
еИЖеЄГеЉПдЄАиЗіжАІ
еЬ®дЄАдЄ™еИЖеЄГеЉПз≥їзїЯдЄ≠пЉМе¶ВдљХдњЭиѓБйЫЖзЊ§дЄ≠жЙАжЬЙиКВзВєдЄ≠зЪДжХ∞жНЃеЃМеЕ®зЫЄеРМеєґдЄФиГље§ЯеѓєжЯРдЄ™жПРж°ИпЉИProposalпЉЙиЊЊжИРдЄАиЗіжШѓеИЖеЄГеЉПз≥їзїЯж≠£еЄЄеЈ•дљЬзЪДж†ЄењГйЧЃйҐШпЉМиАМеЕ±иѓЖзЃЧж≥Хе∞±жШѓзФ®жЭ•дњЭиѓБеИЖеЄГеЉПз≥їзїЯдЄАиЗіжАІзЪДжЦєж≥ХгАВ
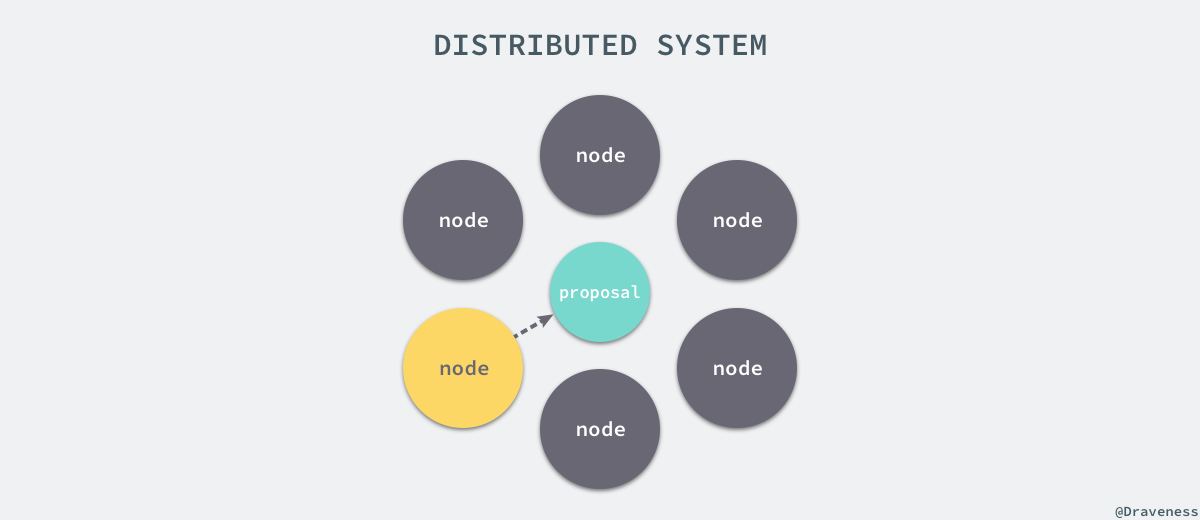
зДґиАМеИЖеЄГеЉПз≥їзїЯзФ±дЇОеЉХеЕ•дЇЖе§ЪдЄ™иКВзВєпЉМжЙАдї•з≥їзїЯдЄ≠дЉЪеЗЇзО∞еРДзІНйЭЮеЄЄе§НжЭВзЪДжГЕеЖµпЉЫйЪПзЭАиКВзВєжХ∞йЗПзЪДеҐЮеК†пЉМиКВзº姱жХИгАБжХЕйЪЬжИЦиАЕеЃХжЬЇе∞±еПШжИРдЇЖдЄАдїґйЭЮеЄЄеЄЄиІБзЪДдЇЛжГЕпЉМиІ£еЖ≥еИЖеЄГеЉПз≥їзїЯдЄ≠зЪДеРДзІНиЊєзХМжЭ°дїґеТМжДПе§ЦжГЕеЖµдєЯеҐЮеК†дЇЖиІ£еЖ≥еИЖеЄГеЉПдЄАиЗіжАІйЧЃйҐШзЪДйЪЊеЇ¶гАВ
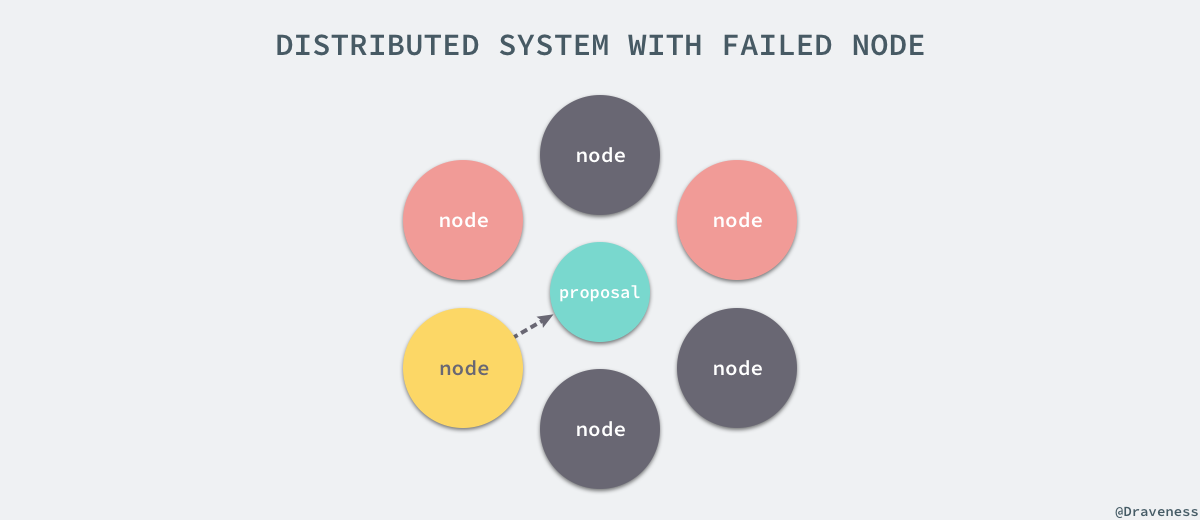
еЬ®дЄАдЄ™еИЖеЄГеЉПз≥їзїЯдЄ≠пЉМйЩ§дЇЖиКВзВєзЪД姱жХИжШѓдЉЪеѓЉиЗідЄАиЗіжАІдЄНеЃєжШУиЊЊжИРзЪДдЄїи¶БеОЯеЫ†дєЛе§ЦпЉМиКВзВєдєЛйЧізЪДзљСзїЬйАЪдњ°жФґеИ∞еє≤жЙ∞зФЪиЗ≥йШїжЦ≠дї•еПКеИЖеЄГеЉПз≥їзїЯзЪДињРи°МйАЯеЇ¶зЪДеЈЃеЉВйГљжШѓиІ£еЖ≥еИЖеЄГеЉПз≥їзїЯдЄАиЗіжАІжЙАйЭҐдЄізЪДйЪЊйҐШгАВ
CAP
еЬ® 1998 еєізЪДзІЛ姩пЉМеК†еЈЮдЉѓеЕЛеИ©е§Іе≠¶зЪДжХЩжОИ Eric Brewer зђђдЄАжђ°еПСеЄГдЇЖ CAP зРЖиЃЇпЉМеЬ® 1999 еєіиЃЇжЦЗ¬†BrewerвАЩs Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services¬†ж≠£еЉПеПСеЄГпЉМеЕґдЄ≠жАїзїУдЇЖ Eric Brewer жПРеЗЇзЪД CAP зРЖиЃЇгАВ
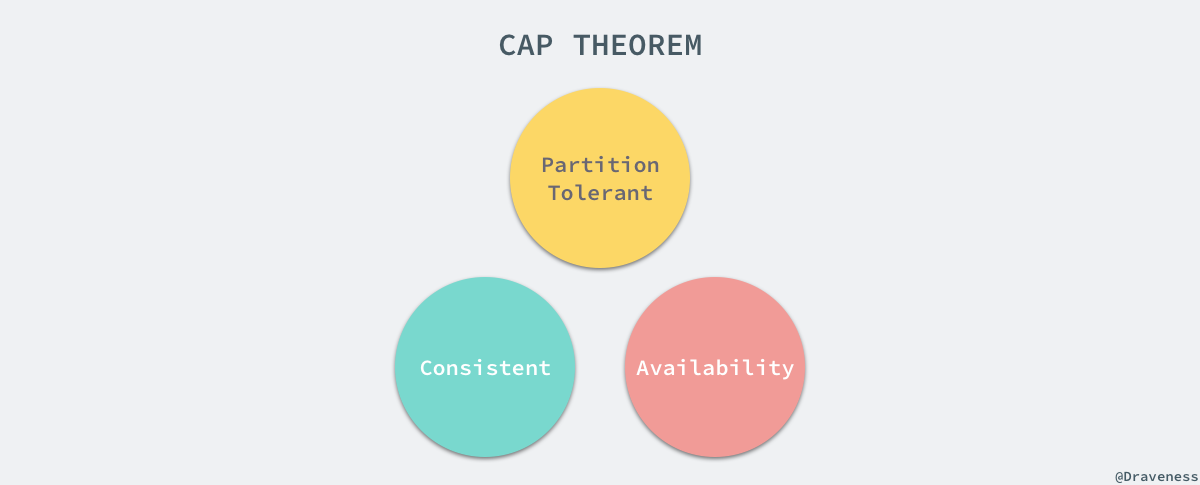
ињЩзѓЗиЃЇжЦЗиѓБжШОдЇЖдЄ§дЄ™йЭЮеЄЄжЬЙжДПжАЭзЪДзРЖиЃЇпЉМй¶ЦеЕИжШѓеЬ®еЉВж≠•зЪДзљСзїЬж®°еЮЛдЄ≠пЉМжЙАжЬЙзЪДиКВзВєзФ±дЇОж≤°жЬЙжЧґйТЯдїЕдїЕиГљж†єжНЃжО•жФґеИ∞зЪДжґИжБѓдљЬеЗЇеИ§жЦ≠пЉМињЩжЧґеЃМеЕ®дЄНиГљеРМжЧґдњЭиѓБдЄАиЗіжАІгАБеПѓзФ®жАІеТМеИЖеМЇеЃєйФЩжАІпЉМжѓПдЄАдЄ™з≥їзїЯеП™иГљеЬ®ињЩдЄЙзІНзЙєжАІдЄ≠йАЙжЛ©дЄ§зІНгАВ
дЄНињЗињЩйЗМиЃ®иЃЇзЪДдЄАиЗіжАІеЕґеЃЮйГљжШѓеЉЇдЄАиЗіжАІпЉМдєЯе∞±жШѓжЙАжЬЙиКВзВєжО•жФґеИ∞еРМж†ЈзЪДжУНдљЬжЧґдЉЪжМЙзЕІеЃМеЕ®зЫЄеРМзЪДй°ЇеЇПжЙІи°МпЉМ襀дЄАдЄ™иКВзВєжПРдЇ§зЪДжЫіжЦ∞жУНдљЬдЉЪзЂЛеИїеПНжШ†еЬ®еЕґдїЦйАЪињЗеЉВж≠•жИЦйГ®еИЖеРМж≠•зљСзїЬињЮжО•зЪДиКВзВєдЄКпЉМе¶ВжЮЬжГ≥и¶БеРМжЧґжї°иґ≥дЄАиЗіжАІеТМеИЖеМЇеЃєйФЩжАІпЉМеЬ®еЉВж≠•зЪДзљСзїЬдЄ≠пЉМжИСдїђеП™иГљдЄ≠ењГеМЦе≠ШеВ®жЙАжЬЙжХ∞жНЃпЉМйАЪињЗеЕґдїЦиКВзВєе∞ЖиѓЈж±ВиЈѓзФ±зїЩдЄ≠ењГиКВзВєиЊЊеИ∞ињЩдЄ§дЄ™зЫЃзЪДгАВ
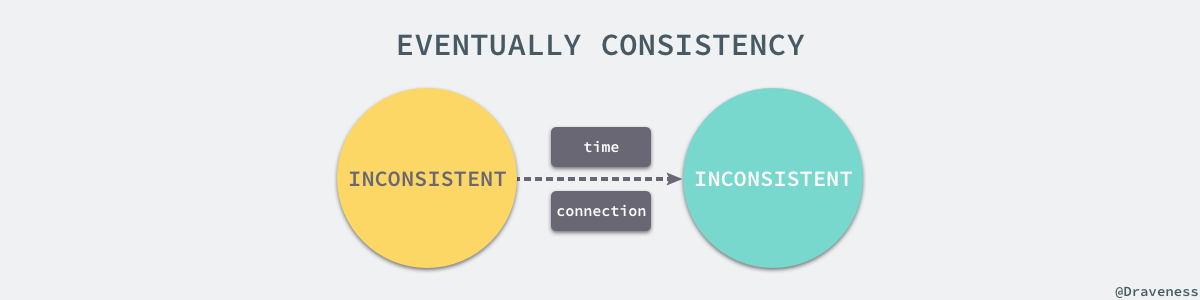
дљЖжШѓеЬ®зО∞еЃЮдЄЦзХМдЄ≠еЕґеЃЮеєґдЄНе≠ШеЬ®зїЭеѓєеЉВж≠•зЪДзљСзїЬзОѓеҐГпЉМе¶ВжЮЬжИСдїђеЕБиЃЄжѓПдЄАдЄ™иКВзВєжЛ•жЬЙиЗ™еЈ±зЪДжЧґйТЯпЉМињЩдЇЫжЧґйТЯиЩљзДґжЬЙзЭАеЃМеЕ®дЄНеРМзЪДжЧґйЧіпЉМдљЖжШѓеЃГдїђзЪДжЫіжЦ∞йҐСзОЗжШѓеЃМеЕ®зЫЄеРМзЪДпЉМжЙАдї•жИСдїђеПѓдї•йАЪињЗжЧґйТЯеЊЧзЯ•жО•жФґжґИжБѓзЪДйЧійЪФжЧґйЧіпЉМеЬ®ињЩзІНжЫіеЃљжЭЊзЪДеЙНжПРдЄЛпЉМжИСдїђиГље§ЯеЊЧеИ∞жЫіеЉЇе§ІзЪДжЬНеК°гАВ
зДґиАМеЬ®йГ®еИЖеРМж≠•зЪДзљСзїЬзОѓеҐГдЄ≠пЉМжИСдїђдїНзДґж≤°жЬЙеКЮж≥ХеРМжЧґдњЭиѓБдЄАиЗіжАІгАБеПѓзФ®жАІеТМеИЖеМЇеЃєйФЩжАІпЉМиѓБжШОзЪДињЗз®ЛеЕґеЃЮйЭЮеЄЄзЃАеНХпЉМеПѓдї•зЫіжО•йШЕиѓї¬†иЃЇжЦЗ¬†зЪД 4.2 иКВпЉМзДґиАМжЧґйТЯзЪДеЗЇзО∞иГље§ЯиЃ©жИСдїђзЯ•йБУељУеЙНжґИжБѓжЬЙе§ЪдєЕж≤°жЬЙеЊЧеИ∞еЫЮеЇФпЉМйАЪињЗиґЕжЧґжЧґйЧіе∞±иГљеЬ®дЄАеЃЪз®ЛеЇ¶дЄКиІ£еЖ≥дњ°жБѓдЄҐе§±зЪДйЧЃйҐШгАВ
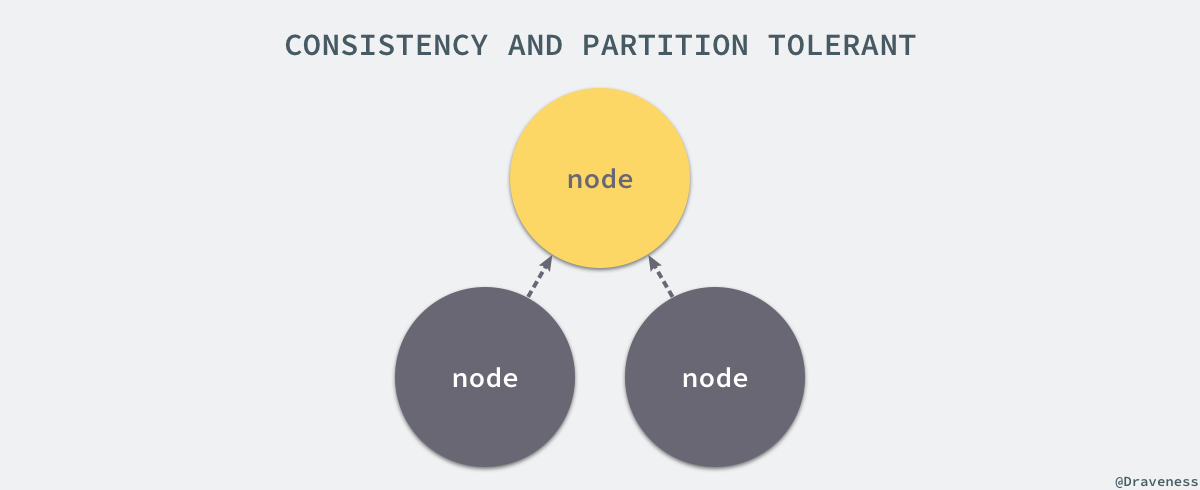
зФ±дЇОзљСзїЬдЄАеЃЪдЉЪе≠ШеЬ®еїґжЧґпЉМжЙАдї•ж≤°жЬЙеКЮж≥ХеЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠еБЪеИ∞еЉЇдЄАиЗіжАІзЪДеРМжЧґдњЭиѓБеПѓзФ®жАІпЉМдЄНињЗжИСдїђеПѓдї•йАЪињЗйЩНдљОеѓєдЄАиЗіжАІзЪДи¶Бж±ВпЉМеЬ®дЄАиЗіжАІеТМеПѓзФ®жАІдєЛйЧіеБЪеЗЇжЭГи°°пЉМиАМињЩеЕґеЃЮдєЯжШѓиЃЊиЃ°еИЖеЄГеЉПз≥їзїЯй¶ЦеЕИйЬАи¶БиАГиЩСзЪДйЧЃйҐШпЉМзФ±дЇОеЉЇдЄАиЗіжАІзЪДз≥їзїЯдЉЪеѓЉиЗіз≥їзїЯзЪДеПѓзФ®жАІйЩНдљОпЉМдїЕдїЕе∞ЖжО•еПЧиѓЈж±ВзЪДеЈ•дљЬдЇ§зїЩеЕґдїЦиКВзВєеѓєдЇОйЂШеєґеПСзЪДжЬНеК°еєґдЄНиГљиІ£еЖ≥йЧЃйҐШпЉМжЙАдї•еЬ®зЫЃеЙНдЄїжµБзЪДеИЖеЄГеЉПз≥їзїЯдЄ≠йГљйАЙжЛ©жЬАзїИдЄАиЗіжАІгАВ
жЬАзїИдЄАиЗіжАІеЕБиЃЄе§ЪдЄ™иКВзВєзЪДзКґжАБеЗЇзО∞еЖ≤з™БпЉМдљЖжШѓжЙАжЬЙиГље§Яж≤ЯйАЪзЪДиКВзВєйГљиГље§ЯеЬ®жЬЙйЩРзЪДжЧґйЧіеЖЕиІ£еЖ≥еЖ≤з™БпЉМдїОдЄНдЄАиЗізЪДзКґжАБжБҐе§НеИ∞дЄАиЗіпЉМињЩйЗМеИЧеЗЇзЪДдЄ§дЄ™жЭ°дїґжѓФиЊГйЗНи¶БпЉМдЄАжШѓиКВзВєзЫіжО•еПѓдї•ж≠£еЄЄйАЪдњ°пЉМдЇМжШѓеЖ≤з™БйЬАи¶БеЬ®жЬЙйЩРзЪДжЧґйЧіеЖЕиІ£еЖ≥пЉМеП™жЬЙеЬ®ињЩдЄ§дЄ™жЭ°дїґжИРзЂЛжЧґжЙНиГљиЊЊеИ∞жЬАзїИдЄАиЗіжАІгАВ
жЛЬеН†еЇ≠е∞ЖеЖЫйЧЃйҐШ
жЛЬеН†еЇ≠е∞ЖеЖЫйЧЃйҐШжШѓ Leslie Lamport еЬ®¬†The Byzantine Generals Problem¬†иЃЇжЦЗдЄ≠жПРеЗЇзЪДеИЖеЄГеЉПйҐЖеЯЯзЪДеЃєйФЩйЧЃйҐШпЉМеЃГжШѓеИЖеЄГеЉПйҐЖеЯЯдЄ≠жЬАе§НжЭВгАБжЬАдЄ•ж†ЉзЪДеЃєйФЩж®°еЮЛгАВ
еЬ®иѓ•ж®°еЮЛдЄЛпЉМз≥їзїЯдЄНдЉЪеѓєйЫЖзЊ§дЄ≠зЪДиКВзВєеБЪдїїдљХзЪДйЩРеИґпЉМеЃГдїђеПѓдї•еРСеЕґдїЦиКВзВєеПСйАБйЪПжЬЇжХ∞жНЃгАБйФЩиѓѓжХ∞жНЃпЉМдєЯеПѓдї•йАЙжЛ©дЄНеУНеЇФеЕґдїЦиКВзВєзЪДиѓЈж±ВпЉМињЩдЇЫжЧ†ж≥ХйҐДжµЛзЪДи°МдЄЇдљњеЊЧеЃєйФЩињЩдЄАйЧЃйҐШеПШеЊЧжЫіеК†е§НжЭВгАВ
жЛЬеН†еЇ≠е∞ЖеЖЫйЧЃйҐШжППињ∞дЇЖдЄАдЄ™е¶ВдЄЛзЪДеЬЇжЩѓпЉМжЬЙдЄАзїДе∞ЖеЖЫеИЖеИЂжМЗжМ•дЄАйГ®еИЖеЖЫйШЯпЉМжѓПдЄАдЄ™е∞ЖеЖЫйГљдЄНзЯ•йБУеЕґеЃГе∞ЖеЖЫжШѓеР¶жШѓеПѓйЭ†зЪДпЉМдєЯдЄНзЯ•йБУеЕґдїЦе∞ЖеЖЫдЉ†йАТзЪДдњ°жБѓжШѓеР¶еПѓйЭ†пЉМдљЖжШѓеЃГдїђйЬАи¶БйАЪињЗжКХз•®йАЙжЛ©жШѓеР¶и¶БињЫжФїжИЦиАЕжТ§йААпЉЪ
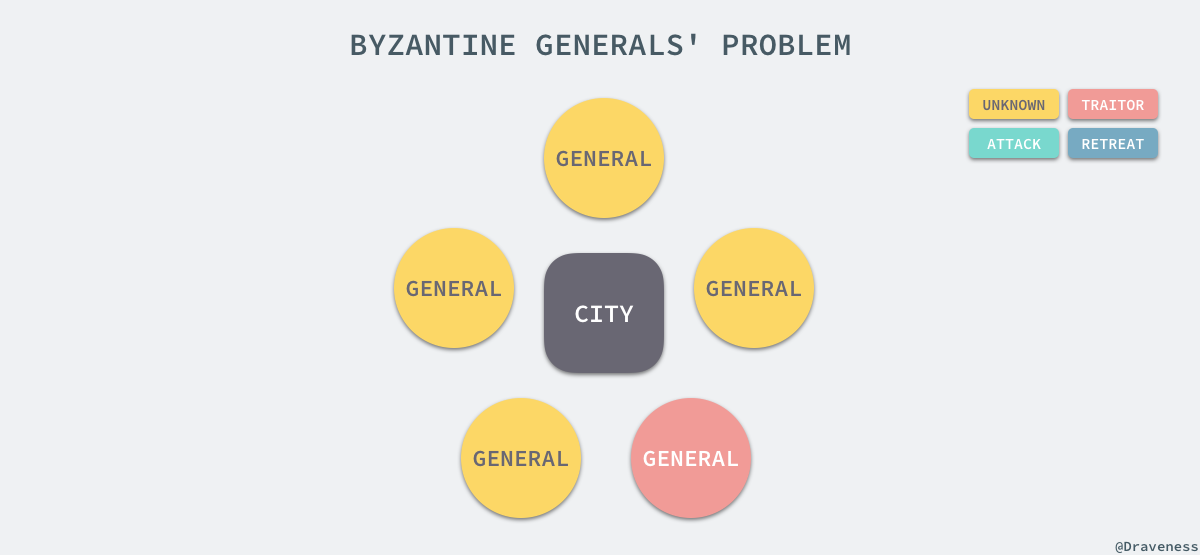
еЬ®ињЩдЄАиКВдЄ≠пЉМйїДиЙ≤дї£и°®зКґжАБжЬ™зЯ•пЉМзїњиЙ≤дї£и°®ињЫжФїпЉМиУЭиЙ≤дї£и°®жТ§йААпЉМжЬАеРОзЇҐиЙ≤дї£и°®ељУеЙНе∞ЖеЖЫзЪДдњ°жБѓдЄНеПѓйЭ†гАВ
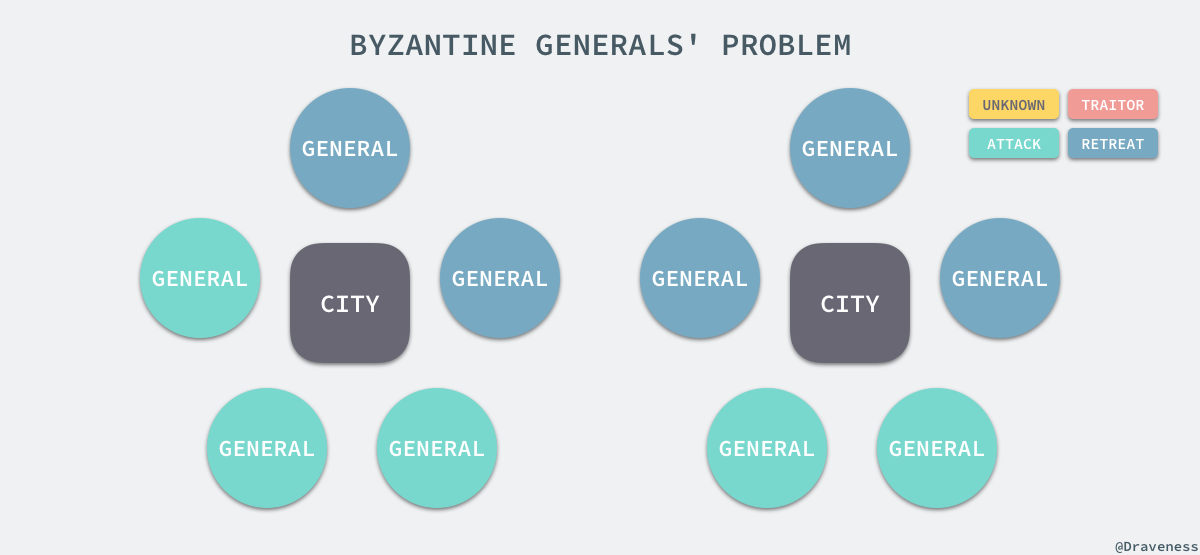
еЬ®ињЩжЧґпЉМжЧ†иЃЇе∞ЖеЖЫжШѓеР¶еПѓйЭ†пЉМеП™и¶БжЙАжЬЙзЪДе∞ЖеЖЫиЊЊжИРдЇЖзїЯдЄАзЪДжЦєж°ИпЉМйАЙжЛ©ињЫжФїжИЦиАЕжТ§йААеЕґеЃЮе∞±жШѓж≤°жЬЙдїїдљХйЧЃйҐШзЪДпЉЪ
дЄКињ∞зЪДжГЕеЖµдЄНдЉЪеѓєељУеЙНзЪДжИШе±АжЬЙ姙е§ЪзЪДељ±еУНпЉМдєЯдЄНдЉЪйА†жИРжНЯ姱пЉМдљЖжШѓе¶ВжЮЬеЕґдЄ≠зЪДдЄАдЄ™е∞ЖеЖЫеСКиѓЙеЕґдЄ≠дЄАйГ®еИЖе∞ЖеЖЫйАЙжЛ©ињЫжФїгАБеП¶дЄАйГ®еИЖйАЙжЛ©жТ§йААпЉМе∞±дЉЪеЗЇзО∞йЭЮеЄЄдЄ•йЗНзЪДйЧЃйҐШдЇЖгАВ
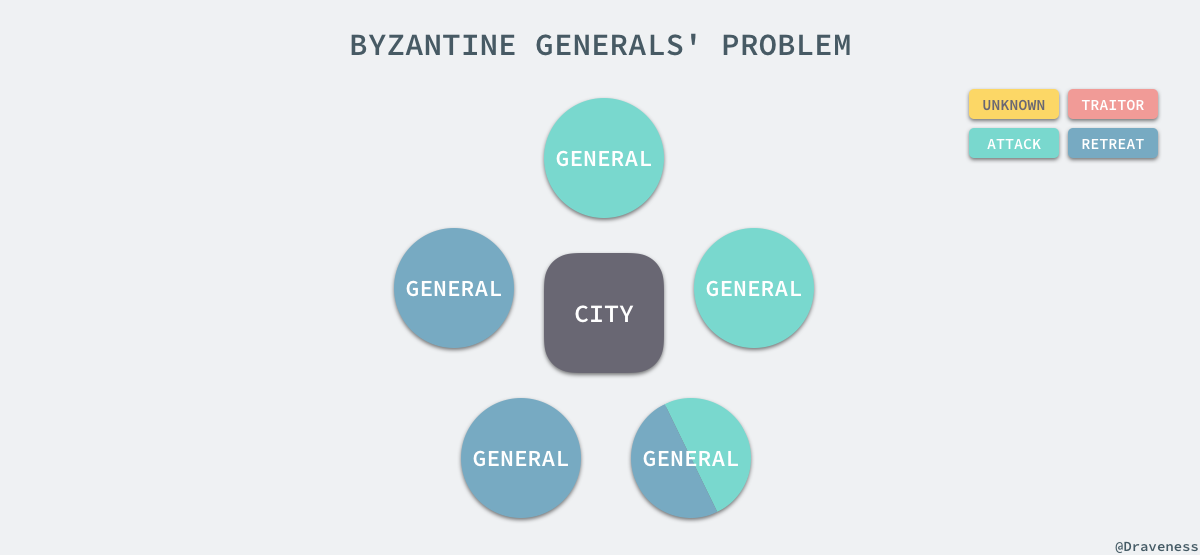
зФ±дЇОе∞ЖеЖЫзЪДйШЯдЉНдЄ≠еЗЇдЇЖдЄАдЄ™еПЫеЊТжИЦиАЕдњ°жБѓеЬ®дЉ†йАТзЪДињЗз®ЛдЄ≠襀жЛ¶жИ™пЉМдЉЪеѓЉиЗідЄАйГ®еИЖе∞ЖеЖЫдЉЪйАЙжЛ©ињЫжФїпЉМеЙ©дЄЛзЪДдЄАйГ®еИЖдЉЪйАЙжЛ©жТ§йААпЉМеЃГдїђйГљиЃ§дЄЇиЗ™еЈ±зЪДйАЙжЛ©жШѓе§Іе§ЪжХ∞дЇЇзЪДйАЙжЛ©пЉМињЩжЧґе∞±еЗЇзО∞дЇЖдЄ•йЗНзЪДдЄНдЄАиЗійЧЃйҐШгАВ
жЛЬеН†еЇ≠е∞ЖеЖЫйЧЃйҐШжШѓеѓєеИЖеЄГеЉПз≥їзїЯеЃєйФЩзЪДжЬАйЂШи¶Бж±ВпЉМзДґиАМињЩдЄНжШѓжЧ•еЄЄеЈ•дљЬдЄ≠дљњзФ®зЪДе§Іе§ЪжХ∞еИЖеЄГеЉПз≥їзїЯдЄ≠дЉЪйЭҐеѓєзЪДйЧЃйҐШпЉМжИСдїђйБЗеИ∞жЫіе§ЪзЪДињШжШѓиКВзВєжХЕйЪЬеЃХжЬЇжИЦиАЕдЄНеУНеЇФз≠ЙжГЕеЖµпЉМињЩе∞±е§Іе§ІзЃАеМЦдЇЖз≥їзїЯеѓєеЃєйФЩзЪДи¶Бж±ВпЉЫдЄНињЗз±їдЉЉ BitcoinгАБEthereum з≠ЙеИЖеЄГеЉПз≥їзїЯз°ЃеЃЮйЬАи¶БиАГиЩСжЛЬеН†еЇ≠еЃєйФЩзЪДйЧЃйҐШпЉМжИСдїђдЉЪеЬ®дЄЛйЭҐдїЛзїНеЃГдїђжШѓе¶ВдљХиІ£еЖ≥зЪДгАВ
FLP
FLP дЄНеПѓиГљеЃЪзРЖжШѓеИЖеЄГеЉПз≥їзїЯйҐЖеЯЯжЬАйЗНи¶БзЪДеЃЪзРЖдєЛдЄАпЉМеЃГзїЩеЗЇдЇЖдЄАдЄ™йЭЮеЄЄйЗНи¶БзЪДзїУиЃЇпЉЪеЬ®зљСзїЬеПѓйЭ†еєґдЄФе≠ШеЬ®иКВзº姱жХИзЪДеЉВж≠•ж®°еЮЛз≥їзїЯдЄ≠пЉМдЄНе≠ШеЬ®дЄАдЄ™еПѓдї•иІ£еЖ≥дЄАиЗіжАІйЧЃйҐШзЪДз°ЃеЃЪжАІзЃЧж≥ХгАВ
In this paper, we show the surprising result that no completely asynchronous consensus protocol can tolerate even a single unannounced process death. We do not consider Byzantine failures, and we assume that the message system is reliable it delivers all messages correctly and exactly once.
ињЩдЄ™еЃЪзРЖеЕґеЃЮдєЯе∞±жШѓеСКиѓЙжИСдїђдЄНи¶Бжµ™иієжЧґйЧіеОїдЄЇеЉВж≠•еИЖеЄГеЉПз≥їзїЯиЃЊиЃ°еЬ®дїїжДПеЬЇжЩѓдЄКйГљиГље§ЯеЃЮзО∞еЕ±иѓЖзЪДзЃЧж≥ХпЉМеЉВж≠•з≥їзїЯеЃМеЕ®ж≤°жЬЙеКЮж≥ХдњЭиѓБиГљеЬ®жЬЙйЩРжЧґйЧіеЖЕиЊЊжИРдЄАиЗіпЉМеЬ®ињЩйЗМдљЬиАЕеєґдЄНдЉЪе∞ЭиѓХеОїиѓБжШО FLP дЄНеПѓиГљеЃЪзРЖпЉМиѓїиАЕеПѓдї•йШЕиѓїзЫЄеЕ≥иЃЇжЦЗ¬†Impossibility of Distributed Consensuswith One Faulty Process¬†дЇЖиІ£жЫіе§ЪзЪДеЖЕеЃєгАВ
еЕ±иѓЖзЃЧж≥Х
еЬ®дЄКдЄАиКВдЄ≠пЉМжИСдїђеЈ≤зїПзЃАеНХдЇЖиІ£дЇЖеИЖеЄГеЉПз≥їзїЯдЄ≠йЭҐеѓєзЪДйЧЃйҐШдЄОжМСжИШпЉМеЬ®ињЩйЗМжИСдїђдЉЪдїЛзїНдЄНеРМеЕ±иѓЖзЃЧж≥ХзЪДеЃЮзО∞еОЯзРЖпЉМеМЕжЛђдЉ†зїЯеИЖеЄГеЉПз≥їзїЯйҐЖеЯЯзЪД PaxosгАБRaft дї•еПКеѓЖз†БиіІеЄБдЄ≠дљњзФ®зЪДеЈ•дљЬйЗПиѓБжШОпЉИPOWпЉЙгАБжЭГзЫКиѓБжШОпЉИPOSпЉЙеТМеІФжЙШжЭГзЫКиѓБжШОпЉИDPOSпЉЙпЉМйАЪињЗеѓєињЩдЇЫеЕ±иѓЖзЃЧж≥ХеОЯзРЖзЪДдїЛзїНеТМеИЖжЮРпЉМжИСзЫЄдњ°еРДдљНиѓїиАЕиГљеѓєеИЖеЄГеЉПдЄАиЗіжАІеТМеЕ±иѓЖзЃЧж≥ХжЬЙжЫіжЈ±зЪДзРЖиІ£гАВ
Paxos еТМ Raft
Paxos еТМ Raft жШѓзЫЃеЙНеИЖеЄГеЉПз≥їзїЯйҐЖеЯЯдЄ≠дЄ§зІНйЭЮеЄЄиСЧеРНзЪДиІ£еЖ≥дЄАиЗіжАІйЧЃйҐШзЪДеЕ±иѓЖзЃЧж≥ХпЉМдЄ§иАЕйГљиГљиІ£еЖ≥еИЖеЄГеЉПз≥їзїЯдЄ≠зЪДдЄАиЗіжАІйЧЃйҐШпЉМдљЖжШѓеЙНиАЕзЪДеЃЮзО∞дЄОиѓБжШОйЭЮеЄЄйЪЊдї•зРЖиІ£пЉМеРОиАЕзЪДеЃЮзО∞жѓФиЊГзЃАжіБеєґдЄФйБµеЊ™дЇЇзЪДзЫіиІЙпЉМеЃГзЪДеЗЇзО∞е∞±жШѓдЄЇдЇЖиІ£еЖ≥ Paxos йЪЊдї•зРЖиІ£еєґеТМйЪЊдї•еЃЮзО∞зЪДйЧЃйҐШгАВ
жИСдїђеЕИжЭ•зЃАеНХдїЛзїНдЄАдЄЛ¬†Paxos¬†з©ґзЂЯжШѓдїАдєИпЉМPaxos еЕґеЃЮжШѓдЄАз±їиГље§ЯиІ£еЖ≥еИЖеЄГеЉПдЄАиЗіжАІйЧЃйҐШзЪДеНПиЃЃпЉМеЃГиГље§ЯиЃ©еИЖеЄГеЉПзљСзїЬдЄ≠зЪДиКВзВєеЬ®еЗЇзО∞йФЩиѓѓжЧґдїНзДґдњЭжМБдЄАиЗіпЉЫLeslie Lamport жПРеЗЇзЪД Paxos еПѓдї•еЬ®ж≤°жЬЙжБґжДПиКВзВєзЪДеЙНжПРдЄЛдњЭиѓБз≥їзїЯдЄ≠иКВзВєзЪДдЄАиЗіжАІпЉМдєЯжШѓзђђдЄА䪙襀иѓБжШОеЃМе§ЗзЪДеЕ±иѓЖзЃЧж≥ХпЉМзЫЃеЙНзЪДеЃМе§ЗзЪДеЕ±иѓЖзЃЧж≥ХеМЕжЛђ Raft жЬђиі®дЄКйГљжШѓ Paxos зЪДеПШзІНгАВ
дљЬдЄЇдЄАз±їеНПиЃЃпЉМPaxos дЄ≠еМЕеРЂ Basic PaxosгАБMulti-PaxosгАБCheap Paxos еТМеЕґдїЦзЪДеПШзІНпЉМеЬ®ињЩдЄАе∞ПиКВжИСдїђдЉЪзЃАеНХдїЛзїН Basic Paxos еТМ Multi-Paxos ињЩдЄ§зІНеНПиЃЃгАВ
Basic Paxos
Basic Paxos жШѓ Paxos дЄ≠жЬАдЄЇеЯЇз°АзЪДеНПиЃЃпЉМжѓПдЄАдЄ™ Basic Paxos зЪДеНПиЃЃеЃЮдЊЛжЬАзїИйГљдЉЪйАЙжЛ©еФѓдЄАдЄАдЄ™зїУжЮЬпЉЫдљњзФ® Paxos дљЬдЄЇеЕ±иѓЖзЃЧж≥ХзЪДеИЖеЄГеЉПз≥їзїЯдЄ≠пЉМиКВзВєйГљдЉЪжЬЙдЄЙзІНиЇЂдїљпЉМеИЖеИЂжШѓ ProposerгАБAcceptor еТМ LearnerпЉЪ
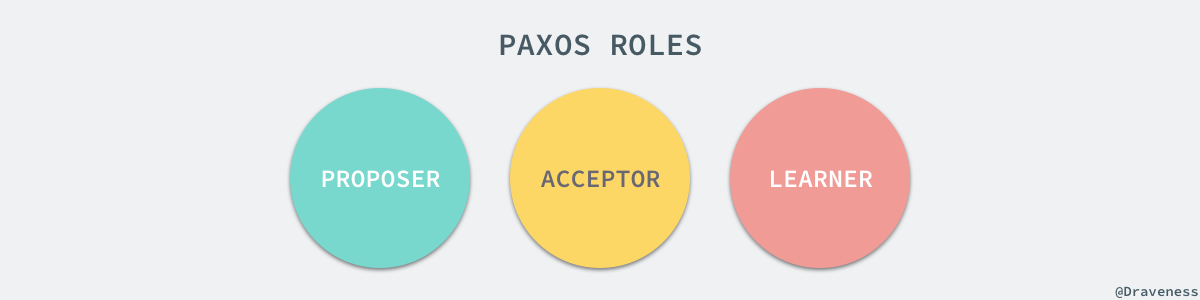
жИСдїђеЬ®ињЩйЗМдЉЪењљзХ•жЬАеРОдЄАзІНиЇЂдїљ Learner зЃАеМЦеНПиЃЃзЪДињРи°МињЗз®ЛпЉМдЊњдЇОиѓїиАЕзРЖиІ£пЉЫPaxos зЪДињРи°МињЗз®ЛеИЖдЄЇдЄ§дЄ™йШґжЃµпЉМеИЖеИЂжШѓеЗЖе§ЗйШґжЃµпЉИPrepareпЉЙеТМжО•еПЧйШґжЃµпЉИAcceptпЉЙпЉМељУ Proposer жО•жФґеИ∞жЭ•иЗ™еЃҐжИЈзЂѓзЪДиѓЈж±ВжЧґпЉМе∞±дЉЪињЫеЕ•е¶ВдЄЛжµБз®ЛпЉЪ

дї•дЄКжИ™еЫЊеПЦиЗ™¬†Paxos lecture (Raft user study)¬†зЪДзђђ 12 й°µгАВ
еЬ®жХідЄ™еЕ±иѓЖзЃЧж≥ХињРи°МзЪДињЗз®ЛдЄ≠пЉМProposer иіЯиі£жПРеЗЇжПРж°ИеєґеРС Acceptor еИЖеИЂеПСеЗЇдЄ§жђ° RPC иѓЈж±ВпЉМPrepare еТМ AcceptпЉЫAcceptor дЉЪж†єжНЃеЕґжМБжЬЙзЪДдњ°жБѓ¬†minProposalгАБacceptedProposal¬†еТМ¬†acceptedValue¬†йАЙжЛ©жО•еПЧжИЦиАЕжЛТзїЭељУеЙНзЪДжПРж°ИпЉМељУжЯРдЄАдЄ™жПРж°И襀ињЗеНКжХ∞зЪД Acceptor жО•еПЧдєЛеРОпЉМжИСдїђе∞±иЃ§дЄЇељУеЙНжПРж°И襀жХідЄ™йЫЖзЊ§жО•еПЧдЇЖгАВ
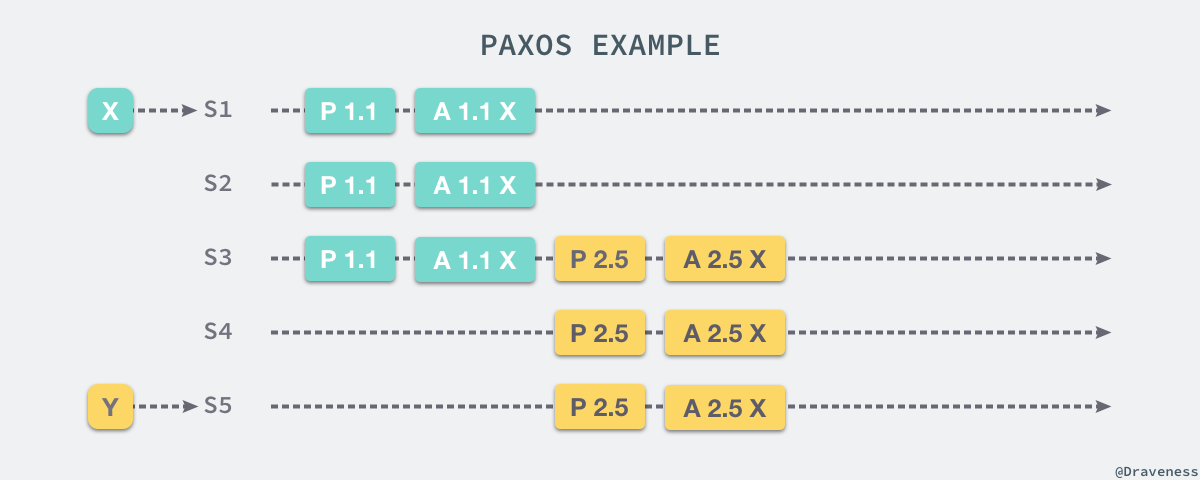
жИСдїђзЃАеНХдЄЊдЄАдЄ™дЊЛе≠РдїЛзїН Paxos жШѓе¶ВдљХеЬ®е§ЪдЄ™жПРж°ИдЄЛдњЭиѓБжЬАзїИиГље§ЯиЊЊеИ∞дЄАиЗіжАІзЪДпЉМдЄКињ∞еЫЊзЙЗдЄ≠ S1 еТМ S5 еИЖеИЂжФґеИ∞дЇЖжЭ•иЗ™еЃҐжИЈзЂѓзЪДиѓЈж±В X еТМ YпЉМS1 й¶ЦеЕИеРС S2 еТМ S3 еПСеЗЇ Prepare RPC еТМ Accept RPCпЉМдЄЙдЄ™жЬНеК°еЩ®йГљжО•еПЧдЇЖ S1 зЪДжПРж°И XпЉЫеЬ®ињЩдєЛеРОпЉМS5 еРС S3 еТМ S4 жЬНеК°еЩ®еПСеЗЇ¬†Prepare(2.5)¬†зЪДиѓЈж±ВпЉМS3 зФ±дЇОеЈ≤зїПжО•еПЧдЇЖ XпЉМжЙАдї•еЃГдЉЪињФеЫЮжО•еПЧзЪДжПРж°ИеТМеАЉ¬†(1.1, X)пЉМињЩжЧґжЬНеК°еЩ®дљњзФ®жО•жФґеИ∞зЪДжПРж°Идї£жЫњиЗ™еЈ±зЪДжПРж°И YпЉМйЗНжЦ∞еРСеЕґдїЦжЬНеК°еЩ®еПСйАБ¬†Accept(2.5, X)¬†зЪД RPCпЉМжЬАзїИжЙАжЬЙзЪДжЬНеК°еЩ®дЉЪиЊЊжИРдЄАиЗіеєґйАЙжЛ©зЫЄеРМзЪДеАЉгАВ
жГ≥и¶БдЇЖиІ£жЫіе§ЪдЄО Paxos еНПиЃЃеЬ®ињРи°МињЗз®ЛдЄ≠зЪДеЕґдїЦжГЕеЖµеПѓдї•зЬЛдЄАдЄЛ¬†Paxos lecture (Raft user study)¬†иІЖйҐСгАВ
Multi-Paxos
зФ±дЇОе§Іе§ЪжХ∞зЪДеИЖеЄГеЉПйЫЖзЊ§йГљйЬАи¶БжО•еПЧдЄАз≥їеИЧзЪДеАЉпЉМе¶ВжЮЬдљњзФ® Basic Paxos жЭ•е§ДзРЖжХ∞жНЃжµБпЉМйВ£дєИе∞±дЉЪеѓЉиЗійЭЮеЄЄжШОжШЊзЪДжАІиГљжНЯ姱пЉМиАМ Multi-Paxos жШѓеЙНиАЕзЪДеК†еЉЇзЙИпЉМе¶ВжЮЬйЫЖзЊ§дЄ≠зЪД Leader жШѓйЭЮеЄЄз®≥еЃЪзЪДпЉМйВ£дєИжИСдїђеЊАеЊАдЄНйЬАи¶БеЗЖе§ЗйШґжЃµзЪДеЈ•дљЬпЉМињЩж†Је∞±иГље§Яе∞Ж RPC зЪДжХ∞йЗПеЗПе∞СдЄАеНКгАВ

дЄКињ∞еЫЊзЙЗдЄ≠жППињ∞зЪДе∞±жШѓз®≥еЃЪйШґжЃµ Multi-Paxos зЪДе§ДзРЖињЗз®ЛпЉМS1 жШѓжХідЄ™йЫЖзЊ§зЪД LeaderпЉМељУеЕґдїЦзЪДжЬНеК°еЩ®жО•жФґеИ∞жЭ•иЗ™еЃҐжИЈзЂѓзЪДиѓЈж±ВжЧґпЉМйГљдЉЪе∞ЖиѓЈж±ВиљђеПСзїЩ Leader ињЫи°Ме§ДзРЖгАВ
ељУзДґпЉМLeader иІТиЙ≤зЪДеЗЇзО∞иЗ™зДґдЉЪеЄ¶жЭ•еП¶дЄАдЄ™йЧЃйҐШпЉМдєЯе∞±жШѓ Leader з©ґзЂЯеЇФиѓ•е¶ВдљХйАЙдЄЊпЉМеЬ®¬†Paxos Made Simple¬†дЄАжЦЗдЄ≠еєґж≤°жЬЙзїЩеЗЇ Multi-Paxos зЪДеЕЈдљУеЃЮзО∞жЦєж≥ХеТМзїЖиКВпЉМжЙАдї•дЄНеРМ Multi-Paxos зЪДеЃЮзО∞дЄКжАїжЬЙеРДзІНеРДж†ЈзїЖеЊЃзЪДеЈЃеИЂгАВ
Raft
Raft еЕґеЃЮе∞±жШѓ Multi-Paxos зЪДдЄАдЄ™еПШзІНпЉМRaft йАЪињЗзЃАеМЦ Multi-Paxos зЪДж®°еЮЛпЉМеЃЮзО∞дЇЖдЄАзІНжЫіеЃєжШУиЃ©дЇЇзРЖиІ£зЪДеЕ±иѓЖзЃЧж≥ХпЉМеЃГдїђдЄ§иАЕйГљиГље§ЯеѓєдЄАз≥їеИЧињЮзї≠зЪДйЧЃйҐШиЊЊжИРдЄАиЗігАВ
Raft еЬ® Multi-Paxos зЪДеЯЇз°АдєЛдЄКеБЪдЇЖдЄ§дЄ™йЩРеИґпЉМй¶ЦеЕИжШѓ Raft дЄ≠ињљеК†жЧ•ењЧзЪДжУНдљЬењЕй°їжШѓињЮзї≠зЪДпЉМиАМ Multi-Paxos дЄ≠ињљеК†жЧ•ењЧзЪДжУНдљЬжШѓеєґеПСзЪДпЉМдљЖжШѓеѓєдЇОиКВзВєеЖЕйГ®зЪДзКґжАБжЬЇжЭ•иѓідЄ§иАЕйГљжШѓжЬЙеЇПзЪДпЉМзђђдЇМе∞±жШѓ Raft еѓє Leader йАЙдЄЊзЪДжЭ°дїґеБЪдЇЖйЩРеИґпЉМеП™жЬЙжЛ•жЬЙжЬАжЦ∞гАБжЬАеЕ®жЧ•ењЧзЪДиКВзВєжЙНиГље§ЯељУйАЙ LeaderпЉМдљЖжШѓ Multi-Paxos зФ±дЇОдїїжДПиКВзВєйГљеПѓдї•еЖЩжЧ•ењЧпЉМжЙАдї•еЬ®йАЙжЛ© Leader дЄКдєЯж≤°жЬЙдїАдєИйЩРеИґпЉМеП™жШѓеЬ®йАЙжЛ© Leader дєЛеРОйЬАи¶Бе∞Ж Leader дЄ≠зЪДжЧ•ењЧи°•еЕ®гАВ
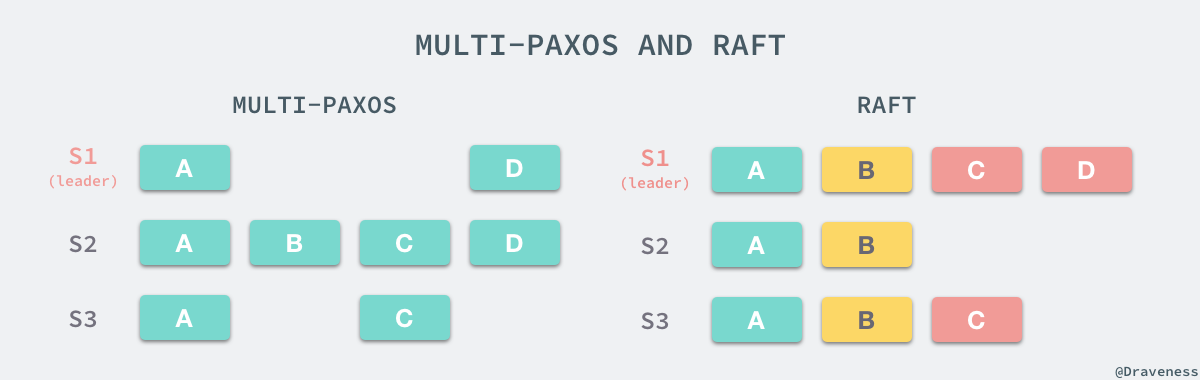
еЬ® Raft дЄ≠пЉМжЙАжЬЙ Follower зЪДжЧ•ењЧйГљжШѓ Leader зЪДе≠РйЫЖпЉМиАМ Multi-Paxos дЄ≠зЪДжЧ•ењЧеєґдЄНдЉЪеБЪињЩдЄ™дњЭиѓБпЉМзФ±дЇО Raft еѓєжЧ•ењЧињљеК†зЪДжЦєеЉПеТМйАЙдЄЊињЗз®ЛињЫи°МдЇЖйЩРеИґпЉМжЙАдї•еЬ®еЃЮзО∞дЄКдЉЪжЫіеК†еЃєжШУеТМзЃАеНХгАВ
дїОзРЖиЃЇдЄКжЭ•иЃ≤пЉМжФѓжМБеєґеПСжЧ•ењЧињљеК†зЪД Paxos дЉЪжѓФ Raft жЬЙжЫідЉШзІАзЪДжАІиГљпЉМдЄНињЗеЕґзРЖиІ£еТМеЃЮзО∞дЄКињШжШѓжѓФиЊГе§НжЭВзЪДпЉМеЊИе§ЪдЇЇйГљдЉЪиѓі Paxos жШѓзІСе≠¶пЉМиАМ Raft жШѓеЈ•з®ЛпЉМељУдљЬиАЕйЬАи¶БеОїеЃЮзО∞дЄАдЄ™еЕ±иѓЖзЃЧж≥ХпЉМдЉЪйАЙжЛ©дљњзФ® Raft еТМжЫізЃАжіБзЪДеЃЮзО∞пЉМйБњеЕНеЫ†дЄЇдЄАдЇЫиЊєзХМжЭ°дїґиАМеЄ¶жЭ•зЪДе§НжЭВйЧЃйҐШгАВ
ињЩзѓЗжЦЗзЂ†еєґдЄНдЉЪе±ХеЉАдїЛзїН Raft зЪДеЃЮзО∞ињЗз®ЛеТМзїЖиКВпЉМе¶ВжЮЬеѓє Raft жЬЙеЕіиґ£зЪДиѓїиАЕеПѓдї•еЬ®¬†The Raft Consensus Algorithm¬†жЙЊеИ∞йЭЮеЄЄе§ЪзЪДиµДжЦЩгАВ
POW(Proof-of-Work)
дЄКдЄАиКВдїЛзїНзЪДеЕ±иѓЖзЃЧж≥ХпЉМжЧ†иЃЇжШѓ Paxos ињШжШѓ Raft еЕґеЃЮйГљеП™иГљиІ£еЖ≥йЭЮжЛЬеН†еЇ≠е∞ЖеЖЫеЃєйФЩзЪДдЄАиЗіжАІйЧЃйҐШпЉМдЄНиГље§ЯеЇФеѓєеИЖеЄГеЉПзљСзїЬдЄ≠еЗЇзО∞зЪДжЮБзЂѓжГЕеЖµпЉМдљЖжШѓињЩеЬ®дЉ†зїЯзЪДеИЖеЄГеЉПз≥їзїЯйГљдЄНжШѓдїАдєИйЧЃйҐШпЉМжЧ†иЃЇжШѓеИЖеЄГеЉПжХ∞жНЃеЇУињШжШѓжґИжБѓйШЯеИЧйЫЖзЊ§пЉМеЃГдїђеЖЕйГ®зЪДиКВзВєеєґдЄНдЉЪжХЕжДПзЪДеПСйАБйФЩиѓѓдњ°жБѓпЉМеЬ®з±їдЉЉз≥їзїЯдЄ≠пЉМжЬАеЄЄиІБзЪДйЧЃйҐШе∞±жШѓиКВзº姱еОїеУНеЇФжИЦиАЕ姱жХИпЉМжЙАдї•еЃГдїђеЬ®ињЩзІНеЙНжПРдЄЛжШѓжЬЙжХИеПѓи°МзЪДпЉМдєЯжШѓеЕЕеИЖзЪДгАВ
ињЩдЄАиКВдїЛзїНзЪД¬†еЈ•дљЬйЗПиѓБжШОпЉИPOWпЉМProof-of-WorkпЉЙжШѓдЄАдЄ™зФ®дЇОйШїж≠ҐжЛТзїЭжЬНеК°жФїеЗїеТМз±їдЉЉеЮГеЬЊйВЃдїґз≠ЙжЬНеК°йФЩиѓѓйЧЃйҐШзЪДеНПиЃЃпЉМеЃГеЬ® 1993 庳襀 Cynthia Dwork еТМ Moni Naor жПРеЗЇпЉМеЃГиГље§ЯеЄЃеК©еИЖеЄГеЉПз≥їзїЯиЊЊеИ∞жЛЬеН†еЇ≠еЃєйФЩгАВ
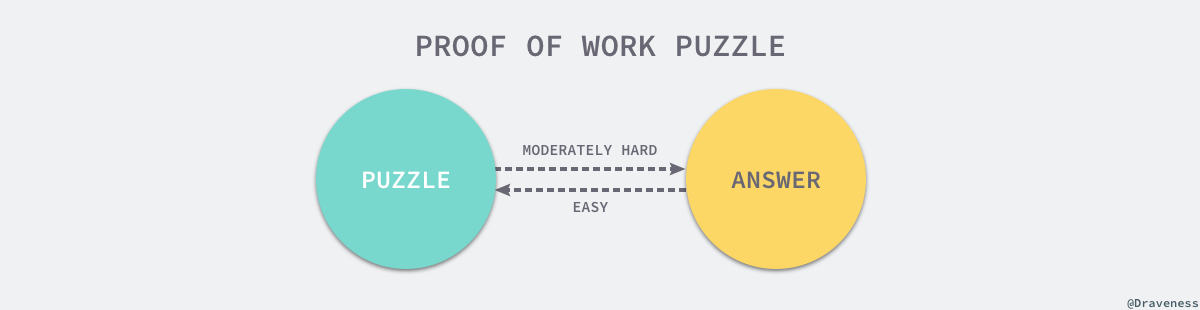
еЈ•дљЬйЗПиѓБжШОзЪДеЕ≥йФЃзЙєзВєе∞±жШѓпЉМеИЖеЄГеЉПз≥їзїЯдЄ≠зЪДиѓЈж±ВжЬНеК°зЪДиКВзВєењЕй°їиІ£еЖ≥дЄАдЄ™дЄАиИђйЪЊеЇ¶дљЖжШѓеПѓи°МпЉИfeasibleпЉЙзЪДйЧЃйҐШпЉМдљЖжШѓй™МиѓБйЧЃйҐШз≠Фж°ИзЪДињЗз®ЛеѓєдЇОжЬНеК°жПРдЊЫиАЕжЭ•иѓіеНійЭЮеЄЄеЃєжШУпЉМдєЯе∞±жШѓдЄАдЄ™дЄНеЃєжШУиІ£з≠ФдљЖжШѓеЃєжШУй™МиѓБзЪДйЧЃйҐШгАВ
ињЩзІНйЧЃйҐШйАЪеЄЄйЬАи¶БжґИиАЧдЄАеЃЪзЪД CPU жЧґйЧіжЭ•иЃ°зЃЧжЯРдЄ™йЧЃйҐШзЪДз≠Фж°ИпЉМзЫЃеЙНжЬАе§ІзЪДеМЇеЭЧйУЊзљСзїЬ - жѓФзЙєеЄБпЉИBitcoinпЉЙе∞±дљњзФ®дЇЖеЈ•дљЬйЗПиѓБжШОзЪДеИЖеЄГеЉПдЄАиЗіжАІзЃЧж≥ХпЉМзљСзїЬдЄ≠зЪДжЙАжЬЙиКВзВєиЃ°зЃЧйАЪињЗдї•дЄЛзЪДи∞ЬйҐШжЭ•иОЈеЊЧељУеЙНеМЇеЭЧзЪДиЃ∞иі¶жЭГпЉЪ
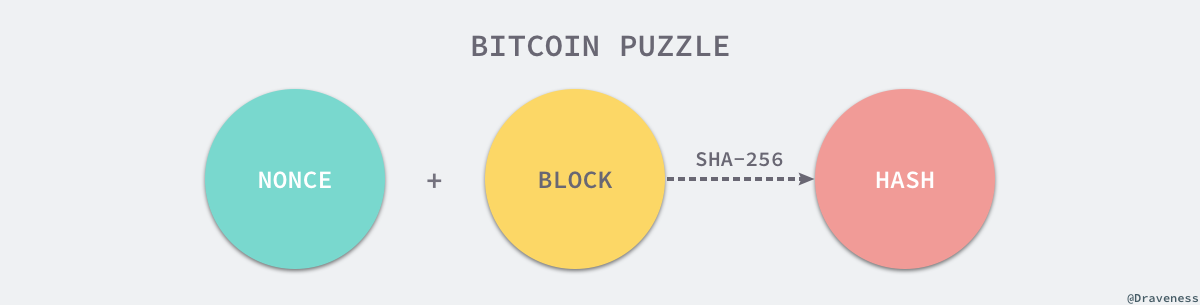
SHA-256 дљЬдЄЇдЄАдЄ™еУИеЄМеЗљжХ∞пЉМжГ≥и¶БйАЪињЗ SHA-256 еЗљжХ∞зЪДиЊУеЗЇжО®жЦ≠еЗЇиЊУеЕ•еЬ®зЫЃеЙНжЭ•зЬЛеПѓиГљжАІжШѓеПѓдї•ењљзХ•дЄНиЃ°зЪДпЉМжѓФзЙєеЄБзљСзїЬе∞±йЬАи¶БжѓПдЄАдЄ™иКВзВєдЄНжЦ≠жФєеПШ¬†NONCE¬†жЭ•еЊЧеИ∞дЄНеРМзЪДзїУжЮЬ¬†HASHпЉМе¶ВжЮЬеЊЧеИ∞зЪД HASH зїУжЮЬеЬ®е∞ПдЇОжЯРдЄ™иМГеЫіпЉМзЫЃеЙНпЉИ2017.12.17пЉЙзЪДйЪЊеЇ¶жШѓпЉЪ
0x0000000000000000000000000000000000000000000000000000017268d8a21a
дєЯе∞±жШѓе¶ВжЮЬеП™иЃ°зЃЧдЄАжђ° SHA-256 зЪДеАЉиГље§Яе∞ПдЇОдЄКињ∞зїУжЮЬзЪДеПѓиГљжАІжШѓ¬†пЉМељУеЙНзЪДеЕ®зљСзЃЧеКЫдєЯиЊЊеИ∞дЇЖ 13,919 PH/sпЉМињЩжШѓдЄАдЄ™йЭЮеЄЄжБРжАЦзЪДжХ∞е≠ЧпЉМйЪПзЭАзљСзїЬзЃЧеКЫзЪДдЄНжЦ≠жФєеПШжѓФзЙєеЄБдєЯдЉЪдЄНжЦ≠жФєеПШељУеЙНйЧЃйҐШзЪДйЪЊеЇ¶пЉМдњЭиѓБжѓПдЄ™еМЇеЭЧ襀еПСзО∞зЪДжЧґйЧіеЬ® 10min еЈ¶еП≥пЉЫеЬ®жХідЄ™жѓФзЙєеЄБзљСзїЬдЄ≠пЉМи∞БеЕИеЊЧеИ∞ељУеЙНйЧЃйҐШзЪДз≠Фж°Ие∞±иГље§ЯиОЈеЊЧињЩдЄ™еМЇеЭЧзЪДиЃ∞иі¶жЭГеєґе∞ЖељУеЙНеМЇеЭЧйАЪињЗ Gossip еНПиЃЃеПСйАБзїЩе∞љеПѓиГље§ЪзЪДжѓФзЙєеЄБиКВзВєгАВ
еЈ•дљЬйЗПиѓБжШОзЪДеОЯзРЖеЕґеЃЮйЭЮеЄЄзЃАеНХпЉМжѓФзЙєеЄБзљСзїЬйАЙжЛ©зЪДи∞ЬйҐШйЭЮеЄЄе•љзЪДйАВеЇФдЇЖеЈ•дљЬйЗПиѓБжШОеЃЪдєЙдЄ≠зЪДйЧЃйҐШпЉМжѓФиЊГйЪЊдї•еѓїжЙЊеРМжЧґеПИжШУдЇОиѓБжШОпЉМжИСдїђеПѓдї•зЃАеНХзРЖиІ£дЄЇеЈ•дљЬйЗПиѓБжШОйШ≤ж≠ҐйФЩиѓѓжИЦиАЕжЧ†жХИиѓЈж±ВзЪДеОЯзРЖе∞±жШѓеҐЮеК†еЃҐжИЈзЂѓиѓЈж±ВжЬНеК°зЪДеЈ•дљЬйЗПпЉМиАМйАВеРИйЪЊеЇ¶зЪДи∞ЬйҐШеПИиГље§ЯдњЭиѓБеРИж≥ХзЪДиѓЈж±ВдЄНдЉЪеПЧеИ∞ељ±еУНгАВ
зФ±дЇОеЈ•дљЬйЗПиѓБжШОйЬАи¶БжґИиАЧе§ІйЗПзЪДзЃЧеКЫпЉМеРМжЧґжѓФзЙєеЄБе§ІзЇ¶ 10min жЙНдЉЪдЇІзФЯдЄАдЄ™еМЇеЭЧпЉМеМЇеЭЧзЪДе§Іе∞ПдєЯеП™жЬЙ 1MBпЉМдїЕдїЕиГље§ЯеМЕеРЂ 3гАБ4000 зђФдЇ§жШУпЉМеє≥еЭЗдЄЛжЭ•жѓПзІТеП™иГље§Яе§ДзРЖ 5~7пЉИдЄ™дљНжХ∞пЉЙзђФдЇ§жШУпЉМжЙАдї•жѓФзЙєеЄБзљСзїЬзЪДж˕况зКґеЖµйЭЮеЄЄдЄ•йЗНгАВ
POS(Proof-of-Stake)
жЭГзЫКиѓБжШОжШѓеМЇеЭЧйУЊзљСзїЬдЄ≠зЪДдљњзФ®зЪДеП¶дЄАзІНеЕ±иѓЖзЃЧж≥ХпЉМеЬ®еЯЇдЇОжЭГзЫКиѓБжШОзЪДеѓЖз†БиіІеЄБдЄ≠пЉМдЄЛдЄАдЄ™еМЇеЭЧзЪДйАЙжЛ©жШѓж†єжНЃдЄНеРМиКВзВєзЪДиВ°дїљеТМжЧґйЧіињЫи°МйЪПжЬЇйАЙжЛ©зЪДгАВ
зФ±дЇОеИЫйА†жЦ∞зЪДеМЇеЭЧеєґдЄНдЉЪжґИиАЧе§ІйЗПзЪД CPUпЉМе¶ВжЮЬеЃГдЄНиѓЪеЃЮдєЯдЄНдЉЪ姱еОїдїАдєИпЉМињЩдєЯе∞±зїЩдЇЖеЊИе§ЪиКВзВєдљЬеЭПзЪДзРЖзФ±пЉМжѓПдЄАдЄ™иКВзВєдЄЇдЇЖжЬАе§ІеМЦеИ©зЫКдЉЪеЬ®е§ЪжЭ°йУЊдЄКеРМжЧґжМЦзЯњгАВ
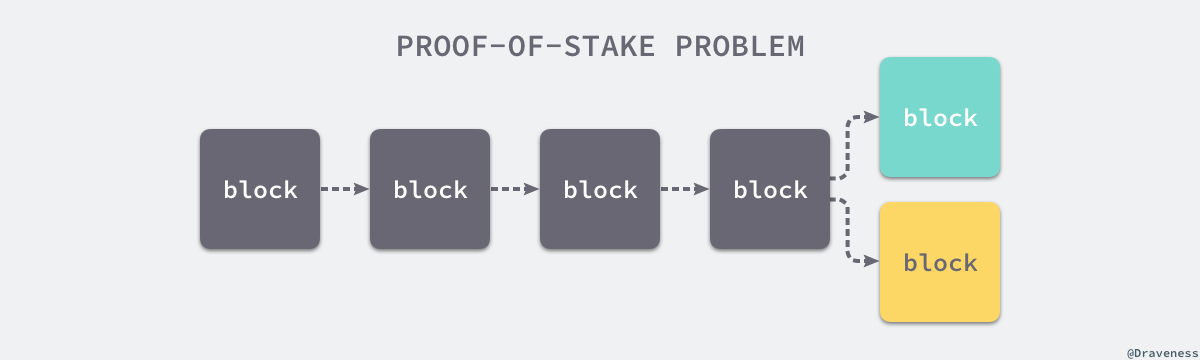
еЬ®жЧ©жЬЯзЪДжЙАжЬЙжЭГиѓБжШОзЃЧж≥ХдЄ≠пЉМжХідЄ™зљСзїЬеП™дЉЪе•ЦеК±еИЫеїЇеМЇеЭЧзЪДиКВзВєпЉМдЄНе≠ШеЬ®дїїдљХжГ©зљЪпЉМеЬ®ињЩжЧґжѓПдЄ™иКВзВєеЬ®еИЫйА†зЪДе§ЪжЭ°йУЊдЄКеРМжЧґжКХз•®жЙНиГље§ЯжЬАе§ІеМЦеИ©зЫКпЉМеЬ®ињЩзІНжГЕеЖµдЄЛзљСзїЬдЄ≠зЪДиКВзВєеЊИйЪЊеѓєдЄАжЭ°йУЊиЊЊжИРеЕ±иѓЖгАВ
жЬЙдЄ§зІНеКЮж≥ХиГље§ЯиІ£еЖ≥зЉЇдєПеИ©еЃ≥еЕ≥з≥їпЉИnothing-at-stakeпЉЙйА†жИРзЪДйЧЃйҐШпЉМдЄАзІНжШѓдљњзФ®¬†Slasher¬†еНПиЃЃпЉМжГ©зљЪеРМжЧґеЬ®е§ЪжЭ°йУЊдЄКжКХз•®зЪДиКВзВєпЉМзђђдЇМзІНжЦєж≥ХжЧґзЫіжО•жГ©зљЪеЬ®йФЩиѓѓзЪДйУЊдЄКеИЫеїЇеЭЧзЪДиКВзВєпЉМжАїиАМи®АдєЛе∞±жШѓйАЪињЗзЃЧж≥ХдєЛе§ЦзЪДдЇЛжГЕиІ£еЖ≥ињЩдЄ™йЧЃйҐШпЉМеЉХеЕ•жњАеК±еТМжГ©зљЪгАВ
дЄОеЈ•дљЬйЗПиѓБжШОзЫЄжѓФпЉМжЭГзЫКиѓБжШОдЄНйЬАи¶БжґИиАЧе§ІйЗПзЪДзФµеКЫе∞±иГље§ЯдњЭиѓБеМЇеЭЧйУЊзљСзїЬзЪДеЃЙеЕ®жАІпЉМеРМжЧґдєЯдЄНйЬАи¶БеЬ®жѓПдЄ™еМЇеЭЧдЄ≠еИЫеїЇжЦ∞зЪДиіІеЄБжЭ•жњАеК±зЯњеЈ•еПВдЄОељУеЙНзљСзїЬзЪДињРи°МпЉМињЩдєЯе∞±еЬ®дЄАеЃЪз®ЛеЇ¶дЄКзЉ©зЯ≠дЇЖиЊЊжИРеЕ±иѓЖжЙАйЬАи¶БзЪДжЧґйЧіпЉМеЯЇдЇОжЭГзЫКиѓБжШОзЪД Ethereum жѓПзІТе§Іж¶ВиГље§ДзРЖ 30 зђФдЇ§жШУеЈ¶еП≥гАВ
DPOS(Delegated Proof-of-Stake)
еЙНйЭҐдїЛзїНзЪДжЭГзЫКиѓБжШОзЃЧж≥ХеПѓдї•е∞ЖжХідЄ™еМЇеЭЧйУЊзљСзїЬзРЖиІ£дЄЇдЄАеЃґеЕђеПЄпЉМеЗЇиµДжЬАе§ЪгАБеН†жѓФжЬАе§ІзЪДдЇЇжЬЙжЫіе§ЪзЪДжЬЇдЉЪеЊЧеИ∞иѓЭиѓ≠жЭГпЉИиЃ∞иі¶жЭГпЉЙпЉЫеѓєдЇОе∞ПиВ°дЄЬжЭ•иѓіпЉМеНГеИЖдєЛеЗ†зФЪиЗ≥дЄЗеИЖдєЛеЗ†зЪДиВ°дїљеЊИйЪЊжЬЙдїАдєИдљЬдЄЇпЉМеП™иГљеЊЧеИ∞иВ°дїљеЄ¶жЭ•зЪДеИЖзЇҐеТМжФґзЫКгАВ
дљЖжШѓеЬ®ињЩйЗМдїЛзїНзЪДеІФжЙШжЭГзЫКиѓБжШОпЉИDPOSпЉМDelegated Proof-of-StakeпЉЙиГље§ЯиЃ©жѓПдЄАдЄ™дЇЇйАЙеЗЇеПѓдї•дї£и°®иЗ™еЈ±еИ©зЫКзЪДдЇЇеПВдЄОеИ∞иЃ∞иі¶жЭГзЪДдЇЙе§ЇдЄ≠пЉМињЩж†Је§ЪдЄ™е∞ПиВ°дЄЬе∞±иГље§ЯйАЪињЗжКХз•®йАЙеЗЇиЗ™еЈ±зЪДдї£зРЖдЇЇпЉМдњЭйЪЬиЗ™еЈ±зЪДеИ©зЫКгАВжХідЄ™зљСзїЬдЄ≠йАЙдЄЊеЗЇзЪДе§ЪдЄ™иКВзВєиГље§ЯеЬ® 1s дЄ≠дєЛеЖЕеѓє 99.9% зЪДдЇ§жШУињЫи°Мз°ЃиЃ§пЉМдљњзФ®еІФжЙШжЭГзЫКиѓБжШОзЪД EOS иГље§ЯжѓПзІТе§ДзРЖеЗ†еНБдЄЗзђФдЇ§жШУпЉМеРМжЧґдєЯиГље§ЯжѓФиЊГзЫСзЃ°зЪДеє≤йҐДгАВ

еЬ®еІФжЙШжЭГзЫКиѓБжШОдЄ≠пЉМжѓПдЄАдЄ™еПВдЄОиАЕйГљиГље§ЯйАЙдЄЊдїїжДПжХ∞йЗПзЪДиКВзВєзФЯжИРдЄЛдЄАдЄ™еМЇеЭЧпЉМеЊЧз•®жЬАе§ЪзЪДеЙН N дЄ™иКВзВєдЉЪ襀йАЙжЛ©жИРдЄЇеМЇеЭЧзЪДеИЫеїЇиАЕпЉМдЄЛдЄАдЄ™еМЇеЭЧзЪДеИЫеїЇиАЕе∞±дЉЪдїОињЩж†ЈдЄАзїДељУйАЙиАЕдЄ≠йЪПжЬЇйАЙеПЦпЉМйЩ§ж≠§дєЛе§ЦпЉМN зЪДжХ∞йЗПдєЯжШѓзФ±жХідЄ™зљСзїЬжКХз•®еЖ≥еЃЪзЪДпЉМжЙАдї•еПѓдї•е∞љеПѓиГљеЬ∞дњЭиѓБзљСзїЬзЪДеОїдЄ≠ењГеМЦгАВ
жАїзїУ
еЬ®ињЩзѓЗжЦЗзЂ†дЄ≠пЉМжИСдїђй¶ЦеЕИдїЛзїНдЇЖеИЖеЄГеЉПз≥їзїЯдЄ≠йЭҐеѓєзЪДжЬАйЗНи¶БйЧЃйҐШпЉМеИЖеЄГеЉПдЄАиЗіжАІпЉМйЪПеРОеПИдїЛзїНдЇЖдЇФзІНдЄНеРМзЪДеЕ±иѓЖзЃЧж≥ХпЉМдїОиІ£еЖ≥йЭЮжЛЬеН†еЇ≠йЧЃйҐШдЄЛдЄАиЗіжАІзЪД Paxos еТМ Raft еИ∞иІ£еЖ≥жЛЬеН†еЇ≠йЧЃйҐШдЄЛзЪД POWгАБPOS еТМ DPOSпЉМзЃАеНХеЫЮењЖдЄАдЄЛпЉМиІ£еЖ≥жЛЬеН†еЇ≠йЧЃйҐШзЪДе§ЪдЄ™еЕ±иѓЖзЃЧж≥ХзЪДеЃЮзО∞еПНиАМжЫіеК†зЃАеНХпЉМињЩжШѓдЄАдїґйЭЮеЄЄжЬЙжДПжАЭзЪДдЇЛжГЕгАВ
ељУжХідЄ™зљСзїЬйЬАи¶БеЃЮзО∞жЛЬеН†еЇ≠еЃєйФЩжЧґпЉМдїЕйЭ†зЃЧж≥Хз°ЃеЃЮжШѓжѓФиЊГйЪЊдї•еЃЮзО∞зЪДпЉМеЊАеЊАйГљйЬАи¶БдљњзФ®еЕґдїЦжЦєйЭҐзЪДжњАеК±жИЦиАЕжГ©зљЪпЉМиЃ©иѓЪеЃЮи°®зО∞зЪДиКВзВєеИ©зЫКжЬАе§ІеМЦжЙНжШѓиІ£еЖ≥дЄАиЗіжАІзЪДжЬАдљ≥жЦєж°ИпЉЫдїОеЈ•дљЬйЗПиѓБжШОгАБжЭГзЫКиѓБжШОеЖНеИ∞еІФжЙШжЭГзЫКиѓБжШОпЉМеЕ±иѓЖзЃЧж≥ХзЪДдЄНеРМеѓЉиЗіжАІиГљдєЯжЬЙзЭАйЭЮеЄЄе§ІзЪДеЈЃеЉВпЉМжИСдїђеПѓдї•зЬЛеИ∞йЪПзЭАзљСзїЬдЄ≠ињЫи°МгАОжКХз•®гАПзЪДиКВзВєиґКе∞СпЉМзљСзїЬзЪДе§ДзРЖиГљеКЫе∞±дЉЪиґКеЉЇеТМжАІиГље∞±дЉЪиґКењЂпЉМеІФжЙШжЭГзЫКиѓБжШОйАЙдЄЊдЇЖ N дЄ™иКВзВєжЭ•дњЭиѓБжАІиГљеТМеОїдЄ≠ењГеМЦз®ЛеЇ¶з°ЃеЃЮжШѓдЄАдїґйЭЮеЄЄиБ™жШОзЪДдЇЛжГЕгАВ
дЄ≠ењГеМЦзЪДзљСзїЬз°ЃеЃЮиГље§ЯеЄ¶жЭ•жАІиГљзЪДжПРеНЗпЉМдљЖжШѓеЬ®еѓЖз†БиіІеЄБдЄ≠пЉМеПВдЄОиАЕеЊАеЊАжЫізЫЄдњ°еОїдЄ≠ењГеМЦзЪДжЬЇеИґпЉМеЫ†дЄЇж≤°жЬЙжњАеК±еТМжГ©зљЪжИСдїђеєґдЄНиГљдњЭиѓБдЄЛдЄАдЄ™иіЯиі£иЃ∞иі¶зЪДиКВзВєжШѓеР¶жШѓиѓЪеЃЮзЪДпЉМзФ±ж≠§жЭ•зЬЛпЉМе¶ВдљХеЬ®дњЭиѓБеОїдЄ≠ењГеМЦзЪДеРМжЧґжПРеНЗзљСзїЬзЪДжАІиГљжШѓжѓПдЄАдЄ™еМЇеЭЧйУЊзљСзїЬйГљйЬАи¶БиАГиЩСзЪДдЇЛжГЕгАВ
Reference
- Consensus (computer science)
- еМЇеЭЧйУЊеЕ±иѓЖзЃЧж≥ХпЉИPOW,POS,DPOS,PBFTпЉЙдїЛзїНеТМењГеЊЧ
- Paxos дЄО Raft
- Proof-of-work system
- Proof-of-stake
- Proof of Stake FAQ ¬Ј Ethereum Wiki
- Delegated Proof of Stake
- Delegated Proof-of-Stake Consensus
- DPOSеЕ±иѓЖзЃЧж≥Х вАУ зЉЇе§±зЪДзЩљзЪЃдє¶
- еЕ±иѓЖзЃЧж≥Х
- CAP theorem
- Paxos Made Simple
- The Raft Consensus Algorithm
- In Search of an Understandable Consensus Algorithm
- и∞Ии∞И paxos, multi-paxos, raft
- BrewerвАЩs Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services
- вАЬEventual ConsistencyвАЭ vs вАЬStrong Eventual ConsistencyвАЭ vs вАЬStrong ConsistencyвАЭ?
- Impossibility of Distributed Consensuswith One Faulty Process
- The Byzantine Generals Problem
- Byzantine fault tolerance
- A Brief Tour of FLP Impossibility
- Paxos Made Simple
- Neat Algorithms - Paxos
- FLP Impossibility зЪДиѓБжШО
- зЩљиѓЭеМЇеЭЧйУЊ
- Paxos
- Paxos lecture (Raft user study)
- Bitcoin: A Peer-to-Peer Electronic Cash System
- Proof of Stake ¬Ј Bitcoin Wiki
- Slasher
- Proof of Stake FAQ
relпЉЪ¬†https://draveness.me/consensus



зЫЄеЕ≥жО®иНР
PaxosжШѓдЄАзІНеЯЇдЇОеЕ±иѓЖзЪДеИЖеЄГеЉПдЄАиЗіжАІзЃЧж≥ХпЉМзФ±Leslie LamportжПРеЗЇгАВеЃГзЪДзЫЃж†ЗжШѓеЬ®дЄАзїДеПѓиГљеЗЇйФЩзЪДиКВзВєдЄ≠иЊЊжИРдЄАиЗізЪДеЖ≥еЃЪгАВPaxosзЪДж†ЄењГжАЭжГ≥жШѓйАЪињЗжПРж°ИиАЕгАБжО•еПЧиАЕеТМе≠¶дє†иАЕзЪДиІТиЙ≤еНПдљЬпЉМдњЭиѓБеП™жЬЙдЄАдЄ™жПРж°И襀жО•еПЧгАВеЃГиІ£еЖ≥дЇЖеЬ®...
ж†єжНЃжПРдЊЫзЪДжЦЗж°£дњ°жБѓпЉМжЬђжЦЗе∞ЖеѓєвАЬеИЖеЄГеЉПдЄАиЗіжАІзЃЧж≥ХYacвАЭињЫи°МжЈ±еЕ•иІ£иѓїпЉМжПРзВЉеЗЇеЕ≥йФЃзЪДзЯ•иѓЖзВєгАВ ### еИЖеЄГеЉПдЄАиЗіжАІзЃЧж≥ХYacж¶Вињ∞ #### 1. з†Фз©ґиГМжЩѓдЄОеК®жЬЇ еЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠пЉМдЄАиЗіжАІзЃЧж≥ХжШѓеЃЮзО∞иКВзВєйЧіжХ∞жНЃеРМж≠•зЪДеЯЇз°АгАВдЉ†зїЯзЪД...
иѓізЪДзЃАеНХжШОдЇЖдїЦдїђиѓідљ†жШѓж≥Ыж≥ЫиАМи∞ИпЉМзЃЧж≥ХињЩдЄЬи•њжШѓиЃ≤жШОзЩљзЪДеРЧпЉЯиЗ™еЈ±дЄНеК®жЙЛеЕЙжГ≥еРђеИЂдЇЇ...2000еєіпЉМEric BrewerжХЩжОИеЬ®ACMеИЖеЄГеЉПиЃ°зЃЧеєідЉЪдЄКжМЗеЗЇдЇЖиСЧеРНзЪДCAPзРЖиЃЇпЉЪеИЖеЄГеЉПз≥їзїЯдЄНеПѓиГљеРМжЧґжї°иґ≥дЄАиЗіжАІ(Consistency)пЉМеПѓзФ®жАІ(Availa
гАКдїОPaxosеИ∞ZookeeperеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµгАЛжШѓдЄАжЬђжЈ±еЕ•жОҐиЃ®еИЖеЄГеЉПз≥їзїЯдЄАиЗіжАІйЧЃйҐШзЪДиСЧдљЬпЉМеЕґдЄ≠йЗНзВєиЃ≤иІ£дЇЖPaxosзЃЧж≥ХдЄОZookeeperеЬ®еЃЮйЩЕеЇФзФ®дЄ≠зЪДзРЖиЃЇдЄОеЃЮиЈµгАВPaxosжШѓеИЖеЄГеЉПиЃ°зЃЧйҐЖеЯЯдЄ≠иСЧеРНзЪДеЕ±иѓЖзЃЧж≥ХпЉМдЄЇиІ£еЖ≥еИЖеЄГеЉП...
жЬђдє¶гАКдїОPAXOSеИ∞ZOOKEEPERеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµгАЛе∞ЖеЄ¶йҐЖиѓїиАЕдїОзРЖиЃЇеЯЇз°АеЗЇеПСпЉМйАРж≠•иІ£жЮРPAXOSзЃЧж≥ХзЪДеОЯзРЖпЉМзДґеРОжЈ±еЕ•еИ∞ZOOKEEPERзЪДеЃЮйЩЕеЇФзФ®пЉМеЄЃеК©иѓїиАЕжОМжП°еИЖеЄГеЉПдЄАиЗіжАІиЃЊиЃ°дЄОеЃЮзО∞зЪДеЕ≥йФЃжКАжЬѓгАВйАЪињЗеѓєдє¶дЄ≠еЖЕеЃєзЪДжЈ±еЕ•е≠¶дє†...
гАКPaxosеИ∞ZookeeperвАФвАФеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµгАЛжШѓдЄАжЬђжЈ±еЕ•жОҐиЃ®еИЖеЄГеЉПдЄАиЗіжАІйЧЃйҐШзЪДдє¶з±НпЉМеѓєдЇОзРЖиІ£еєґеЇФзФ®ZookeeperињЩдЄАеЕ≥йФЃзЪДеИЖеЄГеЉПеНПи∞Гз≥їзїЯеЕЈжЬЙйЗНи¶БдїЈеАЉгАВжЬђдє¶жЧ®еЬ®еЄЃеК©иѓїиАЕжОМжП°еИЖеЄГеЉПзОѓеҐГдЄ≠зЪДжХ∞жНЃдЄАиЗіжАІеОЯзРЖпЉМеєґ...
гАКдїОPAXOSеИ∞ZOOKEEPERеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµгАЛжШѓдЄАжЬђжЈ±еЕ•жОҐиЃ®еИЖеЄГеЉПз≥їзїЯж†ЄењГж¶ВењµзЪДдє¶з±НпЉМе∞§еЕґеЕ≥ж≥®еЬ®еИЖеЄГеЉПзОѓеҐГдЄ≠е¶ВдљХеЃЮзО∞жХ∞жНЃзЪДдЄАиЗіжАІгАВPAXOSзЃЧж≥ХжШѓеИЖеЄГеЉПиЃ°зЃЧйҐЖеЯЯзЪДдЄАдЄ™йЗМз®ЛзҐСпЉМеЃГдЄЇиІ£еЖ≥еИЖеЄГеЉПз≥їзїЯдЄ≠зЪДеЕ±иѓЖйЧЃйҐШ...
гАКдїОPaxosеИ∞ZookeeperеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµгАЛдЄОгАКZooKeeper-еИЖеЄГеЉПињЗз®ЛеНПеРМжКАжЬѓиѓ¶иІ£гАЛињЩдЄ§жЬђдє¶жЈ±еЕ•жОҐиЃ®дЇЖеИЖеЄГеЉПз≥їзїЯдЄ≠зЪДдЄАдЄ™йЗНи¶Бж¶ВењµвАФвАФдЄАиЗіжАІпЉМдї•еПКе¶ВдљХйАЪињЗZooKeeperињЩдЄАеЈ•еЕЈжЭ•еЃЮзО∞йЂШжХИзЪДеИЖеЄГеЉПеНПеРМгАВ...
еЬ®з†Фз©ґеИЖеЄГеЉПз≥їзїЯйҐЖеЯЯдЄ≠пЉМеИЖеЄГеЉПдЄАиЗіжАІзКґжАБдЉ∞иЃ°зЃЧж≥ХжШѓз°ЃдњЭзљСзїЬдЄ≠еРДдЄ™иКВзВєиГље§ЯеНПеРМеЈ•дљЬеєґжЬАзїИиЊЊжИРеѓєжЯРдЄАзКґжАБзЪДеЕ±иѓЖзЪДеЕ≥йФЃжКАжЬѓгАВжЬђжЦЗжЈ±еЕ•жОҐиЃ®дЇЖеЬ®йЭЮеЭЗеМАжЛУжЙСзљСзїЬзОѓеҐГдЄЛпЉМе¶ВдљХйЂШжХИеЬ∞еЃЮзО∞еИЖеЄГеЉПдЄАиЗіжАІзКґжАБдЉ∞иЃ°пЉМжПРеЗЇдЇЖеЫЫ...
ж≠§е§ЦпЉМдє¶дЄ≠еПѓиГљињШдЉЪиЃ®иЃЇZookeeperдЄОеЕґдїЦеИЖеЄГеЉПдЄАиЗіжАІиІ£еЖ≥жЦєж°ИпЉМе¶ВRaftзЃЧж≥ХгАБChubbyжЬНеК°з≠ЙзЪДеѓєжѓФпЉМеЄЃеК©иѓїиАЕжЫіеЕ®йЭҐеЬ∞зРЖиІ£еРДзІНжКАжЬѓзЪДдЉШзЉЇзВєгАВ жАїзЪДжЭ•иѓіпЉМгАКдїОPaxosеИ∞ZookeeperгАЛжШѓдЄАжЬђжЈ±еЕ•дЇЖиІ£еИЖеЄГеЉПдЄАиЗіжАІзРЖиЃЇдЄОеЃЮиЈµ...
гАКдїОPAXOSеИ∞ZOOKEEPERеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµ.pdfгАЛињЩдїљжЦЗж°£пЉМеЊИеПѓиГљдЉЪжЈ±еЕ•иІ£жЮРPAXOSзЃЧж≥ХзЪДеОЯзРЖпЉМеМЕжЛђеЕґеЯЇжЬђж®°еЮЛгАБжґИжБѓдЇ§жНҐињЗз®Лдї•еПКеРДзІНеПШзІНпЉМжѓФе¶ВMulti-PAXOSгАВеРМжЧґпЉМеЃГдЉЪиѓ¶зїЖдїЛзїНZOOKEEPERзЪДжЮґжЮДиЃЊиЃ°гАБAPIдљњзФ®дї•еПК...
гАКдїОPAXOSеИ∞ZOOKEEPERеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµгАЛжШѓдЄАжЬђжЈ±еЕ•жОҐиЃ®еИЖеЄГеЉПз≥їзїЯдЄ≠дЄАиЗіжАІйЧЃйҐШзЪДйЗНи¶Бдє¶з±НгАВеЬ®еИЖеЄГеЉПиЃ°зЃЧйҐЖеЯЯпЉМдЄАиЗіжАІжШѓз°ЃдњЭе§ЪдЄ™иКВзВєйЧіжХ∞жНЃеРМж≠•зЪДеЕ≥йФЃзЙєжАІпЉМеЃГеѓєдЇОжЮДеїЇеПѓйЭ†гАБйЂШеПѓзФ®зЪДз≥їзїЯиЗ≥еЕ≥йЗНи¶БгАВињЩжЬђдє¶дЄїи¶Б...
PaxosзЃЧж≥ХжШѓLeslie LamportжПРеЗЇзЪДдЄАзІНеИЖеЄГеЉПдЄАиЗіжАІеНПиЃЃпЉМжЧ®еЬ®иІ£еЖ≥еЬ®дЄНеПѓйЭ†зљСзїЬзОѓеҐГдЄ≠иЊЊжИРеЕ±иѓЖзЪДйЧЃйҐШгАВPaxosзЪДж†ЄењГжАЭжГ≥жШѓйАЪињЗжПРж°ИгАБжО•еПЧеТМеЖ≥еЃЪдЄЙдЄ™йШґжЃµжЭ•з°ЃдњЭйЫЖзЊ§дЄ≠е§ЪжХ∞иКВзВєеѓєжЯРдЄ™еАЉиЊЊжИРдЄАиЗігАВињЩдЄ™ињЗз®ЛжґЙеПКжПРиЃЃиАЕгАБ...
гАКдїОPaxosеИ∞ZookeeperпЉЪеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµгАЛињЩжЬђдє¶жЈ±еЕ•жОҐиЃ®дЇЖеИЖеЄГеЉПз≥їзїЯдЄ≠иЗ≥еЕ≥йЗНи¶БзЪДвАЬдЄАиЗіжАІвАЭйЧЃйҐШгАВеЬ®ељУдїКе§ІжХ∞жНЃеТМдЇСиЃ°зЃЧзЪДжЧґдї£иГМжЩѓдЄЛпЉМеИЖеЄГеЉПдЄАиЗіжАІжШѓжЮДеїЇйЂШеПѓзФ®гАБйЂШжАІиГљжЬНеК°зЪДеЯЇз°АпЉМдєЯжШѓиЃЄе§Ъе§ІеЮЛдЇТиБФзљСеЕђеПЄ...
гАКдїОPAXOSеИ∞ZOOKEEPERеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµгАЛжШѓдЄАжЬђжЈ±еЕ•жОҐиЃ®еИЖеЄГеЉПз≥їзїЯдЄАиЗіжАІйЧЃйҐШзЪДдє¶з±НпЉМеЕґдЄ≠жЇРз†БйГ®еИЖеѓєдЇОзРЖиІ£ZOOKEEPERе¶ВдљХеЃЮзО∞еИЖеЄГеЉПдЄАиЗіжАІеЕЈжЬЙжЮБйЂШзЪДдїЈеАЉгАВPAXOSзЃЧж≥ХжШѓеИЖеЄГеЉПиЃ°зЃЧйҐЖеЯЯзЪДдЄАдЄ™йЗМз®ЛзҐСпЉМеЃГдЄЇиІ£еЖ≥...
### еИЖеЄГеЉПжХ∞жНЃеЇУдЄАиЗіжАІдњЭиѓБзЃЧж≥Х ...еРМжЧґпЉМPaxosзЃЧж≥ХеТМRaftзЃЧж≥ХдљЬдЄЇдЄ§зІНдЄїжµБзЪДеИЖеЄГеЉПдЄАиЗіжАІзЃЧж≥ХпЉМеЬ®еЃЮйЩЕеЇФзФ®дЄ≠жЬЙзЭАеєњж≥ЫзЪДеЇФзФ®гАВзРЖиІ£еєґжОМжП°ињЩдЇЫзЃЧж≥ХзЪДеЈ•дљЬеОЯзРЖеТМеЇФзФ®еЬЇжЩѓпЉМеѓєдЇОеИЖеЄГеЉПз≥їзїЯзЪДиЃЊиЃ°еТМеЉАеПСеЕЈжЬЙйЗНи¶БзЪДжДПдєЙгАВ
йАЪињЗиѓѓеЈЃзЯ©йШµзЪДеК†жЭГжЫіжЦ∞пЉМдїЦдїђжФєињЫдЇЖеЕ±иѓЖзЃЧж≥ХпЉМдљњеЊЧеЬ®зљСзїЬеК®жАБеПШеМЦзЪДжГЕеЖµдЄЛпЉМиКВзВєзКґжАБзЪДдЄАиЗіжАІеЊЧдї•дњЭжМБгАВињЩзІНжЦєж≥ХеЕБиЃЄзљСзїЬдЄ≠зЪДжѓПдЄ™иКВзВєзЛђзЂЛеЬ∞ињЫи°МзКґжАБдЉ∞иЃ°пЉМеРМжЧґињШиГљдЄОеЕґдїЦиКВзВєдњЭжМБдЄАиЗізЪДзїУжЮЬпЉМеН≥дљњж≤°жЬЙдЄ≠ењГиКВзВєзЪД...
зРЖиІ£PaxosзЃЧж≥ХеПѓдї•еЄЃеК©жИСдїђжЈ±еЕ•зРЖиІ£еИЖеЄГеЉПдЄАиЗіжАІиГМеРОзЪДзРЖиЃЇпЉМиАМZookeeperеИЩдЄЇжИСдїђжПРдЊЫдЇЖеЃЮзО∞ињЩдЇЫзРЖиЃЇзЪДеЃЮзФ®еЈ•еЕЈгАВдїОPaxosеИ∞ZookeeperпЉМињЩдЄНдїЕжШѓзРЖиЃЇеИ∞еЃЮиЈµзЪДиЈ®иґКпЉМдєЯжШѓиІ£еЖ≥еИЖеЄГеЉПз≥їзїЯдЄАиЗіжАІйЧЃйҐШзЪДеЕ≥йФЃж≠•й™§гАВйАЪињЗжЈ±еЕ•...
жАїзЪДжЭ•иѓіпЉМгАКдїОPaxosеИ∞ZookeeperеИЖеЄГеЉПдЄАиЗіжАІеОЯзРЖдЄОеЃЮиЈµгАЛињЩжЬђдє¶еЕ®йЭҐдїЛзїНдЇЖеИЖеЄГеЉПдЄАиЗіжАІйЧЃйҐШпЉМдїОзРЖиЃЇеЯЇз°АPaxosзЃЧж≥ХеИ∞еЃЮйЩЕеЇФзФ®ZookeeperпЉМжЈ±еЕ•жµЕеЗЇеЬ∞иЃ≤иІ£дЇЖе¶ВдљХеЬ®е§НжЭВеИЖеЄГеЉПзОѓеҐГдЄ≠дњЭиѓБжХ∞жНЃдЄАиЗіжАІгАВжЧ†иЃЇжШѓеѓєдЇОеИЭе≠¶иАЕ...