故事发生在10月份的一次面试经历中,本来我不想说出来丢人显眼,但是为了警醒自己和告诫后人,我决定写成博文发出来。因为在面试过程中,我讲在2009年写过QQ农场助手,在这期间深入学习了HTTP协议,而且在2010-05-18写了博文:HTTP协议及其POST与GET操作差异 & C#中如何使用POST、GET等。面试官说既然我熟悉HTTP协议,就问“当HTTP采用keepalive模式,当客户端向服务器发生请求之后,客户端如何判断服务器的数据已经发生完成?”
说实话,当时我懵了,一直没有关注过keepalive模式。我只知道:HTTP协议中客户端发送一个小请求,服务器响应以所期望的信息(例如一个html文件或一副gif图像)。服务器通常在发送回所请求的数据之后就关闭连接。这样客户端读数据时会返回EOF(-1),就知道数据已经接收完全了。我就这样被面试官判了死刑!!!说我完全停留在表面,没有深入(当时真的很受打击,一直自认为技术还不错!)。我当时真的很想找各种借口:
觉得各种解释都是那么苍白无力!我再次感叹书到用时方恨少,也感叹一个人的时间是多么的有限(曾一度想成为一个IT专业全才),根本没有精力面面俱到,而且当没有真正使用一个东西的时候,往往会忽略掉很多细节。朋友如果你也答不上来,请认真细看下文,不要怀着浮躁了的心,说不定下次就有人问你这个问题。
1、什么是Keep-Alive模式?
我们知道HTTP协议采用“请求-应答”模式,当使用普通模式,即非KeepAlive模式时,每个请求/应答客户和服务器都要新建一个连接,完成之后立即断开连接(HTTP协议为无连接的协议);当使用Keep-Alive模式(又称持久连接、连接重用)时,Keep-Alive功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive功能避免了建立或者重新建立连接。
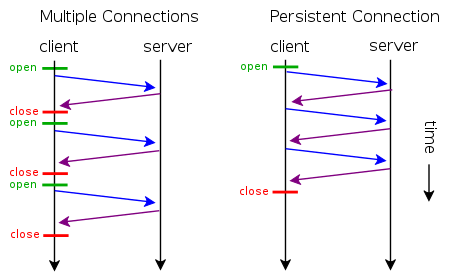
http 1.0中默认是关闭的,需要在http头加入"Connection: Keep-Alive",才能启用Keep-Alive;http 1.1中默认启用Keep-Alive,如果加入"Connection: close ",才关闭。目前大部分浏览器都是用http1.1协议,也就是说默认都会发起Keep-Alive的连接请求了,所以是否能完成一个完整的Keep-Alive连接就看服务器设置情况。
2、启用Keep-Alive的优点
从上面的分析来看,启用Keep-Alive模式肯定更高效,性能更高。因为避免了建立/释放连接的开销。下面是RFC 2616上的总结:
-
-
By opening and closing fewer TCP connections, CPU time is saved in routers and hosts (clients, servers, proxies, gateways, tunnels, or caches), and memory used for TCP protocol control blocks can be saved in hosts.
-
HTTP requests and responses can be pipelined on a connection. Pipelining allows a client to make multiple requests without waiting for each response, allowing a single TCP connection to be used much more efficiently, with much lower elapsed time.
-
Network congestion is reduced by reducing the number of packets caused by TCP opens, and by allowing TCP sufficient time to determine the congestion state of the network.
-
Latency on subsequent requests is reduced since there is no time spent in TCP's connection opening handshake.
-
HTTP can evolve more gracefully, since errors can be reported without the penalty of closing the TCP connection. Clients using future versions of HTTP might optimistically try a new feature, but if communicating with an older server, retry with old semantics after an error is reported.
RFC 2616(P47)还指出:单用户客户端与任何服务器或代理之间的连接数不应该超过2个。一个代理与其它服务器或代码之间应该使用超过2 * N的活跃并发连接。这是为了提高HTTP响应时间,避免拥塞(冗余的连接并不能代码执行性能的提升)。
3、回到我们的问题(即如何判断消息内容/长度的大小?)
Keep-Alive模式,客户端如何判断请求所得到的响应数据已经接收完成(或者说如何知道服务器已经发生完了数据)?我们已经知道了,Keep-Alive模式发送玩数据HTTP服务器不会自动断开连接,所有不能再使用返回EOF(-1)来判断(当然你一定要这样使用也没有办法,可以想象那效率是何等的低)!下面我介绍两种来判断方法。
3.1、使用消息首部字段Conent-Length
故名思意,Conent-Length表示实体内容长度,客户端(服务器)可以根据这个值来判断数据是否接收完成。但是如果消息中没有Conent-Length,那该如何来判断呢?又在什么情况下会没有Conent-Length呢?请继续往下看……
3.2、使用消息首部字段Transfer-Encoding
当客户端向服务器请求一个静态页面或者一张图片时,服务器可以很清楚的知道内容大小,然后通过Content-length消息首部字段告诉客户端需要接收多少数据。但是如果是动态页面等时,服务器是不可能预先知道内容大小,这时就可以使用Transfer-Encoding:chunk模式来传输数据了。即如果要一边产生数据,一边发给客户端,服务器就需要使用"Transfer-Encoding: chunked"这样的方式来代替Content-Length。
chunk编码将数据分成一块一块的发生。Chunked编码将使用若干个Chunk串连而成,由一个标明长度为0的chunk标示结束。每个Chunk分为头部和正文两部分,头部内容指定正文的字符总数(十六进制的数字)和数量单位(一般不写),正文部分就是指定长度的实际内容,两部分之间用回车换行(CRLF)隔开。在最后一个长度为0的Chunk中的内容是称为footer的内容,是一些附加的Header信息(通常可以直接忽略)。
Chunk编码的格式如下:
Chunked-Body = *chunk
"0" CRLF
footer
CRLF
chunk = chunk-size [ chunk-ext ] CRLF
chunk-data CRLF
hex-no-zero = <HEX excluding "0">
chunk-size = hex-no-zero *HEX
chunk-ext = *( ";" chunk-ext-name [ "=" chunk-ext-value ] )
chunk-ext-name = token
chunk-ext-val = token | quoted-string
chunk-data = chunk-size(OCTET)
footer = *entity-header
即Chunk编码由四部分组成:1、0至多个chunk块,2、"0" CRLF,3、footer,4、CRLF.而每个chunk块由:chunk-size、chunk-ext(可选)、CRLF、chunk-data、CRLF组成。
4、消息长度的总结
其实,上面2中方法都可以归纳为是如何判断http消息的大小、消息的数量。RFC 2616对消息的长度总结如下:一个消息的transfer-length(传输长度)是指消息中的message-body(消息体)的长度。当应用了transfer-coding(传输编码),每个消息中的message-body(消息体)的长度(transfer-length)由以下几种情况决定(优先级由高到低):
- 任何不含有消息体的消息(如1XXX、204、304等响应消息和任何头(HEAD,首部)请求的响应消息),总是由一个空行(CLRF)结束。
- 如果出现了Transfer-Encoding头字段 并且值为非“identity”,那么transfer-length由“chunked” 传输编码定义,除非消息由于关闭连接而终止。
- 如果出现了Content-Length头字段,它的值表示entity-length(实体长度)和transfer-length(传输长度)。如果这两个长度的大小不一样(i.e.设置了Transfer-Encoding头字段),那么将不能发送Content-Length头字段。并且如果同时收到了Transfer-Encoding字段和Content-Length头字段,那么必须忽略Content-Length字段。
- 如果消息使用媒体类型“multipart/byteranges”,并且transfer-length 没有另外指定,那么这种自定界(self-delimiting)媒体类型定义transfer-length 。除非发送者知道接收者能够解析该类型,否则不能使用该类型。
- 由服务器关闭连接确定消息长度。(注意:关闭连接不能用于确定请求消息的结束,因为服务器不能再发响应消息给客户端了。)
为了兼容HTTP/1.0应用程序,HTTP/1.1的请求消息体中必须包含一个合法的Content-Length头字段,除非知道服务器兼容HTTP/1.1。一个请求包含消息体,并且Content-Length字段没有给定,如果不能判断消息的长度,服务器应该用用400 (bad request) 来响应;或者服务器坚持希望收到一个合法的Content-Length字段,用 411 (length required)来响应。
所有HTTP/1.1的接收者应用程序必须接受“chunked” transfer-coding (传输编码),因此当不能事先知道消息的长度,允许使用这种机制来传输消息。消息不应该够同时包含 Content-Length头字段和non-identity transfer-coding。如果一个消息同时包含non-identity transfer-coding和Content-Length ,必须忽略Content-Length 。
5、HTTP头字段总结
最后我总结下HTTP协议的头部字段。
- 1、 Accept:告诉WEB服务器自己接受什么介质类型,*/* 表示任何类型,type/* 表示该类型下的所有子类型,type/sub-type。
- 2、 Accept-Charset: 浏览器申明自己接收的字符集
Accept-Encoding: 浏览器申明自己接收的编码方法,通常指定压缩方法,是否支持压缩,支持什么压缩方法(gzip,deflate)
Accept-Language:浏览器申明自己接收的语言
语言跟字符集的区别:中文是语言,中文有多种字符集,比如big5,gb2312,gbk等等。
- 3、 Accept-Ranges:WEB服务器表明自己是否接受获取其某个实体的一部分(比如文件的一部分)的请求。bytes:表示接受,none:表示不接受。
- 4、 Age:当代理服务器用自己缓存的实体去响应请求时,用该头部表明该实体从产生到现在经过多长时间了。
- 5、 Authorization:当客户端接收到来自WEB服务器的 WWW-Authenticate 响应时,用该头部来回应自己的身份验证信息给WEB服务器。
- 6、 Cache-Control:请求:no-cache(不要缓存的实体,要求现在从WEB服务器去取)
max-age:(只接受 Age 值小于 max-age 值,并且没有过期的对象)
max-stale:(可以接受过去的对象,但是过期时间必须小于 max-stale 值)
min-fresh:(接受其新鲜生命期大于其当前 Age 跟 min-fresh 值之和的缓存对象)
响应:public(可以用 Cached 内容回应任何用户)
private(只能用缓存内容回应先前请求该内容的那个用户)
no-cache(可以缓存,但是只有在跟WEB服务器验证了其有效后,才能返回给客户端)
max-age:(本响应包含的对象的过期时间)
ALL: no-store(不允许缓存)
- 7、 Connection:请求:close(告诉WEB服务器或者代理服务器,在完成本次请求的响应后,断开连接,不要等待本次连接的后续请求了)。
keepalive(告诉WEB服务器或者代理服务器,在完成本次请求的响应后,保持连接,等待本次连接的后续请求)。
响应:close(连接已经关闭)。
keepalive(连接保持着,在等待本次连接的后续请求)。
Keep-Alive:如果浏览器请求保持连接,则该头部表明希望 WEB 服务器保持连接多长时间(秒)。例如:Keep-Alive:300
- 8、 Content-Encoding:WEB服务器表明自己使用了什么压缩方法(gzip,deflate)压缩响应中的对象。例如:Content-Encoding:gzip
- 9、Content-Language:WEB 服务器告诉浏览器自己响应的对象的语言。
- 10、Content-Length: WEB 服务器告诉浏览器自己响应的对象的长度。例如:Content-Length: 26012
- 11、Content-Range: WEB 服务器表明该响应包含的部分对象为整个对象的哪个部分。例如:Content-Range: bytes 21010-47021/47022
- 12、Content-Type: WEB 服务器告诉浏览器自己响应的对象的类型。例如:Content-Type:application/xml
- 13、ETag:就是一个对象(比如URL)的标志值,就一个对象而言,比如一个 html 文件,如果被修改了,其 Etag 也会别修改,所以ETag 的作用跟 Last-Modified 的作用差不多,主要供 WEB 服务器判断一个对象是否改变了。比如前一次请求某个 html 文件时,获得了其 ETag,当这次又请求这个文件时,浏览器就会把先前获得的 ETag 值发送给WEB 服务器,然后 WEB 服务器会把这个 ETag 跟该文件的当前 ETag 进行对比,然后就知道这个文件有没有改变了。
- 14、 Expired:WEB服务器表明该实体将在什么时候过期,对于过期了的对象,只有在跟WEB服务器验证了其有效性后,才能用来响应客户请求。是 HTTP/1.0 的头部。例如:Expires:Sat, 23 May 2009 10:02:12 GMT
- 15、 Host:客户端指定自己想访问的WEB服务器的域名/IP 地址和端口号。例如:Host:rss.sina.com.cn
- 16、 If-Match:如果对象的 ETag 没有改变,其实也就意味著对象没有改变,才执行请求的动作。
- 17、 If-None-Match:如果对象的 ETag 改变了,其实也就意味著对象也改变了,才执行请求的动作。
- 18、 If-Modified-Since:如果请求的对象在该头部指定的时间之后修改了,才执行请求的动作(比如返回对象),否则返回代码304,告诉浏览器该对象没有修改。例如:If-Modified-Since:Thu, 10 Apr 2008 09:14:42 GMT
- 19、 If-Unmodified-Since:如果请求的对象在该头部指定的时间之后没修改过,才执行请求的动作(比如返回对象)。
- 20、 If-Range:浏览器告诉 WEB 服务器,如果我请求的对象没有改变,就把我缺少的部分给我,如果对象改变了,就把整个对象给我。浏览器通过发送请求对象的 ETag 或者 自己所知道的最后修改时间给 WEB 服务器,让其判断对象是否改变了。总是跟 Range 头部一起使用。
- 21、 Last-Modified:WEB 服务器认为对象的最后修改时间,比如文件的最后修改时间,动态页面的最后产生时间等等。例如:Last-Modified:Tue, 06 May 2008 02:42:43 GMT
- 22、 Location:WEB 服务器告诉浏览器,试图访问的对象已经被移到别的位置了,到该头部指定的位置去取。例如:Location:http://i0.sinaimg.cn/dy/deco/2008/0528/sinahome_0803_ws_005_text_0.gif
- 23、 Pramga:主要使用 Pramga: no-cache,相当于 Cache-Control: no-cache。例如:Pragma:no-cache
- 24、 Proxy-Authenticate: 代理服务器响应浏览器,要求其提供代理身份验证信息。Proxy-Authorization:浏览器响应代理服务器的身份验证请求,提供自己的身份信息。
- 25、 Range:浏览器(比如 Flashget 多线程下载时)告诉 WEB 服务器自己想取对象的哪部分。例如:Range: bytes=1173546-
- 26、 Referer:浏览器向 WEB 服务器表明自己是从哪个 网页/URL 获得/点击 当前请求中的网址/URL。例如:Referer:http://www.sina.com/
- 27、 Server: WEB 服务器表明自己是什么软件及版本等信息。例如:Server:Apache/2.0.61 (Unix)
- 28、 User-Agent: 浏览器表明自己的身份(是哪种浏览器)。例如:User-Agent:Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.8.1.14) Gecko/20080404 Firefox/2、0、0、14
- 29、 Transfer-Encoding: WEB 服务器表明自己对本响应消息体(不是消息体里面的对象)作了怎样的编码,比如是否分块(chunked)。例如:Transfer-Encoding: chunked
- 30、 Vary: WEB服务器用该头部的内容告诉 Cache 服务器,在什么条件下才能用本响应所返回的对象响应后续的请求。假如源WEB服务器在接到第一个请求消息时,其响应消息的头部为:Content-Encoding: gzip; Vary: Content-Encoding那么 Cache 服务器会分析后续请求消息的头部,检查其 Accept-Encoding,是否跟先前响应的 Vary 头部值一致,即是否使用相同的内容编码方法,这样就可以防止 Cache 服务器用自己 Cache 里面压缩后的实体响应给不具备解压能力的浏览器。例如:Vary:Accept-Encoding
- 31、 Via: 列出从客户端到 OCS 或者相反方向的响应经过了哪些代理服务器,他们用什么协议(和版本)发送的请求。当客户端请求到达第一个代理服务器时,该服务器会在自己发出的请求里面添加 Via 头部,并填上自己的相关信息,当下一个代理服务器收到第一个代理服务器的请求时,会在自己发出的请求里面复制前一个代理服务器的请求的Via 头部,并把自己的相关信息加到后面,以此类推,当 OCS 收到最后一个代理服务器的请求时,检查 Via 头部,就知道该请求所经过的路由。例如:Via:1.0 236.D0707195.sina.com.cn:80 (squid/2.6.STABLE13)
===============================================================================
HTTP 请求消息头部实例:
Host:rss.sina.com.cn
User-Agent:Mozilla/5、0 (Windows; U; Windows NT 5、1; zh-CN; rv:1、8、1、14) Gecko/20080404 Firefox/2、0、0、14
Accept:text/xml,application/xml,application/xhtml+xml,text/html;q=0、9,text/plain;q=0、8,image/png,*/*;q=0、5
Accept-Language:zh-cn,zh;q=0、5
Accept-Encoding:gzip,deflate
Accept-Charset:gb2312,utf-8;q=0、7,*;q=0、7
Keep-Alive:300
Connection:keep-alive
Cookie:userId=C5bYpXrimdmsiQmsBPnE1Vn8ZQmdWSm3WRlEB3vRwTnRtW <-- Cookie
If-Modified-Since:Sun, 01 Jun 2008 12:05:30 GMT
Cache-Control:max-age=0
HTTP 响应消息头部实例:
Status:OK - 200 <-- 响应状态码,表示 web 服务器处理的结果。
Date:Sun, 01 Jun 2008 12:35:47 GMT
Server:Apache/2、0、61 (Unix)
Last-Modified:Sun, 01 Jun 2008 12:35:30 GMT
Accept-Ranges:bytes
Content-Length:18616
Cache-Control:max-age=120
Expires:Sun, 01 Jun 2008 12:37:47 GMT
Content-Type:application/xml
Age:2
X-Cache:HIT from 236-41、D07071951、sina、com、cn <-- 反向代理服务器使用的 HTTP 头部
Via:1.0 236-41.D07071951.sina.com.cn:80 (squid/2.6.STABLE13)
Connection:close
本节摘自:http://ynhu33.blog.51cto.com/412835/408801
——最后我想说:“怪自己学艺不精,浪费了一次机会(而且是我最想进的公司)”
希望老天再给我一次机会。
PS:还有一点加速了我的死亡,我学习过Android开发。
但是用的是JAVA,经理说研究Android开发就得用NDK,那才是核心。
作者:吴秦
出处:http://www.cnblogs.com/skynet/
本文基于署名 2.5 中国大陆许可协议发布,欢迎转载,演绎或用于商业目的,但是必须保留本文的署名吴秦(包含链接).
分享到:





{kind=link}
相关推荐
实验选取了常见的HTTP协议作为研究对象,通过对HTTP协议的深入剖析,使学生能够掌握HTTP协议的基本原理、报文格式以及其工作流程。 #### 实验环境配置 - **操作系统**:Windows 7 - **网络平台**:实验室内部...
要认清HTTP协议的本质,我们需要从以下几个关键点入手: 1. 请求与响应模型:HTTP通信基于请求-响应模型。客户端发起一个HTTP请求到服务器,服务器处理请求并返回一个HTTP响应。请求由方法(如GET、POST)、URL、...
pb通过http协议传json; pb通过http协议传json; pb通过http协议传json; pb通过http协议传json; pb通过http协议传json; pb通过http协议传json; pb通过http协议传json; pb通过http协议传json; pb通过http协议传json; pb...
HTTP协议和TCP协议pcap数据包下载,支持抓包软件(如:wireshark)打开并学习HTTP协议和TCP协议报文解析。需要其他协议,请查看我发布的其他资源。
HTTP协议的工作原理: 1. 请求过程:当用户在浏览器中输入URL并按下回车键时,浏览器作为客户端(Client)构造一个HTTP请求报文,包括方法(GET、POST等)、URL、协议版本、头部信息和请求主体(如果有的话)。然后...
在IT行业中,串口通信和HTTP协议是两个重要的领域,它们在各种硬件设备与网络服务之间建立起连接。本文将深入探讨如何将串口数据转换为HTTP协议数据,并将其发送到云端,以及源码软件的跨平台特性。 串口通信,也...
HTTP 协议详解 HTTP 协议是一种应用层面的、面向对象的协议,用于分布式超媒体信息系统。它于 1990 年提出,经过多年的发展和完善,目前在 WWW 中使用的是 HTTP/1.0 的第六版,HTTP/1.1 的规范化工作正在进行中。 ...
串口转HTTP协议发送数据工具源码是一种实用的软件解决方案,它允许用户将从串行端口(串口)接收到的数据转换为HTTP协议格式,然后发送到预设的云端HTTP服务器。这种工具在物联网(IoT)和嵌入式系统中特别有用,...
**HTTP协议详解** HTTP(Hypertext Transfer Protocol)超文本传输协议是互联网上应用最广泛的一种网络协议。它是用于从万维网服务器传输超文本到本地浏览器的传输协议,是Web应用的基础。HTTP协议定义了客户端...
1. **无状态**:HTTP协议自身不维护连接状态,每次请求和响应都是独立的,服务器不会记住之前请求的信息。为了实现状态保持,开发者通常会使用Cookie或Session。 2. **简单快速**:设计时主要考虑快速传输,对数据...
HTTP协议分析工具能够帮助我们深入理解HTTP通信过程,包括请求方法、状态码、头部信息、请求体和响应体等关键元素。 首先,让我们看看JavaScript。JavaScript是一种轻量级的解释性编程语言,常用于网页和网络应用...
HTTP协议详解 HTTP协议详解HTTP协议详解HTTP协议详解HTTP协议详解HTTP协议详解.pdf小巧,清晰,全面的PDF,值得收藏
本次实验是关于计算机网络原理的Wireshark工具使用,主要目标是对HTTP协议进行深入分析。实验过程中,我们使用Wireshark对电脑的WLAN端口进行抓包,观察并解析访问www.baidu.com网站时的网络通信过程。通过对HTTP...
HTTP协议详解电子书 HTTP(超文本传输协议)是互联网上应用最为广泛的一种网络协议,它的设计目的是为了传输数据,并且使数据交换变得简单、高效。HTTP协议是基于TCP/IP通信协议来传输数据的,主要负责客户端...
基于STM32f103 http协议历程
【基于STM32F103单片机,配合HTTP协议上传数据到服务器】的知识点主要涵盖以下几个方面: 1. **STM32F103单片机**:STM32是意法半导体(STMicroelectronics)推出的一种基于ARM Cortex-M3内核的微控制器系列。STM32...
本文将深入探讨基于HTTP协议的自定义协议封装,特别是在使用XML作为数据载体时如何进行设计和实现。HTTP(超文本传输协议)是互联网上应用最为广泛的一种网络协议,它允许客户端(如浏览器)和服务器之间交换数据。...
在深入探讨iOS网络编程中HTTP协议的应用之前,首先需要了解HTTP协议本身的一些基础知识。HTTP协议全称为超文本传输协议(Hypertext Transfer Protocol),是一种应用层协议,用于在客户端和服务器之间进行无状态的、...
### HTTP协议详细介绍 #### HTTP协议概述 HTTP,全称为HyperText Transfer Protocol,即超文本传输协议,是一种用于从Web服务器传输超文本到本地浏览器的传送协议。它在互联网的应用层中占据重要地位,使得浏览器...