨеӨ–пјҢи®әж–ҮеҸҜиғҪиҝҳдјҡж¶үеҸҠи®ҫи®ЎеҺҹеҲҷпјҢеҰӮејҖй—ӯеҺҹеҲҷпјҲеҜ№жү©еұ•ејҖж”ҫпјҢ...
жҖ»зҡ„жқҘиҜҙпјҢJavaзұ»еҠ иҪҪеҺҹзҗҶжҳҜJavaзЁӢеәҸе‘ҳиҝӣйҳ¶зҡ„еҝ…дҝ®иҜҫпјҢе®ғж¶үеҸҠеҲ°дәҶJVMзҡ„еҶ…йғЁиҝҗдҪңжңәеҲ¶пјҢж·ұе…ҘзҗҶи§ЈеҸҜд»Ҙеё®еҠ©жҲ‘们жӣҙеҘҪең°дјҳеҢ–зЁӢеәҸжҖ§иғҪпјҢи§ЈеҶідёҖдәӣжЈҳжүӢзҡ„й—®йўҳпјҢеҗҢж—¶д№ҹиғҪи®©жҲ‘们еҜ№Javaе№іеҸ°жңүжӣҙе…Ёйқўзҡ„и®ӨиҜҶгҖӮйҖҡиҝҮйҳ…иҜ»зӣёе…іж–Үз« е’Ң...