
Apache Kafka 从 0.11.0 开始,支持了一个非常大的 feature,就是对事务性的支持,在 Kafka 中关于事务性,是有三种层面上的含义:一是幂等性的支持;二是事务性的支持;三是 Kafka Streams 的 exactly once 的实现,关于 Kafka 事务性系列的文章我们只重点关注前两种层面上的事务性,与 Kafka Streams 相关的内容暂时不做讨论。社区从开始讨论事务性,前后持续近半年时间,相关的设计文档有六十几页(参考 Exactly Once Delivery and Transactional Messaging in Kafka)。事务性这部分的实现也是非常复杂的,之前 Producer 端的代码实现其实是非常简单的,增加事务性的逻辑之后,这部分代码复杂度提高了很多,本篇及后面几篇关于事务性的文章会以 2.0.0 版的代码实现为例,对这部分做了一下分析,计划分为五篇文章:
- 第一篇:Kafka 幂等性实现;
- 第二篇:Kafka 事务性实现;
- 第三篇:Kafka 事务性相关处理请求在 Server 端如何处理及其实现细节;
- 第四篇:关于 Kafka 事务性实现的一些思考,也会简单介绍一下 RocketMQ 事务性的实现,做一下对比;
- 第五篇:Flink + Kafka 如何实现 Exactly Once;
这篇是 Kafka 事务性系列的第一篇文章,主要讲述幂等性实现的整体流程,幂等性的实现相对于事务性的实现简单很多,也是事务性实现的基础。
Producer 幂等性
Producer 的幂等性指的是当发送同一条消息时,数据在 Server 端只会被持久化一次,数据不丟不重,但是这里的幂等性是有条件的:
- 只能保证 Producer 在单个会话内不丟不重,如果 Producer 出现意外挂掉再重启是无法保证的(幂等性情况下,是无法获取之前的状态信息,因此是无法做到跨会话级别的不丢不重);
- 幂等性不能跨多个 Topic-Partition,只能保证单个 partition 内的幂等性,当涉及多个 Topic-Partition 时,这中间的状态并没有同步。
如果需要跨会话、跨多个 topic-partition 的情况,需要使用 Kafka 的事务性来实现。
幂等性示例
Producer 使用幂等性的示例非常简单,与正常情况下 Producer 使用相比变化不大,只需要把 Producer 的配置 enable.idempotence 设置为 true 即可,如下所示:
1 2 3 4 5 6 7 8 9 10 |
Properties props = new Properties(); props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true"); props.put("acks", "all"); // 当 enable.idempotence 为 true,这里默认为 all props.put("bootstrap.servers", "localhost:9092"); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer producer = new KafkaProducer(props); producer.send(new ProducerRecord(topic, "test"); |
Prodcuer 幂等性对外保留的接口非常简单,其底层的实现对上层应用做了很好的封装,应用层并不需要去关心具体的实现细节,对用户非常友好。
幂等性要解决的问题
在看 Producer 是如何实现幂等性之前,首先先考虑一个问题:幂等性是来解决什么问题的? 在 0.11.0 之前,Kafka 通过 Producer 端和 Server 端的相关配置可以做到数据不丢,也就是 at least once,但是在一些情况下,可能会导致数据重复,比如:网络请求延迟等导致的重试操作,在发送请求重试时 Server 端并不知道这条请求是否已经处理(没有记录之前的状态信息),所以就会有可能导致数据请求的重复发送,这是 Kafka 自身的机制(异常时请求重试机制)导致的数据重复。
对于大多数应用而言,数据保证不丢是可以满足其需求的,但是对于一些其他的应用场景(比如支付数据等),它们是要求精确计数的,这时候如果上游数据有重复,下游应用只能在消费数据时进行相应的去重操作,应用在去重时,最常用的手段就是根据唯一 id 键做 check 去重。
在这种场景下,因为上游生产导致的数据重复问题,会导致所有有精确计数需求的下游应用都需要做这种复杂的、重复的去重处理。试想一下:如果在发送时,系统就能保证 exactly once,这对下游将是多么大的解脱。这就是幂等性要解决的问题,主要是解决数据重复的问题,正如前面所述,数据重复问题,通用的解决方案就是加唯一 id,然后根据 id 判断数据是否重复,Producer 的幂等性也是这样实现的,这一小节就让我们看下 Kafka 的 Producer 如何保证数据的 exactly once 的。
幂等性的实现原理
在讲述幂等性处理流程之前,先看下 Producer 是如何来保证幂等性的,正如前面所述,幂等性要解决的问题是:Producer 设置 at least once 时,由于异常触发重试机制导致数据重复,幂等性的目的就是为了解决这个数据重复的问题,简单来说就是:
at least once + 幂等 = exactly once
通过在 al least once 的基础上加上 幂等性来做到 exactly once,当然这个层面的 exactly once 是有限制的,比如它会要求单会话内有效或者跨会话使用事务性有效等。这里我们先分析最简单的情况,那就是在单会话内如何做到幂等性,进而保证 exactly once。
要做到幂等性,要解决下面的问题:
- 系统需要有能力鉴别一条数据到底是不是重复的数据?常用的手段是通过 唯一键/唯一 id 来判断,这时候系统一般是需要缓存已经处理的唯一键记录,这样才能更有效率地判断一条数据是不是重复;
- 唯一键应该选择什么粒度?对于分布式存储系统来说,肯定不能用全局唯一键(全局是针对集群级别),核心的解决思路依然是 分而治之,数据密集型系统为了实现分布式都是有分区概念的,而分区之间是有相应的隔离,对于 Kafka 而言,这里的解决方案就是在分区的维度上去做,重复数据的判断让 partition 的 leader 去判断处理,前提是 Produce 请求需要把唯一键值告诉 leader;
- 分区粒度实现唯一键会不会有其他问题?这里需要考虑的问题是当一个 Partition 有来自多个 client 写入的情况,这些 client 之间是很难做到使用同一个唯一键(一个是它们之间很难做到唯一键的实时感知,另一个是这样实现是否有必要)。而如果系统在实现时做到了 client + partition 粒度,这样实现的好处是每个 client 都是完全独立的(它们之间不需要有任何的联系,这是非常大的优点),只是在 Server 端对不同的 client 做好相应的区分即可,当然同一个 client 在处理多个 Topic-Partition 时是完全可以使用同一个 PID 的。
有了上面的分析(都是个人见解,如果有误,欢迎指教),就不难理解 Producer 幂等性的实现原理,Kafka Producer 在实现时有以下两个重要机制:
- PID(Producer ID),用来标识每个 producer client;
- sequence numbers,client 发送的每条消息都会带相应的 sequence number,Server 端就是根据这个值来判断数据是否重复。
下面详细讲述这两个实现机制。
PID
每个 Producer 在初始化时都会被分配一个唯一的 PID,这个 PID 对应用是透明的,完全没有暴露给用户。对于一个给定的 PID,sequence number 将会从0开始自增,每个 Topic-Partition 都会有一个独立的 sequence number。Producer 在发送数据时,将会给每条 msg 标识一个 sequence number,Server 也就是通过这个来验证数据是否重复。这里的 PID 是全局唯一的,Producer 故障后重新启动后会被分配一个新的 PID,这也是幂等性无法做到跨会话的一个原因。
Producer PID 申请
这里看下 PID 在 Server 端是如何分配的?Client 通过向 Server 发送一个 InitProducerIdRequest 请求获取 PID(幂等性时,是选择一台连接数最少的 Broker 发送这个请求),这里看下 Server 端是如何处理这个请求的?KafkaApis 中 handleInitProducerIdRequest() 方法的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
def handleInitProducerIdRequest(request: RequestChannel.Request): Unit = { val initProducerIdRequest = request.body[InitProducerIdRequest] val transactionalId = initProducerIdRequest.transactionalId if (transactionalId != null) { //note: 设置 txn.id 时,验证对 txn.id 的权限 if (!authorize(request.session, Write, Resource(TransactionalId, transactionalId, LITERAL))) { sendErrorResponseMaybeThrottle(request, Errors.TRANSACTIONAL_ID_AUTHORIZATION_FAILED.exception) return } } else if (!authorize(request.session, IdempotentWrite, Resource.ClusterResource)) { //note: 没有设置 txn.id 时,验证对集群是否有幂等性权限 sendErrorResponseMaybeThrottle(request, Errors.CLUSTER_AUTHORIZATION_FAILED.exception) return } def sendResponseCallback(result: InitProducerIdResult): Unit = { def createResponse(requestThrottleMs: Int): AbstractResponse = { val responseBody = new InitProducerIdResponse(requestThrottleMs, result.error, result.producerId, result.producerEpoch) trace(s"Completed $transactionalId's InitProducerIdRequest with result $result from client ${request.header.clientId}.") responseBody } sendResponseMaybeThrottle(request, createResponse) } //note: 生成相应的了 pid,返回给 producer txnCoordinator.handleInitProducerId(transactionalId, initProducerIdRequest.transactionTimeoutMs, sendResponseCallback) } |
这里实际上是调用了 TransactionCoordinator (Broker 在启动 server 服务时都会初始化这个实例)的 handleInitProducerId() 方法做了相应的处理,其实现如下(这里只关注幂等性的处理):
1 2 3 4 5 6 7 8 9 10 11 12 |
def handleInitProducerId(transactionalId: String, transactionTimeoutMs: Int, responseCallback: InitProducerIdCallback): Unit = { if (transactionalId == null) { //note: 只设置幂等性时,直接分配 pid 并返回 // if the transactional id is null, then always blindly accept the request // and return a new producerId from the producerId manager val producerId = producerIdManager.generateProducerId() responseCallback(InitProducerIdResult(producerId, producerEpoch = 0, Errors.NONE)) } ... } |
Server 在给一个 client 初始化 PID 时,实际上是通过 ProducerIdManager 的 generateProducerId() 方法产生一个 PID。
Server PID 管理
如前面所述,在幂等性的情况下,直接通过 ProducerIdManager 的 generateProducerId() 方法产生一个 PID,其中 ProducerIdManager 是在 TransactionCoordinator 对象初始化时初始化的,这个对象主要是用来管理 PID 信息:
- 在本地的 PID 端用完了或者处于新建状态时,申请 PID 段(默认情况下,每次申请 1000 个 PID);
- TransactionCoordinator 对象通过
generateProducerId()方法获取下一个可以使用的 PID;
PID 端申请是向 ZooKeeper 申请,zk 中有一个 /latest_producer_id_block 节点,每个 Broker 向 zk 申请一个 PID 段后,都会把自己申请的 PID 段信息写入到这个节点,这样当其他 Broker 再申请 PID 段时,会首先读写这个节点的信息,然后根据 block_end 选择一个 PID 段,最后再把信息写会到 zk 的这个节点,这个节点信息格式如下所示:
1
|
{"version":1,"broker":35,"block_start":"4000","block_end":"4999"}
|
ProducerIdManager 向 zk 申请 PID 段的方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
private def getNewProducerIdBlock(): Unit = { var zkWriteComplete = false while (!zkWriteComplete) { //note: 直到从 zk 拿取到分配的 PID 段 // refresh current producerId block from zookeeper again val (dataOpt, zkVersion) = zkClient.getDataAndVersion(ProducerIdBlockZNode.path) // generate the new producerId block currentProducerIdBlock = dataOpt match { case Some(data) => //note: 从 zk 获取当前最新的 pid 信息,如果后面更新失败,这里也会重新从 zk 获取 val currProducerIdBlock = ProducerIdManager.parseProducerIdBlockData(data) debug(s"Read current producerId block $currProducerIdBlock, Zk path version $zkVersion") if (currProducerIdBlock.blockEndId > Long.MaxValue - ProducerIdManager.PidBlockSize) {//note: 不足以分配1000个 PID // we have exhausted all producerIds (wow!), treat it as a fatal error //note: 当 PID 分配超过限制时,直接报错了(每秒分配1个,够用2百亿年了) fatal(s"Exhausted all producerIds as the next block's end producerId is will has exceeded long type limit (current block end producerId is ${currProducerIdBlock.blockEndId})") throw new KafkaException("Have exhausted all producerIds.") } ProducerIdBlock(brokerId, currProducerIdBlock.blockEndId + 1L, currProducerIdBlock.blockEndId + ProducerIdManager.PidBlockSize) case None => //note: 该节点还不存在,第一次初始化 debug(s"There is no producerId block yet (Zk path version $zkVersion), creating the first block") ProducerIdBlock(brokerId, 0L, ProducerIdManager.PidBlockSize - 1) } val newProducerIdBlockData = ProducerIdManager.generateProducerIdBlockJson(currentProducerIdBlock) // try to write the new producerId block into zookeeper //note: 将新的 pid 信息写入到 zk,如果写入失败(写入之前会比对 zkVersion,如果这个有变动,证明这期间有别的 Broker 在操作,那么写入失败),重新申请 val (succeeded, version) = zkClient.conditionalUpdatePath(ProducerIdBlockZNode.path, newProducerIdBlockData, zkVersion, Some(checkProducerIdBlockZkData)) zkWriteComplete = succeeded if (zkWriteComplete) info(s"Acquired new producerId block $currentProducerIdBlock by writing to Zk with path version $version") } } |
ProducerIdManager 申请 PID 段的流程如下:
- 先从 zk 的
/latest_producer_id_block节点读取最新已经分配的 PID 段信息; - 如果该节点不存在,直接从 0 开始分配,选择 0~1000 的 PID 段(ProducerIdManager 的 PidBlockSize 默认为 1000,即是每次申请的 PID 段大小);
- 如果该节点存在,读取其中数据,根据 block_end 选择 <block_end+1, block_end+1000="">这个 PID 段(如果 PID 段超过 Long 类型的最大值,这里会直接返回一个异常);
- 在选择了相应的 PID 段后,将这个 PID 段信息写回到 zk 的这个节点中,如果写入成功,那么 PID 段就证明申请成功,如果写入失败(写入时会判断当前节点的 zkVersion 是否与步骤1获取的 zkVersion 相同,如果相同,那么可以成功写入,否则写入就会失败,证明这个节点被修改过),证明此时可能其他的 Broker 已经更新了这个节点(当前的 PID 段可能已经被其他 Broker 申请),那么从步骤 1 重新开始,直到写入成功。
明白了 ProducerIdManager 如何申请 PID 段之后,再看 generateProducerId() 这个方法就简单很多了,这个方法在每次调用时,都会更新 nextProducerId 值(下一次可以使用 PID 值),如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
def generateProducerId(): Long = { this synchronized { // grab a new block of producerIds if this block has been exhausted if (nextProducerId > currentProducerIdBlock.blockEndId) { //note: 如果分配的 pid 用完了,重新再向 zk 申请一批 getNewProducerIdBlock() nextProducerId = currentProducerIdBlock.blockStartId + 1 } else { nextProducerId += 1 } nextProducerId - 1 //note: 返回当前分配的 pid } } |
这里就是 Producer PID 如何申请(事务性情况下 PID 的申请会复杂一些,下篇文章再讲述)以及 Server 端如何管理 PID 的。
sequence numbers
再有了 PID 之后,在 PID + Topic-Partition 级别上添加一个 sequence numbers 信息,就可以实现 Producer 的幂等性了。ProducerBatch 也提供了一个 setProducerState() 方法,它可以给一个 batch 添加一些 meta 信息(pid、baseSequence、isTransactional),这些信息是会伴随着 ProduceRequest 发到 Server 端,Server 端也正是通过这些 meta 来做相应的判断,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
// ProducerBatch public void setProducerState(ProducerIdAndEpoch producerIdAndEpoch, int baseSequence, boolean isTransactional) { recordsBuilder.setProducerState(producerIdAndEpoch.producerId, producerIdAndEpoch.epoch, baseSequence, isTransactional); } // MemoryRecordsBuilder public void setProducerState(long producerId, short producerEpoch, int baseSequence, boolean isTransactional) { if (isClosed()) { // Sequence numbers are assigned when the batch is closed while the accumulator is being drained. // If the resulting ProduceRequest to the partition leader failed for a retriable error, the batch will // be re queued. In this case, we should not attempt to set the state again, since changing the producerId and sequence // once a batch has been sent to the broker risks introducing duplicates. throw new IllegalStateException("Trying to set producer state of an already closed batch. This indicates a bug on the client."); } this.producerId = producerId; this.producerEpoch = producerEpoch; this.baseSequence = baseSequence; this.isTransactional = isTransactional; } |
幂等性实现整体流程
在前面讲述完 Kafka 幂等性的两个实现机制(PID+sequence numbers)之后,这里详细讲述一下,幂等性时其整体的处理流程,主要讲述幂等性相关的内容,其他的部分会简单介绍(可以参考前面【Kafka 源码分析系列文章】了解 Producer 端处理流程以及 Server 端关于 ProduceRequest 请求的处理流程),其流程如下图所示:
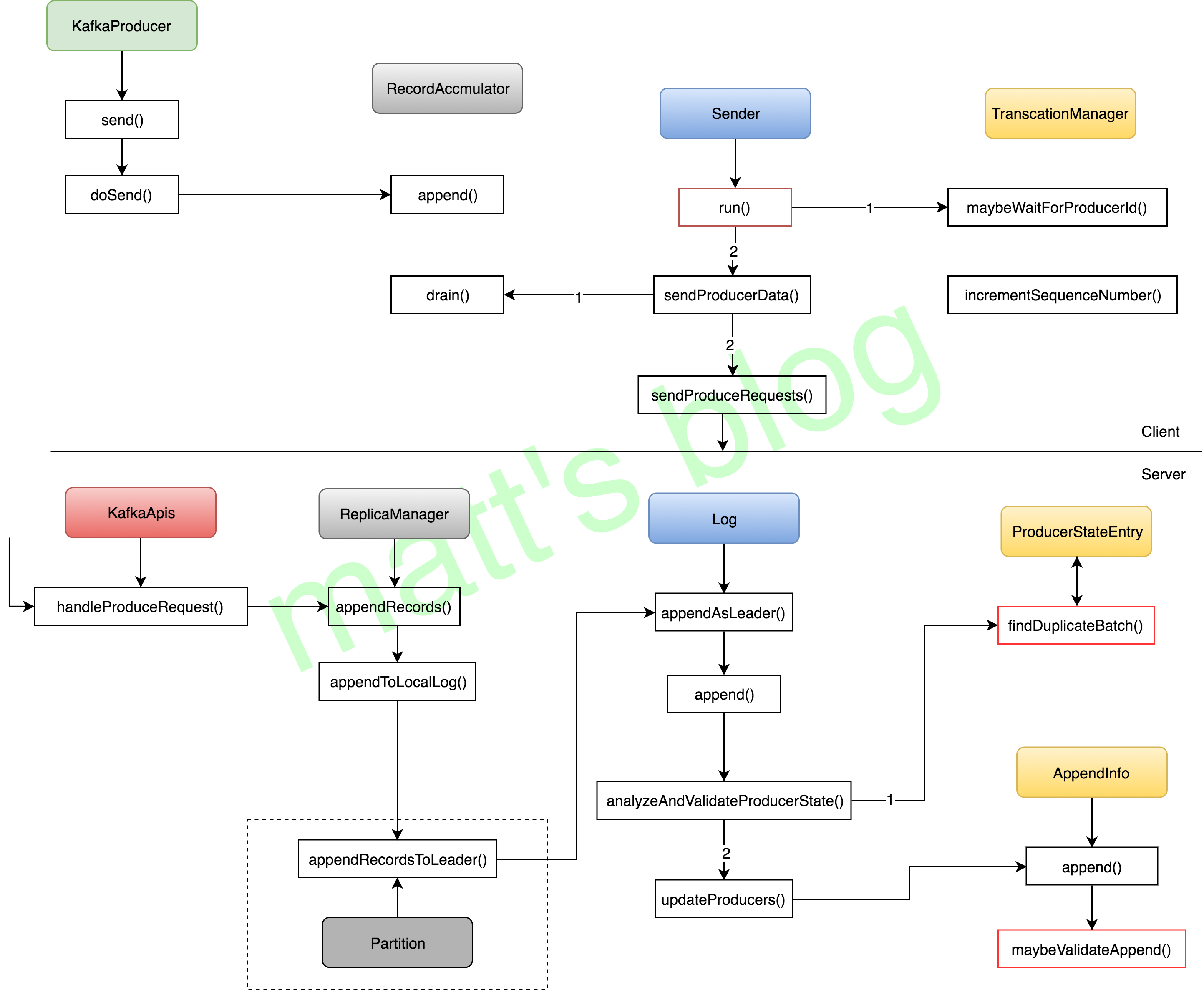 Producer 幂等性时处理流程
Producer 幂等性时处理流程
这个图只展示了幂等性情况下,Producer 的大概流程,很多部分在前面的文章中做过分析,本文不再讲述,这里重点关注与幂等性相关的内容(事务性实现更加复杂,后面的文章再讲述),首先 KafkaProducer 在初始化时会初始化一个 TransactionManager 实例,它的作用有以下几个部分:
- 记录本地的事务状态(事务性时必须);
- 记录一些状态信息以保证幂等性,比如:每个 topic-partition 对应的下一个 sequence numbers 和 last acked batch(最近一个已经确认的 batch)的最大的 sequence number 等;
- 记录 ProducerIdAndEpoch 信息(PID 信息)。
Client 幂等性时发送流程
如前面图中所示,幂等性时,Producer 的发送流程如下:
- 应用通过 KafkaProducer 的
send()方法将数据添加到 RecordAccumulator 中,添加时会判断是否需要新建一个 ProducerBatch,这时这个 ProducerBatch 还是没有 PID 和 sequence number 信息的; - Producer 后台发送线程 Sender,在
run()方法中,会先根据 TransactionManager 的shouldResetProducerStateAfterResolvingSequences()方法判断当前的 PID 是否需要重置,重置的原因是因为:如果有 topic-partition 的 batch 重试多次失败最后因为超时而被移除,这时 sequence number 将无法做到连续,因为 sequence number 有部分已经分配出去,这时系统依赖自身的机制无法继续进行下去(因为幂等性是要保证不丢不重的),相当于程序遇到了一个 fatal 异常,PID 会进行重置,TransactionManager 相关的缓存信息被清空(Producer 不会重启),只是保存状态信息的 TransactionManager 做了clear+new操作,遇到这个问题时是无法保证 exactly once 的(有数据已经发送失败了,并且超过了重试次数); - Sender 线程通过
maybeWaitForProducerId()方法判断是否需要申请 PID,如果需要的话,这里会阻塞直到获取到相应的 PID 信息; - Sender 线程通过
sendProducerData()方法发送数据,整体流程与之前的 Producer 流程相似,不同的地方是在 RecordAccumulator 的drain()方法中,在加了幂等性之后,drain()方法多了如下几步判断:- 常规的判断:判断这个 topic-partition 是否可以继续发送(如果出现前面2中的情况是不允许发送的)、判断 PID 是否有效、如果这个 batch 是重试的 batch,那么需要判断这个 batch 之前是否还有 batch 没有发送完成,如果有,这里会先跳过这个 Topic-Partition 的发送,直到前面的 batch 发送完成,最坏情况下,这个 Topic-Partition 的 in-flight request 将会减少到1(这个涉及也是考虑到 server 端的一个设置,文章下面会详细分析);
- 如果这个 ProducerBatch 还没有这个相应的 PID 和 sequence number 信息,会在这里进行相应的设置;
- 最后 Sender 线程再调用
sendProduceRequests()方法发送 ProduceRequest 请求,后面的就跟之前正常的流程保持一致了。
这里看下几个关键方法的实现,首先是 Sender 线程获取 PID 信息的方法 maybeWaitForProducerId() ,其实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
//note: 等待直到 Producer 获取到相应的 PID 和 epoch 信息 private void maybeWaitForProducerId() { while (!transactionManager.hasProducerId() && !transactionManager.hasError()) { try { Node node = awaitLeastLoadedNodeReady(requestTimeoutMs); //note: 选取 node(本地连接数最少的 node) if (node != null) { ClientResponse response = sendAndAwaitInitProducerIdRequest(node); //note: 发送 InitPidRequest InitProducerIdResponse initProducerIdResponse = (InitProducerIdResponse) response.responseBody(); Errors error = initProducerIdResponse.error(); if (error == Errors.NONE) { //note: 更新 Producer 的 PID 和 epoch 信息 ProducerIdAndEpoch producerIdAndEpoch = new ProducerIdAndEpoch( initProducerIdResponse.producerId(), initProducerIdResponse.epoch()); transactionManager.setProducerIdAndEpoch(producerIdAndEpoch); return; } else if (error.exception() instanceof RetriableException) { log.debug("Retriable error from InitProducerId response", error.message()); } else { transactionManager.transitionToFatalError(error.exception()); break; } } else { log.debug("Could not find an available broker to send InitProducerIdRequest to. " + "We will back off and try again."); } } catch (UnsupportedVersionException e) { transactionManager.transitionToFatalError(e); break; } catch (IOException e) { log.debug("Broker {} disconnected while awaiting InitProducerId response", e); } log.trace("Retry InitProducerIdRequest in {}ms.", retryBackoffMs); time.sleep(retryBackoffMs); metadata.requestUpdate(); } } |
再看下 RecordAccumulator 的 drain() 方法,重点需要关注的是关于幂等性和事务性相关的处理,具体如下所示,这里面关于事务性相关的判断在上面的流程中已经讲述。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 |
/** * Drain all the data for the given nodes and collate them into a list of batches that will fit within the specified * size on a per-node basis. This method attempts to avoid choosing the same topic-node over and over. * * @param cluster The current cluster metadata * @param nodes The list of node to drain * @param maxSize The maximum number of bytes to drain * @param now The current unix time in milliseconds * @return A list of {@link ProducerBatch} for each node specified with total size less than the requested maxSize. */ public Map<Integer, List<ProducerBatch>> drain(Cluster cluster, Set<Node> nodes, int maxSize, long now) { if (nodes.isEmpty()) return Collections.emptyMap(); Map<Integer, List<ProducerBatch>> batches = new HashMap<>(); for (Node node : nodes) { int size = 0; List<PartitionInfo> parts = cluster.partitionsForNode(node.id()); List<ProducerBatch> ready = new ArrayList<>(); /* to make starvation less likely this loop doesn't start at 0 */ int start = drainIndex = drainIndex % parts.size(); do { PartitionInfo part = parts.get(drainIndex); TopicPartition tp = new TopicPartition(part.topic(), part.partition()); // Only proceed if the partition has no in-flight batches. if (!isMuted(tp, now)) { Deque<ProducerBatch> deque = getDeque(tp); if (deque != null) { synchronized (deque) { //note: 先判断有没有数据,然后后面真正处理时再加锁处理 ProducerBatch first = deque.peekFirst(); if (first != null) { boolean backoff = first.attempts() > 0 && first.waitedTimeMs(now) < retryBackoffMs; // Only drain the batch if it is not during backoff period. if (!backoff) { if (size + first.estimatedSizeInBytes() > maxSize && !ready.isEmpty()) { // there is a rare case that a single batch size is larger than the request size due // to compression; in this case we will still eventually send this batch in a single // request break; } else { ProducerIdAndEpoch producerIdAndEpoch = null; boolean isTransactional = false; if (transactionManager != null) { //note: 幂等性或事务性时, 做一些检查判断 if (!transactionManager.isSendToPartitionAllowed(tp)) break; producerIdAndEpoch = transactionManager.producerIdAndEpoch(); if (!producerIdAndEpoch.isValid()) //note: pid 是否有效 // we cannot send the batch until we have refreshed the producer id break; isTransactional = transactionManager.isTransactional(); if (!first.hasSequence() && transactionManager.hasUnresolvedSequence(first.topicPartition)) //note: 当前这个 topic-partition 的数据出现过超时,不能发送,如果是新的 batch 数据直接跳过(没有 seq number 信息) // Don't drain any new batches while the state of previous sequence numbers // is unknown. The previous batches would be unknown if they were aborted // on the client after being sent to the broker at least once. break; int firstInFlightSequence = transactionManager.firstInFlightSequence(first.topicPartition); if (firstInFlightSequence != RecordBatch.NO_SEQUENCE && first.hasSequence() && first.baseSequence() != firstInFlightSequence) //note: 重试操作(seq number 不为0),如果这个 batch 的 baseSequence 与 in-flight //note: queue 中第一个 request batch 的 baseSequence不同的话(证明它前面还有请求未成功), //note: 会等待下次循环再判断, 最坏的情况下会导致 in-flight request 为1(只影响这个 partition) //note: 这种情况下,继续发送这个是没有意义的,因为幂等性时保证顺序的,只有前面的都成功,后面的再发送才有意义 //note: 这里是 break,相当于在这次发送中直接跳过了这个 topic-partition 的发送 // If the queued batch already has an assigned sequence, then it is being // retried. In this case, we wait until the next immediate batch is ready // and drain that. We only move on when the next in line batch is complete (either successfully // or due to a fatal broker error). This effectively reduces our // in flight request count to 1. break; } ProducerBatch batch = deque.pollFirst(); if (producerIdAndEpoch != null && !batch.hasSequence()) {//note: batch 的相关信息(seq id)是在这里设置的 //note: 这个 batch 还没有 seq number 信息 // If the batch already has an assigned sequence, then we should not change the producer id and // sequence number, since this may introduce duplicates. In particular, // the previous attempt may actually have been accepted, and if we change // the producer id and sequence here, this attempt will also be accepted, // causing a duplicate. // // Additionally, we update the next sequence number bound for the partition, // and also have the transaction manager track the batch so as to ensure // that sequence ordering is maintained even if we receive out of order // responses. //note: 给这个 batch 设置相应的 pid、seq id 等信息 batch.setProducerState(producerIdAndEpoch, transactionManager.sequenceNumber(batch.topicPartition), isTransactional); transactionManager.incrementSequenceNumber(batch.topicPartition, batch.recordCount); //note: 增加 partition 对应的下一个 seq id 值 log.debug("Assigned producerId {} and producerEpoch {} to batch with base sequence " + "{} being sent to partition {}", producerIdAndEpoch.producerId, producerIdAndEpoch.epoch, batch.baseSequence(), tp); transactionManager.addInFlightBatch(batch); } batch.close(); size += batch.records().sizeInBytes(); ready.add(batch); batch.drained(now); } } } } } } this.drainIndex = (this.drainIndex + 1) % parts.size(); } while (start != drainIndex); batches.put(node.id(), ready); } return batches; } |
幂等性时 Server 端如何处理 ProduceRequest 请求
如前面途中所示,当 Broker 收到 ProduceRequest 请求之后,会通过 handleProduceRequest() 做相应的处理,其处理流程如下(这里只讲述关于幂等性相关的内容):
- 如果请求是事务请求,检查是否对 TXN.id 有 Write 权限,没有的话返回 TRANSACTIONAL_ID_AUTHORIZATION_FAILED;
- 如果请求设置了幂等性,检查是否对 ClusterResource 有 IdempotentWrite 权限,没有的话返回 CLUSTER_AUTHORIZATION_FAILED;
- 验证对 topic 是否有 Write 权限以及 Topic 是否存在,否则返回 TOPIC_AUTHORIZATION_FAILED 或 UNKNOWN_TOPIC_OR_PARTITION 异常;
- 检查是否有 PID 信息,没有的话走正常的写入流程;
- LOG 对象会在
analyzeAndValidateProducerState()方法先根据 batch 的 sequence number 信息检查这个 batch 是否重复(server 端会缓存 PID 对应这个 Topic-Partition 的最近5个 batch 信息),如果有重复,这里当做写入成功返回(不更新 LOG 对象中相应的状态信息,比如这个 replica 的 the end offset 等); - 有了 PID 信息,并且不是重复 batch 时,在更新 producer 信息时,会做以下校验:
- 检查该 PID 是否已经缓存中存在(主要是在 ProducerStateManager 对象中检查);
- 如果不存在,那么判断 sequence number 是否 从0 开始,是的话,在缓存中记录 PID 的 meta(PID,epoch, sequence number),并执行写入操作,否则返回 UnknownProducerIdException(PID 在 server 端已经过期或者这个 PID 写的数据都已经过期了,但是 Client 还在接着上次的 sequence number 发送数据);
- 如果该 PID 存在,先检查 PID epoch 与 server 端记录的是否相同;
- 如果不同并且 sequence number 不从 0 开始,那么返回 OutOfOrderSequenceException 异常;
- 如果不同并且 sequence number 从 0 开始,那么正常写入;
- 如果相同,那么根据缓存中记录的最近一次 sequence number(currentLastSeq)检查是否为连续(会区分为 0、Int.MaxValue 等情况),不连续的情况下返回 OutOfOrderSequenceException 异常。
- 下面与正常写入相同。
幂等性时,Broker 在处理 ProduceRequest 请求时,多了一些校验操作,这里重点看一下其中一些重要实现,先看下 analyzeAndValidateProducerState() 方法的实现,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
private def analyzeAndValidateProducerState(records: MemoryRecords, isFromClient: Boolean): (mutable.Map[Long, ProducerAppendInfo], List[CompletedTxn], Option[BatchMetadata]) = { val updatedProducers = mutable.Map.empty[Long, ProducerAppendInfo] val completedTxns = ListBuffer.empty[CompletedTxn] for (batch <- records.batches.asScala if batch.hasProducerId) { //note: 有 pid 时,才会做相应的判断 val maybeLastEntry = producerStateManager.lastEntry(batch.producerId) // if this is a client produce request, there will be up to 5 batches which could have been duplicated. // If we find a duplicate, we return the metadata of the appended batch to the client. if (isFromClient) { maybeLastEntry.flatMap(_.findDuplicateBatch(batch)).foreach { duplicate => return (updatedProducers, completedTxns.toList, Some(duplicate)) //note: 如果这个 batch 已经收到过,这里直接返回 } } val maybeCompletedTxn = updateProducers(batch, updatedProducers, isFromClient = isFromClient) //note: 这里 maybeCompletedTxn.foreach(completedTxns += _) } (updatedProducers, completedTxns.toList, None) } |
如果这个 batch 有 PID 信息,会首先检查这个 batch 是否为重复的 batch 数据,其实现如下,batchMetadata 会缓存最新 5个 batch 的数据(如果超过5个,添加时会进行删除,这个也是幂等性要求 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION 小于等于5 的原因,与这个值的设置有关),根据 batchMetadata 缓存的 batch 数据来判断这个 batch 是否为重复的数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
def findDuplicateBatch(batch: RecordBatch): Option[BatchMetadata] = { if (batch.producerEpoch != producerEpoch) None else batchWithSequenceRange(batch.baseSequence, batch.lastSequence) } // Return the batch metadata of the cached batch having the exact sequence range, if any. def batchWithSequenceRange(firstSeq: Int, lastSeq: Int): Option[BatchMetadata] = { val duplicate = batchMetadata.filter { metadata => firstSeq == metadata.firstSeq && lastSeq == metadata.lastSeq } duplicate.headOption } private def addBatchMetadata(batch: BatchMetadata): Unit = { if (batchMetadata.size == ProducerStateEntry.NumBatchesToRetain) batchMetadata.dequeue() //note: 只会保留最近 5 个 batch 的记录 batchMetadata.enqueue(batch) //note: 添加到 batchMetadata 中记录,便于后续根据 seq id 判断是否重复 } |
如果 batch 不是重复的数据,analyzeAndValidateProducerState() 会通过 updateProducers() 更新 producer 的相应记录,在更新的过程中,会做一步校验,校验方法如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
//note: 检查 seq number private def checkSequence(producerEpoch: Short, appendFirstSeq: Int): Unit = { if (producerEpoch != updatedEntry.producerEpoch) { //note: epoch 不同时 if (appendFirstSeq != 0) { //note: 此时要求 seq number 必须从0开始(如果不是的话,pid 可能是新建的或者 PID 在 Server 端已经过期) //note: pid 已经过期(updatedEntry.producerEpoch 不是-1,证明时原来的 pid 过期了) if (updatedEntry.producerEpoch != RecordBatch.NO_PRODUCER_EPOCH) { throw new OutOfOrderSequenceException(s"Invalid sequence number for new epoch: $producerEpoch " + s"(request epoch), $appendFirstSeq (seq. number)") } else { //note: pid 已经过期(updatedEntry.producerEpoch 为-1,证明 server 端 meta 新建的,PID 在 server 端已经过期,client 还在接着上次的 seq 发数据) throw new UnknownProducerIdException(s"Found no record of producerId=$producerId on the broker. It is possible " + s"that the last message with t()he producerId=$producerId has been removed due to hitting the retention limit.") } } } else { val currentLastSeq = if (!updatedEntry.isEmpty) updatedEntry.lastSeq else if (producerEpoch == currentEntry.producerEpoch) currentEntry.lastSeq else RecordBatch.NO_SEQUENCE if (currentLastSeq == RecordBatch.NO_SEQUENCE && appendFirstSeq != 0) { //note: 此时期望的 seq number 是从 0 开始,因为 currentLastSeq 是 -1,也就意味着这个 pid 还没有写入过数据 // the epoch was bumped by a control record, so we expect the sequence number to be reset throw new OutOfOrderSequenceException(s"Out of order sequence number for producerId $producerId: found $appendFirstSeq " + s"(incoming seq. number), but expected 0") } else if (!inSequence(currentLastSeq, appendFirstSeq)) { //note: 判断是否连续 throw new OutOfOrderSequenceException(s"Out of order sequence number for producerId $producerId: $appendFirstSeq " + s"(incoming seq. number), $currentLastSeq (current end sequence number)") } } } |
其校验逻辑如前面流程中所述。
小思考
这里主要思考两个问题:
- Producer 在设置幂等性时,为什么要求 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION 小于等于 5,如果设置大于 5(不考虑 Producer 端参数校验的报错),会带来什么后果?
- Producer 在设置幂等性时,如果我们设置 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION 大于 1,那么是否可以保证有序,如果可以,是怎么做到的?
先说一下结论,问题 1 的这个设置要求其实上面分析的时候已经讲述过了,主要跟 server 端只会缓存最近 5 个 batch 的机制有关;问题 2,即使 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION 大于 1,幂等性时依然可以做到有序,下面来详细分析一下这两个问题。
为什么要求 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION 小于等于5
其实这里,要求 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION 小于等于 5 的主要原因是:Server 端的 ProducerStateManager 实例会缓存每个 PID 在每个 Topic-Partition 上发送的最近 5 个batch 数据(这个 5 是写死的,至于为什么是 5,可能跟经验有关,当不设置幂等性时,当这个设置为 5 时,性能相对来说较高,社区是有一个相关测试文档,忘记在哪了),如果超过 5,ProducerStateManager 就会将最旧的 batch 数据清除。
假设应用将 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION 设置为 6,假设发送的请求顺序是 1、2、3、4、5、6,这时候 server 端只能缓存 2、3、4、5、6 请求对应的 batch 数据,这时候假设请求 1 发送失败,需要重试,当重试的请求发送过来后,首先先检查是否为重复的 batch,这时候检查的结果是否,之后会开始 check 其 sequence number 值,这时候只会返回一个 OutOfOrderSequenceException 异常,client 在收到这个异常后,会再次进行重试,直到超过最大重试次数或者超时,这样不但会影响 Producer 性能,还可能给 Server 带来压力(相当于client 狂发错误请求)。
那有没有更好的方案呢?我认为是有的,那就是对于 OutOfOrderSequenceException 异常,再进行细分,区分这个 sequence number 是大于 nextSeq (期望的下次 sequence number 值)还是小于 nextSeq,如果是小于,那么肯定是重复的数据。
当 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION 配置大于1时,是否保证有序
先来分析一下,在什么情况下 Producer 会出现乱序的问题?没有幂等性时,乱序的问题是在重试时出现的,举个例子:client 依然发送了 6 个请求 1、2、3、4、5、6(它们分别对应了一个 batch),这 6 个请求只有 2-6 成功 ack 了,1 失败了,这时候需要重试,重试时就会把 batch 1 的数据添加到待发送的数据列队中),那么下次再发送时,batch 1 的数据将会被发送,这时候数据就已经出现了乱序,因为 batch 1 的数据已经晚于了 batch 2-6。
当 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION 设置为 1 时,是可以解决这个为题,因为同时只允许一个请求正在发送,只有当前的请求发送完成(成功 ack 后),才能继续下一条请求的发送,类似单线程处理这种模式,每次请求发送时都会等待上次的完成,效率非常差,但是可以解决乱序的问题(当然这里有序只是针对单 client 情况,多 client 并发写是无法做到的)。
系统能提供的方案,基本上就是有序性与性能之间二选一,无法做到兼容,实际上系统出现请求重试的几率是很小的(一般都是网络问题触发的),可能连 0.1% 的时间都不到,但是就是为了这 0.1% 时间都不到的情况,应用需要牺牲性能问题来解决,在大数据场景下,我们是希望有更友好的方式来解决这个问题。简单来说,就是当出现重试时,max-in-flight-request 可以动态减少到 1,在正常情况下还是按 5 (5是举例说明)来处理,这有点类似于分布式系统 CAP 理论中关于 P 的考虑,当出现问题时,可以容忍性能变差,但是其他的情况下,我们希望的是能拥有原来的性能,而不是一刀切。令人高兴的,在 Kafka 2.0.0 版本中,如果 Producer 开始了幂等性,Kafka 是可以做到这一点的,如果不开启幂等性,是无法做到的,因为它的实现是依赖了 sequence number。
当请求出现重试时,batch 会重新添加到队列中,这时候是根据 sequence number 添加到队列的合适位置(有些 batch 如果还没有 sequence number,那么就保持其相对位置不变),也就是队列中排在这个 batch 前面的 batch,其 sequence number 都比这个 batch 的 sequence number 小,其实现如下,这个方法保证了在重试时,其 batch 会被放到合适的位置:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
/** * Re-enqueue the given record batch in the accumulator to retry */ public void reenqueue(ProducerBatch batch, long now) { batch.reenqueued(now); //note: 重试,更新相应的 meta Deque<ProducerBatch> deque = getOrCreateDeque(batch.topicPartition); synchronized (deque) { if (transactionManager != null) insertInSequenceOrder(deque, batch); //note: 将 batch 添加到队列的合适位置(根据 seq num 信息) else deque.addFirst(batch); } } |
另外 Sender 在发送请求时,会首先通过 RecordAccumulator 的 drain() 方法获取其发送的数据,在遍历 Topic-Partition 对应的 queue 中的 batch 时,如果发现 batch 已经有了 sequence number 的话,则证明这个 batch 是重试的 batch,因为没有重试的 batch 其 sequence number 还没有设置,这时候会做一个判断,会等待其 in-flight-requests 中请求发送完成,才允许再次发送这个 Topic-Partition 的数据,其判断实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
//note: 获取 inFlightBatches 中第一个 batch 的 baseSequence, inFlightBatches 为 null 的话返回 RecordBatch.NO_SEQUENCE int firstInFlightSequence = transactionManager.firstInFlightSequence(first.topicPartition); if (firstInFlightSequence != RecordBatch.NO_SEQUENCE && first.hasSequence() && first.baseSequence() != firstInFlightSequence) //note: 重试操作(seq number 不为0),如果这个 batch 的 baseSequence 与 in-flight //note: queue 中第一个 request batch 的 baseSequence不同的话(证明它前面还有请求未成功), //note: 会等待下次循环再判断, 最坏的情况下会导致 in-flight request 为1(只影响这个 partition) //note: 这种情况下,继续发送这个是没有意义的,因为幂等性时保证顺序的,只有前面的都成功,后面的再发送才有意义 //note: 这里是 break,相当于在这次发送中直接跳过了这个 topic-partition 的发送 // If the queued batch already has an assigned sequence, then it is being // retried. In this case, we wait until the next immediate batch is ready // and drain that. We only move on when the next in line batch is complete (either successfully // or due to a fatal broker error). This effectively reduces our // in flight request count to 1. break; } |
仅有 client 端这两个机制还不够,Server 端在处理 ProduceRequest 请求时,还会检查 batch 的 sequence number 值,它会要求这个值必须是连续的,如果不连续都会返回异常,Client 会进行相应的重试,举个栗子:假设 Client 发送的请求顺序是 1、2、3、4、5(分别对应了一个 batch),如果中间的请求 2 出现了异常,那么会导致 3、4、5 都返回异常进行重试(因为 sequence number 不连续),也就是说此时 2、3、4、5 都会进行重试操作添加到对应的 queue 中。
Producer 的 TransactionManager 实例的 inflightBatchesBySequence 成员变量会维护这个 Topic-Partition 与目前正在发送的 batch 的对应关系(通过 addInFlightBatch() 方法添加 batch 记录),只有这个 batch 成功 ack 后,才会通过 removeInFlightBatch() 方法将这个 batch 从 inflightBatchesBySequence 中移除。接着前面的例子,此时 inflightBatchesBySequence 中还有 2、3、4、5 这几个 batch(有顺序的,2 在前面),根据前面的 RecordAccumulator 的 drain() 方法可以知道只有这个 Topic-Partition 下次要发送的 batch 是 batch 2(跟 transactionManager 的这个 firstInFlightSequence() 方法获取 inFlightBatches 中第一个 batch 的 baseSequence 来判断) 时,才可以发送,否则会直接 break,跳过这个 Topic-Partition 的数据发送。这里相当于有一个等待,等待 batch 2 重新加入到 queue 中,才可以发送,不能跳过 batch 2,直接重试 batch 3、4、5,这是不允许的。
简单来说,其实现机制概括为:
- Server 端验证 batch 的 sequence number 值,不连续时,直接返回异常;
- Client 端请求重试时,batch 在 reenqueue 时会根据 sequence number 值放到合适的位置(有序保证之一);
- Sender 线程发送时,在遍历 queue 中的 batch 时,会检查这个 batch 是否是重试的 batch,如果是的话,只有这个 batch 是最旧的那个需要重试的 batch,才允许发送,否则本次发送跳过这个 Topic-Partition 数据的发送等待下次发送。



相关推荐
此外,Kafka的幂等性和Exactly-Once语义(通过Idempotent Producer和Transaction Support)确保了数据一致性。 4. **C#中的Kafka高级特性**: - **幂等性生产者**:启用幂等性可以防止重复消息。 - **事务支持**...
此外,你还可以利用Kafka的特性,如消息补偿、幂等性、事务支持等,来构建更复杂的应用场景。 通过这个项目,初学者可以深入了解Spring Boot与Kafka的结合,为构建实时数据处理系统打下基础。随着对Kafka和Spring ...
3. **事务性生产者**:通过开启事务支持,可以确保消息的原子性,即一组消息要么全部成功,要么全部失败。 4. **消费者位移提交**:自动提交或手动提交消费者位移(offset),以跟踪已消费的消息。 5. **消费者组...
除了基本的生产和消费功能,Kafka还支持一些高级特性,如幂等性生产者、事务性消费者、连接器(Connectors)以及Kafka Streams,这些都可能在"Kafka-java-demo"中有所体现,帮助你更好地理解和应用Kafka。...
除了基本的生产和消费,你还可以探索更高级的功能,例如错误处理、批处理、幂等性、事务和消费者组等。了解这些特性可以帮助你构建健壮的Kafka应用。 总结一下,"C# kafka demo"提供了一个简单的起点,教你如何在C#...
- **幂等性(Idempotence)**:确保消息不会被重复处理,这对于金融交易等场景尤为重要。 - **事务支持**:允许生产者在一组消息中提供跨分区和跨主题的一致性。 - **延迟队列**:通过配置延迟生产者,可以实现消息...
- **End-to-End Exactly-Once**:端到端的恰好一次交付,通过幂等性和事务特性实现。 4. **Kafka的性能** - **高吞吐量**:通过批量发送、零拷贝等技术实现高效的消息处理。 - **低延迟**:通过分区和消费者组...
- **幂等性(Idempotence)**:在2.0.0版本中,Kafka引入了幂等性,确保消息在任何情况下只会被处理一次,提高了数据一致性。 - **事务(Transactions)**:Kafka支持跨分区和跨 producer 的事务,保证数据的一致...
- Kafka 0.11.0.0引入了幂等性生产者,确保相同的消息不会被多次处理,增强了数据一致性。 - 通过Kafka的事务API,可以在生产者端实现跨多个主题的原子操作,保证数据完整性。 综上所述,这个示例应用将展示如何...
2. **幂等性**:2.*版本引入了幂等性生产者,避免了重复消息的问题。关键在于`IdempotentProducer`和`TransactionalId`的使用,它们确保了在同一事务中多次发送相同消息只会在Kafka中保存一次。 3. **延迟消息**:...
5. **高级特性**:这个库还支持更高级的功能,如分区分配策略、自动提交偏移量、事务性生产和消费、幂等性生产等。例如,你可以自定义分区器以决定消息发送到哪个分区。 6. **版本兼容性**:确保 confluent-kafka-...
在本文中,我们将深入探讨如何将...随着对Spring和Kafka的进一步了解,你可以实现更复杂的功能,比如消息分组、幂等性消费、事务支持等。这只是一个起点,但已经足够帮助新手入门并逐步掌握分布式消息传递的精髓。
SpringBoot 集成了 Kafka 事务支持,允许在分布式环境中实现事务性的消息发送,保证消息的原子性,即要么所有消息都发送成功,要么全部失败。 九、Kafka 可视化工具: 有许多可视化工具如 Kafdrop 或 Kafka Manager...
此外,还可以利用Kafka的特性,如自定义分区器、幂等性生产者和事务性消费者,来优化数据处理和保证数据一致性。 总的来说,Kafka与Java的结合使得数据流处理变得简单且高效。通过上述的"**kafkaDemoTest**"项目,...
- **答案解析**:Kafka的幂等性是指生产者可以多次发送相同的消息,但最终只会被保存一次。这主要通过Kafka的幂等生产者API实现。当启用幂等性时,如果生产者连续两次发送相同的消息,则第二次发送不会覆盖第一次的...
3. **Exactly-Once语义**: 在保证幂等性和事务的基础上,确保消息被处理且仅被处理一次。 4. **Offset管理**: 消费者保存已消费消息的偏移量,下次消费时从上次位置开始。 通过以上步骤,我们可以成功地在...
- **Exactly-Once**:精确一次,Kafka 0.11.0.0及以后版本通过幂等性和事务支持实现。 5. **Kafka的数据持久化与复制** - **Log**:Kafka将消息存储在磁盘上的日志文件中,保证了高效读写。 - **Replication**:...
《Apache Kafka 2.2.0 安装与使用指南》 Apache Kafka 是一个高性能、分布式的消息中间件,常用于...在实践中,不断学习和掌握 Kafka 的高级特性,如幂等性生产者、事务支持等,将进一步提升系统的稳定性和可靠性。
总结,Kafka的数据可靠性机制涉及多个层面,从副本复制、ISR管理到acks策略、幂等性和事务支持,再到消费者组和故障恢复机制,这些都为Kafka构建了一个强大且可靠的数据流平台。理解并合理利用这些机制,可以有效地...
理解并掌握这些基本操作只是开始,深入学习Kafka还需要了解其核心概念,如生产者、消费者、offset管理、幂等性、事务支持等。此外,还要熟悉Kafka的高级特性,如Kafka Connect用于集成外部系统,Kafka Streams用于流...