Web-Harvest是一个Java开源Web数据抽取工具。它能够收集指定的Web页面并从这些页面中提取有用的数据。其实现原理是,根据预先定义的配置文件用httpclient获取页面的全部内容(关于httpclient的内容,本博有些文章已介绍),然后运用XPath、XQuery、正则表达式等这些技术来实现对text/xml的内容筛选操作,选取精确的数据。前两年比较火的垂直搜索(比如:酷讯等)也是采用类似的原理实现的。Web-Harvest应用,关键就是理解和定义配置文件,其他的就是考虑怎么处理数据的Java代码。当然在爬虫开始前,也可以把Java变量填充到配置文件中,实现动态的配置。
(友情提示:本博文章欢迎转载,但请注明出处:陈新汉,http://www.blogjava.net/hankchen)
现在以爬取天涯论坛的所有版面信息为例,介绍Web-Harvest的用法,特别是其配置文件。
天涯的版块地图页面时:http://www.tianya.cn/bbs/index.shtml
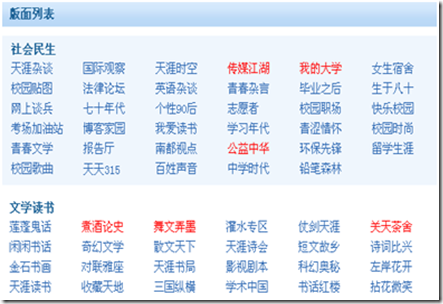
[天涯的部分版面列表]
我们的目标就是要抓取全部的版块信息,包括版块之间的父子关系。
先查看版块地图的页面源代码,寻求规律:
<div class="backrgoundcolor">
<div class="bankuai_list">
<h3>社会民生</h3>
<ul>
<li><a href="http://www.tianya.cn/publicforum/articleslist/0/free.shtml" id="item天涯杂谈">天涯杂谈</a></li>
<li><a href="http://www.tianya.cn/publicforum/articleslist/0/worldlook.shtml" id="item国际观察">国际观察</a></li>
<li><a href="http://www.tianya.cn/publicforum/articleslist/0/news.shtml" id="item天涯时空">天涯时空</a></li>
<li><a href="http://www.tianya.cn/publicforum/articleslist/0/no06.shtml" id="item传媒江湖">传媒江湖</a></li>
…… //省略
</ul>
</div>
<div class="clear"></div>
</div>
<div class="nobackrgoundcolor">
<div class="bankuai_list">
<h3>文学读书</h3>
<ul>
<li><a href="http://www.tianya.cn/techforum/articleslist/0/16.shtml" id="item莲蓬鬼话">莲蓬鬼话</a></li>
<li><a href="http://www.tianya.cn/publicforum/articleslist/0/no05.shtml" id="item煮酒论史">煮酒论史</a></li>
<li><a href="http://www.tianya.cn/publicforum/articleslist/0/culture.shtml" id="item舞文弄墨">舞文弄墨</a></li>
……. //省略
</ul>
</div>
<div class="clear"></div>
</div>
……. //省略
通过页面源码分析,发现每个大板块都是在<div class="bankuai_list"></div>的包括之下,而大板块下面的小版块都是下面的形式包含的。
<li><a href="xxx" id="xxx">xxx</a></li>,这些规律就是webharvest爬数据的规则。
下面先给出全部的配置:(tianya.xml)
<config charset="utf-8">
<var-def name="start">
<html-to-xml>
<http url="http://www.tianya.cn/bbs/index.shtml" charset="utf-8" />
</html-to-xml>
</var-def>
<var-def name="ulList">
<xpath expression="//div[@class='bankuai_list']">
<var name="start" />
</xpath>
</var-def>
<file action="write" path="tianya/siteboards.xml" charset="utf-8">
<![CDATA[ <site> ]]>
<loop item="item" index="i">
<list><var name="ulList"/></list>
<body>
<xquery>
<xq-param name="item">
<var name="item"/>
</xq-param>
<xq-expression><![CDATA[
declare variable $item as node() external;
<board boardname="{normalize-space(data($item//h3/text()))}" boardurl="">
{
for $row in $item//li return
<board boardname="{normalize-space(data($row//a/text()))}" boardurl="{normalize-space(data($row/a/@href))}" />
}
</board>
]]></xq-expression>
</xquery>
</body>
</loop>
<![CDATA[ </site> ]]>
</file>
</config>
这个配置文件分为三个部分:
1. 定义爬虫入口:
<var-def name="start">
<html-to-xml>
<http url="http://www.tianya.cn/bbs/index.shtml" charset="utf-8" />
</html-to-xml>
</var-def>
爬虫的入口URL是:http://www.tianya.cn/bbs/index.shtml
同时,指定了爬虫的爬数据的编码,这个编码应该根据具体的页面编码来定,例如上面的入口页面的编码就是utf-8。其实,有很多的中文页面的编码是gbk或者gb2312,那么这个地方的编码就要相应设置,否则会出现数据乱码。
2. 定义数据的过滤规则:
<var-def name="ulList">
<xpath expression="//div[@class='bankuai_list']">
<var name="start" />
</xpath>
</var-def>
上面配置就是根据XPath从爬得的数据中筛选合适的内容。这里需要得到所有的<div class="bankuai_list"></div>信息。有关XPath和XQuery的语法请网上查询。
3. 最后一步就是处理数据。可以写入XML文件,也可以使用SetContextVar的方式把收集的数据塞到一个集合变量中,供Java代码调用(比如:数据直接入库)。
这里是直接写入XML文件,然后解析XML即可。
注意下面的for循环,这是XQuery的语法,提供遍历的功能。由于大版面小版块是一个树状结构,需要这种遍历。
<board boardname="{normalize-space(data($item//h3/text()))}" boardurl="">
{
for $row in $item//li return
<board boardname="{normalize-space(data($row//a/text()))}" boardurl="{normalize-space(data($row/a/@href))}" />
}
</board>
相关的Java代码如下:
/**
* Copyright(C):2009
* @author陈新汉
* Sep4,20093:24:58PM
*/
String configFile="tianya.xml";
ScraperConfiguration config = new ScraperConfiguration(configFile);
String targetFolder="c:\\chenxinhan";
Scraper scraper = new Scraper(config,targetFolder);
//设置爬虫代理
scraper.getHttpClientManager().setHttpProxy("218.56.64.210","8080");
scraper.setDebug(true);
scraper.execute();
上面代码执行完成后,收集的数据文件地址为:c:\chenxinhan\tianya\siteboards.xml
友情提示:本博文章欢迎转载,但请注明出处:陈新汉,http://www.blogjava.net/hankchen
分享到:





相关推荐
Python网络爬虫是一种用于自动化获取网页内容的技术,广泛应用于互联网数据采集、数据分析和信息监控等领域。在Python中,有许多强大的库和框架可以帮助开发者构建高效、稳定的爬虫程序。 一、选题背景 随着互联网...
《网络爬虫技术与应用》课程教学大纲.pdf《网络爬虫技术与应用》课程教学大纲.pdf《网络爬虫技术与应用》课程教学大纲.pdf《网络爬虫技术与应用》课程教学大纲.pdf《网络爬虫技术与应用》课程教学大纲.pdf《网络爬虫...
解析Python网络爬虫_复习大纲.docx 本文档是关于Python网络爬虫的复习大纲,涵盖了爬虫的基本概念、实现原理、技术、网页请求原理、抓取网页数据、数据解析、并发下载、抓取动态内容、图像识别与文字处理、存储爬虫...
Python网络爬虫技术是当前IT领域中非常热门的一个分支,尤其在大数据分析和人工智能应用中起着关键作用。本资源“Python网络爬虫技术_习题答案.rar”看似是一个教学资料,包含了一些图像文件和章节内容,我们可以从...
Python在网络爬虫中的应用广泛且深入,尤其在自动化数据采集方面扮演着重要角色。网络爬虫,又称为Web Spider或网络机器人,是一种程序,用于自动地遍历互联网上的网页,采集所需信息。这种技术不仅服务于搜索引擎的...
在本课程设计中,基于Python的网络爬虫设计旨在让学生掌握网络爬虫的基本原理、实现方法以及在实际中的应用。通过该项目,学生能够学习到如何利用Python语言和相关库进行网页抓取、数据解析,并对抓取的数据进行有效...
网络爬虫 网络爬虫 网络爬虫网络爬虫网络爬虫网络爬虫网络爬虫网络爬虫网络爬虫网络爬虫网络爬虫网络爬虫网络爬虫
本书从Python的安装开始,详细讲解了Python从简单程序延伸到Python网络爬虫的全过程。本书从实战出发,根据不同的需求选取不同的爬虫,有针对性地讲解了几种Python网络爬虫。本书共8章,涵盖的内容有Python语言的...
通过以上知识点的学习和应用,网络爬虫技术可以帮助我们从海量互联网数据中获取有价值的信息,服务于各种领域,如市场分析、学术研究、舆情监控等。随着大数据时代的到来,网络爬虫的重要性和应用价值将进一步提升。
- **目的**:评估不同并行网络爬虫架构的性能表现,为实际应用提供参考。 - **结构框架**: - **数据采集层**:负责网页抓取和预处理。 - **数据处理层**:对采集到的数据进行清洗、分析、索引等操作。 - **...
Python 资源之网络爬虫框架是指使用 Python 语言开发的网络爬虫框架,旨在帮助开发者快速构建高效的网络爬虫应用程序。在本节中,我们将对 Python 资源之网络爬虫框架进行详细的介绍,并对其特点、优缺点和应用场景...
总结而言,本篇入门网络爬虫的精华文章覆盖了网络爬虫的基础知识,介绍了三个核心的工作版块,反爬虫策略的应对方法,并且简单提及了Scrapy框架。此外,还提供了进一步学习的资源参考。通过本篇内容,初学者可以快速...
在Web开发和数据分析领域,爬虫扮演着至关重要的角色,它们能够自动化地从互联网上获取大量信息,为研究、统计或个性化推荐等应用提供数据支持。Webharvest正是这样一种灵活且功能强大的爬虫工具,尤其适合那些对XML...
Python 网络爬虫实验报告六 Python 网络爬虫实验报告六是关于使用 Python 语言进行网络爬虫的实验报告,主要内容包括抓取学习强国下学习金句的内容,并保存音频资源至本地。下面是实验报告的详细内容: 一、上机...
网络爬虫论文答辩,网络爬虫论文答辩课件,网络爬虫论文答辩PPT
最后,本论文的研究成果,为网络爬虫技术的进一步发展提供了理论基础和实践指导,具有重要的学术价值和应用前景。随着网络技术的不断进步和数据量的不断增加,网络爬虫与反爬虫技术的研究将变得更加重要,为智能信息...
网络爬虫系统的应用非常广泛,例如搜索引擎、数据挖掘、网络监控等。 1.3 定义 网络爬虫需求分析是指对网络爬虫系统的需求进行分析和定义,以确保系统的开发和实施符合用户的需求和期望。网络爬虫需求分析的目的是...
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
【爬虫开发】《Python3网络爬虫开发实战代码》 说明:《Python3网络爬虫开发实战代码》---->mitmtest (Practical code for development of Python 3 web crawler) 【爬虫开发】《Python3网络爬虫开发实战代码》文件...