
Kafka 是高吞吐低延迟的高并发、高性能的消息中间件,在大数据领域有极为广泛的运用。配置良好的 Kafka 集群甚至可以做到每秒几十万、上百万的超高并发写入。
那么 Kafka 到底是如何做到这么高的吞吐量和性能的呢?这篇文章我们来详细说一下。
页缓存技术 + 磁盘顺序写
首先 Kafka 每次接收到数据都会往磁盘上去写,如下图所示:
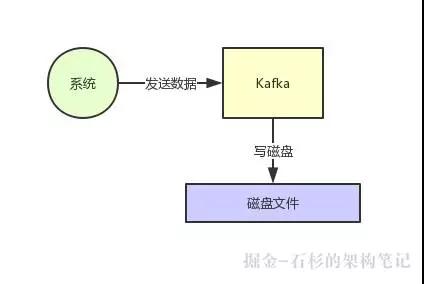
那么在这里我们不禁有一个疑问了,如果把数据基于磁盘来存储,频繁的往磁盘文件里写数据,这个性能会不会很差?大家肯定都觉得磁盘写性能是极差的。
没错,要是真的跟上面那个图那么简单的话,那确实这个性能是比较差的。
但是实际上 Kafka 在这里有极为优秀和出色的设计,就是为了保证数据写入性能,首先 Kafka 是基于操作系统的页缓存来实现文件写入的。
操作系统本身有一层缓存,叫做 Page Cache,是在内存里的缓存,我们也可以称之为 OS Cache,意思就是操作系统自己管理的缓存。
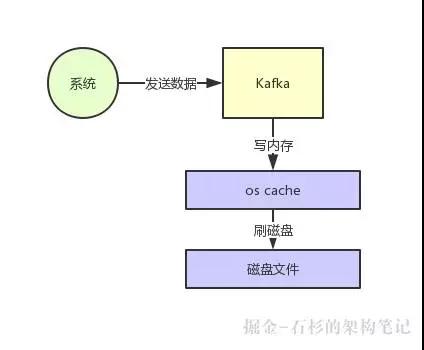
你在写入磁盘文件的时候,可以直接写入这个 OS Cache 里,也就是仅仅写入内存中,接下来由操作系统自己决定什么时候把 OS Cache 里的数据真的刷入磁盘文件中。
仅仅这一个步骤,就可以将磁盘文件写性能提升很多了,因为其实这里相当于是在写内存,不是在写磁盘,大家看下图:
接着另外一个就是 kafka 写数据的时候,非常关键的一点,它是以磁盘顺序写的方式来写的。
也就是说,仅仅将数据追加到文件的末尾,不是在文件的随机位置来修改数据。
普通的机械磁盘如果你要是随机写的话,确实性能极差,也就是随便找到文件的某个位置来写数据。
但是如果你是追加文件末尾按照顺序的方式来写数据的话,那么这种磁盘顺序写的性能基本上可以跟写内存的性能本身也是差不多的。
所以大家就知道了,上面那个图里,Kafka 在写数据的时候,一方面基于 OS 层面的 Page Cache 来写数据,所以性能很高,本质就是在写内存罢了。
另外一个,它是采用磁盘顺序写的方式,所以即使数据刷入磁盘的时候,性能也是极高的,也跟写内存是差不多的。
基于上面两点,Kafka 就实现了写入数据的超高性能。那么大家想想,假如说 Kafka 写入一条数据要耗费 1 毫秒的时间,那么是不是每秒就是可以写入 1000 条数据?
但是假如 Kafka 的性能极高,写入一条数据仅仅耗费 0.01 毫秒呢?那么每秒是不是就可以写入 10 万条数据?
所以要保证每秒写入几万甚至几十万条数据的核心点,就是尽最大可能提升每条数据写入的性能,这样就可以在单位时间内写入更多的数据量,提升吞吐量。
零拷贝技术
说完了写入这块,再来谈谈消费这块。
大家应该都知道,从 Kafka 里我们经常要消费数据,那么消费的时候实际上就是要从 Kafka 的磁盘文件里读取某条数据然后发送给下游的消费者,如下图所示:
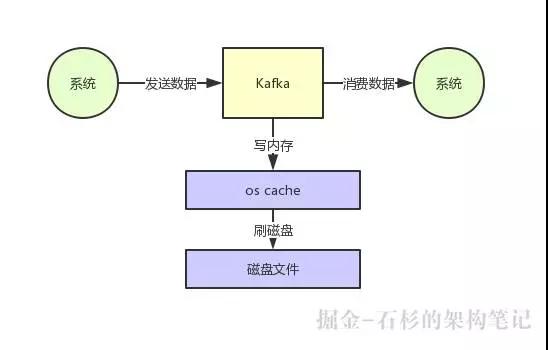
那么这里如果频繁的从磁盘读数据然后发给消费者,性能瓶颈在哪里呢?
假设要是 Kafka 什么优化都不做,就是很简单的从磁盘读数据发送给下游的消费者,那么大概过程如下所示:
- 先看看要读的数据在不在 OS Cache 里,如果不在的话就从磁盘文件里读取数据后放入 OS Cache。
- 接着从操作系统的 OS Cache 里拷贝数据到应用程序进程的缓存里,再从应用程序进程的缓存里拷贝数据到操作系统层面的 Socket 缓存里。
- 最后从 Socket 缓存里提取数据后发送到网卡,最后发送出去给下游消费。
整个过程,如下图所示:
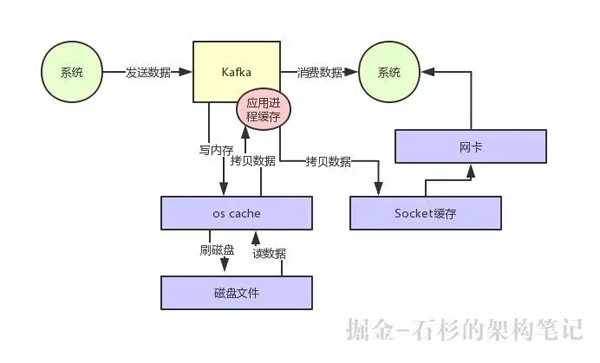
大家看上图,很明显可以看到有两次没必要的拷贝吧!一次是从操作系统的 Cache 里拷贝到应用进程的缓存里,接着又从应用程序缓存里拷贝回操作系统的 Socket 缓存里。
而且为了进行这两次拷贝,中间还发生了好几次上下文切换,一会儿是应用程序在执行,一会儿上下文切换到操作系统来执行。
所以这种方式来读取数据是比较消耗性能的。Kafka 为了解决这个问题,在读数据的时候是引入零拷贝技术。
也就是说,直接让操作系统的 Cache 中的数据发送到网卡后传输给下游的消费者,中间跳过了两次拷贝数据的步骤,Socket 缓存中仅仅会拷贝一个描述符过去,不会拷贝数据到 Socket 缓存。
大家看下图,体会一下这个精妙的过程:

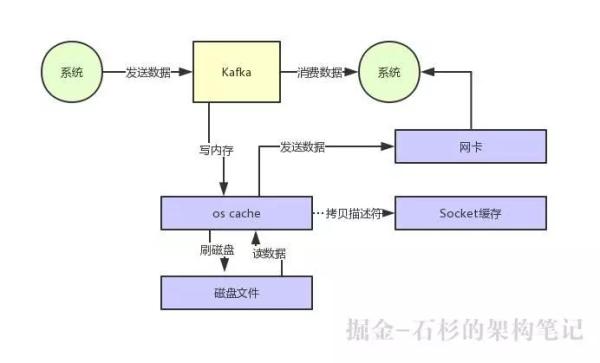
通过零拷贝技术,就不需要把 OS Cache 里的数据拷贝到应用缓存,再从应用缓存拷贝到 Socket 缓存了,两次拷贝都省略了,所以叫做零拷贝。
对 Socket 缓存仅仅就是拷贝数据的描述符过去,然后数据就直接从 OS Cache 中发送到网卡上去了,这个过程大大的提升了数据消费时读取文件数据的性能。
而且大家会注意到,在从磁盘读数据的时候,会先看看 OS Cache 内存中是否有,如果有的话,其实读数据都是直接读内存的。
如果 Kafka 集群经过良好的调优,大家会发现大量的数据都是直接写入 OS Cache 中,然后读数据的时候也是从 OS Cache 中读。
相当于是 Kafka 完全基于内存提供数据的写和读了,所以这个整体性能会极其的高。
说个题外话,下回有机会给大家说一下 Elasticsearch 的架构原理,其实 ES 底层也是大量基于 OS Cache 实现了海量数据的高性能检索的,跟 Kafka 原理类似。
总结
通过这篇文章对 Kafka 底层的页缓存技术的使用,磁盘顺序写的思路,以及零拷贝技术的运用,大家应该就明白 Kafka 每台机器在底层对数据进行写和读的时候采取的是什么样的思路,为什么它的性能可以那么高,做到每秒几十万的吞吐量。



相关推荐
标题"使用netty实现TCP长链接消息写入kafka以及kafka批量消费数据"揭示了这个项目的核心内容:通过Netty接收TCP长连接的数据,并将这些数据存储到Kafka中,同时利用Kafka的批量消费功能对数据进行处理。下面我们将...
- **Partition**: 分区是 Topic 的逻辑细分,每个分区在物理上存储在一个或多个 Broker 上,确保数据的并行处理。 - **Producer**: 生产者是向 Kafka 发送数据的应用程序,它可以将数据发布到特定的 Topic。 - **...
kafka使用kafka实现的项目代码.zip使用kafka实现的项目代码.zip使用kafka实现的项目代码.zip使用kafka实现的项目代码.zip使用kafka实现的项目代码.zip使用kafka实现的项目代码.zip使用kafka实现的项目代码.zip使用...
接下来,我们要介绍如何配置Logback来写入Kafka。Kafka是一个分布式流处理平台,可以作为消息中间件,用于实时数据流处理和存储。KafkaAppender是Logback的一个扩展,它实现了将日志事件发送到Kafka的功能。以下是一...
【KAFKA:如何做到1秒发布百万级条消息1】 KAFKA是一个分布式发布-订阅消息系统,设计用于处理大量的实时数据流。其高吞吐量性能是其核心优势,能够在一个普通的虚拟机上每秒处理数十万条消息,即使在内存和CPU资源...
kafka 线上会遇到哪些问题?kafka 线上会遇到哪些问题?kafka 线上会遇到哪些问题?kafka 线上会遇到哪些问题?kafka 线上会遇到哪些问题?kafka 线上会遇到哪些问题?kafka 线上会遇到哪些问题?kafka 线上会遇到...
使用kafka实现的java版时间轮.zip使用kafka实现的java版时间轮.zip使用kafka实现的java版时间轮.zip使用kafka实现的java版时间轮.zip使用kafka实现的java版时间轮.zip使用kafka实现的java版时间轮.zip使用kafka实现...
综上所述,这个压缩包提供的源码展示了如何使用Apache Flink实现实时从Kafka读取数据,基于定时或数量条件进行聚合,最后将结果存入MySQL数据库。同时,还包括了Kafka和Zookeeper的安装包,便于用户搭建完整的实时...
本示例中,我们探讨的主题是如何利用Apache Flink进行并发消费Kafka数据,并将处理结果写入Hadoop Distributed File System(HDFS)。Flink是一个强大的流处理框架,而Kafka是一个高效的分布式消息中间件,HDFS则是...
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒;可扩展性:kafka集群支持热扩展;持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;容错性:允许集群中节点故障...
本文是系列文章的第4篇,第一篇"第二篇第三篇第四篇第五篇第六篇《Kafka设计解析》系列上一篇《Kafka高性能架构之道——Kafka设计解析(六)》从宏观架构到具体实现分析了Kafka实现高性能的原理。本文介绍了Kafka...
6. **高吞吐量**:Kafka设计的目标是处理大规模的数据流,因此它优化了网络I/O和磁盘I/O,可以实现每秒数十万条消息的处理速度。 7. **连接器(Connectors)和流处理(Kafka Streams)**:Kafka Connect允许用户...
本项目涉及到一个用Go编写的程序,它实现了从Apache Kafka主题中读取数据,并将这些数据写入Elasticsearch集群。Kafka是一个分布式流处理平台,而Elasticsearch则是一种流行的全文搜索引擎和实时数据分析工具。接...
"大话务并发数据流吞吐系统设计" 一、系统背景 在中国电信股份有限公司上海分公司,统一消息推送平台的数据吞吐量较低,无法满足新的业务需求。为了解决这个问题,需要设计一个高吞吐量的大话务并发数据流系统。 ...
### Kylin与Kafka结合实现流式报表计算 #### 一、引言 在大数据处理领域,实时数据处理越来越受到重视。随着业务的发展和技术的进步,企业对于数据分析的需求也在不断升级,传统的批处理方式已无法满足现代业务...
在Kafka中,Topic由多个Partition组成,每个Partition又分布在不同的Broker上。因此,迁移Topic实质上是迁移其所有的Partition。为了实现自动化,我们通常会编写脚本,包括以下步骤: 1. **准备目标集群**:确认...
消费kafka数据,然后批量导入到Elasticsearch,本例子使用的kafka版本0.10,es版本是6.4,使用bulk方式批量导入到es中,也可以一条一条的导入,不过比较慢。 <groupId>org.elasticsearch <artifactId>elastic...
**Kafka、Spark Streaming与HBase的集成** 在大数据处理领域,Kafka作为一个高吞吐量的分布式消息系统,常用于实时数据流处理;Spark Streaming则提供了基于微批处理的实时计算框架,能够高效地处理持续的数据流;...
每个分区都有一个主副本和多个备份副本,分布在不同的broker上。如果主副本失败,其中一个备份会自动接管。此外,Kafka还支持位移管理,消费者可以保存自己的消费位置,即使崩溃后也能恢复。 **7. 消息保留策略** ...
- 启动Kafka Connect服务,它会读取配置文件,并开始将Kafka中的数据写入MySQL。 5. **监控和管理** - 通过Kafka Connect REST API或Confluent Control Center(如果使用了Confluent Platform)来监控数据迁移...