
Learn how C4's concurrently compacting garbage collection algorithm helps boost Java scalability for low-latency enterprise Java applications, in this installment of Eva Andreasson's JVM performance optimization series.
By now in this series it is obvious that I consider stop-the-world garbage collection to be a serious roadblock to Java application scalability, which is fundamental to modern Java enterprise development. Fortunately, some newer flavors of JVMs are finding ways to either fine-tune stop-the-world garbage collection or -- better yet -- do away with its lengthy pauses altogether. I am excited about new approaches to Java scalability that fully leverage the potential of multicore systems, where memory is cheap and plentiful.
In this article I focus primarily on the C4 algorithm, which is an upgrade of the Azul Systems Pauseless GC algorithm, currently implemented only for the Zing JVM. I also briefly discuss Oracle's G1 and IBM's Balanced Garbage Collection Policy algorithms. I hope that learning about these different approaches to garbage collection will expand your sense of what is possible with Java's memory-management model and with Java application scalability. Perhaps it will even inspire you to come up with some new innovative ideas for handling compaction? You will at least know more about your options when choosing a JVM, along with some basic guidelines for different application scenarios. (Note that this article focuses on low-latency and latency-sensitive Java applications.)
Concurrency in the C4 algorithm
Azul Systems' Concurrent Continuously Compacting Collector (C4) algorithm takes an interesting and unique approach to low latency generational garbage collection. C4 is different from most generational garbage collectors because it is built on the assumptions that garbage is good -- meaning that applications generating garbage are doing good work -- and that compaction is inevitable. C4 is designed to satisfy varying and dynamic memory requirements, making it especially well-suited for long-running server-side applications.
Read the JVM performance optimization series
- JVM performance optimization, Part 1: Overview
- JVM performance optimization, Part 2: Compilers
- JVM performance optimization, Part 3: Garbage collection
The C4 algorithm decouples the process of freeing memory from application behavior and allocation rates. It is concurrent in a way that allows applications to run continuously without having to wait for the garbage collector to do its thing. This concurrency is key to providing consistently low pause times, regardless of how much live data is on the heap or how many references need to be traversed and updated during garbage collection. As I discussed in "JVM performance optimization, Part 3," most garbage collectors do stop-the-world compaction, which means that they experience increased pause times as the amount of live data and complexity on the heap increases. A garbage collector running the C4 algorithm does compaction concurrently with running application threads, thereby eliminating one of the biggest hurdles to JVM scalability.
Being concurrent, the C4 algorithm actually changes the premise of modern Java enterprise architecture and deployment models. Just consider what hundreds of GB per JVM instance could do for your Java applications:
- What does a Java deployment look like if it's able to scale within a single JVM instance rather than across many?
- What type of objects might be stored in memory that weren't before due to GC constraints?
- How might distributed clusters -- be they caches, region servers, or some other type of server nodes -- change as a result of larger JVM instances? What happens to traditional node counts, node deaths, and cache misses when the JVM size can increase without negatively impacting application responsiveness?
The three phases of the C4 algorithm
The main design premises of the C4 algorithm are "garbage is good" and "compaction is inevitable." C4's design goal is to be both concurrent and collaborative, thus eliminating the need for stop-the-world collection. The C4 garbage collection algorithm consists of three phases:
- Marking -- finding what's live
- Relocation -- moving things together to free up larger consecutive space (also known as compaction)
- Remapping -- updating references to moved objects
We'll look at each phase in detail.
Marking in C4
The marking phase of the C4 algorithm uses a concurrent marking and reference-tracing approach, which I discussed in detail in Part 3 of this series.
The marking phase is started by GC threads traversing the references from known live objects in thread stacks and registers. These threads continue to trace references until all reachable objects have been found on the heap. In this phase, the C4 algorithm is quite similar to other concurrent markers.
C4's marker starts to differentiate during the concurrent mark phase. If an application thread hits an unmarked object during this phase, it facilitates that object to be queued up for further reference tracing. It also ensures that the object is marked, so that it never has to be traversed again by the garbage collector or another application thread. This saves marking time and eliminates the risk of recursive remarks. (Note that a long recursive mark would potentially force the application to run out of memory before memory could be reclaimed -- a pervasive problem in most garbage collection scenarios.)
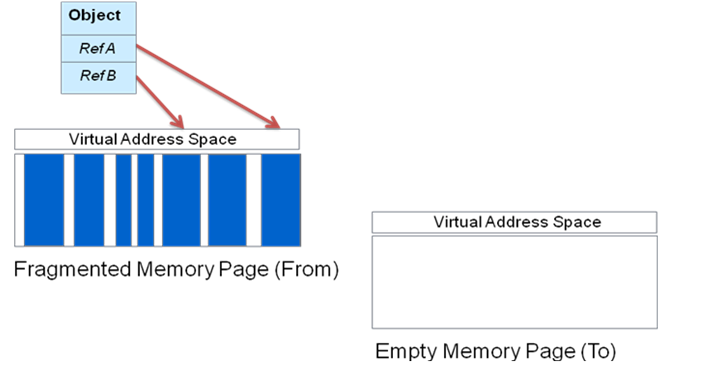 Figure 1. Application threads traverse the heap just once during marking
Figure 1. Application threads traverse the heap just once during marking
If the C4 algorithm relied on dirty-card tables or other methods of logging reads and writes into already-traversed heap areas, an application's GC threads might have to revisit certain areas for re-marking. In extreme cases a thread could get stuck in an infinite re-marking scenario -- at least infinite enough to cause the application to run out of memory before new memory could be freed. But C4 relies on a self-healing load value barrier (LVB), which enables application threads to immediately see if a reference is already marked. If the reference is not marked, the application thread will add it to the GC queue. Once the reference is in the queue it can't be re-marked. The application thread is free to continue on with its work.
Dirty objects and card tables
Objects that need to be revisited by the garbage collector for some reason (such as if the object has been accessed and changed during a concurrent GC cycle) are often called dirty objects. References to dirty objects, or dirty areas of the heap, are usually managed in a separate data structure, known as a card table.
With C4 there is never a need for a re-marking phase: all reachable objects are marked in the initial round of traversing the heap. Because the runtime never has to re-mark, endless re-marking loops are eliminated, thus reducing the risk of the application running out of memory before unreferenced memory can be reclaimed.
Relocation in C4 -- where threads and GC collaborate
The relocation phase of C4 is both collaborative and concurrent. This is because both GC and application threads are active concurrently, and because whichever thread first reaches an object to be moved can (collaboratively) facilitate that move. Application threads can thus smoothly continue their tasks, without having to wait for an entire garbage collection cycle to complete.
As Figure 2 shows, the live objects in a fragmented memory page are to be relocated. In the case of an application thread reaching a yet-to-be-moved object, the initial part of the move is facilitated by the application thread, so that it can quickly continue with its tasks. Virtual addresses (and thus references) are kept intact, so that memory can be immediately reclaimed.
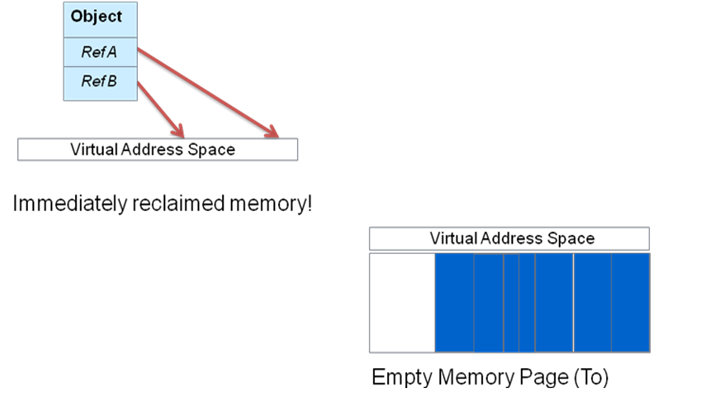 Figure 2. A page selected for relocation and the empty new page that it will be moved to
Figure 2. A page selected for relocation and the empty new page that it will be moved to
If a GC thread is assigned an object to be moved then there are no complications; the GC thread simply does the move. If an application thread tries to reach an object during the remapping phase (which is next), then it must check whether the object is to be moved. If so the application thread will escalate the relocation of the object so that it can continue with its work. (Larger objects are moved via shattered object moves. If you are interested in learning more about how shattered object moves work, I recommend reading the white paper "C4: The Continuously Concurrent Compacting Collector," listed in Resources.)
Once all the live objects are completely moved out of a memory page, anything left behind is garbage. The page that the objects have moved out of is immediately available to be reclaimed, as you can see in the bottom display of Figure 2.
What about sweep?
The C4 algorithm includes a mechanism that obviates the need for a sweep phase, thus eliminating an operation that is common to most GC algorithms. The virtual address space of the from page does have to be preserved until references to moved objects have been updated to point to their new location. So C4 implements a mechanism to guarantee that no virtual address space is unlocked until all references to that page are in a sane state. Then the algorithm is free to reclaim the physical memory page immediately.
Clearly there is great benefit to eliminating the need to stop the world in order to move objects together. As all live objects are concurrently moved during the relocation phase, they are also efficiently moved into adjacent addresses, where they end up fully compacted in the target page. Through concurrent relocation the heap is continuously compacted, without the need to ever stop all application threads at once. This approach to compaction removes the traditional limits to Java application access to memory (see Part 1 for more about the Java application memory model).
Having said all that, what about updating references? How is that not a stop-the-world operation?
Remapping in C4
Some references to moved objects are automatically updated as part of an object relocation. The references to a relocated page are not touched during the relocation phase, however, so they still need to be updated. C4's remapping phase handles updating references that are still pointing to a page where live objects have been moved out. The remapping phase is also concurrent and collaborative.
In Figure 3, live objects have just been moved to a new memory page during the relocation phase. After relocation, the GC threads immediately start updating references to preserved virtual memory addresses, pointing them to the moved objects' new locations. The garbage collector continues this activity until all references are updated and the virtual memory space can be reclaimed.
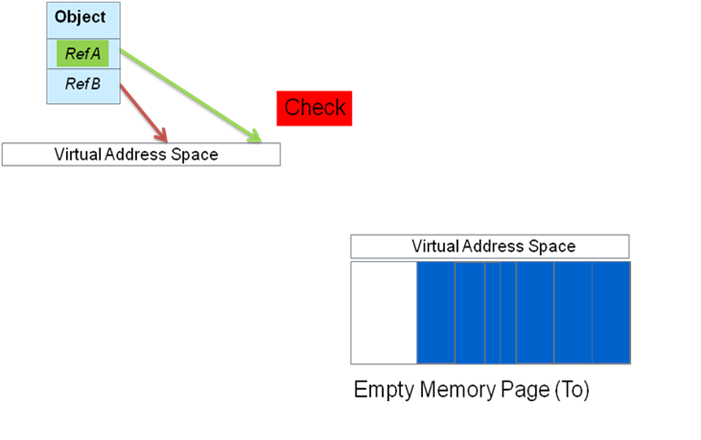 Figure 3. Whatever thread finds an invalid address enables an update to the correct new address
Figure 3. Whatever thread finds an invalid address enables an update to the correct new address
But what if an application thread tries to access a moved object before the GC has updated the reference? It's here that C4's ability to let the application thread collaboratively facilitate updates comes in handy. If an application thread hits this non-sane reference during a remapping phase, it will check to find out whether the reference needs to be updated. If it does, the application thread will retrieve the forwarding address and trigger an immediate reference update. Once that is done, it will smoothly resume its work.
The collaborative approach to remapping ensures that a reference only needs to be touched once to be updated. All subsequent reference calls will hit the new address. Additionally, a reference's forwarding addresses will not be stored in the previous object location, as is common with other GC implementations; instead it is stored in an off-heap structure. Rather than having to keep an entire page intact until all references are updated, memory can be instantly reclaimed.
So is C4 really pauseless?
A thread following a reference during the C4 remapping phase will be interrupted just once, and the interrupt will only last as long as a lookup and an update, after which the thread will be up and running. This approach to remapping is a huge improvement over other concurrent algorithms that have to run every single thread to a safe point, stop all threads at the same time, perform all reference updates, and only then release all threads.
For a concurrently compacting collector, pause time caused by garbage collection is never an issue. There is also no worse-case fragmentation scenario with C4's approach to relocation. A C4 garbage collector won't do back-to-back garbage collection cycles or stop the running application for seconds or even minutes at a time. If you ever did experience a stop-the-world scenario with this garbage collector, it would simply indicate that you had assigned your application too little memory. You can assign a garbage collector running the C4 algorithm as much memory as it needs, without ever having to worry about pause times.
Evaluating the C4 algorithm, and other alternatives
As always, you should choose a JVM and garbage collector based on the needs of your application. The C4 algorithm is designed to guarantee consistently low pause times, no matter how much live memory occupies your heap, as long as you provide enough memory to your application. This makes C4 an excellent choice for latency-sensitive application environments deployed on modern hardware, which has plenty of RAM.
C4 is a less optimal choice for client-side applications that run quickly, and usually within smaller heap sizes, with no issues. C4 is also not well-suited for applications that prioritize throughput (like static benchmarks). C4 really makes a difference for application scenarios that need to deploy 4 to 16 JVM instances per server in order to support the application load. C4 is also worth considering for an application scenario where you find yourself constantly tuning your garbage collector. Above all, consider C4 when response time is more important than throughput for your business use case. C4 is an ideal choice for applications that can't stop for a long time (be it downtime or GC pause time).
If you are considering using C4 for a production application, then you probably also want to rethink how you deploy. Instead of, for example, 16 JVM instances of 2-GB heap size each for your current application load per server, you could now consider one JVM with 64 GB (or two for failover). C4 wants as large a heap as possible to guarantee that a free page is always available for allocating threads. (Remember that memory is cheap!)
If you can't provide a server with 64 GB, 128 GB, or 1 TB RAM (or more), then a distributed multi-JVM deployment could be a better choice. In those cases you might consider using the Oracle HotSpot JVM's G1 garbage collector, or IBM JVM's Balanced Garbage Collection Policy. I'll briefly discuss both options below.
Garbage-First (G1) garbage collector
G1 (Garbage-First) is a fairly new garbage collector that is part of the Oracle HotSpot JVM. G1 first appeared in the later versions of JDK 6. It is enabled by specifying -XX:+UseG1GC on your Oracle JDK startup command line.
Like C4, this mark-and-sweep collector offers an alternative approach to garbage collection in latency-sensitive applications. The G1 algorithm divides HotSpot's heap into fixed-size areas, onto which partial collection can be applied. It utilizes background threads to do heap marking concurrently with running application threads, which is similar to other concurrent marking algorithms.
G1's incremental approach results in shorter but more frequent pauses, which for some applications is enough to avoid long stop-the-world pauses. On the downside, as discussed in Part 3, G1 does require you to spend time tuning the garbage collector for your current application load needs, and it does stop the world for GC interruptions. So G1 isn't a good fit for all low-latency applications. Moreover, the total time paused in G1 is high compared to in CMS, Oracle JVM's best-known concurrent mark-and-sweep collector.
G1 uses a copying algorithm (discussed in Part 3) for its partial collections. As a result, completely free areas are produced with each collection. The G1 garbage collector defines a set of areas as young space and the rest are designated as old space.
G1 has received considerable attention and caused some hype, but it presents challenges in real-world deployments. Getting the tuning right is one -- recall that there is no "right tuning" for dynamic application loads. One issue is how to handle large objects that are close to the size of the partitions, because the left-over spaces cause fragmentation. There is also a performance tax associated with low-latency garbage collectors generally, which is that the collector must manage additional data structures. For me, the key issue of using G1 would be how to manage stop-the-world pauses. Stop-the-world pauses hinder any garbage collector's ability to scale with growing heap sizes and live data sizes, presenting a roadblock to Java enterprise scalability.
IBM JVM Balanced Garbage Collection Policy
The IBM JVM Balanced Garbage Collection (BGC) Policy is enabled by specifying -Xgcpolicy:balanced on your IBM JDK startup command line. BGC looks at first glance very much like G1. It splits the Java heap into many equal-sized areas called regions, each of which can be collected independently. Heuristics are applied to choose which regions to garbage-collect for the best return on effort. BGC's approach to generations is very similar to G1's.
IBM's Balanced Garbage Collection Policy is available only on 64-bit platforms. It is NUMA (Non-Uniform Memory Architecture) aware, and it is designed to work well with heap sizes over 4 GB. BGC's partial collections are mostly stop-the-world GCs, either due to the copying approach or to the need for compaction (which is a non-concurrent operation). So in the end BGC reproduces the tuning and scalability challenges found in G1 and other low-latency garbage collectors that don't implement concurrent compaction.
In conclusion: Reflection points and highlights
C4 is a reference-tracing, generational, concurrent, and collaborative garbage collection algorithm. It is currently only implemented for Azul System's Zing JVM. The key values of the C4 algorithm are as follows:
- No more re-marking loops means no more risk of running out of memory due during a marking phase.
- Compaction, automatically and continuously throughout the relocation phase eliminates the old rule: the more live data on the heap, the longer the compaction pause.
- No more stop-the-world garbage collection means significantly faster application response times
- No more sweep phase reduces the risk of running out of memory before the entire GC is finished and all free memory is reclaimed.
- Memory is immediately reclaimed on a page basis, making large spaces of memory continuously available for memory-hungry Java applications.(
Concurrent compaction is what makes C4 unique. Letting application threads and GC threads collaboratively update object references, as they are discovered, ensures that your application will never be blocked until GC is finished. C4 fully decouples allocation rates from the ability to provide enough free and consecutive memory. The C4 algorithm enables you to make JVM instances as large as you need them, without worrying about pauses. Used appropriately, this is one JVM innovation that can bring low-latency Java applications up to speed with today's multicore and TB-size hardware.
G1 is a good alternative if you don't mind tuning and retuning, or frequent restarts, and if your application adapts well to a horizontal deployment model for scale, e.g., hundreds of small instances instead of few larger ones.
BGC is an innovative approach to dynamic low-latency heuristic adaption, something that JVM researchers have worked on for decades. This algorithm allows for slightly larger heap sizes. The downside of a dynamic self-tuning algorithm, is the instance when self-tuning can't keep up with sudden peaks and changes. You will still have to live with worst-case scenarios and allocate resources accordingly.
In the end the choice of best JVM and garbage collector for your application comes down to your priorities. What do you want to spend time and money on? From a purely technical angle,based on a decade of garbage collection experience, I am looking forward to seeing more innovation around concurrent compaction, or perhaps other approaches to moving objects or doing reallocation as a less intrusive operation. I think the key to Java enterprise scalability lies in concurrency.



зЫЄеЕ≥жО®иНР
Dive into JVM garbage collection logging, monitoring, tuning, and tools Explore JIT compilation and Java language performance techniques Learn performance aspects of the Java Collections API and get ...
гАРJavaдЄ≠зЪД`java.net.BindException: Address already in use: JVM_Bind`еЉВеЄЄгАС еЬ®JavaзЉЦз®ЛдЄ≠пЉМељУдљ†е∞ЭиѓХеРѓеК®дЄАдЄ™жЬНеК°еЩ®зЂѓеЇФзФ®пЉМе¶ВTomcatпЉМжИЦиАЕдїїдљХйЬАи¶БзЫСеРђзЙєеЃЪзЂѓеП£зЪДжЬНеК°жЧґпЉМеПѓиГљдЉЪйБЗеИ∞`java.net.BindException: ...
JVM ињРи°Мдњ°жБѓпЉЪJVM ињЫи°Мдњ°жБѓиЃ∞ељХдЇЖ JVM зЪДињРи°МзКґжАБпЉМеМЕжЛђ JVM зЪДзЙИжЬђеПЈгАБйЕНзљЃдњ°жБѓгАБзЇњз®ЛеИЧи°®гАБе†Ждњ°жБѓгАБGC дЇЛдїґгАБйАЖеРСдЉШеМЦдЇЛдїґгАБеЖЕйГ®йФЩиѓѓз≠Йдњ°жБѓгАВињЩдЇЫдњ°жБѓеПѓдї•еЄЃеК©еЉАеПСиАЕеТМзїіжК§иАЕењЂйАЯеЃЪдљНеТМиІ£еЖ≥йЧЃйҐШгАВ еі©жЇГеОЯеЫ†пЉЪ...
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗж°£иѓ¶зїЖдїЛзїНдЇЖJavaиЩЪжЛЯжЬЇпЉИJVMпЉЙзЪДзЫЄеЕ≥зЯ•иѓЖзВєпЉМжґµзЫЦJavaеЖЕе≠Шж®°еЮЛгАБеЮГеЬЊеЫЮжФґжЬЇеИґеПКзЃЧж≥ХгАБеЮГеЬЊжФґйЫЖеЩ®гАБеЖЕе≠ШеИЖйЕНз≠ЦзХ•гАБиЩЪжЛЯжЬЇз±їеК†иљљжЬЇеИґеТМJVMи∞ГдЉШз≠ЙеЖЕеЃєгАВй¶ЦеЕИйШРињ∞дЇЖJavaдї£з†БзЪДзЉЦиѓСеТМињРи°МињЗз®ЛпЉМдї•еПКJVMзЪД...
JavaиЩЪжЛЯжЬЇпЉИJVMпЉЙзЪДеЮГеЬЊжФґйЫЖпЉИGarbage Collection, GCпЉЙжШѓJavaз®ЛеЇПињРи°МжЧґзЃ°зРЖеЖЕе≠ШзЪДеЕ≥йФЃжЬЇеИґгАВеЃГиЗ™еК®еЬ∞иѓЖеИЂеєґйЗКжФЊдЄНеЖНдљњзФ®зЪДеѓєи±°пЉМдїОиАМйБњеЕНдЇЖз®ЛеЇПеСШжЙЛеК®зЃ°зРЖеЖЕе≠ШеПѓиГљеѓЉиЗізЪДеЖЕе≠Шж≥ДжЉПйЧЃйҐШгАВзРЖиІ£JVMзЪДGCеѓєдЇОдЉШеМЦJava...
JVM жЇРдї£з†Б part07
JVM жЇРдї£з†Б part06
иµДжЇРеРНзІ∞пЉЪжЈ±еЕ•зРЖиІ£JVM пЉЖ G1 GCеЖЕеЃєзЃАдїЛпЉЪG1 GCжПРеЗЇдЇЖдЄНз°ЃеЃЪжАІRegionпЉМжѓПдЄ™з©ЇйЧ≤RegionдЄНжШѓдЄЇжЯРдЄ™еЫЇеЃЪеєідї£еЗЖе§ЗзЪДпЉМеЃГжШѓзБµжіїзЪДпЉМйЬАж±Вй©±еК®зЪДпЉМжЙАдї•G1 GCдї£и°®дЇЖеЕИињЫжАІгАВгАКжЈ±еЕ•зРЖиІ£JVM пЉЖ G1 GCгАЛдЄїи¶БдЄЇе≠¶дє†Javaиѓ≠и®АзЪД...
4. **еЮГеЬЊжФґйЫЖжЬЇеИґ**пЉЪGCжШѓJVMиЗ™еК®зЃ°зРЖеЖЕе≠ШзЪДдЄїи¶БжЙЛжЃµпЉМжґЙеПКеИЖдї£жФґйЫЖгАБж†ЗиЃ∞-жЄЕйЩ§гАБе§НеИґгАБж†ЗиЃ∞-жХізРЖз≠Йе§ЪзІНзЃЧж≥ХгАВдє¶дЄ≠дЉЪиѓ¶зїЖдїЛзїНеРДзІНзЃЧж≥ХзЪДеЈ•дљЬеОЯзРЖгАБдЉШзЉЇзВєпЉМдї•еПКеЬ®дЄНеРМеЬЇжЩѓдЄЛзЪДйАЙжЛ©гАВ 5. **GCи∞ГдЉШ**пЉЪеМЕжЛђе¶ВдљХеИЖжЮР...
"JVM еПВжХ∞и∞ГдЉШ-optimization-jvm.zip"ињЩдЄ™еОЛзЉ©еМЕеЊИеПѓиГљжШѓеМЕеРЂдЇЖдЄАе•ЧеЕ≥дЇОJVMи∞ГдЉШзЪДиµДжЦЩжИЦиАЕдї£з†Бз§ЇдЊЛпЉМеПѓиГљеМЕжЛђжЦЗж°£гАБжХЩз®ЛжИЦеЈ•еЕЈгАВиЩљзДґеЕЈдљУзЪДжЦЗдїґеЖЕеЃєжЬ™зїЩеЗЇпЉМдљЖжИСдїђеПѓдї•ж†єжНЃж†ЗйҐШеТМжППињ∞жЭ•иЃ®иЃЇJVMи∞ГдЉШзЪДдЄАдЇЫеЕ≥йФЃзЯ•иѓЖзВє...
JVMдЄОGCи∞ГдЉШиѓЊз®ЛиІЖйҐС гАЦиѓЊз®ЛдїЛзїНгАЧ: JVMдЄОGCи∞ГдЉШиѓЊз®ЛиІЖйҐС гАЦиѓЊз®ЛзЫЃељХгАЧ: 1.зђФиЃ∞/ вФЬвФАвФА зђђ1зѓЗ-е≠ЧиКВз†БзѓЗ.png?x-oss-process=style/pnp8 вФЬвФАвФА зђђ2зѓЗ-з±їзЪДеК†иљљзѓЗ.png?x-oss-process=style/pnp8 вФЬвФАвФА зђђ3зѓЗ-ињРи°МжЧґ...
гАКжЈ±еЕ•зРЖиІ£JVM & G1 GCгАЛдЄАдє¶жЈ±еЕ•еЙЦжЮРдЇЖJavaиЩЪжЛЯжЬЇпЉИJVMпЉЙзЪДеЈ•дљЬеОЯзРЖпЉМзЙєеИЂжШѓйТИеѓєеЮГеЬЊжФґйЫЖеЩ®пЉИGCпЉЙдЄ≠зЪДG1пЉИGarbage-FirstпЉЙзЃЧж≥ХињЫи°МдЇЖиѓ¶е∞љзЪДжОҐиЃ®гАВJVMжШѓJavaз®ЛеЇПињРи°МзЪДеЯЇз°АпЉМеЃГиіЯиі£иІ£жЮРгАБзЉЦиѓСгАБжЙІи°МJavaдї£з†БпЉМеєґзЃ°зРЖ...
еЬ®JavaеЉАеПСдЄ≠пЉМJVMпЉИJavaиЩЪжЛЯжЬЇпЉЙзЪДжАІиГљдЉШеМЦжШѓдЄАй°єеЕ≥йФЃдїїеК°пЉМзЙєеИЂжШѓеѓєдЇОе§ІеЮЛз≥їзїЯиАМи®АпЉМйҐСзєБзЪДFull GCпЉИеЮГеЬЊжФґйЫЖпЉЙдЉЪеѓЉиЗіеЇФзФ®жЪВеБЬжЧґйЧіињЗйХњпЉМељ±еУНзФ®жИЈдљУй™МгАВжЬђиµДжЦЩ"jvm-full-gcи∞ГдЉШ-jvm-full-gc.zip"жШЊзДґжШѓйТИеѓєе¶ВдљХ...
4. **JVMеПВжХ∞и∞ГдЉШ**пЉЪ - `-Xms` еТМ `-Xmx`пЉЪиЃЊзљЃе†ЖеЖЕе≠ШзЪДеИЭеІЛе§Іе∞ПеТМжЬАе§Іе§Іе∞ПгАВ - `-XX:NewRatio`пЉЪжЦ∞зФЯдї£дЄОиАБеєідї£зЪДжѓФдЊЛгАВ - `-XX:SurvivorRatio`пЉЪEdenеМЇдЄОSurvivorеМЇзЪДжѓФдЊЛгАВ - `-XX:MaxHeapFreeRatio` еТМ `-...
### Sun Hotspot V1.6.0 JVM GCиѓ¶иІ£ #### дЄАгАБJVMзїУжЮДдЄОGCеЯЇз°АзЯ•иѓЖ ##### 1.1 JVMеЖЕе≠ШзїУжЮДж¶Вињ∞ JavaиЩЪжЛЯжЬЇпЉИJVMпЉЙеЖЕе≠ШдЄїи¶БеИЖдЄЇдї•дЄЛеЗ†дЄ™йГ®еИЖпЉЪ - **з®ЛеЇПиЃ°жХ∞еЩ®пЉИPC RegisterпЉЙ**пЉЪиЃ∞ељХељУеЙНзЇњз®ЛжЙАжЙІи°МзЪДе≠ЧиКВз†БжМЗдї§...
еЬ®myeclipseдЄ≠е∞ЖhtmlжЦЗдїґжФєжИРjspжЦЗдїґжЧґmyeclipseеН°дљПпЉЫе∞ЖдєЛеЙНзЪДдїїеК°еЕ≥жОЙпЉЫеЖНжЙУеЉАжЧґе§Ъжђ°йГ®зљ≤й°єзЫЃзЪДжЧґеАЩжК•йФЩ
JVM жЇРдї£з†Бpart1 пЉИзЬЛжИСзЪДдЄКдЉ†иЃ∞ељХ жЬЙ1--9 дЄ™partпЉЙ
JavaиЩЪжЛЯжЬЇпЉИJVMпЉЙжШѓJavaз®ЛеЇПињРи°МзЪДеЯЇз°АпЉМеЃГзЪДйЕНзљЃеПВжХ∞еТМеЮГеЬЊжФґйЫЖпЉИGCпЉЙжЬЇеИґеѓєдЇОдЉШеМЦеЇФзФ®з®ЛеЇПжАІиГљиЗ≥еЕ≥йЗНи¶БгАВжЬђжЦЗе∞ЖжЈ±еЕ•жОҐиЃ®JVMеПВжХ∞еПКеЕґдЄОJavaеЮГеЬЊжФґйЫЖзЫЄеЕ≥зЪДзЯ•иѓЖгАВ дЄАгАБJVMеПВжХ∞иѓ¶иІ£ JVMеПВжХ∞еПѓдї•еИЖдЄЇдЄЙз±їпЉЪеРѓеК®еПВжХ∞...
гАКJVMгАБGCиѓ¶иІ£еПКи∞ГдЉШгАЛжШѓдЄАдїљжЈ±еЕ•иІ£жЮРJavaиЩЪжЛЯжЬЇпЉИJVMпЉЙеТМеЮГеЬЊжФґйЫЖпЉИGarbage CollectionпЉМзЃАзІ∞GCпЉЙзЪДиѓ¶зїЖиµДжЦЩгАВжЬђжЦЗе∞Жж†єжНЃжПРдЊЫзЪДдњ°жБѓпЉМжЈ±еЕ•йШРињ∞JVMзЪДеЈ•дљЬеОЯзРЖпЉМGCзЪДжЬЇеИґдї•еПКе¶ВдљХињЫи°МJVMзЪДжАІиГљи∞ГдЉШгАВ й¶ЦеЕИпЉМJVMжШѓ...
4. **еЮГеЬЊжФґйЫЖ**пЉЪJVMжПРдЊЫдЇЖе§ЪзІНGCзЃЧж≥ХпЉМе¶ВSerialгАБParNewгАБParallel ScavengeгАБCMSгАБG1еТМZGCз≠ЙпЉМеЃГдїђеРДжЬЙдЉШзЉЇзВєпЉМйАВзФ®дЇОдЄНеРМеЬЇжЩѓгАВ **GCиѓ¶иІ£** 1. **GCзЫЃж†З**пЉЪGCзЪДдЄїи¶БзЫЃж†ЗжШѓйЂШжХИеЬ∞еЫЮжФґеЖЕе≠ШпЉМеЗПе∞СеБЬй°њжЧґйЧіпЉМеєґ...