
و‘کè¦پï¼ڑآ وœ؛ه™¨ه¦ن¹ PAIé€ڑè؟‡ه£°éں³و•°وچ®هˆ†è¾¨ç”·ه¥³ï¼ˆهگ«è¯éں³ç‰¹ه¾پوڈگهڈ–相ه…³و•°وچ®ه’Œن»£ç پ)
背و™¯
éڑڈç€ن؛؛ه·¥و™؛能çڑ„ç®—و³•هڈ‘ه±•ï¼Œه¯¹ن؛ژé结و„هŒ–و•°وچ®çڑ„ه¤„çگ†èƒ½هٹ›è¶ٹو¥è¶ٹهڈ—هˆ°é‡چ视,è؟™é‡Œé¢çڑ„ه…³é”®ن¸€çژ¯ه°±وک¯è¯éں³و•°وچ®çڑ„ه¤„çگ†م€‚ç›®ه‰چ,许ه¤ڑه…³ن؛ژè¯éں³è¯†هˆ«çڑ„ه؛”用و،ˆن¾‹ه·²ç»ڈه½±ه“چç€وˆ‘ن»¬çڑ„ç”ںو´»ï¼Œن¾‹ه¦‚ن¸€ن؛›و™؛能éں³ç®±ن¸هˆ©ç”¨è¯éں³هڈ‘é€پوŒ‡ن»¤ï¼Œن¸€ن؛›وگœç´¢ه·¥ه…·هˆ©ç”¨è¯éں³è¾“ه‡؛و–‡وœ¬ن»£و›؟é”®ç›که½•ه…¥م€‚
وœ¬و–‡وˆ‘ن»¬ه°†é’ˆه¯¹è¯éں³è¯†هˆ«ن¸وœ€ç®€هچ•çڑ„و،ˆن¾‹â€œç”·ه¥³ه£°éں³â€è¯†هˆ«ï¼Œç»“هگˆوœ¬هœ°çڑ„Rه·¥ه…·ن»¥هڈٹوœ؛ه™¨ه¦ن¹ PAI,ن¸؛ه¤§ه®¶è؟›è،Œن»‹ç»چم€‚é€ڑè؟‡وœ¬و،ˆن¾‹ï¼Œهڈ¯ن»¥ه°†ن»»ن½•ç”¨وˆ·çڑ„è¯éں³و•°وچ®و ‡è®°ه‡؛و€§هˆ«ï¼Œه¹¶ن¸”ن؟وŒپé«که‡†ç،®çژ‡م€‚وˆ‘ن»¬وٹٹو•´ن¸ھه®éھŒوµپ程هˆ‡هˆ†ن¸؛ن¸¤éƒ¨هˆ†ï¼Œç¬¬ن¸€éƒ¨هˆ†وک¯ه£°éں³ن؟،هڈ·çڑ„特ه¾پوڈگهڈ–,é€ڑè؟‡Rçڑ„ن؟،هڈ·ه¤„çگ†ه·¥ه…·ه®çژ°ï¼›ç¬¬ن؛Œéƒ¨هˆ†é€ڑè؟‡وœ؛ه™¨ه¦ن¹ PAIه®çژ°ç”·ه¥³ه£°éں³هˆ†ç±»و¨،ه‹çڑ„è®ç»ƒï¼Œوœ¬ه®éھŒéœ€è¦پن؛‹ه…ˆç§¯ç´¯ç”·ه¥³ه£°éں³çڑ„ه½•éں³و•°وچ®ï¼Œوœ¬و–‡ه·²ç»ڈوڈگن¾›ه¤„çگ†ه¥½çڑ„3000و،è¯éں³و•°وچ®ï¼Œو–‡ç« وœ«ه°¾وڈگن¾›ن¸‹è½½م€‚
ه£°éں³ن؟،هڈ·ç‰¹ه¾پوڈگهڈ–
è¯éں³و•°وچ®ن¸ژه›¾هƒڈو•°وچ®ن»¥هڈٹو–‡وœ¬و•°وچ®ن¸چهگŒï¼Œه¦‚وœç»ڈه¸¸ن½؟用KوŒè½¯ن»¶وˆ–者وک¯è¯éں³هگˆوˆگ软ن»¶ï¼Œن¸چéڑ¾çگ†è§£è¯éں³و•°وچ®é€ڑه¸¸وˆگن؟،هڈ·çٹ¶هˆ†ه¸ƒم€‚ ن¸؛ن؛†وœ‰و•ˆçڑ„é€ڑè؟‡ç®—و³•ه¤„çگ†è؟™ç§چو³¢ه½¢و•°وچ®ï¼Œéœ€è¦پ首ه…ˆé€ڑè؟‡ن؟،هڈ·ه¤„çگ†ه·¥ه…·ه¯¹è¯éں³ن؟،هڈ·è؟›è،Œه¤„çگ†م€‚وœ¬و–‡وˆ‘ن»¬é€‰ç”¨çڑ„وک¯Rè¯è¨€çڑ„warbleRهŒ…,warbleRهŒ…هگ«ه¤§é‡ڈçڑ„频谱ه¤„çگ†ه·¥ه…·ï¼Œهڈ¯ن»¥é€ڑè؟‡ه…¶ن¸çڑ„频谱ه¤„çگ†ه‡½و•°وڈگهڈ–ه‡؛ه…³ن؛ژه£°éں³çڑ„ن»¥ن¸‹ç‰¹ه¾پن؟،وپ¯ï¼Œه› ن¸؛ç”·ç”ںه’Œه¥³ç”ںهœ¨ه£°éں³é¢‘çژ‡م€پوŒ¯ه¹…çڑ„و–¹é¢ن¸€ه®ڑوœ‰ه¾ˆه¤§هŒ؛هˆ«ï¼Œو‰€ن»¥è¦پé€ڑè؟‡وڈگهڈ–ن»¥ن¸‹ç‰¹ه¾په¸®هٹ©وˆ‘ن»¬è؟›è،Œهˆ†ç±»ï¼ڑ
ن¸؛ن؛†وœ‰و•ˆçڑ„é€ڑè؟‡ç®—و³•ه¤„çگ†è؟™ç§چو³¢ه½¢و•°وچ®ï¼Œéœ€è¦پ首ه…ˆé€ڑè؟‡ن؟،هڈ·ه¤„çگ†ه·¥ه…·ه¯¹è¯éں³ن؟،هڈ·è؟›è،Œه¤„çگ†م€‚وœ¬و–‡وˆ‘ن»¬é€‰ç”¨çڑ„وک¯Rè¯è¨€çڑ„warbleRهŒ…,warbleRهŒ…هگ«ه¤§é‡ڈçڑ„频谱ه¤„çگ†ه·¥ه…·ï¼Œهڈ¯ن»¥é€ڑè؟‡ه…¶ن¸çڑ„频谱ه¤„çگ†ه‡½و•°وڈگهڈ–ه‡؛ه…³ن؛ژه£°éں³çڑ„ن»¥ن¸‹ç‰¹ه¾پن؟،وپ¯ï¼Œه› ن¸؛ç”·ç”ںه’Œه¥³ç”ںهœ¨ه£°éں³é¢‘çژ‡م€پوŒ¯ه¹…çڑ„و–¹é¢ن¸€ه®ڑوœ‰ه¾ˆه¤§هŒ؛هˆ«ï¼Œو‰€ن»¥è¦پé€ڑè؟‡وڈگهڈ–ن»¥ن¸‹ç‰¹ه¾په¸®هٹ©وˆ‘ن»¬è؟›è،Œهˆ†ç±»ï¼ڑ
وژ¥ن¸‹و¥ن¼ڑ讲解ه¦‚ن½•وڈگهڈ–è؟™ن؛›ه£°éں³ن؟،هڈ·çڑ„特ه¾پï¼ڑ
1.ه®‰è£…R
首ه…ˆه®‰è£…Rè¯è¨€هŒ…,warbleR需è¦پRçڑ„版وœ¬وک¯3.2ن»¥ن¸ٹ,è؟™é‡Œه¼؛烈ه»؛è®®ه¤§ه®¶ن½؟用3.3.3版وœ¬ï¼ˆهچڑن¸»هœ¨ن½؟用3.4çڑ„و—¶ه€™éپ‡هˆ°é”™è¯¯ï¼‰م€‚ه…·ن½“Rçڑ„ه®‰è£…و–¹ه¼ڈ网ن¸ٹوœ‰ه¾ˆه¤ڑن»‹ç»چ,è؟™é‡Œه°±ن¸چ详细ن»‹ç»چن؛†م€‚
2.ه®‰è£…warbleR
ه®‰è£…ه®ŒRن¹‹هگژ,è؟›ه…¥Rه‘½ن»¤è،Œï¼Œéœ€è¦پé€ڑè؟‡ن»¥ن¸‹ه‘½ن»¤ه®‰è£…warbleRï¼ڑ

è؟™é‡Œéœ€è¦پو³¨و„ڈçڑ„وک¯é•œهƒڈوœ€ه¥½ن½؟用ç¾ژه›½çڑ„é»ک认镜هƒڈوœچهٹ،,需è¦پç؟»*,ن¸چ然ه¾ˆوœ‰هڈ¯èƒ½ن¼ڑه®‰è£…ن¸چوˆگهٹں,ه› ن¸؛ه›½ه†…çڑ„é•œهƒڈن¼ڑç¼؛ه°‘وںگن؛›ن¾èµ–هŒ…م€‚
3.特ه¾پوڈگهڈ–
首ه…ˆوٹٹ需è¦په¤„çگ†çڑ„ه½•éں³و•°وچ®ï¼ˆه؟…é،»وک¯wavو ¼ه¼ڈ)وŒ‰ç…§ç”·ه£°م€په¥³ه£°هˆ†è£…هœ¨maleه’Œfemaleن¸¤ن¸ھو–‡ن»¶ه¤¹ن¸ï¼Œç„¶هگژو‰§è،Œç¬”者وڈگن¾›çڑ„Rè„ڑوœ¬ن»£ç پ(و–‡وœ«وڈگن¾›ن؛†ن¸‹è½½é“¾وژ¥ï¼‰م€‚需è¦په°†ن»£ç پن¸ن»¥ن¸‹ن¸¤ن¸ھو–‡ن»¶è·¯ه¾„و”¹ن¸؛è‡ھه·±ه»؛ç«‹çڑ„maleن»¥هڈٹfemaleو–‡ن»¶è·¯ه¾„هچ³هڈ¯ï¼ڑ
و‰§è،Œè؟™ن¸ھRè„ڑوœ¬ï¼Œه°±ن¼ڑه°†wavو ¼ه¼ڈçڑ„ه£°éں³و–‡ن»¶è½¬هŒ–ن¸؛结و„هŒ–و•°وچ®ï¼Œو•°وچ®ن¼ڑهکه‚¨ن¸؛ن¸€ن¸ھCSVو–‡ن»¶م€‚و–‡ن»¶éƒ¨هˆ†وˆھه›¾ï¼ڑ
PAIè®ç»ƒç”·ه¥³ه£°éں³هˆ†ç±»و¨،ه‹
1.ه¯¼ه…¥و•°وچ®
ه°†é€ڑè؟‡Rه¤„çگ†هگژçڑ„و•°وچ®ه¯¼ه…¥PAIه¹³هڈ°ï¼Œن¹ںهڈ¯ن»¥ç›´وژ¥ه°†و–‡وœ«وڈگن¾›çڑ„ه¤„çگ†ه¥½çڑ„و•°وچ®ه¯¼ه…¥م€‚ه…·ن½“و–¹و³•هڈ¯ن»¥çœ‹ï¼ڑ
https://help.aliyun.com/video_detail/54945.html
و•°وچ®ه¯¼ه…¥هگژ,هڈ¯ن»¥çœ‹هˆ°وœ‰20ن¸ھ特ه¾پن»¥هڈٹ1هˆ—labelهˆ—,
2.ه»؛ç«‹هˆ†ç±»و¨،ه‹
é€ڑè؟‡و‹–و‹‰PAIه¹³هڈ°çڑ„组ن»¶وگه»؛ه®éھŒï¼Œه®éھŒوµپ程ه›¾ï¼ڑ
-
voice_classify:ن¸؛و•°وچ®è¯»ه…¥و؛گ
-
و‹†هˆ†:ه°†و•°وچ®é›†و‹†هˆ†ن¸؛è®ç»ƒé›†ن»¥هڈٹ预وµ‹é›†
-
ç؛؟و€§و”¯وŒپهگ‘é‡ڈوœ؛ï¼ڑé€ڑè؟‡SVMç®—و³•è®ç»ƒç”ںوˆگو¨،ه‹
-
预وµ‹ç»„ن»¶ï¼ڑé€ڑè؟‡و¨،ه‹ه¯¹é¢„وµ‹é›†é¢„وµ‹
-
و··و·†çں©éکµï¼ڑ用و¥è¯„ن¼°
è؟™وک¯ن¸€ن¸ھو¯”较简هچ•çڑ„ن؛Œهˆ†ç±»هœ؛و™¯ï¼Œه…·ن½“ن¹ںهڈ¯ن»¥هڈ‚看ن¹‹ه‰چçڑ„ن¸€ن؛›و–‡ç« ï¼ڑ
https://yq.aliyun.com/articles/54260
3.评ن¼°
وœ€ç»ˆâ€œو··و·†çں©éکµâ€ç»„ن»¶ن¼ڑوک¾ç¤؛ه¦‚ن¸‹ه›¾çڑ„هˆ†ç±»è¯„ن¼°ï¼ڑ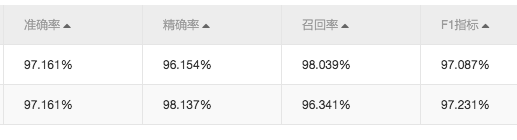 é€ڑè؟‡و··و·†çں©éکµï¼Œهڈ¯ن»¥çœ‹هˆ°ç”·ه¥³ه£°éں³çڑ„هˆ†ç±»è؟کوک¯éه¸¸ç²¾ه‡†çڑ„م€‚
é€ڑè؟‡و··و·†çں©éکµï¼Œهڈ¯ن»¥çœ‹هˆ°ç”·ه¥³ه£°éں³çڑ„هˆ†ç±»è؟کوک¯éه¸¸ç²¾ه‡†çڑ„م€‚
و€»ç»“
وœ¬و–‡é€ڑè؟‡ن½؟用Rè„ڑوœ¬ن»¥هڈٹوœ؛ه™¨ه¦ن¹ PAIه®çژ°ن؛†ç”·ه¥³ه£°éں³هˆ†ç±»çڑ„و،ˆن¾‹ï¼Œوœ€ç»ˆçڑ„ه‡†ç،®çژ‡è¾¾هˆ°ç™¾هˆ†ن¹‹ن¹هچپه…«ه·¦هڈ³م€‚هœ¨ه®é™…ن½؟用è؟‡ç¨‹ن¸ï¼Œç”¨وˆ·éœ€è¦پو‰§è،Œن»¥ن¸‹ه‡ و¥ï¼ڑ(1)首ه…ˆç§¯ç´¯éœ€è¦پهˆ†ç±»çڑ„ه£°éں³و–‡ن»¶ï¼Œو•°وچ®è¶ٹه¤ڑè¶ٹه¥½ï¼Œهکه‚¨ن¸؛wavو ¼ه¼ڈم€‚(2)然هگژé€ڑè؟‡Rè„ڑوœ¬ه¯¹و‰“و ‡ه¥½çڑ„ه£°éں³و–‡ن»¶è؟›è،Œç‰¹ه¾پوڈگهڈ–م€‚(3)ه°†ه¤„çگ†هگژçڑ„و•°وچ®ن¸ٹن¼ PAI,ه»؛ç«‹هˆ†ç±»و¨،ه‹هچ³هڈ¯م€‚
PAIهœ°ه€ï¼ڑ
https://data.aliyun.com/product/learnن¼پن¸ڑوœچهٹ،ه’¨è¯¢ï¼ڑ
https://survey.aliyun.com/survey/AMgL8_Pm5و•°وچ®ن¸‹è½½ï¼ˆن»£ç پهڈٹو•°وچ®و¥è‡ھwarbleR社هŒ؛ه¼€و؛گوڈگن¾›ï¼‰ï¼ڑ
https://github.com/jimenbian/PAI_voice_classify
آ
هژںو–‡é“¾وژ¥ï¼ڑhttps://yq.aliyun.com/articles/217214



相ه…³وژ¨èچگ
ن¾‹ه¦‚,هœ¨وƒ…و„ں识هˆ«ن¸ï¼Œé€ڑè؟‡OpenSMILEوڈگهڈ–çڑ„特ه¾پهڈ¯ن»¥è¾“ه…¥هˆ°وœ؛ه™¨ه¦ن¹ و¨،ه‹ï¼Œه¦‚و”¯وŒپهگ‘é‡ڈوœ؛(SVM)م€پو·±ه؛¦ç¥ç»ڈ网络(DNN)ç‰ï¼Œو¥è®ç»ƒه’Œé¢„وµ‹è¯´è¯ن؛؛çڑ„وƒ…ç»ھçٹ¶و€پم€‚هœ¨è¯´è¯ن؛؛识هˆ«ن»»هٹ،ن¸ï¼ŒOpenSMILEهڈ¯ن»¥وڈگهڈ–说è¯ن؛؛çڑ„独特è¯éں³ç‰¹ه¾پ,...
م€گmcm è¯éں³ç‰¹ه¾پوڈگهڈ–程ه؛ڈم€‘وک¯ç”¨ن؛ژه¤„çگ†ه’Œهˆ†وگéں³é¢‘و•°وچ®çڑ„ن¸“ن¸ڑه·¥ه…·ï¼Œه®ƒن¸»è¦په؛”用ن؛ژè¯éں³è¯†هˆ«م€پè¯éں³هگˆوˆگم€پوƒ…و„ںهˆ†وگç‰è¯éں³ه¤„çگ†é¢†هںںم€‚程ه؛ڈçڑ„و ¸ه؟ƒهٹں能وک¯وڈگهڈ–è¯éں³ن؟،هڈ·çڑ„ه…³é”®ç‰¹ه¾پ,ن»¥ن¾؟ن؛ژهگژç»çڑ„وœ؛ه™¨ه¦ن¹ وˆ–و¨،ه¼ڈ识هˆ«ن»»هٹ،م€‚هœ¨وڈڈè؟°ن¸...
çژ°ن»£وœ؛ه™¨ه¦ن¹ 领هںںن¸ï¼Œو·±ه؛¦ه¦ن¹ هœ¨ه›¾هƒڈ特ه¾پوڈگهڈ–و–¹é¢çڑ„ه؛”用ه·²ç»ڈوˆگن¸؛ن¸»وµپوٹ€وœ¯م€‚و·±ه؛¦ه¦ن¹ ,特هˆ«وک¯و·±ه؛¦ç¥ç»ڈ网络(DNN),能ه¤ںن»ژهژںه§‹و•°وچ®ن¸è‡ھهٹ¨ه¦ن¹ هˆ°é«کç؛§هˆ«çڑ„وٹ½è±،特ه¾پ,ن»ژ而وپه¤§هœ°وڈگهچ‡ن؛†ه›¾هƒڈه¤„çگ†ن»»هٹ،çڑ„و€§èƒ½م€‚ن¼ ç»ںçڑ„وœ؛ه™¨...
وœ؛ه™¨ه¦ن¹ وˆ؟ن»·é¢„وµ‹و•°وچ®é›†و؛گن»£ç پوœ؛ه™¨ه¦ن¹ وˆ؟ن»·é¢„وµ‹و•°وچ®é›†و؛گن»£ç پوœ؛ه™¨ه¦ن¹ وˆ؟ن»·é¢„وµ‹و•°وچ®é›†و؛گن»£ç پوœ؛ه™¨ه¦ن¹ وˆ؟ن»·é¢„وµ‹و•°وچ®é›†و؛گن»£ç پوœ؛ه™¨ه¦ن¹ وˆ؟ن»·é¢„وµ‹و•°وچ®é›†و؛گن»£ç پم€‚وœ؛ه™¨ه¦ن¹ وˆ؟ن»·é¢„وµ‹و•°وچ®é›†و؛گن»£ç پوœ؛ه™¨ه¦ن¹ وˆ؟ن»·é¢„وµ‹و•°وچ®é›†و؛گن»£ç پ...
MFCCه€ں鉴ن؛†ن؛؛耳ه¯¹ه£°éں³é¢‘çژ‡و„ںçں¥çڑ„特و€§ï¼Œé€ڑè؟‡و¢…ه°”و»¤و³¢ه™¨ç»„ه°†é¢‘è°±هˆ†و®µï¼Œç„¶هگژè؟›è،Œç¦»و•£ن½™ه¼¦هڈکوچ¢ï¼ˆDCT),وœ€ç»ˆه¾—هˆ°ن¸€ç³»هˆ—ç³»و•°ï¼Œè؟™ن؛›ç³»و•°èƒ½ه¤ںوœ‰و•ˆهœ°وچ•وچ‰هˆ°è¯éں³ن؟،هڈ·çڑ„ن¸»è¦پ特ه¾پ,هŒ…و‹¬éں³è°ƒم€پéں³èٹ‚结و„ه’Œéںµه¾‹ç‰م€‚ هœ¨MFCCçڑ„وڈگهڈ–...
çژ°ن»£وœ؛ه™¨ه¦ن¹ 领هںں,ه°¤ه…¶وک¯و·±ه؛¦ه¦ن¹ ,ه·²ç»ڈهœ¨ه›¾هƒڈ特ه¾پوڈگهڈ–و–¹é¢هڈ–ه¾—ن؛†وک¾è‘—çڑ„è؟›و¥م€‚ه›¾هƒڈ特ه¾پوڈگهڈ–وک¯è®،ç®—وœ؛视觉ن¸çڑ„ه…³é”®و¥éھ¤ï¼Œه®ƒو¶‰هڈٹهˆ°ن»ژهژںه§‹هƒڈç´ و•°وچ®ن¸وڈگهڈ–ه‡؛وœ‰و„ڈن¹‰çڑ„م€پوœ‰هٹ©ن؛ژهˆ†ç±»وˆ–识هˆ«çڑ„特ه¾پم€‚و·±ه؛¦ه¦ن¹ é€ڑè؟‡و„ه»؛ه¤چو‚çڑ„...
ه°†è؟™ن¸¤é،¹وٹ€وœ¯ه؛”用ن؛ژوپ¶و„ڈن»£ç پو£€وµ‹ï¼Œو„ڈه‘³ç€é€ڑè؟‡è®ç»ƒوœ؛ه™¨ه¦ن¹ و¨،ه‹و¥è‡ھهٹ¨è¯†هˆ«وپ¶و„ڈ软ن»¶çڑ„هگ„ç§چ特ه¾پ,ه¹¶é€ڑè؟‡و•°وچ®وŒ–وژکوٹ€وœ¯ن»ژه¤§é‡ڈو ·وœ¬ن¸وڈگ炼ه‡؛وœ‰و•ˆçڑ„و£€وµ‹و¨،ه¼ڈم€‚ هœ¨هں؛ن؛ژو•°وچ®وŒ–وژکه’Œوœ؛ه™¨ه¦ن¹ çڑ„وپ¶و„ڈن»£ç پو£€وµ‹و–¹و³•ن¸ï¼Œé¦–ه…ˆéœ€è¦په»؛ç«‹...
و–‡ç« ن¸çڑ„ه®وˆکو،ˆن¾‹ه±•ç¤؛ن؛†وœ؛ه™¨ه¦ن¹ هœ¨ه®é™…ن¸ڑهٹ،ن¸çڑ„ه؛”用,ه¦‚ه›¾هƒڈهˆ†ç±»ه’Œé£ژ险وژ§هˆ¶ï¼Œè؟™ن؛›ه؛”用ن¸چن»…ن»…وک¯çگ†è®؛ن¸ٹçڑ„ه°è¯•ï¼Œè€Œوک¯é€ڑè؟‡PAIه¹³هڈ°çڑ„é«کو•ˆه®çژ°ï¼Œن½“çژ°ن؛†وœ؛ه™¨ه¦ن¹ وٹ€وœ¯هœ¨è§£ه†³ه®é™…é—®é¢کن¸çڑ„ه·¨ه¤§و½œهٹ›ه’Œن»·ه€¼م€‚éڑڈç€وœ؛ه™¨ه¦ن¹ ه’Œ...
هœ¨وœ¬و–‡ن¸ï¼Œوˆ‘ن»¬ه°†و·±ه…¥وژ¢è®¨هں؛ن؛ژوœ؛ه™¨ه¦ن¹ çڑ„è¯éں³ن؟،هڈ·هڈکه£°هڈک调系ç»ں,该系ç»ںوک¯ç”¨MATLAB编程è¯è¨€ه®çژ°çڑ„,ه¹¶é™„ه¸¦ن؛†ç›¸ه؛”çڑ„و؛گن»£ç په’Œو•°وچ®é›†م€‚MATLABوک¯ن¸€ç§چه¹؟و³›ç”¨ن؛ژ科ه¦è®،ç®—م€پو•°وچ®هˆ†وگه’Œه·¥ç¨‹ه؛”用çڑ„ه¼؛ه¤§ه·¥ه…·ï¼Œه…¶ن¸°ه¯Œçڑ„ه؛“ه’Œç›´è§‚çڑ„...
è؟™ن¸ھهگچن¸؛“وœ€و–°وœ؛ه™¨ه¦ن¹ ن»£ç په’Œو•°وچ®â€çڑ„هژ‹ç¼©هŒ…وک¾ç„¶وڈگن¾›ن؛†è؟™و ·çڑ„资و؛گ,特هˆ«é€‚هگˆé‚£ن؛›ه¯¹وœ؛ه™¨ه¦ن¹ ه’Œو·±ه؛¦ه¦ن¹ وœ‰çƒوƒ…çڑ„ه¦ن¹ 者ه’Œن¸“ن¸ڑن؛؛ه£«م€‚ 首ه…ˆï¼Œوˆ‘ن»¬و¥çœ‹و–‡ن»¶هگچ“firstcoursemlcodeâ€م€‚è؟™ه¾ˆهڈ¯èƒ½وک¯ن¸€ن¸ھهŒ…هگ«هˆç؛§هˆ°ن¸ç؛§و°´ه¹³...
وœ¬ه¥—و–‡ن»¶ن¸çڑ„ه†…ه®¹و¶‰هڈٹن؛†è¯éں³و•°وچ®ç‰¹ه¾پوڈگهڈ–ن¸ژهˆ†ç±»çڑ„و•´ن¸ھوµپ程,هŒ…و‹¬وٹ€وœ¯ç»†èٹ‚م€په¼•è¨€م€پهˆ†ç±»ç®—و³•çڑ„选و‹©ه’Œç²¾ه؛¦è¯„ن¼°ç‰م€‚é€ڑè؟‡è؟™ن؛›و–‡و،£èµ„و–™ï¼Œهڈ¯ن»¥ç³»ç»ںهœ°ن؛†è§£هœ¨MATLABçژ¯ه¢ƒن¸‹ه¦‚ن½•è؟›è،Œè¯éں³و•°وچ®çڑ„ه¤„çگ†ه’Œهˆ†وگ,ن¸؛相ه…³é¢†هںںç ”ç©¶è€…ه’Œ...
éک؟里ن؛‘وœ؛ه™¨ه¦ن¹ PAIه¹³هڈ°وڈگن¾›ن؛†ه¼؛ه¤§çڑ„وœ؛ه™¨ه¦ن¹ ç®—و³•ه’Œو¨،ه‹و¥ه¤„çگ†é©¾é©¶è،Œن¸؛识هˆ«ن¸çڑ„و•°وچ®م€‚ه¹³هڈ°و”¯وŒپه¤ڑç§چوœ؛ه™¨ه¦ن¹ ç®—و³•ï¼Œه¦‚ه†³ç–و ‘م€پéڑڈوœ؛و£®و—م€پç¥ç»ڈ网络ç‰ï¼Œهڈ¯ن»¥و ¹وچ®ه…·ن½“çڑ„ه؛”用هœ؛و™¯é€‰و‹©هگˆé€‚çڑ„ç®—و³•م€‚هگŒو—¶ï¼Œه¹³هڈ°è؟کوڈگن¾›ن؛†ن¸°ه¯Œçڑ„...
هœ¨وœ¬و¬،讨è®؛çڑ„و–‡ن»¶هگچ称هˆ—è،¨ن¸ï¼Œوˆ‘ن»¬هڈ¯ن»¥çœ‹هˆ°ه¤ڑن¸ھن¸ژè¯éں³و•°وچ®ç‰¹ه¾پوڈگهڈ–ه’Œهˆ†ç±»ç›¸ه…³çڑ„و–‡و،£ï¼Œه¦‚“هں؛ن؛ژçڑ„è¯éں³و•°وچ®ç‰¹ه¾پوڈگهڈ–هˆ†ç±»ن¸ژç²¾ه؛¦è¯„ن¼°ن¸€ه¼•è¨€هœ¨ه½“ه‰چ.docâ€ه’Œâ€œهں؛ن؛ژçڑ„è¯éں³و•°وچ®ç‰¹ه¾پوڈگهڈ–ن¸ژهˆ†ç±»هˆ†وگن¸€ه¼•è¨€هœ¨ه½“ن»ٹçڑ„و•°.docâ€م€‚...
该ه®ن¾‹ن»£ç پوڈگن¾›ن؛†ن¸€ن¸ھه®Œو•´çڑ„وœ؛ه™¨ه¦ن¹ ه›ه½’ه®ن¾‹ï¼Œه±•ç¤؛ن؛†ه¦‚ن½•ن½؟用 Python è¯è¨€ه’Œç›¸ه…³ه؛“و¥è§£ه†³ه›ه½’é—®é¢کم€‚该ه®ن¾‹ن»£ç پهڈ¯ن»¥ن½œن¸؛وœ؛ه™¨ه¦ن¹ ه…¥é—¨è€…çڑ„هڈ‚考,ه¸®هٹ©ن»–ن»¬و›´ه¥½هœ°çگ†è§£وœ؛ه™¨ه¦ن¹ çڑ„هں؛وœ¬و¦‚ه؟µه’Œه®çژ°و–¹و³•م€‚
è؟™ç¯‡و–‡و،£ه°†و·±ه…¥وژ¢è®¨ن¸€ن¸ھهˆ©ç”¨وœ؛ه™¨ه¦ن¹ وٹ€وœ¯é€ڑè؟‡è¯éں³هˆ†وگو¥è¯ٹو–ه¸•é‡‘و£®ç—…çڑ„é،¹ç›®م€‚ه¸•é‡‘و£®ç—…وک¯ن¸€ç§چç¥ç»ڈç³»ç»ں退è،Œو€§ç–¾ç—…,ن¸»è¦پè،¨çژ°ن¸؛震颤م€پ肌肉هƒµç›´ه’Œè؟گهٹ¨éڑœç¢چم€‚é€ڑè؟‡è¯éں³ç‰¹ه¾پçڑ„هˆ†وگ,هڈ¯ن»¥وچ•وچ‰هˆ°ه¸•é‡‘و£®ç—…و‚£è€…特وœ‰çڑ„è¯è¨€ه¼‚ه¸¸ï¼Œ...
è؟™ن¸ھو•°وچ®é›†ï¼Œهگچن¸؛“وœ؛ه™¨ه¦ن¹ è¯éں³è¯†هˆ«و•°وچ®â€ï¼Œوک¯ن¸“ن¸؛هˆه¦è€…设è®،çڑ„ن¸€ن¸ھ简هچ•è¯†هˆ«و•°وچ®é›†ï¼Œç”¨ن؛ژو•™وژˆه’Œه®è·µه¦‚ن½•ه؛”用وœ؛ه™¨ه¦ن¹ ç®—و³•è؟›è،Œè¯éں³ç‰¹ه¾پهˆ†وگن¸ژهˆ†ç±»م€‚ 首ه…ˆï¼Œوˆ‘ن»¬و¥وژ¢è®¨è¯éں³è¯†هˆ«çڑ„هں؛وœ¬هژںçگ†م€‚è¯éں³ن؟،هڈ·وک¯ن¸€ç§چéç؛؟و€§م€پé...
وœ¬é،¹ç›®وک¯هں؛ن؛ژPythonه®çژ°çڑ„MFCC特ه¾پوڈگهڈ–,é€ڑè؟‡ن»–ن؛؛çڑ„ن»£ç پهں؛ç،€è؟›è،Œن؛†ن¸€ن؛›ه¼€هڈ‘,هŒ…و‹¬ه¯¹هں؛وœ¬ç‰¹ه¾پم€پن¸€ç؛§ه·®هˆ†ه’Œن؛Œç؛§ه·®هˆ†çڑ„وڈگهڈ–م€‚ MFCCçڑ„وڈگهڈ–وµپ程ن¸»è¦پهŒ…و‹¬ن»¥ن¸‹ه‡ ن¸ھو¥éھ¤ï¼ڑ 1. **预هٹ é‡چ**ï¼ڑهœ¨éں³é¢‘ن؟،هڈ·çڑ„ه¼€ه¤´هٹ وƒï¼Œن»¥و¨،و‹ںن؛؛...
و¨،ه¼ڈ识هˆ«ن¸ژوœ؛ه™¨ه¦ن¹ ï¼ڑ第ه››ç« 特ه¾پ选و‹©ه’Œوڈگهڈ–.ppt