
Martin Fowler has written a really good article describing not only the Disruptor, but also how it fits into the architecture at LMAX. This gives some of the context that has been missing so far, but the most frequently asked question is still “What is the Disruptor?”.
I’m working up to answering that. I’m currently on question number two: “Why is it so fast?”.
These questions do go hand in hand, however, because I can’t talk about why it’s fast without saying what it does, and I can’t talk about what it is without saying why it is that way.
So I’m trapped in a circular dependency. A circular dependency of blogging.
To break the dependency, I’m going to answer question one with the simplest answer, and with any luck I’ll come back to it in a later post if it still needs explanation: the Disruptor is a way to pass information between threads.
As a developer, already my alarm bells are going off because the word “thread” was just mentioned, which means this is about concurrency, and Concurrency Is Hard.
Concurrency 101
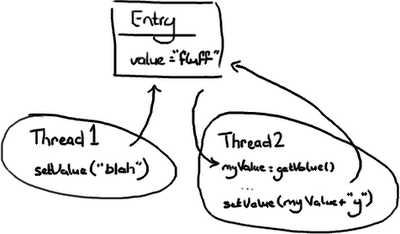
Case One: Thread 1 gets there first:
- The value changes to “blah”
- Then the value changes to “blahy” when Thread 2 gets there.
- The value changes to “fluffy”
- Then the value changes to “blah” when Thread 1 gets there.
- Thread 2 gets the value “fluff” and stores it as
myValue - Thread 1 goes in and updates value to “blah”
- Then Thread 2 wakes up and sets the value to “fluffy”.
Case Three is probably the only one which is definitely wrong, unless you think the naive approach to wiki editing is OK (Google Code Wiki, I’m looking at you…). In the other two cases it’s all about intentions and predictability. Thread 2 might not care what’s in value, the intention might be to append “y” to whatever is in there regardless. In this circumstance, cases one and two are both correct.
Assuming that Thread 2 wants to set the value to “fluffy”, there are some different approaches to solving the problem.
Approach One: Pessimistic locking
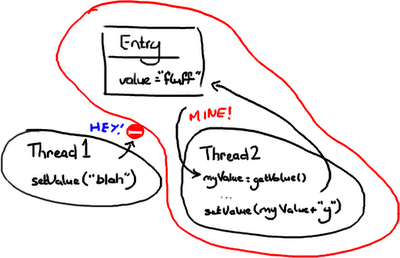
(Does the “No Entry” sign make sense to people who don’t drive in Britain?)
The terms pessimistic and optimistic locking seem to be more commonly used when talking about database reads and writes, but the principal applies to getting a lock on an object.
Thread 2 grabs a lock on Entry as soon as it knows it needs it and stops anything from setting it. Then it does its thing, sets the value, and lets everything else carry on.
You can imagine this gets quite expensive, with threads hanging around all over the place trying to get hold of objects and being blocked. The more threads you have, the more chance that things are going to grind to a halt.
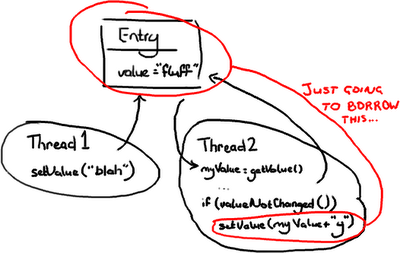
In this case Thread 2 will only lock Entry when it needs to write to it. In order to make this work, it needs to check if Entry has changed since it first looked at it. If Thread 1 came in and changed the value to “blah” after Thread 2 had read the value, Thread 2 couldn’t write “fluffy” to the Entry and trample all over the change from Thread 1. Thread 2 could either re-try (go back, read the value, and append “y” onto the end of the new value), which you would do if Thread 2 didn’t care what the value it was changing was; or it could throw an exception or return some sort of failed update flag if it was expecting to change “fluff” to “fluffy”. An example of this latter case might be if you have two users trying to update a Wiki page, and you tell the user on the other end of Thread 2 they’ll need to load the new changes from Thread 1 and then reapply their changes.
Locking can lead to all sorts of issues, for example deadlock. Imagine two threads that need access to two resources to do whatever they need to do:
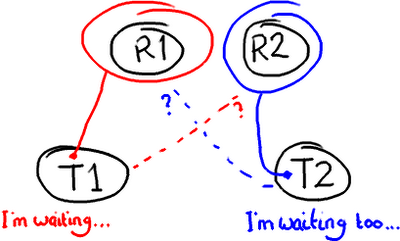
The thing about locks is that they need the operating system to arbitrate the argument. The threads are like siblings squabbling over a toy, and the OS kernel is the parent that decides which one gets it. It’s like when you run to your Dad to tell him your sister has nicked the Transformer
I’m just touching the surface of the problem, and obviously I’m using very simple examples. But the point is, if your code is meant to work in a multi-threaded environment, your job as a developer just got a lot more difficult:
- Naive code can have unintended consequences. Case Three above is an example of how things can go horribly wrong if you don’t realise you have multiple threads accessing and writing to the same data.
- Selfish code is going to slow your system down. Using locks to protect your code from the problem in Case Three can lead to things like deadlock or simply poor performance.
This is why many organisations have some sort of concurrency problems in their interview process (certainly for Java interviews). Unfortunately it’s very easy to learn how to answer the questions without really understanding the problem, or possible solutions to it.
How does the Disruptor address these issues?
For a start, it doesn’t use locks. At all.
Instead, where we need to make sure that operations are thread-safe (specifically, updating the next available sequence number in the case of multiple producers), we use a CAS (Compare And Swap/Set) operation. This is a CPU-level instruction, and in my mind it works a bit like optimistic locking – the CPU goes to update a value, but if the value it’s changing it from is not the one it expects, the operation fails because clearly something else got in there first.
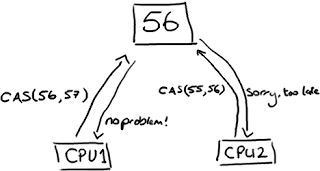
Note this could be two different cores rather than two separate CPUs.
CAS operations are much cheaper than locks because they don’t involve the operating system, they go straight to the CPU. But they’re not cost-free – in the experiment I mentioned above, where a lock-free thread takes 300ms and a thread with a lock takes 10,000ms, a single thread using CAS takes 5,700ms. So it takes less time than using a lock, but more time than a single thread that doesn’t worry about contention at all.
Back to the Disruptor – I talked about the ClaimStrategy when I went over the producers. In the code you’ll see two strategies, a SingleThreadedStrategy and a MultiThreadedStrategy. You could argue, why not just use the multi-threaded one with only a single producer? Surely it can handle that case? And it can. But the multi-threaded one uses an AtomicLong (Java’s way of providing CAS operations), and the single-threaded one uses a simple long with no locks and no CAS. This means the single-threaded claim strategy is as fast as possible, given that it knows there is only one producer and therefore no contention on the sequence number.
I know what you’re thinking: turning one single number into an AtomicLong can’t possibly have been the only thing that is the secret to the Disruptor’s speed. And of course, it’s not – otherwise this wouldn’t be called “Why it’s so fast (part one)”.
But this is an important point – there’s only one place in the code where multiple threads might be trying to update the same value. Only one place in the whole of this complicated data-structure-slash-framework. And that’s the secret. Remember everything has its own sequence number? If you only have one producer then every sequence number in the system is only ever written to by one thread. That means there is no contention. No need for locks. No need even for CAS. The only sequence number that is ever written to by more than one thread is the one on the ClaimStrategy if there is more than one producer.
This is also why each variable in the Entry can only be written to by one consumer. It ensures there’s no write contention, therefore no need for locks or CAS.
Back to why queues aren’t up to the job
So you start to see why queues, which may implemented as a ring buffer under the covers, still can’t match the performance of the Disruptor. The queue, and the basic ring buffer, only has two pointers – one to the front of the queue and one to the end:
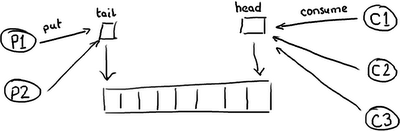
If more than one producer wants to place something on the queue, the tail pointer will be a point of contention as more than one thing wants to write to it. If there’s more than one consumer, then the head pointer is contended, because this is not just a read operation but a write, as the pointer is updated when the item is consumed from the queue.
But wait, I hear you cry foul! Because we already knew this, so queues are usually single producer and single consumer (or at least they are in all the queue comparisons in our performance tests).
There’s another thing to bear in mind with queues/buffers. The whole point is to provide a place for things to hang out between producers and consumers, to help buffer bursts of messages from one to the other. This means the buffer is usually full (the producer is out-pacing the consumer) or empty (the consumer is out-pacing the producer). It’s rare that the producer and consumer will be so evenly-matched that the buffer has items in it but the producers and consumers are keeping pace with each other.
So this is how things really look. An empty queue:
…and a full queue:
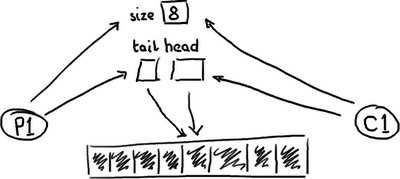
The queue needs a size so that it can tell the difference between empty and full. Or, if it doesn’t, it might determine that based on the contents of that entry, in which case reading an entry will require a write to erase it or mark it as consumed.
Whichever implementation is chosen, there’s quite a bit of contention around the tail, head and size variables, or the entry itself if a consume operation also includes a write to remove it.
On top of this, these three variables are often in the same cache line, leading to false sharing. So, not only do you have to worry about the producer and the consumer both causing a write to the size variable (or the entry), updating the tail pointer could lead to a cache-miss when the head pointer is updated because they’re sat in the same place. I’m going to duck out of going into that in detail because this post is quite long enough as it is.
So this is what we mean when we talk about “Teasing Apart the Concerns” or a queue’s “conflated concerns”. By giving everything its own sequence number and by allowing only one consumer to write to each variable in the Entry, the only case the Disruptor needs to manage contention is where more than one producer is writing to the ring buffer.
In summary
The Disruptor a number of advantages over traditional approaches:
- No contention = no locks = it’s very fast.
- Having everything track its own sequence number allows multiple producers and multiple consumers to use the same data structure.
- Tracking sequence numbers at each individual place (ring buffer, claim strategy, producers and consumers), plus the magic cache line padding, means no false sharing and no unexpected contention.



相关推荐
### 深度剖析安卓恶意软件:特征与演变 #### 引言 随着智能手机的普及与广泛应用,移动设备上的恶意软件问题变得日益严重。特别是针对Android平台的恶意软件,其数量的增长速度尤为惊人。该研究旨在对现有Android...
### Oracle Redo Logs深入解析 #### 引言 Oracle数据库管理系统以其卓越的可靠性和稳定性而闻名,这其中一个重要因素就是其redo日志(redo logs)机制的设计。每当对数据库状态进行更改(例如创建或删除表、更新行等...
In 2019, the rapid rate at which GPU manufacturers refresh their designs, coupled with their reluctance to disclose microarchitectural details, is still a hurdle for those software designers who want ...
dissecting MFC 2e part2
GTC 2018Dissecting the Volta GPU Architecture throughMicrobenchmarkingZhe Jia, Marco Maggioni, Benjamin Staiger, Daniele P. ScarpazzaHigh-Performance Computing Group• Micro-architectural details ...
"Dissecting the Hotspot JVM" 本文档是关于 Java 虚拟机(JVM)的深入分析,作者 Martin Toshev 通过分享 JVM 的架构、实现机理和调试技术,帮助读者更好地理解 JVM,并为其提供了实践经验。 虚拟机基础 虚拟机...
Real World Java EE Night Hacks--Dissecting the Business Tier.jpg(电子书的封面图片)
一本很好的关于MFC的书,深入显出的教你掌握MFC。
H0w t0 R34d Dissecting the Hack: The F0rb1dd3n Network xvii About the Authors xix PART 1 F0RB1DD3N PR010gu3 3 A New Assignment 3 ChAPTeR 0N3 15 Problem Solved 15 Getting Started 21 The Acquisition 22 ...
本书通过深入了解SharpDevelop(一种用C#编写的完整集成开发环境)来教授高级.NET编程技术。
这些分部分的PDF文件(dissecting MFC 2e part1至part5)可以按照顺序阅读,逐步深入MFC的世界。 总之,《深入浅出MFC》是一本全面而深入的教程,适合对MFC有一定基础的开发者进一步提升技能,也适合初学者系统学习...
It’s All the Same, Just Different Now with More Savings! DIY Rotation Forcing the Issue Making Sense of It All ■Chapter 20: Working with Resources The Resource Lineup String Theory Plain ...
Completely updated and featuring 12 new chapters, Gray Hat Hacking: The Ethical Hacker's Handbook, Fourth Edition explains the enemy’s current weapons, skills, and tactics and offers field-tested ...
The developers who created SharpDevelop give you an inside track on application development with a guided tour of the source code for SharpDevelop. They will show you the most important code ...
这种类型的书籍对安全研究员、网络安全分析师、IT专业人员、以及对网络攻击和防御技术感兴趣的读者来说,是非常重要的参考资料。 在了解这本书的背景信息之后,读者能够更好地理解其价值和使用范围。建议那些在网络...
written to follow the conversion rules so specifically that it does not recognize time-saving shortcuts that can be made in the final assembly language code, or it is unable to compensate for poorly...
《Dissecting A CSharp Application》是一本深入探讨C#应用程序开发的专业资源,英文版包含了未公开发布的第18章节的珍贵内容。这本书是对于理解C#编程语言和其在实际应用中的工作原理的宝贵资料,特别关注的是使用...