原文链接地址:http://www.cnblogs.com/zhengyun_ustc/p/55solution9.html
提纲:
- 监控平台要做到什么程度?为什么要自己做?
- 几个通用技术问题
- 绘图所依赖的数据如何收集?如何加工?如何存储?
- 图形如何绘制,各种指标如何叠加?
- 拓扑关系如何绘制?
技术选型哲学
最终选了statsd+graphite
数据的采集
数据存储的粒度
天机的技术选型
一,监控平台要做到什么程度?为什么要自己做?
运维监控满满都是着各种开源系统以及它们的 Dashboard:
- Zabbix
- Nagios
- Centreon
- Logstash
- Ganglia+Cacti
以及各种业务指标趋势的 Dashboard。
我们认为,监控不能只是各种数据的采集和罗列,不仅仅是弄若干个报表并进一步配置成仪表盘,
而是有一定智能,仿照我们日常的排查问题思路,建立一定规则,自动检查,深度检查,友情提示。
随手举一个例子:
|
规则:模仿我们发现问题后先检查数据库主从同步是否有问题的习惯
|
|
天机系统发现成单金额或验证券数或短信发送条数环比大幅下降后,启动检查规则,
自动逐一检查各种从库的主从同步情况。
如果发现主从延迟超过阈值,则天机 DashBoard 应浮出两条红色警告提示(可点击进入):
- 5分钟销售数据环比下降50%
- 某某从库DBXXXX与主库DBYYYY的同步延迟了300秒
如果发现主从同步失败导致了同步停止,则应浮出两条红色警告提示(可点击进入):
- 5分钟验证券数环比下降40%
- 某某从库DBXXXX与主库DBYYYY的同步停止,失败原因为:blabla
|
就这样,只有自己动手,才能把我们日常分析问题、定位问题的经验变成一条条系统规则,还是那句话:
自动化才是王道。
二,几个通用技术问题
大致想来,李丹刘奎还需要解决这么几个基础问题:
2.1.绘图所依赖的监控原始数据如何收集?如何加工?如何存储?
不同运维指标和业务指标的时间粒度大小不一,1秒、1分钟、5分钟……
数据是业务方自行上报?还是主动采集?考虑一下可伸缩性:如果是数以百计物理机、成千上万个虚拟机或容器的数以万计指标呢?如果采集频率非常高呢?
拿到原始数据后,原始数据至少还要经过 min/max/sum/count/mean/media……等计算才能变为可视化图表要展示的维度。
这些东西又怎么存储?
2.2.图形如何绘制,各种指标如何叠加?
在使用 Centreon 时,我们就抱怨不能把多个维度的指标自由组合后叠加在一张图上看。是的,Centreon 能在一张图上展示某个主机的它定义好的几个指标,如下图所示:
图1 centreon图例
但我们希望还能把不同主机的不同指标按我们的意愿放在一张图上绘制,也就是可配置的,这样有利于排查问题,能快速看出趋势变化和关联关系。
其次,绘图得快,而且运维看的都是近乎实时的度量数据,怎么才能足够快。
2.3.拓扑关系如何绘制?
拓扑关系很重要,最好能自动可视化,毕竟一图胜过千言万语。
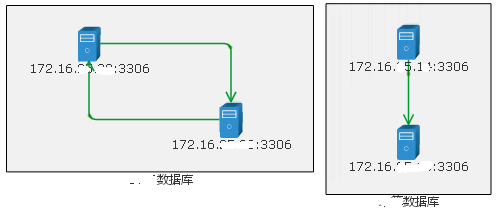
随手举个例子:
|
数据库拓扑关系
|
|
在监控系统里登记了 DB 的IP和分组后,其实已经可以探测到 DB 之间的主从关系(包括级联关系)了,能自动绘制出登记的所有数据库服务器之间的关系。举例如下:
图2 自动绘制数据库拓扑
|
三,技术选型哲学
选型两个重要观点:
- 不重复制造轮子;
- 既然找轮子,那这个轮子就应该只做一件事,且把它做到最好。
可供选择的方案有:
- grafana + influxdb
- statsd + graphite
- collectd + graphite
- grafana + graphite
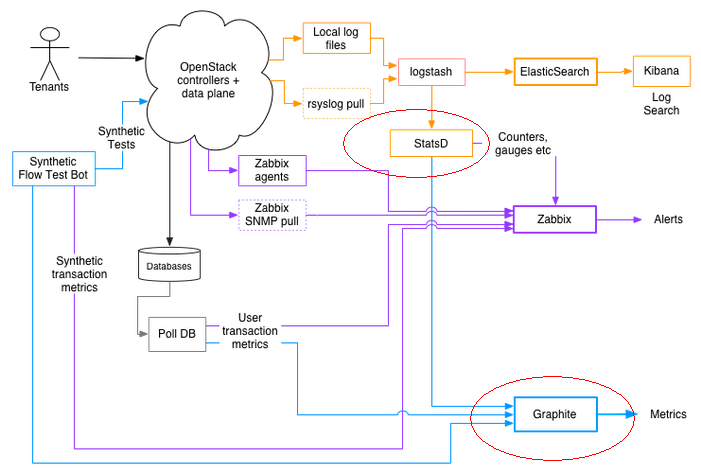
3.1.StatsD
图3 ebay云的监控报警
StatsD 是一个 NodeJs 的 daemon 程序,简单轻巧,使用 UDP 协议,专门用来收集数据,收集完数据就发送到其他服务器进行处理。
3.2.Graphite
Graphite 是一个企业级的监控工具,用 Python 编写,采用 django 框架,sqlite 数据库存储,自有简单文本协议通讯,绘图功能强大。最初由 Chris Davis 在 Orbitz 工作时,作为一个辅助项目开发的,最终成了一个监控基础工具,如他所言,Graphite provides real-time visualization and storage of numeric time-series data,重点解决:
严格地说,Graphite 只是一个根据数据绘图的工具,数据收集通常由第三方工具或插件完成,它自带了 carbon 和 whisper,还可根据其协议选用别的数据源供其绘图。官方描述,预计用 Ceres 替代 Whisper。
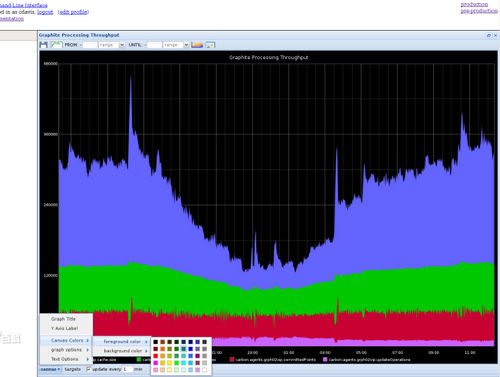
图4 graphite图例
简单的文本协议和强大的绘图功能使得它可以方便地扩展到任何需要监控的系统上。豆瓣、Google、GitHub、Instagram、Uber等公司都用它。
3.3.CollectD
C语言开发的 collectd 是一个较为古老的工具,像 statsd 一样它也做周期性收集统计数据,collectd 还管数据存储。它能够通过插件支持检测各种各样的系统信息,如数据库、UPS。
要想查看 collectd 收集的信息,还需要安装 web 界面或者 Cacti,于是工作模式就是:
collectd 作为守护进程运行,每隔 10 秒收集信息,而 Cacti 每隔5分钟运行一个 PHP 脚本来收集信息(两者的时间间隔可配置)。
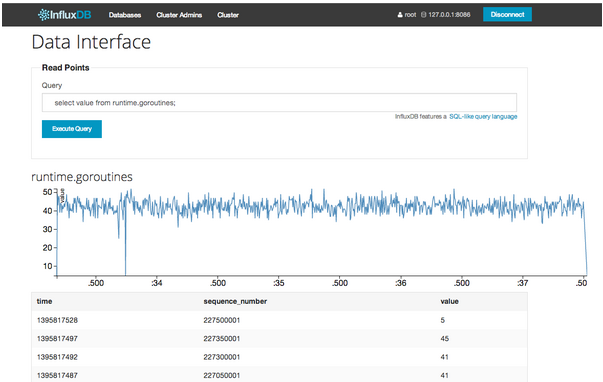
3.4.Influxdb
InfluxDB 是一个开源分布式时序、事件和指标数据库。使用 Go 语言编写,无需外部依赖。其设计目标是实现分布式和水平伸缩扩展。向这个时间序列数据库插入数据,每条数据都会自动附加上两个字段,一个时间,一个序列号(用来作为主键的)。
特点:
- schemaless(无结构),可以是任意数量的列
- Scalable
- min, max, sum, count, mean, median 一系列函数,方便统计
- Native HTTP API, 内置http支持,使用http读写
- Powerful Query Language,类似SQL
- Built-in Explorer,自带管理工具
管理界面如下图所示:
图5 influxdb图例
grafana 则类似 ES Kibana 的可视化面板,有着非常漂亮的图表和布局,目前支持 Graphite、Influxdb 和 Opentsdb) + influxdb(分布式时序、事件和指标数据库)等配搭。
grafana 与 influxdb 整合后的效果如下图所示:
图6 grafana+influxdb整合图例
四,最终选了statsd+graphite
最终李丹和刘奎选择的方案是:statsd(采集) + graphite(绘制, whisper 负责存储)。
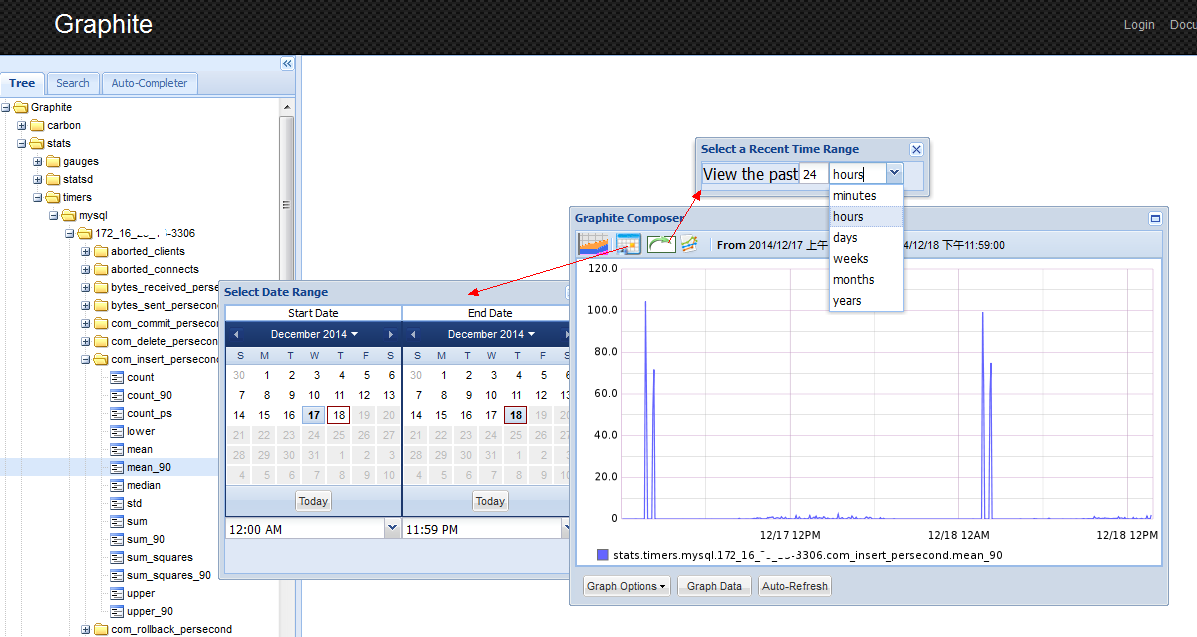
搭建了 Graphite 之后,你可以在它自带的管理站点上看到所有指标的历史数据,可以选时间范围,如下图所示:
图7 graphite管理站点图例
graphite 管理界面里的图形,请求格式如下所示:
http://graphite系统域名/render/?width=586&height=308&_salt=1410088306.115&target=stats.timers.mysql.172_16_999_999-3306.aborted_clients.upper_90
如果我们的监控系统要把多个指标拼到一个图形上渲染,则请求格式如下所示:
http://监控系统域名/db/createImage/target/%5B%22stats.timers.mysql.172_16_999_991-3306.com_select_persecond.upper%22%2C%22stats.timers.mysql.172_16_999_992-3306.com_select_persecond.upper%22%2C%22stats.timers.mysql.172_16_999_993-3306.com_select_persecond.upper%22%5D/from/-1hour.html?width=492&n=0.8623758849623238
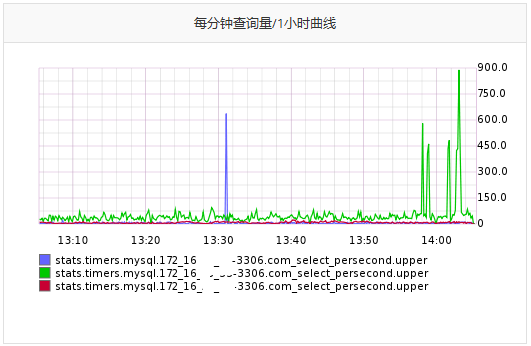
从而绘制出如下图形,这就是我在前面2.2小节说想要的特性:
图8 三个主机的指标绘制在一起
Graphite 分为三个组件:
-
carbon - a Twisted daemon that listens for time-series data
-
whisper - a simple database library for storing time-series data (similar in design to RRD)
-
graphite webapp - A Django webapp that renders graphs on-demand using Cairo
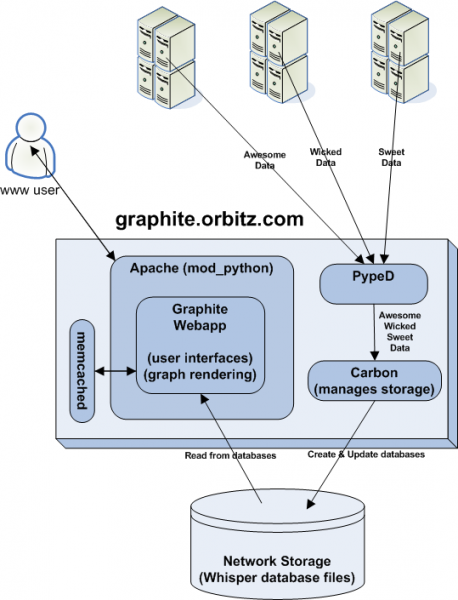
它的 High Level 图如下所示:
图9 graphite high level
从上图看出,Carbon 接到度量数据后,写入 Whisper 库里,Graphite Webapp 去 Whisper 读取数据,系统应该也做了一份缓存,所以你发送数据给 Carbon,立即就可以在 Webapp 中绘图,这也是为什么在磁盘 I/O 反应不过来的时候,Webapp 的图形仍能以接近实时的方式显示的原因。
下面两张图能帮助大家进一步理解 Graphite 里 Carbon 和 Whisper 如何协同的。
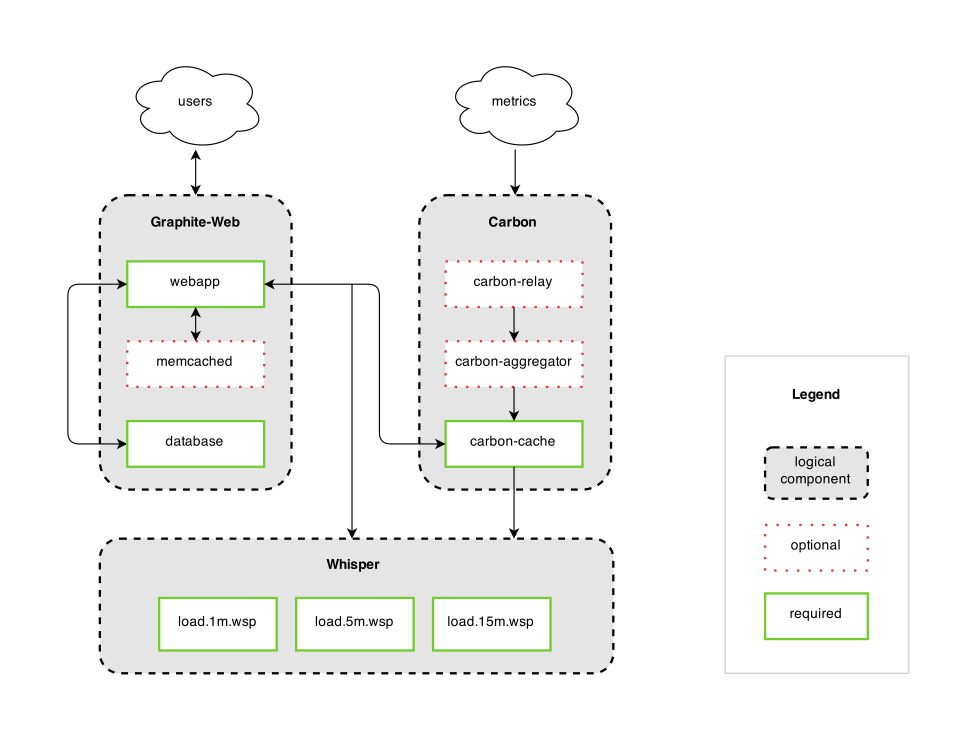
图10 graphite 逻辑图
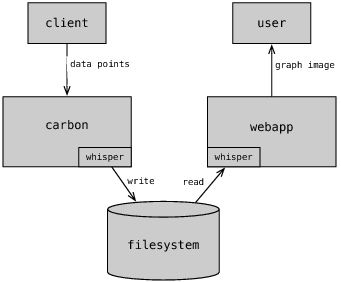
图11 Graphite 数据流转图
五,数据的采集
采集数据共有两种方式:Get_Data 和 Push_Data。
- 天机平台主动拉数据,主要集中在数据库的主从同步、数据库的拓扑关系等这样的关系型数据采集上。
- 其他场景下,基本都需要采集单点状态的数据,则由客户端脚本(即 agent)获取数据后,再推送到天机平台。
采集到的数据会走 UDP 协议发给 StatsD,由 StatsD 解析、提取、计算处理后,周期性地发送给 Graphite。
数据推送到 Graphite 时,时间周期为1分钟,采集1分钟内的业务数据按照 metric_path value timestamp\n 的格式发送。需要注意的是每次发送的数据必须以 \n 结尾,不能省略。
六,数据存储的粒度
首先,我们需要知道 statsD 默认10秒一个周期,可以通过修改 config.js 的 flushInterval 属性变更。
其次,Graphite 里有一个 retention(保留)的概念,即明确数据精度以及丢弃多久之前的数据,在 /opt/graphite/conf/
storage-schemas.conf 配置文件里定义。retention 定义的表达式为 frequency:history,每一个 retention 之间用英文逗号分隔。
默认是按10秒一个数据的方式,存一天的数据,一天前的数据就没了,如下面的配置所言:
[default_1min_for_1day]
pattern = .*
retentions = 10s:1d
可以自定义 retentions,注意表达式里每一个时间间隔必须是第一个的倍数,也就是说,第一个是10s,那么第二个只能是10s的整数倍,以此类推。
天机的数据库监控的粒度为:
[stats]
pattern = ^stats.*
retentions = 10s:1d,30s:7d,1m:28d,15m:5y
依次解释一下:
10s:1d——1天以内的数据是10秒为一个值,
30s:7d——大于1天小于7天内的数据是以30秒为一个值,
1m:28d——大于7天小于28天内的是以1分钟为一个值,
15m:5y——大于28天小于5年的,是以15分钟为一个值,
大于5年的数据丢弃。
当把10秒的数据降为1分钟数据时,默认是算平均值,但你也可以按合计值、最大值、最小值等,反正都在 storage-aggregation.conf 里配置。
天机的业务指标监控的粒度为:
[business_monitoring]
pattern = ^business_monitoring\.
retentions = 1m:5y
为什么这么定义?因为天机要能绘制任意时间段里粒度为1分钟的业务指标曲线图,所以 Graphite 不能缩小精度。
七,天机的技术选型
涉及到的开发语言有:
php,node.js,python,javascript
涉及相关的框架和服务:
Yii,graphite,StatsD,D3js(数据可视化JS框架),pt-query-digest(分析MySQL慢查日志)
最后,天机系统的目标是以最有效率的方式查找到事故点,为此要做到数据一体化和自动化。
-over-
参考资料:
分享到:




相关推荐
总结,Statsd是一个强大的监控工具,通过简单易用的接口收集和聚合数据,配合后端存储和可视化工具,为IT运维提供了一套完整的监控解决方案。它的灵活性和可扩展性使其成为许多大型互联网公司的首选监控工具。
与其他监控工具(如 Prometheus、Grafana 或 ELK Stack)配合使用,`node-statsd` 可以帮助构建一个全面的性能监控体系,从而更好地理解应用程序的运行状况,及时发现和解决问题。 总结,`node-statsd` 是前端...
总的来说,Alexcesaro-statsd是一个强大且高效的StatsD客户端,它的设计和实现充分考虑了性能和内存管理,为需要实时监控的应用提供了可靠的解决方案。通过参与和使用这样的开源项目,开发者不仅可以提升自己的技术...
《单机 20 亿指标,知乎 Graphite 极致优化!》这篇文章详细介绍了知乎在面临大规模数据监控挑战时,如何对 Graphite 进行...同时,文章还展示了未来可能的发展趋势,即利用新型存储技术和架构来持续优化监控解决方案。
Statsd是由 Etsy 开发的一款轻量级代理服务,它运行在后端服务器上,接收来自应用的计数、计时等性能数据,并将其聚合后转发给图形化展示工具(如Graphite或InfluxDB),用于实时监控和故障排查。通过使用Statsd,...
9. **社区支持与文档**:作为开源项目,statsd-tags有社区提供的文档和问题解答,这有助于开发者在遇到问题时找到解决方案。 10. **版本升级与兼容性**:3.2.1版可能包含了一些bug修复、性能优化或新功能。在升级或...
"statsd-redis-backend"是一个针对此需求的解决方案,它结合了StatsD和Redis的强大功能,为开发者提供了一种高效、灵活的数据统计和存储后端。本文将深入探讨这一工具的核心概念、工作原理以及如何在实际项目中应用...
**Python库 django-statsd-unleashed 1.0.6** `django-statsd-unleashed` 是一个Python库,专为Django框架设计,...通过这个库,你可以实现更精细化的监控,及时发现并解决潜在问题,提升整体的开发效率和应用质量。
Sherlog.js与后端的Graphite或Sentry结合,可以提供完整的端到端监控解决方案。 5. **Fabric**:Fabric是一个用Python编写的命令任务执行库,它简化了远程服务器的自动化操作,包括部署、配置管理等。"守望者"利用...
开源项目statsd-over-slf4j.zip提供了一个巧妙的解决方案,它将Java StatsD客户端与SLF4J(Simple Logging Facade for Java)相结合,使得日志数据能够方便地传输到StatsD服务器,进一步进行统计和分析。本文将深入...
6. **监控与日志系统**:建立了基于Statsd、Graphite和Grafana的监控体系,以及Banshee等日志收集分析工具,实现了全面的性能监控和故障排查能力。 综上所述,饿了么通过构建一套完整的服务治理体系,不仅提升了...
此外,InfluxDB提供了Telegraf(采集代理)、Chronograf(界面组件)和Kapacitor(告警组件),构建了一个完整的监控解决方案。而Graphite社区也有一些类似组件,如statsd和graphite-web。 在兼容性和分发策略方面...
通过与其他组件如Grafana的配合,可以构建出一套完整的监控解决方案,适用于现代云原生环境的监控需求。然而,在特定需要精确数据的场景下,Prometheus可能不是最佳选择。在部署前,确保网络配置无误是至关重要的。
虽然Mambo Collector已不再是最新的解决方案,但其设计理念和实现方式对于理解如何集成监控工具和数据库,以及如何利用statsd进行数据收集仍然十分有用。你可以参考其源代码,学习如何构建类似的收集器,或者寻找...
针对这些问题,解决方案通常涉及技术选型和架构设计。 首先,技术选型是解决这些问题的关键。在选择数据库技术时,需要考虑开源与闭源的先天基因。开源项目通常具有更高的透明度、活跃的社区支持和持续的维护,但...
**gostatsd** 是一个基于 **Go** 语言实现的网络统计代理,它是 Etsy 的原始 statsd 实现的一个...通过充分利用 Go 语言的优势和 Atlassian 的持续维护,gostatsd 能够为现代云原生环境提供高效、可靠的统计解决方案。
Zabbix是一款开源监控解决方案,它提供了实时监控网络和应用的功能。 5. 监控与日志分析 - 演讲PPT提到graphite+statsd、efk(Elasticsearch+Fluentd+Kibana)以及fluent-plugin-qqwry和fluent-plugin-statsd,...
这些组件共同构建了一个全面的监控解决方案,覆盖了从基础架构到应用服务的多个层面,确保你可以及时了解系统运行状况并应对可能出现的问题。通过Prometheus的图形界面,你可以可视化这些指标,创建自定义仪表板,...
3. **部署架构**:Jenkins被用作发布系统,结合Zabbix进行系统监控,Elasticsearch和Graphite + Statsd则提供日志存储和性能指标收集。 4. **监控告警框架**:Fluentd作为日志聚合工具,搭配fluent-plugin-qqwry和...
而存储解决方案的选择将直接影响到系统能够处理的数据量和历史数据的保存时长。在检索和展示方面,系统需要有高效的查询机制和灵活的可视化工具,以适应不同的业务场景和用户需求。 此外,系统的可扩展性也是一个...