原帖地址:http://www.aboutyun.com/thread-5641-1-1.html
您还没有登录,请您登录后再发表评论
官方MapReduce运行机制动画图,详细描述Job的提交流程
在MapReduce的工作流程中,Shuffle机制扮演着至关重要的角色,它确保了数据在传递到Reducer阶段之前被正确地分区和排序。本文将深入探讨MapReduce的Shuffle机制,并讨论如何通过自定义Partitioner来满足特定的业务...
### MapReduce工作原理详解 #### 一、MapReduce概述与特性 MapReduce是一种分布式计算模型,主要用于处理大规模数据集。该技术由Google首先提出,并在Hadoop中得到了广泛应用。MapReduce的基本思想是将大规模的...
4. **容错机制**:MapReduce也内置了容错机制,如果某个Map或Reduce任务失败,系统会重新调度任务。 通过HDFS和MapReduce的协同工作,Hadoop能够处理PB级别的数据,广泛应用于数据分析、日志处理、推荐系统、机器...
- **容错性**:MapReduce框架内置了容错机制,当某个任务失败时,框架会自动重试该任务,确保数据处理的完整性。 #### 六、MapReduce的限制 尽管MapReduce是一种强大的数据处理模型,但它也有一定的局限性: - **...
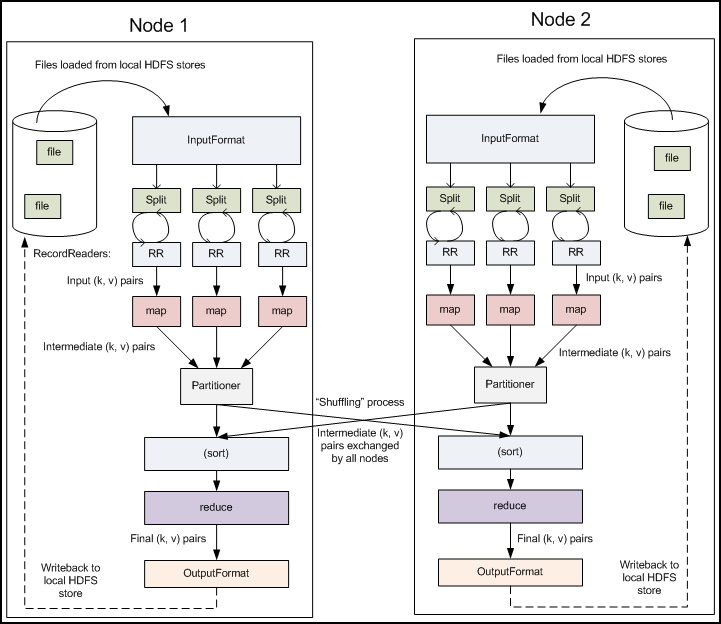
在整个MapReduce过程中,涉及到了多个组件,包括HDFS、DataNode、inputformat等。HDFS是MapReduce运行的基础,提供了数据存储功能。DataNode是HDFS的组成部分,负责存储数据。inputformat负责定义数据如何被切割成...
运行结果可以通过Hadoop的Web界面查看,这有助于理解MapReduce的工作流程。 在MapReduce Web界面上,可以监控作业的进度、任务分布以及资源使用情况。此外,通过Shell命令如`mapred job -status id`,可以在运行...
#### 二、MapReduce的工作机制 1. **文件切片**:在MapReduce任务启动之前,首先对输入文件进行逻辑上的切片处理。每个切片对应一个独立的Map任务。切片的大小默认与HDFS块大小一致,但可以通过配置调整。 2. **Map...
MapReduce是一种分布式计算模型,由Google开发,用于处理和生成大量数据。这个模型主要由两个主要阶段组成:Map(映射)和Reduce(规约)。MapReduce的核心思想是将复杂的大规模数据处理任务分解成一系列可并行执行...
通过理解并动手实现这个框架,开发者不仅可以深入理解MapReduce的工作机制,还能掌握如何在实际项目中应用分布式计算解决大数据问题。对于那些关注人工智能和大数据处理的开发者,这将是一次宝贵的实践经历。
总之,MapReduce不仅仅是一项技术革新,它代表了一种思维方式的转变,即将复杂的大数据处理问题分解为可管理的小任务,再通过并行计算来加速整个过程。这一理念在当今的大数据时代依然具有重要意义,启发了后续众多...
#### 二、MapReduce的工作原理 MapReduce的基本思想是将大规模的数据集分割成较小的部分,通过并行处理的方式在多台计算机上进行计算。整个计算过程可以分为两个主要阶段:**Map** 和 **Reduce** 阶段。 1. **Map...
01.mapreduce分布式计算框架的整体工作机制.mp4
2. 基于MapReduce的决策树算法实现:在Reducer中,主要实现了决策树算法的计算工作,包括对树的构建、决策树的分裂和叶节点的计算等。Reducer需要对Mapper输出的结果进行处理和计算,以生成最终的决策树模型。 3. ...
图解MapReduce,系统介绍Hadoop MapReduce工作过程原理
8. 计数模式(Counting with Counters):计数器是MapReduce中用于记录任务执行过程中特定事件次数的机制。它可以用来监控MapReduce作业的性能,例如计算错误数据的数量或特定数据的出现频率。 9. 过滤模式...
这篇论文详细介绍了MapReduce的概念、工作机制以及在实际中的应用。MapReduce模型通过两个主要函数——Map函数和Reduce函数来处理数据,使得程序员能够自动地并行化程序并执行于大规模集群计算环境中。 在MapReduce...
1. **理解MapReduce的工作原理**:深入学习MapReduce的工作机制,理解其分布式计算的优势。 2. **实际编程经验积累**:通过编写MapReduce程序,积累了实际编程经验,熟悉了Hadoop和MapReduce的API。 3. **分布式计算...




相关推荐
官方MapReduce运行机制动画图,详细描述Job的提交流程
在MapReduce的工作流程中,Shuffle机制扮演着至关重要的角色,它确保了数据在传递到Reducer阶段之前被正确地分区和排序。本文将深入探讨MapReduce的Shuffle机制,并讨论如何通过自定义Partitioner来满足特定的业务...
### MapReduce工作原理详解 #### 一、MapReduce概述与特性 MapReduce是一种分布式计算模型,主要用于处理大规模数据集。该技术由Google首先提出,并在Hadoop中得到了广泛应用。MapReduce的基本思想是将大规模的...
4. **容错机制**:MapReduce也内置了容错机制,如果某个Map或Reduce任务失败,系统会重新调度任务。 通过HDFS和MapReduce的协同工作,Hadoop能够处理PB级别的数据,广泛应用于数据分析、日志处理、推荐系统、机器...
- **容错性**:MapReduce框架内置了容错机制,当某个任务失败时,框架会自动重试该任务,确保数据处理的完整性。 #### 六、MapReduce的限制 尽管MapReduce是一种强大的数据处理模型,但它也有一定的局限性: - **...
在整个MapReduce过程中,涉及到了多个组件,包括HDFS、DataNode、inputformat等。HDFS是MapReduce运行的基础,提供了数据存储功能。DataNode是HDFS的组成部分,负责存储数据。inputformat负责定义数据如何被切割成...
运行结果可以通过Hadoop的Web界面查看,这有助于理解MapReduce的工作流程。 在MapReduce Web界面上,可以监控作业的进度、任务分布以及资源使用情况。此外,通过Shell命令如`mapred job -status id`,可以在运行...
#### 二、MapReduce的工作机制 1. **文件切片**:在MapReduce任务启动之前,首先对输入文件进行逻辑上的切片处理。每个切片对应一个独立的Map任务。切片的大小默认与HDFS块大小一致,但可以通过配置调整。 2. **Map...
MapReduce是一种分布式计算模型,由Google开发,用于处理和生成大量数据。这个模型主要由两个主要阶段组成:Map(映射)和Reduce(规约)。MapReduce的核心思想是将复杂的大规模数据处理任务分解成一系列可并行执行...
通过理解并动手实现这个框架,开发者不仅可以深入理解MapReduce的工作机制,还能掌握如何在实际项目中应用分布式计算解决大数据问题。对于那些关注人工智能和大数据处理的开发者,这将是一次宝贵的实践经历。
总之,MapReduce不仅仅是一项技术革新,它代表了一种思维方式的转变,即将复杂的大数据处理问题分解为可管理的小任务,再通过并行计算来加速整个过程。这一理念在当今的大数据时代依然具有重要意义,启发了后续众多...
#### 二、MapReduce的工作原理 MapReduce的基本思想是将大规模的数据集分割成较小的部分,通过并行处理的方式在多台计算机上进行计算。整个计算过程可以分为两个主要阶段:**Map** 和 **Reduce** 阶段。 1. **Map...
01.mapreduce分布式计算框架的整体工作机制.mp4
2. 基于MapReduce的决策树算法实现:在Reducer中,主要实现了决策树算法的计算工作,包括对树的构建、决策树的分裂和叶节点的计算等。Reducer需要对Mapper输出的结果进行处理和计算,以生成最终的决策树模型。 3. ...
图解MapReduce,系统介绍Hadoop MapReduce工作过程原理
8. 计数模式(Counting with Counters):计数器是MapReduce中用于记录任务执行过程中特定事件次数的机制。它可以用来监控MapReduce作业的性能,例如计算错误数据的数量或特定数据的出现频率。 9. 过滤模式...
这篇论文详细介绍了MapReduce的概念、工作机制以及在实际中的应用。MapReduce模型通过两个主要函数——Map函数和Reduce函数来处理数据,使得程序员能够自动地并行化程序并执行于大规模集群计算环境中。 在MapReduce...
1. **理解MapReduce的工作原理**:深入学习MapReduce的工作机制,理解其分布式计算的优势。 2. **实际编程经验积累**:通过编写MapReduce程序,积累了实际编程经验,熟悉了Hadoop和MapReduce的API。 3. **分布式计算...